새벽 2시, 모니터링 알람이 울립니다. "메모리 사용률 95%". 서버에 급히 접속해 free -h를 실행했더니 used가 높고 free는 거의 없습니다. 그런데 available은 아직 여유가 있습니다. 진짜 위기인지 아닌지 판단이 서지 않습니다. 그 사이 OOM Killer가 조용히 핵심 프로세스를 종료해버렸고, 서비스는 아무 에러 없이 그냥 멈춰있습니다. free -h의 숫자를 읽는 법과 OOM Killer가 무엇을 죽일지를 미리 알았다면 위기를 조기에 차단할 수 있었을 겁니다.
메모리 관리 & Swap
새벽 2시, 모니터링 알람이 울립니다. "메모리 사용률 95%". 심장이 빨라집니다. 지금 당장 서버가 죽을까요? 아니면 그냥 지켜봐도 될까요?
정답은 **"알람만으로는 알 수 없다"**입니다. Linux 메모리 관리는 OS가 남는 메모리를 캐시로 적극 활용하기 때문에, 95%라는 숫자가 진짜 위기인지 아닌지를 판단하려면 free, vmstat, OOM Killer 동작 원리를 알아야 합니다.
이 챕터를 마치면 메모리 알람이 와도 5분 안에 진짜 위기 여부를 판단하고, 필요시 즉시 조치할 수 있습니다.
- 1가상 메모리와 물리 메모리 구조를 이해하고 MMU 매핑 원리를 설명할 수 있다
- 2free -h 출력에서 used/free/available/buff-cache 차이를 해석할 수 있다
- 3vmstat으로 swap in/out을 실시간 모니터링하고 스래싱을 감지할 수 있다
- 4OOM Killer 동작 원리를 이해하고 oom_score 기반 프로세스 선택 메커니즘을 예측할 수 있다
- 5swapfile을 생성·활성화하고 vm.swappiness를 튜닝할 수 있다
- 6Hugepages 개념을 이해하고 대용량 메모리 환경에서 성능을 최적화할 수 있다
free -h && vmstat 1 3swapon --show && cat /proc/meminfo | grep -E 'MemTotal|MemFree|MemAvailable|SwapTotal|SwapFree'sudo dmesg | grep -i 'oom\|killed' | tail -20스왑 파일 생성 실습은 root 권한이 필요합니다. 클라우드 VM의 경우 /swapfile 경로에 여유 공간(최소 2GB)을 확보해 두세요.
가상 메모리와 물리 메모리 구조
 확대
확대
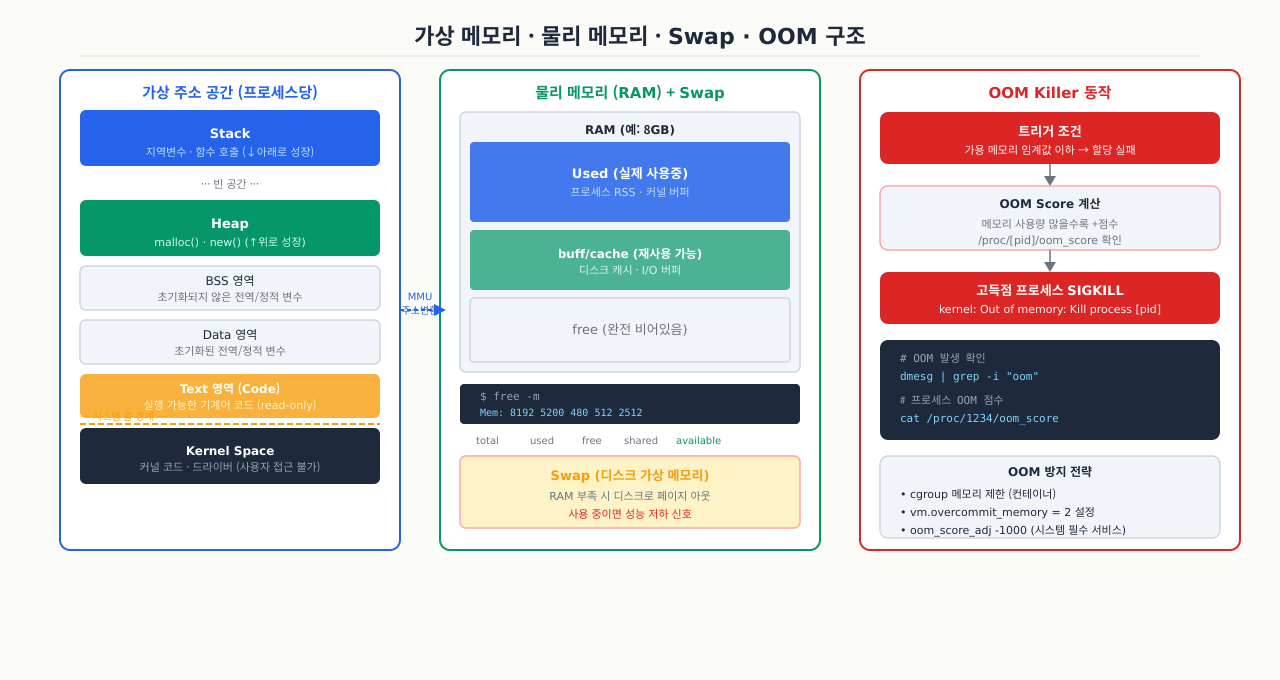
free -h로 메모리를 봤더니 "used"가 90%인데, 실제로 서버가 느리지는 않습니다. "buff/cache"가 대부분을 차지하고 있어서 실제 메모리가 부족한 게 아닙니다. 반대로 "available"이 충분한 것 같은데 프로세스가 OOM으로 죽는 경우도 있습니다. 이런 상황이 혼란스러운 이유는 Linux 메모리 관리가 눈에 보이는 것과 실제 동작 방식이 다르기 때문입니다. 가상 주소 공간, 물리 메모리, 스왑이 어떻게 나뉘어서 동작하는지를 이해하면 free, top, vmstat 출력을 제대로 읽을 수 있습니다.
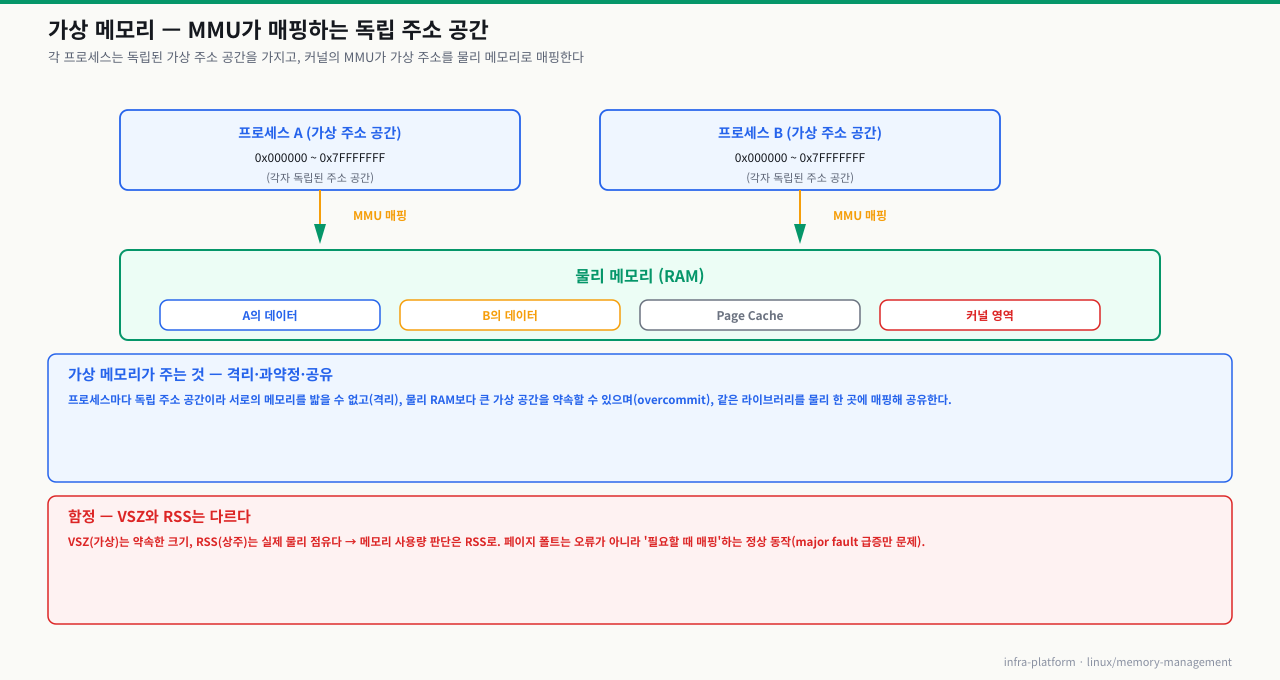
Linux의 메모리 관리를 이해하려면 가상 메모리(Virtual Memory) 와 물리 메모리(Physical Memory) 의 분리 개념부터 시작해야 합니다.
