새벽 2시, 페이지가 완전히 멈췄다는 알림이 옵니다. 확인해보니 WAS 서버 한 대가 다운됐고, keepalived가 Standby 서버로 Failover를 수행해 VIP가 이동됐습니다. 그런데 서비스가 살아나지 않습니다. VIP는 분명 신규 Active로 넘어갔는데 — DB 연결이 안 됩니다.
"Standby 서버에서 DB 방화벽 오픈이 빠졌네요." 선임이 말합니다. 망 분리 구조를 모르면 이 문장이 무슨 뜻인지조차 파악할 수 없습니다.
- 1DMZ, 내부망, DB망의 구분 기준과 각 구간에 위치하는 서버를 설명할 수 있다
- 2Active/Standby와 Active/Active 이중화의 차이와 선택 기준을 설명할 수 있다
- 3VIP가 서비스 연속성을 유지하는 원리를 설명할 수 있다
- 4실제 3-Tier 구성에서 구간별 방화벽 허용 정책을 파악할 수 있다
- 5WAS→DB 연결 실패 시 방화벽 오픈 여부를 점검하는 절차를 수행할 수 있다
망 분리 구조와 보안 원칙
외부에서 들어오는 트래픽이 DB 서버까지 직접 닿는다면 어떻게 될까요. 공격자가 Web 서버 한 대를 장악하는 순간 DB의 모든 데이터가 노출됩니다. 망 분리는 이 경로를 물리적·논리적으로 끊는 것입니다.
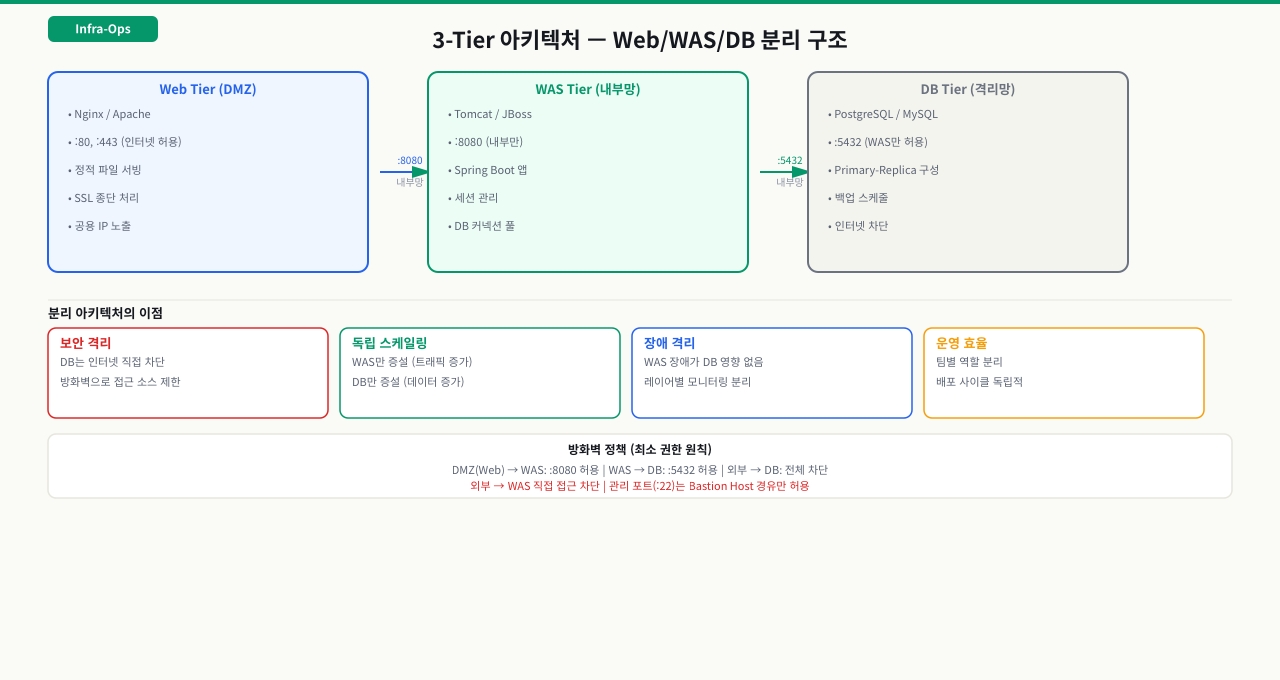
DMZ / 내부망 / DB망 — 3단 방어선
망 분리는 보안 요구사항처럼 느껴지지만, 실제로는 침해 범위를 제한하기 위한 인프라 설계 원칙입니다. Web 서버가 뚫렸을 때 DB까지 직선 경로가 있다면 단 한 번의 침해로 전체 데이터가 노출되지만, 구간 사이에 방화벽이 있으면 피해가 그 계층에서 멈춥니다. 이 구조를 이해해야 신규 서버 구성 요청을 받을 때 어느 구간에 어떤 방화벽 정책을 요청해야 하는지 판단할 수 있습니다.
