자정에 API 서버가 조용히 죽었습니다. 모니터링 알림은 새벽 1시에 왔고, 그때는 이미 서버가 재시작된 뒤였습니다. /var/log/app.log를 열었더니 재시작 이후 로그만 있었습니다. journald는 기본 설정 그대로라 재부팅과 함께 메모리 로그가 날아간 상태였습니다. 장애가 왜 시작됐는지, 어느 프로세스가 먼저 죽었는지, OOM이 개입했는지 — 아무것도 알 수 없었습니다. journald를 제대로 구성해두었다면 재부팅 직전까지의 전체 타임라인이 한 곳에 모여 있었을 겁니다.
journald 심화 — 로그로 모든 것을 추적하는 법
자정에 API 서버가 조용히 죽었습니다. 모니터링 알림은 새벽 1시에 왔고, 그때는 이미 서버가 재시작된 뒤였습니다. /var/log/app.log를 열었더니 재시작 이후 로그만 있었고, nginx 에러 로그에는 upstream 연결 실패 기록만 잔뜩이었습니다. 각 서비스가 제각각 다른 파일에 로그를 남기는 구조였고, journald는 기본 설정 그대로라 재부팅과 함께 메모리 로그가 날아간 상태였습니다. 장애가 왜 시작됐는지, 어느 프로세스가 먼저 죽었는지, 커널 OOM이 개입했는지 — 아무것도 알 수 없었습니다. journald를 제대로 구성하고 journalctl을 능숙하게 다룰 수 있었다면, 재부팅 직전까지의 전체 타임라인이 한 곳에 모여 있었을 겁니다. 이 모듈은 그 도구를 실무에서 쓰는 방식 그대로 다룹니다.
학습 목표
이 모듈을 마치면 다음을 할 수 있습니다:
journalctl의 핵심 필터 옵션을 조합해 원하는 로그만 정확히 추출한다- 구조화 필드(
_EXE=,_PID=,_UID=)로 유닛 이름 없이도 로그를 추적한다 -k옵션으로 커널 메시지를 분리해 하드웨어·OOM 장애를 진단한다- 로그가 "없는" 세 가지 원인을 구분하고 각각 해결한다
- 포스트모텀용 로그를 시간 범위 지정, JSON 포맷으로 추출한다
- journald.conf 영구 저장 설정을 적용하고 용량 정책을 구성한다
- 1journalctl 핵심 필터(-u, -f, --since/--until, -p, -o json)를 활용할 수 있다
- 2_EXE=, _PID=, _UID=, _SYSTEMD_UNIT= 구조화 필드로 쿼리할 수 있다
- 3-k로 커널 메시지를 분리해 dmesg를 대체하고 OOM Killer를 추적할 수 있다
- 4로그가 없는 세 가지 경우를 진단하고 각각 해결할 수 있다
- 5journald 영구 저장 설정과 용량 관리 정책을 구성할 수 있다
- 6시간 범위와 JSON 포맷을 조합해 포스트모텀용 로그를 추출할 수 있다
systemctl status systemd-journald && ls /var/log/journal/ 2>/dev/null || echo '영구 저장 미설정'journalctl --disk-usagejournalctl --list-bootscat /etc/systemd/journald.conf | grep -v '^#' | grep -v '^$'journald.conf 수정과 /var/log/journal/ 디렉터리 생성은 root 권한이 필요합니다. 프로덕션에서는 설정 변경 전 반드시 백업하세요.
1. journalctl 핵심 필터 — 찾는 로그만 꺼내는 법
log-rotation 모듈과 이 모듈의 차이
journald 로그 영구 저장 강제 전환
디폴트 상태의 journald는 /run/log/journal/ 메모리 풀에 로그를 박아 두므로 재부팅 시 수사 기록이 완전 증발합니다. 이를 디스크 풀 영역에 영구 보존하려면 다음과 같은 파일시스템 및 권한 교정을 수행해야 합니다.
# 1. 영구 로그 보존용 물리 디렉토리 생성
$ sudo mkdir -p /var/log/journal
# 2. systemd 임시 파일 설정 도구를 활용해 소유권 및 권한 정합성을 자동 교정
$ sudo systemd-tmpfiles --create --prefix /var/log/journal
# 3. journald 데몬 재기동하여 설정을 즉시 실무 락인
$ sudo systemctl restart systemd-journald
이 과정을 거치면 재부팅 이후에도 journald에 기록된 골든 트러블슈팅 로그가 안전하게 디스크에 남아 있게 됩니다.
