트래픽이 늘어난 뒤부터 nginx가 간헐적으로 Too many open files 에러를 내뱉습니다. 코드는 바뀐 게 없는데 서비스만 죽습니다. 커널 튜닝을 해본다고 sysctl -w net.core.somaxconn=65535를 설정했지만, 서버를 재부팅하자 원상복구됐습니다. 그리고 TIME_WAIT 소켓이 수만 개 쌓여 있다는 사실을 이제서야 발견했습니다. OS 기본값은 보수적으로 설정되어 있습니다. 실제 워크로드에 맞게 조정하지 않으면 코드를 아무리 최적화해도 OS 레벨에서 막힙니다.
커널 파라미터 & 성능 튜닝
Nginx가 Too many open files로 죽고, TIME_WAIT 소켓이 수만 개 쌓이고, 연결이 backlog에서 조용히 drop되는 현상 — 이 모든 것은 코드 버그가 아니라 OS 설정 문제입니다. 대규모 트래픽 환경에서 서버가 버티려면 Linux 커널이 기본으로 설정해 놓은 보수적인 값들을 실제 워크로드에 맞게 조정해야 합니다. 이 챕터를 마치면 커널 파라미터의 구조를 이해하고, sysctl과 ulimit을 자유자재로 다루며, 고트래픽 서버의 대표적인 OS 레벨 장애를 직접 해결할 수 있습니다.
1. 커널 파라미터란? /proc/sys/ 파일시스템 구조
- 1/proc/sys/ 가상 파일시스템 구조와 sysctl 파라미터 계층을 이해할 수 있다
- 2sysctl로 런타임 값을 조회·변경하고 /etc/sysctl.conf로 영구 적용할 수 있다
- 3파일 디스크립터 개념을 이해하고 ulimit으로 프로세스 리소스 한도를 제어할 수 있다
- 4/etc/security/limits.conf와 systemd LimitNOFILE로 영구 ulimit을 설정할 수 있다
- 5고트래픽 서버를 위해 TCP 백로그·TIME_WAIT·포트 범위 파라미터를 튜닝할 수 있다
- 6lsmod, modprobe, modinfo로 커널 모듈을 관리할 수 있다
sysctl -a 2>/dev/null | wc -l && sysctl fs.file-max net.core.somaxconn vm.swappinessulimit -a | grep -E 'open files|max user processes' && cat /proc/sys/fs/file-nrls /etc/sysctl.conf /etc/sysctl.d/ 2>/dev/nullsysctl 값 변경과 limits.conf 수정은 root 권한이 필요합니다. 잘못된 커널 파라미터는 시스템 불안정을 유발할 수 있으므로 반드시 변경 전 기존 값을 기록해 두세요.
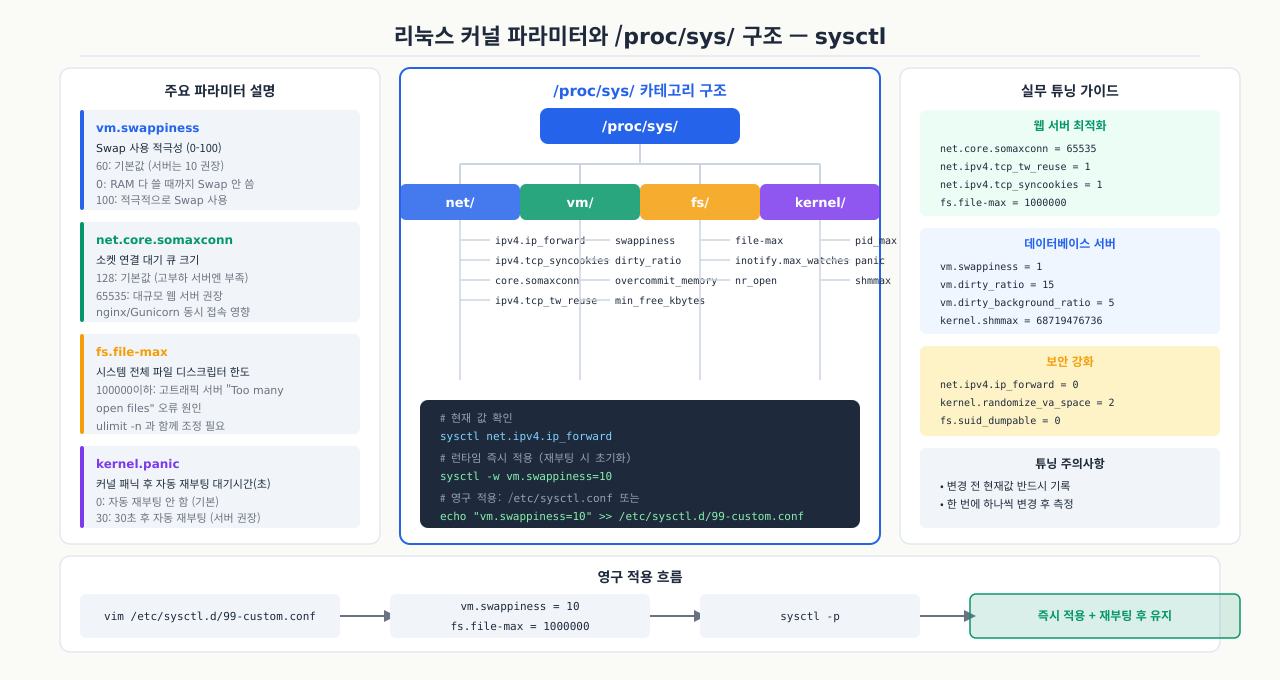
리눅스 커널 파라미터와 /proc/sys/ 구조
 확대
확대
실서비스에서 net.core.somaxconn을 128에서 4096으로 올렸더니 갑자기 연결 drop이 사라졌습니다. 그런데 재부팅 후 다시 128로 돌아갔습니다. sysctl -w로 변경하면 런타임에만 적용되고, /etc/sysctl.conf에 써야 영구 적용됩니다. 커널 파라미터는 수백 개이지만, 그 이름들이 /proc/sys/ 디렉토리 구조를 그대로 따르기 때문에 계층 구조를 한 번만 파악해두면 낯선 파라미터 이름도 어느 영역인지 바로 알 수 있습니다.