 확대
확대
Web 서버가 해킹됐는데 DB 서버까지 접근이 됐다는 보고가 왔습니다. 망 분리 없이 모든 서버가 같은 네트워크에 있었기 때문입니다. 이 한 번의 침해로 고객 전체 데이터가 노출됐습니다. DMZ에 있는 Web 서버가 뚫리더라도 내부망 WAS나 DB망까지 이동할 수 없도록 구간을 나누는 것이 피해를 한 계층으로 제한하는 방법입니다.
서비스 인프라는 외부 노출 정도에 따라 세 구간으로 분리합니다.
DMZ (Demilitarized Zone, 비무장지대)
인터넷에서 직접 접근이 허용되는 구간입니다. Nginx, Apache 같은 Web 서버가 위치합니다. 방화벽은 외부에서 80/443 포트만 허용하고 나머지는 전부 차단합니다. DMZ 서버가 뚫려도 내부망에는 바로 접근할 수 없도록 구간 간 방화벽이 존재합니다.
내부망 (Internal Network)
WAS 서버가 위치하는 구간입니다. 외부 인터넷에서 직접 접근할 수 없습니다. Web 서버(DMZ)가 8080 포트로 WAS에 요청을 전달하는 것만 허용합니다. 개발자나 운영자의 직접 접근도 Bastion Host(점프 서버)를 경유해야 합니다.
DB망 (Database Network)
가장 폐쇄적인 구간입니다. WAS 서버에서 DB 포트(MySQL 3306, PostgreSQL 5432, Oracle 1521)로의 접근만 허용합니다. Web 서버에서 DB망으로의 직접 통신은 차단됩니다.
구간별 방화벽 허용 정책 예시:
| 출발지 | 도착지 | 허용 포트 | 차단 |
|---|---|---|---|
| 인터넷 (0.0.0.0/0) | DMZ (Web) | 80, 443 | 나머지 전체 |
| DMZ (Web) | 내부망 (WAS) | 8080 | 나머지 전체 |
| 내부망 (WAS) | DB망 (DB) | 3306 (MySQL) | 나머지 전체 |
| 인터넷 | 내부망 | — | 전체 차단 |
| 인터넷 | DB망 | — | 전체 차단 |
| DMZ | DB망 | — | 전체 차단 |
실무 원칙 — 포트 오픈 최소화:
방화벽 오픈 요청이 들어오면 "왜 필요한가?"를 반드시 확인합니다. "일단 전체 오픈해주세요"는 절대 수용하지 않습니다. 실제 통신에 필요한 IP와 포트만, 방향을 지정해서 오픈합니다.
방화벽 오픈 요청 양식 예시:
- 출발지 IP: 10.10.1.11 (WAS01)
- 목적지 IP: 10.10.3.10 (DB Primary)
- 포트: TCP 3306
- 목적: WAS → DB MySQL 연결
- 신청자: 홍길동 (개발팀)
- 승인자: 팀장 김철수
요청이 Web·WAS·DB 3계층을 완주하고 돌아오는 법 — 6단계
앞 절에서 계층을 왜 나누는지(심층 방어)를 봤다면, 이제 요청 하나가 그 세 계층을 어떻게 통과하고 역순으로 돌아오는지를 봅니다. 이 경로를 단계로 쥐고 있으면, 장애 알림이 왔을 때 "어느 계층 경계에서 막혔나"를 바로 좁힐 수 있습니다 — 경계마다 방화벽·타임아웃·커넥션 풀이라는 서로 다른 조절 지점이 있기 때문입니다.
