프로덕션 서버에서 응답 없는 프로세스를 마주쳤을 때 반사적으로 kill -9를 입력하는 엔지니어가 많습니다. 그런데 어느 날 DB 프로세스에 kill -9를 날렸다가 데이터 파일이 손상되는 사고가 났습니다. 알고 보니 SIGKILL은 cleanup 코드를 실행할 기회 없이 프로세스를 즉시 종료합니다.
시그널의 동작 방식을 이해하면 안전하게 종료하고, 세션이 끊겨도 작업을 유지하며, bash 스크립트에서 정리 로직까지 구현할 수 있습니다.
시그널 & 프로세스 종료
- 1리눅스 시그널의 개념과 커널 전달 메커니즘을 설명할 수 있다
- 2SIGTERM과 SIGKILL의 차이를 이해하고 안전한 종료 순서를 적용할 수 있다
- 3kill, killall, pkill로 프로세스에 시그널을 전송할 수 있다
- 4bash trap으로 스크립트 내 시그널 핸들러를 구현해 정리 로직을 보장할 수 있다
- 5좀비·고아 프로세스 발생 원인을 이해하고 부모 프로세스를 통해 처리할 수 있다
kill -lps aux | head -20sudo apt-get install -y tmux # 또는 sudo yum install -y tmuxkill -9(SIGKILL)는 데이터 정리 없이 즉시 종료되므로 프로덕션에서는 먼저 SIGTERM을 시도할 것
리눅스 시그널(Signal)이란 무엇인가
systemctl stop 으로 서비스를 내렸는데 30초를 기다렸다가 종료되고, Ctrl+C로 프로그램을 끊었을 때 클린업 작업이 진행되기도 합니다. 반면 kill -9는 항상 즉시 종료됩니다. 이 차이는 운영체제가 프로세스에게 "지금 멈춰"를 전달하는 방식, 즉 시그널에 있습니다. Ctrl+C, systemctl stop, kill 명령 모두 내부적으로 시그널을 보내는 것이며, 어떤 시그널인지에 따라 프로세스의 반응이 달라집니다. 시그널의 종류와 처리 방식을 이해하면 서비스 종료가 왜 때로는 우아하게, 때로는 강제로 이루어지는지 파악할 수 있습니다.
운영체제 위에서 동작하는 프로세스들은 서로 의사소통할 방법이 필요합니다. 사람이 다른 사람에게 어깨를 두드려 "잠깐, 지금 멈춰"라고 알리는 것처럼, 운영체제는 프로세스에게 **시그널(Signal)**을 보내 즉각적인 행동 변화를 요청합니다. Ctrl+C로 프로그램을 멈추는 것도, systemctl stop nginx로 서비스를 종료하는 것도, 모두 내부적으로 시그널을 통해 이루어집니다.
**시그널(Signal)**은 커널 또는 다른 프로세스가 특정 프로세스에게 보내는 비동기 알림입니다. 프로세스는 시그널을 받으면 실행 흐름을 즉시 중단하고 해당 시그널에 대한 처리(핸들러)를 수행합니다. 시그널은 IPC(Inter-Process Communication)의 가장 단순한 형태이며, 운영체제 수준에서 프로세스 생명주기를 제어하는 핵심 메커니즘입니다.
 확대
확대
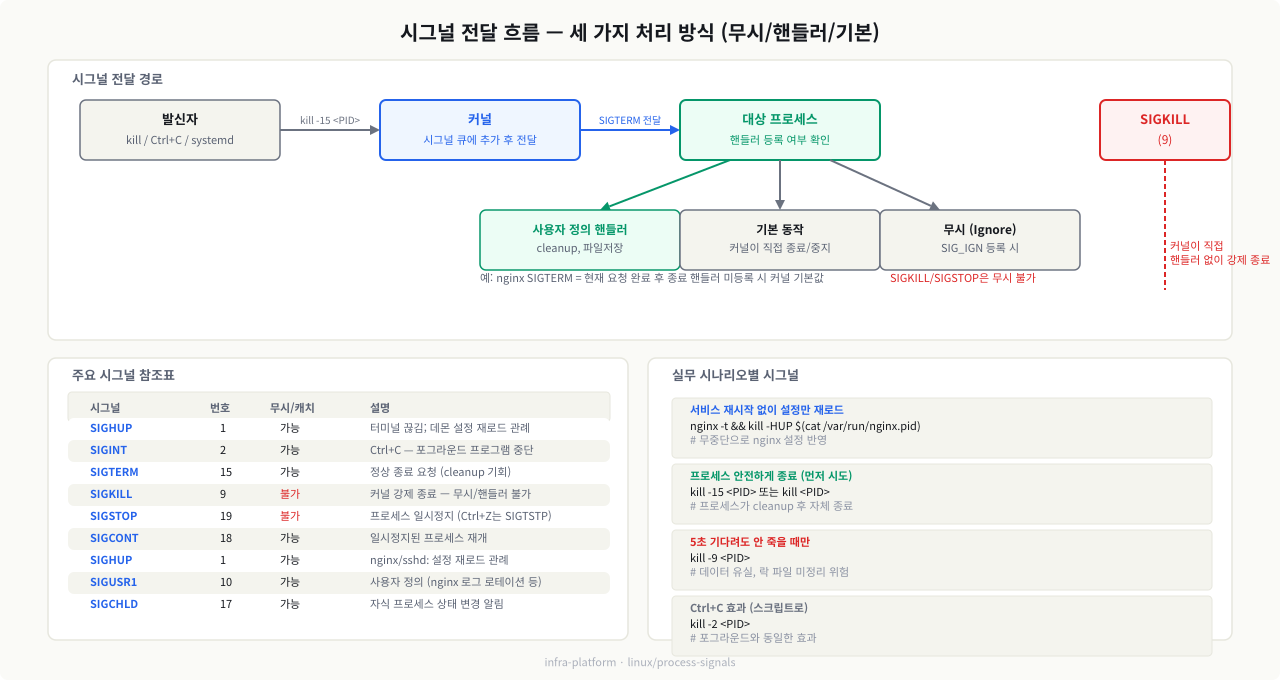
시그널의 세 가지 처리 방식
프로세스는 시그널을 받았을 때 다음 세 가지 중 하나로 반응합니다:
- 기본 동작(Default Action) 수행 — 시그널별로 커널이 정의한 기본 동작(종료, 중지, 무시 등)을 실행합니다.
- 사용자 정의 핸들러 실행 —
signal()또는sigaction()시스템 콜로 등록한 함수를 실행합니다. 데이터베이스나 웹 서버가 SIGTERM을 받았을 때 열린 트랜잭션을 완료하고 파일을 닫는 것이 이 방식입니다. - 시그널 무시 —
SIG_IGN으로 설정하면 해당 시그널이 도착해도 아무 일도 하지 않습니다.
