선임 엔지니어가 급한 회의에 들어가면서 말합니다. "랙 3번 서버 스펙을 오늘 오후까지 DB 팀에 보내줘요. CPU 코어 수, 메모리, 디스크 구성, 네트워크 인터페이스 다요." SSH 접속 정보만 달랑 받았습니다. 어디서 어떤 명령어를 실행해야 하는지 모른다면 1시간이 걸려도 반밖에 못 채웁니다. lscpu, dmidecode, lsblk를 알면 10분 만에 완성도 높은 스펙 문서가 나옵니다.
서버 하드웨어 파악 & /proc 파일시스템
신입 엔지니어가 가장 당황하는 순간 중 하나는 "이 서버 좀 봐줘요"라는 말을 들었을 때다. 어디서부터 봐야 할지, 어떤 정보를 수집해야 할지 몰라서 멍하니 터미널 앞에 앉아있게 된다. 이 챕터를 마치고 나면 낯선 서버 앞에 앉아도 5분 안에 핵심 스펙을 정리할 수 있게 된다.
신규 입사 첫 주, 선임 엔지니어가 갑자기 급한 회의에 들어가면서 이렇게 말한다.
"저기 랙 3번 서버, 오늘 오후에 DB 팀에 스펙 전달해줘야 해요. CPU 코어 수, 메모리, 디스크 구성이랑 네트워크 인터페이스 정리해서 슬랙으로 보내주세요."
SSH 접속 정보만 달랑 받았다. 이 챕터에서 배우는 명령어들로 10분 만에 완성도 높은 스펙 문서를 만들 수 있다. DB 팀이 감탄할 정도로.
- 1/proc 가상 파일시스템 구조와 커널 정보 접근 원리를 이해할 수 있다
- 2lscpu·dmidecode로 CPU 소켓/코어/하이퍼스레딩을 파악할 수 있다
- 3lsmem·dmidecode -t 17로 메모리 슬롯 및 DIMM 정보를 조회할 수 있다
- 4lsblk·hdparm·lspci로 디스크와 PCI 장치를 확인할 수 있다
- 5numactl로 NUMA 토폴로지를 분석하고 서버 스펙을 문서화할 수 있다
sudo apt install -y util-linux pciutils usbutils hdparm dmidecode numactlsudo -v물리 서버 또는 VM(권장 RAM 2GB 이상) — lscpu·dmidecode 출력 확인용
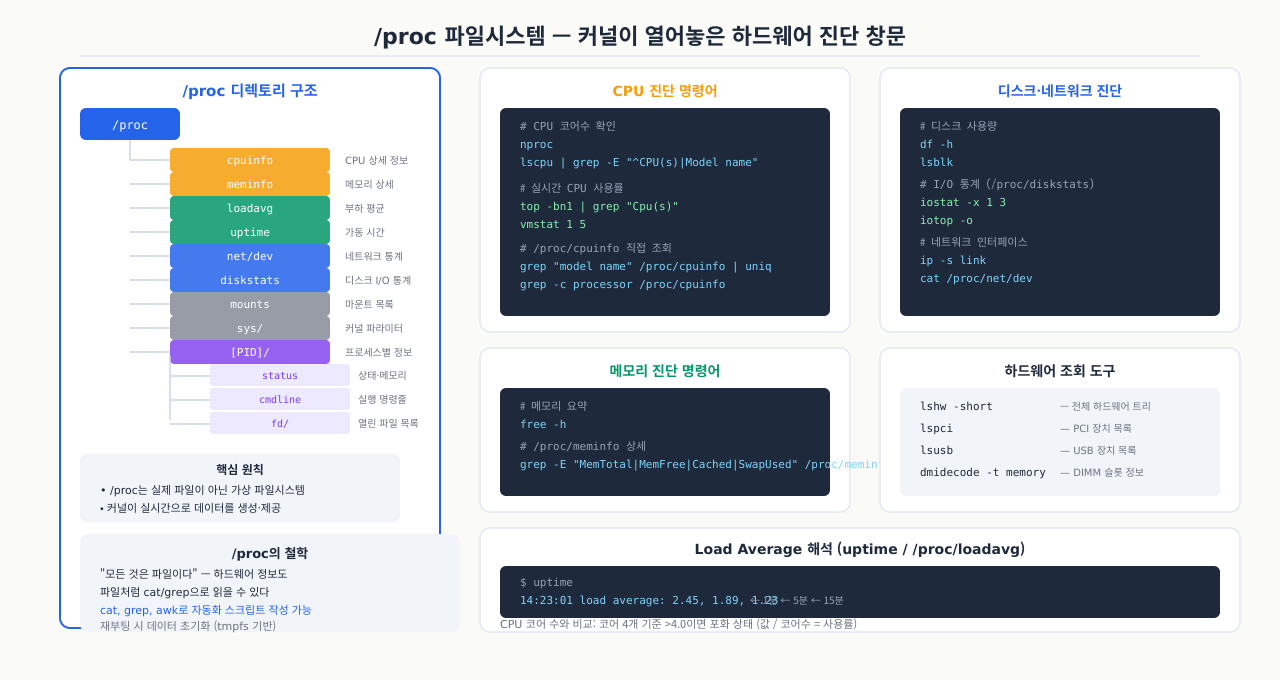
1. /proc 파일시스템이란 무엇인가
/proc 파일시스템: 커널이 열어놓은 창문
 확대
확대
CPU 개수나 메모리 총량을 확인하려고 /proc/cpuinfo, /proc/meminfo를 열면 파일 크기가 0바이트로 표시되는데 내용이 나옵니다. 수정도 안 되는 것들이 있는가 하면, sysctl -w로 값을 쓰면 /proc/sys/ 아래 파일이 바뀝니다. 일반 파일처럼 보이지만 동작이 다른 이유는 /proc가 디스크가 아닌 커널 메모리에만 존재하는 가상 파일시스템이기 때문입니다. 커널 파라미터 튜닝, 프로세스 상태 확인, 각종 진단 도구가 모두 이 /proc를 통해 커널 내부에 접근합니다.
/proc는 실제 디스크에 존재하는 디렉토리가 아니다. 리눅스 커널이 메모리에 올려놓은 **가상 파일시스템(Virtual Filesystem)**이다. 시스템이 부팅될 때 커널이 메모리에 직접 생성하고, 종료되면 사라진다.
왜 파일 형태로 보이는가?
리눅스의 철학 중 하나는 "모든 것은 파일이다(Everything is a file)"다. 커널 내부 상태, 프로세스 정보, 하드웨어 구성 등을 파일처럼 읽을 수 있게 노출시킴으로써 일반 프로그램들이 특별한 시스템 콜 없이도 커널 정보에 접근할 수 있게 한다.
/proc/ 아래의 주요 항목입니다.
cpuinfo— CPU 상세 정보meminfo— 메모리 사용 현황loadavg— 시스템 부하 평균uptime— 가동 시간version— 커널 버전mounts— 마운트된 파일시스템 목록net/— 네트워크 관련 정보 (dev: 인터페이스 통계,if_inet6: IPv6 주소)sys/— 커널 파라미터 (sysctl)1/— PID 1번 프로세스 (systemd)1234/— PID 1234번 프로세스 정보 (cmdline: 실행 명령어,status: 상태,fd/: 열린 FD,maps: 메모리 맵)
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/linux/part5/exam_28 && cd /tmp/linux/part5/exam_28
# 하드웨어 정보 수집 스크립트
cat > hw_info.sh << 'EOF'
#!/bin/bash
echo "=== CPU 정보 ===" && lscpu | grep -E "^(Architecture|CPU\(s\)|Thread|Core|Socket|Model name)"
echo "" && echo "=== 메모리 ===" && free -h
echo "" && echo "=== 디스크 ===" && lsblk -d -o NAME,SIZE,TYPE,MODEL 2>/dev/null
echo "" && echo "=== 네트워크 인터페이스 ===" && ip -br link show
echo "" && echo "=== 가상화 여부 ===" && systemd-detect-virt 2>/dev/null || cat /proc/cpuinfo | grep hypervisor | head -1
EOF
chmod +x hw_info.sh
이제 실습을 진행합니다.