[클라이언트] 주문 조회 요청 (HTTPS)
│
① DMZ · Web(Nginx) 수신 — TLS 종단, 정적이면 여기서 직접 응답
│
② 경계1 · Nginx → 내부망 WAS(8080) 중계 (구간 방화벽 8080 허용 필요)
│
③ WAS · 스레드 배정 → 비즈니스 로직 → DB 커넥션 풀에서 커넥션 1개 획득
│
④ 경계2 · WAS → DB망 DB(3306) 쿼리 전송 (구간 방화벽 3306 허용 필요)
│
⑤ DB · 쿼리 실행 → 결과를 WAS로 반환 → 커넥션 풀에 반납
│
⑥ WAS가 결과를 HTML/JSON으로 조립 → Nginx → 클라이언트
▼
[클라이언트] 200 OK (역순: DB → WAS → Web → 클라이언트)
각 단계와 경계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① Web 수신 | DMZ의 Nginx가 TLS 종단, 정적은 직접 처리 | Web 다운·80/443 미개방 → 클라이언트 타임아웃/refused |
| ② 경계1 (Web→WAS) | 구간 방화벽 8080을 지나 WAS로 중계 | 방화벽 미오픈·WAS 다운 → Nginx 502, connection timed out |
| ③ WAS 로직·커넥션 획득 | 스레드 배정 후 DB 커넥션 풀에서 커넥션 확보 | 풀 고갈 → 스레드가 커넥션 대기로 묶임 → 지연 폭증·pool timeout, 처리량 급락 |
| ④ 경계2 (WAS→DB) | 구간 방화벽 3306을 지나 쿼리 전송 | 방화벽 미오픈 → java.net.ConnectException: timed out · 계정/권한 → Access denied |
| ⑤ DB 실행·반납 | 쿼리 실행 후 커넥션을 풀에 되돌림 | 슬로우 쿼리·락 → DB에서 지연 → 커넥션이 오래 안 반납됨 → ③의 고갈을 가속 → 504 |
| ⑥ 조립·응답 | 결과를 응답 본문으로 만들어 역순 전달 | 대용량 결과를 WAS 메모리에서 조립 → GC 압박·OOM 위험 |
정리하면 "연결 자체가 안 된다"는 대개 경계(②의 8080, ④의 3306)의 방화벽·기동 문제이고, nc -zv DB_IP 3306으로 그 경계부터 확인합니다. 반면 "연결은 되는데 느리다·일부만 실패한다"는 대개 ③↔⑤의 커넥션 풀-DB 축입니다 — 슬로우 쿼리가 커넥션을 오래 물면(⑤) 풀이 마르고(③), 스레드가 대기하다 504로 번집니다. 계층을 나눈 이유가 여기서 드러납니다: 경계마다 독립된 방화벽·타임아웃·풀 크기라는 손잡이가 생겨, 장애를 한 계층에 가두고 계층별로 스케일·격리할 수 있습니다.
1. 현재 서버 IP 및 네트워크 인터페이스 확인
ip addr show | grep 'inet ' | grep -v '127.0.0.1'2. DB 포트 외부 노출 여부 확인
ss -tlnp | grep -E ':3306|:5432|:1521' && echo '---DB 포트 바인딩 확인---'3. 서버 간 연결 가능 여부 테스트
timeout 2 bash -c 'echo >/dev/tcp/127.0.0.1/3306' 2>/dev/null && echo 'DB 포트 열림' || echo 'DB 포트 닫힘 또는 없음'- ss -tlnp | grep 3306 으로 바인딩 IP 먼저 확인, 그 다음 ip addr show 로 서버 IP 대역 확인 — 바인딩 IP와 서버 네트워크 구성을 함께 봐야 외부 접근 가능 여부를 정확히 판단
- 바인딩 기준: 127.0.0.1=로컬 전용(외부 DB 분리 환경에서는 잘못된 설정), 10.10.3.X=내부 DB망만 허용(정상), 0.0.0.0=모든 IP 허용(즉시 조치) — DB 서버는 WAS망 IP로만 바인딩이 표준
- DB 포트가 내부망 IP로 바인딩됐는데 WAS에서 연결 실패하면 → 방화벽이 WAS→DB 구간을 차단 중 — nc -zv DB_IP 3306 으로 포트 도달 여부 확인 후 "succeeded" 없으면 방화벽 오픈 요청
이중화 구조 패턴
서버 한 대가 죽었을 때 서비스가 멈추면 안 됩니다. 이중화는 이 상황을 버티기 위한 설계입니다. 하지만 방식에 따라 비용과 복잡도, 세션 관리 방법이 달라집니다.
