서비스가 갑자기 느려졌다는 신고가 왔습니다. top을 열었더니 CPU는 한가하고, 메모리도 여유가 있어 보입니다. 그런데 서비스는 분명히 느립니다. 원인을 찾지 못하고 서버를 재시작했는데, 잠시 후 또 느려졌습니다. 나중에 알고보니 디스크 I/O가 포화 상태였습니다. vmstat의 wa(iowait) 컬럼이 계속 40%를 넘고 있었는데, top만 봐서는 이 신호를 놓쳤습니다. 병목의 종류를 체계적으로 확인하는 순서를 알면, 막연한 재시작 대신 5분 안에 원인을 특정할 수 있습니다.
시스템 모니터링 심화 (vmstat / iostat / sar)
서비스가 느려졌다는 신고가 들어왔을 때, 막연하게 서버를 재시작하거나 로그만 뒤적이는 것은 숙련된 엔지니어의 접근법이 아닙니다. 이 챕터에서는 시스템 성능 병목을 정확히 진단하는 체계적인 방법론과, 그 방법론을 뒷받침하는 핵심 도구들을 다룹니다.
1. 성능 병목 진단 순서
실무에서 성능 장애를 받았을 때 무작위로 도구를 실행하면 시간을 낭비하게 됩니다. 아래 순서대로 좁혀 나가는 것이 가장 효율적입니다.
[1] CPU 포화도 확인 → vmstat, top, mpstat
[2] 메모리 압박 확인 → vmstat (swap si/so), free -h
[3] Disk I/O 확인 → iostat -x, iotop
[4] 네트워크 확인 → sar -n DEV, ss -s, iftop
[5] 프로세스 수준 드릴다운 → perf top, strace, lsof
이 흐름을 머릿속에 새겨 두면 어떤 서버에서도 30초 안에 방향을 잡을 수 있습니다.
- 1성능 병목 4가지 유형(CPU/I/O/메모리/네트워크)을 체계적으로 진단할 수 있다
- 2vmstat으로 CPU iowait·swap 활동·프로세스 대기열을 분석할 수 있다
- 3iostat -x의 await·%util로 디스크 포화도를 측정할 수 있다
- 4sar로 과거 시계열 데이터를 재조회하고 트렌드를 분석할 수 있다
- 5iotop·strace·lsof로 프로세스 수준까지 드릴다운할 수 있다
sudo apt install -y sysstat # Ubuntu/Debian
sudo yum install -y sysstat # RHEL/CentOSsudo systemctl enable --now sysstatsudo apt install -y iotop성능 병목의 4가지 유형
 확대
확대
서버가 느려졌다는 알람이 왔을 때 어디부터 봐야 할지 막막하면, 먼저 "CPU인가, 메모리인가, 디스크인가, 네트워크인가"를 구분하는 것부터 시작합니다. 증상이 비슷해 보여도 원인 자원이 다르면 봐야 하는 지표가 다르고, 대응 방법도 다릅니다. CPU 병목인 줄 알고 CPU를 늘렸는데 실제 원인이 디스크 I/O였다면 비용만 낭비한 겁니다. 4가지 병목 유형과 그 특징적인 지표를 알아두면 top, iostat, vmstat로 보는 숫자들이 문장처럼 읽히기 시작합니다.
시스템 자원은 크게 네 가지로 나뉩니다. 각 병목은 서로 다른 증상과 지표를 보입니다.
CPU 병목 (CPU-bound)
- 증상:
vmstat의us(user) 또는sy(system) 값이 지속적으로 높음 - 원인: 연산 집약적 프로세스, 스레드 수 과다, 잘못된 알고리즘
- 확인:
top에서 CPU 100% 프로세스,mpstat -P ALL로 코어별 분포
I/O 병목 (I/O-bound)
- 증상:
vmstat의wa(iowait) 값이 높음, Load Average 높음 - 원인: 느린 디스크, 디스크 큐 포화, 비효율적 쿼리의 대량 읽기
- 확인:
iostat -x의await와%util값
메모리 병목 (Memory-bound)
- 증상:
vmstat의si/so(swap in/out) 값이 0이 아님, 시스템 전반적 둔화 - 원인: 메모리 부족으로 인한 스왑 활성화
- 확인:
free -h로 가용 메모리,vmstat의swpd필드
네트워크 병목 (Network-bound)
- 증상: 애플리케이션 지연은 있지만 CPU/메모리/디스크는 정상
- 원인: 대역폭 포화, 패킷 손실, 높은 지연 시간(RTT)
- 확인:
sar -n DEV,ss -s,netstat -s
각 유형은 독립적으로 발생하기도 하지만, I/O 병목이 CPU 대기를 유발하거나 메모리 부족이 스왑 I/O를 유발하는 식으로 연쇄적으로 발생하는 경우가 더 많습니다.
vmstat·iostat가 '율'을 만드는 법 — 커널 카운터에서 병목 판단까지
vmstat 1의 첫 줄은 늘 버리고 둘째 줄부터 보라고 배웁니다. 왜 그런지 알면 순간값에 속지 않습니다. 이 도구들은 값을 그 자리에서 "측정"하는 게 아니라, 커널이 계속 쌓아 둔 누적 카운터를 두 번 읽어 그 차이(델타)로 초당 율(rate)을 계산합니다. 이 원리를 알면 표본 하나로 단정하는 실수와, 간격이 길어 스파이크가 평균에 묻히는 함정을 함께 피할 수 있습니다.
[커널] /proc·/sys 에 누적 카운터를 계속 증가시킴
│ (/proc/stat의 CPU tick, /proc/diskstats의 IO 완료 수 등)
│
① t0 시점 카운터를 읽음 (스냅샷 A)
│
② interval(예: 1초) 대기
│
③ t1 시점 카운터를 다시 읽음 (스냅샷 B)
│
④ 델타 환산: (B - A) / interval → 초당 율
│ (그래서 첫 줄=부팅~지금 평균, 둘째 줄부터가 '지금')
│
⑤ 해석: 어느 자원이 한계인가 (us·sy·wa / await·%util / si·so)
│
⑥ 조치·프로세스 드릴다운 (top·iotop·strace로 범인 특정)
▼
[판단] 순간의 인상이 아니라 구간 평균으로 병목 자원 확정
각 단계에서 무엇을 하고, 잘못 읽으면 어떤 증상인가:
| 단계 | 무엇을 하나 | 잘못 읽으면 증상 |
|---|---|---|
| ① 카운터 읽기 | /proc·/sys의 단조 증가 누적값을 읽음 | 카운터는 절대값이라 한 번만 읽으면 "지금 얼마나 바쁜지"가 아니라 부팅 이후 총량일 뿐 |
| ② interval 대기 | 두 스냅샷 사이 간격 확보 | 간격이 너무 길면(sar 10분 등) 짧은 스파이크가 평균에 묻혀 사라짐(평균 함정) |
| ③ 재읽기 | t1 스냅샷 확보 | 카운터가 랩어라운드·리셋되면 음수 델타로 값이 튐 |
| ④ 델타→율 | 차이를 시간으로 나눠 초당 율로 환산 | 첫 줄(부팅 평균)을 현재값으로 오해하면 늘 낙관적 수치 — 반드시 둘째 줄부터 |
| ⑤ 해석 | 율을 자원별 지표로 매핑 | 순간값 한 줄만 보고 결론내면 튀는 표본에 속음 — 여러 줄 추세로 판단 |
| ⑥ 드릴다운 | 자원 특정 뒤 프로세스로 좁힘 | 자원을 못 정한 채 프로세스부터 뒤지면 엉뚱한 곳에 시간 낭비 |
즉 이 도구들이 뿜는 숫자는 전부 "두 시점 카운터의 차이"입니다 — 그래서 표본이 최소 둘은 있어야 하고(첫 줄은 버린다), 간격이 증상의 시간 규모와 맞아야 하며(짧은 스파이크엔 짧은 간격), 한 줄이 아니라 여러 줄의 추세로 읽어야 속지 않습니다. vmstat 1 5를 실행해 둘째 줄부터 wa·r·si/so가 어떻게 움직이는지 보는 것이 병목 자원을 좁히는 출발점입니다.
2. vmstat — 시스템 상태의 한눈 보기
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/linux/part6/exam_30 && cd /tmp/linux/part6/exam_30
# 부하 발생 스크립트 (모니터링 실습용)
cat > generate_load.sh << 'EOF'
#!/bin/bash
echo "CPU 부하 발생 (30초)..."
for i in $(seq 1 $(nproc)); do
dd if=/dev/zero of=/dev/null &
done
PIDS=$(jobs -p)
sleep 30
kill $PIDS 2>/dev/null
echo "완료"
EOF
cat > generate_io.sh << 'EOF'
#!/bin/bash
echo "I/O 부하 발생 (30초)..."
dd if=/dev/zero of=/tmp/linux/part6/exam_30/iotest bs=1M count=500 &
DD_PID=$!
sleep 30
kill $DD_PID 2>/dev/null
rm -f /tmp/linux/part6/exam_30/iotest
echo "완료"
EOF
chmod +x *.sh
이제 실습을 진행합니다.
vmstat(Virtual Memory Statistics)은 CPU, 메모리, 스왑, 블록 I/O, 프로세스 상태를 한 줄에 요약해 주는 도구입니다. 가장 먼저 실행해야 할 명령어입니다.