물리 메모리 (RAM)
실제 하드웨어에 꽂혀 있는 메모리 칩입니다. CPU가 직접 접근할 수 있는 유일한 저장소입니다. 용량은 고정되어 있으며, 서버에 따라 수 GB에서 수 TB까지 다양합니다.
가상 메모리 (Virtual Memory)
각 프로세스에게 자신만의 독립된 메모리 공간이 있는 것처럼 보이게 해주는 추상화 계층입니다. 커널의 MMU(Memory Management Unit)가 가상 주소와 물리 주소 간 매핑을 관리합니다.
 확대
확대
Page와 Page Table
메모리는 Page 단위(보통 4KB)로 관리됩니다. 커널은 각 프로세스마다 Page Table 을 유지하며, 가상 주소를 물리 주소로 변환합니다.
Page Cache와 Buffer — 가장 중요한 개념
Linux 커널은 남는 물리 메모리를 절대 놀리지 않습니다. 디스크에서 읽은 파일 데이터는 Page Cache 에 저장해두고, 같은 파일을 다시 읽을 때 디스크 접근 없이 메모리에서 바로 반환합니다.
| 종류 | 역할 | 특징 |
|---|---|---|
| Page Cache | 파일 시스템 데이터 캐시 | 읽기/쓰기 모두 캐시. 메모리 부족 시 커널이 자동으로 해제 |
| Buffer Cache | 블록 디바이스 메타데이터 캐시 | 파일 시스템 메타데이터(슈퍼블록, inode 등) |
| Anonymous Memory | 프로세스의 실제 데이터 | 힙, 스택 — 커널이 임의로 해제 불가 |
핵심: Page Cache와 Buffer는 "쓸 수 있는 여분"이지 "사용 중인 메모리"가 아닙니다. 메모리가 부족해지면 커널이 이 캐시를 자동으로 반환하여 프로세스에게 할당합니다. 그래서 free 출력에서 used가 높아도 available이 크다면 실제 위기가 아닐 수 있습니다.
Demand Paging
프로세스가 메모리를 요청해도 커널은 실제로 바로 물리 메모리를 할당하지 않습니다. 실제로 해당 주소에 접근하는 순간 Page Fault가 발생하고, 그때 물리 메모리를 할당합니다. 이를 Demand Paging이라 합니다. 덕분에 메모리를 효율적으로 사용할 수 있지만, 처음 접근 시 약간의 지연이 발생합니다.
OOM Killer — 커널의 마지막 수단
 확대
확대
새벽에 프로덕션 Java 서비스가 갑자기 죽었습니다. systemctl status를 보면 "Killed"이고, dmesg에는 Out of memory: Kill process 12345 (java) score 824 or sacrifice child라는 로그가 찍혀 있습니다. 아무도 수동으로 죽인 게 아닌데 프로세스가 사라진 이 상황의 주범이 OOM Killer입니다. 커널이 메모리 고갈 상황에서 어떤 기준으로 프로세스를 선택해서 죽이는지 알면, score를 낮춰 특정 프로세스를 보호하거나 재발 방지 대책을 세울 수 있습니다.
물리 메모리가 완전히 고갈되면 커널은 OOM(Out of Memory) Killer 를 작동시킵니다. OOM Killer는 "지금 가장 희생해도 덜 아픈 프로세스"를 골라 강제로 kill합니다.
OOM Killer 발동 조건
- 물리 메모리 + Swap 공간이 모두 소진
- 페이지 할당 요청을 처리할 수 없는 상태
- 메모리 회수를 시도했지만 충분하지 않은 경우
OOM Score 계산 방식
각 프로세스는 /proc/<PID>/oom_score 값을 가집니다. 점수가 높을수록 OOM Killer에게 먼저 희생됩니다.
OOM Score 높을수록 Kill 대상 1순위
계산 요소:
- 프로세스가 사용 중인 메모리 크기 (클수록 점수 높음)
- 실행 시간 (짧을수록 점수 높음 — 오래된 프로세스 보호)
- root 프로세스 여부 (root이면 점수 낮춤)
- oom_score_adj 보정값 (-1000 ~ +1000)
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/linux/part5/exam_25 && cd /tmp/linux/part5/exam_25
# 메모리 사용량 시뮬레이션 스크립트 생성
cat > mem_hog.sh << 'EOF'
#!/bin/bash
# 메모리를 점진적으로 소비하는 테스트 스크립트
DATA=""
for i in $(seq 1 50); do
DATA="${DATA}$(head -c 1048576 /dev/urandom | base64)"
echo "Allocated ~${i}MB — free: $(free -m | awk '/^Mem:/{print $4}')MB"
sleep 1
done
EOF
chmod +x mem_hog.sh
이제 실습을 진행합니다.
oom_score_adj로 프로세스 보호
특정 프로세스를 OOM Killer로부터 보호하거나 반대로 먼저 kill되게 설정할 수 있습니다.
# 값 범위: -1000 (절대 kill 안 함) ~ +1000 (가장 먼저 kill)
# 기본값: 0
# 현재 OOM score 확인
cat /proc/1234/oom_score
# 출력: 450
# OOM score 보정값 확인
cat /proc/1234/oom_score_adj
# 출력: 0
# 중요한 프로세스 보호 (-1000이면 OOM Killer가 절대 선택 안 함)
echo -1000 > /proc/$(pgrep nginx)/oom_score_adj
# systemd 서비스로 영구 설정 (서비스 파일에 추가)
# [Service]
# OOMScoreAdjust=-500
OOM Kill은 증상이지 원인이 아닙니다. OOM Killer가 발동했다면 근본 원인(메모리 누수, 과부하, 부족한 RAM)을 반드시 찾아야 합니다.
 확대
확대
메모리를 달라고 하면 물리 RAM에 담기기까지 — 요청부터 OOM까지 5단계
프로세스가 malloc으로 1GB를 잡아도 그 순간엔 물리 메모리가 거의 안 줄고, 한참 뒤 데이터를 채울 때가 되어서야 부족해지는 걸 본 적이 있을 겁니다. "메모리를 요청했다"와 "물리 RAM을 실제로 썼다"는 같은 사건이 아니기 때문입니다. 요청이 실제 물리 프레임으로 바뀌고, 부족할 때 캐시 회수·스왑·OOM으로 이어지는 이 한 줄기 흐름을 알면 free·vmstat·dmesg의 숫자가 지금 어느 단계인지 짚을 수 있습니다.
프로세스: p = malloc(1GB)
│
① 가상 주소만 예약 (VSZ↑, 물리 프레임 0, RSS 그대로)
│
② 첫 접근 → page fault (커널이 물리 프레임 1장 매핑 = demand paging, RSS↑)
│
── 물리 RAM 여유 있나? ── 예 → 그대로 사용
│ 아니오
③ 페이지 캐시부터 회수 (clean file page 반환 = buff/cache↓, 아직 무해)
│
④ 그래도 부족 → 스왑 아웃 (anon 페이지를 디스크로 → si/so 발생, 심하면 thrashing)
│
⑤ 스왑까지 고갈 → OOM Killer (oom_score 최고 프로세스에 SIGKILL)
▼
dmesg: "Out of memory: Killed process 8432 (java)"
각 단계에서 무슨 일이 일어나고, 어긋나면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 어긋나면 (증상) |
|---|---|---|
| ① 가상 예약 | malloc·mmap이 가상 주소 공간에 영역만 확보하고 물리 프레임은 주지 않음 — 오버커밋이라 물리 RAM보다 큰 예약도 성공 | top의 VSZ만 크고 RSS는 작음. VSZ를 실사용량으로 오해하면 진단이 틀어짐 |
| ② page fault 매핑 | 그 주소에 처음 접근하는 순간 fault → 커널이 물리 프레임을 할당·매핑(demand paging). 이때부터 RSS 증가 | 지연 할당이라 malloc은 성공해도 나중에 실제로 채울 때 뒤늦게 메모리 부족이 드러남 |
| ③ 페이지 캐시 회수 | RAM이 차면 커널이 먼저 회수 가능한 페이지 캐시(clean file page)를 반환. free의 buff/cache가 available로 잡히는 이유 | used가 높아도 available이 크면 위기 아님 — used만 보고 놀라면 오탐(캐시는 메모리 아님) |
| ④ 스왑 아웃 | 캐시로도 부족하면 anonymous 페이지(힙·스택)를 디스크 스왑으로 밀어냄. vm.swappiness가 적극성 결정 | swap in·out 반복 = thrashing. vmstat의 si/so가 지속적으로 크면 디스크 왕복으로 서버가 사실상 마비 |
| ⑤ OOM Killer | 스왑까지 고갈되면 oom_score(메모리 점유 + oom_score_adj) 최고 프로세스를 골라 SIGKILL | 핵심 프로세스가 조용히 종료 — 보호하려면 oom_score_adj를 낮춰 표적에서 뺌 |
즉 "메모리 부족"은 한 순간이 아니라 ③→④→⑤로 단계적으로 악화됩니다 — 캐시 회수(무해) → 스왑(느려짐) → OOM(프로세스 사망). 그래서 free의 available과 vmstat의 si/so를 함께 보면 지금 어느 단계인지 짚을 수 있습니다: available이 넉넉하면 ③ 이전(안전), si/so가 튀기 시작하면 ④(주의), dmesg에 oom 로그가 있으면 ⑤(이미 사망)입니다. used 수치 하나만으로 판단하지 않는 이유가 여기 있습니다.