 확대
확대
이전 모듈(log-rotation)에서는 로그를 얼마나 보관하고 언제 삭제할 것인가 — 보존 정책을 다뤘습니다. 이 모듈은 이미 있는 로그에서 정확히 원하는 것을 어떻게 꺼내는가 — 탐색과 추적에 집중합니다.
journalctl은 단순한 로그 뷰어가 아닙니다. journald는 각 로그 항목을 저장할 때 유닛 이름, PID, UID, GID, 실행 파일 경로, 커널/사용자 구분, 우선순위(severity) 등을 구조화 필드로 함께 기록합니다. 이 필드들을 직접 쿼리할 수 있다는 점이 /var/log/*.log를 grep으로 뒤지는 것과 근본적으로 다릅니다.
각 journald 항목은 다음과 같은 구조화 필드(key=value)로 저장됩니다.
MESSAGE=Connection reset by peer
_SYSTEMD_UNIT=nginx.service
_PID=12345
_EXE=/usr/sbin/nginx
_UID=33 (www-data)
PRIORITY=3 (err)
__REALTIME_TIMESTAMP=1705312800000000
_HOSTNAME=web-prod-01
이 필드들을 이용해 유닛 이름, PID, 실행 경로, 심각도 등 다양한 기준으로 필터링할 수 있습니다.
로그 한 줄이 journald에 쌓였다가 조회되기까지 — 수집·저장·조회 4단계
journalctl -u myapp을 쳤는데 아무것도 안 나오는 상황은, 대개 "조회가 안 되는" 문제가 아니라 그 앞 어딘가에서 로그가 저널에 안 들어갔거나 이미 사라진 것입니다. journald는 로그 한 줄을 수집 → 메타데이터 부착 → 저장 → 조회의 파이프라인으로 다루고, -u로 안 보이는 로그·재부팅 후 증발·rate-limit 드롭은 각각 이 파이프라인의 다른 지점에서 벌어집니다. 4단계를 알면 "로그가 없다"를 조회 문제와 저장 문제로 갈라 진단할 수 있습니다.
[서비스] 앱이 stdout/stderr 또는 syslog(3)로 로그 한 줄 출력
│
① 수집: systemd가 서비스 출력을 journald로 연결 (syslog도 journald가 수신)
│
② 메타데이터: 수신하며 필드 자동 부착
│ _PID · _UID · _SYSTEMD_UNIT · _EXE · PRIORITY
│ + 벽시계(__REALTIME) · 단조시계(__MONOTONIC) 두 타임스탬프
│
③ 저장: 바이너리 저널에 기록
│ ├─ /var/log/journal/ 있음 → 디스크(영속, 재부팅 후에도 남음)
│ └─ 없음 → /run/log/journal/(휘발, 재부팅 시 소멸)
│ + rate-limit 초과분 드롭 · 용량 초과 시 오래된 것부터 회전 삭제
│
④ 조회: journalctl이 인덱싱된 필드로 필터
│ -u(유닛) · -p(우선순위) · --since/--until(기간) · _PID= · _EXE=
▼
[결과] 텍스트를 grep으로 뒤지는 게 아니라 필드 쿼리로 정확히 추출
각 단계에서 무슨 일이 일어나고, 새거나 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 새면/막히면 |
|---|---|---|
| ① 수집 | systemd가 서비스 stdout/stderr를 저널로 연결, syslog도 journald가 받음 | 앱이 StandardOutput=file:이나 자체 파일 로거를 쓰면 저널을 우회 → -u로 안 보임 |
| ② 메타데이터 | _PID·_UID·_SYSTEMD_UNIT·PRIORITY를 자동 부착 | 필드가 붙으니 유닛 이름을 몰라도 _EXE=·_PID=로 추적 가능 |
| ③ 저장 | 영속(/var/log/journal) 또는 휘발(/run)에 바이너리로 저장 | 휘발이면 재부팅 후 과거 로그 증발 · rate-limit 초과분은 Suppressed로 드롭 · 용량 초과는 회전 삭제 |
| ④ 조회 | 인덱스 필드로 필터 쿼리 | 시간창은 벽시계 기준 — 시계 점프(VM·NTP)면 --since가 직관과 다르게 잘림 |
그래서 "로그가 없다"는 대개 ④(조회)가 아니라 앞 단계의 문제입니다 — ①에서 저널을 우회했거나, ③에서 휘발 저장이라 사라졌거나 rate-limit에 드롭된 것입니다. ls /var/log/journal/로 ③의 영속 여부를, systemctl cat <유닛>의 StandardOutput으로 ①의 우회 여부를 먼저 확인하면, 조회가 안 되는 게 아니라 애초에 저장이 안 된 경우를 골라낼 수 있습니다.
아래 명령들은 실무에서 가장 자주 쓰는 패턴입니다. 하나씩 실행해보며 출력 형식을 눈에 익히고, 마지막엔 유닛+우선순위+시간을 조합해 "최근 1시간 nginx 에러만" 뽑아봅니다.