Linux 커널은 수백 개의 동작 방식을 런타임에 조정할 수 있도록 가상 파일시스템 형태로 파라미터를 노출합니다. 이 파일시스템이 /proc/sys/입니다. sysctl net.core.somaxconn이라고 입력하면 커널이 /proc/sys/net/core/somaxconn 파일의 값을 읽어 반환합니다. 디렉토리 계층 구조를 먼저 파악하면 파라미터 이름이 낯설지 않게 됩니다.
/proc/sys/ 아래의 주요 디렉토리 계층입니다.
kernel/— 커널 전반:pid_max,hostname,panicnet/— 네트워크 스택 전체core/— 소켓 버퍼·백로그:somaxconn,rmem_max,wmem_maxipv4/— IPv4 TCP/UDP:tcp_tw_reuse,ip_local_port_range,tcp_fin_timeout
vm/— 가상 메모리:swappiness,dirty_ratio,overcommit_memoryfs/— 파일시스템:file-max,inotify/
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/linux/part5/exam_9 && cd /tmp/linux/part5/exam_9
# 현재 커널 파라미터 스냅샷
sysctl -a 2>/dev/null | grep -E "^(net\.|vm\.|kernel\.)" | sort > current_params.txt
echo "파라미터 스냅샷 저장 완료: $(wc -l < current_params.txt)개"
# 적용할 튜닝 설정 파일 초안
cat > 99-custom-tuning.conf << 'EOF'
# /etc/sysctl.d/99-custom-tuning.conf
# 웹 서버 최적화 설정
# TCP 연결 최대 대기열
net.core.somaxconn = 65535
# TIME_WAIT 소켓 재사용 허용
net.ipv4.tcp_tw_reuse = 1
# 스왑 사용 최소화 (SSD 서버)
vm.swappiness = 10
# 파일 디스크립터 최대값
fs.file-max = 1000000
EOF
이제 실습을 진행합니다.
핵심 개념: /proc/sys/ 아래의 모든 파일은 실제 디스크에 존재하지 않습니다. 커널 메모리의 값을 파일처럼 읽고 쓸 수 있도록 가상화한 것입니다. 따라서 cat으로 읽고 echo로 쓸 수 있지만, 재부팅하면 원래대로 돌아갑니다.
# 현재 커널 파라미터 직접 읽기
cat /proc/sys/net/core/somaxconn
# 128
# 직접 쓰기 (즉시 적용, 재부팅 시 초기화됨)
echo 65535 > /proc/sys/net/core/somaxconn
/proc/sys/ 경로와 sysctl 키 이름의 관계:
/proc/sys/net/core/somaxconn → sysctl 키: net.core.somaxconn
경로 구분자 /가 점 .으로 바뀝니다. 이 점-표기법이 sysctl 명령에서 사용하는 키 이름입니다.
sysctl 한 줄이 커널에 적용되고 재부팅 후에도 살아남기까지 — 4단계
실서비스에서 net.core.somaxconn을 65535로 올려 연결 drop을 잡았는데, 재부팅하니 128로 돌아가 장애가 재발한 경험은 흔합니다. 커널 파라미터에는 "지금 적용"과 "재부팅 후에도 유지"라는 서로 다른 두 가지가 있고, 이 둘은 각각 따로 해줘야 하기 때문입니다. sysctl -w로 바꾼 값이 /proc/sys에 반영됐다가 어떻게 영속 파일로 저장되고 부팅 때 다시 로드되는지, 그 흐름을 알면 "고쳤는데 왜 또 돌아왔지"가 사라집니다.
