새벽 2시, 모니터링 대시보드에 빨간 알림이 켜집니다. "nginx 500 에러율 급등 — 결제 API 영향 가능." Slack에는 "지금 얼마나 심각해요?"라는 메시지가 쌓이고 있습니다. /var/log/nginx/access.log를 열었더니 수백만 줄. 눈으로 읽는 건 불가능합니다.
grep, awk, sed를 파이프로 엮는 법을 알면 30초 안에 "203.0.113.42에서 분당 500 에러 47건, /api/payment 집중"이라는 답이 나옵니다.
텍스트 처리 (grep/awk/sed)
프로덕션 서버에서 장애가 발생했습니다. /var/log/nginx/access.log에는 수백만 줄의 로그가 쌓여 있고, 상사는 "지금 HTTP 500 에러가 얼마나 나고 있어?" 라고 묻습니다. 이때 필요한 것이 바로 리눅스 텍스트 처리 3대 도구입니다.
grep, awk, sed는 단순한 명령어가 아닙니다. 이 세 도구를 파이프(|)로 연결하면 수백만 줄의 로그를 1초 안에 분석하고, SSH 무차별 대입 공격의 출처 IP를 추출하고, 설정 파일을 일괄 수정할 수 있습니다. 이 챕터를 마치면 로그 파일 앞에서 더 이상 당황하지 않을 것입니다.
- 1표준 스트림(stdin/stdout/stderr)과 파이프 동작 원리를 이해하고 데이터 흐름을 설계할 수 있다
- 2grep 정규표현식으로 수백만 줄 로그에서 원하는 패턴을 정밀하게 추출할 수 있다
- 3awk로 구조화된 로그에서 필드별 집계와 통계를 한 줄 명령으로 만들 수 있다
- 4sed로 설정 파일과 로그를 일괄 치환·삭제할 수 있다
- 5grep/awk/sed/sort/jq를 파이프로 연결해 SSH 공격 IP 탐지와 HTTP 에러율 분석을 수행할 수 있다
cat > /tmp/sample.log << 'EOF'
...(샘플 내용)...
EOFgrep --version && awk --version && sed --versionsudo dnf install -y jq # RHEL/CentOS 계열/tmp 디렉토리를 실습 공간으로 활용하며, 생성한 임시 파일은 실습 후 정리합니다
표준 입출력과 파이프 — 데이터 흐름의 기본 원리
 확대
확대
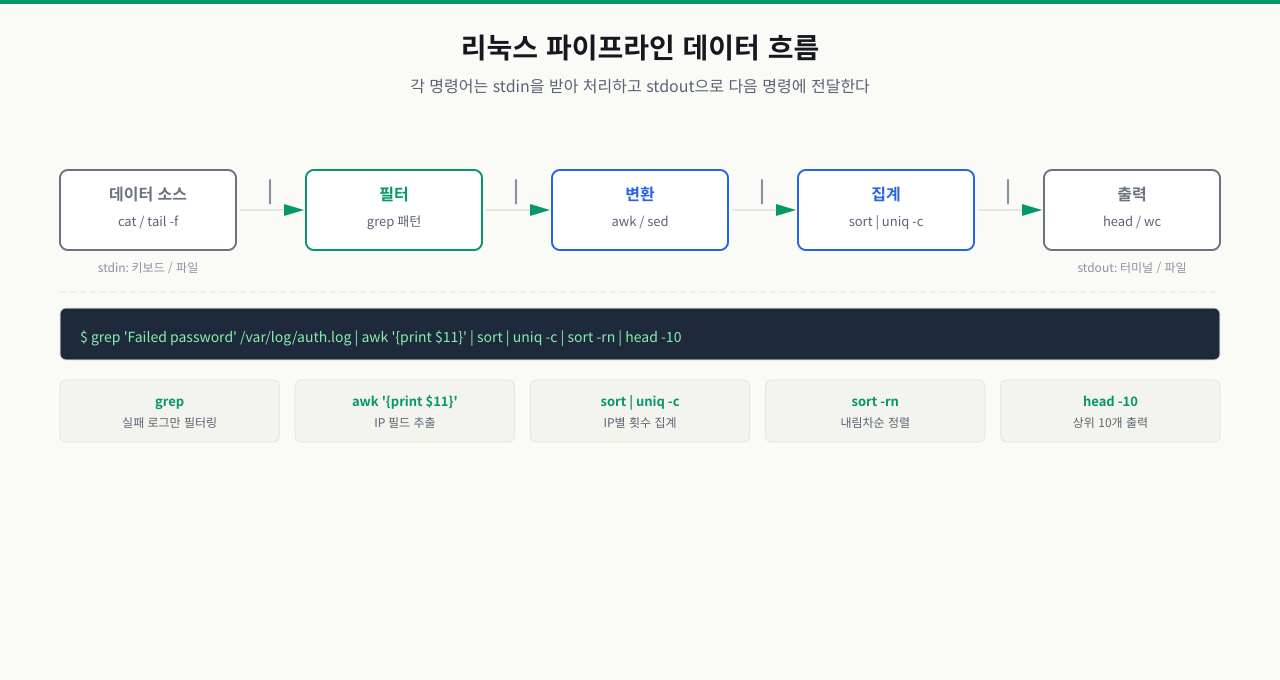
로그 파일에서 특정 패턴을 찾아 에러 수를 세고 이메일로 보내야 하는 업무를 받았을 때, 당장 Python 스크립트를 짜거나 로그를 전부 내려받아야 한다고 생각하기 쉽습니다. 하지만 셸에서 grep "ERROR" app.log | wc -l로 끝낼 수 있습니다. 이것이 가능한 이유는 리눅스의 모든 도구가 표준 입출력 스트림을 공유하고 파이프(|)로 연결되기 때문입니다. 이 원리를 이해하면 grep, awk, sed 같은 도구들을 조합해 복잡한 로그 분석을 한 줄 명령으로 처리할 수 있습니다.
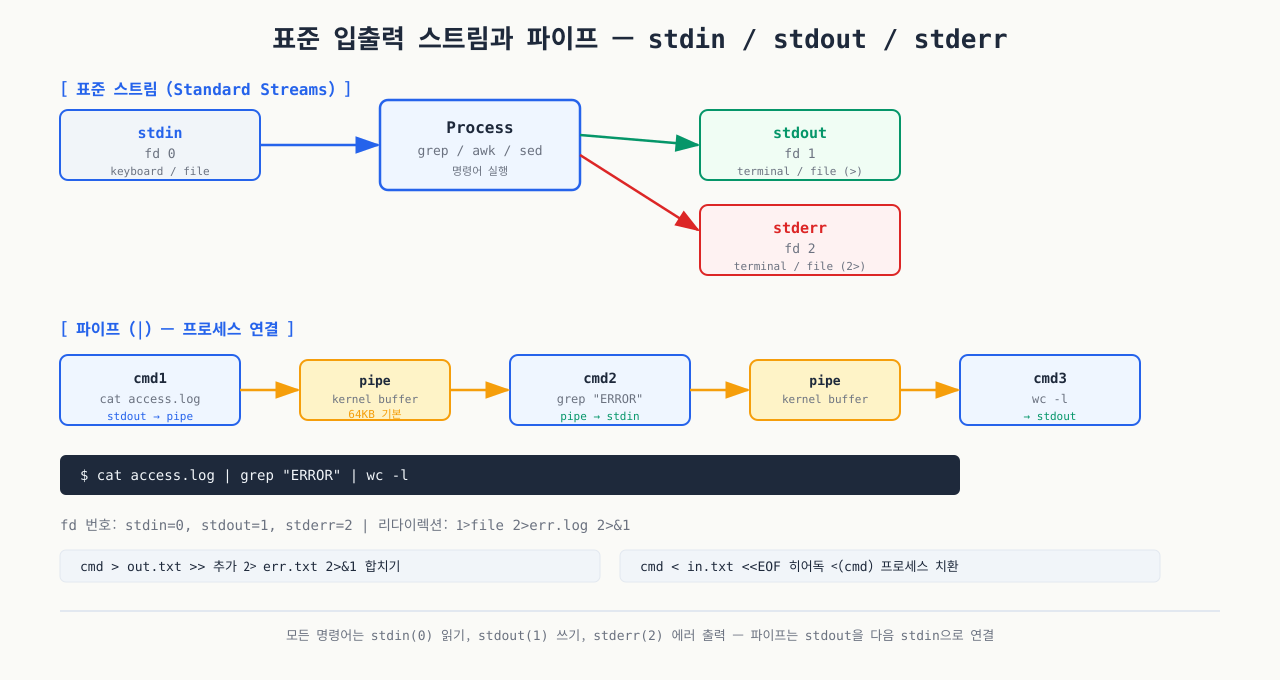
리눅스의 모든 텍스트 처리 도구는 표준 스트림(Standard Streams) 위에서 동작합니다. 이 개념을 이해하지 않으면 파이프라인이 왜 작동하는지 알 수 없습니다.
세 가지 표준 스트림 — 모든 Linux 프로세스는 stdin/stdout/stderr 세 채널로 입출력을 처리합니다:
| 스트림 | 번호 | 기호 | 역할 |
|---|---|---|---|
| stdin (표준 입력) | 0 | < | 명령어가 데이터를 읽는 곳. 기본값: 키보드 |
| stdout (표준 출력) | 1 | > | 명령어가 정상 결과를 내보내는 곳. 기본값: 터미널 |
| stderr (표준 에러) | 2 | 2> | 에러 메시지를 내보내는 곳. 기본값: 터미널 |
파이프(|)의 원리:
파이프는 왼쪽 명령어의 stdout을 오른쪽 명령어의 stdin으로 연결합니다. 파일을 임시로 저장하지 않고 메모리에서 데이터를 직접 전달하기 때문에 빠릅니다.