핵심 포인트: lscpu, free, df 같은 명령어들은 대부분 /proc 파일을 읽어서 보기 좋게 출력해주는 래퍼(wrapper)에 불과하다. 원본 데이터는 항상 /proc에 있다.
# lscpu가 내부적으로 읽는 파일
cat /proc/cpuinfo
# free가 내부적으로 읽는 파일
cat /proc/meminfo
# uptime이 내부적으로 읽는 파일
cat /proc/uptime
2. CPU 정보 파악
lscpu — CPU 아키텍처 한눈에 보기
lscpu는 /proc/cpuinfo와 /sys/devices/system/cpu/ 디렉토리를 읽어서 CPU 관련 정보를 구조화된 형태로 출력한다.
lscpu
출력 예시:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) Gold 6130 CPU @ 2.10GHz
CPU family: 6
Model: 85
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 2
Stepping: 4
CPU MHz: 2100.000
CPU max MHz: 3700.0000
CPU min MHz: 800.0000
BogoMIPS: 4200.00
Virtualization: VT-x
Caches (sum of all):
L1d: 512 KiB (16 instances)
L1i: 512 KiB (16 instances)
L2: 16 MiB (16 instances)
L3: 44 MiB (2 instances)
NUMA:
NUMA node(s): 2
NUMA node0 CPU(s): 0-7,16-23
NUMA node1 CPU(s): 8-15,24-31
핵심 필드 해석:
| 필드 | 의미 |
|---|---|
CPU(s): 32 | 논리 프로세서(스레드) 총 수 |
Thread(s) per core: 2 | 코어당 하이퍼스레딩 스레드 수 |
Core(s) per socket: 8 | 소켓(CPU 패키지)당 물리 코어 수 |
Socket(s): 2 | 물리 CPU 패키지 수 |
NUMA node(s): 2 | NUMA 노드 수 (물리 소켓과 일치) |
총 논리 CPU 수 계산:
논리 CPU = Socket(s) × Core(s) per socket × Thread(s) per core
= 2 × 8 × 2 = 32
물리 코어 vs 논리 코어 (하이퍼스레딩)
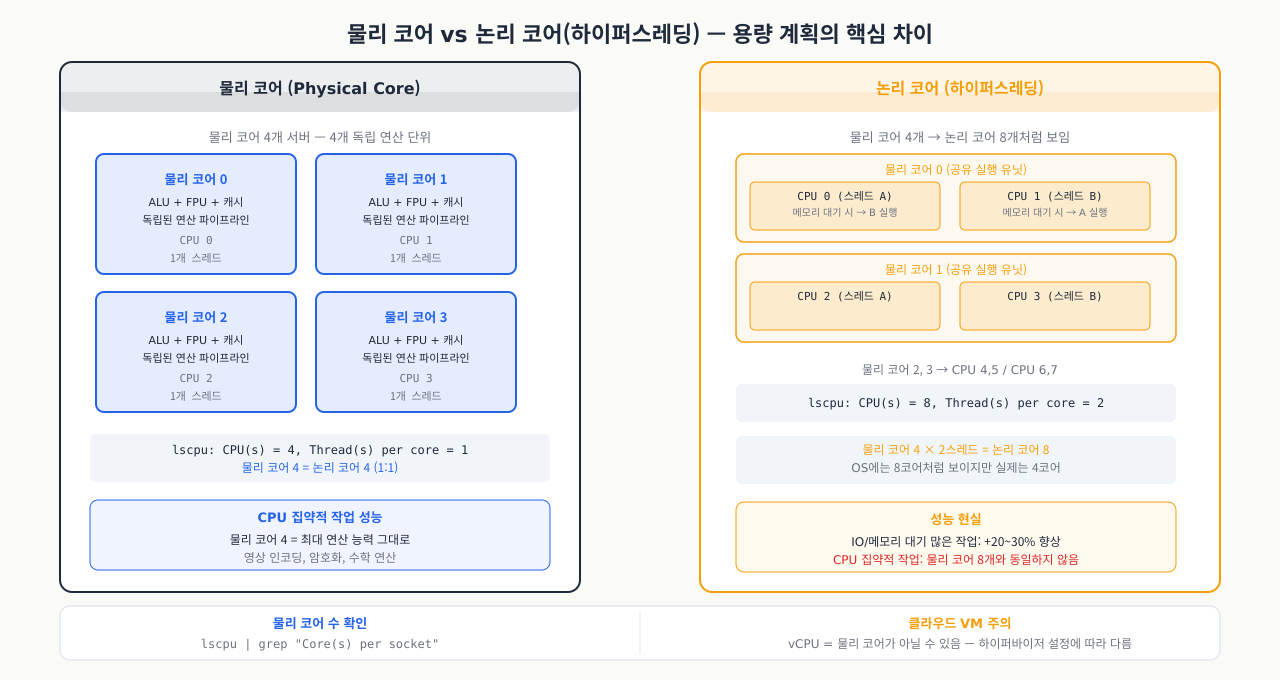 확대
확대
"CPU 4코어" 서버인데 lscpu를 보면 CPU(스레드)가 8개로 표시됩니다. EC2 인스턴스를 vCPU 개수 기준으로 선택했는데 CPU 집약적인 작업에서 기대만큼 성능이 안 나오는 경우가 있습니다. 하이퍼스레딩으로 하나의 물리 코어를 논리적으로 두 개로 보이게 만들기 때문입니다. 연산 집약적인 작업에서 vCPU 8개는 물리 코어 8개와 동일한 성능을 내지 않으며, 이 차이를 모르면 용량 계획에서 실수를 하게 됩니다.
이 개념을 혼동하면 용량 계획(capacity planning)에서 심각한 실수를 저지를 수 있다.
물리 코어 (Physical Core)
- 실리콘 칩 위에 물리적으로 존재하는 연산 단위
- 독립된 ALU(산술논리장치), FPU(부동소수점 장치), 캐시를 가짐
- CPU 패키지를 열어보면 실제로 보이는 것
논리 코어 / 하이퍼스레딩 (Logical Core / HyperThreading)
- Intel의 SMT(Simultaneous Multi-Threading) 기술
- 하나의 물리 코어를 OS에게 2개의 CPU처럼 보이게 함
- 물리 코어의 실행 단위(execution unit)를 두 스레드가 나눠씀
- CPU가 한 스레드를 기다리는 동안(메모리 접근 등) 다른 스레드 실행
성능 차이가 중요한 이유:
물리 코어 8개 ≠ 논리 코어 16개 (하이퍼스레딩)
CPU 집약적 작업 (예: 영상 인코딩, 암호화):
- 물리 코어 8개 서버 = 논리 코어 16개 서버의 약 90~100% 성능
메모리/IO 대기가 많은 작업 (예: 웹 서버, DB):
- 논리 코어 16개는 물리 코어 8개보다 약 20~30% 향상
- 하지만 물리 코어 16개와는 다름
실무에서 물리 코어 수 확인하는 방법:
# 방법 1: lscpu 계산
lscpu | grep -E "^(CPU\(s\)|Thread|Core|Socket)"
# 방법 2: /proc/cpuinfo에서 고유한 physical id + core id 조합 세기
grep -P "^physical id|^core id" /proc/cpuinfo | \
paste - - | sort -u | wc -l
# 방법 3: 직접 계산 (가장 명확)
echo "물리 코어 수: $(lscpu | grep "Core(s) per socket" | awk '{print $NF}') × $(lscpu | grep "Socket(s)" | awk '{print $NF}') = $(( $(lscpu | grep "Core(s) per socket" | awk '{print $NF}') * $(lscpu | grep "Socket(s)" | awk '{print $NF}') ))"
가상화 환경에서 주의사항:
VM(가상머신) 안에서 lscpu를 실행하면 하이퍼바이저가 할당한 vCPU 수가 나온다. 이 vCPU가 실제 물리 서버의 어떤 코어에 대응하는지는 하이퍼바이저 설정에 따라 다르다. 클라우드 VM에서 CPU(s): 4는 물리 코어 4개가 아닐 수 있다.