sysctl -w net.core.somaxconn=65535
│
① 커널 메모리의 값 변경 (즉시)
│
② /proc/sys/net/core/somaxconn 에 반영 (지금부터 커널 동작이 바뀜, 그러나 디스크엔 없음)
│
── 여기서 멈추면? ── 재부팅 시 값 유실 → 기본값으로 복귀
│
③ /etc/sysctl.d/99-tune.conf 에 기록 (영속화 — 적는다고 지금 적용되진 않음)
│ └ sysctl --system (또는 -p) → 파일을 읽어 지금 즉시 반영
│
④ 재부팅 → systemd-sysctl 이 *.conf 로드 (부팅 시 값 복원)
▼
cat /proc/sys/net/core/somaxconn → 65535 (재부팅 후에도 유지)
각 단계에서 무슨 일이 일어나고, 어긋나면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 어긋나면 (증상) |
|---|---|---|
| ① 값 설정 | sysctl -w key=value 또는 /proc/sys에 직접 echo — 커널 메모리의 튜닝 값을 즉시 변경 | 잘못된 값(과도한 버퍼 등)은 즉시 성능 저하·불안정. 변경 전 원래 값을 안 적어두면 되돌리기 어려움 |
| ② /proc/sys 반영 | 점(.) 표기 키가 /proc/sys의 파일 경로에 대응 → 쓰는 즉시 런타임 동작이 바뀜. 단 재부팅까지만 유효 | 여기서 끝내면 재부팅 시 커널 기본값으로 복귀 → "어제 고쳤는데 오늘 또" 장애의 전형 |
| ③ 영속 파일 기록 | /etc/sysctl.conf 또는 /etc/sysctl.d/*.conf에 key = value 한 줄로 저장 | 파일에 적기만 하고 sysctl -p·--system을 안 하면 다음 재부팅 전까지 미적용. 접두 숫자가 낮으면 뒤 파일이 덮어씀 |
| ④ 부팅 시 로드 | 부팅 때 systemd-sysctl이 /usr/lib·/run·/etc의 *.conf를 순서대로 읽어 재적용 | 컨테이너·네임스페이스별 파라미터는 호스트에서 바꿔도 컨테이너 안에 반영 안 될 수 있음 → 어느 네임스페이스인지 확인 |
즉 "적용"과 "영속"은 별개의 두 작업입니다 — ①②는 지금 이 순간의 런타임 적용, ③④는 재부팅 후에도 살아남게 하는 영속화입니다. 둘 다 해야 완성이고, 가장 흔한 사고는 ②만 하고 ③을 빼먹어 재부팅 때 값이 사라지는 것입니다. 반대로 ③만 적고 sysctl --system을 안 하면 지금은 반영되지 않습니다. 그래서 확인도 두 곳을 봅니다: 지금 값은 sysctl <key>(=cat /proc/sys/...)로, 영속 여부는 /etc/sysctl.d/에 파일이 있는지로 판단합니다.
2. sysctl 명령어: 조회, 임시 변경, 영구 적용
조회
# 특정 파라미터 조회
sysctl net.core.somaxconn
# net.core.somaxconn = 128
# 키워드로 관련 파라미터 전체 조회
sysctl -a | grep tcp_tw
# net.ipv4.tcp_tw_reuse = 0
# 전체 파라미터 목록 (출력이 매우 길어 grep과 함께 사용)
sysctl -a | grep net.ipv4 | head -30
# 파일에서 직접 읽기 (스크립트에서 유용)
cat /proc/sys/net/ipv4/tcp_tw_reuse
임시 변경 (재부팅 시 초기화)
# 단일 파라미터 변경 — 즉시 적용
sudo sysctl -w net.core.somaxconn=65535
# 여러 파라미터 한 번에 변경
sudo sysctl -w net.core.somaxconn=65535 net.ipv4.tcp_tw_reuse=1
# 변경 후 확인
sysctl net.core.somaxconn
# net.core.somaxconn = 65535
영구 적용 — /etc/sysctl.conf 또는 /etc/sysctl.d/
# 방법 1: /etc/sysctl.conf 직접 편집 (레거시 방식, 여전히 널리 사용)
sudo vi /etc/sysctl.conf
# /etc/sysctl.conf 예시
# TCP 연결 backlog 확장
net.core.somaxconn = 65535
# TIME_WAIT 소켓 재사용 허용
net.ipv4.tcp_tw_reuse = 1
# 로컬 포트 범위 확장 (기본: 32768~60999)
net.ipv4.ip_local_port_range = 10000 65535
# 소켓 수신/송신 버퍼 최대값 (바이트, 256MB)
net.core.rmem_max = 268435456
net.core.wmem_max = 268435456
# 스왑 사용 최소화
vm.swappiness = 10
# 방법 2: /etc/sysctl.d/ 드롭-인 방식 (권장 — 모듈화, 충돌 방지)
sudo vi /etc/sysctl.d/99-network-tuning.conf
# /etc/sysctl.d/99-network-tuning.conf
# 숫자 접두사(99-)로 적용 순서 제어. 숫자가 클수록 나중에 적용됨.
net.core.somaxconn = 65535
net.ipv4.tcp_tw_reuse = 1
net.ipv4.ip_local_port_range = 10000 65535
net.core.rmem_max = 268435456
net.core.wmem_max = 268435456
# 설정 파일 즉시 적용 (재부팅 없이)
sudo sysctl -p # /etc/sysctl.conf 적용
sudo sysctl -p /etc/sysctl.d/99-network-tuning.conf # 특정 파일 적용
sudo sysctl --system # /etc/sysctl.d/ 전체 적용 (권장)
적용 우선순위: /etc/sysctl.d/ 파일들은 파일명 알파벳 순으로 적용됩니다. 99-로 시작하는 파일은 거의 마지막에 적용되므로 다른 패키지 설정을 덮어쓸 수 있습니다.