# 파이프 없이: 임시 파일 경유
grep "ERROR" /var/log/app.log > /tmp/errors.txt
wc -l /tmp/errors.txt
rm /tmp/errors.txt
# 파이프 사용: 메모리에서 직접 전달 (훨씬 효율적)
grep "ERROR" /var/log/app.log | wc -l
리다이렉션과 조합 — >, >>, 2>, &> 연산자로 출력을 파일이나 다른 스트림으로 보냅니다:
# stdout을 파일로 저장하면서 동시에 stderr도 같은 파일로
command > output.txt 2>&1
# stdout과 stderr를 분리해서 저장
command > output.txt 2> error.txt
# /dev/null: 블랙홀 — 출력을 버릴 때
command > /dev/null 2>&1
# 파이프라인 중간에 파일 저장 (tee)
grep "ERROR" app.log | tee errors.txt | wc -l
# errors.txt에도 저장되고, 동시에 wc -l로도 전달됨
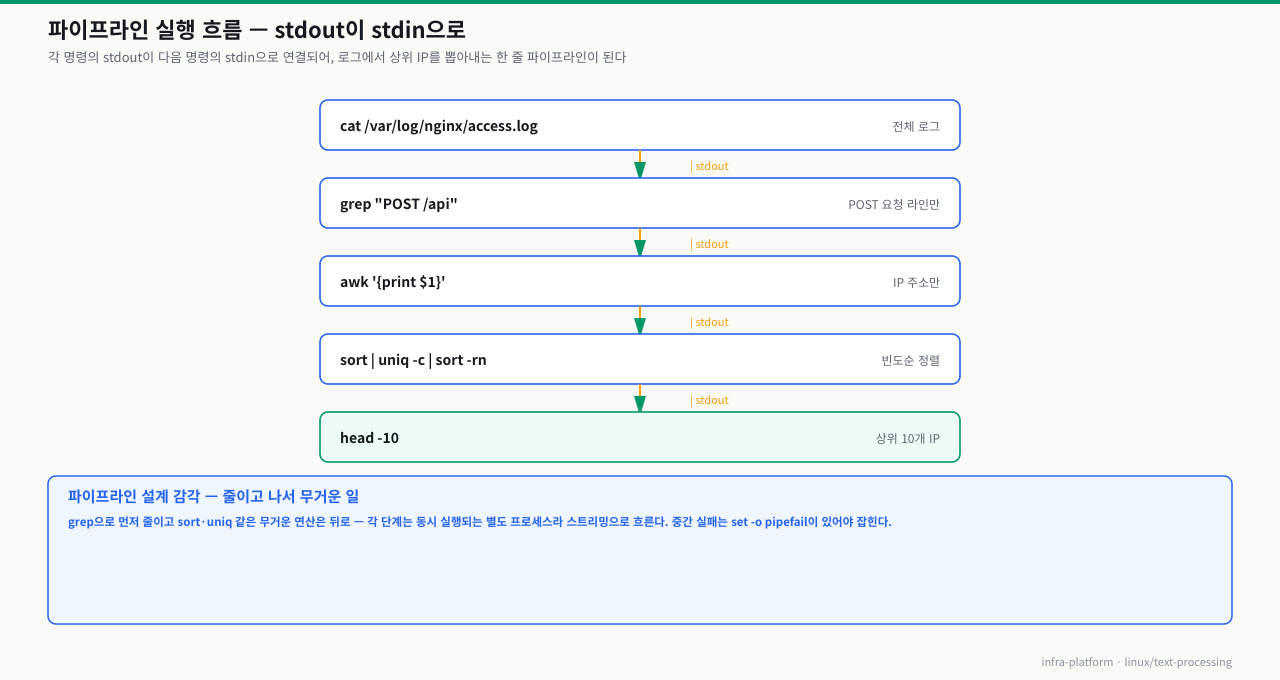
파이프라인 실행 흐름 시각화 — 각 명령이 앞 명령의 출력을 입력으로 받아 연결되는 구조입니다:
 확대
확대
각 도구는 자신이 받은 stdin을 처리하고 stdout으로 내보내기만 합니다. 이 단순한 규칙이 수십 개의 명령어를 조합할 수 있게 만듭니다.
 확대
확대
grep · awk · sort · uniq 한 줄이 실제로 어떻게 흐르나 — 소스에서 최종 출력까지 6단계
grep "Failed password" auth.log | awk '{print $NF}' | sort | uniq -c | sort -rn 한 줄. Enter를 누르면 수백만 줄짜리 로그가 몇 초 만에 "IP별 실패 횟수, 많은 순" 표로 바뀝니다. 이 짧은 순간에 데이터는 파일에서 읽혀 → 걸러지고 → 필드가 뽑히고 → 정렬되고 → 집계되어 → 다시 정렬됩니다. 각 명령은 앞 명령의 출력을 파이프로 넘겨받아 자기 일만 하고 넘깁니다. 이 흐름을 알면 "파이프라인이 왜 멈췄지", "큰 파일에서 왜 터졌지"를 단계로 좁힐 수 있습니다.
auth.log (수백만 줄)
│
① grep "Failed password" 한 줄씩 읽어 매칭 줄만 통과, 나머지는 버림
│ stdout ↓
② 파이프 = 커널 버퍼(64KB) grep가 쓰고 awk가 당겨감. 버퍼 차면 grep 잠깐 멈춤(배압)
│ stdin ↓
③ awk '{print $NF}' 각 줄을 필드로 쪼개 마지막 필드(IP)만 출력
│ stdout ↓
④ sort ★ 흐름이 멈추는 벽 — 전부 받아야 정렬 가능(블로킹)
│ stdout ↓
⑤ uniq -c 인접한 같은 줄을 세어 "횟수 값"으로 (그래서 ④가 앞)
│ stdout ↓
⑥ sort -rn 횟수 기준 숫자 내림차순 → 최종 출력
▼
터미널: 47 203.0.113.42
9 198.51.100.7
각 단계가 하는 일과, 스트리밍인지·어디서 막히는지:
| 단계 | 하는 일 | 스트리밍이냐 · 주의점 |
|---|---|---|
| ① grep 필터 | 파일을 한 줄씩 읽어 패턴에 맞는 줄만 stdout으로 내보내고 나머지는 버림 | 스트리밍 — 수백만 줄이어도 한 줄분 메모리만 씀. 큰 파일에 안전 |
| ② 파이프(커널 버퍼) | 앞 명령 stdout을 커널 파이프 버퍼(기본 64KB)에 담고 뒤 명령 stdin이 당겨감 | 파일 안 거치고 메모리 직결이라 빠름. 버퍼가 차면 앞 명령이 잠깐 멈춰(배압) 느린 뒤 명령에 자동으로 맞춤 |
| ③ awk 필드 추출 | 각 줄을 공백 기준 필드로 쪼개 원하는 열($1·$NF 등)만 출력 | 스트리밍 — 줄 단위로 바로 통과. grep+awk까지는 입력이 아무리 커도 일정 메모리 |
| ④ sort | 들어온 것을 정렬. 정렬하려면 마지막 줄까지 다 받아야 해 여기서 스트림이 멈춤 | 블로킹 — 앞 출력을 전부 모음. 입력이 메모리보다 크면 /tmp에 임시파일(외부 정렬) |
| ⑤ uniq -c | 인접한 같은 줄을 하나로 합치고 반복 횟수를 셈 | 인접 중복만 보므로 반드시 ④ sort가 앞. sort 없이 uniq면 떨어져 있는 중복을 못 셈 |
| ⑥ sort -rn | 앞의 "횟수 · 값" 두 열을 숫자(-n) 내림차순(-r)으로 재정렬 → 출력 | 블로킹(다시 전체 정렬). 상위 몇 개만 필요하면 뒤에 head를 붙여 잘라냄 |
즉 파이프라인은 한 줄씩 흘려보내는 필터(grep·awk)와, 전부 모아야 하는 벽(sort) 의 조합입니다. grep·awk는 입력이 아무리 커도 일정 메모리로 스트리밍하지만, sort는 마지막 줄까지 받아야 첫 출력을 낼 수 있어 여기서 메모리·/tmp를 씁니다. 그래서 파이프라인이 아무 출력 없이 멈춰 보이면 대개 sort 같은 블로킹 단계가 EOF(입력 끝)를 기다리는 것이고, 거대한 파일에서 No space left on device로 죽으면 sort의 임시파일이 /tmp를 채운 것입니다. 그리고 uniq가 이상하게 중복을 못 세면 십중팔구 앞에 sort를 빠뜨린 순서 문제입니다.
grep 심화 — 텍스트에서 패턴 찾기
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/linux/part2/exam_7 && cd /tmp/linux/part2/exam_7
# 실습용 웹 서버 액세스 로그 생성
cat > /tmp/linux/part2/exam_7/access.log << 'EOF'
192.168.1.10 - alice [01/Jan/2024:10:00:01] "GET /index.html" 200 2048
192.168.1.20 - bob [01/Jan/2024:10:00:15] "POST /api/login" 401 512
192.168.1.10 - alice [01/Jan/2024:10:01:02] "GET /dashboard" 200 8192
10.0.0.5 - - [01/Jan/2024:10:01:30] "GET /health" 200 64
192.168.1.30 - charlie [01/Jan/2024:10:02:00] "DELETE /api/user/99" 403 256
192.168.1.20 - bob [01/Jan/2024:10:02:45] "POST /api/login" 200 1024
10.0.0.5 - - [01/Jan/2024:10:03:00] "GET /health" 200 64
192.168.1.40 - dave [01/Jan/2024:10:03:10] "PUT /api/config" 500 2048
EOF
# 실습용 CSV 파일 생성
cat > /tmp/linux/part2/exam_7/users.csv << 'EOF'
id,name,role,dept
1,alice,admin,infra
2,bob,developer,backend
3,charlie,developer,frontend
4,dave,ops,infra
5,eve,manager,product
EOF
이제 실습을 진행합니다.
grep은 "Global Regular Expression Print"의 약자입니다. 파일이나 stdin에서 패턴과 일치하는 줄을 출력합니다.
실습용 샘플 로그 파일 생성 — 실습에 사용할 테스트 로그 파일을 만듭니다:
cat > /tmp/sample.log << 'EOF'
2024-01-15 08:23:11 INFO User login: alice@example.com from 192.168.1.10
2024-01-15 08:24:02 ERROR Failed login attempt: bob@example.com from 10.0.0.55
2024-01-15 08:24:45 INFO User login: charlie@example.com from 192.168.1.22
2024-01-15 08:25:13 ERROR Failed login attempt: ADMIN from 203.0.113.42
2024-01-15 08:25:58 WARN Rate limit exceeded for 203.0.113.42
2024-01-15 08:26:30 ERROR Failed login attempt: root from 203.0.113.42
2024-01-15 08:27:01 INFO User login: dave@example.com from 192.168.1.15
2024-01-15 08:28:44 ERROR Failed login attempt: administrator from 198.51.100.7
2024-01-15 08:29:10 INFO Password reset: alice@example.com
2024-01-15 08:30:55 ERROR Connection timeout: database server unreachable
EOF
핵심 옵션별 실습 — -i, -n, -c, -v 등 grep 핵심 옵션을 하나씩 확인합니다:
# -i: 대소문자 무시 (case Insensitive)
grep -i "error" /tmp/sample.log
# "ERROR", "Error", "error" 모두 매칭
# -v: 반전 (inVert) — 패턴이 없는 줄 출력
grep -v "INFO" /tmp/sample.log
# INFO가 없는 줄, 즉 ERROR와 WARN 줄만 출력
# -c: 카운트 (Count) — 매칭된 줄 수만 출력
grep -c "ERROR" /tmp/sample.log
# 출력: 5
# -n: 라인번호 (liNe number) 함께 출력
grep -n "Failed login" /tmp/sample.log
# 출력:
# 2:2024-01-15 08:24:02 ERROR Failed login attempt: bob@example.com from 10.0.0.55
# 4:2024-01-15 08:25:13 ERROR Failed login attempt: ADMIN from 203.0.113.42
# 6:2024-01-15 08:26:30 ERROR Failed login attempt: root from 203.0.113.42
# 8:2024-01-15 08:28:44 ERROR Failed login attempt: administrator from 198.51.100.7
# -r: 디렉토리 재귀 탐색 (Recursive)
grep -r "database" /tmp/
# /tmp/ 아래 모든 파일에서 "database" 검색
컨텍스트 옵션 — 주변 줄도 함께 보기 — 매칭 줄 위아래 N줄을 함께 출력해 문맥을 파악합니다:
# -A 3: 매칭 줄 이후(After) 3줄
grep -A 2 "Rate limit" /tmp/sample.log
# -B 2: 매칭 줄 이전(Before) 2줄
grep -B 1 "Connection timeout" /tmp/sample.log
# -C 2: 전후 2줄 (Context)
grep -C 1 "WARN" /tmp/sample.log
- 먼저 grep -c ERROR /tmp/sample.log 로 에러 줄 수를 확인한다 — 그 다음 grep -c ERROR /tmp/sample.log 와 grep ERROR /tmp/sample.log | wc -l 을 비교한다. 두 값이 다르면 grep -c 는 매칭된 파일 수를 세고 wc -l 은 줄 수를 세는 차이가 있기 때문이다
- grep -v INFO /tmp/sample.log | wc -l 로 INFO를 제외한 줄 수를 확인한다 — 전체 줄 수(wc -l /tmp/sample.log)에서 이 값을 빼면 INFO 줄이 몇 개인지 나온다. 비율이 90% 이상이면 로그 레벨이 과도하게 상세한 것이다
- sed -i 's/ERROR/CRITICAL/g' 는 인자 파일을 즉시 덮어쓴다 — 백업 없이 실행하면 원본을 복구할 수 없다. sed -i.bak 처럼 확장자를 붙이면 .bak 백업 파일이 자동 생성된다. 프로덕션 설정 파일에는 반드시 -i.bak 옵션을 쓴다
grep -E(또는 egrep)는 확장 정규표현식(ERE)을 사용합니다. 단순 문자열 검색을 넘어 패턴으로 매칭할 수 있습니다.