유닛별 로그 조회 — 가장 기본
# 특정 서비스 로그 전체 보기
journalctl -u nginx
# 마지막 50줄만
journalctl -u nginx -n 50
# 실시간 스트리밍 (tail -f와 동일)
journalctl -u nginx -f
시간 범위 지정 — 장애 구간 좁히기
# 오늘 오후 2시부터 3시까지
journalctl -u payment-service --since "2024-01-15 14:00:00" --until "2024-01-15 15:00:00"
# 상대 시간 표현도 가능
journalctl -u nginx --since "1 hour ago"
journalctl -u nginx --since "yesterday"
journalctl -u nginx --since "2 hours ago" --until "1 hour ago"
우선순위(severity) 필터 — 에러만 추출
# err 이상(err, crit, alert, emerg)만 출력
journalctl -u myapp -p err
# 우선순위 번호로도 지정 가능 (0=emerg, 3=err, 6=info, 7=debug)
journalctl -u myapp -p 3
# 범위 지정: warning 이상
journalctl -p warning
# 전체 시스템에서 오늘 발생한 에러
journalctl -p err --since today
우선순위 체계는 syslog 표준을 따릅니다:
| 번호 | 레벨 | 의미 |
|---|---|---|
| 0 | emerg | 시스템 불능 |
| 1 | alert | 즉각 조치 필요 |
| 2 | crit | 심각한 오류 |
| 3 | err | 일반 오류 |
| 4 | warning | 경고 |
| 5 | notice | 주목할 만한 정상 상태 |
| 6 | info | 정보성 메시지 |
| 7 | debug | 디버그 정보 |
여러 유닛 동시 조회
# 두 서비스를 함께 보기 (API 게이트웨이 + 백엔드 연관 추적 시 유용)
journalctl -u nginx -u node-app --since "30 minutes ago"
journalctl -u nginx -p err --since '1 hour ago'- 유닛+우선순위+시간을 조합(-u nginx -p err --since)했을 때 출력이 확 줄었는지 본다 — 전체 로그가 그대로 나오면 필터가 안 먹은 것(옵션 오타/따옴표 확인)
- -p err 결과에 info/debug 줄이 섞여 있으면 안 된다 — err 이상(0~3)만 보여야 정상. 섞이면 -p 숫자/레벨을 다시 확인
- --since 결과의 첫 줄 타임스탬프가 지정 시각 이후인지 확인 — 더 과거가 보이면 시간 표현이 파싱 안 돼 무시된 것
- 여러 유닛 조회 시 두 서비스 로그가 시간순으로 섞여 나오는지 본다 — 한 유닛만 나오면 -u를 반복하지 않고 덮어쓴 것
2. 구조화 로그 읽기 — JSON 출력의 진짜 활용
journald 구조화 출력이 중요한 이유
 확대
확대
텍스트 로그를 grep으로 파싱하는 방식은 로그 포맷이 바뀌면 스크립트가 망가집니다. journald의 JSON 출력은 각 항목을 키-값 쌍으로 노출해 로그 포맷 변경과 무관하게 안정적으로 파싱할 수 있습니다. 포스트모텀 보고서를 작성할 때, 또는 로그를 자동화 파이프라인으로 넘길 때 JSON 출력이 기준이 됩니다.
출력 포맷은 -o (또는 --output) 옵션으로 지정합니다:
| 포맷 | 설명 | 용도 |
|---|---|---|
short | 기본 텍스트 출력 | 사람이 직접 읽기 |
short-precise | 마이크로초 단위 타임스탬프 | 성능 분석, 순서 정렬 |
json | 한 줄에 항목 하나 (기계 파싱용) | 파이프라인, 스크립트 |
json-pretty | 들여쓰기 있는 JSON (사람 읽기용) | 디버깅, 포스트모텀 검토 |
cat | 메시지 텍스트만 출력 | grep과 조합 |
verbose | 모든 필드 표시 | 가용 필드 확인 시 |
JSON 출력 실습
# 읽기 쉬운 JSON 형식으로 출력
journalctl -u nginx -n 5 -o json-pretty
# 출력 예시 (주요 필드)
{
"__REALTIME_TIMESTAMP" : "1705312800123456",
"_HOSTNAME" : "web-prod-01",
"_SYSTEMD_UNIT" : "nginx.service",
"_PID" : "12345",
"_EXE" : "/usr/sbin/nginx",
"_UID" : "0",
"PRIORITY" : "6",
"MESSAGE" : "start worker process 12346",
"SYSLOG_IDENTIFIER" : "nginx"
}
jq로 필요한 필드만 추출
# 타임스탬프와 메시지만 추출
journalctl -u nginx --since "1 hour ago" -o json | \
jq -r '[.__REALTIME_TIMESTAMP, .MESSAGE] | @tsv'
# 에러 레벨 로그의 PID와 메시지만
journalctl -u myapp -p err -o json | \
jq -r 'select(.PRIORITY <= "3") | "\(._PID) \(.MESSAGE)"'
포스트모텀용 로그 추출 — 실무 패턴
# 장애 발생 시간대 로그를 파일로 저장
journalctl -u payment-service \
--since "2024-01-15 14:00:00" \
--until "2024-01-15 15:00:00" \
-o json-pretty > incident-20240115-payment.json
# 여러 서비스를 함께 타임라인 순으로 저장
journalctl -u api-gateway -u payment-service -u inventory-service \
--since "2024-01-15 13:55:00" \
--until "2024-01-15 15:05:00" \
-o json > incident-full-timeline.json
3. 구조화 필드 직접 쿼리 — 유닛 이름 없이 추적하기
실습: _EXE=, _PID=, _UID=로 필터링
유닛 이름(-u)을 모를 때, 또는 같은 바이너리를 여러 유닛이 공유할 때 구조화 필드가 유용합니다.