/proc/cpuinfo 직접 읽기
# 전체 CPU 정보 (매우 길다)
cat /proc/cpuinfo
# 첫 번째 CPU 정보만
cat /proc/cpuinfo | head -40
# 모델명만 추출 (중복 제거)
grep "model name" /proc/cpuinfo | sort -u
# 물리 CPU(소켓) 수
grep "physical id" /proc/cpuinfo | sort -u | wc -l
# 총 논리 CPU 수
grep -c "^processor" /proc/cpuinfo
# CPU 플래그 확인 (가상화 지원 여부)
grep "flags" /proc/cpuinfo | head -1 | grep -o "vmx\|svm"
# vmx = Intel VT-x 지원, svm = AMD-V 지원
3. 메모리 정보 파악
단계 1: free 명령어로 메모리 현황 확인
free -h
출력 예시:
total used free shared buff/cache available
Mem: 62Gi 18Gi 12Gi 1.2Gi 31Gi 42Gi
Swap: 8.0Gi 512Mi 7.5Gi
각 컬럼 의미:
| 컬럼 | 의미 |
|---|---|
total | 물리 메모리 총량 |
used | 프로세스가 실제 사용 중인 메모리 |
free | 아무도 사용하지 않는 완전히 빈 메모리 |
shared | tmpfs 등 공유 메모리 |
buff/cache | 커널이 디스크 캐시로 사용 중인 메모리 |
available | 실제로 새 프로세스가 쓸 수 있는 메모리 (중요!) |
자주 하는 실수: free 값이 작다고 메모리가 부족하다고 판단하는 것. 리눅스는 남는 메모리를 파일 캐시로 적극 활용하므로 free는 항상 작게 보인다. 실제 가용 메모리는 available 컬럼을 봐야 한다.
단계 2: 상세 메모리 정보 확인
# 총 물리 메모리
cat /proc/meminfo | grep MemTotal
# 실제 가용 메모리
cat /proc/meminfo | grep MemAvailable
# 스왑 사용 현황
cat /proc/meminfo | grep -i swap
# 메모리 관련 핵심 항목만 필터링
cat /proc/meminfo | grep -E "^(MemTotal|MemFree|MemAvailable|SwapTotal|SwapFree|Cached|Buffers):"
단계 3: 메모리 슬롯 물리 정보 확인 (dmidecode 필요)
# root 권한 필요
sudo dmidecode -t memory | grep -E "(Size|Speed|Type|Manufacturer|Part Number)" | grep -v "No Module"
출력 예시:
Size: 16 GB
Type: DDR4
Speed: 2933 MT/s
Manufacturer: Samsung
Part Number: M393A2K43CB2-CVF
Size: 16 GB
Type: DDR4
Speed: 2933 MT/s
Manufacturer: Samsung
Part Number: M393A2K43CB2-CVF
이 정보로 실제 장착된 DIMM 슬롯 수와 각 슬롯의 용량/속도를 파악할 수 있다.
- lscpu 출력에서 먼저 Socket(s), Core(s) per socket, Thread(s) per core 세 줄을 찾아 확인한 뒤 곱셈으로 CPU(s) 값을 검산한다 — Socket × Core × Thread = CPU(s) 숫자와 불일치하면 가상화 환경이거나 일부 코어가 비활성화된 것
- Thread(s) per core 값이 1이면 하이퍼스레딩 비활성화(물리 코어 = 논리 코어), 2이면 HT 활성화 — CPU 집약적 작업에서 HT 비활성 서버와 HT 활성 서버를 같은 성능으로 취급하면 용량 계획 오류 발생
- free -h 의 total 이 dmidecode -t 17 슬롯 용량 합계(GB 단위)와 1~2GB 차이가 나면 정상 — OS와 BIOS가 일부 메모리를 예약하기 때문. 4GB 이상 차이가 나면 DIMM 슬롯이 인식되지 않은 것이므로 sudo dmidecode -t 17 | grep -c "Size: [0-9]" 로 인식된 슬롯 수 확인
- lsblk -d -o NAME,SIZE,ROTA 결과에서 ROTA 값이 0이면 SSD/NVMe, 1이면 HDD(회전식) — ROTA=0 디스크에서 I/O 성능 기대치가 다름(SSD: 수백 MB/s, HDD: 수십 MB/s)
4. 디스크 정보 파악
단계 1: 블록 디바이스 전체 구조 파악
lsblk -f
출력 예시:
NAME FSTYPE FSVER LABEL UUID FSAVAIL FSUSE% MOUNTPOINTS
sda
├─sda1 vfat FAT32 C3E4-1A2B 511M 1% /boot/efi
├─sda2 ext4 1.0 a1b2c3d4-e5f6-... 800M 20% /boot
└─sda3 LVM2_member 2 xyz12345-...
├─vg0-root ext4 1.0 11111111-... 18G 45% /
├─vg0-home ext4 1.0 22222222-... 80G 30% /home
└─vg0-swap swap 1 33333333-... [SWAP]
nvme0n1
└─nvme0n1p1 ext4 1.0 44444444-... 400G 10% /data
lsblk 주요 옵션:
# 파일시스템 타입과 UUID 포함
lsblk -f
# 디스크 크기 포함, 트리 형태
lsblk -o NAME,SIZE,TYPE,FSTYPE,MOUNTPOINT
# 물리 디스크만 (파티션 제외)
lsblk -d -o NAME,SIZE,MODEL,ROTA
# ROTA: 1=HDD(회전식), 0=SSD/NVMe
단계 2: 마운트된 파일시스템 사용량 파악
df -hT
출력 예시:
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs tmpfs 32G 0 32G 0% /dev/shm
/dev/mapper/vg0-root ext4 20G 9.0G 11G 45% /
/dev/sda2 ext4 976M 196M 713M 22% /boot
/dev/mapper/vg0-home ext4 88G 26G 62G 30% /home
/dev/nvme0n1p1 ext4 440G 44G 396G 10% /data
tmpfs tmpfs 6.3G 8.0K 6.3G 1% /run/user/1000
핵심 옵션:
-h: 사람이 읽기 쉬운 단위(GB, MB 등)-T: 파일시스템 타입 표시
단계 3: 특정 디스크의 물리 정보
# 디스크 모델, 시리얼, 펌웨어 버전 (root 권한 필요)
sudo hdparm -I /dev/sda | grep -E "(Model|Serial|Firmware)"
# NVMe SSD 정보
sudo nvme list
# 디스크 SMART 건강 상태 확인
sudo smartctl -a /dev/sda | grep -E "(Model|Serial|Health|Power_On_Hours)"
단계 4: I/O 스케줄러 확인
# 현재 I/O 스케줄러 확인
cat /sys/block/sda/queue/scheduler
# 출력: [mq-deadline] none kyber bfq
# 대괄호 안이 현재 활성 스케줄러
5. 네트워크 인터페이스 파악
단계 1: 모든 네트워크 인터페이스 확인
ip addr
출력 예시:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:1a:2b:3c:4d:5e brd ff:ff:ff:ff:ff:ff
inet 192.168.1.100/24 brd 192.168.1.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::21a:2bff:fe3c:4d5e/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:1a:2b:3c:4d:5f brd ff:ff:ff:ff:ff:ff
inet 10.0.0.100/24 brd 10.0.0.255 scope global eth1
valid_lft forever preferred_lft forever
단계 2: 인터페이스 속도와 링크 상태 확인
# 특정 인터페이스의 속도/듀플렉스 확인
ethtool eth0
출력 예시:
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
10000baseT/Full
Supported pause frame use: Symmetric
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
10000baseT/Full
Speed: 10000Mb/s
Duplex: Full
Auto-negotiation: on
Port: Twisted Pair
PHYAD: 0
Transceiver: internal
MDI-X: off (auto)
Link detected: yes
단계 3: 모든 인터페이스 속도 한번에 확인
for iface in $(ls /sys/class/net/ | grep -v lo); do
echo -n "$iface: "
ethtool $iface 2>/dev/null | grep -E "Speed:|Link detected:" | tr '\n' ' '
echo ""
done
단계 4: 라우팅 테이블 확인
ip route show
# 기본 게이트웨이만
ip route | grep default
단계 5: NIC 드라이버 정보
# 네트워크 카드 드라이버 확인
ethtool -i eth0
출력:
driver: ixgbe
version: 5.1.0-k
firmware-version: 0x800010cf
bus-info: 0000:04:00.0
6. OS 및 커널 정보 파악
OS 배포판 정보
# 표준 방법 (모든 현대 리눅스 배포판)
cat /etc/os-release
출력 예시:
NAME="Rocky Linux"
VERSION="9.3 (Blue Onyx)"
ID=rocky
ID_LIKE="rhel centos fedora"
VERSION_ID="9.3"
PLATFORM_ID="platform:el9"
PRETTY_NAME="Rocky Linux 9.3 (Blue Onyx)"
ANSI_COLOR="0;32"
LOGO="fedora-logo-icon"
CPE_NAME="cpe:/o:rocky:rocky:9::baseos"
HOME_URL="https://rockylinux.org/"
BUG_REPORT_URL="https://bugzilla.rockylinux.org/"
SUPPORT_END="2032-05-31"
# 더 간결하게
. /etc/os-release && echo "$PRETTY_NAME"
# RHEL 계열에서 버전 확인
cat /etc/redhat-release 2>/dev/null || cat /etc/debian_version 2>/dev/null
# LSB 정보 (설치된 경우)
lsb_release -a 2>/dev/null
커널 버전 정보
# 현재 실행 중인 커널 버전
uname -r
# 출력 예시: 5.14.0-362.24.1.el9_3.x86_64
# 전체 커널 정보
uname -a
# 출력: Linux hostname 5.14.0-362.24.1.el9_3.x86_64 #1 SMP ... x86_64 GNU/Linux
# 설치된 커널 목록 (RHEL 계열)
rpm -q kernel 2>/dev/null || dpkg -l linux-image-* 2>/dev/null | grep "^ii"
커널 버전 형식 해석:
커널 버전 5.14.0-362.24.1.el9_3.x86_64는 다음과 같이 해석합니다.