정규표현식 핵심 문법 — grep -E 옵션과 함께 사용하는 주요 메타문자 표입니다:
| 패턴 | 의미 | 예시 |
|---|---|---|
. | 임의의 문자 1개 | 20..-01 → 2001-01, 2024-01 등 |
* | 앞 문자 0회 이상 반복 | lo*g → lg, log, looog |
+ | 앞 문자 1회 이상 반복 | lo+g → log, looog (lg 제외) |
? | 앞 문자 0 또는 1회 | colou?r → color, colour |
[] | 문자 클래스 | [0-9] → 숫자 한 자리 |
^ | 줄의 시작 | ^2024 → 2024로 시작하는 줄 |
$ | 줄의 끝 | timeout$ → timeout으로 끝나는 줄 |
\b | 단어 경계 | \broot\b → root (프로덕트, 루트 등 제외) |
| | OR (기본 grep) | ERROR|WARN |
| ` | ` | OR (grep -E) |
실습 — 정규표현식 패턴이 실제로 어떻게 매칭되는지 확인합니다:
# IP 주소 패턴 매칭
grep -E "[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}" /tmp/sample.log
# 203.0.113.42에서 온 모든 로그 (공격자 IP 추적)
grep -E "203\.0\.113\.42" /tmp/sample.log
# ERROR 또는 WARN 줄만 추출
grep -E "ERROR|WARN" /tmp/sample.log
# 이메일 주소가 포함된 줄
grep -E "[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}" /tmp/sample.log
# 줄의 시작이 2024-01-15 08:2로 시작하는 줄 (특정 분대 로그)
grep "^2024-01-15 08:2[4-9]" /tmp/sample.log
# "root" 또는 "admin" 계정 시도 (단어 경계 사용)
grep -E "\b(root|admin|administrator|ADMIN)\b" /tmp/sample.log
실전 패턴 — SSH 인증 로그에서 비밀번호 실패 추출 — 현업에서 가장 자주 쓰는 grep 패턴입니다:
# /var/log/auth.log 또는 /var/log/secure 형식
# 실제 SSH 실패 로그 형식:
# Jan 15 08:24:02 hostname sshd[1234]: Failed password for root from 203.0.113.42 port 22 ssh2
grep -E "Failed password for .+ from [0-9.]+" /var/log/auth.log 2>/dev/null || \
grep -E "Failed password for .+ from [0-9.]+" /var/log/secure 2>/dev/null
awk — 구조화된 텍스트의 외과적 분석
 확대
확대
grep으로 특정 에러 줄을 찾았는데, 그 줄에서 IP 주소만 뽑거나 응답 시간 컬럼만 합산해야 할 때 grep으로는 더 이상 진행이 안 됩니다. 이때 awk가 등장합니다. 공백 기준으로 나뉜 텍스트에서 "3번째 컬럼만 출력", "특정 조건에 맞는 행의 5번째 컬럼을 합산" 같은 작업을 한 줄로 처리할 수 있습니다. ps aux나 df -h 출력에서 원하는 수치만 추출하거나, 수백만 줄의 액세스 로그에서 응답 코드별 집계를 내는 것이 모두 awk 한 줄로 가능합니다.
awk는 단순한 명령어가 아니라 프로그래밍 언어입니다. 필드(열) 단위로 텍스트를 처리하는 데 특화되어 있으며, 로그 분석부터 보고서 생성까지 폭넓게 쓰입니다.
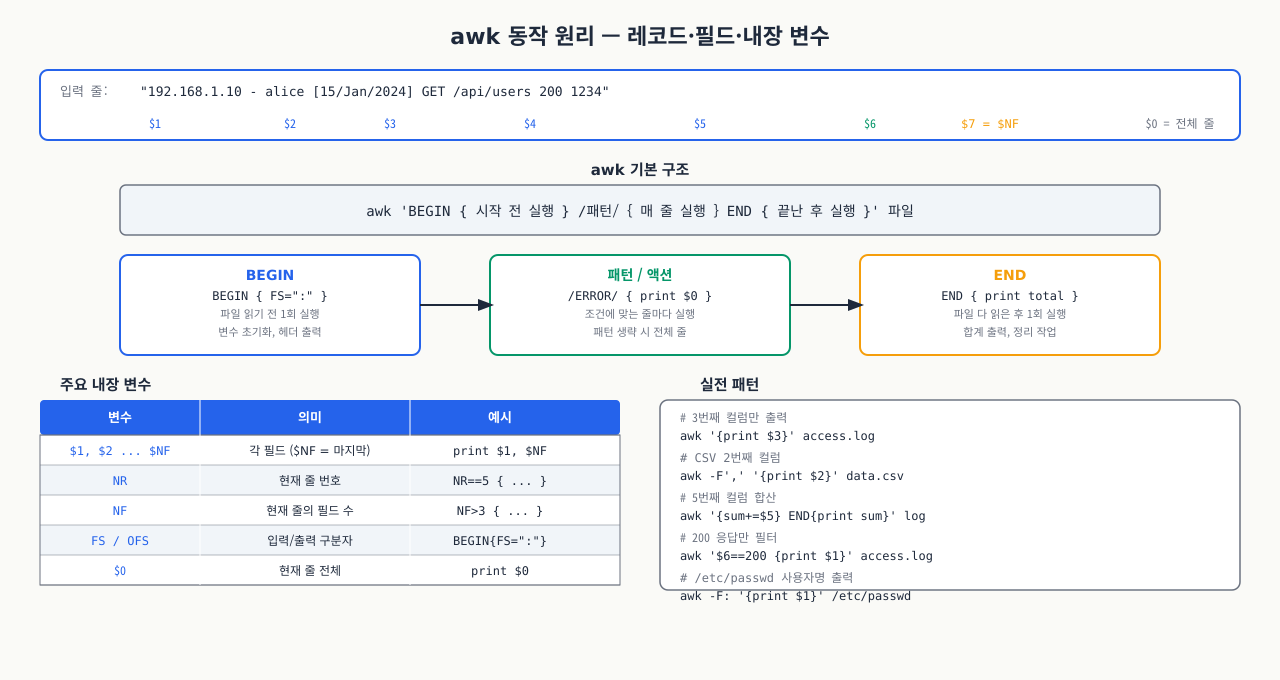
awk의 동작 원리:
awk는 입력을 한 줄씩 읽으면서 각 줄을 **레코드(record)**로, 공백(또는 지정한 구분자)을 기준으로 나눈 각 단어를 **필드(field)**로 처리합니다.
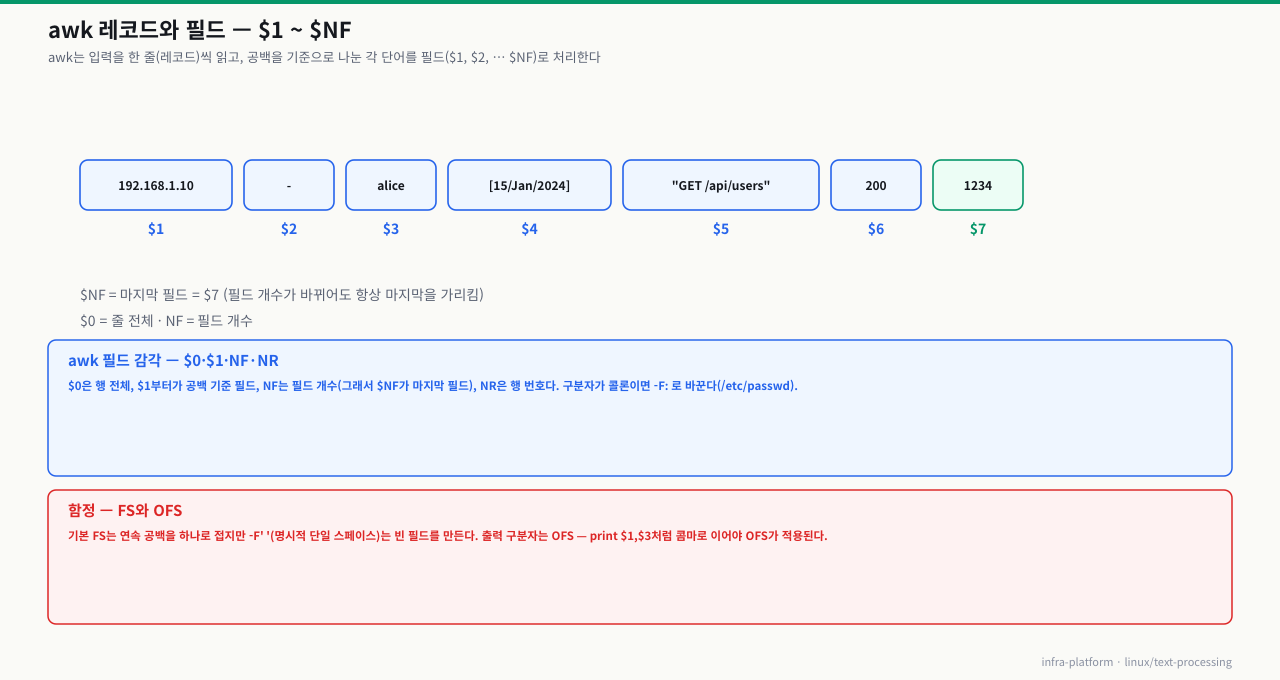 확대
확대
기본 문법 구조 — awk는 패턴과 액션으로 구성되며, 각 줄을 순서대로 처리합니다:
awk 'BEGIN { 시작 전 실행 } /패턴/ { 매 줄 실행 } END { 끝난 후 실행 }' 파일
필드 구분자 지정 — -F 옵션으로 CSV, 콜론 구분 파일 등 다양한 형식을 처리합니다:
# 기본: 공백/탭
awk '{print $1}' file.log
# -F로 구분자 지정
awk -F: '{print $1}' /etc/passwd # : 구분
awk -F',' '{print $2}' data.csv # , 구분 (CSV)
awk -F'\t' '{print $3}' data.tsv # 탭 구분
주요 내장 변수 — awk가 자동으로 설정하는 변수들로 필드 수, 구분자, 줄 번호를 다룹니다:
| 변수 | 의미 | 예시 |
|---|---|---|
$0 | 현재 줄 전체 | awk '{print $0}' (cat과 동일) |
$1, $2 ... | 각 필드 | $1: 첫 번째 필드 |
$NF | 마지막 필드 | 필드 수가 줄마다 달라도 항상 마지막 |
NR | 현재 줄 번호 | NR==5: 5번째 줄만 처리 |
NF | 현재 줄의 필드 수 | NF>3: 필드가 3개 이상인 줄 |
FS | 입력 구분자 | BEGIN{FS=":"} |
OFS | 출력 구분자 | BEGIN{OFS=","} |
RS | 레코드 구분자 | 기본값: 줄바꿈 |
실습용 Nginx 액세스 로그 생성 — awk 실습에 사용할 Nginx 형식의 액세스 로그를 만듭니다:
cat > /tmp/access.log << 'EOF'
192.168.1.10 - alice [15/Jan/2024:08:23:11 +0900] "GET /api/users HTTP/1.1" 200 1543
10.0.0.55 - - [15/Jan/2024:08:24:02 +0900] "POST /login HTTP/1.1" 401 89
192.168.1.22 - charlie [15/Jan/2024:08:24:45 +0900] "GET /dashboard HTTP/1.1" 200 8921
203.0.113.42 - - [15/Jan/2024:08:25:13 +0900] "GET /admin HTTP/1.1" 403 156
192.168.1.15 - dave [15/Jan/2024:08:27:01 +0900] "POST /api/orders HTTP/1.1" 201 2341
198.51.100.7 - - [15/Jan/2024:08:28:44 +0900] "GET /wp-admin HTTP/1.1" 404 189
192.168.1.10 - alice [15/Jan/2024:08:29:10 +0900] "GET /api/products HTTP/1.1" 200 4521
203.0.113.42 - - [15/Jan/2024:08:30:55 +0900] "POST /login HTTP/1.1" 500 67
192.168.1.22 - charlie [15/Jan/2024:08:31:20 +0900] "DELETE /api/users/5 HTTP/1.1" 204 0
10.0.0.55 - - [15/Jan/2024:08:32:01 +0900] "GET /api/users HTTP/1.1" 200 1543
EOF
기본 필드 추출 — $1, $NF 등 필드 변수로 원하는 컬럼만 꺼냅니다:
# IP 주소만 추출 ($1)
awk '{print $1}' /tmp/access.log
# HTTP 상태 코드 추출 ($9)
awk '{print $9}' /tmp/access.log
# IP와 상태 코드만 출력
awk '{print $1, $9}' /tmp/access.log
# 출력 구분자를 탭으로 변경
awk 'BEGIN{OFS="\t"} {print $1, $7, $9}' /tmp/access.log
조건 처리 — 특정 상태 코드 필터링 — 패턴 조건을 걸어 HTTP 500 같은 에러만 걸러냅니다:
# HTTP 200이 아닌 요청만 출력
awk '$9 != "200"' /tmp/access.log
# HTTP 500 에러만 출력
awk '$9 == "500" {print $1, $7, $9}' /tmp/access.log
# 4xx, 5xx 에러 (상태 코드 400 이상)
awk '$9 >= 400 {print $1, $6, $7, $9}' /tmp/access.log
# 응답 크기가 1000 바이트 이상인 요청 ($10이 응답 바이트)
awk '$10 >= 1000 {print $1, $7, $9, $10, "bytes"}' /tmp/access.log
BEGIN / END 블록 — 합계와 통계 — BEGIN은 첫 줄 처리 전, END는 마지막 줄 처리 후 실행됩니다:
# 전체 요청 수와 200 성공 수 카운트
awk 'BEGIN{total=0; ok=0}
{total++; if($9=="200") ok++}
END{print "전체 요청:", total, "/ 성공(200):", ok, "/ 성공률:", int(ok/total*100)"%"}' \
/tmp/access.log
# 출력: 전체 요청: 10 / 성공(200): 4 / 성공률: 40%
# 특정 IP의 요청 횟수 세기
awk '{count[$1]++}
END{for(ip in count) print count[ip], ip}' /tmp/access.log | sort -rn
문자열 함수 활용 — length(), substr(), gsub() 등 awk 내장 문자열 함수를 씁니다:
# 날짜/시간 필드에서 시간만 추출 ([15/Jan/2024:08:23:11 에서 08:23:11)
awk '{split($4, t, ":"); print t[2]":"t[3]":"t[4]}' /tmp/access.log
# HTTP 메서드 추출 ("GET /api/users HTTP/1.1" 에서 GET)
awk '{gsub(/"/, "", $6); print $6}' /tmp/access.log
sed — 스트림 편집기
sed(Stream EDitor)는 파이프라인에서 텍스트를 변환할 때 사용합니다. 파일을 직접 열지 않고 스트림을 통해 수정합니다.