핵심 시그널 테이블
시그널은 종류마다 번호와 이름이 있으며, 프로세스가 핸들러를 등록해 직접 처리할 수 있는 것과 커널이 강제로 처리하는 것으로 나뉩니다. 실무에서 자주 만나는 시그널을 정리하면 아래와 같습니다:
| 시그널 | 번호 | 기본 동작 | 무시/캐치 가능 | 주요 사용 상황 |
|---|---|---|---|---|
| SIGHUP | 1 | 종료 | 가능 | 터미널 연결 해제 시 발생; 데몬에서는 설정 재로드 관례로 사용 |
| SIGINT | 2 | 종료 | 가능 | Ctrl+C와 동일; 포어그라운드 프로세스 인터럽트 |
| SIGQUIT | 3 | 코어 덤프 후 종료 | 가능 | Ctrl+\; 디버깅용 코어 파일 생성 |
| SIGKILL | 9 | 즉시 강제 종료 | 불가능 | 커널이 직접 프로세스 제거; cleanup 없음 |
| SIGTERM | 15 | 종료 | 가능 | 정상 종료 요청; 프로세스에게 cleanup 기회 부여 |
| SIGSTOP | 19 | 프로세스 일시 정지 | 불가능 | Ctrl+Z 대응; 프로세스를 멈추되 제거하지 않음 |
| SIGCONT | 18 | 정지된 프로세스 재개 | 가능 | SIGSTOP/SIGTSTP으로 멈춘 프로세스를 다시 실행 |
| SIGUSR1 | 10 | 종료 | 가능 | 사용자 정의 목적; nginx 로그 로테이션 등 |
| SIGUSR2 | 12 | 종료 | 가능 | 사용자 정의 목적; 애플리케이션마다 다름 |
| SIGCHLD | 17 | 무시 | 가능 | 자식 프로세스 상태 변경 시 부모에게 발송 |
# 시스템에서 지원하는 전체 시그널 목록 확인
kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE
9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2
13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT
17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU
25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH
29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN
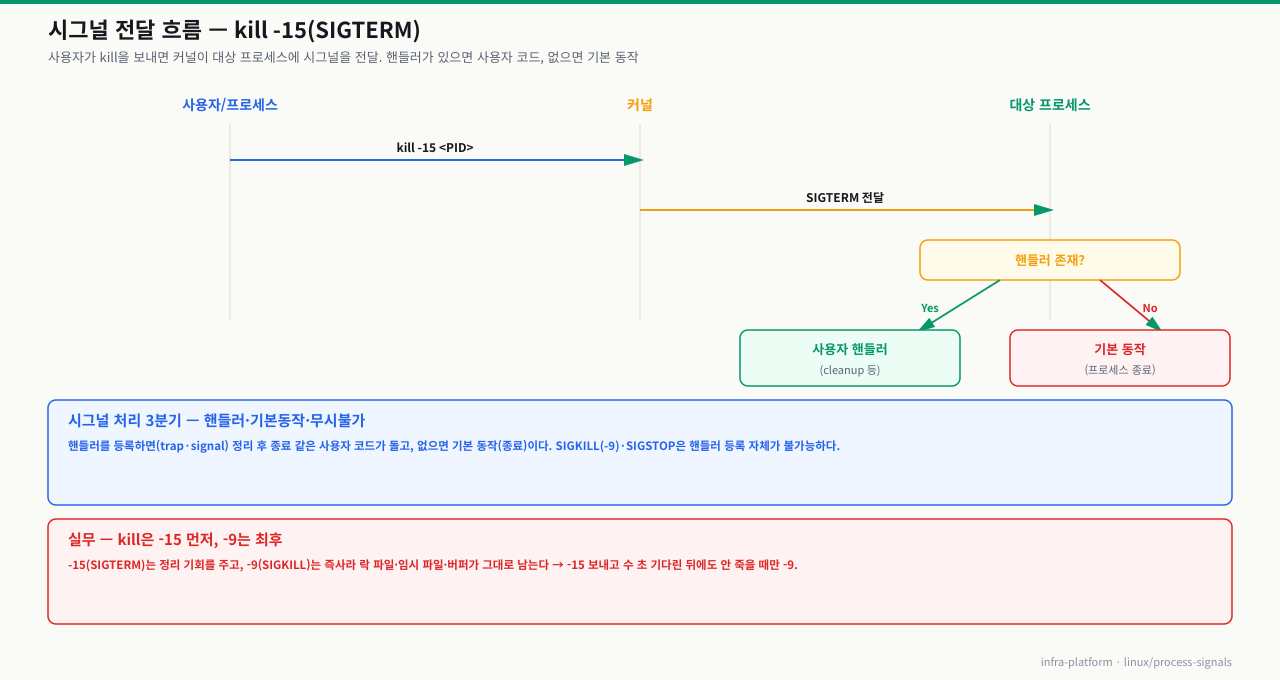
시그널 전달 흐름
 확대
확대
시그널 한 방이 프로세스에 닿기까지 — 발신부터 처리까지 5단계
kill -TERM 1234를 눌렀는데 프로세스가 바로 안 죽거나, kill -9를 보내도 D 상태 프로세스가 버티거나, 좀비가 kill로 안 사라지는 일이 있습니다. 이 셋은 전부 "시그널을 보냈다"와 "프로세스가 반응했다" 사이에 있는 등록 → 확인 → 처리 단계 때문입니다. 시그널은 즉시 실행되는 명령이 아니라, 커널이 대상에게 등록해 두고 대상이 다음에 깨어날 때 확인하는 비동기 알림입니다. 이 5단계를 알면 앞서 본 좀비·D 상태·SIGKILL 예외가 각각 어느 단계의 이야기인지 한 줄로 정리됩니다.
[보내는 쪽] kill -TERM <PID> 또는 커널(타이머·하드웨어 예외·자식 종료)
│
① 발신: kill(2) 시스템콜로 "이 PID에 이 시그널을" 커널에 요청
│
② 등록: 커널이 대상 프로세스 task_struct의 pending 집합에 시그널 비트 세트
│ → 이 순간 대상은 아직 아무것도 모름 (비동기)
│
③ 확인: 대상이 커널 → 유저공간으로 복귀할 때 pending을 검사
│ (시스템콜 반환·인터럽트 종료·스케줄되어 CPU를 받는 시점)
│
④ 처리: 어떻게 반응할지 결정
│ ├─ 핸들러 등록됨 → 유저 핸들러 실행(cleanup 등) → 원래 흐름 복귀
│ ├─ 핸들러 없음 → 기본 동작 (종료 / 코어덤프 / 무시 / 정지)
│ └─ 블록(mask)됨 → 처리 보류, pending에 남아 대기
│
⑤ 예외: SIGKILL(9)·SIGSTOP은 ④의 선택 자체가 없음
│ → 커널이 직접 종료·정지, 프로세스는 개입 불가
▼
[결과] 종료 / 코어파일 / 무시 / 정지 — 시그널 종류와 핸들러 등록 여부에 달림
각 단계에서 무슨 일이 일어나고, 어긋나면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 어긋나면 |
|---|---|---|
| ① 발신 | kill·pkill이 kill(2)로 요청. 커널도 타이머(SIGALRM)·예외(SIGSEGV)·자식 종료(SIGCHLD)로 스스로 발신 | 남의 소유 프로세스면 발신 단계에서 Operation not permitted |
| ② 등록 | 커널이 대상 task_struct의 pending 비트를 세트. 같은 표준 시그널은 여러 번 와도 1개로 합쳐짐(큐잉 안 됨) | 짧은 간격의 SIGCHLD가 하나로 뭉쳐, 부모가 몰아서 wait 안 하면 좀비 누적 |
| ③ 확인 | 유저공간으로 복귀하는 순간에만 검사 — 전달은 "즉시"가 아니라 "다음 복귀 때" | D 상태(uninterruptible)면 I/O가 끝나 복귀할 때까지 검사 지점에 못 가 kill -9도 대기 |
| ④ 처리 | 핸들러 있으면 실행, 없으면 기본 동작. 셸의 trap은 이 단계에 핸들러를 끼우는 것 | 핸들러가 블로킹·무한루프면 종료 요청을 받고도 그 안에서 멈춰 안 죽음 |
| ⑤ 예외 | SIGKILL·SIGSTOP은 ④를 건너뛰고 커널이 직접 처리 — 잡기·무시·핸들러 모두 불가 | SIGKILL 보냈는데 안 죽으면 대상이 D 상태이거나 커널 스레드([kswapd] 등) |
즉 "kill을 보냈다"와 "프로세스가 죽었다" 사이에는 등록(②) → 확인(③) → 처리(④) 세 관문이 있습니다. trap은 ④에 개입하는 것이고, 좀비는 ②에서 뭉친 SIGCHLD를 부모가 처리하지 않은 결과이며, D 상태는 ③에서 막힌 것이고, SIGKILL이 안 통하는 예외는 ⑤입니다. 그래서 종료가 뜻대로 안 될 때는 ps -o pid,stat,cmd로 대상의 상태(R/S/D/Z/T)를 먼저 보고, 어느 관문에서 멈췄는지를 좁히는 것이 순서입니다.