5— 메이저 버전14— 마이너 버전0— 패치 레벨362— 배포판 패치 번호el9_3— 배포판 태그 (el9 = RHEL 9계열)x86_64— 아키텍처
hostnamectl — 호스트 종합 정보
hostnamectl
출력 예시:
Static hostname: prod-db-01.example.com
Icon name: computer-server
Chassis: server
Machine ID: abc123def456...
Boot ID: xyz789...
Operating System: Rocky Linux 9.3 (Blue Onyx)
CPE OS Name: cpe:/o:rocky:rocky:9::baseos
Kernel: Linux 5.14.0-362.24.1.el9_3.x86_64
Architecture: x86-64
Hardware Vendor: Dell Inc.
Hardware Model: PowerEdge R750
Firmware Version: 1.7.8
Firmware Date: Tue 2023-08-15
7. 물리 하드웨어 상세 정보
dmidecode — BIOS/UEFI에서 하드웨어 정보 읽기
dmidecode는 SMBIOS(System Management BIOS) 데이터를 파싱하여 하드웨어 제조사가 기록한 정보를 보여준다. root 권한이 필요하다.
# 시스템 전체 요약
sudo dmidecode -t system
# CPU 정보 (소켓, 코어, 스레드)
sudo dmidecode -t processor
# 메모리 슬롯 상세 정보
sudo dmidecode -t memory
# BIOS 정보
sudo dmidecode -t bios
# 모든 정보 (매우 길다)
sudo dmidecode | less
# 서버 제조사, 모델, 시리얼 넘버만
sudo dmidecode -t system | grep -E "(Manufacturer|Product Name|Serial Number|UUID)"
출력 예시 (시스템 정보):
System Information
Manufacturer: Dell Inc.
Product Name: PowerEdge R750
Version: Not Specified
Serial Number: ABC123XYZ
UUID: 12345678-1234-1234-1234-123456789abc
Wake-up Type: Power Switch
SKU Number: SKU=NotProvided;ModelName=PowerEdge R750
Family: PowerEdge
lspci — PCI 장치 목록
# 모든 PCI 장치 목록
lspci
# 네트워크 카드만
lspci | grep -i "ethernet\|network"
# 스토리지 컨트롤러만
lspci | grep -i "storage\|raid\|sata\|nvme"
# GPU 확인
lspci | grep -i "vga\|3d\|display\|nvidia\|amd"
# 상세 정보 (-v)
lspci -v | head -50
출력 예시:
00:00.0 Host bridge: Intel Corporation Xeon E7 v4/Xeon E5 v4 DMI2
01:00.0 Ethernet controller: Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection (rev 01)
01:00.1 Ethernet controller: Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection (rev 01)
02:00.0 RAID bus controller: LSI Logic / Symbios Logic MegaRAID SAS-3 3108 (rev 02)
03:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd NVMe SSD Controller SM981/PM981/PM983
lshw — 하드웨어 전체 목록 (종합)
# 전체 하드웨어 목록 (매우 상세)
sudo lshw | less
# 클래스별 필터링
sudo lshw -class cpu
sudo lshw -class memory
sudo lshw -class disk
sudo lshw -class network
# 짧은 요약 형태
sudo lshw -short
# HTML 보고서 생성
sudo lshw -html > hardware-report.html
lshw -short 출력 예시:
H/W path Device Class Description
====================================================
system PowerEdge R750
/0 bus 0XJKKP
/0/0 memory 64KiB BIOS
/0/400 processor Intel(R) Xeon(R) Gold 6342 CPU @ 2.80GHz
/0/400/700 memory 1MiB L1 cache
/0/400/701 memory 30MiB L2 cache
/0/400/702 memory 36MiB L3 cache
/0/1000 memory 256GiB System Memory
/0/1000/0 memory 32GiB DIMM DDR4 Synchronous 3200 MHz
/0/100/1f.2 /dev/sda disk 960GB MR9560-16i
/0/100/1c/0 eth0 network Ethernet Connection (14) I219-LM
8. 시스템 가동 상태 파악
uptime — 가동 시간과 부하 평균
uptime
출력 예시:
14:32:18 up 45 days, 12:34, 3 users, load average: 0.45, 0.32, 0.28
해석:
up 45 days, 12:34: 45일 12시간 34분 동안 재부팅 없이 운영 중3 users: 현재 3개의 세션이 연결됨load average: 0.45, 0.32, 0.28: 1분, 5분, 15분 평균 부하
부하 평균 해석 기준:
CPU 32개 서버에서:
load average 32 = 모든 CPU가 꽉 찬 상태 (100% 이용률)
load average 16 = 50% 이용률 (여유 있음)
load average 64 = 200% 과부하 (프로세스 대기 중)
load average가 CPU 수보다 지속적으로 높으면 → 병목 발생
w — 현재 접속 사용자와 하는 일
w
출력 예시:
14:32:18 up 45 days, 12:34, 3 users, load average: 0.45, 0.32, 0.28
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
admin pts/0 192.168.1.10 13:45 1.00s 0.05s 0.01s w
devops pts/1 10.0.0.50 14:20 5:32 0.02s 0.02s -bash
root pts/2 192.168.1.50 14:30 0.00s 0.10s 0.05s top
last reboot — 재부팅 이력
# 마지막 재부팅 시각
last reboot | head -5
출력 예시:
reboot system boot 5.14.0-362.24.1 Tue Feb 6 02:15 - 14:32 (45+12:16)
reboot system boot 5.14.0-284.11.1 Mon Jan 8 03:22 - 02:15 (28+22:52)
reboot system boot 5.14.0-284.11.1 Fri Dec 1 01:30 - 03:22 (37+01:51)
이 정보로 언제 재부팅이 있었는지, 커널 업데이트가 이루어졌는지 파악할 수 있다.
# 전체 로그인 이력 (who was here)
last | head -20
# 실패한 로그인 시도
sudo lastb | head -10
9. 트러블슈팅
증상:
free -h
total used free shared buff/cache available
Mem: 62Gi 58Gi 256Mi 1.2Gi 4.2Gi 3.8Gi
Swap: 8.0Gi 7.5Gi 512Mi
free 컬럼이 256MB밖에 없고 스왑까지 거의 다 찼다. 메모리가 부족한 상황처럼 보인다.