기본 문법 — sed는 스트림 편집기로, 파일을 열지 않고 파이프라인에서 텍스트를 변환합니다:
sed '[범위][명령][옵션]' 파일
치환 명령 s — 가장 많이 쓰는 sed 기능 — s/찾을패턴/바꿀텍스트/플래그 형식으로 텍스트를 치환합니다:
# 기본 치환: s/찾을패턴/바꿀내용/플래그
# 각 줄의 첫 번째 ERROR를 [ERROR]로
sed 's/ERROR/[ERROR]/' /tmp/sample.log
# g 플래그: 줄 내 모든 패턴 치환 (global)
sed 's/ERROR/[ERROR]/g' /tmp/sample.log
# i 플래그: 대소문자 무시
sed 's/error/[ERROR]/gi' /tmp/sample.log
# 구분자를 / 외에도 사용 가능 (경로 치환 시 편리)
sed 's|/old/path|/new/path|g' config.txt
sed 's,/usr/local,/opt,g' config.txt
# 정규표현식 사용
sed 's/[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}/[REDACTED]/g' /tmp/sample.log
# -i 옵션: 파일을 직접 수정 (in-place)
sed -i 's/old_password/new_password/g' config.ini
# -i.bak: 백업 파일 만들면서 직접 수정
sed -i.bak 's/DEBUG/INFO/g' app.properties
줄 삭제 명령 d — 패턴에 매칭되는 줄이나 특정 범위의 줄을 제거합니다:
# 주석 줄 삭제 (# 로 시작하는 줄)
sed '/^#/d' config.txt
# 빈 줄 삭제
sed '/^$/d' config.txt
# INFO 로그 줄 삭제 (ERROR와 WARN만 남기기)
sed '/INFO/d' /tmp/sample.log
# 빈 줄과 주석 줄 동시 삭제
sed '/^#/d; /^$/d' config.txt
# 특정 줄 번호 삭제 (5번째 줄 삭제)
sed '5d' file.txt
# 범위 삭제 (3번째~7번째 줄)
sed '3,7d' file.txt
라인 선택 명령 p — -n 옵션과 함께 써서 원하는 줄만 출력합니다:
# -n 옵션과 함께: 매칭된 줄만 출력 (grep과 유사)
sed -n '/ERROR/p' /tmp/sample.log
# 줄 번호로 선택
sed -n '3,5p' /tmp/sample.log # 3~5번째 줄만 출력
sed -n '1p' /tmp/sample.log # 첫 번째 줄만
# 마지막 줄
sed -n '$p' /tmp/sample.log
# 패턴 사이 줄 추출
sed -n '/START/,/END/p' file.txt
여러 명령 조합 — -e 옵션이나 세미콜론으로 여러 sed 명령을 한 번에 실행합니다:
# -e 로 여러 명령 결합
sed -e 's/ERROR/[ERROR]/g' -e '/^$/d' /tmp/sample.log
# 세미콜론으로 구분
sed 's/ERROR/[ERROR]/g; /^$/d' /tmp/sample.log
# 설정 파일에서 주석 제거 후 포트 번호 변경
sed '/^#/d; /^$/d; s/port=8080/port=9090/' server.conf
tail -f 실시간 로그 모니터링
tail -f는 파일이 커질 때마다 새로운 내용을 자동으로 출력합니다. 장애 상황에서 로그를 실시간으로 모니터링할 때 필수입니다.
기본 사용법 — tail -f로 파일 끝을 실시간 추적합니다:
# 파일 끝에서부터 10줄 출력하고 계속 추적
tail -f /var/log/nginx/error.log
# 처음부터가 아닌 100줄부터 추적
tail -n 100 -f /var/log/nginx/access.log
# 여러 파일 동시 추적 (파일명이 자동으로 표시됨)
tail -f /var/log/nginx/access.log /var/log/nginx/error.log
# --follow=name: 로그 로테이션 후에도 같은 파일명 추적
tail --follow=name /var/log/app/app.log
grep과 조합한 실시간 필터링 — tail의 스트림 출력에 grep을 연결해 특정 패턴만 실시간으로 봅니다:
# 실시간으로 ERROR 줄만 출력
tail -f /var/log/app/app.log | grep --line-buffered "ERROR"
# --line-buffered 옵션이 중요! 없으면 버퍼링 때문에 실시간 출력이 안 될 수 있음
# HTTP 500 에러만 실시간 추적
tail -f /var/log/nginx/access.log | grep --line-buffered '" 500 '
# 특정 IP의 접근만 추적
tail -f /var/log/nginx/access.log | grep --line-buffered "203.0.113.42"
# 에러이면서 특정 API 경로인 것만
tail -f /var/log/app/app.log | grep --line-buffered -E "ERROR.*(/api/payment|/api/order)"
실시간 모니터링 + 타임스탬프 추가 — awk로 각 줄에 현재 시각을 붙여 언제 발생했는지 기록합니다:
# 출력에 현재 시각 추가 (ts 명령어, moreutils 패키지)
tail -f /var/log/app/app.log | ts '[%Y-%m-%d %H:%M:%S]'
# ts 없이 awk로 타임스탬프 추가
tail -f /var/log/app/app.log | awk '{print strftime("[%Y-%m-%d %H:%M:%S]"), $0}'
# 실시간 에러 카운터 (5초마다 에러 수 출력)
tail -f /var/log/app/app.log | grep --line-buffered "ERROR" | \
awk 'BEGIN{count=0} {count++; if(count%10==0) print count, "errors so far"}'
multitail로 더 편리하게 (설치 필요) — 여러 로그 파일을 화면 분할로 동시에 모니터링합니다:
# 여러 로그를 분할 화면으로 동시 모니터링
multitail /var/log/nginx/access.log /var/log/nginx/error.log /var/log/app/app.log
sort, uniq, cut, wc 활용
grep, awk, sed가 주인공이라면, sort, uniq, cut, wc는 이들을 완성하는 조연입니다.
wc — 줄/단어/바이트 카운트 — 로그 파일의 에러 건수나 규모를 빠르게 파악할 때 씁니다:
# -l: 줄 수 (line count)
wc -l /tmp/access.log
grep "ERROR" /tmp/sample.log | wc -l
# -w: 단어 수 (word count)
wc -w /tmp/sample.log
# -c: 바이트 수 (character/byte count)
wc -c /tmp/access.log
# 여러 파일 동시
wc -l /var/log/nginx/*.log
cut — 필드 잘라내기 — CSV나 공백 구분 파일에서 특정 컬럼만 추출합니다:
# -d: 구분자, -f: 필드 번호
# /etc/passwd에서 사용자명과 홈디렉토리만
cut -d: -f1,6 /etc/passwd
# 로그에서 날짜 부분만 추출 (첫 10글자)
cut -c1-10 /tmp/sample.log
# CSV에서 2번째와 4번째 컬럼
cut -d',' -f2,4 data.csv
# access.log에서 IP 주소만 (공백 구분 첫 번째 필드)
cut -d' ' -f1 /tmp/access.log
sort — 정렬 — 텍스트 또는 숫자 기준으로 정렬하고, 중복 제거와 조합해 집계에 활용합니다:
# 기본 알파벳순 정렬
sort /tmp/access.log
# -r: 역순 (reverse)
sort -r /tmp/access.log
# -n: 숫자 정렬 (numeric) — "10"이 "2"보다 크게 처리
sort -n numbers.txt
# -k: 키 필드 지정 (k필드번호)
sort -k9 /tmp/access.log # 9번째 필드(상태코드)로 정렬
sort -k9 -rn /tmp/access.log # 9번째 필드 내림차순 숫자 정렬
# -t: 구분자 지정
sort -t: -k3 -n /etc/passwd # UID(3번째) 기준 정렬
# -u: 중복 제거 후 정렬
sort -u /tmp/ips.txt
uniq — 중복 처리 — 연속된 중복 줄을 하나로 줄이거나 발생 횟수를 셉니다:
# 반드시 sort 후 사용 (인접한 중복만 제거)
sort /tmp/access.log | uniq
# -c: 각 줄의 반복 횟수 출력 (count)
sort /tmp/access.log | uniq -c
# -d: 중복된 줄만 출력 (duplicate)
sort /tmp/access.log | uniq -d
# -u: 한 번만 나온 줄만 출력 (unique)
sort /tmp/access.log | uniq -u
# IP 주소별 접근 빈도
cut -d' ' -f1 /tmp/access.log | sort | uniq -c | sort -rn
# 출력:
# 3 192.168.1.10
# 2 203.0.113.42
# ...
실전 조합 예시 — HTTP 상태 코드별 통계 — grep, awk, sort, uniq를 연결한 현장 분석 파이프라인입니다:
awk '{print $9}' /tmp/access.log | sort | uniq -c | sort -rn
# 출력:
# 4 200
# 1 201
# 1 204
# 1 401
# 1 403
# 1 404
# 1 500
실무 예제
새벽 2시에 보안 알림이 울립니다. "SSH 로그인 실패가 평소보다 100배 증가했습니다." 다음 파이프라인 하나로 공격자 IP를 5초 안에 파악합니다.