기본 사용법
# 2초 간격으로 10회 출력
vmstat 2 10
# 메가바이트 단위로 출력
vmstat -S M 2 10
# 디스크 통계 포함
vmstat -d 2 5
vmstat 출력 해석
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 1024532 102400 2048000 0 0 5 12 312 789 8 2 88 2 0
5 1 0 512000 98000 1980000 0 0 0 1024 845 1230 45 8 42 5 0
procs 섹션 — r(실행 대기)과 b(블로킹) 값으로 CPU/IO 병목을 1차 판단합니다:
| 필드 | 의미 | 주의 기준 |
|---|---|---|
r | 실행 대기 중인 프로세스 수 (Run queue) | CPU 코어 수보다 지속적으로 크면 CPU 병목 |
b | 블로킹된 프로세스 수 (I/O 대기) | 1 이상이 지속되면 I/O 병목 의심 |
memory 섹션 — swpd가 0이 아니거나 free가 급감하면 메모리 압박이 시작된 것입니다:
| 필드 | 의미 | 주의 기준 |
|---|---|---|
swpd | 사용 중인 스왑 공간 (KB) | 0이 아니면 메모리 부족 발생한 적 있음 |
free | 완전히 비어 있는 메모리 (KB) | 낮아도 cache가 크면 정상 |
buff | 버퍼 캐시 (KB) | 파일시스템 메타데이터 캐시 |
cache | 페이지 캐시 (KB) | 높을수록 좋음 (OS가 I/O 최적화에 사용) |
swap 섹션 — 가장 중요한 두 필드 — si(swap in)/so(swap out) 값이 지속적으로 0이 아니면 메모리 부족 상태입니다:
| 필드 | 의미 | 주의 기준 |
|---|---|---|
si | Swap In — 디스크에서 메모리로 읽어 들인 양 (KB/s) | 0이 아니면 심각한 메모리 부족 |
so | Swap Out — 메모리에서 디스크로 쓴 양 (KB/s) | 0이 아니면 메모리 부족 시작 |
si와so가 동시에 0이 아닌 상태가 지속되면 **스왑 스래싱(swap thrashing)**입니다. 서버가 실제로 동작을 멈추는 수준으로 느려집니다. 즉각적인 대응이 필요합니다.
cpu 섹션 — wa(IO wait)와 id(idle)로 CPU가 실제로 일을 하는지 기다리는지 구분합니다:
| 필드 | 의미 | 주의 기준 |
|---|---|---|
us | User space CPU 사용률 | 애플리케이션 코드 실행 |
sy | Kernel space CPU 사용률 | 시스템 콜, 커널 처리 |
wa | I/O 대기(iowait) | 5% 이상이면 I/O 병목 의심, 20% 이상이면 심각 |
id | Idle (유휴) | 낮을수록 CPU 바쁨 |
st | Stolen — 가상화 환경에서 하이퍼바이저에 뺏긴 시간 | VM 환경에서 높으면 노이지 네이버 문제 |
다음 두 시나리오의 vmstat 출력을 비교하며 진단 능력을 키워 봅니다.
시나리오 1 — CPU 병목 패턴 — r이 CPU 코어 수보다 많고 wa는 낮으면 순수 CPU 병목입니다:
vmstat 1 5
예상 출력:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
8 0 0 2000000 50000 1500000 0 0 0 0 950 2100 85 10 5 0 0
7 0 0 1990000 50000 1500000 0 0 0 0 1020 2300 88 9 3 0 0
진단 포인트:
r값이 CPU 코어 수(예: 4코어)보다 훨씬 큰 8us + sy = 95%로 CPU 포화wa = 0→ I/O는 문제없음b = 0→ I/O 대기 프로세스 없음
결론: 순수 CPU 병목. top으로 어떤 프로세스가 CPU를 독점하는지 확인.
시나리오 2 — I/O 병목 패턴
예상 출력:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 4 0 1800000 30000 1200000 0 0 8500 4200 430 890 5 3 62 30 0
0 3 0 1790000 29000 1180000 0 0 9200 3800 510 920 4 4 55 37 0
진단 포인트:
b값이 3~4 → I/O를 기다리는 프로세스 다수wa = 30~37%→ CPU 시간의 1/3이 I/O 대기bi(block in)와bo(block out) 모두 높음r값은 낮음 → CPU 자체는 한산
결론: I/O 병목. iostat -x로 어느 디스크 디바이스가 포화 상태인지 확인.
실습 명령어 — vmstat로 실제 부하 패턴을 재현하고 수치 변화를 확인합니다:
# 현재 시스템 상태 확인
vmstat 2 15
# 특정 시점의 평균 (첫 줄은 부팅 이후 평균이므로 무시)
vmstat 1 5 | tail -4
# 디스크별 I/O 통계
vmstat -d 2 3
- vmstat 1 5 에서 wa(iowait) 컬럼이 20% 이상이면 디스크 병목 신호다
- vmstat 의 r 컬럼(실행 대기 프로세스)이 CPU 코어 수보다 지속적으로 높으면 CPU 병목이다
- si/so(swap in/out) 컬럼이 0이 아니면 메모리 부족으로 스왑이 발생 중이다
- vmstat -d 에서 특정 디스크의 wait 값이 높으면 해당 디바이스가 I/O 병목이다
3. Load Average 완전 이해
Load Average는 리눅스에서 가장 자주 언급되지만 가장 많이 오해받는 지표입니다.
Load Average의 정의
uptime
# 출력 예: 14:23:11 up 42 days, 3:15, 2 users, load average: 2.15, 1.87, 1.43
# 1분 5분 15분
Load Average는 실행 중이거나 실행 대기 중인 프로세스 수 + D 상태(Disk I/O 대기) 프로세스 수의 지수 이동 평균입니다.
중요: Load Average는 CPU 사용률이 아닙니다. 실행을 원하지만 기다리고 있는 스레드의 평균 개수입니다.
코어 수와의 관계
# CPU 코어 수 확인
nproc
# 또는
grep -c ^processor /proc/cpuinfo
| 코어 수 | Load Average | 해석 |
|---|---|---|
| 4코어 | 2.0 | 코어의 50%만 사용 중, 여유 있음 |
| 4코어 | 4.0 | 정확히 포화 상태, 대기 없음 |
| 4코어 | 8.0 | 2배 포화 — 실행 대기 스레드 상시 존재 |
| 1코어 | 1.0 | 포화 상태 |
핵심 공식: Load Average / CPU 코어 수 > 1.0이 지속되면 CPU 자원이 부족한 것입니다.
1분 / 5분 / 15분 값의 해석
load average: 0.5, 3.2, 4.8
최근 5분전 15분전
1분 < 5분 < 15분→ 부하가 점점 줄어드는 중 (회복 중)1분 > 5분 > 15분→ 부하가 점점 늘어나는 중 (악화 중)1분 >> 15분→ 갑작스러운 스파이크 발생
4. iostat — 디스크 I/O 심층 분석
iostat는 sysstat 패키지에 포함된 도구로, 디스크 장치별 I/O 성능을 상세히 보여줍니다.