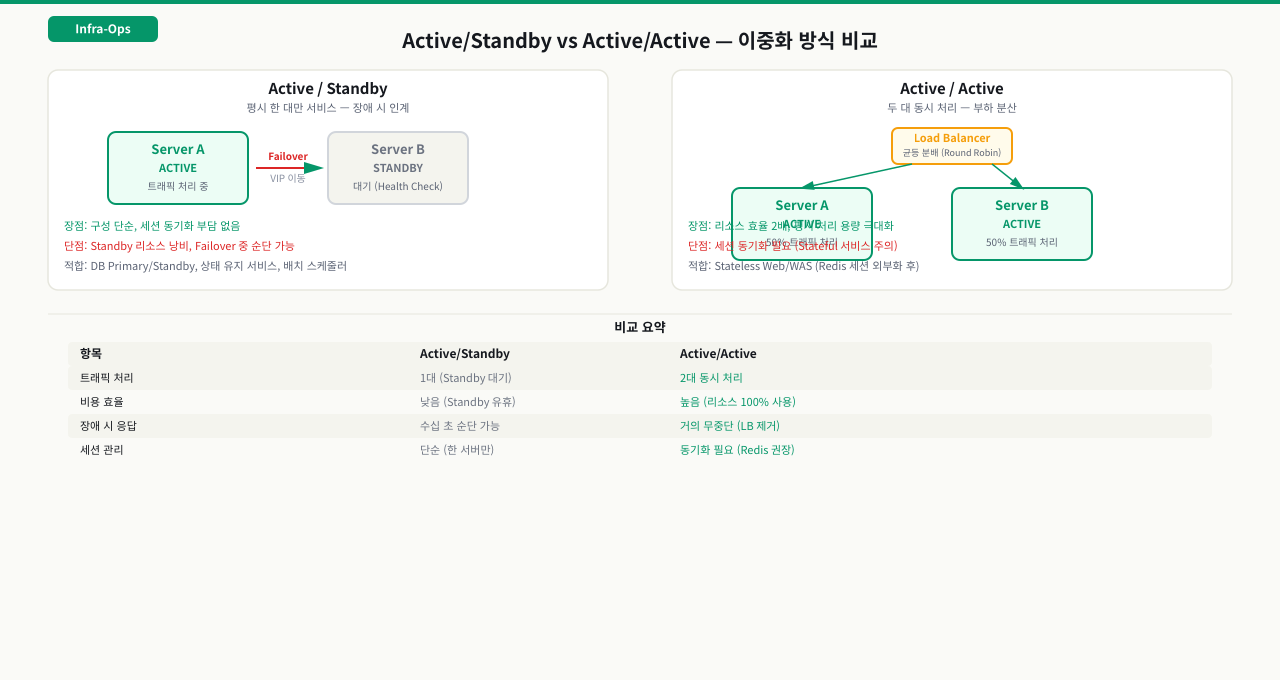
Active/Standby vs Active/Active
이중화 방식을 잘못 선택하면 "서버가 두 대인데 한 대가 고장나자 서비스가 전체 다운됐다"는 역설적인 상황이 생깁니다. 세션을 로컬 메모리에 두는 Stateful 서비스를 Active/Active로 구성하면 로드밸런서가 다른 서버로 요청을 보내는 순간 세션이 사라지고, 쓰기 일관성이 중요한 DB를 Active/Active로 묶으면 Split-Brain으로 데이터가 분기됩니다. 어떤 방식이 맞는지는 서비스가 Stateful인지 Stateless인지, 쓰기 충돌이 발생할 수 있는지에 따라 달라집니다.
 확대
확대
새벽에 DB 서버 한 대가 다운됐는데 서비스가 멈췄습니다. Standby 서버가 있었지만 systemctl enable을 빠뜨려 자동으로 뜨지 않았기 때문입니다. 이중화 구성 자체보다 "장애 시 어떤 흐름으로 전환되는가"를 이해하지 못하면, 이중화를 만들어놓고도 작동하지 않는 상황이 됩니다.
Active/Standby (장애 대기 방식)
평시에는 Active 서버 한 대가 모든 트래픽을 처리합니다. Standby 서버는 대기 상태로 Health Check만 수행합니다. Active 서버에 장애가 발생하면 VIP가 Standby로 이동(Failover)하고 Standby가 서비스를 인계받습니다.
- 장점: 구성 단순, 세션 동기화 부담 적음
- 단점: Standby 서버 리소스 낭비, Failover 중 수십 초의 순단 발생 가능
- 적합한 상황: DB 서버(Primary/Standby), 스케줄러, 상태 유지가 중요한 서비스
Active/Active (부하 분산 방식)
두 대 모두 실제 트래픽을 나눠서 처리합니다. 한 대가 장애 나면 남은 서버가 전체 트래픽을 받습니다.
- 장점: 리소스 효율적, 평시 처리 용량 2배
- 단점: 세션 동기화 필요(Stateful 서비스), 구성 복잡도 상승
- 적합한 상황: Stateless한 Web 서버, 로드밸런서 뒤의 WAS
세션 동기화 — Stateful vs Stateless:
WAS가 로그인 세션을 메모리에 저장하면(Stateful), 로드밸런서가 요청을 다른 WAS로 보낼 때 "로그아웃됐다"는 현상이 발생합니다. 이를 해결하는 방법은 두 가지입니다.
- 세션 외부화: Redis 같은 중앙 세션 저장소에 세션을 저장 → Stateless WAS 구현
- Sticky Session(세션 고정): 같은 사용자의 요청은 항상 같은 WAS로 보내도록 로드밸런서 설정
Split-Brain 문제:
Active/Standby 구성에서 두 노드 간 Heartbeat 통신이 끊기면, 두 노드가 모두 "내가 Active"라고 판단하는 Split-brain이 발생합니다. DB 같은 쓰기 서비스에서 Split-brain이 발생하면 데이터가 분기됩니다. STONITH(Shoot The Other Node In The Head) — 즉, 상대 노드를 강제로 끄는 메커니즘 — 로 이를 방지합니다.
VIP와 로드밸런서
IP 주소는 서버에 종속됩니다. 서버가 교체되면 IP가 바뀌고, 클라이언트는 새 IP를 알아야 합니다. VIP는 이 의존성을 끊는 방법입니다.