실습용 SSH 로그 생성 — 단계별 분석 실습에 사용할 SSH 인증 로그를 만듭니다:
cat > /tmp/auth.log << 'EOF'
Jan 15 08:00:01 server sshd[1234]: Accepted password for alice from 192.168.1.10 port 52341 ssh2
Jan 15 08:01:13 server sshd[1235]: Failed password for root from 203.0.113.42 port 12345 ssh2
Jan 15 08:01:14 server sshd[1236]: Failed password for root from 203.0.113.42 port 12346 ssh2
Jan 15 08:01:15 server sshd[1237]: Failed password for admin from 203.0.113.42 port 12347 ssh2
Jan 15 08:01:16 server sshd[1238]: Failed password for ubuntu from 203.0.113.42 port 12348 ssh2
Jan 15 08:02:00 server sshd[1239]: Accepted password for bob from 192.168.1.22 port 55123 ssh2
Jan 15 08:03:01 server sshd[1240]: Failed password for root from 198.51.100.7 port 44123 ssh2
Jan 15 08:03:02 server sshd[1241]: Failed password for guest from 198.51.100.7 port 44124 ssh2
Jan 15 08:04:00 server sshd[1242]: Accepted publickey for deploy from 10.0.0.5 port 33445 ssh2
Jan 15 08:05:01 server sshd[1243]: Failed password for root from 203.0.113.42 port 12349 ssh2
Jan 15 08:05:02 server sshd[1244]: Failed password for root from 203.0.113.42 port 12350 ssh2
Jan 15 08:05:03 server sshd[1245]: Failed password for oracle from 203.0.113.42 port 12351 ssh2
EOF
단계별 분석 파이프라인 — 로그에서 실패 IP를 추출하고 공격 횟수를 집계하는 전체 흐름입니다:
# Step 1: 실패 로그만 추출
grep "Failed password" /tmp/auth.log
# Step 2: IP 주소 추출 (11번째 필드가 IP)
grep "Failed password" /tmp/auth.log | awk '{print $11}'
# Step 3: IP별 빈도 카운트
grep "Failed password" /tmp/auth.log | awk '{print $11}' | sort | uniq -c
# Step 4: 내림차순 정렬 (가장 많이 시도한 IP가 위에)
grep "Failed password" /tmp/auth.log | awk '{print $11}' | sort | uniq -c | sort -rn
# 출력:
# 7 203.0.113.42 ← 이 IP가 주범
# 2 198.51.100.7
# Step 5: 임계값 이상(5회 초과)인 IP만 추출
grep "Failed password" /tmp/auth.log | \
awk '{print $11}' | sort | uniq -c | sort -rn | \
awk '$1 > 5 {print $2}'
# 출력: 203.0.113.42
# Step 6: 해당 IP로 시도한 계정 목록도 함께 확인
grep "Failed password" /tmp/auth.log | \
grep "203.0.113.42" | \
awk '{print $9}' | sort | uniq -c | sort -rn
# 출력:
# 5 root
# 1 admin
# 1 ubuntu
# 1 oracle
# Step 7: 자동 차단 (실제 운영에서는 신중하게!)
ATTACKER_IP="203.0.113.42"
iptables -A INPUT -s $ATTACKER_IP -j DROP
echo "$(date): Blocked $ATTACKER_IP" >> /var/log/blocked_ips.log
자동화 스크립트 — 위 분석 파이프라인을 cron 등에서 자동 실행할 수 있도록 스크립트화합니다:
#!/bin/bash
LOG_FILE="/var/log/auth.log"
THRESHOLD=10
grep "Failed password" $LOG_FILE | \
awk '{print $11}' | sort | uniq -c | sort -rn | \
awk -v threshold=$THRESHOLD '$1 >= threshold {print $2}' | \
while read ip; do
echo "[$(date '+%Y-%m-%d %H:%M:%S')] 차단: $ip (시도 횟수: $(grep -c $ip $LOG_FILE)회)"
# iptables -A INPUT -s $ip -j DROP
done
웹 서버 운영 중 "요즘 트래픽이 갑자기 늘었는데 어디서 오는 거야?"라는 질문을 받았습니다. 상위 접속 IP를 파악하는 것은 비정상 트래픽 탐지의 첫 단계입니다.
실습 — access.log에서 Top 10 IP — 요청이 가장 많은 IP를 추출해 비정상 트래픽을 탐지합니다:
# 방법 1: cut + sort + uniq 조합
cut -d' ' -f1 /tmp/access.log | sort | uniq -c | sort -rn | head -10
# 방법 2: awk 활용 (더 유연)
awk '{ip[$1]++}
END{for(i in ip) print ip[i], i}' /tmp/access.log | \
sort -rn | head -10
# 출력 형식 개선
awk '{ip[$1]++}
END{for(i in ip) printf "%5d 회 %s\n", ip[i], i}' /tmp/access.log | \
sort -rn | head -10
# 출력 예시:
# 3 회 192.168.1.10
# 2 회 192.168.1.22
# 2 회 10.0.0.55
# 2 회 203.0.113.42
# 1 회 192.168.1.15
# 1 회 198.51.100.7
상위 10 접속 URI — 요청이 집중되는 엔드포인트를 파악해 성능 최적화 우선순위를 결정합니다:
awk '{print $7}' /tmp/access.log | sort | uniq -c | sort -rn | head -10
시간대별 요청 분포 — 트래픽이 몰리는 시간대를 파악해 스케일링 시점을 결정합니다:
# 시간(HH) 기준 요청 수
awk '{print $4}' /tmp/access.log | \
cut -d: -f2 | sort | uniq -c
# 분 단위 분포
awk '{print substr($4,2,14)}' /tmp/access.log | \
cut -d: -f1,2 | sort | uniq -c
IP당 평균 응답 크기 계산 — 대용량 응답을 유발하는 클라이언트를 찾아 CDN 캐시 여부를 판단합니다:
awk '{bytes[$1]+=$10; count[$1]++}
END{
for(ip in bytes)
printf "%-15s %d 요청, 평균 %.0f bytes\n",
ip, count[ip], bytes[ip]/count[ip]
}' /tmp/access.log | sort
특정 시간대 트래픽 급증 탐지 — 배포나 장애 발생 시각을 기준으로 전후 요청량 변화를 확인합니다:
# 분당 요청 수가 100 이상인 시간대 탐지
awk '{print substr($4,2,17)}' /tmp/access.log | \
cut -d: -f1,2,3 | sort | uniq -c | \
awk '$1 >= 2 {print "트래픽 급증:", $2, "-", $1, "요청/분"}'
배포 직후 Slack에 알림이 옵니다. "결제 API 에러율이 급등하고 있어요." 터미널을 열고 다음 명령을 실행합니다.
실시간 HTTP 500 에러 추적 파이프라인 — 배포 직후 에러 발생 여부를 실시간으로 모니터링합니다:
# 기본: 실시간으로 500 에러만 출력
tail -f /var/log/nginx/access.log | grep --line-buffered '" 500 '
# 상세: IP, 요청경로, 상태코드, 응답시간 함께 표시
tail -f /var/log/nginx/access.log | \
grep --line-buffered '" 500 ' | \
awk '{print $1, $7, $9, $10, "bytes"}'
# 특정 API 엔드포인트의 500 에러만
tail -f /var/log/nginx/access.log | \
grep --line-buffered -E '"/api/payment.*" 500 '
# 에러 빈도 실시간 카운터 (매 줄마다 누적 수 표시)
tail -f /var/log/nginx/access.log | \
grep --line-buffered '" 500 ' | \
awk 'BEGIN{count=0}
{count++; print strftime("[%H:%M:%S]"), "에러 누적:", count"회", "| IP:", $1, "| URL:", $7}'
에러 로그와 액세스 로그 동시 추적 — 두 로그를 동시에 보면서 에러 원인과 요청 패턴을 연결합니다:
# 두 로그를 동시에 컬러 구분하여 모니터링
(tail -f /var/log/nginx/access.log | sed 's/^/[ACCESS] /' &
tail -f /var/log/nginx/error.log | sed 's/^/[ERROR] /' &) | \
grep --line-buffered -E "500|crit|error"
배포 전후 에러율 비교 — 배포 직전 N분과 직후 N분의 에러율을 자동으로 계산해 롤백 여부를 판단합니다:
DEPLOY_TIME="08:30"
# 배포 전 에러율
echo "=== 배포 전 에러율 ==="
grep "08:[0-2][0-9]:" /var/log/nginx/access.log | \
awk 'BEGIN{total=0; errors=0}
{total++; if($9>=500) errors++}
END{printf "요청: %d, 에러: %d, 에러율: %.2f%%\n", total, errors, errors/total*100}'
# 배포 후 에러율
echo "=== 배포 후 에러율 ==="
grep "08:[3-5][0-9]:" /var/log/nginx/access.log | \
awk 'BEGIN{total=0; errors=0}
{total++; if($9>=500) errors++}
END{printf "요청: %d, 에러: %d, 에러율: %.2f%%\n", total, errors, errors/total*100}'
에러 롤백 판단 스크립트 — 에러율이 임계값을 초과하면 자동 알림을 보내는 간단한 감시 스크립트입니다:
#!/bin/bash
# 최근 1분간 500 에러율이 5% 이상이면 경보
LOGFILE="/var/log/nginx/access.log"
THRESHOLD=5
# 최근 1분간 로그 (access.log에 타임스탬프 있다고 가정)
RECENT_STATS=$(tail -n 500 $LOGFILE | \
awk 'BEGIN{t=0;e=0} {t++; if($9=="500") e++} END{print t, e}')
TOTAL=$(echo $RECENT_STATS | cut -d' ' -f1)
ERRORS=$(echo $RECENT_STATS | cut -d' ' -f2)
if [ $TOTAL -gt 0 ]; then
ERROR_RATE=$(echo "scale=2; $ERRORS * 100 / $TOTAL" | bc)
echo "최근 500 에러율: ${ERROR_RATE}% (${ERRORS}/${TOTAL})"
if (( $(echo "$ERROR_RATE >= $THRESHOLD" | bc -l) )); then
echo "경보: 에러율이 임계값(${THRESHOLD}%)을 초과했습니다!"
echo "롤백을 고려하세요."
fi
fi
jq — JSON 파싱
현대 마이크로서비스는 로그를 JSON 형식으로 출력합니다. grep과 awk만으로는 중첩된 JSON을 파싱하기 어렵습니다. jq는 JSON 전용 커맨드라인 파서입니다.