설치 및 기본 사용법
# sysstat 설치
sudo apt install sysstat # Ubuntu/Debian
sudo yum install sysstat # RHEL/CentOS
# 기본 실행 (2초 간격, 5회)
iostat 2 5
# 확장 통계 (-x 옵션이 핵심)
iostat -x 2 5
# 특정 디바이스만
iostat -x sda 2 5
# 메가바이트 단위
iostat -xm 2 5
iostat -x 출력 필드 완전 해석
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 45.2 128.6 2.1 8.4 0.0 14.2 0.0 9.9 1.2 18.4 2.41 47.6 66.8 5.2 89.2
nvme0n1 820.0 1240.0 51.2 78.6 0.0 0.0 0.0 0.0 0.3 0.4 0.42 64.0 64.9 0.3 31.0
| 필드 | 의미 | 주의 기준 |
|---|---|---|
r/s | 초당 읽기 요청 수 | 장치 특성에 따라 다름 |
w/s | 초당 쓰기 요청 수 | 장치 특성에 따라 다름 |
rMB/s | 초당 읽기 데이터량 (MB) | 장치 최대 처리량과 비교 |
wMB/s | 초당 쓰기 데이터량 (MB) | 장치 최대 처리량과 비교 |
r_await | 읽기 요청의 평균 응답 시간 (ms) | HDD: 20ms 이상 주의, SSD: 1ms 이상 주의 |
w_await | 쓰기 요청의 평균 응답 시간 (ms) | r_await와 동일 기준 |
aqu-sz | 평균 I/O 큐 크기 | 1.0 이상이면 디스크가 요청을 소화 못 함 |
%util | 디스크 활용률 | 70% 이상 지속되면 병목, 100%는 포화 |
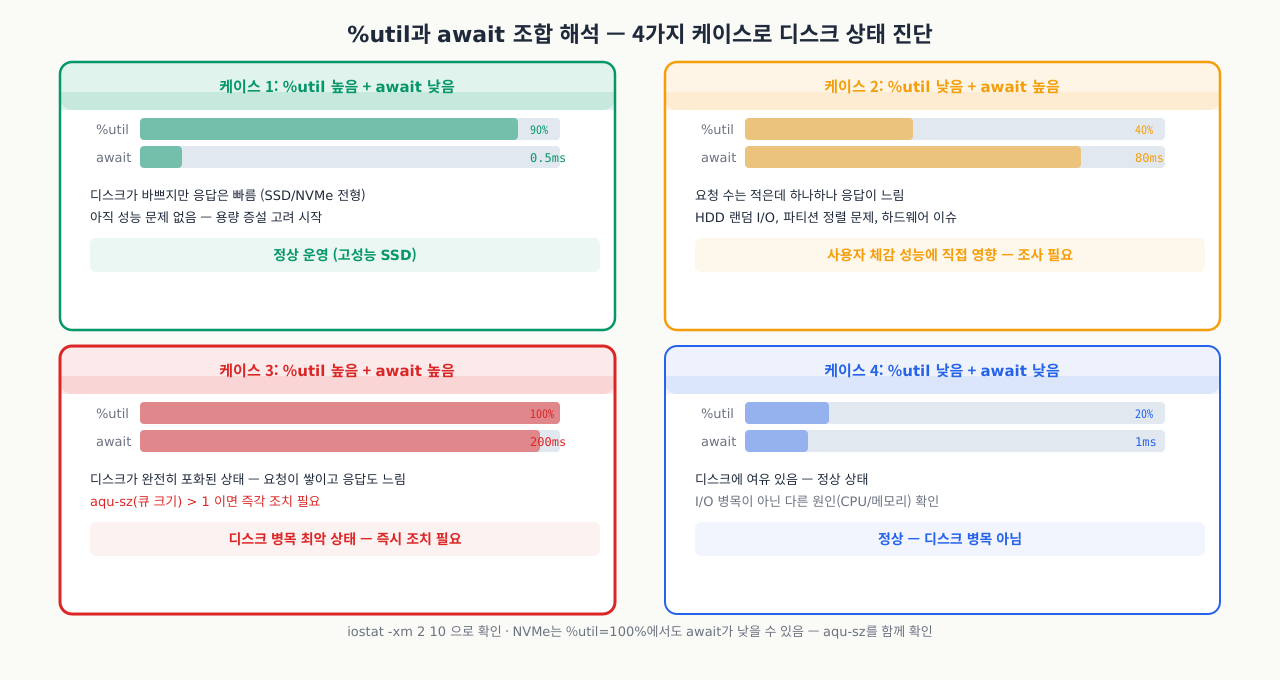
%util과 await의 관계
 확대
확대
iostat -x를 보면 %util이 90%가 넘는데 서버가 빠릅니다. 또 어떤 서버는 %util이 40%인데 I/O 대기 때문에 앱이 느립니다. %util 하나만 보면 오진할 수 있습니다. 실제로는 %util과 await를 함께 봐야 디스크가 얼마나 바쁜지, 그리고 그 바쁨이 실제로 지연을 만드는지를 구분할 수 있습니다.
%util과 await는 함께 해석해야 의미가 있습니다.
케이스 1: %util 높음 + await 낮음
- 디스크가 바쁘지만 응답은 빠름
- SSD나 NVMe에서 흔히 나타남
- 아직 성능상 문제 없음, 하지만 용량 증설을 고려
케이스 2: %util 낮음 + await 높음
- 요청 수는 많지 않은데 하나하나 응답이 느림
- HDD의 랜덤 I/O, 파티션 정렬 문제, 하드웨어 이슈 가능성
- 실제 사용자 체감 성능에 직접 영향
케이스 3: %util 높음 + await 높음 + aqu-sz > 1
- 디스크가 완전히 포화된 상태 (디스크 병목)
- 요청이 쌓이고, 응답도 느려지는 최악의 상황
- 즉시 조치 필요: I/O 패턴 최적화, 디스크 추가, SSD 전환
케이스 4: %util 낮음 + await 낮음
- 정상 상태, 디스크에 여유 있음
NVMe SSD는 병렬 처리 능력이 뛰어나서 %util이 100%에 도달해도 await가 낮을 수 있습니다. 이 경우 aqu-sz(큐 크기)를 함께 봐야 실제 포화 여부를 알 수 있습니다.
실제 운영 환경에서 디스크 병목을 찾는 단계별 과정입니다.
1단계: 전체 디스크 상태 스캔 — 어떤 디스크에서 I/O가 집중되는지 iostat으로 먼저 파악합니다:
# 모든 블록 디바이스의 상태를 2초 간격으로 확인
iostat -xm 2 10
첫 번째 줄은 부팅 이후 전체 평균이므로 무시하고 두 번째 줄부터 분석합니다.
2단계: 문제 디바이스 식별
%util이 70% 이상이거나 await가 기준치를 초과하는 디바이스를 찾습니다.
# 1초 간격으로 util이 높은 장치만 확인
watch -n 1 'iostat -xm 1 2 | grep -v "^$" | tail -n +4'
3단계: 해당 디바이스에 마운트된 파일시스템 확인 — 어느 마운트 포인트가 해당 디스크를 쓰는지 파악합니다:
# 문제 디바이스(예: sda)가 어디에 마운트되어 있는지
lsblk /dev/sda
df -h | grep sda
4단계: iotop으로 I/O 유발 프로세스 확인 — 디스크를 가장 많이 쓰는 프로세스를 실시간으로 확인합니다:
# iotop 설치
sudo apt install iotop
# 실시간 프로세스별 I/O 모니터링
sudo iotop -o # -o: 실제로 I/O 중인 프로세스만 표시
# 배치 모드로 로그 남기기
sudo iotop -b -n 10 -d 2 > /tmp/iotop_$(date +%H%M%S).log
5단계: 해당 프로세스의 I/O 패턴 분석 — strace나 lsof로 어떤 파일에 I/O가 집중되는지 파악합니다:
# PID 1234의 I/O 시스템 콜 추적
sudo strace -e trace=read,write,open,close -p 1234
# 열린 파일 목록
sudo lsof -p 1234 | grep -E "REG|DIR"
실습 스크립트 — 디스크 병목 빠른 진단 — 위 단계를 하나로 묶어 자동 실행하는 진단 스크립트입니다:
#!/bin/bash
echo "=== 디스크 I/O 스냅샷 ==="
echo ""
echo "[iostat 최근 5초 평균]"
iostat -xm 1 5 | tail -n +4 | grep -v "^$"
echo ""
echo "[상위 I/O 프로세스]"
sudo iotop -b -n 1 -d 1 2>/dev/null | head -20
echo ""
echo "[디스크 큐 상태]"
cat /proc/diskstats | awk '{if ($4 > 0 || $8 > 0) print $3, "reads:", $4, "writes:", $8}'
5. sar — 역사 데이터의 보고
sar(System Activity Reporter)는 sysstat의 핵심 도구로, 시간대별 시스템 성능 이력을 수집하고 조회할 수 있습니다. 장애가 발생한 후 그 시점의 데이터를 확인하는 데 필수적입니다.
sar 데이터 수집 설정
# sysstat 서비스 활성화 (데이터 자동 수집)
sudo systemctl enable sysstat
sudo systemctl start sysstat
# 수집 주기 확인 및 변경
cat /etc/cron.d/sysstat
# 기본값: 10분마다 수집
# 데이터 저장 위치
ls /var/log/sysstat/
# sa01, sa02 ... (일자별 파일)
sar 사용법
# CPU 사용률 이력 조회 (오늘)
sar -u
# CPU 사용률 2초 간격 실시간
sar -u 2 10
# 특정 날짜 이력 조회 (sa25 = 25일)
sar -u -f /var/log/sysstat/sa25
# 메모리 이력
sar -r
# 스왑 이력
sar -W
# 디스크 I/O 이력
sar -b
# 네트워크 통계 이력
sar -n DEV
# 모든 통계 한 번에
sar -A | less
sar 출력 예시 — CPU 분석
sar -u -f /var/log/sysstat/sa25 | grep -A 100 "09:0[0-9]"
10:00:01 AM CPU %user %nice %system %iowait %steal %idle
10:10:01 AM all 8.23 0.00 2.14 28.45 0.00 61.18
10:20:01 AM all 12.45 0.00 3.21 35.67 0.00 48.67
10:30:01 AM all 15.23 0.00 4.12 42.33 0.00 38.32
10:40:01 AM all 9.12 0.00 2.45 3.21 0.00 85.22
10:10~10:30 사이에 %iowait가 급등했다가 10:40에 정상화된 패턴을 볼 수 있습니다. 이 시간대에 무슨 일이 있었는지 로그와 대조하면 원인을 찾을 수 있습니다.
sar -n DEV — 네트워크 성능 이력
sar -n DEV 2 5
02:15:01 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
02:15:03 PM eth0 1823.5 2140.2 245.8 892.4 0.0 0.0 0.0 7.1
02:15:05 PM eth0 2910.3 3482.1 398.2 1456.8 0.0 0.0 0.0 11.4
| 필드 | 의미 |
|---|---|
rxpck/s | 초당 수신 패킷 수 |
txpck/s | 초당 송신 패킷 수 |
rxkB/s | 초당 수신 데이터량 (KB) |
txkB/s | 초당 송신 데이터량 (KB) |
%ifutil | 네트워크 인터페이스 활용률 (1Gbps NIC 기준) |
새벽 3시에 장애가 났다는 보고를 받았습니다. 지금은 오전 9시입니다. sar 데이터로 그 시점을 재구성합니다.