원인 분석:
가능한 원인이 두 가지다:
- 실제 메모리 부족 (OOM 상황 임박):
available이 수백 MB 이하이고 스왑 사용량이 높다 - buff/cache의 착시 (정상 상황):
available은 충분하지만 커널이 캐시로 메모리를 최대한 활용 중
진단 방법:
# 핵심 지표 확인
free -h
# available이 넉넉하면 정상 (리눅스의 캐시 활용)
# available이 작으면 실제 문제
# 스왑 사용 증가 추이 확인
vmstat 1 5
# si, so 컬럼: swap in/out. 값이 지속적으로 0이 아니면 스왑 쓰로싱 발생
# 어떤 프로세스가 메모리를 많이 쓰나
ps aux --sort=-%mem | head -10
# OOM killer 발생 이력
dmesg | grep -i "oom\|out of memory" | tail -20
sudo journalctl -k | grep -i "oom"
대응:
# 상황 1: available은 충분, buff/cache만 높음 → 정상. 조치 불필요
# 필요하다면 캐시 강제 해제 (일반적으로 불필요)
echo 3 | sudo tee /proc/sys/vm/drop_caches
# 상황 2: available 부족 + 스왑 사용 급증 → 메모리 누수 또는 용량 부족
# 메모리 많이 쓰는 프로세스 확인 후 재시작 or 추가 메모리 필요
기억할 것: 리눅스에서 메모리가 완전히 비어있다는 것은 낭비다. 커널은 남는 메모리를 I/O 캐시로 활용해 디스크 읽기 성능을 높인다. free가 낮아도 available이 충분하면 정상이다.
증상:
구매 발주서에는 "Intel Xeon 8코어 × 2소켓 = 16코어"라고 되어 있는데, lscpu를 실행하니 CPU(s): 8만 보인다.
lscpu | grep -E "CPU\(s\)|Thread|Core|Socket"
CPU(s): 8
Thread(s) per core: 1
Core(s) per socket: 8
Socket(s): 1
가능한 원인들:
원인 1: VM/컨테이너 환경 실제 물리 서버가 아닌 가상머신에 접속했을 가능성. 하이퍼바이저가 8개의 vCPU만 할당한 상태.
# 가상화 환경 여부 확인
systemd-detect-virt
# 출력: none (베어메탈), kvm, vmware, xen, docker 등
# 대안 방법
cat /proc/cpuinfo | grep "hypervisor"
# 베어메탈에서는 출력 없음, VM에서는 "hypervisor" 플래그 표시
원인 2: CPU 핫플러그로 일부 비활성화 리눅스는 CPU 코어를 런타임에 활성화/비활성화할 수 있다.
# 온라인 CPU 목록 확인
cat /sys/devices/system/cpu/online
# 예: 0-7 (0번부터 7번까지 8개만 활성화)
# 오프라인 CPU 확인
cat /sys/devices/system/cpu/offline
# 예: 8-15 (나머지 8개는 비활성화 상태)
# 비활성화된 CPU 온라인으로 전환
echo 1 | sudo tee /sys/devices/system/cpu/cpu8/online
원인 3: BIOS에서 하이퍼스레딩 비활성화
BIOS/UEFI에서 HT를 꺼놓은 경우. 이 경우 Thread(s) per core: 1로 표시된다. 보안 이유(Hyper-Threading 취약점 대응)나 성능 예측 가능성을 위해 의도적으로 끄기도 한다.
# BIOS 설정 확인은 dmidecode로
sudo dmidecode -t processor | grep -i "thread\|core\|enabled"
원인 4: NUMA 비대칭으로 인한 착시 NUMA 토폴로지를 오해한 경우.
# NUMA 구성 상세 확인
numactl --hardware
# 각 NUMA 노드별 CPU와 메모리 확인
심화 — 신고된 하드웨어와 실제 쓰는 하드웨어
심화: 이 정보는 어디서 오는가 — 커널(/proc·/sys)이 보는 것과 펌웨어(SMBIOS)가 말하는 것
lscpu·lsblk·free는 술술 나오는데 dmidecode·lshw는 왜 따로 있고, 같은 서버에서 값이 왜 서로 다를까요? 두 부류가 서로 다른 출처에서 정보를 읽기 때문입니다. 이 출처의 차이를 알면 값이 어긋날 때 어느 쪽을 믿을지 판단할 수 있습니다.
- 커널이 지금 실제로 보는 것 — /proc, /sys: lscpu, lsblk, free,
/proc/cpuinfo,/proc/meminfo는 모두 실행 중인 커널이 관리하는 상태를 읽습니다. OS가 실제로 인식하고 쓰는 자원 — 온라인 CPU, 가용 메모리, 마운트된 블록 장치 — 을 반영합니다. - 펌웨어가 장착됐다고 말하는 것 — SMBIOS/DMI: dmidecode·lshw는 부팅 시 펌웨어(BIOS/UEFI)가 채워 놓은 SMBIOS(DMI) 테이블을 읽습니다. 물리 슬롯, DIMM 제조사·용량·속도, 메인보드 모델처럼 하드웨어가 스스로 신고한 정보입니다. 커널이 그 자원을 실제로 다 쓰는지와는 별개입니다.
- 둘이 어긋나는 순간: (1) 가상머신에서는 dmidecode 값을 하이퍼바이저가 합성합니다 — 제조사가 QEMU·VMware로 뜨거나 실제 호스트와 무관한 일반 문자열이 나옵니다. (2) 베어메탈에서도 SMBIOS는 물리 DIMM 64GB를 보고하지만, 커널의
/proc/meminfo는 62.x GB만 total로 잡을 수 있습니다 — 펌웨어 예약 영역·메모리 매핑 I/O 구멍·내장 GPU 공유 메모리 때문입니다. - 그래서 교차 확인: 한 출처만 믿지 않습니다. 이 서버에 물리적으로 뭐가 꽂혀 있나는 dmidecode(펌웨어 관점)로, 커널이 실제로 뭘 쓰나는 /proc·free·lsblk(커널 관점)로 봅니다. VM이면 커널·하이퍼바이저 도구를, 물리 자산 실사면 SMBIOS와 BMC/IPMI를 우선합니다.
정리하면 하드웨어 정보에는 신고된 것과 실제 쓰는 것 두 층이 있고, 값이 다를 때는 버그가 아니라 이 두 층의 차이인 경우가 많습니다.
상황: 새로 인수받은 물리 서버의 스펙을 정리하는데, dmidecode -t 17로는 16GB DIMM 4개 = 64GB가 분명히 보입니다. 그런데 free -h의 total과 /proc/meminfo의 MemTotal은 62.x GB로, 1GB 넘게 모자랍니다. 불량 메모리를 의심하게 됩니다.
원인: 불량이 아니라 정상입니다. SMBIOS(dmidecode)는 물리적으로 장착된 용량을 보고하고, /proc/meminfo의 MemTotal은 커널이 실제로 쓸 수 있는 용량을 보고합니다. 이 둘 사이에서 일부가 예약됩니다 — 메모리 매핑 I/O를 위한 주소 구멍, 펌웨어(UEFI)·ACPI 예약 영역, 내장 GPU가 떼어 가는 공유 메모리, 그리고 커널이 크래시 덤프용으로 잡아 두는 crashkernel= 예약 등입니다. 그래서 장착 64GB와 커널 total 62.x GB가 어긋나는 것은 자연스럽습니다.
진단: dmidecode -t 17 | grep -i size로 물리 장착 합계를, grep MemTotal /proc/meminfo로 커널 total을 비교합니다. 예약된 영역은 커널 로그에서 확인합니다 — dmesg | grep -iE 'memory|reserved|crashkernel'로 예약 사유와 크기를, 내장 GPU 공유 메모리는 dmesg | grep -i stolen으로 봅니다. 줄어든 양이 이런 예약들의 합과 맞아떨어지면 정상입니다.
해결: 대부분 조치할 필요가 없습니다 — 설계상 예약이기 때문입니다. 다만 줄어든 양이 예약 합보다 훨씬 크거나(예: DIMM 하나가 통째로 안 잡힘) 특정 슬롯이 /proc/meminfo에 반영되지 않으면 그때는 실제 문제입니다: DIMM 재장착, 슬롯·채널 규칙 확인, BIOS의 메모리 리매핑(4GB 이상을 쓰려면 Memory Remap 또는 Above 4G Decoding) 설정을 점검합니다. 인수인계 문서에는 장착 64GB / OS 가용 62.x GB(예약 차이)처럼 두 값을 함께 적어 다음 사람이 다시 놀라지 않게 합니다.