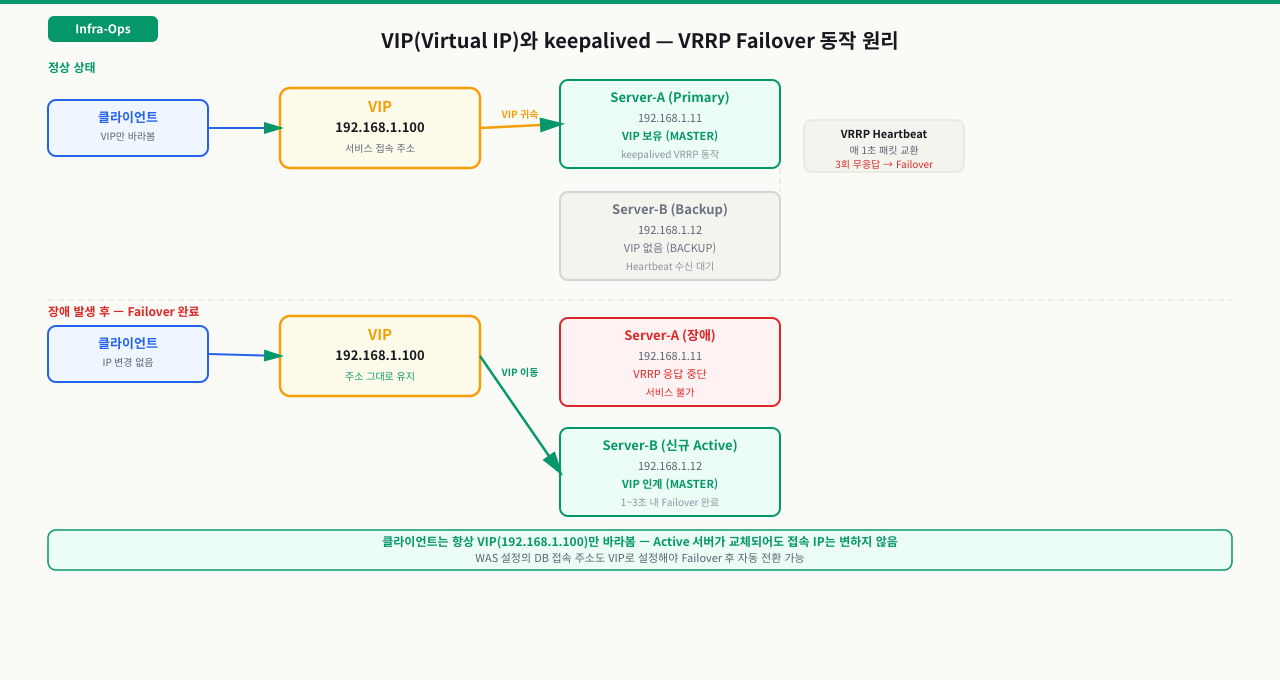
VIP(Virtual IP)와 keepalived
Failover가 됐는데도 서비스가 살아나지 않는다면 VIP 개념을 모른 채 설정한 경우가 대부분입니다. 실제 서버 IP가 아닌 VIP로 접속하도록 구성해두면 Active 서버가 교체될 때 클라이언트나 상위 로드밸런서는 아무것도 바꾸지 않아도 됩니다. VIP가 없으면 DB 접속 문자열에 Primary 서버의 실제 IP를 하드코딩하게 되고, Failover 직후 새 Primary로 자동 전환이 되지 않아 수동 개입이 필요한 상황이 반복됩니다.
 확대
확대
Failover가 됐는데 서비스가 살아나지 않았습니다. 확인해보니 WAS 설정에 DB 서버 IP가 실제 IP로 하드코딩되어 있었고, Failover 후 새로운 Primary IP로 자동 전환이 안 됐습니다. VIP를 쓰면 실제 서버가 바뀌어도 접속 IP는 변하지 않습니다. 이 차이를 모르면 이중화 구성이 완성돼 있어도 장애 복구가 안 됩니다.
VIP란:
실제 서버 NIC에 할당된 IP가 아닌, 소프트웨어로 관리되는 가상 IP입니다. 클라이언트나 로드밸런서는 항상 VIP로 접속합니다. Active 서버가 바뀌면 VIP만 새 Active 서버로 이동합니다.
keepalived와 VRRP:
Linux 환경에서 VIP를 구현하는 가장 일반적인 방법입니다. keepalived는 VRRP(Virtual Router Redundancy Protocol) 프로토콜을 이용해 두 서버가 Heartbeat를 주고받으며 Master(Active)를 결정합니다.