# 특정 실행 파일이 남긴 로그 (절대 경로 필수)
journalctl _EXE=/usr/bin/python3
# 특정 PID가 남긴 로그 — 크래시 직전 프로세스 추적
journalctl _PID=12345
# 특정 사용자(UID)가 실행한 프로세스 로그 전체
journalctl _UID=1001
# 조합 필터 — AND 조건 (같은 줄에 나열)
journalctl _UID=1001 _EXE=/usr/bin/python3
# OR 조건 — 두 필드 중 하나라도 일치하면 출력
journalctl _EXE=/usr/sbin/nginx + _EXE=/usr/bin/nginx
가용 필드 확인
어떤 필드들이 있는지 모를 때:
# 특정 항목의 모든 필드를 verbose로 확인
journalctl -u nginx -n 1 -o verbose
# 필드 이름 목록만 확인
journalctl -F _TRANSPORT # 사용 가능한 _TRANSPORT 값 목록
journalctl -F _SYSTEMD_UNIT # 현재 저널에 있는 모든 유닛 이름
journalctl -F _EXE # 저널에 기록된 모든 실행 파일 경로
실무 시나리오: 서비스명 모르는 Python 스크립트 로그 찾기
# 1단계: 어떤 Python 실행 파일들이 로그를 남겼는지 확인
journalctl -F _EXE | grep python
# 출력 예시
# /usr/bin/python3
# /usr/bin/python3.10
# /opt/venv/bin/python3
# 2단계: 해당 경로로 직접 필터링
journalctl _EXE=/usr/bin/python3 --since "1 hour ago" -p err
커널 메시지 분리 — -k 옵션
# 커널 메시지만 (dmesg와 동일하지만 시간 필터 등 journalctl 기능 사용 가능)
journalctl -k
# 부팅 시 커널 메시지 (하드웨어 감지, 드라이버 로드 순서 확인)
journalctl -k -b
# 이전 부팅의 커널 메시지 (크래시 직전 상황)
journalctl -k -b -1
# OOM Killer 발생 여부 확인 — 메모리 부족으로 프로세스 강제 종료
journalctl -k | grep -i "oom\|killed process\|out of memory"
# 디스크 오류 확인
journalctl -k | grep -i "error\|i/o error\|failed\|reset"
# 특정 시간대 커널 메시지
journalctl -k --since "2024-01-15 03:00:00" --until "2024-01-15 03:30:00"
OOM Killer 로그 예시 — 이런 출력이 나오면 메모리 부족이 원인
Jan 15 03:14:22 web-prod-01 kernel: Out of memory: Killed process 8823 (java) total-vm:4194304kB, anon-rss:3145728kB