1단계: 어젯밤 데이터 파일 확인 — sar가 수집한 데이터 파일 위치를 확인합니다:
# 어제 날짜의 sa 파일 찾기
ls -la /var/log/sysstat/
# 오늘이 26일이면 어제 데이터는 sa25
2단계: 새벽 2~4시 CPU 이력 추출 — sar -u로 문제 시간대의 CPU 사용 패턴을 조회합니다:
sar -u -f /var/log/sysstat/sa25 | awk '
/^[0-2][0-9]:[0-9][0-9]:[0-9][0-9] [AP]M/ {
hour = substr($1, 1, 2)
ampm = $2
if (ampm == "AM" && (hour == "02" || hour == "03" || hour == "04"))
print
}
'
또는 더 간단하게:
sar -u -f /var/log/sysstat/sa25 | grep "^0[234]:"
3단계: 동 시간대 메모리/스왑/I/O 대조 — 같은 시간대의 다른 지표를 비교해 병목 유형을 확정합니다:
# 메모리 상태
sar -r -f /var/log/sysstat/sa25 | grep "^0[234]:"
# 스왑 활동
sar -W -f /var/log/sysstat/sa25 | grep "^0[234]:"
# 디스크 I/O
sar -b -f /var/log/sysstat/sa25 | grep "^0[234]:"
# 네트워크
sar -n DEV -f /var/log/sysstat/sa25 | grep "^0[234]:"
4단계: 타임라인 구성 — CPU/메모리/I/O 이력을 시간 순으로 정리해 근본 원인을 찾습니다:
03:00 AM — CPU iowait 급등 (3% → 45%)
03:10 AM — 디스크 쓰기 I/O 급증 (bo: 50 → 8500)
03:20 AM — 스왑 활동 시작 (so: 0 → 120)
03:30 AM — 서비스 응답 지연 시작 (애플리케이션 로그 대조)
03:50 AM — 부하 자연 감소
04:00 AM — 정상화
5단계: 원인 후보 정리
이 패턴은 대량 배치 쓰기 작업(백업, 로그 로테이션, 데이터 집계)이 I/O를 포화시키고, 그로 인해 메모리 캐시가 밀려나면서 스왑이 활성화된 전형적인 패턴입니다.
# 해당 시간대 크론 작업 확인
grep "03:" /var/log/cron* 2>/dev/null || journalctl -u cron --since "yesterday 02:50" --until "yesterday 04:10"
6. htop 심화 활용
htop은 top의 강화 버전으로, 시각적이고 인터랙티브한 프로세스 모니터링을 제공합니다.
htop 설치 및 실행
sudo apt install htop # Ubuntu/Debian
sudo yum install htop # RHEL/CentOS
htop
htop 주요 기능과 단축키
| 단축키 | 기능 |
|---|---|
F2 | 설정 화면 (컬럼 추가/제거, 색상 테마) |
F3 또는 / | 프로세스 이름 검색 |
F4 | 필터 (특정 문자열 포함 프로세스만) |
F5 | 트리 뷰 (부모-자식 관계) |
F6 | 정렬 기준 선택 |
F9 | 시그널 전송 (kill) |
u | 특정 사용자의 프로세스만 보기 |
H | 스레드 표시/숨기기 |
K | 커널 스레드 표시/숨기기 |
t | 트리 모드 토글 |
Space | 태그 (여러 프로세스 선택) |
I | CPU 정렬 순서 반전 |
htop 헤더 해석
CPU[||||||||||||||||||||| 62.5%]
Mem[||||||||||||||||||||||||||| 7.2G/15.5G]
Swp[ 0K/2.0G]
Tasks: 248, 892 thr; 4 running
Load average: 1.84 2.11 2.45
Uptime: 42 days, 03:15:22
- CPU 막대의 색상: 파란색(낮은 우선순위), 초록색(일반), 빨간색(커널), 노란색(iowait)
- Mem 막대: 초록색(사용 중), 파란색(버퍼), 노란색(캐시) — 캐시+버퍼는 OS가 필요 시 돌려줌
htop에서 유용한 컬럼 추가하기
F2 → Columns에서 추가 가능한 유용한 컬럼:
IO_RATE: 프로세스별 I/O 속도IO_READ_RATE,IO_WRITE_RATE: 읽기/쓰기 분리STARTTIME: 프로세스 시작 시간NLWP: 스레드 수
7. dstat — 종합 실시간 모니터링
dstat은 vmstat, iostat, netstat, ifstat의 기능을 하나로 합친 도구입니다. 한 화면에서 CPU, 디스크, 네트워크, 메모리를 동시에 보고 싶을 때 유용합니다.
sudo apt install dstat
# 기본 실행
dstat
# CPU + 디스크 + 네트워크 + 메모리 + 시스템 통계
dstat -cdnms
# 가장 많은 CPU를 사용하는 프로세스 추가
dstat -cdnms --top-cpu
# 가장 많은 I/O를 사용하는 프로세스 추가
dstat -cdnms --top-io
# 1초 간격으로 CSV 파일에 저장 (분석용)
dstat -cdnms --output /tmp/dstat_$(date +%Y%m%d_%H%M%S).csv 1 60
dstat 출력 해석
----total-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai stl| read writ| recv send| in out | int csw
8 2 88 2 0| 42k 128k| 23k 89k| 0 0 | 312 789
45 8 42 5 0| 120k 1024k| 145k 892k| 0 0 | 845 1230
컬럼 그룹별 색상이 달리 표시되어 가독성이 좋습니다.
8. perf top — CPU 핫스팟 분석
perf는 리눅스 커널에 내장된 성능 분석 도구입니다. CPU가 실제로 어떤 함수를 실행하는 데 시간을 쓰는지 샘플링합니다.
# perf 설치
sudo apt install linux-tools-common linux-tools-$(uname -r)
# 시스템 전체 CPU 핫스팟 (인터랙티브)
sudo perf top
# 특정 프로세스만
sudo perf top -p <PID>
# 10초 동안 샘플링 후 보고서
sudo perf record -g -a sleep 10
sudo perf report
perf top 출력 해석
Overhead Shared Object Symbol
23.45% [kernel] [k] __do_page_fault
18.32% mysqld [.] row_search_mvcc
8.91% [kernel] [k] copy_user_enhanced_fast_string
6.23% python3 [.] PyObject_GenericGetAttr
4.12% [kernel] [k] __softirqentry_text_start
Overhead: 해당 함수에서 소비된 CPU 시간 비율[kernel]: 커널 공간 함수[.]: 사용자 공간 함수- 상위 함수가 특정 애플리케이션에 집중되어 있으면 해당 앱의 코드 최적화 필요
9. mpstat — CPU 코어별 분석
멀티코어 시스템에서 부하가 어느 코어에 집중되어 있는지 확인합니다.
# 모든 코어 상태 2초 간격으로
mpstat -P ALL 2 5
02:20:01 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
02:20:03 PM all 8.23 0.00 2.14 28.45 0.00 0.12 0.00 0.00 0.00 61.06
02:20:03 PM 0 92.00 0.00 5.00 2.00 0.00 0.00 0.00 0.00 0.00 1.00
02:20:03 PM 1 1.00 0.00 1.00 45.00 0.00 0.00 0.00 0.00 0.00 53.00
02:20:03 PM 2 1.50 0.00 1.50 32.00 0.00 0.00 0.00 0.00 0.00 65.00
02:20:03 PM 3 2.00 0.00 1.00 28.00 0.00 0.00 0.00 0.00 0.00 69.00
이 출력에서 CPU 0이 92% usr로 혼자 달리고 있습니다. 단일 스레드 애플리케이션이 CPU 0에 고정되어 있거나, 인터럽트가 CPU 0에 집중된 경우입니다.
# CPU 인터럽트 분포 확인
cat /proc/interrupts | head -30
# IRQ를 여러 CPU에 분산 (예: eth0 인터럽트)
sudo service irqbalance start
10. 실전 트러블슈팅
증상 — load average가 CPU 코어 수를 크게 초과하는 CPU 병목 상황입니다:
uptime
# load average: 8.52, 7.91, 6.43 (4코어 서버)
vmstat 1 3
# r b ... us sy id wa
# 1 7 ... 4 2 55 39
Load Average는 8.5인데 CPU idle은 55%입니다.