# keepalived 상태 확인
systemctl status keepalived
# 현재 VIP가 어느 인터페이스에 붙어 있는지 확인
ip addr show | grep -A2 'eth0'
# Active 서버: inet 10.10.1.100/24 scope global secondary eth0:vip
# Standby 서버: eth0:vip 항목 없음
Failover 발생 시: Active 서버에서 keepalived 응답이 끊기면 Standby가 자신을 Master로 선언하고 VIP를 자신의 인터페이스로 가져옵니다. 이 전환은 보통 1~3초 내에 완료됩니다.
L4 로드밸런서 vs L7 로드밸런서:
| 구분 | L4 LB | L7 LB |
|---|---|---|
| 판단 기준 | IP + Port | HTTP URL, 헤더, 쿠키 |
| 속도 | 빠름 (패킷 레벨) | 상대적으로 느림 (패킷 조립 후 분석) |
| 주요 사용처 | TCP 기반 분산 (DB, WAS) | HTTP 기반 분산 (Web, API) |
| Sticky Session | IP Hash 방식 | 쿠키 기반 가능 |
| 대표 솔루션 | L4 Switch, HAProxy (TCP) | Nginx, HAProxy (HTTP), AWS ALB |
Health Check:
로드밸런서는 주기적으로 서버에 요청을 보내 응답 여부를 확인합니다. 일정 횟수 이상 실패하면 해당 서버를 분산 대상에서 제외합니다.
# Nginx upstream health check 설정 예시
upstream was_pool {
server 10.10.2.10:8080;
server 10.10.2.11:8080;
}
# HAProxy에서는 'check' 옵션으로 Health Check 활성화
# server was01 10.10.2.10:8080 check inter 3s fall 3 rise 2
실제 3-Tier 구성 예시
이론이 아닌 실제 서버 목록과 IP, 포트, 방화벽 정책을 전부 나열해봅니다.
웹 2대 + WAS 4대 + DB 2대 구성
이론으로만 배운 3-Tier 구조는 실제 서버 목록과 IP 대역을 눈으로 보기 전까지 추상적으로 느껴집니다. was02가 다운됐을 때 나머지 3대에 어떻게 트래픽이 재분배되는지, db01 장애 시 db-vip가 db02로 이동하는 흐름이 실제로 어떻게 동작하는지를 구체적인 숫자와 함께 보면 운영 중 받는 장애 알림과 판단이 실제 서버 구성과 연결됩니다. 특히 어느 서버의 방화벽이 열려있어야 하는지를 파악하는 것이 운영 엔지니어의 핵심 역량입니다.
 확대
확대
이론과 달리 실제 서버 목록과 IP를 보면 이해가 달라집니다. was02가 다운됐을 때 나머지 3대에 트래픽이 어떻게 분산되는지, db01 장애 시 db-vip가 db02로 이동하는 흐름이 어떻게 되는지 — 구체적인 숫자와 함께 보면 추상적인 이중화 개념이 실제 운영 판단과 연결됩니다.
서버 목록:
| 서버명 | 역할 | IP | 구간 | OS/미들웨어 |
|---|---|---|---|---|
| web01-prd | Web (Active) | 10.10.1.11 | DMZ | RHEL 8 / Nginx |
| web02-prd | Web (Active) | 10.10.1.12 | DMZ | RHEL 8 / Nginx |
| web-vip | Web VIP | 10.10.1.100 | DMZ | — (가상) |
| was01-prd | WAS | 10.10.2.11 | 내부망 | RHEL 8 / Tomcat |
| was02-prd | WAS | 10.10.2.12 | 내부망 | RHEL 8 / Tomcat |
| was03-prd | WAS | 10.10.2.13 | 내부망 | RHEL 8 / Tomcat |
| was04-prd | WAS | 10.10.2.14 | 내부망 | RHEL 8 / Tomcat |
| db01-prd | DB Primary (Active) | 10.10.3.11 | DB망 | RHEL 8 / MySQL |
| db02-prd | DB Standby | 10.10.3.12 | DB망 | RHEL 8 / MySQL |
| db-vip | DB VIP | 10.10.3.100 | DB망 | — (가상) |
트래픽 경로:
인터넷 클라이언트
→ web-vip (10.10.1.100:443)
→ Nginx (web01 또는 web02, Active/Active)
→ WAS 로드밸런서 (Nginx upstream, 4대 분산)
→ WAS 01~04 (Active/Active)
→ db-vip (10.10.3.100:3306)
→ MySQL Primary (db01, Active/Standby)
장애 시나리오별 서비스 영향:
| 장애 서버 | VIP 이동 | 서비스 영향 |
|---|---|---|
| web01 다운 | web-vip는 web02가 흡수 | 순단 없음 (Active/Active) |