Jan 15 03:14:22 web-prod-01 kernel: oom_reaper: reaped process 8823 (java), now anon-rss:0kB
- 먼저 journalctl -p err --since today 로 오늘 에러를 확인하고(최신 항목이 아래에 위치 — 스크롤 끝으로 이동), 그 다음 journalctl -k | grep -i oom 으로 OOM 이력을 확인한다
- journalctl --disk-usage 가 1GB 이상이면 vacuum 권장 — journalctl --vacuum-time=7d 로 7일 이전 로그 즉시 삭제 가능
- journalctl _EXE=/usr/bin/python3 결과가 나오는데 특정 유닛 로그에는 없다면 → 해당 프로세스가 systemd 외부에서 직접 실행됐음을 의미
- OOM 로그에 프로세스명과 anon-rss 값이 있고 동시에 해당 서비스가 재시작됐다면 → 메모리 한도(MemoryMax) 설정 또는 힙 메모리 누수를 조사해야 함
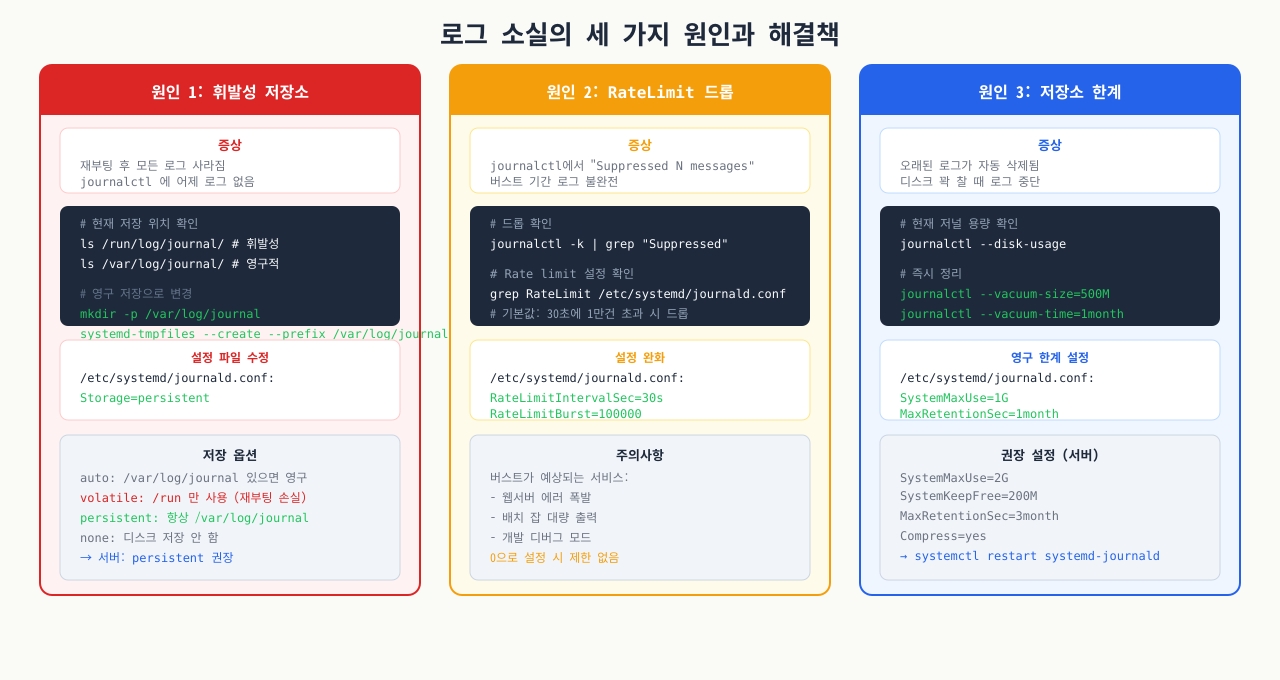
4. 로그가 "없는" 세 가지 경우와 해결법
로그 소실의 세 가지 원인
 확대
확대
장애 대응 중 journalctl -u myapp을 쳤는데 아무것도 나오지 않는 상황은 생각보다 자주 발생합니다. 원인은 크게 세 가지이며, 원인마다 해결 방법이 다릅니다.
케이스 1: journald가 메모리에만 저장 중 — 재부팅 시 소실
Ubuntu 22.04 기본 설치에서 /var/log/journal/ 디렉터리가 없으면 journald는 /run/log/journal/(tmpfs, 메모리)에만 저장합니다. 재부팅하면 로그가 사라집니다.
# 영구 저장 디렉터리 없음 → 재부팅 전 로그는 이미 소실
ls /var/log/journal/ # 결과 없음 = 영구 저장 안 됨
# journalctl --list-boots 결과가 딱 한 줄 (현재 부팅만)
journalctl --list-boots
케이스 2: 서비스가 journald를 통하지 않고 직접 파일에 씀
-u nginx로 로그가 없어도 /var/log/nginx/error.log에는 있을 수 있습니다. systemd가 관리하더라도 서비스 자체가 StandardOutput=file:/path/to/app.log로 설정되어 있거나, 앱이 자체 파일 로거(예: Python의 logging 모듈, Log4j)를 사용하면 journald를 우회합니다.
# unit 파일의 출력 설정 확인
systemctl cat myapp | grep -E "Standard(Output|Error)"
# 직접 파일로 쓰는 경우 → 해당 로그 파일을 확인
# 예: /var/log/myapp/app.log, /opt/myapp/logs/error.log
케이스 3: Rate Limiting으로 로그가 드롭됨
journald는 기본적으로 짧은 시간에 대량의 로그가 발생하면 일부를 드롭합니다. 이 경우 드롭된 사실은 기록되지만 실제 로그는 사라집니다.