원인 분석
Load Average에는 CPU 대기뿐 아니라 D 상태(Uninterruptible Sleep) 프로세스도 포함됩니다. b 값이 7이고 wa가 39%인 것을 보면 7개 프로세스가 I/O를 기다리는 중입니다.
# D 상태 프로세스 확인
ps aux | awk '$8 == "D" {print $0}'
# 더 상세하게
ps -eo pid,stat,comm,wchan | grep "^[0-9]* D"
해결 방법
iostat -x 1 10으로 포화된 디스크 식별iotop -o로 I/O 유발 프로세스 확인- 해당 프로세스가 DB 쿼리라면 슬로우 쿼리 로그 확인
- 해당 프로세스가 백업이라면
ionice로 I/O 우선순위 낮춤
# 백업 프로세스 I/O 우선순위 낮추기
sudo ionice -c 3 -p <PID> # Idle 클래스 (가장 낮은 우선순위)
증상 — free -h에서 available이 감소하고 Swap 사용이 시작되는 메모리 압박 상황입니다:
free -h
# total used free shared buff/cache available
# Mem: 15Gi 4.2Gi 6.8Gi 245Mi 4.1Gi 10.8Gi
# Swap: 2.0Gi 512Mi 1.5Gi
vmstat 1 5
# swpd free ... si so
# 524288 7168000 ... 0 0
메모리 available이 10.8GB인데 스왑이 512MB 사용 중입니다.
원인 분석
리눅스는 메모리가 충분해도 오래된 익명 메모리를 선제적으로 스왑아웃할 수 있습니다. vm.swappiness 설정 때문입니다.
# 현재 swappiness 값 확인
cat /proc/sys/vm/swappiness
# 60 (기본값) — 적극적으로 스왑 사용
# 어떤 프로세스가 스왑을 사용하는지 확인
for pid in $(ls /proc | grep -E '^[0-9]+$'); do
swap=$(awk '/VmSwap/{print $2}' /proc/$pid/status 2>/dev/null)
if [ -n "$swap" ] && [ "$swap" -gt 0 ]; then
comm=$(cat /proc/$pid/comm 2>/dev/null)
echo "$swap KB PID:$pid $comm"
fi
done | sort -rn | head -10
해결 방법 — swappiness를 낮추고 메모리 리크 프로세스를 재시작합니다:
# swappiness를 10으로 낮춤 (메모리가 부족할 때만 스왑 사용)
sudo sysctl vm.swappiness=10
# 영구 설정
echo "vm.swappiness=10" | sudo tee -a /etc/sysctl.conf
# 현재 스왑에서 메모리로 복구 (메모리 여유 있을 때)
sudo swapoff -a && sudo swapon -a
주의:
swapoff -a는 모든 스왑 내용을 메모리로 옮깁니다. 메모리 여유가 충분할 때만 실행하세요.
증상
서비스가 5분에 한 번꼴로 2~3초 지연이 발생합니다. 발생 시점에 모니터링 도구를 실행하면 이미 정상입니다.
접근법: 지속적 수집 후 사후 분석 — 간헐적 이슈는 평소에 수집해두고 발생 후 분석하는 방식이 효과적입니다:
# 10초 간격으로 60분간 vmstat 데이터 수집
vmstat 10 360 > /tmp/vmstat_$(date +%Y%m%d_%H%M).log &
# 5초 간격으로 iostat 수집
iostat -x 5 720 > /tmp/iostat_$(date +%Y%m%d_%H%M).log &
# dstat으로 CSV 수집
dstat -cdnms --output /tmp/dstat_$(date +%Y%m%d_%H%M).csv 5 720 &
echo "수집 PID: $!"
증상 발생 후 데이터 분석:
# vmstat에서 wa 값이 높았던 시점 찾기
awk '$16 > 20 {print NR, $0}' /tmp/vmstat_*.log
# iostat에서 await가 높았던 시점 찾기
awk '$10 > 50 {print NR, $0}' /tmp/iostat_*.log
자동 알림 스크립트 — 부하가 임계치를 초과할 때 슬랙이나 메일로 알림을 보내는 스크립트입니다:
#!/bin/bash
# 임계치 초과 시 로그 남기기
while true; do
iowait=$(vmstat 1 2 | tail -1 | awk '{print $16}')
if [ "$iowait" -gt 20 ]; then
echo "$(date): iowait=$iowait" >> /tmp/alert.log
# 이 시점의 상세 상태 캡처
iostat -x 1 3 >> /tmp/alert_detail.log
iotop -b -n 1 >> /tmp/alert_detail.log 2>/dev/null
fi
sleep 5
done
크론 작업이 원인인 경우 (가장 흔한 케이스) — 새벽 배치 작업이 CPU/I/O를 독점하는 가장 흔한 패턴입니다:
# 5분 단위로 실행되는 크론 확인
crontab -l | grep "*/5"
sudo crontab -l | grep "*/5"
ls /etc/cron.d/
cat /etc/cron.d/*
# 시스템 크론도 확인
grep "*/5" /etc/crontab
10-1. 심화 — 지표가 무엇을 재는지 알아야 안 속는다
심화: %util·load가 거짓말할 때 — 병렬 장치의 포화와 PSI
이 모듈의 핵심 지표인 iostat의 %util과 load average는 오래 믿어 온 포화 신호입니다. 그런데 현대 하드웨어에서는 이 둘이 사람을 속이기 쉽습니다. 각 값이 무엇을 재는지 정확히 알아야 엉뚱한 결론을 피합니다.
- %util은 바쁜 정도가 아니다: iostat의 %util은 표본 구간에서 장치에 처리 중인 요청이 하나라도 있던 시간의 비율입니다. 요청을 하나씩 처리하는 단일 회전 디스크에서는 이게 곧 포화를 뜻했습니다. 하지만 SSD·NVMe·RAID는 수십 개 요청을 동시에 처리하므로, 요청이 끊이지 않기만 하면 여유가 넘쳐도 %util이 100%에 붙습니다. 그래서 NVMe에서 %util 100%를 보고 디스크 포화라 단정하면 틀립니다 — 진짜 신호는 await(요청당 지연)와 aqu-sz(평균 큐 길이), 그리고 실측 처리량이 장치 스펙에 얼마나 근접했는지입니다.
- load average는 뭉뚱그린 값이다: load average는 실행 대기(runnable) 프로세스와 D 상태(I/O 대기) 프로세스를 합쳐 1·5·15분으로 감쇠 평균한 값입니다. 무언가 밀려 있다는 것만 알려줄 뿐, 그것이 CPU인지 디스크인지는 구분해 주지 않습니다(그래서 이 모듈은 vmstat의 r·b·wa로 쪼개 봤습니다).
- 다음 단계 — PSI로 진짜 대기를 직접 재기: 최근 커널은
/proc/pressure/cpu,/proc/pressure/memory,/proc/pressure/io로 압력(Pressure Stall Information)을 제공합니다. 각 자원에서 작업이 그 자원을 기다리느라 멈춘 시간의 비율을 some(하나 이상 멈춤)·full(전부 멈춤)로 직접 보여줍니다. load나 %util처럼 해석이 필요 없이 이 자원 때문에 얼마나 멈췄나를 바로 답해 주므로, 어느 자원이 진짜 병목인지 가릴 때 강력합니다.
정리하면 각 지표는 재는 대상이 정해져 있습니다. %util은 요청이 있었나, await는 얼마나 걸렸나, PSI는 얼마나 멈췄나입니다. 지표가 무엇을 재는지 알면 100%라는 숫자 하나에 속지 않습니다.
상황: DB 서버가 느려 iostat을 보니 데이터 디스크의 %util이 항상 95~100%였습니다. 디스크 포화로 판단해 더 빠른 NVMe로 교체(또는 증설)했는데, 응답 시간이 그대로입니다. %util은 여전히 100%에 붙어 있습니다.
원인: %util이 100%라는 건 장치에 처리 중인 요청이 끊이지 않았다는 뜻일 뿐, 장치가 한계라는 뜻이 아닙니다. NVMe는 요청을 대량으로 병렬 처리하므로 여유가 많아도 %util은 쉽게 100%가 됩니다. 실제로 await(요청당 지연)는 낮고 처리량도 장치 스펙의 일부에 불과했다면, 병목은 디스크 대역폭이 아니라 요청을 내보내는 방식 — 예컨대 트랜잭션마다 동기 fsync로 한 번에 하나씩 순차 대기하는 패턴 — 에 있습니다. 이런 지연은 디스크를 아무리 빠른 걸로 바꿔도 거의 줄지 않습니다.