기본 도구 실습
free는 메모리 현황을 보여주는 가장 기본적인 명령입니다. -h 옵션은 사람이 읽기 좋은 단위(GB, MB)로 출력합니다.
free -h
출력 예시 — free -h 명령의 실제 출력 형태입니다:
total used free shared buff/cache available
Mem: 15Gi 4.2Gi 312Mi 245Mi 10Gi 10Gi
Swap: 2.0Gi 128Mi 1.9Gi
각 컬럼 완전 해석 — total/used/free/shared/buff/cache/available 각 컬럼의 의미와 실무 판단 기준입니다:
| 컬럼 | 의미 | 실무 판단 포인트 |
|---|---|---|
total | 설치된 물리 메모리 총량 | 서버 스펙 확인용 |
used | 실제 사용 중인 메모리 (total - free - buff/cache) | 단독으로 보면 오해 가능 |
free | 완전히 비어있는 메모리 | 이게 작아도 OK — available이 중요 |
shared | tmpfs 등 공유 메모리 | 컨테이너 환경에서 주목 |
buff/cache | Page Cache + Buffer Cache | OS가 쓰는 캐시 — 언제든 반환 가능 |
available | 진짜 사용 가능한 메모리 | 이 값이 핵심 지표 |
available 계산 방식 (근사치) — available은 free+buff/cache의 단순 합이 아닌 커널이 계산한 실제 사용 가능량입니다:
available ≈ free + (buff/cache 중 회수 가능한 부분)
위 예시에서: used가 4.2Gi이지만 available이 10Gi — 실제로는 메모리 여유가 충분합니다.
위험 신호 패턴 — available이 임계치 이하이거나 Swap이 급증할 때 즉시 조치가 필요합니다:
# 위험한 상태: available이 거의 없고 swap 사용률 높음
total used free shared buff/cache available
Mem: 15Gi 14Gi 156Mi 1.2Gi 842Mi 198Mi
Swap: 2.0Gi 1.8Gi 245Mi
# 안전한 상태: used가 높아도 available이 충분
total used free shared buff/cache available
Mem: 15Gi 12Gi 289Mi 198Mi 2.8Gi 3.1Gi
Swap: 2.0Gi 0B 2.0Gi
실시간 모니터링 — free -s 옵션으로 메모리 상태를 주기적으로 갱신해 추이를 봅니다:
# 2초마다 갱신
free -h -s 2
# watch와 함께 사용
watch -n 1 free -h
- free -h 출력에서 'available' 컬럼이 'free'보다 훨씬 높게 나타난다 (buff/cache 공간이 회수 가능하기 때문)
- vmstat 1 5 에서 si(swap in)와 so(swap out)가 모두 0에 가까우면 메모리 상태가 정상이다
- OOM 발생 후 dmesg | grep -i 'oom\|killed' 에서 어떤 프로세스가 종료됐는지 확인된다
- cat /proc/meminfo | grep MemAvailable 값이 free -h 의 available 컬럼과 일치한다
vmstat은 가상 메모리, CPU, I/O 통계를 시계열로 보여줍니다. 특히 si(swap in)과 so(swap out) 필드로 Swap 활동을 직접 관찰할 수 있습니다.
# 1초 간격으로 10번 출력
vmstat 1 10
출력 예시 (정상 상태) — /proc/meminfo에서 Swap 사용이 없고 available이 충분한 상태입니다:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 131072 318452 89344 9876544 0 0 12 45 345 892 8 2 89 1 0
0 0 131072 315688 89344 9878912 0 0 0 32 312 845 5 1 93 1 0
0 0 131072 314200 89344 9880128 0 0 0 16 298 801 3 1 95 1 0
출력 예시 (Swap 사용 중인 위험 상태) — SwapUsed가 0이 아니고 available이 작아지는 경고 상황입니다:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 2 1843200 45000 12000 234000 245 512 1245 890 2341 4521 45 15 25 15 0
4 3 1890000 38000 11000 221000 312 689 1689 1123 3012 5234 52 18 15 15 0
2 4 1934000 29000 10000 198000 189 423 2341 1456 3456 6012 48 22 10 20 0
핵심 필드 해설 — /proc/meminfo의 주요 필드와 위험 기준을 정리했습니다:
| 필드 | 의미 | 위험 기준 |
|---|---|---|
r | 실행 대기 중인 프로세스 수 | CPU 코어 수보다 지속적으로 많으면 병목 |
b | 블록된 프로세스 수 (I/O 대기) | 지속적으로 0보다 크면 I/O 병목 |
swpd | 사용 중인 Swap 크기 (KB) | 0이 이상적. 증가 추세이면 주목 |
free | 사용 가능한 메모리 (KB) | 단독으로 판단 금지 |
si | Swap In (KB/s) — 디스크→RAM | 지속적으로 0보다 크면 심각 |
so | Swap Out (KB/s) — RAM→디스크 | 지속적으로 0보다 크면 심각 |
bi | 블록 디바이스 읽기 (blocks/s) | 높으면 디스크 I/O 부하 |
bo | 블록 디바이스 쓰기 (blocks/s) | 높으면 디스크 I/O 부하 |
wa | I/O 대기 CPU 시간 (%) | 지속적으로 20% 이상이면 I/O 병목 |
Swap In/Out이 지속적으로 발생한다는 것의 의미:
- RAM이 실제로 부족해서 프로세스 데이터를 디스크로 밀어냄 (swap out)
- 나중에 그 데이터가 다시 필요해져서 디스크에서 RAM으로 불러옴 (swap in)
- 디스크는 RAM보다 100배 이상 느리므로 성능이 급격히 저하됨
- 이 상태를 Thrashing 이라 하며, 서버가 사실상 마비된 것과 같음
클라우드 서버는 종종 Swap 파티션 없이 배포됩니다. 운영 중에도 Swap 공간을 추가할 수 있습니다.
현재 Swap 상태 확인 — 현재 Swap 파티션 또는 파일의 크기와 사용량을 확인합니다:
swapon --show
# 출력 (swap이 있는 경우):
# NAME TYPE SIZE USED PRIO
# /dev/sda2 partition 2G 128M -2
# /swapfile file 2G 0B -3
# 출력 (swap이 없는 경우):
# (아무것도 출력되지 않음)
# 또는
cat /proc/swaps
# Filename Type Size Used Priority
# /dev/sda2 partition 2097148 131072 -2
Swapfile 생성 (권장 방식) — 파티션 없이 파일로 Swap 영역을 추가하는 현장 표준 방법입니다:
# 1. 2GB swapfile 생성 (dd 방식 — 더 안전)
sudo dd if=/dev/zero of=/swapfile bs=1M count=2048 status=progress
# 2048+0 records in
# 2048+0 records out
# 2147483648 bytes (2.1 GB, 2.0 GiB) copied, 8.432 s, 255 MB/s
# 또는 fallocate 방식 (더 빠르지만 일부 파일시스템에서 문제 가능)
sudo fallocate -l 2G /swapfile
# 2. 권한 설정 (반드시 필요 — 다른 사용자가 읽으면 보안 위험)
sudo chmod 600 /swapfile
# 3. Swap 포맷
sudo mkswap /swapfile
# Setting up swapspace version 1, size = 2 GiB (2147479552 bytes)
# no label, UUID=a3f0d1c2-4b5e-4f2a-8d3c-1e2f3a4b5c6d
# 4. Swap 활성화
sudo swapon /swapfile
# 5. 확인
swapon --show
# NAME TYPE SIZE USED PRIO
# /swapfile file 2G 0B -2
free -h
# total used free shared buff/cache available
# Mem: 15Gi 4.2Gi 312Mi 245Mi 10Gi 10Gi
# Swap: 2.0Gi 0B 2.0Gi
재부팅 후에도 유지되게 /etc/fstab에 등록 — Swapfile을 영구적으로 활성화하려면 fstab에 등록해야 합니다:
# 현재 /etc/fstab 확인
cat /etc/fstab
# fstab에 추가
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
# 확인
grep swap /etc/fstab
# /swapfile none swap sw 0 0
Swap 비활성화 (일시적) — 테스트나 성능 측정을 위해 Swap을 임시로 끕니다:
# 특정 swap 비활성화
sudo swapoff /swapfile
# 모든 swap 비활성화
sudo swapoff -a
swappiness 조정 — 얼마나 적극적으로 Swap을 쓸 것인가 — 값이 낮을수록 Swap을 덜 쓰고 RAM을 더 활용합니다:
# 현재 swappiness 확인 (기본값: 60)
cat /proc/sys/vm/swappiness
# 60
# 0: swap을 최대한 안 씀 (메모리 부족할 때만)
# 100: 적극적으로 swap 사용
# 서버 환경에서는 10~20 권장
sudo sysctl vm.swappiness=10
# 영구 설정
echo 'vm.swappiness=10' | sudo tee -a /etc/sysctl.d/99-memory.conf
sudo sysctl -p /etc/sysctl.d/99-memory.conf
OOM Killer가 발동했다면 반드시 로그를 확인하고 원인을 분석해야 합니다.