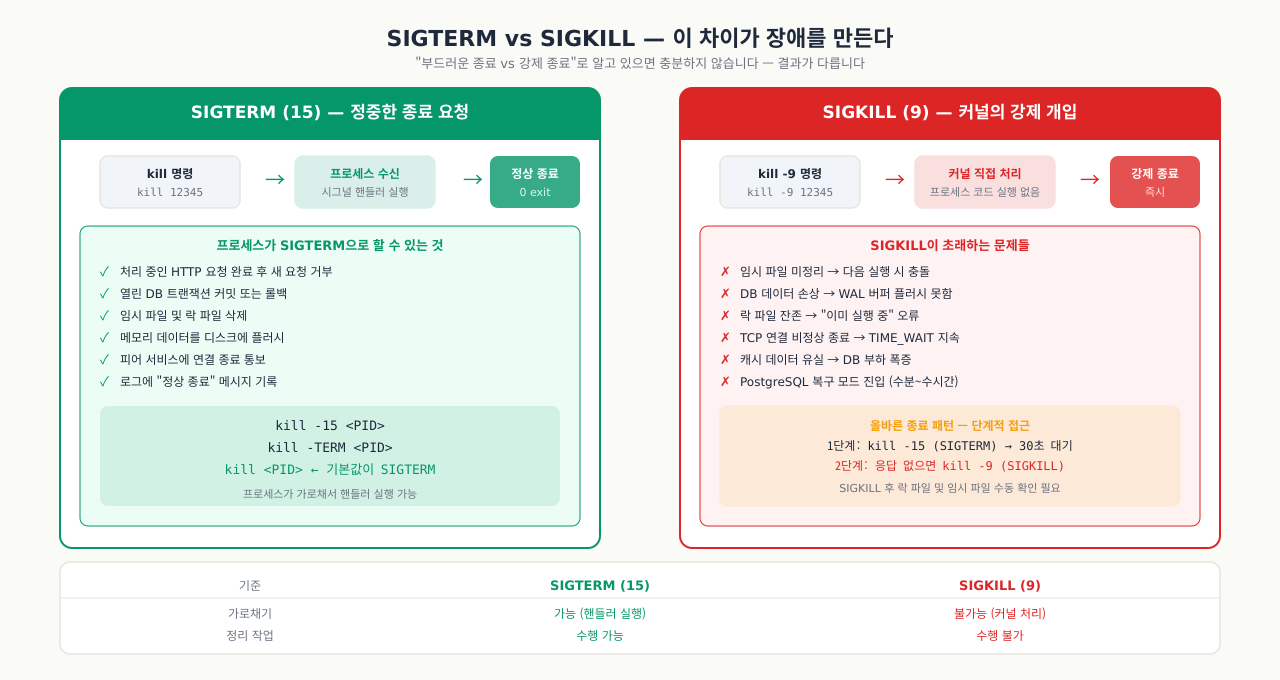
SIGTERM vs SIGKILL — 이 차이가 장애를 만든다
 확대
확대
엔지니어링 현장에서 가장 많이 오해되는 개념이 바로 SIGTERM과 SIGKILL의 차이입니다. 단순히 "부드러운 종료 vs 강제 종료"로만 알고 있으면 충분하지 않습니다. 두 시그널의 동작 방식과 그 결과물의 차이를 이해해야 합니다.
SIGTERM (15) — 정중한 종료 요청
SIGTERM은 프로세스에게 "지금 종료할 준비를 해라"고 알리는 요청입니다.
프로세스가 SIGTERM을 받으면 할 수 있는 것들:
- 처리 중인 HTTP 요청 완료 후 새 요청 거부
- 열린 데이터베이스 트랜잭션 커밋 또는 롤백
- 임시 파일 및 락 파일 삭제
- 메모리 데이터를 디스크에 플러시(flush)
- 피어 서비스에 연결 종료 통보
- 로그에 "정상 종료" 메시지 기록
# SIGTERM 전송 (번호 또는 이름 모두 사용 가능)
kill -15 <PID>
kill -TERM <PID>
kill <PID> # 기본값이 SIGTERM
SIGKILL (9) — 커널의 강제 개입
SIGKILL은 프로세스가 절대 가로챌 수 없습니다. 커널이 프로세스 테이블에서 해당 항목을 직접 제거합니다. 프로세스 코드가 실행될 기회가 전혀 없습니다.
SIGKILL이 초래하는 문제들:
| 문제 | 원인 | 실제 피해 |
|---|---|---|
| 임시 파일 미정리 | /tmp에 생성한 파일을 삭제 못함 | 디스크 낭비, 다음 실행 시 충돌 |
| DB 데이터 손상 | WAL 버퍼 또는 메모리 캐시를 플러시 못함 | PostgreSQL/MySQL 복구 모드 진입 |
| 락 파일(lock file) 잔존 | *.lock, *.pid 파일 미삭제 | 다음 실행 시 "이미 실행 중" 오류 |
| 커넥션 비정상 종료 | TCP 연결 FIN 없이 소멸 | 상대방 TIME_WAIT 상태 장기 지속 |
| 캐시 데이터 유실 | Redis, memcached 메모리 데이터 손실 | 캐시 히트율 급락, 원본 DB 부하 폭증 |
실제 장애 시나리오: PostgreSQL kill -9
DB 프로세스에 SIGKILL을 직접 보내면 WAL 버퍼를 플러시하지 못해 데이터 손상이 발생할 수 있습니다.
DB 프로세스 강제 종료 — 데이터 손상 위험
안전한 실행 조건: SIGTERM(kill -15)으로 먼저 graceful shutdown 시도 → 30초 대기 → 응답 없을 때만 SIGKILL 사용
실행 전 반드시 확인
- pg_ctlcluster 또는 systemctl stop postgresql 로 먼저 정상 종료 시도
- kill -15 $(pgrep postgres) 전송 후 watch ps aux | grep postgres 로 종료 여부 확인
- 30초 이상 응답 없을 때만 kill -9 사용 — 사용 후 /var/lib/postgresql/*/pg_hba.conf 존재 여부 확인
kill -9 $(pgrep postgres)위 항목을 모두 확인한 후 복사할 수 있습니다
# 잘못된 방법 (아래는 위험 사례 설명용, 실제 실행 금지)
kill -9 $(pgrep postgres)
# 결과: PostgreSQL 재시작 시 다음과 같은 메시지가 나타남
LOG: database system was shut down at 2026-03-26 14:23:11 KST
LOG: entering standby mode
LOG: redo starts at 0/18A0020
FATAL: database system identifier differs between pg_control and pg_resetwal
LOG: database system was not properly shut down; automatic recovery in progress
LOG: invalid record length at 0/1A000028: wanted 24, got 0
LOG: redo in progress
SIGKILL 이후 PostgreSQL은 WAL(Write-Ahead Log) 복구를 시작합니다. 짧게는 수분, 길게는 수시간이 걸리며, 최악의 경우 데이터 불일치가 발생합니다.
올바른 종료 패턴: 단계적 접근
#!/bin/bash
# 안전한 프로세스 종료 스크립트
PID=$1
WAIT_SECONDS=30
echo "[1단계] SIGTERM 전송 (PID: $PID)"
kill -15 "$PID"
echo "[대기] 최대 ${WAIT_SECONDS}초 graceful shutdown 기다리는 중..."
for i in $(seq 1 $WAIT_SECONDS); do
if ! kill -0 "$PID" 2>/dev/null; then
echo "프로세스가 정상 종료되었습니다. (${i}초 소요)"
exit 0
fi
sleep 1
done
echo "[2단계] 프로세스가 응답하지 않아 SIGKILL 전송"
kill -9 "$PID"
echo "SIGKILL 전송 완료. 락 파일 및 임시 파일을 수동으로 확인하세요."
# 실행 방법
chmod +x safe-kill.sh
./safe-kill.sh 12345
[1단계] SIGTERM 전송 (PID: 12345)
[대기] 최대 30초 graceful shutdown 기다리는 중...
프로세스가 정상 종료되었습니다. (3초 소요)
kill, killall, pkill, pgrep 실전 사용법
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/linux/part2/exam_3 && cd /tmp/linux/part2/exam_3
# 시그널 처리 테스트 스크립트 생성
cat > /tmp/linux/part2/exam_3/signal_test.sh << 'EOF'
#!/bin/bash
# 시그널 처리 테스트 스크립트
trap 'echo "SIGTERM 수신 - 정상 종료"; exit 0' SIGTERM
trap 'echo "SIGHUP 수신 - 설정 재로드"' SIGHUP
trap 'echo "SIGUSR1 수신 - 사용자 정의 시그널"' SIGUSR1
echo "PID: $$ — 시그널 대기 중..."
while true; do
sleep 1
done
EOF
chmod +x /tmp/linux/part2/exam_3/signal_test.sh
이제 실습을 진행합니다.
kill 명령의 이름이 "죽인다"는 의미지만, 실제로는 "시그널을 보낸다"는 것이 더 정확합니다. 종료 시그널이 아닌 다른 시그널(SIGHUP, SIGUSR1 등)도 전송할 수 있습니다.