설치 — jq는 패키지 관리자로 간단히 설치할 수 있습니다:
# Ubuntu/Debian
sudo apt-get install jq
# CentOS/RHEL
sudo yum install jq
# macOS
brew install jq
실습용 JSON 로그 생성 — 구조화 로그 실습에 쓸 JSON Lines 형식의 샘플 로그를 만듭니다:
cat > /tmp/app.jsonl << 'EOF'
{"timestamp":"2024-01-15T08:23:11Z","level":"INFO","service":"auth","message":"User logged in","user_id":1001,"ip":"192.168.1.10","latency_ms":45}
{"timestamp":"2024-01-15T08:24:02Z","level":"ERROR","service":"payment","message":"Payment failed","user_id":1002,"ip":"10.0.0.55","latency_ms":3201,"error_code":"CARD_DECLINED","amount":59900}
{"timestamp":"2024-01-15T08:24:45Z","level":"INFO","service":"catalog","message":"Product fetched","user_id":1003,"ip":"192.168.1.22","latency_ms":12,"product_id":"P-4521"}
{"timestamp":"2024-01-15T08:25:13Z","level":"WARN","service":"auth","message":"Rate limit approaching","ip":"203.0.113.42","requests_per_min":95,"limit":100}
{"timestamp":"2024-01-15T08:26:30Z","level":"ERROR","service":"order","message":"Database timeout","user_id":1002,"latency_ms":30000,"db_host":"db-primary.internal","retries":3}
{"timestamp":"2024-01-15T08:27:01Z","level":"INFO","service":"cart","message":"Item added to cart","user_id":1004,"ip":"192.168.1.15","latency_ms":8,"product_id":"P-1234","quantity":2}
{"timestamp":"2024-01-15T08:28:44Z","level":"ERROR","service":"payment","message":"Payment failed","user_id":1005,"ip":"192.168.1.30","latency_ms":2890,"error_code":"INSUFFICIENT_FUNDS","amount":129000}
EOF
jq 기본 사용법 — .필드명으로 JSON 값을 추출하고 -r로 따옴표 없이 출력합니다:
# 전체 JSON 예쁘게 출력 (pretty print)
cat /tmp/app.jsonl | jq '.'
# 특정 필드만 추출
cat /tmp/app.jsonl | jq '.level'
cat /tmp/app.jsonl | jq '.message'
cat /tmp/app.jsonl | jq '.service'
# 여러 필드 추출 (새 JSON으로)
cat /tmp/app.jsonl | jq '{level: .level, service: .service, message: .message}'
# 원시 문자열 출력 (-r 옵션, 따옴표 없이)
cat /tmp/app.jsonl | jq -r '.level'
# 여러 필드를 탭으로 구분하여 출력
cat /tmp/app.jsonl | jq -r '[.timestamp, .level, .service, .message] | @tsv'
jq 필터링 — select() 함수로 조건에 맞는 로그 항목만 걸러냅니다:
# ERROR 레벨만 출력
cat /tmp/app.jsonl | jq 'select(.level == "ERROR")'
# ERROR 레벨의 서비스와 에러코드만
cat /tmp/app.jsonl | jq -r 'select(.level == "ERROR") | "\(.service): \(.message)"'
# 레이턴시가 1000ms 이상인 로그
cat /tmp/app.jsonl | jq 'select(.latency_ms >= 1000)'
# payment 서비스의 에러만
cat /tmp/app.jsonl | jq 'select(.service == "payment" and .level == "ERROR")'
# 에러코드가 있는 로그만 (필드 존재 여부)
cat /tmp/app.jsonl | jq 'select(.error_code != null)'
jq 집계와 통계 — group_by, length, add 등으로 JSON 데이터를 집계합니다:
# 서비스별 로그 수 카운트
cat /tmp/app.jsonl | jq -r '.service' | sort | uniq -c | sort -rn
# 에러 코드 목록 추출
cat /tmp/app.jsonl | jq -r 'select(.error_code) | .error_code' | sort | uniq -c
# 평균 레이턴시 계산
cat /tmp/app.jsonl | jq -s '[.[].latency_ms] | add/length'
# 서비스별 최대 레이턴시
cat /tmp/app.jsonl | jq -r '[.service, (.latency_ms|tostring)] | @tsv' | \
sort -k1,1 -k2,2rn | awk '!seen[$1]++'
jq + grep + awk 조합 — JSON 파싱 후 전통적인 텍스트 도구와 연결해 복잡한 분석을 수행합니다:
# JSON 로그에서 ERROR만 추출 후 IP 빈도 분석
cat /tmp/app.jsonl | \
jq -r 'select(.level == "ERROR") | .ip // "N/A"' | \
sort | uniq -c | sort -rn
# JSON 로그에서 실시간 에러 모니터링
tail -f /var/log/app/app.jsonl | \
jq --unbuffered -r 'select(.level == "ERROR") |
"[\(.timestamp)] \(.service) | \(.message) | latency: \(.latency_ms)ms"'
트러블슈팅
상황: tail -f app.log | grep "ERROR" 를 실행했는데 에러가 발생해도 터미널에 즉시 출력되지 않고, 한참 뒤에 한꺼번에 출력됩니다. 장애 대응 중에 실시간으로 에러를 확인해야 하는데 반응이 없습니다.
원인: grep은 출력 대상이 터미널이 아닌 파이프로 연결될 때 성능을 위해 블록 버퍼링을 활성화합니다. 터미널 직접 출력이면 줄 단위(line-buffered)로 즉시 보내지만, 파이프에선 4~8KB 버퍼가 꽉 찰 때까지 출력을 보류합니다.
진단: 버퍼링 여부를 두 창을 열어 확인합니다.
# 창 1: 버퍼링 상태로 실행
tail -f /tmp/test.log | grep "test"
# 창 2: 로그 추가
echo "test message" >> /tmp/test.log
# → --line-buffered 없으면 즉시 출력 안 됨. 4KB 이상 쌓여야 출력됨
해결: --line-buffered 옵션을 추가합니다. 다른 도구들은 각자의 방법으로 버퍼링을 해제합니다.
# grep: --line-buffered 옵션으로 줄 단위 즉시 출력
tail -f app.log | grep --line-buffered "ERROR"
# 또는 stdbuf로 버퍼 크기를 0으로 강제 설정
tail -f app.log | stdbuf -oL grep "ERROR"
# sed의 경우 -u (unbuffered) 옵션
tail -f app.log | sed -u 's/ERROR/[ERROR]/'
# awk의 경우 fflush()로 즉시 플러시
tail -f app.log | awk '/ERROR/{print; fflush()}'
# python3: flush=True로 즉시 출력 (설치 없이 사용 가능)
tail -f app.log | python3 -c "
import sys
for line in sys.stdin:
if 'ERROR' in line:
print(line, end='', flush=True)
"
상황: sed -i 's/listen 80/listen 8080/g' /etc/nginx/sites-enabled/default 실행 후 두 가지 문제 중 하나가 발생합니다. ① 파일이 비어있거나 내용이 손상되었거나, ② 심볼릭 링크가 일반 파일로 바뀌어 원본 sites-available 파일 변경이 적용되지 않습니다.
원인: sed -i는 내부적으로 임시 파일을 만들고 원본 inode를 교체합니다. 이 과정에서 심볼릭 링크 관계, 파일 권한, inode 번호가 바뀝니다. 또한 macOS의 sed -i는 GNU sed와 문법이 달라 Linux 스크립트를 macOS에서 실행하면 오류가 납니다.
진단: 수정 대상이 심볼릭 링크인지, 실제 파일이 어디 있는지 확인합니다.
# 심볼릭 링크 여부 확인
ls -la /etc/nginx/sites-enabled/
# lrwxrwxrwx 1 root root 34 Jan 15 08:00 default -> /etc/nginx/sites-available/default
# l로 시작하면 심볼릭 링크
# 실제 파일 경로 확인
readlink -f /etc/nginx/sites-enabled/default
# /etc/nginx/sites-available/default
해결: 심볼릭 링크엔 실제 파일 경로로, 일반 파일엔 -i.bak으로 백업하며 수정합니다.
# 백업 파일 만들면서 수정 (권장 — config.txt.bak에 원본 보존)
sed -i.bak 's/old/new/g' config.txt
# 심볼릭 링크: readlink -f 로 실제 경로에 적용
TARGET=$(readlink -f /etc/nginx/sites-enabled/default)
sed -i.bak 's/listen 80/listen 8080/' "$TARGET"
# macOS vs GNU sed 차이 처리
sed -i '' 's/old/new/g' config.txt # macOS (빈 문자열 필요)
sed -i 's/old/new/g' config.txt # GNU/Linux
# 가장 안전한 방법: 임시 파일 사용 (inode 유지)
sed 's/old/new/g' config.txt > config.txt.tmp && mv config.txt.tmp config.txt
# macOS/Linux 공통 문법: perl 사용
perl -pi -e 's/old/new/g' config.txt
상황: awk '$9 >= 400 {print $0}' access.log로 4xx/5xx 에러 요청만 걸러내려 했는데, HTTP 200, 301 같은 정상 코드 줄도 함께 출력됩니다. 반대로 awk '$9 < 400'이 실제로 200인 줄을 걸러내지 못하기도 합니다.
원인: awk는 필드가 숫자처럼 생겼어도 선행 공백이나 따옴표 같은 특수문자가 붙어 있으면 문자열로 처리합니다. 문자열 비교에서 "200" >= "400"은 첫 글자 "2" < "4" 비교이므로 false이지만, "500" >= "400"은 "5" > "4" 이므로 true — 결과가 예상과 뒤바뀔 수 있습니다.
진단: 필드 값의 타입과 선행 문자 여부를 직접 확인합니다.
# 문제 재현: 따옴표가 붙은 필드
echo '"200"' | awk '{if($1 >= 400) print "error"; else print "ok"}'
# "200"은 따옴표 때문에 숫자 변환 실패 → 문자열 비교 → 예상 외 결과
# awk 타입 변환 규칙 확인
echo "abc123" | awk '{print $1+0}' # 출력: 0 (문자 시작 → 0)
echo "123abc" | awk '{print $1+0}' # 출력: 123 (숫자 앞부분만)
echo " 200 " | awk '{print $1+0}' # 출력: 200 (공백은 자동 제거됨)
해결: +0으로 강제 숫자 변환하거나, 정규식으로 코드 범위를 직접 매칭합니다.
# 방법 1: +0 으로 강제 숫자 변환 (가장 일반적)
awk '{code=$9+0; if(code >= 400) print $0}' /tmp/access.log
# 방법 2: int() 함수 사용
awk '{if(int($9) >= 400) print $0}' /tmp/access.log
# 방법 3: gsub으로 비숫자 문자 완전 제거 후 비교
awk '{gsub(/[^0-9]/, "", $9); if($9+0 >= 400) print $0}' /tmp/access.log
# 방법 4: 정규식으로 4xx/5xx 패턴 직접 매칭 (가장 확실)
awk '$9 ~ /^[45][0-9][0-9]$/' /tmp/access.log
# 검증: 정상/에러 구분 테스트
echo "200 500 404 301" | tr ' ' '\n' | \
awk '{n=$1+0; if(n>=400) print n, "에러"; else print n, "정상"}'
# 출력:
# 200 정상
# 500 에러
# 404 에러
# 301 정상
심화 — 같은 결과, 다른 비용: 집계가 대용량에서 갈리는 지점
심화: '정렬해서 세기'와 '한 번 훑어 세기'는 규모가 커지면 완전히 다른 도구다
이 모듈에서는 빈도 집계를 두 가지로 배웠습니다 — sort | uniq -c | sort -rn과 awk '{c[$1]++}'. 작은 로그에선 결과가 똑같아 취향 차이처럼 보이지만, 수억 줄 규모에서는 자원 사용이 근본적으로 갈립니다. 내부 동작을 알면 대용량 로그 앞에서 어느 쪽을 골라야 할지 판단할 수 있습니다.
- sort | uniq -c 는 '전부 줄 세우기': uniq는 인접한 중복만 합치므로 반드시 전체를 먼저 정렬해야 합니다. 정렬은 O(n log n)이고, 입력이 메모리보다 크면 sort가 데이터를 조각내 정렬한 뒤 임시 파일로 디스크에 써 가며 병합하는 외부 정렬(external merge sort)을 합니다. 즉 n이 커질수록 디스크 임시 공간과 시간이 함께 커집니다.