진단: %util 대신 다른 값을 봅니다 — iostat -x의 await·r_await·w_await가 실제로 큰지(크면 장치 지연, 작으면 장치는 한가), aqu-sz(평균 큐 길이)가 장치의 병렬성 대비 낮은지, 그리고 실측 처리량(rkB/s·wkB/s)이 장치 스펙에 근접했는지. await가 낮고 처리량이 스펙보다 한참 아래인데 %util만 100%면 디스크는 범인이 아닙니다. /proc/pressure/io의 full 비율이 낮으면 I/O로 멈춘 시간이 적다는 뜻이라 이 판단을 뒷받침합니다.
해결: 병목이 대역폭이 아니라 요청 패턴이므로, 개별 요청 지연을 줄이거나 병렬성을 올립니다 — DB라면 커밋을 묶는 그룹 커밋, fsync 빈도 조정, 비동기·배치 쓰기, 커넥션/워커 수 조정입니다. 하드웨어를 바꾸기 전에 항상 await·처리량·PSI로 장치가 실제로 한계인지를 먼저 확인합니다. %util 100%는 조사의 시작이지 결론이 아닙니다.
11. 성능 장애 30초 체크리스트
장애 신고를 받은 즉시, 30초 안에 방향을 잡는 명령어 시퀀스입니다. 이 순서를 외워 두세요.
[0~5초] 전체 조감 — uptime과 w 명령으로 시스템 부하와 접속 사용자를 먼저 파악합니다:
uptime
# load average 확인: 코어 수 대비 몇 배인지
[5~15초] CPU / 메모리 / I/O 한눈 보기 — vmstat 1회 실행으로 CPU/메모리/스왑/I/O 지표를 동시에 확인합니다:
vmstat 1 5
# r(런큐), b(I/O대기), si/so(스왑), wa(iowait) 확인
[15~20초] 상위 프로세스 확인 — top의 스냅샷을 찍어 CPU/메모리를 많이 쓰는 프로세스를 찾습니다:
# CPU 탑 프로세스
ps aux --sort=-%cpu | head -10
# 메모리 탑 프로세스
ps aux --sort=-%mem | head -10
[20~25초] 디스크 상태 (wa가 높거나 b가 높을 때) — vmstat에서 wa(IO wait)가 높으면 디스크 병목을 의심합니다:
iostat -xm 1 3 | grep -v "^$"
[25~30초] 메모리 상세 (si/so가 있을 때) — vmstat에서 si/so가 있으면 Swap 압박이 진행 중입니다:
free -h
결과에 따른 다음 단계 — 관찰 결과별로 어떤 명령어로 심화 분석해야 하는지 안내합니다:
| 관찰 | 다음 명령어 |
|---|---|
r > 코어수, us+sy > 80% | top, mpstat -P ALL, perf top |
b > 2, wa > 20% | iostat -x 1 10, iotop -o |
si > 0 또는 so > 0 | free -h, swapon -s, 스왑 프로세스 찾기 |
| CPU/메모리/디스크 모두 정상 | sar -n DEV, ss -s, 네트워크 확인 |
| 모두 정상인데 느림 | 애플리케이션 로그, DB 슬로우 쿼리, 외부 API 지연 |
매일 아침 어젯밤 시스템 성능 요약을 이메일로 받거나 파일로 저장하는 스크립트입니다.
#!/bin/bash
# /usr/local/bin/daily-perf-report.sh
REPORT_DATE=$(date -d "yesterday" +%Y%m%d)
SA_FILE="/var/log/sysstat/sa$(date -d yesterday +%d)"
REPORT_FILE="/var/log/perf-reports/report_${REPORT_DATE}.txt"
mkdir -p /var/log/perf-reports
cat > "$REPORT_FILE" <<EOF
===================================================
시스템 성능 일간 리포트: $REPORT_DATE
===================================================
[서버 정보]
호스트명: $(hostname)
CPU 코어: $(nproc)개
메모리: $(free -h | awk '/Mem/{print $2}')
[CPU 사용률 요약]
EOF
sar -u -f "$SA_FILE" | tail -3 >> "$REPORT_FILE"
cat >> "$REPORT_FILE" <<EOF
[피크 iowait 시간대 (상위 5개)]
EOF
sar -u -f "$SA_FILE" | awk 'NF==10 && $6+0 > 5 {print $6, $0}' | sort -rn | head -5 | awk '{$1=""; print}' >> "$REPORT_FILE"
cat >> "$REPORT_FILE" <<EOF
[메모리 사용률 요약]
EOF
sar -r -f "$SA_FILE" | tail -3 >> "$REPORT_FILE"
cat >> "$REPORT_FILE" <<EOF
[스왑 활동 (0이 아닌 경우만)]
EOF
sar -W -f "$SA_FILE" | awk 'NF==5 && ($3+0 > 0 || $4+0 > 0) {print}' >> "$REPORT_FILE"
echo "" >> "$REPORT_FILE"
echo "리포트 생성 완료: $(date)" >> "$REPORT_FILE"
echo "리포트 저장 위치: $REPORT_FILE"
cat "$REPORT_FILE"
크론 등록:
chmod +x /usr/local/bin/daily-perf-report.sh
echo "30 8 * * * root /usr/local/bin/daily-perf-report.sh" | sudo tee /etc/cron.d/daily-perf-report
12. 실무 적용 — 직업별 맥락
개발자가 운영팀에 "서버가 느려요"라고만 말하면 문제 해결이 늦어집니다. 직접 1차 진단을 해서 구체적인 정보를 전달하면 해결 속도가 10배 빨라집니다.
상황: API 응답이 500ms를 초과하는 경우 — 응답 지연 원인을 CPU/메모리/I/O/네트워크 순으로 좁혀갑니다:
# 1. 내 서비스 프로세스의 CPU 사용량 확인
ps aux | grep "node\|python\|java\|go" | grep -v grep
# 2. 내 서비스의 PID 찾기
PID=$(pgrep -f "node server.js")
# 3. 해당 PID의 실시간 리소스 사용
top -p $PID
# 4. 해당 PID의 I/O 확인
sudo iotop -p $PID -b -n 5
# 5. 열린 파일 디스크립터 수 (너무 많으면 누수)
ls /proc/$PID/fd | wc -l
# 6. 스레드 수 확인 (스레드 폭발 확인)
ls /proc/$PID/task | wc -l
내 서비스 관점에서 병목을 좁힌 후 DBA나 인프라팀에 구체적인 수치를 제시합니다.
"API 응답이 느립니다"가 아니라 "PID 1234(node 서버)가 iowait 35%로 디스크 대기 중이며, 쿼리 실행 중 대용량 파일 읽기가 발생하는 것 같습니다"라고 말할 수 있게 됩니다.
PagerDuty나 Alertmanager 알람이 울렸을 때의 표준 대응 절차입니다.