# 기본 문법
kill [옵션] <PID>
# 시그널 번호로 전송
kill -9 1234
kill -15 1234
kill -1 1234
# 시그널 이름으로 전송 (더 명확하고 가독성 좋음)
kill -KILL 1234
kill -TERM 1234
kill -HUP 1234
# 여러 PID에 동시 전송
kill -15 1234 5678 9012
# 프로세스가 존재하는지 확인 (시그널 0은 실제 전송 없이 존재 여부만 확인)
kill -0 1234 && echo "프로세스 존재" || echo "프로세스 없음"
프로세스 존재
# 음수 PID: 프로세스 그룹 전체에 시그널 전송
# PID 1234의 프로세스 그룹 전체를 종료
kill -15 -1234
# 현재 셸의 프로세스 그룹에 SIGTERM
kill -15 0
PID를 알아내는 빠른 방법:
# 현재 실행 중인 특정 프로세스의 PID 확인
ps aux | grep nginx
pgrep nginx
cat /var/run/nginx.pid # 많은 데몬이 PID 파일을 남김
- kill -15 <PID> 전송 후 ps aux | grep <PID> 로 프로세스가 사라지면 SIGTERM을 받고 정상 종료된 것이다
- kill -HUP <nginx_PID> 후 nginx 에러 로그에 'reloaded' 메시지가 기록되면 설정 재로드가 성공한 것이다
- pgrep nginx 결과가 여러 줄이면 마스터 프로세스와 워커 프로세스가 각각 동작 중인 것이다
- kill -0 <PID> 의 종료 코드가 0이면 해당 PID의 프로세스가 아직 살아있다는 의미이다
- 읽기 순서: ps aux 로 STAT 컬럼 확인 → R/S/Z 상태 파악 → 필요한 시그널 선택 순으로 본다
- 안전 종료 순서: SIGTERM(15) 먼저 → 3~5초 대기 → 응답 없으면 SIGKILL(9) — 이 순서를 반드시 지킨다
- kill -9 후 프로세스가 Z(zombie) 상태로 남으면 부모 프로세스가 wait()를 호출하지 않은 것 — 부모 프로세스를 재시작해야 좀비가 제거된다
- PID 1(init/systemd)은 절대 SIGKILL 보내면 안 됨 — 커널 패닉 또는 시스템 다운으로 이어진다
- kill -9 는 DB 프로세스에 특히 위험 — WAL 버퍼를 플러시하지 못해 복구 모드로 진입하거나 데이터 불일치가 발생할 수 있다
kill은 PID가 필요하지만, killall과 pkill은 프로세스 이름으로 직접 시그널을 보낼 수 있습니다. 단, 잘못 쓰면 의도하지 않은 프로세스까지 종료될 수 있으니 주의가 필요합니다.
# killall: 정확한 프로세스 이름으로 시그널 전송
killall nginx # SIGTERM 전송
killall -9 nginx # SIGKILL 전송
killall -HUP nginx # 설정 재로드
# 대소문자 무시 (-I 옵션)
killall -I NGINX
# 특정 사용자의 프로세스만
killall -u www-data nginx
# 실행 후 종료 대기
killall -w nginx # nginx가 완전히 종료될 때까지 대기
# pkill: 패턴 매칭으로 시그널 전송 (더 유연함)
pkill python3 # "python3"를 포함하는 프로세스 이름
pkill -f "python3 app.py" # 전체 명령행에서 패턴 검색 (-f 옵션)
pkill -u deploy # deploy 사용자의 모든 프로세스
pkill -P 1234 # PID 1234의 자식 프로세스만
pkill -15 gunicorn # SIGTERM 전송
# 실전 예시: 특정 포트를 사용하는 프로세스 종료
pkill -f ":8080"
# pgrep: 종료하지 않고 PID만 조회 (kill 전 확인용)
pgrep nginx
pgrep -l nginx # PID와 이름 함께 출력
pgrep -a nginx # PID와 전체 명령행 출력
pgrep -u www-data # 특정 사용자의 모든 프로세스
pgrep -f "gunicorn master" # 전체 명령행 패턴 검색
# 여러 이름 동시 검색
pgrep -l "nginx|python|node"
1234 nginx
1235 nginx
5678 python3
9012 node
killall vs pkill 선택 기준:
| 상황 | 추천 명령 | 이유 |
|---|---|---|
| 정확한 프로세스 이름을 앎 | killall | 이름이 정확히 일치해야 함 |
| 명령행 인수로 구분해야 할 때 | pkill -f | 전체 명령행 패턴 검색 |
| 특정 사용자의 프로세스만 | pkill -u | 사용자 필터링이 직관적 |
| 부모-자식 관계로 처리할 때 | pkill -P | 자식 프로세스만 선택 |
SSH로 서버에 접속해서 작업할 때 가장 흔한 실수는 nohup 없이 긴 작업을 실행하는 것입니다. SSH 세션이 끊기면 SIGHUP이 발생하고, 프로세스도 함께 종료됩니다.
SIGHUP의 동작 원리
 확대
확대
nohup 사용법
# 기본 사용법: SIGHUP 무시하고 백그라운드 실행
nohup python3 data_processing.py &
# 출력 확인
tail -f nohup.out
nohup: ignoring input and appending output to 'nohup.out'
[1] 14523
# 출력 파일을 별도로 지정
nohup python3 data_processing.py > /var/log/myapp/process.log 2>&1 &
# PID 저장 (나중에 종료하기 위해)
nohup python3 data_processing.py > process.log 2>&1 &
echo $! > process.pid
cat process.pid
14523
# nohup.out 로그 모니터링
tail -f nohup.out
# 특정 라인부터 보기
tail -n 100 nohup.out
# 실시간 라인 수 확인
wc -l nohup.out
백그라운드 작업: &, jobs, fg, bg
# & : 백그라운드로 실행
sleep 300 &
python3 long_task.py &
# jobs: 현재 셸의 백그라운드 작업 목록
jobs
[1]- Running sleep 300 &
[2]+ Running python3 long_task.py &
# fg: 백그라운드 작업을 포어그라운드로 전환
fg %1 # 작업 번호 1을 포어그라운드로
fg %python3 # 이름으로 지정
# Ctrl+Z: 실행 중인 포어그라운드 작업을 일시 정지
# (여기서 Ctrl+Z를 누른 상황)
^Z
[2]+ Stopped python3 long_task.py
# bg: 일시 정지된 작업을 백그라운드에서 재개
bg %2
# jobs로 상태 다시 확인
jobs
[1]- Running sleep 300 &
[2]+ Running python3 long_task.py &
# wait: 모든 백그라운드 작업이 끝날 때까지 대기
wait
# 특정 PID 대기
wait 14523
nohup은 단일 명령에 적합하지만, 대화형 작업이 많거나 여러 창이 필요하다면 tmux가 훨씬 강력합니다. tmux는 SSH 연결이 끊겨도 서버에서 독립적으로 실행되는 세션을 유지합니다.
tmux 기본 워크플로우
# tmux 설치 (없을 경우)
sudo dnf install tmux # RHEL/CentOS/Rocky
sudo apt install tmux # Ubuntu/Debian
# 새 세션 시작 (이름 지정 권장)
tmux new-session -s deploy
# 기존 세션에 다시 연결
tmux attach -t deploy
tmux a -t deploy # 단축형
# 실행 중인 세션 목록
tmux list-sessions
tmux ls
deploy: 1 windows (created Thu Mar 26 09:15:00 2026) [220x50]
monitor: 2 windows (created Thu Mar 26 08:30:00 2026) [220x50]
tmux 핵심 키 바인딩
모든 tmux 명령은 Ctrl+B(prefix)를 먼저 누른 후 입력합니다.
| 키 조합 | 동작 |
|---|---|
Ctrl+B, d | 세션 분리(detach) — SSH 끊기 전에 반드시 실행 |
Ctrl+B, c | 새 창(window) 생성 |
Ctrl+B, n | 다음 창으로 이동 |
Ctrl+B, p | 이전 창으로 이동 |
Ctrl+B, % | 창을 세로로 분할(pane) |
Ctrl+B, " | 창을 가로로 분할(pane) |
Ctrl+B, 방향키 | pane 간 이동 |
Ctrl+B, z | 현재 pane 전체화면 토글 |
Ctrl+B, [ | 스크롤 모드 진입 (q로 종료) |
실전 시나리오: 배포 작업 중 SSH 재접속
# [서버 접속 후]
tmux new-session -s release-v2.5
# 배포 스크립트 실행
./deploy.sh production
# [네트워크 문제로 SSH 연결 끊김]
# ...
# [다시 SSH 접속]
ssh user@server
# 세션 복원
tmux attach -t release-v2.5
# 배포 스크립트는 중단 없이 계속 실행 중
[2026-03-26 14:35:22] Pulling latest image...
[2026-03-26 14:35:45] Running database migrations...