OOM 로그 위치 — OOM Killer가 작동했을 때 어떤 로그 파일에 기록이 남는지 확인합니다:
# RHEL/CentOS/AlmaLinux (journald 사용 시스템)
sudo journalctl -k | grep -i "oom\|killed process\|out of memory"
# 또는 /var/log/messages (rsyslog 사용 시스템)
sudo grep -i "oom\|killed process\|out of memory" /var/log/messages
# 최근 커널 메시지에서 확인
sudo dmesg | grep -i "oom\|killed"
실제 OOM 로그 예시 — OOM Killer가 프로세스를 종료할 때 남기는 실제 커널 로그 형태입니다:
Mar 26 02:14:33 prod-server kernel: java invoked oom-killer: gfp_mask=0x201da, order=0, oom_score_adj=0
Mar 26 02:14:33 prod-server kernel: java cpuset=/ mems_allowed=0
Mar 26 02:14:33 prod-server kernel: CPU: 3 PID: 8432 Comm: java Not tainted 5.14.0-570 #1
Mar 26 02:14:33 prod-server kernel: Mem-Info:
Mar 26 02:14:33 prod-server kernel: active_anon:3891234 inactive_anon:234512 isolated_anon:0
Mar 26 02:14:33 prod-server kernel: active_file:1234 inactive_file:890 isolated_file:0
Mar 26 02:14:33 prod-server kernel: unevictable:0 dirty:45 writeback:12 unstable:0
Mar 26 02:14:33 prod-server kernel: Node 0 DMA free:15360kB min:128kB low:160kB high:192kB
Mar 26 02:14:33 prod-server kernel: [ pid ] uid tainted total_vm rss pgtables_bytes swapents oom_score_adj name
Mar 26 02:14:33 prod-server kernel: [ 8432] 1001 0 4194304 3891234 32768000 524288 0 java
Mar 26 02:14:33 prod-server kernel: [ 9012] 1001 0 524288 412345 4096000 0 0 python3
Mar 26 02:14:33 prod-server kernel: [ 1234] 0 0 102400 89012 1024000 0 -1000 nginx
Mar 26 02:14:33 prod-server kernel: Out of memory: Killed process 8432 (java) total-vm:16777216kB, anon-rss:15564936kB, file-rss:0kB, shmem-rss:0kB, UID:1001
Mar 26 02:14:33 prod-server kernel: oom_reaper: reaped process 8432 (java), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
로그 해석 포인트:
java invoked oom-killer— java 프로세스가 메모리 할당을 요청하다가 OOM 조건 촉발anon-rss:15564936kB— java가 약 15GB의 익명 메모리를 사용 중이었음 (힙 등)Killed process 8432 (java)— java 프로세스가 최종 선택되어 kill됨nginx의oom_score_adj: -1000— nginx는 보호 설정이 되어 있어 선택되지 않음
OOM score 직접 확인 — OOM Killer가 어떤 프로세스를 먼저 죽일지 결정하는 점수를 봅니다:
# 모든 프로세스의 OOM score 확인 (높은 순)
for pid in $(ls /proc | grep '^[0-9]'); do
if [ -f /proc/$pid/oom_score ]; then
score=$(cat /proc/$pid/oom_score 2>/dev/null)
comm=$(cat /proc/$pid/comm 2>/dev/null)
echo "$score $pid $comm"
fi
done | sort -rn | head -20
# 출력 예시:
# 812 8432 java
# 456 9012 python3
# 312 7891 node
# 123 1234 mysqld
# 0 234 nginx
Page Cache 수동 해제
메모리 압박 상황에서 커널이 자동으로 캐시를 해제하지만, 테스트나 긴급 상황에서 수동으로 해제할 수 있습니다.
# /proc/sys/vm/drop_caches 값의 의미:
# 1 = PageCache만 해제
# 2 = dentries와 inodes 해제
# 3 = PageCache + dentries + inodes 모두 해제
# 실행 전 sync (디스크에 데이터 flush 필수!)
sync
# 캐시 해제
echo 3 | sudo tee /proc/sys/vm/drop_caches
# 출력: 3
# 해제 전후 비교
free -h
# total used free shared buff/cache available
# Mem: 15Gi 4.2Gi 312Mi 245Mi 10Gi 10Gi ← 해제 전
# (해제 후)
# Mem: 15Gi 4.1Gi 9.8Gi 245Mi 189Mi 10Gi ← 해제 후
주의: 프로덕션 서버에서 drop_caches를 실행하면 이후 디스크 I/O가 급증합니다. 캐시가 사라졌으므로 모든 파일 접근이 디스크에서 새로 읽어야 하기 때문입니다. 실제 메모리 부족 상황에서는 커널이 알아서 처리합니다.
메모리 병목 진단 순서 — 체크리스트 — 메모리 부족 의심 시 단계별로 원인을 좁혀가는 순서입니다:
# Step 1: available 메모리 확인
free -h
# → available이 총 RAM의 10% 미만이면 주의
# Step 2: Swap 활성 여부 확인
swapon --show
vmstat 1 5
# → si/so가 지속적으로 0보다 크면 실제 메모리 부족
# Step 3: 메모리를 많이 쓰는 프로세스 파악
ps aux --sort=-%mem | head -15
# 출력 예시:
# USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
# webapp 8432 12.3 78.4 16777216 12582912 ? Sl 01:00 234:12 java -Xmx12g
# mysql 1234 2.1 8.9 2097152 1425408 ? Sl Jan01 45:23 mysqld
# www-data 9012 0.3 3.2 524288 512000 ? S 02:00 1:23 python3 app.py
# Step 4: 특정 프로세스의 메모리 상세 분석
cat /proc/8432/status | grep -i vm
# VmPeak: 16777216 kB (최대 가상 메모리)
# VmSize: 16777216 kB (현재 가상 메모리)
# VmRSS: 12582912 kB (실제 물리 메모리 사용량 ← 핵심)
# VmSwap: 524288 kB (swap에 있는 양)
# Step 5: OOM 발생 이력 확인
sudo journalctl -k --since "1 hour ago" | grep -i oom
# Step 6: 메모리 누수 의심 프로세스 추적
# (일정 시간 간격으로 RSS 변화 관찰)
watch -n 5 'ps aux --sort=-%mem | head -10'
smem으로 실제 메모리 사용량 측정 (더 정확) — PSS 기준으로 공유 메모리를 按比例 분배해 프로세스별 실제 사용량을 측정합니다:
# smem 설치
sudo dnf install smem -y # RHEL계열
sudo apt install smem -y # Debian계열
# 프로세스별 실제 메모리 사용량 (PSS 기준 — 공유 메모리 정확 계산)
smem -r -k | head -20
# PID User Command Swap USS PSS RSS
# 8432 webapp java -Xmx12g -jar app.jar 512M 11.8G 11.9G 12.1G
# 1234 mysql mysqld 0 1.3G 1.4G 1.5G
Hugepages 기초
Hugepages — 대용량 메모리 성능 최적화
 확대
확대
PostgreSQL 서버에 메모리를 128GB 달았는데 vmstat을 보면 si(swap in)가 간헐적으로 발생하고 쿼리 레이턴시가 불규칙하게 튑니다. 메모리가 충분한데도 성능이 나쁜 이유로 DBA가 "Hugepages 설정 안 됐으면 TLB 미스 때문에 성능이 나빠질 수 있다"고 합니다. 대용량 메모리를 쓰는 DB나 JVM 환경에서는 기본 4KB 페이지 수백만 개를 관리하는 주소 변환 오버헤드가 실제 처리 성능에 영향을 줍니다. Hugepages로 페이지 크기를 늘리면 TLB 미스 횟수 자체를 줄여 이 오버헤드를 제거합니다.