- awk 해시 집계는 '한 번만 훑기':
awk '{c[$1]++}'는 입력을 한 번 지나가며 연상 배열(해시)에 카운트를 누적합니다. O(n) 단일 패스이고, 메모리는 줄 수가 아니라 고유 키 개수(예: 서로 다른 IP 수)에만 비례합니다. 임시 파일도 필요 없습니다. - 그래서 언제 뭘 쓰나: 로그 집계는 보통 '줄은 수억인데 고유 IP는 수만'인 형태라 awk가 압도적으로 가볍습니다. 반대로 고유 키가 폭발적으로 많으면(예: 모든 요청 URL에 유니크 파라미터가 붙는 경우) awk의 해시가 메모리를 크게 먹어, 이때는 정렬 기반이 오히려 안전합니다.
- 정렬을 꼭 써야 한다면 가볍게:
LC_ALL=C로 로케일 비교 오버헤드를 없애고,-S로 메모리 버퍼를,--parallel로 코어를 늘리고,-T로 임시 디렉토리를 여유 있는 곳에 둡니다.
정리하면 두 파이프라인은 '같은 답을 주는 다른 알고리즘'입니다 — 결과가 아니라 비용을 보고 골라야 합니다.
상황: 20GB짜리 access.log에서 IP별 빈도를 뽑으려고 sort access.log | uniq -c | sort -rn 을 돌렸습니다. 몇 분 뒤 sort가 No space left on device로 죽습니다. 그런데 df로 보니 로그가 놓인 데이터 파티션엔 아직 수백 GB가 남아 있어 영문을 모르겠습니다.
원인: sort는 입력이 메모리보다 크면 데이터를 여러 조각으로 나눠 정렬한 뒤 임시 파일로 디스크에 쓰고 병합하는 외부 정렬을 합니다. 이 임시 파일은 입력 파일이 있는 위치가 아니라 기본적으로 /tmp(또는 TMPDIR 환경변수가 가리키는 곳)에 쌓입니다. /tmp가 작은 파티션이거나 RAM 기반 tmpfs이면, 20GB를 정렬하는 동안 임시 파일이 /tmp를 가득 채워 터집니다. 로그 디스크의 여유 공간과는 무관합니다.
진단:
# 로그 파티션이 아니라 임시 공간을 봐야 한다
df -h /tmp
df -h /var/log # 로그가 있는 곳 — 여긴 여유가 있다
# sort가 실제로 어디에 임시 파일을 쓰는지
echo $TMPDIR # 비어 있으면 기본값 /tmp 사용
/tmp의 여유 용량이 입력 파일 크기보다 작으면 이 문제로 확정입니다.
해결:
# 방법 1: 여유 있는 디렉토리를 임시 공간으로 지정
sort -T /data/tmp access.log | uniq -c | sort -rn
# 방법 2 (권장): 애초에 전체 정렬을 피한다 — 빈도 집계는 한 번 훑기로 충분
awk '{c[$1]++} END{for(k in c) print c[k], k}' access.log | sort -rn | head
# 방법 3: 정렬이 꼭 필요하면 가볍고 빠르게
LC_ALL=C sort -S 50% --parallel=4 -T /data/tmp access.log | uniq -c
핵심 교훈: '디스크가 꽉 찼다'는 에러를 만나면 입력 파일이 아니라 임시 파일이 쌓이는 곳을 먼저 의심하세요. 그리고 단순 빈도 집계에 굳이 전체 정렬을 쓰고 있지 않은지 돌아보세요 — awk 한 줄이면 임시 파일 문제 자체가 사라집니다.
고급 파이프라인 패턴
지금까지 배운 도구를 모두 조합하여 실무에서 바로 쓸 수 있는 로그 분석 보고서를 만들어 봅니다.
종합 로그 분석 스크립트 — 지금까지 배운 grep, awk, sed, sort를 조합한 실무형 로그 분석 스크립트입니다:
#!/bin/bash
# log_report.sh — Nginx 액세스 로그 종합 분석
LOG_FILE="${1:-/tmp/access.log}"
echo "============================================"
echo " Nginx 액세스 로그 분석 보고서"
echo " 파일: $LOG_FILE"
echo " 생성: $(date '+%Y-%m-%d %H:%M:%S')"
echo "============================================"
echo ""
echo "[ 전체 요청 통계 ]"
TOTAL=$(wc -l < "$LOG_FILE")
echo "총 요청 수: $TOTAL"
echo ""
echo "[ HTTP 상태 코드별 분포 ]"
awk '{print $9}' "$LOG_FILE" | sort | uniq -c | sort -rn | \
awk '{printf " %s: %d 회 (%.1f%%)\n", $2, $1, $1/'$TOTAL'*100}'
echo ""
echo "[ 상위 10 접속 IP ]"
awk '{print $1}' "$LOG_FILE" | sort | uniq -c | sort -rn | head -10 | \
awk '{printf " %-15s %5d 회\n", $2, $1}'
echo ""
echo "[ 상위 10 요청 URL ]"
awk '{print $7}' "$LOG_FILE" | sort | uniq -c | sort -rn | head -10 | \
awk '{printf " %5d 회 %s\n", $1, $2}'
echo ""
echo "[ 에러 요청 (4xx/5xx) ]"
awk '$9 >= 400 {print $9, $1, $7}' "$LOG_FILE" | sort | \
awk '{printf " [%s] %-15s %s\n", $1, $2, $3}'
echo ""
echo "[ 응답 크기 통계 ]"
awk 'NF>=10 && $10~/^[0-9]+$/ {
total+=$10; count++;
if($10>max) max=$10
}
END{
printf " 평균: %.0f bytes\n", total/count
printf " 최대: %d bytes\n", max
printf " 총합: %.2f MB\n", total/1024/1024
}' "$LOG_FILE"
echo ""
echo "============================================"
실행 — 스크립트에 실행 권한을 주고 실제로 돌려봅니다:
chmod +x log_report.sh
./log_report.sh /tmp/access.log
예상 출력 — 스크립트 실행 시 나타나는 결과 형식입니다:
============================================
Nginx 액세스 로그 분석 보고서
파일: /tmp/access.log
생성: 2024-01-15 09:00:00
============================================
[ 전체 요청 통계 ]
총 요청 수: 10
[ HTTP 상태 코드별 분포 ]
200: 4 회 (40.0%)
500: 1 회 (10.0%)
404: 1 회 (10.0%)
403: 1 회 (10.0%)
401: 1 회 (10.0%)
204: 1 회 (10.0%)
201: 1 회 (10.0%)
[ 상위 10 접속 IP ]
192.168.1.10 3 회
192.168.1.22 2 회
10.0.0.55 2 회
203.0.113.42 2 회
192.168.1.15 1 회
198.51.100.7 1 회
[ 상위 10 요청 URL ]
3 회 /api/users
2 회 /login
...
한 줄 분석 치트시트 — 현장에서 바로 쓸 수 있는 one-liner 패턴 모음입니다:
# 현재 초당 요청 수 (실시간)
tail -f access.log | awk '{print substr($4,2,17)}' | uniq -c
# 응답 시간 상위 5개 요청
awk '{print $NF, $7}' access.log | sort -rn | head -5
# 특정 User-Agent 통계 (봇 탐지)
grep -oE '"[^"]*"$' access.log | sort | uniq -c | sort -rn | head -10
# 404 에러가 가장 많이 발생하는 URL
awk '$9=="404"{print $7}' access.log | sort | uniq -c | sort -rn | head -10
# 분당 에러율 추이
awk '$9>=500{
split($4,t,":"); key=t[2]":"t[3]
errors[key]++; total[key]++
} $9<500{
split($4,t,":"); key=t[2]":"t[3]
total[key]++
} END{
for(k in total)
printf "%s 에러율: %.1f%% (%d/%d)\n", k, errors[k]/total[k]*100, errors[k], total[k]
}' access.log | sort
대용량 로그 성능 팁 — LC_ALL=C·grep -F·병렬 처리
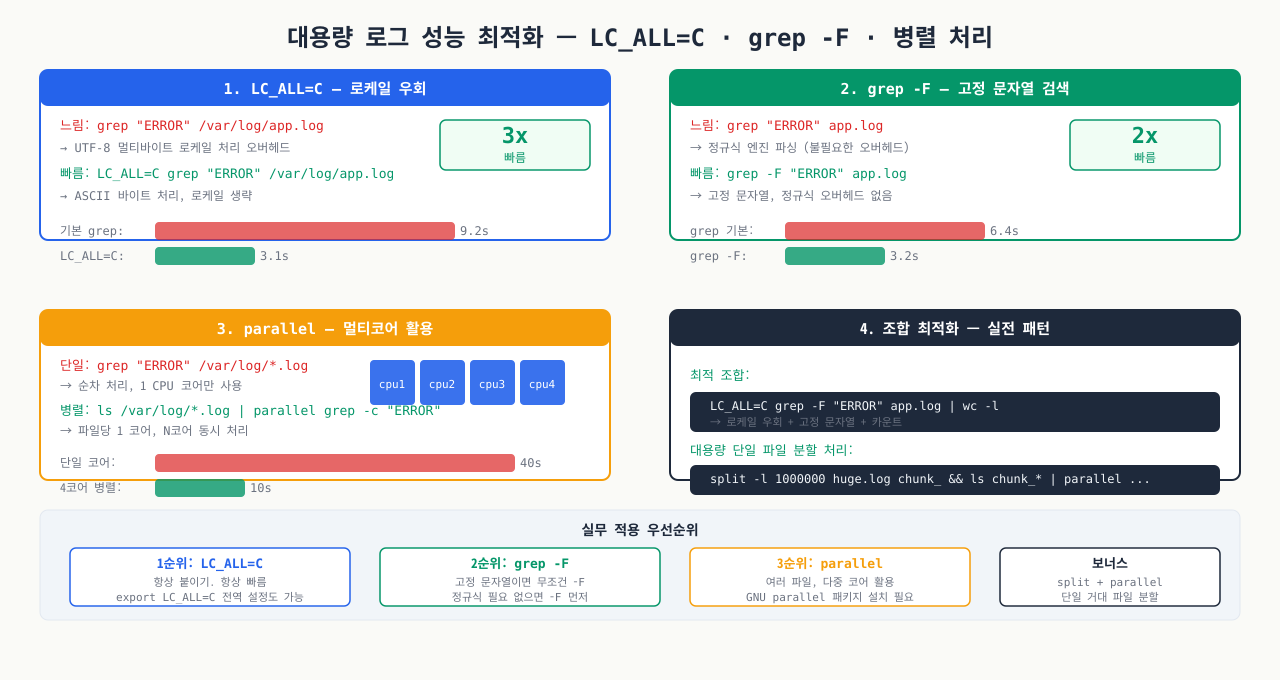 확대
확대
수백 GB 로그 파일에서 grep이 너무 느릴 때 적용할 수 있는 최적화 기법입니다.