10. 서버 인수인계 스펙 문서화 스크립트
팀에서 서버 인수인계를 받을 때마다 수동으로 명령어를 하나씩 실행하고 복사-붙여넣기 하는 것은 비효율적이다. 이 스크립트를 사용하면 10초 만에 표준화된 서버 스펙 문서를 생성할 수 있다.
실제 현장에서는 이 스크립트를 내부 위키나 Confluence 페이지에 붙여넣거나, 슬랙에 공유하거나, Git 레포지토리의 infra/servers/ 디렉토리에 커밋한다.
아래 스크립트를 /usr/local/bin/server-spec-report.sh로 저장하고 실행 권한을 부여하면 된다.
#!/usr/bin/env bash
# server-spec-report.sh
# 서버 스펙을 자동으로 수집하여 마크다운 형식으로 출력
# 사용법: sudo bash server-spec-report.sh [출력파일.md]
OUTPUT_FILE="${1:-server-spec-$(hostname)-$(date +%Y%m%d).md}"
collect_spec() {
cat <<EOF
# 서버 스펙 보고서
생성 일시: $(date '+%Y-%m-%d %H:%M:%S %Z')
수집 서버: $(hostname -f)
---
## 1. 시스템 기본 정보
| 항목 | 값 |
|------|-----|
| 호스트명 | $(hostname -f) |
| OS | $(. /etc/os-release && echo "$PRETTY_NAME") |
| 커널 | $(uname -r) |
| 아키텍처 | $(uname -m) |
| 가동 시간 | $(uptime -p) |
| 마지막 부팅 | $(who -b | awk '{print $3, $4}') |
| 가상화 | $(systemd-detect-virt 2>/dev/null || echo "unknown") |
EOF
# dmidecode가 있고 root이면 하드웨어 벤더 정보 추가
if command -v dmidecode &>/dev/null && [ "$(id -u)" = "0" ]; then
cat <<EOF
| 제조사 | $(dmidecode -t system 2>/dev/null | grep "Manufacturer:" | awk -F': ' '{print $2}' | xargs) |
| 모델 | $(dmidecode -t system 2>/dev/null | grep "Product Name:" | awk -F': ' '{print $2}' | xargs) |
| 시리얼 | $(dmidecode -t system 2>/dev/null | grep "Serial Number:" | awk -F': ' '{print $2}' | xargs) |
EOF
fi
cat <<EOF
---
## 2. CPU 정보
| 항목 | 값 |
|------|-----|
| 모델 | $(grep "model name" /proc/cpuinfo | head -1 | awk -F': ' '{print $2}' | xargs) |
| 소켓 수 | $(lscpu | grep "^Socket(s):" | awk '{print $NF}') |
| 소켓당 물리 코어 | $(lscpu | grep "Core(s) per socket:" | awk '{print $NF}') |
| 총 물리 코어 | $(echo $(($(lscpu | grep "Core(s) per socket:" | awk '{print $NF}') * $(lscpu | grep "^Socket(s):" | awk '{print $NF}')))) |
| 스레드/코어 (HT) | $(lscpu | grep "Thread(s) per core:" | awk '{print $NF}') |
| 총 논리 CPU | $(lscpu | grep "^CPU(s):" | awk '{print $NF}') |
| 기본 클럭 | $(lscpu | grep "CPU MHz:" | awk '{print $NF}') MHz |
| 최대 클럭 | $(lscpu | grep "CPU max MHz:" | awk '{printf "%.0f", $NF}') MHz |
| L3 캐시 | $(lscpu | grep "L3 cache:" | awk '{print $3, $4}') |
| NUMA 노드 | $(lscpu | grep "NUMA node(s):" | awk '{print $NF}') |
---
## 3. 메모리 정보
| 항목 | 값 |
|------|-----|
| 총 메모리 | $(free -h | awk '/^Mem:/{print $2}') |
| 사용 중 | $(free -h | awk '/^Mem:/{print $3}') |
| 가용 메모리 | $(free -h | awk '/^Mem:/{print $7}') |
| 스왑 총량 | $(free -h | awk '/^Swap:/{print $2}') |
| 스왑 사용 | $(free -h | awk '/^Swap:/{print $3}') |
EOF
# DIMM 슬롯 정보 (root 권한 필요)
if command -v dmidecode &>/dev/null && [ "$(id -u)" = "0" ]; then
echo "### DIMM 슬롯 상세"
echo ""
echo "\`\`\`"
dmidecode -t memory 2>/dev/null | grep -E "(Size|Speed|Type:|Manufacturer|Part Number|Locator)" | \
grep -v "No Module\|Unknown\|Array Handle" | \
sed 's/^\s*//'
echo "\`\`\`"
fi
cat <<EOF
---
## 4. 디스크 정보
### 블록 디바이스 구성
\`\`\`
$(lsblk -o NAME,SIZE,TYPE,FSTYPE,MOUNTPOINT,ROTA 2>/dev/null || lsblk -f)
\`\`\`
### 파일시스템 사용량
\`\`\`
$(df -hT | grep -v "^tmpfs\|^devtmpfs\|^udev")
\`\`\`
---
## 5. 네트워크 인터페이스
\`\`\`
$(ip -brief addr show | grep -v "^lo")
\`\`\`
### 인터페이스 상세 (속도/링크)
| 인터페이스 | IP 주소 | 속도 | 링크 상태 |
|-----------|---------|------|----------|
EOF
for iface in $(ip -brief link show | grep -v "^lo" | awk '{print $1}'); do
iface="${iface%%@*}" # VLAN 인터페이스 "@" 이후 제거
ip_addr=$(ip -brief addr show "$iface" 2>/dev/null | awk '{print $3}')
speed=$(ethtool "$iface" 2>/dev/null | grep "Speed:" | awk '{print $2}')
link=$(ethtool "$iface" 2>/dev/null | grep "Link detected:" | awk '{print $3}')
echo "| $iface | ${ip_addr:-N/A} | ${speed:-N/A} | ${link:-N/A} |"
done
cat <<EOF
---
## 6. 접속 현황
### 현재 접속 사용자
\`\`\`
$(w)
\`\`\`
### 최근 재부팅 이력
\`\`\`
$(last reboot | head -5)
\`\`\`
---
## 7. 부하 현황
| 항목 | 값 |
|------|-----|
| 현재 시각 | $(date) |
| 1분 부하 평균 | $(uptime | awk -F'load average:' '{print $2}' | cut -d',' -f1 | xargs) |
| 5분 부하 평균 | $(uptime | awk -F'load average:' '{print $2}' | cut -d',' -f2 | xargs) |
| 15분 부하 평균 | $(uptime | awk -F'load average:' '{print $2}' | cut -d',' -f3 | xargs) |
| CPU 기준 부하 | $(echo "scale=1; $(uptime | awk -F'load average:' '{print $2}' | cut -d',' -f1 | xargs) / $(lscpu | grep "^CPU(s):" | awk '{print $NF}') * 100" | bc 2>/dev/null || echo "N/A")% |
---
*이 보고서는 server-spec-report.sh 스크립트에 의해 자동 생성되었습니다.*
*생성 시각: $(date -Iseconds)*
EOF
}
# 실행 및 저장
collect_spec | tee "$OUTPUT_FILE"
echo ""
echo "====================================="
echo "보고서 저장 완료: $OUTPUT_FILE"
echo "====================================="
스크립트 사용법:
# 스크립트 저장
sudo curl -o /usr/local/bin/server-spec-report.sh \
https://your-internal-wiki/scripts/server-spec-report.sh
# 또는 직접 위 내용을 복사하여 파일 생성
# 실행 권한 부여
sudo chmod +x /usr/local/bin/server-spec-report.sh
# 실행 (화면 출력 + 파일 저장 동시에)
sudo server-spec-report.sh
# 파일명 지정
sudo server-spec-report.sh prod-web-01-spec.md
# 출력만 보기 (파일 저장 안 함)
sudo server-spec-report.sh /dev/null
11. 핵심 명령어 빠른 참조표
아래 명령어들을 순서대로 실행하여 낯선 서버의 전체 그림을 파악하는 연습을 한다.