기본 Page 크기는 4KB입니다. 수십 GB의 메모리를 사용하는 데이터베이스나 Java 애플리케이션은 수백만 개의 Page를 관리하게 되고, 이로 인해 TLB(Translation Lookaside Buffer) 미스가 빈번히 발생하여 성능이 저하됩니다.
Hugepages 는 이 문제를 Page 크기를 크게 키워서 해결합니다.
Hugepages 종류 — 2MB Static Hugepage와 자동 관리되는 Transparent Hugepage의 차이점입니다:
| 종류 | 크기 | 특징 | 사용 사례 |
|---|---|---|---|
| Standard Page | 4KB | 기본값 | 일반 용도 |
| Hugepages | 2MB (x86_64) | 정적 할당, 미리 예약 | Oracle DB, 고성능 Java |
| Transparent Hugepages (THP) | 2MB | 커널이 자동 관리 | 기본 활성화 — 일부 앱은 비활성화 권장 |
| Gigantic Pages | 1GB | 매우 큰 페이지 | HPC, 특수 용도 |
Transparent Hugepages (THP) 확인 — THP가 활성화 상태인지 확인하고 DB 등 특정 워크로드에서는 비활성화합니다:
# THP 상태 확인
cat /sys/kernel/mm/transparent_hugepage/enabled
# [always] madvise never
# → always: 기본 활성화 (권장하지 않는 경우: Redis, MongoDB, Elasticsearch)
# THP 비활성화 (Redis, MongoDB 등에서 권장)
echo never | sudo tee /sys/kernel/mm/transparent_hugepage/enabled
# 영구 설정 (grub 커널 파라미터에 transparent_hugepage=never 추가)
# 또는 rc.local/systemd 서비스로 설정
Static Hugepages 설정 — Redis, Oracle DB 같은 고성능 앱에 Static Hugepage를 할당합니다:
# 현재 hugepages 상태 확인
cat /proc/meminfo | grep -i huge
# AnonHugePages: 614400 kB (THP가 사용 중인 크기)
# ShmemHugePages: 0 kB
# HugePages_Total: 0 (정적 hugepages 총 개수)
# HugePages_Free: 0 (사용 가능한 hugepages)
# HugePages_Rsvd: 0 (예약된 hugepages)
# HugePages_Surp: 0 (초과 할당)
# Hugepagesize: 2048 kB (hugepage 하나의 크기: 2MB)
# 정적 hugepages 할당 (예: 512개 = 1GB)
echo 512 | sudo tee /proc/sys/vm/nr_hugepages
# 영구 설정
echo 'vm.nr_hugepages=512' | sudo tee -a /etc/sysctl.d/99-hugepages.conf
sudo sysctl -p /etc/sysctl.d/99-hugepages.conf
실무 참고: Oracle Database, PostgreSQL(shared_buffers 설정 시), Java 애플리케이션(JVM -XX:+UseHugeTLBFS)에서 hugepages를 활용하면 수% ~ 수십%의 성능 향상을 얻을 수 있습니다. 단, 미리 예약하는 메모리는 다른 용도로 사용 불가하므로 실제 필요량을 정확히 계산해야 합니다.
 확대
확대
장애 대응 시나리오
새벽에 메모리 95% 알람이 왔습니다. 모니터링 시스템의 메트릭은 used / total = 0.95입니다. 패닉하지 말고 다음 순서로 확인합니다.
Step 1: available 메모리 확인 (30초) — available 수치로 실제 여유 메모리를 먼저 파악합니다:
free -h
시나리오 A — 사실은 괜찮은 상황 — buff/cache가 크더라도 available이 충분하면 실제 문제가 아닙니다:
total used free shared buff/cache available
Mem: 15Gi 14Gi 312Mi 245Mi 4.5Gi 5.1Gi
Swap: 2.0Gi 0B 2.0Gi
해석: used는 14Gi(93%)지만 available이 5.1Gi(34%)이고, Swap 사용량이 0. buff/cache가 4.5Gi인데, 이것이 available에 포함됩니다. 서비스에 영향 없음. 모니터링 시스템이 used/total로 계산한 오탐(False Alarm)입니다.
→ 조치: 모니터링 알람 기준을 available < X GB 또는 available/total < 10%로 수정
시나리오 B — 진짜 위기 — available이 200MB 이하이고 Swap si/so가 빠르게 증가하는 실제 위기 상황입니다:
total used free shared buff/cache available
Mem: 15Gi 14Gi 89Mi 1.2Gi 842Mi 156Mi
Swap: 2.0Gi 1.8Gi 245Mi
해석: available이 156Mi(1%)이고, Swap 1.8Gi 사용 중. 즉각 조치 필요.
Step 2: Swap 활동 확인 (1분) — vmstat로 si/so(swap in/out) 속도를 측정해 Swap 압박 여부를 판단합니다:
vmstat 1 5
# si/so 컬럼이 지속적으로 100 이상이면 thrashing 상태
Step 3: 주범 프로세스 파악 — RSS 사용량이 가장 큰 프로세스를 찾아 원인을 특정합니다:
ps aux --sort=-%mem | head -10
즉시 조치 옵션 (시나리오 B) — 메모리 위기 상황에서 즉각 실행할 수 있는 응급 처치 방법입니다:
# 옵션 1: 메모리 누수 의심 프로세스 재시작 (서비스 재시작이 안전한 경우)
sudo systemctl restart suspected-service
# 옵션 2: 불필요한 프로세스 종료
kill -15 <PID> # SIGTERM 먼저
# 옵션 3: Page Cache 강제 해제 (임시방편 — 근본 해결 아님)
sync && echo 3 | sudo tee /proc/sys/vm/drop_caches
# 옵션 4: 추가 swap 즉시 생성
sudo dd if=/dev/zero of=/swapfile2 bs=1M count=2048 status=progress
sudo chmod 600 /swapfile2
sudo mkswap /swapfile2
sudo swapon /swapfile2
결론: 메모리 알람이 와도 available과 si/so를 먼저 확인하면 진짜 위기인지 3분 내로 판단할 수 있습니다.
systemctl status 확인 시 Java 서비스가 계속 재시작(restart loop)되고 있습니다.
증상 확인 — 서비스 상태와 OOM 로그를 확인해 메모리 부족 여부를 파악합니다:
# 서비스 상태 확인
sudo systemctl status myapp.service
# ● myapp.service - My Java Application
# Loaded: loaded (/etc/systemd/system/myapp.service; enabled)
# Active: activating (start) since Thu 2026-03-26 02:15:01 KST; 2s ago
# (restarting repeatedly)
# 최근 로그 확인
sudo journalctl -u myapp.service -n 50 --no-pager
# OOM 로그 확인
sudo journalctl -k | grep -i "oom\|killed process" | tail -20
# Mar 26 02:14:33 server kernel: Out of memory: Killed process 8432 (java) total-vm:16777216kB, anon-rss:15564936kB
원인 분석 — JVM 힙 설정과 메모리 사용 추이를 분석해 원인을 특정합니다:
# JVM 힙 설정 확인
ps aux | grep java
# webapp 8432 12.3 78.4 16777216 12582912 ... java -Xmx14g -jar myapp.jar
# → -Xmx14g: JVM 힙 최대 14GB. 서버 RAM이 15GB면 OS + 다른 프로세스 몫 없음
# 메모리 사용 추이 확인 (메모리 누수 여부)
# 재시작 직후부터 RSS 모니터링
watch -n 10 'ps aux | grep java | grep -v grep | awk "{print \$6/1024 \" MB\"}"'
# 5분마다 RSS가 꾸준히 증가한다면 메모리 누수
조치 — 메모리 리크 프로세스를 재시작하고 설정을 강화합니다:
# 1. JVM 힙 사이즈 조정 (서버 RAM의 70~75% 이내 권장)
# /etc/systemd/system/myapp.service 편집
# ExecStart=/usr/bin/java -Xms2g -Xmx10g -jar /opt/myapp/myapp.jar
# 2. OOM 보호 설정 (재시작 중에도 다른 서비스 보호)
echo -500 > /proc/$(pgrep java)/oom_score_adj
# 3. systemd OOMScoreAdjust 영구 설정
# [Service] 섹션에 추가:
# OOMScoreAdjust=-500
# 4. GC 로그 활성화로 메모리 패턴 분석
# ExecStart=/usr/bin/java -Xmx10g \
# -Xlog:gc*:file=/var/log/myapp/gc.log:time,uptime:filecount=5,filesize=20m \
# -jar /opt/myapp/myapp.jar
sudo systemctl daemon-reload
sudo systemctl restart myapp.service
vmstat 1을 보니 si와 so가 수백 KB/s 이상으로 지속됩니다. 서버 응답이 매우 느립니다.