# Rate limit 드롭 메시지 확인
journalctl -u myapp | grep "Suppressed"
# 또는
journalctl | grep "systemd-journald.*Suppressed"
로그 Rate Limiting은 /etc/systemd/journald.conf에서 조정 가능합니다:
[Journal]
RateLimitIntervalSec=30s
RateLimitBurst=10000 # 30초에 최대 10000개 (기본값 1000)
5. journal 영구 저장 설정과 용량 관리
실습: persistent 저장 설정
# 1단계: 영구 저장 디렉터리 생성
sudo mkdir -p /var/log/journal
# 2단계: 권한 설정 (journald가 쓸 수 있도록)
sudo systemd-tmpfiles --create --prefix /var/log/journal
# 3단계: journald 재시작
sudo systemctl restart systemd-journald
# 4단계: 확인 — 이제 --list-boots에 이전 부팅 기록이 쌓임
journalctl --list-boots
또는 /etc/systemd/journald.conf를 직접 수정:
sudo nano /etc/systemd/journald.conf
[Journal]
# 영구 저장 강제 (auto: 디렉터리 있을 때만 영구, volatile: 항상 메모리)
Storage=persistent
# 최대 디스크 사용량 (전체 파일시스템의 10% 또는 여기서 지정한 값 중 작은 것)
SystemMaxUse=2G
# 각 journal 파일의 최대 크기
SystemMaxFileSize=200M
# 특정 기간 이전 로그 자동 삭제
MaxRetentionSec=3months
# Rate Limiting 완화 (로그가 드롭되는 경우)
RateLimitIntervalSec=30s
RateLimitBurst=10000
설정 후 적용:
sudo systemctl restart systemd-journald
이전 부팅 로그 조회
영구 저장이 설정되면 이전 부팅 때의 로그도 볼 수 있습니다. 서버가 갑자기 재부팅됐을 때 재부팅 직전 로그를 확인하는 핵심 기능입니다.
# 부팅 기록 목록 확인 (왼쪽 번호: 0=현재, -1=직전, -2=전전)
journalctl --list-boots
# 출력 예시
# -2 abc123def Mon 2024-01-14 09:00:00 KST—Mon 2024-01-14 18:00:00 KST
# -1 xyz789ghi Tue 2024-01-15 09:00:00 KST—Tue 2024-01-15 03:14:25 KST ← 비정상 종료
# 0 pqr456stu Tue 2024-01-15 03:15:10 KST—still running
# 재부팅 직전 로그 확인 (-1 = 직전 부팅)
journalctl -b -1
# 직전 부팅의 특정 서비스 로그
journalctl -b -1 -u nginx
# 직전 부팅의 커널 메시지 (크래시 원인 추적)
journalctl -b -1 -k -p err
상황: journalctl 실행 시 No journal files were found 또는 -- No entries -- 출력
원인 1: journald가 실행되지 않음
systemctl status systemd-journald
# active (running) 이 아니면:
sudo systemctl start systemd-journald
sudo systemctl enable systemd-journald
원인 2: 현재 사용자에게 저널 읽기 권한 없음
# root로 실행하거나
sudo journalctl
# 또는 현재 사용자를 systemd-journal 그룹에 추가
sudo usermod -aG systemd-journal $USER
# 로그아웃 후 재로그인 필요
원인 3: 저널 디렉터리 권한 오류
# /run/log/journal/ 또는 /var/log/journal/ 권한 확인
ls -la /run/log/journal/
ls -la /var/log/journal/ 2>/dev/null
# 권한 복구
sudo chown root:systemd-journal /var/log/journal/
sudo chmod 2755 /var/log/journal/
sudo systemctl restart systemd-journald
원인 4: 저널 파일 손상
# 저널 파일 무결성 검사
sudo journalctl --verify
# 손상된 파일 발견 시 해당 파일만 제거 후 재시작
# (주의: 해당 파일의 로그는 소실됨)
sudo systemctl stop systemd-journald
sudo rm /var/log/journal/$(hostname -m)/*.journal~ # ~는 손상된 파일
sudo systemctl start systemd-journald
심화 — 로그의 시간을 믿을 수 있는가
심화: journald가 시간을 두 번 기록하는 이유 — 실시간 시계와 단조 시계
각 로그 항목에는 시각이 두 개 저장됩니다: __REALTIME_TIMESTAMP(벽시계, Unix epoch 마이크로초)와 __MONOTONIC_TIMESTAMP(부팅 이후 흐른 단조 증가 시간). journalctl이 기본으로 보여주는 사람이 읽는 시각은 realtime입니다. 왜 굳이 둘을 다 둘까요?