알람 유형별 즉시 실행 명령어 — 모니터링 알람 종류에 따라 처음 실행해야 할 명령어 모음입니다:
# 알람: CPU 사용률 > 90% 지속
vmstat 1 10
mpstat -P ALL 1 5
ps aux --sort=-%cpu | head -15
# 알람: 메모리 사용률 > 90%
free -h
vmstat -S M 1 5 | awk '{print $3, $4, $5, $6, $7, $8}' # swpd si so
ps aux --sort=-%mem | head -10
# 알람: 디스크 I/O 지연 > 100ms
iostat -xm 1 10
sudo iotop -o -b -n 5
# 알람: Load Average > 코어수*2
uptime
vmstat 1 5
ps aux | awk '$8 == "D" {print $0}' | head -20
런북(Runbook) 기록 형식
장애 대응 후 반드시 다음을 기록합니다:
## 장애 일시
2026-03-26 03:14 KST
## 증상
API 평균 응답 시간 450ms → 8200ms
## 초동 진단 (vmstat)
- r=2, b=6, wa=42%, si=0, so=0
- Load Average: 12.4 / 10.8 / 8.2 (8코어 서버)
## 원인
- iostat: /dev/sdb %util=98%, await=185ms
- iotop: mysqld가 I/O 1위 (2.3 GB/s 쓰기)
- 원인: 집계 쿼리가 임시 테이블 생성으로 대량 디스크 쓰기
## 조치
- 해당 쿼리 KILL
- 인덱스 추가 계획 수립
## 재발 방지
- MySQL slow query log 설정
- 집계 쿼리를 읽기 전용 레플리카로 라우팅
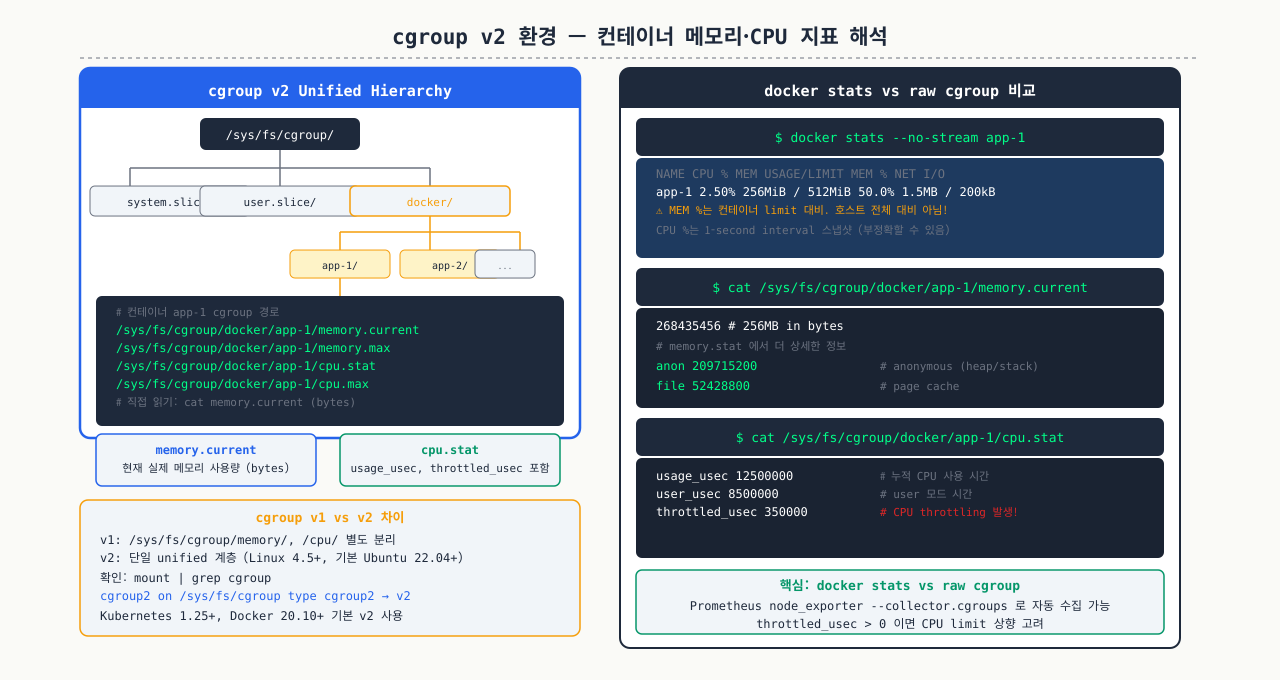
cgroup v2 환경 — 컨테이너 메모리·CPU 지표 해석
 확대
확대
쿠버네티스 파드가 OOM Kill로 재시작되는데 노드에서 free를 실행하면 메모리가 충분해 보입니다. 컨테이너 안에서 free를 실행해도 마찬가지로 노드 전체 메모리를 보여줍니다. 컨테이너에 설정된 memory limit은 free에 반영되지 않기 때문입니다. 실제 컨테이너가 limit에 얼마나 가까운지는 cgroup 파일을 직접 읽어야 알 수 있으며, 이 값이 limit에 근접하면 OOM Kill이 발생합니다.
컨테이너(Docker/Kubernetes) 환경에서는 free, top, vmstat가 호스트 전체 값을 보여줍니다. 컨테이너 단위 지표를 보려면 cgroup 파일을 직접 읽어야 합니다.
cgroup v1 vs v2 구분 — cgroup 버전에 따라 컨테이너 리소스 제한을 확인하는 경로가 다릅니다:
# cgroup 버전 확인
mount | grep cgroup
# cgroup2 on /sys/fs/cgroup type cgroup2 ← v2 (RHEL 9, Ubuntu 22.04+)
# cgroup on /sys/fs/cgroup/memory type cgroup ← v1
# 또는
stat -f /sys/fs/cgroup | grep "Type"
# Type: tmpfs ← v1 혼합 마운트
# Type: cgroup2fs ← 순수 v2
cgroup v2에서 컨테이너 메모리 확인 — cgroup v2 파일시스템 경로로 컨테이너 메모리 한도와 사용량을 봅니다:
# Docker 컨테이너의 cgroup 경로 찾기
CONTAINER_ID=<컨테이너ID>
CGROUP_PATH="/sys/fs/cgroup/system.slice/docker-${CONTAINER_ID}.scope"
# 현재 메모리 사용량
cat "${CGROUP_PATH}/memory.current" # bytes
# 메모리 제한 (limits.memory)
cat "${CGROUP_PATH}/memory.max" # bytes (또는 "max" = 무제한)
# 메모리 통계 상세
cat "${CGROUP_PATH}/memory.stat" | grep -E "anon|file|slab"
Kubernetes 컨테이너 지표 — kubectl top과 describe로 pod 레벨의 리소스 사용량을 확인합니다:
# kubectl top (metrics-server 필요)
kubectl top pods -n production
kubectl top nodes
# 특정 Pod의 컨테이너별 메모리 제한 확인
kubectl describe pod <pod-name> | grep -A3 "Limits\|Requests"
# 컨테이너 내부에서 가용 메모리 확인 (호스트 free와 다름)
# /sys/fs/cgroup/memory.max를 읽는 것이 정확
cat /sys/fs/cgroup/memory.max
"호스트 free"와 "컨테이너 available"이 다른 이유 — 컨테이너는 cgroup 한도를 기준으로 메모리를 계산하므로 호스트 free와 다릅니다:
호스트 free: 16GB → 실제 물리 메모리 여유
컨테이너 memory.max: 512MB → 이 컨테이너가 쓸 수 있는 최대치
컨테이너 관점에서 "메모리 부족"은 memory.max 초과가 기준
호스트 관점에서 "메모리 부족"은 전체 물리 메모리 고갈이 기준
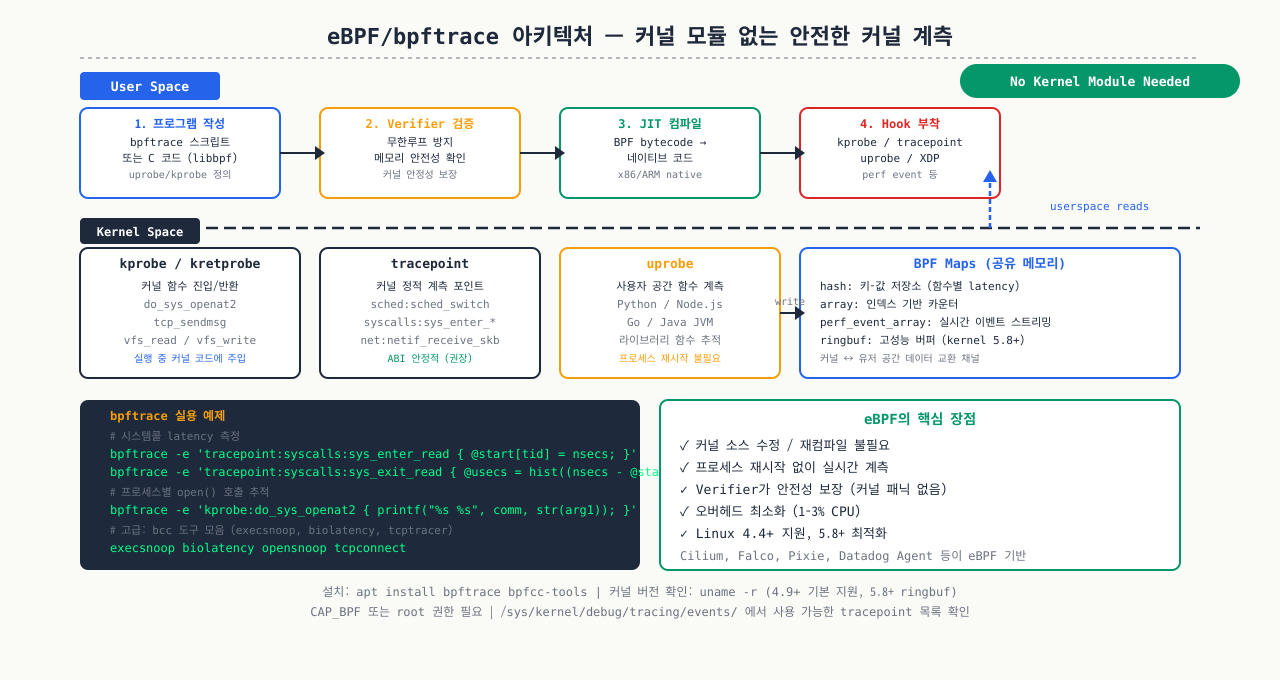
eBPF/bpftrace 입문 — 현대 리눅스 성능 분석
 확대
확대
strace로 시스템 콜을 추적하면 오버헤드가 너무 커서 프로덕션에서 쓸 수 없습니다. 커널 소스를 수정하고 재컴파일하는 건 더 현실적이지 않습니다. eBPF는 커널 내부에 "미니 프로그램"을 안전하게 삽입해서, 프로덕션에서도 성능 영향 없이 실시간으로 시스템 콜, 함수 진입/종료, 네트워크 패킷을 추적할 수 있게 합니다. Brendan Gregg의 flamegraph가 이 기술 위에 만들어졌고, Netflix, Meta, Google의 프로덕션 성능 분석이 eBPF로 돌아갑니다.
eBPF(extended Berkeley Packet Filter)는 커널 코드 수정 없이 커널 내부를 관찰할 수 있는 현대 리눅스 성능 분석의 표준입니다.