- sysctl fs.file-max 실행 후 변경한 값이 즉시 반영되어 있다
- sysctl -p 실행 후 /etc/sysctl.conf 에 기록한 값이 '설정' 메시지와 함께 출력된다
- cat /proc/sys/net/core/somaxconn 값이 변경 전 128(또는 시스템 기본값)에서 설정한 값으로 바뀌어 있다
- 재부팅 후에도 sysctl -a | grep somaxconn 에서 설정한 값이 유지된다 (영구 설정 검증)
3. 파일 디스크립터(File Descriptor) 개념
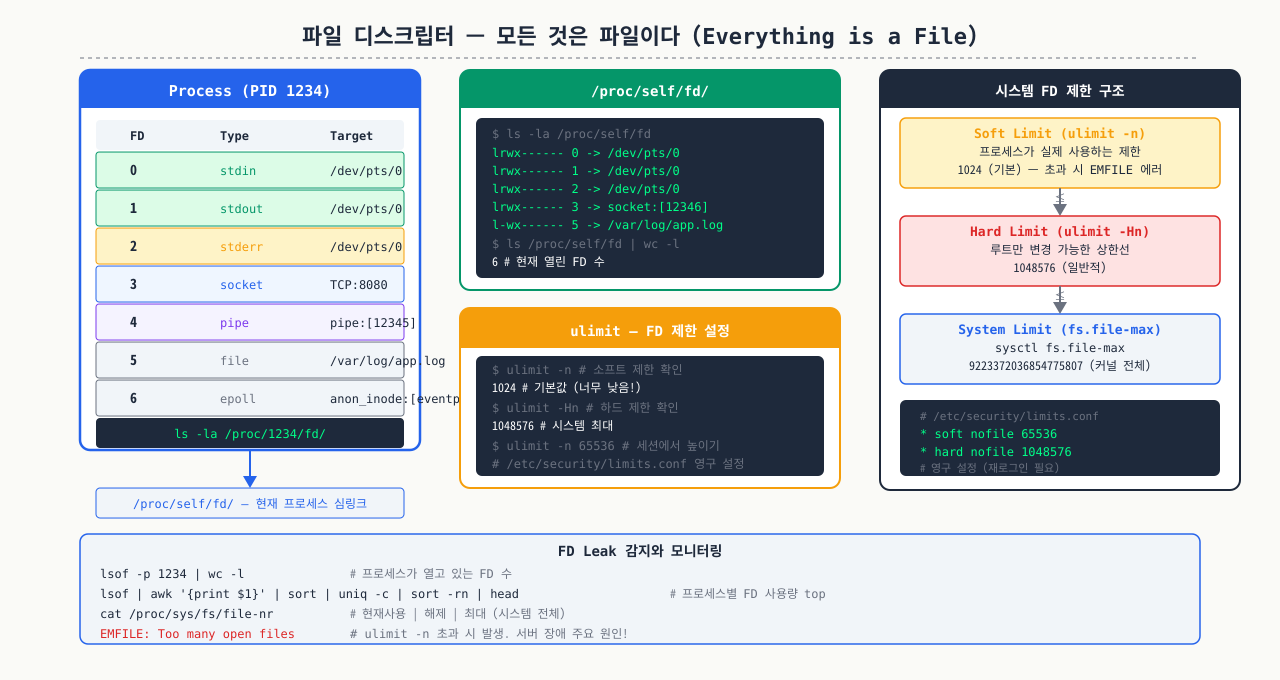
파일 디스크립터 — 모든 것은 파일이다
 확대
확대
Nginx 로그에 (24: Too many open files) 에러가 찍히기 시작하면, 서버 메모리나 CPU 문제가 아닙니다. Nginx 프로세스가 열 수 있는 파일 디스크립터 한도에 도달한 겁니다. ulimit -n으로 보면 1024이고, HTTP 연결 하나에 최소 소켓 2개가 필요하니 동시 연결 500개도 안 됩니다. 이 한도는 왜 존재하는지, 어디서 늘려야 하는지(ulimit vs limits.conf vs systemd LimitNOFILE)를 알려면 파일 디스크립터가 무엇인지부터 이해해야 합니다.
Linux의 핵심 철학 중 하나는 **"모든 것은 파일이다(Everything is a file)"**입니다. 일반 파일뿐 아니라 네트워크 소켓, 파이프, 디바이스, 타이머도 모두 파일 디스크립터(FD)를 통해 접근합니다.