- 벽시계는 점프할 수 있다: realtime은 NTP가 큰 오차를 한 번에 보정(step)하거나, 관리자가 시간을 바꾸거나, VM이 스냅샷·일시정지 후 재개되면 앞으로/뒤로 훌쩍 뜁니다. 그러면 realtime 기준으로는 로그가 거꾸로 흐르거나 특정 구간이 비어/겹쳐 보입니다.
- 단조 시계는 절대 뒤로 안 간다: monotonic은 부팅 이후 단조 증가만 하므로, 한 부팅 안에서 무엇이 먼저 일어났나의 진짜 순서는 monotonic이 답합니다. 그래서 순서가 중요한 분석은
-o short-monotonic으로 단조 시각을 봅니다. - 한계 — 시간 범위 필터는 벽시계로 자른다:
--since·--until은 realtime 기준입니다. 벽시계가 점프한 구간에서는 시간 범위 필터가 직관과 다르게 동작해, 필요한 로그가 빠지거나 중복됩니다. 서버 간 타임라인 합산이 NTP 동기에 의존하는 것(JobContext에서 본 문제)도 realtime을 쓰기 때문입니다. - 다음 단계 — 부팅 경계는 boot ID로 가른다: 재부팅하면 monotonic은 0부터 다시 시작하므로 부팅을 넘는 순서 비교엔 못 씁니다. 그땐
_BOOT_ID로 부팅을 먼저 나눈 뒤, 각 부팅 안에서 monotonic으로 정렬합니다.
정리하면 journald가 시간을 두 번 적는 것은 낭비가 아니라 대비책입니다 — 사람이 읽기 좋은 벽시계와, 순서를 보장하는 단조 시계를 나눠 두어, 시계가 튀는 순간에도 진짜 순서를 잃지 않게 합니다.
상황: 특정 시각의 장애를 조사하려 journalctl --since ... --until ...로 구간을 잘랐더니, 타임스탬프가 중간에 거꾸로 가거나(뒤 시각이 앞 시각보다 먼저 나옴) 몇 분 구간이 통째로 비어 보입니다. 그 서버는 VM이거나, 최근 NTP가 시간을 크게 보정한 이력이 있습니다.
원인: journalctl이 보여주는 사람 시각은 벽시계(__REALTIME_TIMESTAMP)입니다. VM이 일시정지 후 재개됐거나 NTP가 큰 오차를 한 번에 step 보정하면 벽시계가 앞으로/뒤로 점프합니다. 로그는 실제로는 연속으로 쌓였지만, 점프 순간을 걸친 항목들의 realtime 값이 어긋나 거꾸로/공백처럼 보이는 것입니다. --since·--until도 realtime으로 자르므로, 점프한 구간이 필터에서 빠지거나 겹칩니다. 로그가 사라진 게 아니라 시각 축이 흔들린 것입니다.
진단: 순서의 진실은 단조 시계로 확인합니다 — journalctl -b -o short-monotonic으로 보면 부팅 이후 단조 증가 시각이라 절대 거꾸로 가지 않으므로, realtime이 튄 지점이 드러납니다. 시간 점프 자체는 journalctl -u systemd-timesyncd(또는 chronyd) 로그, 커널의 clock/time jumped 메시지, VM이면 하이퍼바이저의 pause/resume 이력으로 확인합니다. _BOOT_ID는 같은데 realtime만 튀면 클럭 점프로 확정입니다.
해결: 순서가 중요한 분석은 realtime 대신 -o short-monotonic(같은 부팅 내)으로 하고, 부팅이 바뀌면 _BOOT_ID로 먼저 가른 뒤 각 부팅 안에서 정렬합니다. 근본 예방은 시계를 안 튀게 하는 것 — chrony/NTP를 상시 동기해 큰 step 보정이 안 일어나게 하고(작은 slew로 흡수되게), VM 스냅샷·일시정지 후에는 시간 재동기를 확인합니다. --since·--until이 이상하면 시간 범위를 넉넉히 잡아 점프 구간을 포함시킨 뒤 monotonic으로 다시 정렬합니다.
SRE가 장애 포스트모텀 작성할 때 로그 추출하는 방법
포스트모텀(Post-Mortem)은 장애가 종료된 후 원인, 타임라인, 재발 방지를 문서화하는 과정입니다. 로그 추출이 제대로 안 되면 타임라인을 정확히 복원할 수 없고, 결국 "아마도 이런 이유였을 것"이라는 추측으로 끝납니다.