상태 확인 — Swap 고갈 증상과 현재 Swap 사용 상태를 확인합니다:
vmstat 1
# procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
# r b swpd free buff cache si so bi bo in cs us sy id wa st
# 5 4 1843200 23000 4000 34000 456 823 2341 1890 5234 8932 32 22 5 41 0
# 6 5 1901000 18000 3500 29000 512 934 2891 2123 6123 9845 28 25 3 44 0
# 4 6 1956000 14000 2800 22000 389 712 3012 2456 7012 11234 25 28 2 45 0
해석:
si/so지속적으로 수백 이상 → 심각한 Swap I/Owa41~45% → CPU가 I/O를 기다리며 낭비b(블록된 프로세스) 증가 추세- 이 상태는 Thrashing — 서버가 데이터를 RAM↔Swap 간 계속 이동시키느라 실제 작업을 거의 못 함
즉각 대응 — Swap이 가득 찼을 때 즉시 실행하는 긴급 대응 절차입니다:
# Step 1: 가장 많은 메모리를 쓰는 프로세스 확인
ps aux --sort=-%mem | head -10
# Step 2: 비핵심 프로세스 종료로 메모리 확보
# (로그 수집기, 모니터링 에이전트 등 임시 중단 가능)
sudo systemctl stop filebeat # 로그 수집기
sudo systemctl stop node_exporter # 모니터링 에이전트
# Step 3: 즉시 메모리 확보
sync && echo 3 | sudo tee /proc/sys/vm/drop_caches
# Step 4: vmstat 재확인 (si/so 감소 여부)
vmstat 1 5
# Step 5: 여전히 thrashing이면 주요 원인 프로세스에 SIGTERM
kill -15 <PID>
# Step 6: Swap 추가 (이미 Swap이 있어도 추가 가능)
sudo fallocate -l 4G /swapfile_emergency
sudo chmod 600 /swapfile_emergency
sudo mkswap /swapfile_emergency
sudo swapon /swapfile_emergency
근본 해결 (안정화 후):
- RAM 증설 검토
- 프로세스별 메모리 한도 설정 (cgroups, systemd
MemoryMax) - 애플리케이션 메모리 누수 코드 리뷰
- Swap이 없었다면 적절한 크기의 Swap 구성 (RAM의 1~2배, 최대 8GB)
심화 — 큰 서버에서는 '메모리가 남아도' 스왑한다
심화: NUMA — 메모리는 노드별로 나뉘어 있고, 한쪽만 고갈될 수 있다
지금까지는 물리 메모리를 하나의 큰 풀로 봤습니다. 하지만 소켓이 2개 이상인 서버(대형 DB·JVM 호스트)에서는 이 그림이 깨집니다. free의 available은 넉넉한데 특정 프로세스만 스왑하며 느려지는 기묘한 상황이 여기서 나옵니다.
- 메모리는 CPU 소켓별로 쪼개져 있습니다(NUMA 노드): 각 CPU 소켓은 자기 옆에 붙은 로컬 메모리(노드)를 가장 빠르게 접근하고, 다른 소켓의 메모리(원격 노드)는 인터커넥트를 건너가 더 느리게 접근합니다.
numactl --hardware로 노드별 용량과 거리(distance)를 볼 수 있습니다. - 커널은 기본적으로 '가까운 노드'에 먼저 할당합니다: 프로세스가 실행 중인 소켓의 로컬 노드에서 메모리를 얻으려 합니다(로컬리티 최적화). 그래서 한 노드에 큰 프로세스가 몰리면, 전체 RAM은 절반이 비어 있어도 그 노드만 먼저 고갈됩니다.
vm.zone_reclaim_mode가 함정을 만듭니다: 이 값이 켜져 있으면 로컬 노드가 부족할 때 원격 노드에서 빌리는 대신 로컬의 페이지 캐시를 회수하거나 스왑을 시도합니다. 그 결과 '전체는 여유, 한 노드는 스왑'이 됩니다. 대부분의 서버 워크로드에서는 0(끔)이 권장됩니다.- 관측은 free가 아니라 numastat으로:
free·/proc/meminfo는 노드를 합산해 보여주므로 불균형이 보이지 않습니다.numastat -m이나/proc/<pid>/numa_maps로 노드별 사용량을 봐야 원인이 드러납니다.
즉 대형 서버에서 '메모리는 남는데 느리다'는 대개 총량이 아니라 배치(placement) 문제입니다. 해결의 방향은 총량 증설이 아니라, 프로세스를 노드에 맞게 배치하거나(interleave/바인딩) zone_reclaim을 끄는 쪽입니다.
상황: 2소켓 서버(총 256GB)에서 특정 DB 프로세스만 간헐적으로 느려지고 vmstat에 si/so가 찍힙니다. 그런데 free -h의 available은 100GB가 넘게 남아 있어, '메모리 부족'이라는 진단이 앞뒤가 안 맞습니다.
원인: 메모리가 NUMA 노드로 나뉜 서버에서, 이 프로세스가 한 노드(node 0)에 묶여 실행되며 그 노드의 로컬 메모리를 거의 다 썼습니다. vm.zone_reclaim_mode가 켜져 있어, 커널이 여유 있는 node 1에서 빌려오는 대신 node 0의 페이지를 스왑으로 밀어냈습니다. 총량(available)은 다른 노드의 여유까지 합산한 값이라 넉넉해 보였던 것입니다.
진단: 노드별 사용량을 직접 봅니다.
numactl --hardware
# available: 2 nodes (0-1)
# node 0 size: 128000 MB node 0 free: 900 MB ← 거의 고갈
# node 1 size: 128000 MB node 1 free: 110000 MB ← 여유
numastat -m | grep -iE 'MemFree|MemUsed'
cat /proc/sys/vm/zone_reclaim_mode
# 1 ← 켜져 있으면 로컬 회수(스왑)를 유발
node 0 free만 바닥이고 zone_reclaim_mode가 1이면 확정입니다.
해결: 즉시로는 sudo sysctl vm.zone_reclaim_mode=0으로 로컬 회수를 꺼, 부족한 노드가 원격 노드에서 빌리도록 바꿉니다(재발 방지로 /etc/sysctl.d/에 영구화). 구조적으로는 큰 프로세스를 한 노드에 몰지 말고 numactl --interleave=all로 노드에 분산 배치하거나, DB의 공유 버퍼 크기를 노드 용량 안에 맞춥니다. 총 RAM 증설은 배치 문제를 못 고치므로 마지막 선택지입니다(프로세스 관리와 작업 제어에서 프로세스의 CPU·노드 친화도를 함께 봅니다).
실무 맥락
실제 온콜(On-call) 상황에서 메모리 알람이 왔을 때의 표준 대응 절차입니다.
알람 유형과 의미 — 모니터링 시스템에서 오는 메모리 관련 알람과 즉시 조치 필요 여부입니다:
| 알람 | 의미 | 즉시 조치 필요 |
|---|---|---|
memory.used_percent > 80% | 모니터링 시스템이 잘못 설정된 경우 많음 | Available 확인 후 판단 |
memory.available < 500MB | 실제 가용 메모리 부족 | 즉시 조사 |
swap.used > 0 | Swap 사용 시작 | vmstat으로 si/so 확인 |
swap.used_percent > 50% | Swap 절반 이상 사용 | 높은 우선순위로 대응 |
oom_kill_total 증가 | OOM Kill 발생 | 즉시 로그 확인, 프로세스 재시작 원인 파악 |
온콜 5분 대응 스크립트 — 새벽에 메모리 알람을 받았을 때 5분 안에 상황을 파악하는 스크립트입니다:
#!/bin/bash
# memory_oncall_check.sh — 메모리 알람 수신 시 즉시 실행
echo "=== $(date) 메모리 현황 ==="
free -h
echo ""
echo "=== Swap 활동 (5초) ==="
vmstat 1 5
echo ""
echo "=== 메모리 Top 10 프로세스 ==="
ps aux --sort=-%mem | head -11
echo ""
echo "=== 최근 OOM 이벤트 ==="
journalctl -k --since "1 hour ago" | grep -i "oom\|killed process" | tail -5
echo ""
echo "=== 시스템 uptime과 load ==="
uptime
모니터링 알람 기준 개선 권고 — free 기준 대신 available 기준으로 알람을 설정하는 Prometheus 규칙입니다:
# Prometheus Alert Rules 예시 (잘못된 설정)
- alert: HighMemoryUsage
expr: (1 - node_memory_MemFree_bytes / node_memory_MemTotal_bytes) > 0.9
# → buff/cache를 used로 계산하는 오류
# 올바른 설정 (available 기준)
- alert: LowMemoryAvailable
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes < 0.1
for: 5m
labels:
severity: warning
annotations:
summary: "가용 메모리 10% 미만 ({{ $value | humanizePercentage }})"
- alert: CriticalMemoryAvailable
expr: node_memory_MemAvailable_bytes < 200 * 1024 * 1024 # 200MB
for: 2m
labels:
severity: critical
- alert: SwapActivityHigh
expr: rate(node_vmstat_pswpin[5m]) + rate(node_vmstat_pswpout[5m]) > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Swap I/O 높음 — 메모리 부족 가능성"
메모리 용량 계획 (Capacity Planning) 기준:
available이 total의 20% 미만 → 증설 계획 검토available이 total의 10% 미만 → 즉시 증설- Swap 사용 → RAM이 부족하다는 신호 (Swap은 안전망이지 정상 동작이 아님)
- 프로세스 RSS 합산 > 물리 RAM 80% → OOM 위험 구간
같은 애플리케이션이라도 환경에 따라 메모리 설정 전략이 달라집니다.