파일 디스크립터가 중요한 이유:
프로세스가 열 수 있는 FD 수 = 동시에 처리할 수 있는 연결/파일 수
Nginx가 처리하는 HTTP 연결 1개 = FD 최소 2개 (클라이언트 소켓 + upstream 소켓)
따라서 동시 연결 10,000개 = FD 최소 20,000개 필요
프로세스별 FD 현황 확인:
# 특정 프로세스의 열린 FD 수
ls /proc/$(pgrep nginx | head -1)/fd | wc -l
# lsof로 프로세스별 열린 파일 목록
lsof -p $(pgrep nginx | head -1) | wc -l
# 시스템 전체 현재 열린 FD 수 / 최대값
cat /proc/sys/fs/file-nr
# 3456 0 97816
# [현재 열린 수] [해제됐지만 미반환] [최대값]
# 시스템 전체 FD 최대값
cat /proc/sys/fs/file-max
# 97816
기본 FD 3개 — 모든 프로세스에 자동 할당:
| FD 번호 | 이름 | 기본 연결 대상 |
|---|---|---|
| 0 | stdin | 키보드 입력 |
| 1 | stdout | 터미널 출력 |
| 2 | stderr | 터미널 에러 출력 |
따라서 일반 프로세스는 3번 FD부터 새로 열린 파일이나 소켓을 할당받습니다.
FD 한도 초과 시 발생하는 에러:
nginx: [alert] socket() failed (24: Too many open files)
java.io.IOException: Too many open files
OSError: [Errno 24] Too many open files
에러 코드 24가 EMFILE이며, 이는 "프로세스당 FD 한도 초과"를 의미합니다. 에러 코드 23은 ENFILE로 "시스템 전체 FD 한도 초과"입니다.
4. ulimit: soft/hard limit 이해 및 설정
ulimit은 현재 쉘과 그 쉘에서 실행되는 모든 프로세스의 리소스 한도를 설정합니다.
soft limit vs hard limit
soft limit: 현재 적용 중인 실제 한도. 프로세스가 스스로 낮출 수도, hard limit까지 높일 수도 있음.
hard limit: soft limit의 상한선. root만 높일 수 있음. 일반 사용자는 낮추는 것만 가능.
# 현재 쉘의 모든 ulimit 조회
ulimit -a
# 출력 예시:
# open files (-n) 1024 ← 이게 문제의 원인!
# max user processes (-u) 65535
# stack size (kbytes, -s) 8192
# virtual memory (kbytes, -v) unlimited
# soft/hard limit 분리 조회
ulimit -Sn # soft limit (파일 수)
ulimit -Hn # hard limit (파일 수)
주요 ulimit 옵션
# -n : 열 수 있는 파일(FD) 최대 수
ulimit -n 65536
# -u : 생성할 수 있는 프로세스(스레드) 최대 수
ulimit -u 65535
# -s : 스택 크기 (KB 단위)
ulimit -s 8192
# -m : 최대 메모리 크기 (KB, 많은 시스템에서 무효)
ulimit -m unlimited
# -c : 코어 덤프 파일 크기 (0 = 코어 덤프 비활성화)
ulimit -c unlimited # 장애 분석을 위해 활성화
# soft/hard 모두 동시에 설정
ulimit -Sn 65536
ulimit -Hn 65536
현재 세션에서 임시 변경
# Nginx 실행 전 FD 한도 높이기 (현재 세션에만 적용)
ulimit -n 65536
nginx
# 확인
ulimit -n
# 65536
주의: ulimit 설정은 현재 쉘 세션에만 적용됩니다. 새 터미널을 열면 기본값으로 돌아갑니다.
5. /etc/security/limits.conf 영구 설정
ulimit을 영구적으로 적용하려면 /etc/security/limits.conf 또는 /etc/security/limits.d/ 드롭-인 파일을 수정해야 합니다. 이 파일은 PAM(Pluggable Authentication Modules)이 사용자 로그인 시 읽어 적용합니다.
파일 형식
<도메인> <타입> <항목> <값>
| 도메인 | 의미 |
|---|---|
* | 모든 사용자 (root 제외) |
root | root 사용자 |
@nginx | nginx 그룹의 모든 사용자 |
www-data | 특정 사용자 |
| 타입 | 의미 |
|---|---|
soft | soft limit 설정 |
hard | hard limit 설정 |
- | soft/hard 동시 설정 |
실제 설정 예시
sudo vi /etc/security/limits.conf
# /etc/security/limits.conf
# 모든 사용자: 파일 디스크립터 65536개 (soft/hard 동시)
* soft nofile 65536
* hard nofile 65536
# root 사용자: 더 높은 한도
root soft nofile 1048576
root hard nofile 1048576
# www-data (nginx/apache 사용자): 대용량 동시 연결 처리
www-data soft nofile 1048576
www-data hard nofile 1048576
www-data soft nproc 65535
www-data hard nproc 65535
# 모든 사용자: 프로세스 수 제한 (fork 폭탄 방지)
* soft nproc 65535
* hard nproc 65535
# 스택 크기 제한 (MB 단위, 기본 8MB)
* soft stack 8192
* hard stack 65536
드롭-인 방식 (권장)
# 애플리케이션별 파일로 분리하여 관리
sudo vi /etc/security/limits.d/99-nginx.conf
# /etc/security/limits.d/99-nginx.conf
www-data soft nofile 1048576
www-data hard nofile 1048576
www-data soft nproc 65535
www-data hard nproc 65535
적용 확인
# 로그아웃 후 재로그인하거나 새 세션에서 확인
su - www-data -s /bin/bash -c 'ulimit -n'
# 1048576
# 특정 프로세스의 실제 한도 확인 (/proc 사용)
cat /proc/$(pgrep nginx | head -1)/limits
# Limit Soft Limit Hard Limit
# Max open files 1048576 1048576
중요: /etc/security/limits.conf 변경은 로그아웃 후 재로그인 또는 서비스 재시작 후에 적용됩니다. 현재 실행 중인 프로세스에는 즉시 영향을 주지 않습니다.