1단계: 기본 신원 확인 (1분)
# 이 서버는 어떤 서버인가?
hostnamectl
# OS와 커널
cat /etc/os-release && uname -r
# 얼마나 오래 켜져 있었나?
uptime && last reboot | head -3
2단계: CPU와 메모리 (1분)
# CPU 구성
lscpu | grep -E "^(Architecture|CPU\(s\)|Thread|Core|Socket|Model name|Virtualization)"
# 메모리 현황 (available 컬럼 주목)
free -h
3단계: 디스크 구성 (1분)
# 블록 디바이스 트리
lsblk -f
# 파일시스템 사용량 (tmpfs 제외)
df -hT | grep -vE "^(tmpfs|devtmpfs|udev)"
4단계: 네트워크 (1분)
# IP 주소 목록
ip -brief addr show
# 라우팅 (기본 게이트웨이)
ip route | grep default
# 각 인터페이스 속도 (10G? 1G?)
for i in $(ls /sys/class/net/ | grep -v lo); do
echo -n "$i: "; ethtool $i 2>/dev/null | grep Speed; done
5단계: 현재 상태 (1분)
# 현재 접속 중인 사용자와 하는 일
w
# 시스템 부하 (CPU 수 대비 적절한가?)
uptime
# 최근 주요 시스템 이벤트
sudo journalctl -p err --since "24 hours ago" | tail -20
이 5단계를 익히고 나면 어떤 서버를 받아도 자신감 있게 첫 5분을 보낼 수 있다.
클라우드 VM에서 하드웨어 정보 해석 — 가상 장치 값의 한계
 확대
확대
EC2에서 lscpu를 실행하면 CPU 모델명이 "Intel(R) Xeon(R) Platinum 8175M"처럼 실제 물리 서버 CPU 이름이 나옵니다. 그런데 클라우드 VM의 vCPU 2개는 물리 코어 2개가 아닙니다. 실제로는 하이퍼스레드 1개 또는 공유 물리 코어일 수도 있습니다. dmidecode -t memory를 치면 메모리 슬롯 정보가 "Unknown"으로 가득합니다. 물리 서버와 같은 명령어인데 전혀 다른 의미의 값이 나오므로, 클라우드 VM에서 하드웨어 정보를 볼 때는 숫자의 의미를 다르게 해석해야 합니다.
클라우드 VM에서 lscpu, dmidecode 등의 출력은 실제 물리 하드웨어와 다를 수 있습니다.
클라우드 환경에서 주의할 점:
| 명령어 | 물리 서버 | 클라우드 VM (예: AWS EC2) |
|---|---|---|
lscpu | 실제 CPU 모델 | 가상 CPU (vCPU) 개수, 실제 모델 다를 수 있음 |
dmidecode -t memory | 실제 DIMM 정보 | "Unknown" 또는 가상 메모리 정보 |
lsblk | 실제 디스크 | EBS 볼륨 (네트워크 스토리지) |
ethtool eth0 | 물리 NIC 정보 | 가상 NIC (ENI) |
# AWS EC2에서 실제 인스턴스 정보 조회 (IMDS v2)
TOKEN=$(curl -s -X PUT "http://169.254.169.254/latest/api/token" \
-H "X-aws-ec2-metadata-token-ttl-seconds: 21600")
# 인스턴스 타입 확인 (lscpu보다 정확)
curl -s -H "X-aws-ec2-metadata-token: $TOKEN" \
http://169.254.169.254/latest/meta-data/instance-type
# → r6i.2xlarge (실제 인스턴스 유형)
# 가용 영역 확인
curl -s -H "X-aws-ec2-metadata-token: $TOKEN" \
http://169.254.169.254/latest/meta-data/placement/availability-zone
# GCP 인스턴스 정보
curl -s "http://metadata.google.internal/computeMetadata/v1/instance/machine-type" \
-H "Metadata-Flavor: Google"
스토리지 건강 진단 — SMART·smartctl 활용
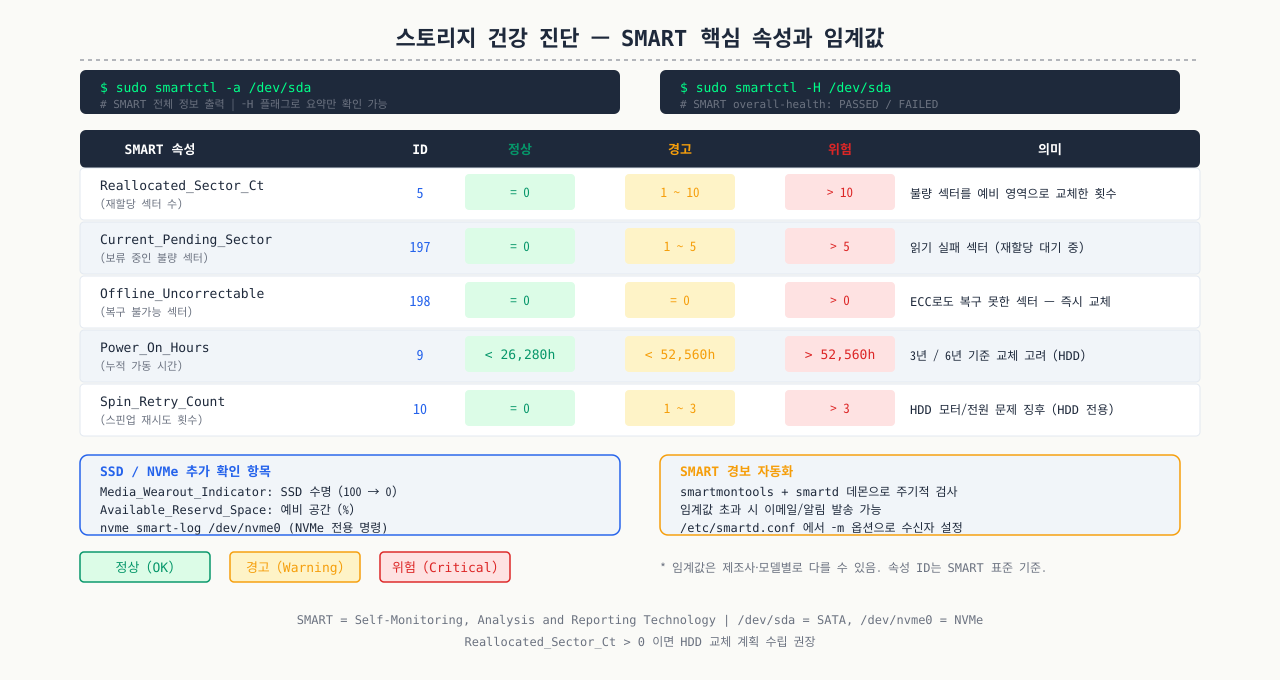 확대
확대
데이터베이스 서버가 갑자기 I/O 오류를 내기 시작했을 때, 이미 디스크는 수일 전부터 불량 섹터가 늘어나는 신호를 보내고 있었던 경우가 많습니다. 모니터링이 없었다면 장애 직전까지 모르다가 데이터 손실로 이어집니다. SMART 데이터를 주기적으로 확인하면 재할당된 섹터 수, 스핀업 실패 횟수 같은 지표로 교체 시점을 미리 예측할 수 있습니다.
디스크 장애는 예고 없이 오지 않습니다. SMART(Self-Monitoring, Analysis and Reporting Technology) 데이터로 미리 감지할 수 있습니다.