개발 환경 — 개발 서버에서는 Swap을 여유있게 잡고 swappiness를 높게 설정합니다:
# 개발자 노트북 (16GB RAM, 개발용 서버)
# - Swap: 불필요시 없어도 됨 (빌드, IDE가 메모리 많이 씀)
# - swappiness: 기본값 60 그대로 사용
# - Page Cache: 많을수록 좋음 (같은 파일 반복 빌드 시 이득)
# - OOM 보호: 불필요
# Docker Desktop 메모리 제한도 확인
docker stats --no-stream
프로덕션 환경 — 운영 서버에서는 Swap 의존을 줄이고 메모리를 넉넉히 확보합니다:
# 프로덕션 서버 권장 설정
# 1. swappiness 낮추기 (10 또는 1)
echo 'vm.swappiness=10' >> /etc/sysctl.d/99-production.conf
# 2. Swap 크기: RAM이 충분하면 RAM의 25~50% (안전망 역할)
# RAM이 부족한 경우: RAM과 동일하거나 2배까지
# 3. 중요 서비스 OOM 보호
# /etc/systemd/system/nginx.service.d/override.conf
# [Service]
# OOMScoreAdjust=-500
# /etc/systemd/system/postgresql.service.d/override.conf
# [Service]
# OOMScoreAdjust=-800
# 4. 메모리 오버커밋 설정
# overcommit_memory:
# 0 = 커널이 적당히 판단 (기본값)
# 1 = 항상 허용 (메모리 계산이 어려운 경우)
# 2 = 엄격히 제한 (금융 시스템 등 안정성 최우선)
cat /proc/sys/vm/overcommit_memory
# 0
# 5. 메모리 오버커밋 비율 (overcommit_memory=2일 때)
cat /proc/sys/vm/overcommit_ratio
# 50 → RAM의 50% + Swap 만큼만 허용
컨테이너 환경 (Docker/Kubernetes) 주의사항 — 컨테이너는 호스트 메모리 전체를 보므로 limits 설정이 필수입니다:
# 컨테이너 메모리 제한 확인
docker inspect <container_id> | grep -i memory
# Kubernetes Pod 메모리 설정 예시
# resources:
# requests:
# memory: "256Mi" # 스케줄링 기준
# limits:
# memory: "512Mi" # 이 이상 쓰면 OOM Kill (컨테이너 재시작)
# 컨테이너 OOM Kill은 /var/log/messages가 아닌
# docker events 또는 kubectl describe pod에서 확인
kubectl describe pod <pod-name> | grep -A5 "OOMKilled\|Last State"
# Last State: Terminated
# Reason: OOMKilled
# Exit Code: 137
# 참고: 컨테이너 내부에서 free -h는 호스트 메모리를 보여줌 (주의!)
# cgroup 제한은 /sys/fs/cgroup/memory/ 에서 확인
팀 내 메모리 관련 문서화 권장 항목:
- 각 서비스별 정상 메모리 사용 범위 (baseline)
- 메모리 알람 기준값과 근거
- OOM 발생 시 대응 절차 런북(Runbook)
- 주요 프로세스 OOMScoreAdjust 설정 목록
- Swap 설정 현황 및 이유
cgroup 제한과 OOM — 컨테이너 OOMKilled vs 호스트 OOM 구분
 확대
확대
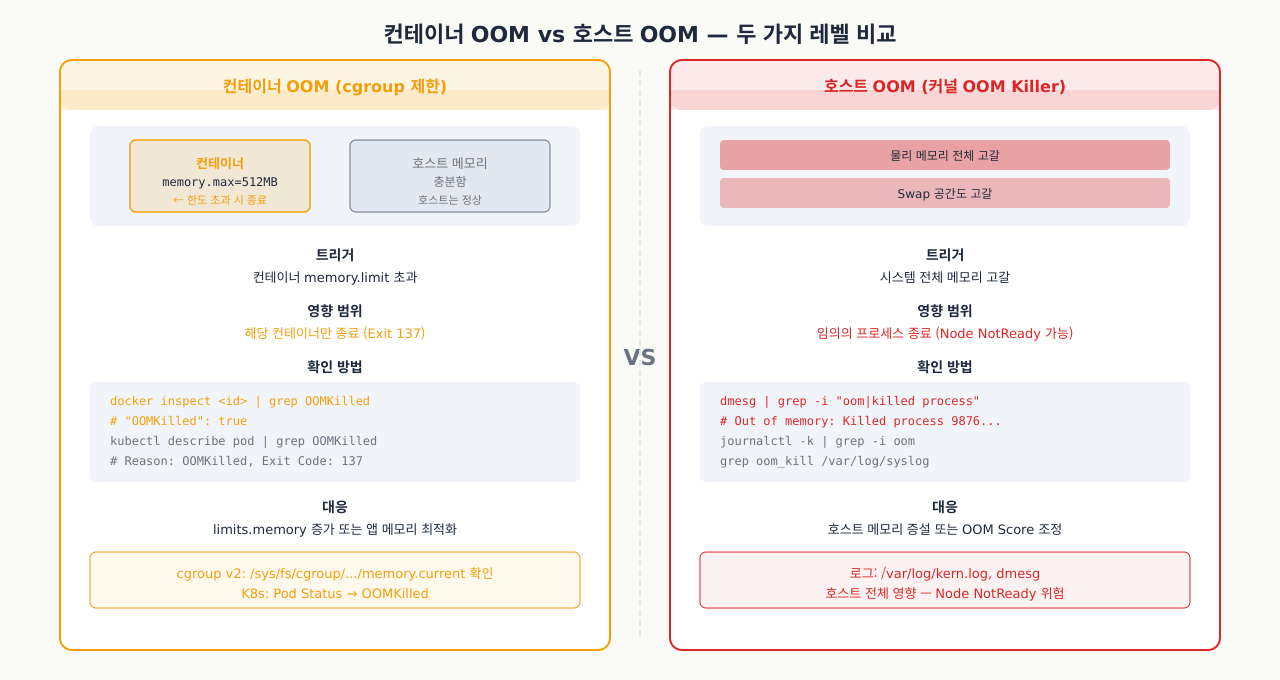
컨테이너로 실행한 Node.js 서비스가 Exited (137)로 죽었습니다. 호스트의 dmesg에는 OOM 메시지가 없고, docker inspect를 보면 "OOMKilled": true라고 찍혀 있습니다. 호스트 메모리는 충분한데 컨테이너만 죽은 이 상황은 호스트 OOM Killer가 아니라 cgroup 메모리 제한에 걸린 것입니다. 두 가지 OOM을 구별하지 못하면 엉뚱한 곳을 파게 됩니다.
컨테이너 환경에서 OOM(Out of Memory)은 두 가지 레벨에서 발생합니다. 원인과 대응이 완전히 다릅니다.