6. 핵심 TCP 튜닝 파라미터
net.core.somaxconn — 연결 backlog 크기
# 현재 값 확인
sysctl net.core.somaxconn
# net.core.somaxconn = 128 ← 기본값, 고트래픽에선 너무 작음
# 문제: 트래픽이 급증하면 accept 큐가 가득 차 연결이 drop됨
# 증상: 클라이언트에서 "Connection refused" 에러 발생
# 영구 적용
sudo bash -c 'cat >> /etc/sysctl.d/99-network-tuning.conf << EOF
net.core.somaxconn = 65535
net.ipv4.tcp_max_syn_backlog = 65535
EOF'
sudo sysctl --system
# Nginx에서도 별도로 backlog 지정 필요
# nginx.conf: listen 80 backlog=65535;
net.ipv4.tcp_tw_reuse — TIME_WAIT 소켓 재사용
sysctl net.ipv4.tcp_tw_reuse
# net.ipv4.tcp_tw_reuse = 0 ← 기본값
# TIME_WAIT 상태: TCP 연결 종료 후 약 60초간 유지되는 상태
# 문제: 로컬 포트가 TIME_WAIT 소켓에 묶여 새 연결에 사용 불가
# tcp_tw_reuse=1: 안전한 경우에만 TIME_WAIT 소켓을 새 연결에 재사용
echo "net.ipv4.tcp_tw_reuse = 1" | sudo tee -a /etc/sysctl.d/99-network-tuning.conf
sudo sysctl --system
# 주의: tcp_tw_recycle은 Linux 4.12부터 제거됨 — 사용 금지!
# NAT 환경(AWS, GCP 등)에서 tcp_tw_recycle 사용 시 심각한 연결 장애 발생
net.ipv4.ip_local_port_range — 로컬 포트 범위
cat /proc/sys/net/ipv4/ip_local_port_range
# 32768 60999 ← 기본값: 약 28,000개의 로컬 포트만 사용 가능
# 문제: Nginx→upstream 연결 등 외부로 나가는 연결이 많을 때 포트 고갈
# 해결: 포트 범위 확장
echo "net.ipv4.ip_local_port_range = 10000 65535" | sudo tee -a /etc/sysctl.d/99-network-tuning.conf
sudo sysctl --system
# 변경 후: 약 55,000개의 로컬 포트 사용 가능
net.core.rmem_max / wmem_max — 소켓 버퍼 크기
sysctl net.core.rmem_max net.core.wmem_max
# net.core.rmem_max = 212992 ← 약 200KB (기본값)
# net.core.wmem_max = 212992
# 고대역폭 환경(10Gbps+)에서는 기본 버퍼가 병목이 됨
# 권장값: 256MB (Bandwidth-Delay Product에 맞게 조정)
cat >> /etc/sysctl.d/99-network-tuning.conf << 'EOF'
# 소켓 수신/송신 버퍼 최대값 (256MB)
net.core.rmem_max = 268435456
net.core.wmem_max = 268435456
# TCP 자동 튜닝 버퍼 범위 (최소, 기본, 최대)
net.ipv4.tcp_rmem = 4096 87380 268435456
net.ipv4.tcp_wmem = 4096 65536 268435456
EOF
sudo sysctl --system
vm.swappiness — 스왑 사용 적극성 제어
sysctl vm.swappiness
# vm.swappiness = 60 ← 기본값: 스왑 사용을 얼마나 적극적으로 고려할지 나타내는 점수(메모리 사용률 60%가 아님)
# 웹 서버/DB 서버: 스왑은 응답 지연을 유발함
# 0: 스왑을 절대 안 쓴다는 의미가 아님 (OOM killer 방지용으로 극소량 씀)
# 1: 스왑을 가능한 한 쓰지 않음 (권장)
# 10: 낮은 스왑 사용 (대부분 서버 환경 권장값)
# 100: 적극적으로 스왑 사용 (데스크톱 환경)
echo "vm.swappiness = 10" | sudo tee -a /etc/sysctl.d/99-network-tuning.conf
sudo sysctl --system
# 현재 스왑 사용량 확인
free -h
swapon --show
추가 유용한 파라미터
# TIME_WAIT 소켓 최대 개수 (기본: 8192, 고트래픽에서 증가 필요)
net.ipv4.tcp_max_tw_buckets = 1440000
# FIN_WAIT_2 타임아웃 단축 (기본: 60초)
net.ipv4.tcp_fin_timeout = 30
# keepalive 설정 (idle 7200초, 간격 75초, 9번 재시도)
net.ipv4.tcp_keepalive_time = 300
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 9
7. 실무: Nginx 'Too many open files' 에러 해결 전 과정
증상
# /var/log/nginx/error.log
2026/03/26 14:23:07 [alert] 12345#12345: *1048576 socket() failed (24: Too many open files) while connecting to upstream
2026/03/26 14:23:07 [crit] 12345#12345: accept4() failed (24: Too many open files)
Nginx가 더 이상 새 연결을 받지 못하고, 이미 연결된 요청도 upstream 소켓을 열지 못해 502 에러 폭발.