[2026-03-26 14:36:10] Migration complete. Starting rollout...
screen 대안 (tmux가 없을 때)
# 새 screen 세션
screen -S deploy
# 분리
# Ctrl+A, D
# 재접속
screen -r deploy
# 세션 목록
screen -ls
There is a screen on:
14523.deploy (Detached)
1 Socket in /run/screen/S-root.
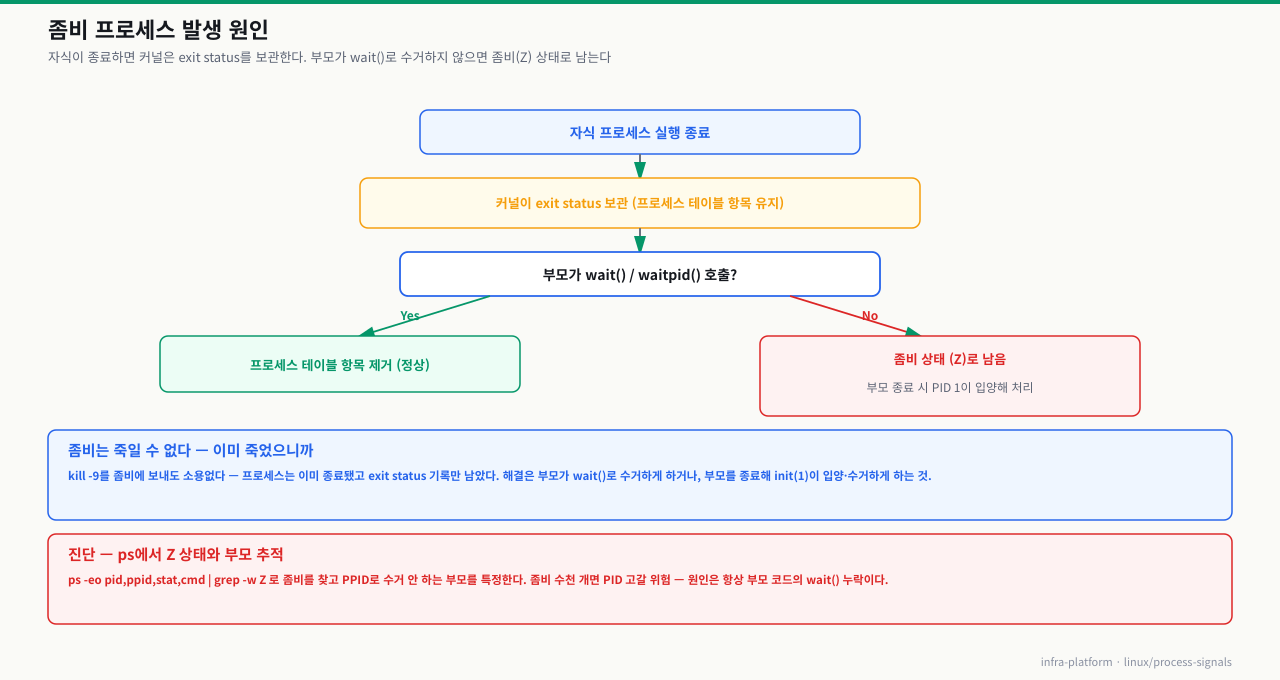
좀비(Zombie) 프로세스는 실행이 완료되었지만 프로세스 테이블에서 제거되지 않은 프로세스입니다. 수십 개의 좀비는 무해하지만, 수천 개가 쌓이면 PID 공간이 고갈되어 새 프로세스를 생성할 수 없게 됩니다.
좀비 프로세스 발생 원인
 확대
확대
핵심: 좀비는 부모 프로세스의 코딩 문제(wait() 호출 누락)에서 비롯됩니다.
좀비 프로세스 확인
# 좀비 프로세스 수 확인
ps aux | grep -c 'Z'
# 좀비 프로세스 상세 정보 (STAT 컬럼이 Z인 것)
ps aux | awk '$8 == "Z" {print}'
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
www-data 18234 0.0 0.0 0 0 ? Z 13:42 0:00 [php-fpm] <defunct>
www-data 18301 0.0 0.0 0 0 ? Z 13:44 0:00 [php-fpm] <defunct>
www-data 18456 0.0 0.0 0 0 ? Z 13:45 0:00 [php-fpm] <defunct>
# 좀비의 부모 프로세스(PPID) 찾기
ps -o pid,ppid,stat,cmd | awk '$3 == "Z" {print "좀비 PID:", $1, "부모 PID:", $2}'
좀비 PID: 18234 부모 PID: 18200
좀비 PID: 18301 부모 PID: 18200
좀비 PID: 18456 부모 PID: 18200
# 부모 프로세스 확인
ps -p 18200 -o pid,cmd
PID CMD
18200 php-fpm: master process (/etc/php-fpm.conf)
좀비 처리 방법
# 방법 1: 부모에게 SIGCHLD 전송 (부모가 wait()를 호출하도록 유도)
kill -SIGCHLD 18200
# 확인
ps aux | awk '$8 == "Z" {print}' | wc -l
0
# 방법 2: 부모 프로세스가 SIGCHLD를 처리하지 않는다면, 부모를 SIGTERM으로 종료
# 부모가 종료되면 좀비는 PID 1(systemd)에 입양되어 자동 회수됨
kill -15 18200
# 방법 3 (최후 수단): 부모가 종료되지 않으면 SIGKILL
kill -9 18200
# 시스템 전체 좀비 수 모니터링 (top에서 확인)
top
Tasks: 247 total, 1 running, 245 sleeping, 0 stopped, 3 zombie
시그널 핸들링: trap으로 스크립트 보호하기
trap은 셸 스크립트에서 시그널을 받았을 때 실행할 명령을 등록하는 내장 명령입니다. trap을 사용하면 스크립트가 Ctrl+C나 SIGTERM으로 종료될 때도 임시 파일 삭제, 잠금 해제 등의 정리 작업을 보장할 수 있습니다.
기본 trap 문법
trap '실행할 명령' 시그널명...
# 단순 예시
trap 'echo "종료 시그널 받음"' SIGTERM SIGINT
실전 스크립트: cleanup 보장
#!/bin/bash
# safe_job.sh — cleanup이 보장되는 배치 작업 스크립트
LOCKFILE="/var/run/myjob.lock"
TMPDIR="/tmp/myjob_$$" # $$ = 현재 프로세스 PID
# cleanup 함수 정의
cleanup() {
local exit_code=$?
echo "[$( date '+%Y-%m-%d %H:%M:%S' )] 정리 작업 시작..."
# 임시 디렉토리 삭제
if [ -d "$TMPDIR" ]; then
rm -rf "$TMPDIR"
echo "임시 디렉토리 삭제 완료: $TMPDIR"
fi
# 락 파일 삭제
if [ -f "$LOCKFILE" ]; then
rm -f "$LOCKFILE"
echo "락 파일 삭제 완료: $LOCKFILE"
fi
echo "정리 작업 완료. 종료 코드: $exit_code"
exit $exit_code
}
# 시그널 등록: EXIT는 스크립트가 어떤 이유로든 종료될 때 호출됨
trap cleanup EXIT
trap 'echo "SIGINT 수신 (Ctrl+C)"; exit 130' INT
trap 'echo "SIGTERM 수신"; exit 143' TERM
# 중복 실행 방지
if [ -f "$LOCKFILE" ]; then
echo "오류: 이미 다른 인스턴스가 실행 중입니다 (lockfile: $LOCKFILE)"
exit 1
fi
# 락 파일 생성
echo $$ > "$LOCKFILE"
mkdir -p "$TMPDIR"
echo "작업 시작 (PID: $$)"
echo "락 파일: $LOCKFILE"
echo "임시 디렉토리: $TMPDIR"
# 실제 작업
for i in $(seq 1 10); do
echo "처리 중: $i/10"
# 임시 파일에 작업 결과 저장
echo "step_$i" > "$TMPDIR/result_$i.tmp"
sleep 2
done
echo "작업 완료"
# trap EXIT에 의해 cleanup이 자동 실행됨
# 실행
chmod +x safe_job.sh
./safe_job.sh &
# 중간에 종료 시도
kill -15 $(pgrep safe_job)
작업 시작 (PID: 21345)
락 파일: /var/run/myjob.lock
임시 디렉토리: /tmp/myjob_21345
처리 중: 1/10
처리 중: 2/10
처리 중: 3/10
SIGTERM 수신
[2026-03-26 15:10:23] 정리 작업 시작...
임시 디렉토리 삭제 완료: /tmp/myjob_21345
락 파일 삭제 완료: /var/run/myjob.lock
정리 작업 완료. 종료 코드: 143
trap 활용 패턴 모음
# 패턴 1: 에러 발생 시 자동 종료 + 정리 (ERR 트랩)
set -e # 에러 발생 시 즉시 종료
trap 'echo "에러 발생 (라인 $LINENO)"; cleanup' ERR
# 패턴 2: 시그널 일시 무시 (중요한 작업 중 인터럽트 방지)
trap '' INT TERM # 시그널 무시
critical_operation
trap - INT TERM # 기본 동작 복원
# 패턴 3: 디버그 트랩 (각 명령 실행 전 출력)
trap 'echo "실행: $BASH_COMMAND"' DEBUG
# 패턴 4: 현재 등록된 trap 확인
trap -p
trap -- 'cleanup' EXIT
trap -- 'echo "SIGINT 수신 (Ctrl+C)"; exit 130' INT
trap -- 'echo "SIGTERM 수신"; exit 143' TERM
문제 해결 사례
상황: nginx를 kill -9로 강제 종료한 뒤 sudo systemctl start nginx를 실행했더니 포트가 이미 점유 중이라는 에러와 함께 시작에 실패합니다.