두 가지 OOM 비교 — 커널 OOM Killer와 컨테이너 cgroup OOM의 동작 방식과 로그 위치가 다릅니다:
| 구분 | 컨테이너 OOM (cgroup 제한) | 호스트 OOM (커널 OOM Killer) |
|---|---|---|
| 트리거 | 컨테이너의 memory.limit 초과 | 시스템 전체 메모리 고갈 |
| 영향 범위 | 해당 컨테이너만 종료 | 임의의 프로세스 종료 |
| 로그 위치 | dmesg + journalctl (cgroup oom) | /var/log/kern.log, dmesg |
| Kubernetes 표시 | Pod Status: OOMKilled | Node NotReady 가능성 |
| 대응 | limits.memory 증가 or 앱 메모리 최적화 | 호스트 메모리 증설 or OOM Score 조정 |
컨테이너 OOM 진단 — docker inspect와 kubectl로 컨테이너 OOM 종료 이력을 확인합니다:
# Docker 컨테이너 OOM 확인
docker inspect <container_id> | grep -A5 OOMKilled
# "OOMKilled": true ← cgroup 제한으로 종료됨
# cgroup v2 메모리 사용량 확인
cat /sys/fs/cgroup/system.slice/docker-<id>.scope/memory.current
cat /sys/fs/cgroup/system.slice/docker-<id>.scope/memory.max
# Kubernetes Pod OOM 확인
kubectl describe pod <pod-name> | grep -A5 "Last State"
# Reason: OOMKilled
# Exit Code: 137 (128 + SIGKILL)
호스트 OOM 진단 — 커널 OOM Killer 작동 이력을 dmesg와 journalctl에서 확인합니다:
# OOM Killer 발동 이력 확인
dmesg | grep -i "oom\|killed process" | tail -20
# [12345.678] Out of memory: Killed process 9876 (java) total-vm:4096000kB...
# 어떤 프로세스가 희생됐는지 확인
grep -i "oom_kill" /var/log/syslog 2>/dev/null || journalctl -k | grep -i oom
OOM Score 조정 (중요 프로세스 보호) — oom_score_adj를 낮춰 중요 프로세스가 마지막까지 살아남도록 합니다:
# OOM Score: -1000(절대 보호) ~ 1000(먼저 종료)
# 기본값은 대부분 0
# nginx 프로세스를 OOM에서 보호 (-1000은 root만 가능)
echo -500 | sudo tee /proc/$(pgrep nginx | head -1)/oom_score_adj
# systemd 서비스 단위로 OOM Score 설정 (권장)
# /etc/systemd/system/nginx.service.d/oom.conf
[Service]
OOMScoreAdjust=-500
 확대
확대
zswap/zram — 압축 스왑의 선택 기준과 운영 주의점
 확대
확대
SSD 서버인데도 스왑이 발생할 때 디스크 I/O가 급등하는 경우가 있습니다. zswap을 활성화하면 스왑 대상 페이지를 디스크에 쓰기 전에 메모리 안에서 압축해서 보관하므로, 디스크까지 안 가도 되는 케이스가 늘어납니다. 반면 디스크가 아예 없는 환경(컨테이너 호스트, 임베디드)에서는 zram을 써서 RAM의 일부를 압축 스왑 영역으로 씁니다. 이 둘은 이름이 비슷하지만 동작 방식과 적합한 환경이 달라서, 잘못 선택하면 효과가 없거나 오히려 부하가 커질 수 있습니다.
zswap vs zram 비교 — 두 압축 메모리 기술의 동작 방식과 적합한 사용 환경을 비교합니다:
| 항목 | zswap | zram |
|---|---|---|
| 위치 | 메모리 내 압축 캐시 (기존 swap 앞단) | 메모리 내 압축 블록 디바이스 |
| 디스크 swap | 필요 (백업 저장소로 사용) | 불필요 (디스크 없이 단독 동작) |
| 용도 | 디스크 swap I/O 줄이기 | 디스크 없는 환경 (컨테이너/임베디드) |
| 권장 환경 | SSD 있는 서버 | 라즈베리파이, 컨테이너 호스트 |
zram 설정 (디스크 없는 환경) — RAM의 일부를 압축해 사용하는 가상 Swap으로, 디스크 없는 환경에 적합합니다:
# zram 모듈 로드
sudo modprobe zram
# 압축 알고리즘 설정 (lz4가 속도, zstd가 압축률 우선)
echo lz4 | sudo tee /sys/block/zram0/comp_algorithm
# zram 크기 설정 (물리 메모리의 50% 권장)
TOTAL_MEM=$(grep MemTotal /proc/meminfo | awk '{print $2}')
echo $((TOTAL_MEM / 2 * 1024)) | sudo tee /sys/block/zram0/disksize
# swap 활성화
sudo mkswap /dev/zram0
sudo swapon -p 100 /dev/zram0 # 우선순위 높게
# 확인
zramctl
swapon --show
운영 주의점:
- zswap/zram은 메모리를 더 효율적으로 쓰지만 CPU 오버헤드가 있습니다 (압축/해제)
- 이미 메모리가 심각하게 부족한 상황에서는 압축 오버헤드가 오히려 악화를 초래할 수 있습니다
- **DB 서버(MySQL, PostgreSQL)**는 자체 버퍼 풀을 관리하므로 swap 자체를 비활성화하거나 vm.swappiness=1로 설정하는 경우가 많습니다
정리 및 핵심 요약
메모리 판단 의사결정 트리
 확대
확대
핵심 명령어 치트시트
# 메모리 현황 (available이 진짜 여유 메모리)
free -h
# Swap I/O 실시간 (si/so가 핵심)
vmstat 1
# 프로세스별 메모리 사용
ps aux --sort=-%mem | head -10
# OOM 로그 확인
journalctl -k | grep -i "oom\|killed process"
# Swap 활성/비활성
swapon /swapfile
swapoff /swapfile
# OOM 보호 설정
echo -500 > /proc/<PID>/oom_score_adj
# 캐시 강제 해제 (프로덕션 주의)
sync && echo 3 > /proc/sys/vm/drop_caches
# swappiness 조정
sysctl vm.swappiness=10
자주 하는 실수
| 실수 | 올바른 방법 |
|---|---|
used/total로 메모리 부족 판단 | available/total 또는 절대값으로 판단 |
| swap 사용량이 0이 아닌 것 자체를 위기로 봄 | si/so(swap in/out 활동)가 지속적인지 확인 |
| OOM 발생 후 프로세스 재시작만 함 | 원인(메모리 누수, 설정 오류) 반드시 분석 |
| drop_caches를 정기적으로 실행 | 커널이 자동 관리하므로 불필요. 테스트 용도만 |
| 모든 서버에 동일한 swappiness 적용 | 용도(DB, 웹서버, 배치)에 따라 다르게 설정 |
| Swap을 크게 만들면 메모리 부족 해결된다고 생각 | Swap은 안전망. 근본 해결은 RAM 증설 또는 앱 최적화 |
명령어·단축키 빠른 참조
이 모듈에서 다룬 메모리·Swap 진단 명령을 실전 옵션과 함께 모았습니다. "자주 쓰는 예" 열의 조합을 메모리 알람 대응 때 그대로 써도 됩니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
free -h | 메모리 현황 스냅샷 (used·free·available) | free -h -s 2 (2초 갱신) · watch -n 1 free -h |
vmstat | 가상메모리·Swap I/O 시계열, 스래싱 감지 | vmstat 1 5 → si·so가 지속 0 초과면 메모리 부족 |
swapon --show | 현재 Swap 파티션/파일 크기·사용량 확인 | swapon --show · cat /proc/swaps |
mkswap + swapon | swapfile 포맷 후 활성화 | sudo mkswap /swapfile && sudo swapon /swapfile |
swapoff | Swap 비활성화 | sudo swapoff /swapfile · 전체 sudo swapoff -a |
fallocate / dd | swapfile 공간 생성 | sudo fallocate -l 2G /swapfile · dd if=/dev/zero of=/swapfile bs=1M count=2048 |
sysctl vm.swappiness | Swap 적극성 조정 (기본 60) | sudo sysctl vm.swappiness=10 (서버 10~20 권장) |
ps aux --sort=-%mem | 메모리(%MEM) 상위 프로세스 파악 | ps aux --sort=-%mem | head -10 |
journalctl -k / dmesg | OOM Killer 발동 로그 확인 | journalctl -k | grep -i oom · dmesg | grep -i killed |
oom_score_adj | 프로세스 OOM 우선순위 보정 (-1000~+1000) | echo -500 > /proc/$(pgrep nginx)/oom_score_adj (보호) |
drop_caches | Page Cache 수동 해제 (프로덕션 주의) | sync && echo 3 | sudo tee /proc/sys/vm/drop_caches |
smem -r -k | PSS 기준 프로세스별 실제 메모리 측정 | smem -r -k | head -20 |
cat /proc/meminfo | 커널 메모리 지표 원본 (MemAvailable·Huge*) | cat /proc/meminfo | grep -i huge |
numactl --hardware | NUMA 노드별 메모리·거리 확인 | numactl --hardware · numastat -m (노드별 사용량) |
관련 모듈로 더 깊이:
- 프로세스 관리와 작업 제어 — 메모리를 잡아먹는 프로세스(누수·과점유)를 찾아 조치하는 법
- vmstat, iostat, sar로 CPU/디스크 IO 성능 병목 진단 — vmstat/sar로 메모리·I/O 병목을 체계적으로 추적
- sysctl 커널 파라미터 튜닝으로 대규모 트래픽 처리 성능 높이기 — swappiness 등 vm.* 커널 파라미터를 용도별로 조정하는 원리
다음 모듈에서는 vmstat, iostat, sar를 활용해 CPU·디스크 I/O 성능 병목을 체계적으로 진단하는 방법을 다룹니다.