LC_ALL=C — 가장 간단하고 효과적인 속도 향상 — 로케일 처리를 생략해 sort와 grep 속도를 크게 높입니다:
# 기본 grep (UTF-8 로케일 처리 오버헤드 있음)
grep "ERROR" /var/log/app.log
# LC_ALL=C로 바이트 단위 처리 (2~3배 빨라짐)
LC_ALL=C grep "ERROR" /var/log/app.log
# 조합: LANG도 함께 설정
LANG=C LC_ALL=C grep "ERROR" /var/log/app.log
grep -F (fixed string) — 정규식 오버헤드 제거 — 고정 문자열 검색에서 정규식 엔진을 거치지 않아 빠릅니다:
# -F: 고정 문자열로 검색 (정규식 파싱 없음, 빠름)
grep -F "NullPointerException" /var/log/app.log
# -E: 확장 정규식 (느림 — 정말 필요할 때만)
grep -E "ERROR|WARN|FATAL" /var/log/app.log
# 속도 비교 (1GB 파일 기준)
# grep "ERROR" → 약 3초
# grep -F "ERROR" → 약 1초
# LC_ALL=C grep -F "ERROR" → 약 0.5초
병렬 처리 — 여러 로그 파일 동시 처리 — xargs -P로 여러 코어를 동시에 활용해 처리 속도를 높입니다:
# xargs -P로 병렬 grep (CPU 코어 수만큼)
ls /var/log/app.log.* | xargs -P $(nproc) -I{} grep -F "ERROR" {}
# GNU parallel (더 강력)
parallel -j $(nproc) grep -F "ERROR" {} ::: /var/log/app.log.*
# --line-buffered: 파이프에서 즉시 출력 (tail -f와 조합)
tail -f /var/log/app.log | grep --line-buffered "ERROR"
공백·특수문자 안전 처리 — NUL 구분 파이프라인
 확대
확대
파일명에 공백이나 특수문자가 있을 때 xargs, for loop가 잘못 동작합니다.
# 위험한 방법 (공백 있는 파일명 처리 실패)
find /var/log -name "*.log" | xargs grep "ERROR" # 공백 있으면 잘못 분리됨
# 안전한 방법 (NUL 문자로 구분)
find /var/log -name "*.log" -print0 | xargs -0 grep -F "ERROR"
# find -print0: 파일명을 NUL(\0)으로 구분해 출력
# xargs -0: NUL 구분자로 인수 파싱
# while IFS= read -r -d '' 패턴 (가장 안전)
while IFS= read -r -d '' file; do
grep -F "ERROR" "$file" >> /tmp/errors.txt
done < <(find /var/log -name "*.log" -print0)
# awk 파이프라인에서 빈 필드 처리
awk -F'\t' '$3 != ""' /var/log/access.log # 3번째 필드가 비어있지 않은 행만
현업 필수 치트시트 — 5xx 비율·Top N·p95/p99 응답시간
 확대
확대
장애 대응 중에 "5xx 에러가 갑자기 늘었다"는 알림을 받으면, 빠르게 nginx 액세스 로그에서 5xx 비율을 뽑고 어떤 엔드포인트에서 많이 나오는지 확인해야 합니다. 이런 상황에서 처음부터 쿼리를 직접 짜는 건 시간이 걸립니다. 자주 쓰는 패턴을 미리 익혀두면 장애 상황에서 바로 꺼내 쓸 수 있습니다.
Nginx/Apache 액세스 로그에서 자주 쓰는 분석 패턴 모음입니다.
# 로그 포맷 가정 (Nginx Combined):
# [IP] - - [시간] "METHOD /path HTTP/1.1" STATUS SIZE "REFERRER" "UA"
# 1. HTTP 상태 코드 분포
awk '{print $9}' /var/log/nginx/access.log | sort | uniq -c | sort -rn
# 1000000 200
# 50000 304
# 1234 500 ← 500 에러 개수
# 2. 5xx 에러율 계산
TOTAL=$(wc -l < /var/log/nginx/access.log)
ERRORS=$(grep -c ' 5[0-9][0-9] ' /var/log/nginx/access.log)
echo "5xx 비율: $(echo "scale=2; $ERRORS * 100 / $TOTAL" | bc)%"
# 3. Top 10 요청 URL
awk '{print $7}' /var/log/nginx/access.log | \
sed 's/?.*$//' | sort | uniq -c | sort -rn | head -10
# 4. Top 10 클라이언트 IP
awk '{print $1}' /var/log/nginx/access.log | \
sort | uniq -c | sort -rn | head -10
# 5. 응답시간 p95/p99 (응답시간이 로그에 있는 경우)
# Nginx: $request_time 필드 추가 필요
awk '{print $NF}' /var/log/nginx/access.log | sort -n | \
awk 'BEGIN{c=0} {a[c++]=$1} END{
p95=int(c*0.95); p99=int(c*0.99)
print "p95:", a[p95], "p99:", a[p99]
}'
# 6. 특정 시간대 에러 집중 확인
grep ' 500 ' /var/log/nginx/access.log | \
awk '{print $4}' | cut -d: -f2 | sort | uniq -c
# 특정 시간(예: 14시)에 에러 집중 여부 파악
핵심 정리
grep/awk/sed/tail-f/sort/uniq — 각 도구의 역할
| 도구 | 핵심 역할 | 대표 사용 상황 |
|---|---|---|
grep | 패턴 매칭 — 원하는 줄 추출 | 로그에서 특정 키워드·에러 찾기 |
awk | 필드 처리 — 열 단위 분석 | 구조화된 로그에서 IP/상태코드 집계 |
sed | 스트림 변환 — 치환·삭제 | 설정 파일 일괄 수정, 민감 정보 마스킹 |
tail -f | 실시간 추적 | 장애 대응 중 에러 실시간 모니터링 |
sort | uniq -c | 정렬·중복 집계 | IP/URL/에러 빈도 분석 |
cut | wc | 단순 추출·카운트 | 빠른 필드 추출, 줄 수 세기 |
jq | JSON 파싱 | 마이크로서비스 구조화 로그 분석 |
로그 분석에서 자주 보이는 HTTP 상태 코드
| 코드 | 분류 | 의미 | grep 패턴 |
|---|---|---|---|
200 | 2xx 성공 | OK — 요청 정상 처리 | '" 200 ' |
201 | 2xx 성공 | Created — POST 리소스 생성 성공 | '" 201 ' |
301 | 3xx 리다이렉트 | Moved Permanently — URL 영구 이동 | '" 301 ' |
302 | 3xx 리다이렉트 | Found — URL 임시 이동 (로그인 후 리다이렉트) | '" 302 ' |
400 | 4xx 클라이언트 오류 | Bad Request — 요청 형식 잘못됨 | '" 400 ' |
401 | 4xx 클라이언트 오류 | Unauthorized — 인증 없음 (로그인 필요) | '" 401 ' |
403 | 4xx 클라이언트 오류 | Forbidden — 권한 없음 | '" 403 ' |
404 | 4xx 클라이언트 오류 | Not Found — 리소스 없음 | '" 404 ' |
429 | 4xx 클라이언트 오류 | Too Many Requests — 요청 한도 초과 | '" 429 ' |
500 | 5xx 서버 오류 | Internal Server Error — 서버 내부 오류 | '" 500 ' |
502 | 5xx 서버 오류 | Bad Gateway — 업스트림 서버 오류 | '" 502 ' |
503 | 5xx 서버 오류 | Service Unavailable — 서버 과부하·점검 | '" 503 ' |
4xx/5xx 에러를 grep으로 한 번에 집계하는 패턴:
# 상태 코드별 에러 수 분포 (4xx, 5xx 합산)
awk '$9 ~ /^[45][0-9][0-9]$/ {count[$9]++} END{for(c in count) print count[c], c}' \
/var/log/nginx/access.log | sort -rn
# 5xx 에러율 계산
TOTAL=$(wc -l < /var/log/nginx/access.log)
ERRORS=$(grep -cE '" 5[0-9]{2} ' /var/log/nginx/access.log)
echo "5xx 에러율: $(echo "scale=2; $ERRORS * 100 / $TOTAL" | bc)%"
대용량 로그를 보는 법 — less가 정답
수백 MB 로그를 여는 올바른 방법 — cat 말고 less, 압축 로그는 zless
장애 대응 중 cat /var/log/app.log를 쳤다가 수십만 줄이 터미널을 쓸고 지나가 아무것도 못 본 경험은 누구나 있습니다. 대용량 파일에 cat은 금물입니다 — 파일 전체를 화면으로 쏟아내고, 압축 로그(.gz)엔 깨진 바이너리를 뿌립니다. 로그는 페이저 less로 봅니다.
less 파일: 파일을 통째로 메모리에 올리지 않고 보는 부분만 스트리밍해서 수 GB 로그도 즉시 열립니다. 이동·검색 키는 vim과 같습니다 —G(끝=최신),gg(처음),/패턴→n/N,Ctrl+f/Ctrl+b(페이지).q로 종료.- 실시간 추적:
less안에서F를 누르면tail -f처럼 새 줄을 따라갑니다(Ctrl+c로 빠져나와 검색). 아예less +F 파일로 열 수도 있습니다. - 보기 좋게:
less -N(줄 번호),less -S(긴 줄을 접지 않고 좌우 스크롤 — access log처럼 한 줄이 긴 로그에 유용). - 한 패턴만 걸러 보기:
less안에서&에러패턴을 치면 매칭되는 줄만 남습니다(페이저 안에서 grep을 거는 셈). - 압축된 회전 로그:
app.log.1.gz같은 파일은 압축을 풀지 않고zless(페이징)·zcat(전체 출력)·zgrep '패턴'(검색)로 봅니다. 여러 날치를 한 번에:zgrep -h ERROR app.log*.gz | less. - systemd 서비스 로그는 파일이 아니라 저널이라
journalctl -u 서비스 -f(실시간),journalctl -u 서비스 --since "1 hour ago" -p err(시간·레벨 필터)로 봅니다.
정리하면 볼 땐 less(압축은 z*), 실시간은 tail -f·less +F·journalctl -f, 걸러낼 땐 grep·&, systemd는 journalctl. cat은 짧은 파일에만 씁니다.
명령어·단축키 빠른 참조
이 모듈에서 다룬 grep·awk·sed와 파이프라인 도구를 실전 옵션과 함께 모았습니다. "예" 열의 조합을 그대로 써도 됩니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
less 파일 | 대용량 파일을 스트리밍으로 조회(cat 대신) | less -SN app.log, 안에서 /·G·&패턴·F(추적) |
zless / zcat / zgrep | 압축(.gz) 회전 로그 조회·검색 | zgrep -h ERROR app.log*.gz | less (여러 날치 한 번에) |
grep | 패턴 검색 | grep -rn -i "error" /var/log (재귀·대소문자·줄번호) |
grep -E | 정규식 검색 | grep -E "4[0-9]{2}|5[0-9]{2}" access.log (4xx·5xx) |
grep -A/-B/-C | 매칭 줄 전후 맥락 | grep -C 2 "ERROR" app.log |
awk | 필드 단위 처리·조건 | awk '$9!=200 {print $1, $9}' access.log |
awk -F | 구분자 지정 | awk -F: '{print $1}' /etc/passwd |
sed | 스트림 치환·삭제 | sed -i.bak 's/old/new/g' config.txt (백업 남기고) |
sort / uniq -c | 정렬·빈도 집계 | … | sort | uniq -c | sort -rn (Top-N) |
cut | 열 추출 | cut -d' ' -f1 access.log (IP만) |
tail -f | 실시간 로그 추적 | tail -f app.log | grep --line-buffered ERROR |
jq | JSON 로그 파싱 | jq 'select(.level=="ERROR") .msg' app.json |
| (파이프) / tee | 출력 연결·중간 저장 | cmd 2>&1 | tee out.log | wc -l |
관련 모듈로 더 깊이:
- 백엔드 개발자를 위한 실전 Bash 쉘 스크립트 핵심 가이드 — 텍스트 처리 명령들을 조건·루프로 엮어 자동화 스크립트를 만드는 법
- logrotate로 서버 용량 갉아먹는 로그 파일 자동 압축/분할 — 분석 대상 로그가 너무 커지지 않게 순환·압축하는 법
- journalctl로 모든 커널/서비스 로그 검색 및 실시간 모니터링 — 파일 로그가 아닌 journald 로그를 추출·필터링하는 법
다음 모듈에서는 grep/awk/sed로 배운 텍스트 처리 능력을 바탕으로 bash 스크립팅을 다룹니다 — 반복 작업을 자동화하고 조건 분기·루프·함수로 실무 스크립트를 구성하는 법을 배웁니다.