원인: kill -9(SIGKILL)는 nginx master 프로세스만 즉시 제거하고, cleanup 코드를 실행할 기회를 주지 않습니다. 그 결과 worker 프로세스들이 좀비(defunct) 상태로 남아 80 포트 소켓을 점유하고 있습니다.
진단: 소켓 점유 프로세스와 좀비 상태를 확인합니다.
# 80 포트를 점유 중인 프로세스 확인
ss -tlnp | grep :80
# LISTEN ... users:(("nginx",pid=19823,...))
# 해당 PID의 프로세스 상태 확인
ps -p 19823 -o pid,stat,cmd
# 19823 Zs [nginx] <defunct> ← Z = 좀비
해결:
# 남아있는 nginx 관련 프로세스 전체 정리
pkill -9 -f nginx
sleep 1
# 포트 점유 해제 확인
ss -tlnp | grep :80 # 아무것도 없어야 함
# pid 파일 잔존 시 삭제
sudo rm -f /var/run/nginx.pid
# nginx 재시작
sudo systemctl start nginx
# 예방: nginx는 항상 systemctl 또는 graceful 신호로 종료
sudo nginx -s quit # graceful shutdown (요청 완료 후 종료)
sudo kill -HUP $(cat /var/run/nginx.pid) # 설정 재로드
상황: nohup python3 crawler.py &로 실행하고 터미널을 닫았습니다. 다시 접속해서 확인하니 프로세스가 종료되어 있습니다.
원인: nohup만으로는 불충분한 경우가 있습니다. & 없이 포그라운드로 실행했거나, jobs 목록에 여전히 남아 있으면 셸이 SSH 끊김 시 SIGHUP을 전파합니다. disown을 통해 셸의 job 목록에서 명시적으로 분리해야 완전합니다.
진단: 실행 직후 jobs 목록과 프로세스 소유자를 확인합니다.
nohup python3 crawler.py &
# jobs 목록 확인 — 목록에 남아있으면 세션과 연결된 것
jobs
# [1]+ Running nohup python3 crawler.py & ← 아직 세션과 연결됨
# disown 없이 exit하면 SIGHUP이 전달됨
해결:
# 방법 1 (확실): nohup + & + disown 조합
nohup python3 crawler.py > crawler.log 2>&1 &
disown $!
# 분리 확인 — jobs 출력이 없어야 함
jobs
# 방법 2 (권장): tmux 안에서 실행
tmux new-session -d -s crawler 'python3 crawler.py > crawler.log 2>&1'
tmux attach -t crawler # 나중에 확인
# 로그 실시간 확인
tail -f crawler.log
상황: kill -15 8765를 실행했더니 Operation not permitted 에러가 납니다. 분명히 실행 중인 프로세스인데 종료가 안 됩니다.
원인: 일반 사용자는 자신이 소유한 프로세스에만 시그널을 전송할 수 있습니다. 다른 사용자(postgres, www-data, root 등) 소유 프로세스에는 root 권한이 필요합니다.
진단: 프로세스 소유자가 누구인지 확인합니다.
# 프로세스 소유자 확인
ps -p 8765 -o pid,user,cmd
# 8765 postgres /usr/lib/postgresql/15/bin/postgres
# 현재 사용자 확인
whoami
# developer ← postgres 소유 프로세스에 시그널 불가
해결:
# 방법 1: sudo로 root 권한 사용
sudo kill -15 8765
# 방법 2 (권장): 서비스 전용 관리 명령 사용
sudo systemctl stop postgresql
# 방법 3: 서비스 계정으로 전환해서 종료
sudo -u postgres pg_ctl stop -D /var/lib/postgresql/15/main -m fast
# fast: 진행 중 트랜잭션 롤백 후 종료
# smart: 모든 클라이언트 연결이 끊길 때까지 대기
# kill 전에 소유자 확인 습관 만들기
ps -p <PID> -o pid,user,cmd
심화 — SIGKILL로도 못 죽이는 것들
심화: SIGTERM/SIGKILL의 한계 — D 상태·커널 스레드, 그리고 PID 1의 특별 규칙
'SIGTERM은 정중히, SIGKILL은 강제로'가 이 모듈의 뼈대였습니다. 그런데 SIGKILL이 '무조건 즉시'가 아닌 예외가 몇 가지 있습니다. 이 예외를 모르면 kill -9를 보내고도 프로세스가 안 죽어 당황하고, 특히 컨테이너에서는 종료가 매번 느려지는 이유를 놓칩니다.
- D 상태(uninterruptible sleep)는 SIGKILL도 미룹니다: 프로세스가 커널에서 디스크·NFS I/O를 기다리는 D 상태면, 시그널 처리 자체가 그 I/O가 끝나고 유저 공간으로 돌아온 뒤에야 일어납니다. 그래서
kill -9를 보내도 I/O가 완료(또는 실패)될 때까지 프로세스는 안 죽습니다 — 시그널이 무시된 게 아니라 '전달이 대기 중'인 것입니다. - 커널 스레드는 시그널을 받지 않습니다:
ps에서 대괄호로 보이는[kswapd0]·[nfsd]같은 커널 스레드는 유저 프로세스가 아니라 시그널 대상이 아닙니다. 여기에kill -9는 아무 효과가 없습니다. - PID 1은 커널이 보호합니다: 커널은 PID 1(init·systemd, 또는 컨테이너의 엔트리포인트)에게는 핸들러를 직접 등록하지 않은 시그널의 기본 동작을 적용하지 않습니다. 즉 SIGTERM 핸들러가 없는 PID 1에게 SIGTERM을 보내면 그냥 무시됩니다. 이는 실수로 init을 죽여 시스템이 죽는 것을 막기 위한 설계입니다.
- 그래서 컨테이너 종료가 느려집니다: 앱이 컨테이너의 PID 1로 뜨고 SIGTERM 핸들러가 없으면,
docker stop이 보내는 SIGTERM은 무시됩니다. 도커는 유예 시간(기본 10초)을 기다린 뒤 SIGKILL로 강제 종료하므로, 매 종료가 10초씩 걸리고 graceful shutdown(연결 정리·flush)도 건너뜁니다.
핵심은 시그널이 '보내면 곧바로 적용되는 명령'이 아니라 대상 프로세스의 상태와 지위에 따라 대기·무시될 수 있는 요청이라는 것입니다. 종료가 뜻대로 안 되면 대상이 D 상태인지, 커널 스레드인지, PID 1인지를 먼저 확인해야 합니다.
상황: 배포 때마다 docker stop(또는 쿠버네티스 파드 종료)이 눈에 띄게 느립니다. 정확히 10초쯤 걸린 뒤에야 컨테이너가 내려가고, 앱이 남기던 '연결 정리 완료' 같은 종료 로그가 안 보입니다. 곧바로 다시 뜨긴 하지만 종료가 지저분합니다.
원인: 애플리케이션이 컨테이너의 PID 1로 직접 실행되고 있고, SIGTERM 핸들러를 등록하지 않았습니다. 커널은 PID 1에 대해 '핸들러 없는 시그널의 기본 동작'을 적용하지 않으므로, docker stop이 보낸 SIGTERM이 그냥 무시됐습니다. 도커는 유예 시간(기본 10초)을 기다렸다가 결국 SIGKILL로 강제 종료했고, 강제 종료라 앱의 정리 코드(graceful shutdown)는 실행되지 못했습니다.
진단: 앱이 PID 1인지, 시그널이 먹히는지 확인합니다.
# 컨테이너 안에서 앱이 PID 1인지
docker exec <컨테이너> ps -eo pid,comm
# PID COMMAND
# 1 java ← 앱이 PID 1 (init 없음)
# SIGTERM을 직접 보내 반응하는지 (무시되면 핸들러 없음)
docker exec <컨테이너> kill -TERM 1 ; sleep 2
docker ps # 여전히 살아 있으면 PID 1이 SIGTERM 무시 중
# 종료 소요 시간 체감
time docker stop <컨테이너> # 10초 근처면 유예 후 SIGKILL 경로
앱이 PID 1이고 kill -TERM 1에 반응이 없으면 확정입니다.