1단계: 현재 상황 진단
# Nginx 프로세스의 실제 FD 한도 확인
cat /proc/$(pgrep -o nginx)/limits | grep "Max open files"
# Max open files 1024 4096
# 현재 Nginx가 사용 중인 FD 수
ls /proc/$(pgrep -o nginx)/fd | wc -l
# 1019 ← 1024 한도에 거의 도달!
# 시스템 전체 FD 사용 현황
cat /proc/sys/fs/file-nr
# 89432 0 97816
# 어떤 파일/소켓이 많이 열렸는지 확인
lsof -p $(pgrep -o nginx) | awk '{print $5}' | sort | uniq -c | sort -rn | head
# 850 IPv4
# 120 REG
# 49 FIFO
2단계: 임시 응급 조치 (서비스 즉시 복구)
# 방법 1: Nginx에 직접 fd 한도를 올려서 재시작 (다운타임 발생)
ulimit -n 1048576
sudo systemctl restart nginx
# 방법 2: Nginx worker 프로세스에 직접 prlimit 적용 (재시작 없이)
# (Linux 3.2+, prlimit 명령 사용)
for pid in $(pgrep nginx); do
sudo prlimit --nofile=1048576:1048576 --pid $pid
done
# 효과 즉시 확인
cat /proc/$(pgrep -o nginx)/limits | grep "Max open files"
# Max open files 1048576 1048576
3단계: 영구 해결
a) /etc/security/limits.d/nginx.conf 설정:
www-data soft nofile 1048576
www-data hard nofile 1048576
b) systemd 서비스 설정 (권장 — 아래 섹션에서 상세 설명):
# /etc/systemd/system/nginx.service.d/override.conf
[Service]
LimitNOFILE=1048576
c) Nginx 설정 파일에서 worker_rlimit_nofile 설정:
# /etc/nginx/nginx.conf
user www-data;
worker_processes auto;
worker_rlimit_nofile 1048576; # ← 이 줄 추가
events {
worker_connections 65536; # worker_rlimit_nofile보다 작아야 함
use epoll;
multi_accept on;
}
d) 시스템 전체 FD 최대값 확장:
echo "fs.file-max = 2097152" | sudo tee -a /etc/sysctl.d/99-fs-tuning.conf
sudo sysctl --system
4단계: 검증
# 재시작 후 실제 한도 확인
sudo systemctl restart nginx
cat /proc/$(pgrep -o nginx)/limits | grep "Max open files"
# Max open files 1048576 1048576
# 로그에 에러가 더 이상 나오지 않는지 모니터링
sudo tail -f /var/log/nginx/error.log
8. 실무: 고트래픽 서버 TIME_WAIT 폭증 문제 해결
 확대
확대
증상
# ss 또는 netstat으로 확인 시 TIME_WAIT 소켓이 수만 개
ss -s
# TCP: 45231 (estab 2341, closed 41823, orphaned 0, timewait 41823)
# ↑ 폭증!
# 새 연결 시도 시 로그에 나타나는 에러
# connect: Cannot assign requested address (EADDRNOTAVAIL)
# 로컬 포트가 모두 TIME_WAIT 상태라 새 소켓을 못 만드는 상황
원인 분석
# TIME_WAIT 상태 소켓 상세 확인
ss -tan state time-wait | head -20
# CLOSE-WAIT 0 0 10.0.1.5:443 10.0.2.100:34521 timer:(timewait,58sec,0)
# 로컬 포트 고갈 여부 확인
cat /proc/sys/net/ipv4/ip_local_port_range
# 32768 60999 ← 약 28,000개 가용
# 현재 사용 중인 포트 수 확인
ss -tan | grep TIME_WAIT | wc -l
# 27891 ← 로컬 포트 범위의 99% 사용 중!
해결 방법
# 1. 로컬 포트 범위 확장 (즉시 가용 포트 증가)
sudo sysctl -w net.ipv4.ip_local_port_range="10000 65535"
# 2. TIME_WAIT 소켓 재사용 허용
sudo sysctl -w net.ipv4.tcp_tw_reuse=1
# 3. TIME_WAIT 타임아웃 단축 (기본 FIN_WAIT_2 60초 → 30초)
sudo sysctl -w net.ipv4.tcp_fin_timeout=30
# 4. TIME_WAIT 버킷 최대값 증가
sudo sysctl -w net.ipv4.tcp_max_tw_buckets=1440000
영구 설정 파일:
# /etc/sysctl.d/99-timewait-tuning.conf
net.ipv4.tcp_tw_reuse = 1
net.ipv4.ip_local_port_range = 10000 65535
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_max_tw_buckets = 1440000
sudo sysctl --system
# 적용 후 모니터링
watch -n 2 'ss -s | grep timewait'
근본적 해결: keepalive 활용
가장 좋은 해결책은 TIME_WAIT 자체를 줄이는 것입니다. Nginx에서 upstream keepalive를 활성화하면 매 요청마다 TCP 연결을 새로 만들지 않아 TIME_WAIT 발생이 극적으로 줄어듭니다.