실무 추출 절차
# 1단계: 영향 받은 서비스와 시간대 파악
# 모니터링 알람 시각 기준으로 전후 10분씩 여유를 줌
INCIDENT_START="2024-01-15 14:00:00"
INCIDENT_END="2024-01-15 15:30:00"
# 2단계: 관련 서비스 로그 전체를 JSON으로 덤프
journalctl \
-u api-gateway \
-u payment-service \
-u database-proxy \
--since "$INCIDENT_START" \
--until "$INCIDENT_END" \
-o json > /tmp/incident-$(date +%Y%m%d)-logs.json
# 3단계: 에러 레벨 이상만 별도 추출 (요약용)
journalctl \
-u api-gateway -u payment-service \
--since "$INCIDENT_START" \
--until "$INCIDENT_END" \
-p err \
-o short-precise > /tmp/incident-$(date +%Y%m%d)-errors.txt
# 4단계: 커널 이상 여부 확인 (OOM, 디스크 오류)
journalctl -k \
--since "$INCIDENT_START" \
--until "$INCIDENT_END" \
-p warning > /tmp/incident-$(date +%Y%m%d)-kernel.txt
# 5단계: 로그 파일을 팀 공유 스토리지로 복사
scp /tmp/incident-*.json /tmp/incident-*.txt postmortem-storage:/incidents/2024-01-15/
포스트모텀 타임라인 재구성 — jq 활용
# 에러 발생 순서대로 타임스탬프 + 서비스 + 메시지 정렬
cat /tmp/incident-20240115-logs.json | \
jq -r 'select(.PRIORITY <= "4") |
"\(.__REALTIME_TIMESTAMP | tonumber / 1000000 | strftime("%Y-%m-%d %H:%M:%S")) [\(._SYSTEMD_UNIT // "kernel")] \(.MESSAGE)"' | \
sort > /tmp/incident-timeline.txt
현우의 현장 팁
포스트모텀 로그 추출은 장애 종료 직후 바로 해야 합니다. journald의 기본 용량 설정에 따라 오래된 로그가 자동 삭제될 수 있습니다. 특히 트래픽이 많은 서버에서는 며칠 치 로그도 하루 만에 밀려날 수 있습니다. 장애 종료 확인 즉시 journalctl 덤프를 외부 스토리지에 저장하는 것을 팀 프로세스로 만들어두세요.
또한 여러 서버가 있는 환경에서는 서버마다 시계가 미세하게 다를 수 있습니다. journalctl의 __REALTIME_TIMESTAMP는 마이크로초 단위 Unix 타임스탬프라 NTP 동기화 상태에 따라 서버 간 타임라인 합산 시 순서가 어긋날 수 있습니다. -o short-precise로 마이크로초 타임스탬프를 확인하고, 중앙 로그 수집 시스템(Loki, Elasticsearch)에서 재정렬하는 것이 정확합니다.
명령어·단축키 빠른 참조
이 모듈에서 다룬 journalctl 필터·구조화 출력·보존 관리 명령을 실전 옵션과 함께 모았습니다. "예" 열의 조합을 그대로 써도 됩니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
journalctl -u <unit> | 특정 서비스 로그 | journalctl -u nginx -f (실시간 스트리밍) |
-p <level> | 우선순위 필터 | journalctl -u nginx -p err --since '1 hour ago' |
--since / --until | 시간 범위 지정 | journalctl --since '14:00' --until '15:00' |
-o json-pretty | 구조화(JSON) 출력 | journalctl -u api -o json-pretty (필드 전체 확인) |
-F <필드> | 필드 값 목록만 조회 | journalctl -F _EXE (로그 남긴 실행파일 목록) |
_EXE= / _PID= / _UID= | 유닛명 없이 필드로 추적 | journalctl _PID=1234 (크래시 직전 프로세스) |
-k | 커널 메시지만 | journalctl -k -b -1 (직전 부팅 커널 로그·OOM) |
-b / -b -1 | 부팅 단위 조회 | journalctl --list-boots 로 부팅 목록 먼저 |
--disk-usage | 저널 용량 확인 | 1GB 이상이면 vacuum 권장 |
--vacuum-time | 오래된 로그 삭제 | journalctl --vacuum-time=7d (7일 이전 삭제) |
--verify | 저널 파일 손상 검사 | sudo journalctl --verify |
journalctl -u a -u b | 다중 유닛 타임라인 | 게이트웨이+백엔드 연관 추적 |
관련 모듈로 더 깊이:
- 리눅스 부팅 시 데몬 프로세스 자동 실행 및 관리 가이드 — 로그를 남기는 서비스 자체를 정의·제어하는 법
- 서버 다운 시 신속하게 CPU/메모리/네트워크/로그 확인하는 룰 — 추출한 로그를 장애 초동 대응 타임라인에 엮는 법
- logrotate로 서버 용량 갉아먹는 로그 파일 자동 압축/분할 — journald 외 파일 로그의 보존·순환을 관리하는 법
다음 모듈에서는 서버 백업 전략과 rsync를 활용해 데이터를 안전하게 보호하고 장애 시 신속하게 복구하는 방법을 다룹니다.
퀴즈
위 frontmatter의 quiz 항목 3개로 모듈 이해도를 확인하세요.