해결: 두 가지 방법이 있습니다. (1) 컨테이너에 가벼운 init을 PID 1로 두어 시그널을 자식 앱에 전달하게 합니다(docker run --init, 또는 tini·dumb-init 사용). 그러면 앱은 PID 1의 특별 규칙에서 벗어나 SIGTERM을 정상 수신합니다. (2) 앱이 직접 PID 1이어야 한다면 코드에 SIGTERM 핸들러를 등록해 graceful shutdown을 구현하고, Dockerfile에서 셸 형식(CMD java ...) 대신 exec 형식(CMD ["java", ...])을 써서 시그널이 셸에 먹히지 않고 앱까지 도달하게 합니다. 어느 쪽이든 유예 시간 대기가 사라지고 종료가 즉시·깨끗해집니다(프로세스 관리와 작업 제어에서 컨테이너 PID 네임스페이스의 PID 매핑도 함께 다룹니다).
실무 적용
SRE(Site Reliability Engineer) 또는 백엔드 엔지니어로 일하다 보면 프로덕션 서버에서 응답하지 않는 서비스를 마주하는 상황이 반드시 옵니다. 이 시나리오는 실제 장애 대응 절차를 보여줍니다.
시나리오: 주문 서비스(Java/Spring Boot)가 응답 없음
상황: 모니터링 알림이 울립니다. order-service가 헬스체크에 실패하고 있습니다.
1단계: 현황 파악 (절대 섣불리 kill하지 않는다)
# 프로세스 상태 확인
ps aux | grep order-service
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
app 23456 99.8 8.2 4200000 670000 ? R 09:00 45:12 java -jar order-service.jar
# CPU 99%이면 무한 루프 또는 GC 문제 의심
# 스레드 덤프로 원인 파악 (SIGQUIT = jstack과 동일)
kill -3 23456 # SIGQUIT → stdout에 스레드 덤프 출력
# 또는 jstack 사용
jstack 23456 > /tmp/thread_dump_$(date +%Y%m%d_%H%M%S).txt
# 스레드 덤프 분석
grep -A 20 "BLOCKED" /tmp/thread_dump_*.txt
"http-nio-8080-exec-10" #85 daemon prio=5 os_prio=0 tid=0x... nid=0x... BLOCKED
at java.lang.Object.wait(Native Method)
- waiting on <0x000000076b8a4e40> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at com.example.order.service.OrderService.processOrder(OrderService.java:142)
2단계: 로그 확인으로 원인 추적
# 최근 에러 로그 확인
tail -200 /var/log/order-service/app.log | grep -E "ERROR|WARN|Exception"
2026-03-26 14:58:33 ERROR c.e.o.s.OrderService - Database connection timeout after 30000ms
2026-03-26 14:58:33 ERROR c.e.o.s.OrderService - Failed to acquire lock on orders table
2026-03-26 14:58:34 ERROR c.e.o.r.OrderRepository - HikariPool-1 - Connection is not available, request timed out after 30000ms
# DB 연결 문제임을 확인
# DB 상태 먼저 확인
sudo systemctl status postgresql
3단계: 안전한 종료 시도
원인이 DB 문제라면 서비스를 재시작해도 DB가 복구되지 않으면 소용없습니다. 그러나 DB가 정상이라면 서비스 재시작이 필요합니다.
# systemctl을 통한 정상 종료 (권장 — Spring Boot의 graceful shutdown 활용)
sudo systemctl stop order-service
# systemctl이 없거나 응답이 없으면 직접 SIGTERM
kill -15 23456
# 30초 대기
sleep 30
kill -0 23456 && echo "아직 실행 중" || echo "종료 완료"
종료 완료
4단계: 재시작 및 확인
sudo systemctl start order-service
# 기동 로그 실시간 확인
journalctl -u order-service -f --since "now"
Mar 26 15:15:00 prod-server order-service[24000]: Started OrderServiceApplication in 8.234 seconds
Mar 26 15:15:05 prod-server order-service[24000]: Hikari pool initialized: 10 connections
Mar 26 15:15:06 prod-server order-service[24000]: Health check passed
# 헬스체크 직접 확인
curl -s http://localhost:8080/actuator/health | python3 -m json.tool
{
"status": "UP",
"components": {
"db": {"status": "UP"},
"diskSpace": {"status": "UP"},
"ping": {"status": "UP"}
}
}
대응 원칙 요약
1. 먼저 파악 → 스레드 덤프, 로그 확인
2. 근본 원인 해결 → DB, 네트워크, 외부 의존성
3. 안전한 종료 → systemctl stop 또는 kill -15
4. 기다림 → 30초 이상 graceful shutdown 대기
5. 최후 수단 → kill -9 (반드시 후속 조치 동반)
6. 재시작 후 검증 → 헬스체크, 로그 모니터링
사후 처리 체크리스트 (kill -9 사용 후)
# 1. 락 파일 확인
find /var/run /tmp -name "*.lock" -o -name "*.pid" 2>/dev/null
# 2. 임시 파일 정리
find /tmp -name "*order*" -mmin -60
# 3. DB 상태 확인
sudo -u postgres psql -c "SELECT pid, state, query FROM pg_stat_activity WHERE state != 'idle';"
# 4. 오픈 파일 핸들 누수 확인 (재시작 후)
lsof -p $(pgrep order-service) | wc -l
# 5. 포트 재사용 가능한지 확인
ss -tlnp | grep 8080
핵심 명령어 빠른 참조
시그널 전송 명령어 요약
# PID로 시그널 전송
kill -TERM <PID> # Graceful 종료 (기본값)
kill -KILL <PID> # 강제 종료
kill -HUP <PID> # 설정 재로드 (데몬)
kill -STOP <PID> # 일시 정지
kill -CONT <PID> # 재개
kill -0 <PID> # 존재 여부 확인
# 이름으로 시그널 전송
killall -15 nginx
pkill -f "python3 app.py"
# PID 조회
pgrep -a nginx
pgrep -u www-data -l
# 백그라운드 실행
nohup command > out.log 2>&1 &
disown $!
# 작업 제어
jobs # 현재 셸의 작업 목록
fg %1 # 작업 1을 포어그라운드로
bg %2 # 작업 2를 백그라운드로 재개
# tmux 세션
tmux new -s 이름
tmux attach -t 이름
tmux ls
# 좀비 확인
ps aux | awk '$8 == "Z"'
ps -o pid,ppid,stat,cmd | awk '$3 == "Z"'
# trap
trap 'cleanup_func' EXIT INT TERM
trap '' INT # 시그널 무시
trap - INT # 기본 동작 복원
kill -9를 쓰기 전 자문해볼 사항
□ SIGTERM을 먼저 보내고 충분히 기다렸는가? (최소 30초)
□ 프로세스가 왜 응답하지 않는지 원인을 파악했는가?
□ DB 트랜잭션이 진행 중은 아닌가?
□ 락 파일이 생성되어 있다면, kill -9 후 수동 삭제할 준비가 됐는가?
□ 이 프로세스가 관리하는 공유 메모리/소켓이 있는가?
□ systemctl stop 또는 서비스별 관리 명령을 먼저 시도했는가?