| was02 다운 | LB가 was02 제외 | 나머지 3대로 분산, 처리량 감소 |
| db01 다운 | db-vip → db02로 이동 | Failover 중 수십 초 순단 |
| db-vip 미이동 | — | 서비스 전체 중단 (DB 연결 불가) |
서버 네트워크 구성 확인
서버 IP 및 네트워크 인터페이스 확인
ip addr show라우팅 테이블 확인
ip route showWAS → DB 포트 연결 확인 (방화벽 점검)
nc -zv 10.10.3.100 3306Web → WAS Health Check 확인
curl -o /dev/null -s -w "%{http_code}" http://10.10.2.11:8080/healthkeepalived 상태와 VIP 위치 확인
systemctl status keepalived && ip addr show | grep secondary- ip addr show 로 VIP 보유 여부 먼저 확인, 그 다음 nc -zv DB_IP 3306 으로 DB 포트 도달 확인, 마지막으로 curl 로 서비스 응답 확인 — 이 순서로 네트워크 레이어를 단계별 검증
- nc 결과 기준: succeeded=방화벽 오픈 정상, Connection refused=방화벽은 열렸지만 DB 프로세스 미기동, 타임아웃=방화벽 차단 — Connection refused와 타임아웃을 구분해야 조치 방향이 달라짐
- nc succeeded인데 WAS에서 DB 연결 실패하면 → DB 계정 권한 문제 또는 DB가 127.0.0.1 바인딩 중 — mysql -h DB_IP -u appuser -p 로 직접 연결 테스트 후 "Access denied" 이면 계정/권한 확인
트러블슈팅
심화 — keepalived가 Master를 정하는 방식, 그리고 Split-Brain
심화: VRRP는 '상대가 들리는가'로 생사를 판정한다 — '안 들린다'와 '죽었다'의 간극
앞에서 keepalived가 Heartbeat로 Master를 정하고, Heartbeat가 끊기면 Split-Brain이 난다고 했습니다. 그 판정 방식을 한 단계 들여다보면 왜 Split-Brain이 이중화의 가장 위험한 함정인지가 보입니다.
- VRRP의 판정 방식: 각 노드는 우선순위(
priority)를 갖고, Master는 주기적으로 VRRP advertisement를 멀티캐스트(224.0.0.18, IP 프로토콜112)로 보냅니다. Backup은 이 광고를 '들으며' Master가 살아있다고 믿습니다. 광고가 일정 시간(대개 광고 주기의 3배) 안 들리면 Backup은 자신을 Master로 승격하고 VIP를 가져간 뒤, GARP(gratuitous ARP)를 뿌려 스위치의 MAC 테이블을 새 위치로 갱신합니다. - 핵심 함정: 이 판정은 오로지 '광고가 들리는가'에만 의존합니다. 그런데 '광고가 안 들린다'는 두 가지를 구분하지 못합니다 — 상대가 정말 죽은 것과, 둘 사이 하트비트 경로만 끊긴 것. 후자라면 두 노드 모두 상대가 죽었다고 믿고 둘 다 Master가 되어 VIP를 동시에 보유합니다. 이것이 Split-Brain입니다. '나는 네가 안 들려' 는 '너는 죽었다' 와 결코 같지 않습니다.
- 그래서 설계에서 지켜야 할 것: ① 하트비트 경로를 서비스 트래픽 경로와 물리적으로 분리·이중화해 한 링크가 끊겨도 다른 경로로 서로를 확인. ② 노드 사이의 방화벽·보안그룹이 VRRP(멀티캐스트·프로토콜
112, 또는unicast_peer설정 시 그 경로)를 반드시 허용. ③virtual_router_id를 같은 세그먼트 안에서 유일하게 — 다른 keepalived 쌍과 겹치면 서로를 같은 그룹으로 오인. ④ 쓰기 DB에는 STONITH/펜싱을 걸어 Split-Brain 순간 한 노드를 강제로 격리해 진짜 하나만 살아남게 함.
정리하면 이중화에서 '서비스 경로'만큼 중요한 것이 '하트비트 경로'입니다. 서비스는 멀쩡한데 노드끼리 서로를 확인하는 길만 막혀도, 이중화가 오히려 장애의 원인이 됩니다.
상황: keepalived로 db-vip를 이중화했는데, 애플리케이션이 db-vip로 붙으면 연결이 '됐다 안 됐다'를 반복합니다. 두 DB 노드에 각각 들어가 ip addr를 찍어 보면 둘 다 VIP를 들고 있고, journalctl -u keepalived에도 양쪽 모두 MASTER 진입 로그가 찍혀 있습니다. 서버는 둘 다 멀쩡히 살아 있습니다.
원인: Split-Brain입니다. 두 노드 사이의 VRRP 광고가 서로에게 닿지 못하고 있습니다. 방화벽·보안그룹이 노드 간 VRRP(멀티캐스트 224.0.0.18·프로토콜 112, 또는 unicast VRRP 경로)를 막았거나, 최근 네트워크 정책 변경으로 하트비트 경로만 끊긴 상황입니다. 서로 상대의 광고를 못 들으니 둘 다 '상대가 죽었다'고 판단해 둘 다 Master가 되고, 둘 다 GARP를 뿌려 스위치의 MAC 매핑이 요청마다 오락가락합니다 — 그래서 '됐다 안 됐다'가 됩니다.