# smartctl 설치
sudo apt install smartmontools # Ubuntu/Debian
sudo dnf install smartmontools # RHEL/Rocky
# 디스크 목록 확인
sudo smartctl --scan
# SMART 전체 상태 확인
sudo smartctl -a /dev/sda
# 핵심 항목만 빠르게 확인
sudo smartctl -A /dev/sda | grep -E "Reallocated|Pending|Uncorrectable|Temperature"
# 5 Reallocated_Sector_Ct → 0이 아니면 불량 섹터 존재 (교체 권장)
# 197 Current_Pending_Sector → 0이 아니면 읽기 불안정 섹터
# 198 Offline_Uncorrectable → 0이 아니면 영구 불량 섹터
# SMART 자가 테스트 실행 (단기: 2분, 장기: 1~2시간)
sudo smartctl -t short /dev/sda
sudo smartctl -t long /dev/sda
# 테스트 결과 확인
sudo smartctl -l selftest /dev/sda
# 자동 모니터링 (smartd daemon 설정)
# /etc/smartd.conf
DEVICESCAN -a -o on -S on -n standby,q \
-W 4,45,50 \ # 온도 임계값 (차이, 경고, 위험)
-m admin@example.com \ # 경고 이메일
-M exec /usr/share/smartmontools/smartd-runner
NVMe SSD 확인:
# NVMe 상태 확인 (smartctl과 별도)
sudo nvme smart-log /dev/nvme0
sudo nvme list # NVMe 디바이스 목록
NIC·NUMA·irqbalance — 고성능 서버 튜닝 기초
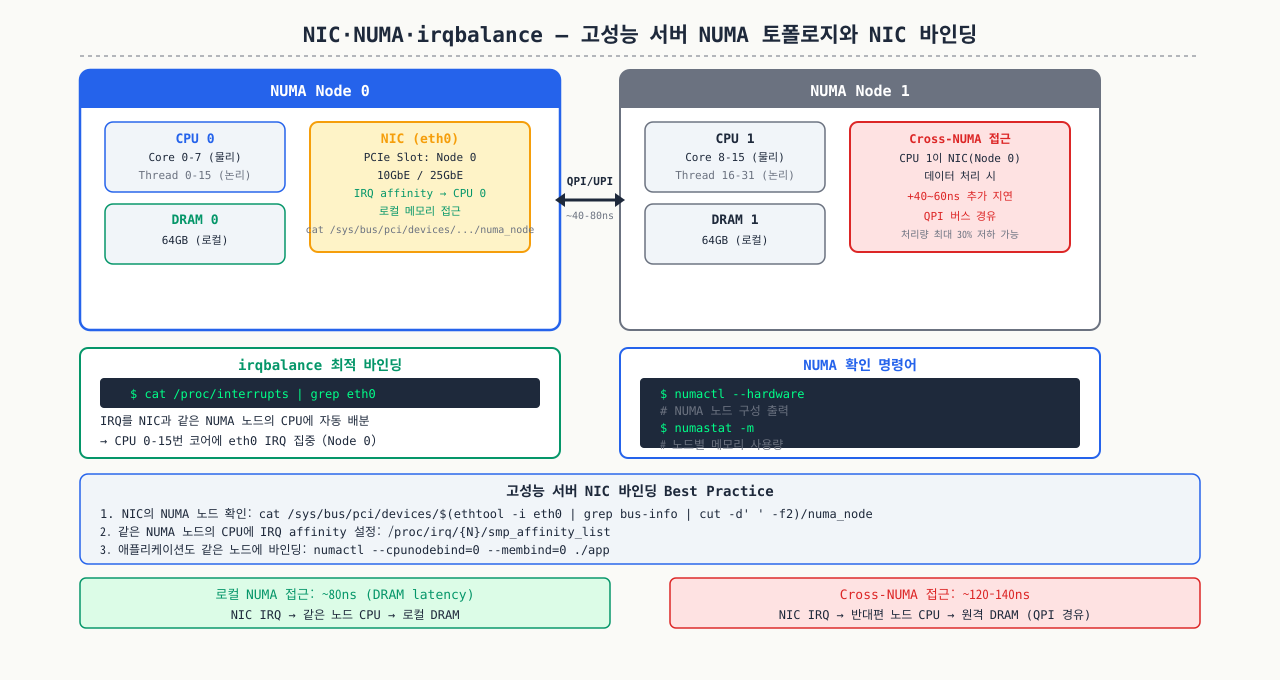 확대
확대
고트래픽 서버에서 CPU 사용률을 보면 CPU 0번만 100%이고 나머지 코어는 한가한 기묘한 상황이 생깁니다. 네트워크 인터럽트가 CPU 0에만 몰리기 때문입니다. irqbalance가 인터럽트를 여러 코어에 분산해 주고, NUMA 아키텍처에서는 NIC가 연결된 CPU 소켓의 로컬 메모리를 쓰느냐 원격 소켓 메모리를 쓰느냐에 따라 레이턴시 차이가 납니다. 하드웨어를 추가해도 성능이 기대만큼 오르지 않는다면 이 인터럽트 분산과 NUMA 토폴로지를 먼저 확인해봐야 합니다.
다중 CPU 소켓 서버나 고트래픽 NIC 환경에서는 인터럽트 분산이 성능에 큰 영향을 미칩니다.
NUMA 토폴로지 확인:
# NUMA 노드 구성 확인
numactl --hardware
# available: 2 nodes (0-1)
# node 0 cpus: 0 1 2 3 4 5 ...
# node 1 cpus: 12 13 14 15 ...
# node 0 size: 32736 MB
# node 1 size: 32768 MB
# 프로세스를 특정 NUMA 노드에 바인딩 (메모리 접근 지연 최소화)
numactl --cpunodebind=0 --membind=0 ./myapp
# NUMA 불균형으로 인한 성능 저하 확인
numastat
# numa_miss가 높으면 다른 노드 메모리를 자주 접근 중 → 성능 저하
NIC 인터럽트 분산 (irqbalance):
# irqbalance 설치 및 상태 확인 (대부분 기본 설치됨)
sudo systemctl status irqbalance
# NIC 인터럽트 현황 확인
cat /proc/interrupts | grep eth0
# 인터럽트가 특정 CPU에 집중되면 bottleneck 발생
# 수동 인터럽트 분산 (RSS가 없는 경우)
# eth0의 인터럽트를 CPU 0~7에 분산
for i in $(seq 0 7); do
IRQ=$(cat /sys/class/net/eth0/device/msi_irqs/ 2>/dev/null | head -1)
echo $i > /proc/irq/$IRQ/smp_affinity_list
done
클라우드 환경: AWS EC2에서는 ENA(Elastic Network Adapter)가 RSS를 지원해 인터럽트가 자동 분산됩니다. irqbalance는 유지하되 별도 튜닝은 대부분 불필요합니다.
정리
이 챕터에서 배운 핵심 명령어들을 한 곳에 정리한다:
| 목적 | 명령어 | 주요 옵션 |
|---|---|---|
| CPU 구성 | lscpu | 기본 실행 |
| CPU 상세 | cat /proc/cpuinfo | grep "model name" |
| 메모리 현황 | free | -h (사람 읽기 쉬운 단위) |
| 메모리 상세 | cat /proc/meminfo | grep MemAvailable |
| 디스크 구성 | lsblk | -f (파일시스템 포함) |
| 파일시스템 사용량 | df | -hT (타입 포함) |
| 네트워크 IP | ip addr | -brief addr show |
| NIC 속도 | ethtool | ethtool eth0 |
| OS 정보 | cat /etc/os-release | . /etc/os-release && echo $PRETTY_NAME |
| 커널 버전 | uname | -r (버전만), -a (전체) |
| 호스트 정보 | hostnamectl | 기본 실행 |
| 하드웨어 상세 | dmidecode | -t system, -t memory |
| PCI 장치 | lspci | grep -i ethernet |
| 하드웨어 목록 | lshw | -short, -class disk |
| 가동 시간 | uptime | -p (사람 읽기 쉽게) |
| 접속 사용자 | w | 기본 실행 |
| 재부팅 이력 | last reboot | head -5 |
관련 모듈로 더 깊이:
- sysctl 커널 파라미터 튜닝으로 대규모 트래픽 처리 성능 높이기 — 파악한 하드웨어 자원을 sysctl/ulimit로 활용하는 다음 단계
- vmstat, iostat, sar로 CPU/디스크 IO 성능 병목 진단 — 하드웨어 스펙 위에서 실시간 자원 사용량을 추적하는 법
- 서버 다운 시 신속하게 CPU/메모리/네트워크/로그 확인하는 룰 — 하드웨어 한계가 장애로 드러날 때 빠르게 원인을 좁히는 법
다음 모듈에서는 커널 파라미터 튜닝으로 파악한 하드웨어 자원을 최대한 활용할 수 있도록 sysctl과 ulimit를 실무 환경에 맞게 설정하는 방법을 다룹니다.