systemd stop/restart가 보내는 시그널 — KillSignal·TimeoutStopSec
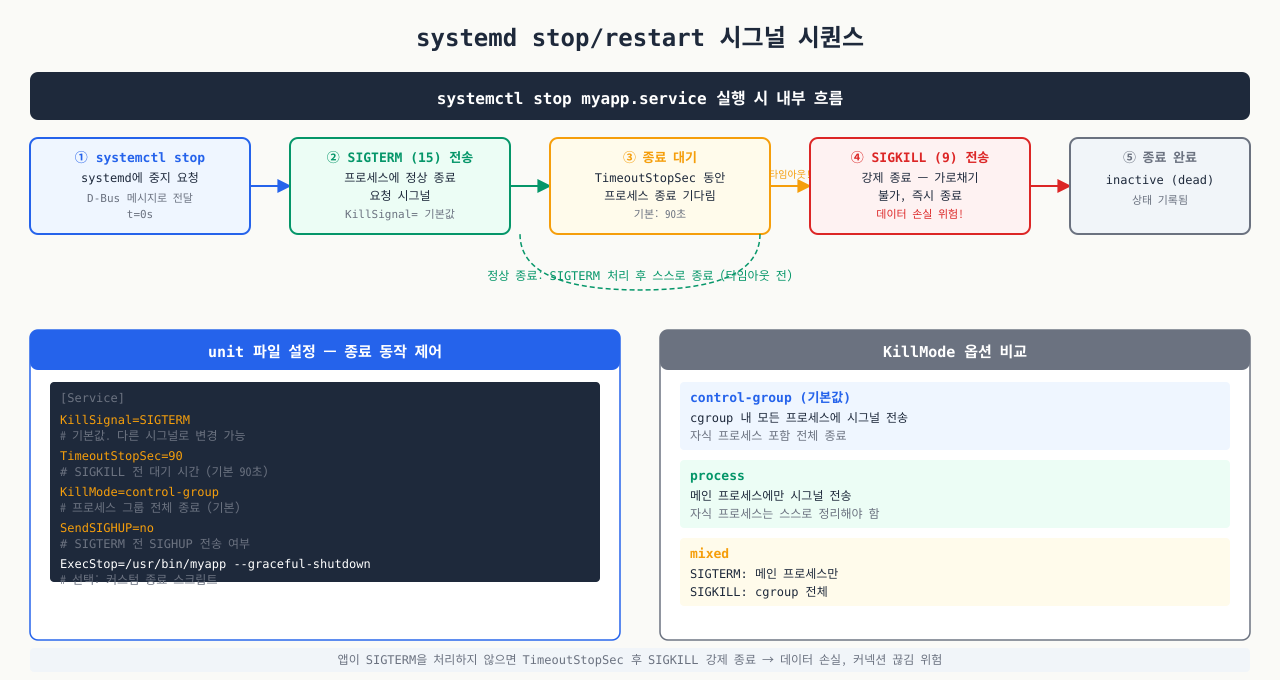 확대
확대
systemctl stop을 실행하면 systemd는 내부적으로 시그널을 전송합니다. 이 과정을 이해하면 "서비스가 종료되는 데 왜 이렇게 오래 걸리지?" 또는 "왜 데이터가 손상됐지?" 같은 장애를 예방할 수 있습니다.
systemd 종료 시퀀스:
systemctl stop myapp
↓
1. KillSignal (기본값: SIGTERM) → 프로세스에 정상 종료 요청
↓
2. TimeoutStopSec (기본값: 90초) 동안 대기
↓
3. SIGKILL (강제 종료) — 90초 내 종료 안 되면 강제 kill
서비스 파일에서 종료 동작 커스터마이징:
[Service]
KillSignal=SIGQUIT # nginx는 SIGQUIT으로 우아한 종료 (연결 완료 후 종료)
TimeoutStopSec=30 # 30초 이내 종료 강제
KillMode=mixed # 메인 프로세스에 KillSignal, 나머지는 SIGKILL
# KillMode 옵션:
# control-group (기본): cgroup 내 모든 프로세스에 시그널
# mixed: 메인에 KillSignal, 나머지에 SIGKILL
# process: 메인 프로세스에만 시그널
TimeoutStopSec 장애 사례:
# 서비스 종료가 너무 오래 걸리는 경우
systemctl stop myapp
# Timeout! Killing processes that didn't stop after 90 seconds
# 진단: 어떤 프로세스가 종료를 막는지
systemctl status myapp
# 종료 중인 PID와 남은 자식 프로세스 확인
# 임시 해결: TimeoutStopSec 늘리기
systemctl edit myapp
# [Service]
# TimeoutStopSec=300
SIGUSR1/2 실무 활용 — nginx·rsyslog 외 서비스 예시
 확대
확대
logrotate로 nginx 로그를 교체한 뒤 nginx를 재시작하지 않으면 nginx는 계속 이전 파일 디스크립터를 물고 있습니다. 재시작하면 커넥션이 끊기는데, 그래서 kill -USR1 $(cat /var/run/nginx.pid)로 로그 파일만 재오픈시킵니다. rsyslog의 설정을 바꾼 뒤에도 재시작 대신 SIGUSR1으로 리로드할 수 있습니다. SIGUSR1/2는 이처럼 각 서비스가 "재시작 없이 특정 작업을 수행하라"는 용도로 자유롭게 의미를 정의할 수 있는 시그널입니다. 어떤 서비스가 어떤 시그널을 어떻게 처리하는지 알아두면 운영 시 재시작 없이 할 수 있는 작업이 넓어집니다.
SIGUSR1과 SIGUSR2는 각 애플리케이션이 자유롭게 정의할 수 있는 사용자 정의 시그널입니다.
주요 서비스별 SIGUSR1/SIGUSR2 의미:
| 서비스 | SIGUSR1 | SIGUSR2 |
|---|---|---|
| nginx | 로그 파일 재오픈 (로테이션 후) | 업그레이드 (새 마스터 프로세스 시작) |
| rsyslog | 설정 리로드 | 통계 출력 |
| haproxy | 통계 초기화 | — |
| PostgreSQL | 설정 리로드 (pg_ctl reload) | — |
# nginx 로그 로테이션 (SIGUSR1)
sudo kill -USR1 $(cat /var/run/nginx.pid)
# 또는
sudo nginx -s reopen
# 적용 확인
ls -la /var/log/nginx/
# access.log ← 새 파일 (방금 생성됨)
# access.log.1 ← 로테이션된 파일
# rsyslog 설정 리로드 (SIGUSR1)
sudo kill -HUP $(cat /var/run/rsyslogd.pid)
# 또는
sudo systemctl reload rsyslog
커스텀 앱에서 SIGUSR1 핸들러 구현 (Python 예제):
import signal
import logging
def handle_usr1(signum, frame):
"""SIGUSR1: 로그 레벨을 DEBUG로 임시 전환"""
logging.getLogger().setLevel(logging.DEBUG)
logging.info("SIGUSR1 수신: 디버그 모드 활성화")
signal.signal(signal.SIGUSR1, handle_usr1)
좀비·고아 프로세스 — 발생 원인과 부모 프로세스 관점 해결
 확대
확대
ps aux를 실행했을 때 STAT 컬럼에 Z가 달린 프로세스를 발견하면 좀비입니다. 좀비 자체는 CPU나 메모리를 쓰지 않지만, 수십 개가 쌓이면 PID 테이블이 고갈돼 새 프로세스를 생성할 수 없게 됩니다. 멀티스레드 서버나 웹 서버의 워커 프로세스에서 이 문제가 흔히 나타납니다. kill -9로 좀비를 없애려 해도 이미 종료된 상태라 아무 반응이 없고, 해결하려면 부모 프로세스가 wait()을 호출하도록 만들어야 합니다. 발생 원리를 이해해야 원인이 되는 부모 프로세스를 찾아서 조치할 수 있습니다.
좀비 프로세스 (Zombie):
자식이 종료됐지만 부모가 wait() 시스템 콜로 종료 상태를 수거하지 않은 상태. PID는 남아 있지만 실제 메모리는 없습니다.
# 좀비 프로세스 확인
ps aux | grep -w Z
# USER PID ... STAT ... COMMAND
# www 1234 ... Z ... [nginx] <defunct>
# 좀비 수 확인
ps aux | awk '{print $8}' | grep -c "^Z"
# 부모 PID 찾기 (PPID가 원인)
ps -o ppid= -p 1234 # 좀비의 부모 PID 확인
ps aux | grep <PPID> # 부모 프로세스 확인
좀비 해결:
# 방법 1: 부모에게 SIGCHLD 전송 → wait() 호출 유도
kill -CHLD <부모PID>
# 방법 2: 부모 프로세스 재시작 (안전한 방법)
sudo systemctl restart <서비스명>
# 방법 3: 부모 프로세스 종료 → 좀비는 init(PID 1)에 입양 후 즉시 수거
kill <부모PID>
# 주의: 좀비 자체는 kill로 제거 불가 (이미 실행 중이 아님)
kill -9 <좀비PID> # 효과 없음
고아 프로세스 (Orphan):
부모가 먼저 종료되면 자식은 init(PID 1)에 입양됩니다. 대부분 문제없지만 의도치 않은 백그라운드 프로세스가 남을 수 있습니다.
# 부모 없는 프로세스 찾기 (PPID=1 인 경우)
ps -eo pid,ppid,cmd | awk '$2==1 && $1!=1'
# systemd로 관리하지 않는 고아 프로세스가 많을 경우
# → 서비스를 systemd unit으로 전환하면 자동 관리됨
관련 모듈로 더 깊이:
- 프로세스 관리와 작업 제어 — 시그널을 보내기 전에 어떤 프로세스가 문제인지 찾는 법
- 리눅스 부팅 시 데몬 프로세스 자동 실행 및 관리 가이드 — SIGTERM 타임아웃·재시작 정책을 unit 파일로 관리하는 법
다음 모듈에서는 systemd 서비스 관리를 다룹니다 — unit 파일 작성, systemctl start/stop/enable, 서비스 재시작 정책, 그리고 journalctl로 서비스 로그를 확인하는 방법을 배웁니다.