진단: 각 노드에서 journalctl -u keepalived | grep -i state로 양쪽이 동시에 MASTER인지 확인합니다. 그다음 tcpdump -ni eth0 proto 112로 상대 노드의 VRRP 광고가 실제로 도착하는지 봅니다 — 자기 것만 보이고 상대 것이 안 보이면 하트비트 경로 단절이 확정입니다. virtual_router_id가 두 노드에서 같은지, 같은 세그먼트의 다른 keepalived 쌍과 겹치지 않는지도 함께 확인합니다.
해결: 노드 간 VRRP 경로(방화벽·보안그룹의 멀티캐스트·프로토콜 112 또는 지정 unicast)를 다시 열어 하트비트를 복구하면 우선순위 낮은 쪽이 Backup으로 내려갑니다. 근본 예방은 하트비트 링크를 서비스망과 분리·이중화하고, 쓰기 DB에는 STONITH/펜싱을 걸어 Split-Brain 시 한 노드를 강제 격리하는 것입니다(L4/L7 로드밸런서와 VIP 기반 이중화 구성). virtual_router_id 중복이 있었다면 그것부터 유일하게 정리합니다.
실제 업무에서 이 지식이 쓰이는 상황:
금융사 온프레미스 신규 프로젝트의 서버 구성 요청서가 들어왔습니다. "Web 서버 2대, WAS 서버 2대, DB 서버 1대 주세요."
인프라 엔지니어로서 이 요청을 검토할 때 확인해야 하는 것들입니다.
첫째, DB 서버가 1대면 이중화가 없습니다. DB 서버 장애 시 서비스 전체가 멈춥니다. "DB도 2대로 Active/Standby 구성이 필요합니다. 1대면 SLA를 맞출 수 없습니다."
둘째, 서버 구간이 명시되어 있지 않습니다. Web 서버는 DMZ, WAS는 내부망, DB는 DB망에 위치해야 하고, 각 구간 사이의 방화벽 오픈 정책을 사전에 확인해야 합니다.
셋째, WAS에서 DB로 접속할 때 DB VIP를 사용해야 합니다. 실제 DB 서버 IP(10.10.3.11)로 하드코딩하면 Failover 후 신규 Primary로 자동 전환되지 않습니다.
이 검토를 서버 발주 전에 해야 구성 완료 후 "DB 접속이 안 된다"는 장애를 막을 수 있습니다. 신규 구성 검토부터 방화벽 오픈 요청, Failover 테스트까지 — 인프라 엔지니어의 업무 흐름입니다.
명령어·단축키 빠른 참조
이 모듈에서 다룬 망 분리·이중화 점검 명령을 실전 옵션과 함께 모았습니다. "예" 열의 조합을 그대로 써도 됩니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
nc -zv 10.10.3.100 3306 | WAS→DB 포트 도달(방화벽) 확인 | succeeded=열림, 타임아웃=차단, refused=DB 미기동 |
telnet DB_IP 3306 | nc 없을 때 포트 확인 대안 | 연결되면 방화벽 통과 |
ss -tlnp | grep -E ':3306|:5432' | DB 포트 바인딩 IP 확인 | 0.0.0.0=전체 노출(위험), 내부망 IP=정상 |
ip addr show | 서버 IP·VIP 보유 확인 | VIP는 secondary/:vip로 표시 |
ip route show | 타 구간 라우팅 경로 확인 | 경로 없으면 통신 자체 불가 |
curl -o /dev/null -s -w "%{http_code}" | Web→WAS Health Check | http://10.10.2.11:8080/health 200 확인 |
systemctl status keepalived | VIP 관리 데몬 상태 | 자동기동: systemctl enable nginx tomcat |
journalctl -u keepalived | grep -i state | Master/Backup 전환 이력 | 양쪽 다 MASTER면 Split-Brain |
tcpdump -ni eth0 proto 112 | VRRP 광고 도달 확인 | 자기 것만 보이면 하트비트 단절 |
mysql -h DB_IP -u appuser -p | DB 직접 연결 테스트 | Access denied=계정·권한 문제 |
관련 모듈로 더 깊이:
- Web Server와 WAS 미들웨어 구조의 이해 — 망 분리 이전에 Web/WAS 역할 분담의 기본 구조
- L4/L7 로드밸런서와 VIP 기반 이중화 구성 — Active/Standby Failover와 DB VIP 전환의 동작 원리
- 네트워크 방화벽 정책과 요청서 작성 실무 — DMZ·내부망·DB망 사이 방화벽 오픈 정책 설계
다음 모듈에서는 실제 Nginx 설정에서 upstream WAS 풀을 구성하고 Health Check를 붙이는 구체적인 방법을 다룹니다.