설치 및 기본 도구 — BCC/bpftrace 도구를 설치합니다:
# bpftrace 설치
sudo apt install bpftrace # Ubuntu 20.04+
sudo dnf install bpftrace # RHEL 8+
# BCC 도구 모음 (더 많은 사전 작성 스크립트)
sudo apt install bpfcc-tools # Ubuntu
sudo dnf install bcc-tools # RHEL
실무에서 자주 쓰는 eBPF 기반 명령 — 레이턴시, 함수 추적, 파일 I/O 등을 커널 레벨에서 실시간으로 관찰합니다:
# 1. execsnoop — 모든 프로세스 실행 추적 (무엇이 실행되나?)
sudo execsnoop-bpfcc
# PCOMM PID PPID RET ARGS
# bash 12345 1234 0 /bin/bash
# 2. opensnoop — 파일 오픈 추적 (어떤 파일을 열고 있나?)
sudo opensnoop-bpfcc -p $(pgrep nginx)
# 3. tcpconnect — TCP 연결 추적
sudo tcpconnect-bpfcc
# PID COMM IP SADDR DADDR DPORT
# 4. biolatency — 디스크 I/O 지연 히스토그램
sudo biolatency-bpfcc
bpftrace 원라이너 예제 — 한 줄짜리 bpftrace 스크립트로 시스템 콜과 레이턴시를 추적합니다:
# 프로세스별 시스템 콜 빈도
sudo bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
# 특정 파일 읽기 추적
sudo bpftrace -e 'kprobe:vfs_read { printf("%s: %s\n", comm, str(arg0)); }'
# TCP 연결 지연 측정
sudo bpftrace -e 'kprobe:tcp_connect { @start[tid] = nsecs; }
kretprobe:tcp_connect { @latency = hist(nsecs - @start[tid]); delete(@start[tid]); }'
주의: eBPF는 커널 5.x+ 환경에서 완전 지원. RHEL 8(커널 4.18)은 일부 기능 제한. 프로덕션에서 장시간 실행 시 약간의 성능 오버헤드가 있으므로 진단 후 즉시 중단하세요.
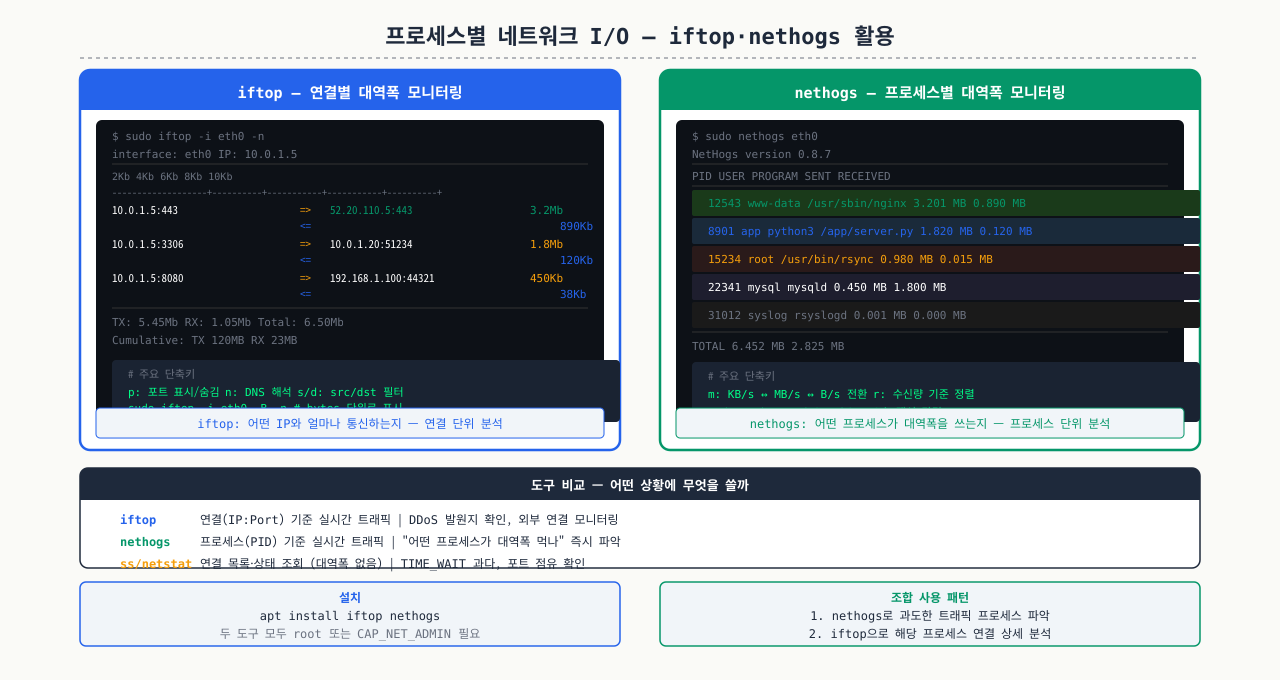
프로세스별 네트워크 I/O — iftop·nethogs 활용
 확대
확대
vmstat, iostat으로는 어떤 프로세스가 네트워크 대역폭을 차지하는지 알 수 없습니다.
# nethogs — 프로세스별 실시간 네트워크 사용량 (가장 직관적)
sudo apt install nethogs # 또는 sudo dnf install nethogs
sudo nethogs eth0
# PID USER PROGRAM DEV SENT RECEIVED
# 1234 www nginx eth0 1.2MB 45.3MB
# iftop — 연결 단위 실시간 대역폭
sudo apt install iftop
sudo iftop -i eth0 # 인터페이스 지정
sudo iftop -i eth0 -n # IP 주소로 표시 (DNS 조회 없음, 속도 향상)
# 조작: q=종료, n=이름조회토글, s=소스만, d=목적지만
# ss로 프로세스별 연결 확인 (nethogs 없을 때)
sudo ss -tnp | grep -v LISTEN
# ESTAB 0 0 192.168.1.100:45678 10.0.0.1:443 users:(("curl",pid=1234,...))
사용 시 주의 (권한/오버헤드) — eBPF 도구는 오버헤드가 있으므로 프로덕션에서는 제한적으로 사용합니다:
| 도구 | 필요 권한 | 오버헤드 | 비고 |
|---|---|---|---|
| nethogs | root | 낮음 | PID와 네트워크 연결 매핑 필요 |
| iftop | root | 낮음 | promiscuous mode 사용 시 오버헤드 큼 |
| tcpdump | root | 중간~높음 | 캡처 파일 크기 제한 필수 (-G, -W) |
13. 핵심 명령어 빠른 참조표
| 목적 | 명령어 | 핵심 확인 포인트 |
|---|---|---|
| 전체 조감 | vmstat 1 10 | r, b, si, so, wa |
| CPU 코어별 분석 | mpstat -P ALL 2 5 | 특정 코어 집중 여부 |
| 디스크 성능 | iostat -xm 2 5 | %util, await, aqu-sz |
| 프로세스별 I/O | iotop -o | 상위 I/O 프로세스 |
| 이력 데이터 | sar -u / -r / -b | 장애 시점 소급 분석 |
| 네트워크 이력 | sar -n DEV 2 5 | %ifutil, rxkB/s |
| CPU 핫스팟 | perf top | 어떤 함수가 CPU 소비 |
| 종합 실시간 | dstat -cdnms --top-cpu | 한 화면에서 전체 |
| Load 분석 | uptime + nproc | Load/코어 비율 |
마무리
시스템 모니터링의 핵심은 도구를 많이 아는 것이 아니라 순서를 지키는 것입니다. 어떤 장애 상황에서도 CPU → 메모리 → 디스크 → 네트워크 순으로 좁혀가면 대부분의 병목을 30초~2분 안에 찾을 수 있습니다.
vmstat의 wa 필드 하나만 제대로 읽어도 I/O 병목을 즉시 진단할 수 있고, sar의 이력 데이터를 활용하면 이미 지나간 장애도 재구성할 수 있습니다. 이 도구들을 반복 실습하면서 각 필드가 어떤 상황에서 변하는지 몸으로 익히는 것이 가장 중요합니다.
관련 모듈로 더 깊이:
- 서버 다운 시 신속하게 CPU/메모리/네트워크/로그 확인하는 룰 — 모니터링으로 이상을 발견한 뒤 장애 원인을 빠르게 좁히는 절차
- OOM Killer 방지를 위한 Swap 메모리 파티션 튜닝 — vmstat의 메모리·스왑 필드를 더 깊이 해석하는 법
- Prometheus & Node Exporter 연동으로 실시간 대시보드 구축 — 실시간 지표를 시계열로 수집해 장기 추이로 만드는 다음 단계
다음 모듈에서는 Prometheus와 Node Exporter를 연동해 시스템 메트릭을 시계열로 수집하고 Grafana 대시보드로 장기 추이를 시각화하는 방법을 다룹니다.