upstream backend {
server 127.0.0.1:8080;
keepalive 300; # upstream과의 keepalive 연결 최대 300개 유지
}
server {
location / {
proxy_pass http://backend;
proxy_http_version 1.1;
proxy_set_header Connection ""; # keepalive를 위해 Connection 헤더 제거
}
}
9. systemd 서비스별 리소스 제한
/etc/security/limits.conf는 로그인 세션에 적용되지만, systemd 서비스는 로그인 없이 직접 실행되므로 systemd Unit 파일에서 별도로 리소스 한도를 설정해야 합니다.
systemd 서비스 단위 리소스 제한 항목
| systemd 옵션 | 대응 ulimit | 의미 |
|---|---|---|
LimitNOFILE | -n | 파일 디스크립터 최대 수 |
LimitNPROC | -u | 프로세스/스레드 최대 수 |
LimitSTACK | -s | 스택 크기 (바이트) |
LimitCORE | -c | 코어 덤프 크기 |
LimitAS | -v | 가상 메모리 크기 |
LimitMEMLOCK | -l | 메모리 잠금 크기 |
방법 1: 드롭-인 override 파일 (권장)
원본 서비스 파일을 건드리지 않고 override만 추가하는 방식입니다. 패키지 업데이트 시 원본이 덮어써져도 override는 유지됩니다.
# systemctl edit 명령으로 override 파일 자동 생성
sudo systemctl edit nginx
에디터가 열리면 다음 내용을 입력합니다:
# 이 파일은 /etc/systemd/system/nginx.service.d/override.conf 로 저장됨
[Service]
LimitNOFILE=1048576
LimitNPROC=65535
# 저장 후 적용
sudo systemctl daemon-reload
sudo systemctl restart nginx
# 확인
systemctl show nginx | grep -E "LimitNOFILE|LimitNPROC"
# LimitNOFILE=1048576
# LimitNPROC=65535
# 실제 프로세스에 적용됐는지 /proc으로 최종 확인
cat /proc/$(pgrep -o nginx)/limits
방법 2: 서비스 파일 직접 수정
# 편집
sudo vi /lib/systemd/system/nginx.service
# 또는 커스텀 위치에 복사 후 편집
sudo cp /lib/systemd/system/nginx.service /etc/systemd/system/nginx.service
sudo vi /etc/systemd/system/nginx.service
[Unit]
Description=A high performance web server and a reverse proxy server
After=network.target
[Service]
Type=forking
PIDFile=/run/nginx.pid
ExecStartPre=/usr/sbin/nginx -t -q -g 'daemon on; master_process on;'
ExecStart=/usr/sbin/nginx -g 'daemon on; master_process on;'
ExecReload=/bin/kill -s HUP $MAINPID
KillSignal=SIGQUIT
TimeoutStopSec=5
KillMode=mixed
PrivateTmp=true
# 리소스 한도 추가
LimitNOFILE=1048576 # FD 최대 1M
LimitNPROC=65535 # 프로세스 65535개
LimitCORE=infinity # 코어 덤프 제한 없음 (장애 분석용)
[Install]
WantedBy=multi-user.target
sudo systemctl daemon-reload
sudo systemctl restart nginx
Java 애플리케이션 예시 (스레드가 많은 경우)
# /etc/systemd/system/myapp.service.d/override.conf
[Service]
LimitNOFILE=1048576
LimitNPROC=131072 # Java는 스레드당 1개의 프로세스로 계산됨
LimitSTACK=67108864 # 64MB 스택
10. 커널 모듈: lsmod, modprobe, modinfo
Linux 커널은 모듈(Module) 방식으로 기능을 동적으로 추가/제거할 수 있습니다. 드라이버, 파일시스템, 네트워크 프로토콜 등이 모듈로 제공됩니다.
현재 로드된 모듈 확인: lsmod
lsmod
# Module Size Used by
# nf_conntrack 172032 4 nf_nat,nf_conntrack_netlink,xt_conntrack,nf_conntrack_ipv4
# br_netfilter 24576 0
# overlay 143360 1
# ip_tables 32768 1 iptables
# ...
# 컬럼 의미:
# Module : 모듈 이름
# Size : 메모리 사용량 (바이트)
# Used by : 이 모듈을 의존하는 다른 모듈 수와 이름
# 특정 모듈 확인
lsmod | grep overlay
# overlay 143360 1
모듈 정보 조회: modinfo
# 모듈의 상세 정보 조회
modinfo overlay
# filename: /lib/modules/5.14.0/kernel/fs/overlayfs/overlay.ko.xz
# description: Overlay filesystem
# author: Miklos Szeredi <miklos@szeredi.hu>
# license: GPL
# depends:
# parm: redirect_dir:Enable directory redirects (bool)
# 파라미터 목록만 추출
modinfo -p br_netfilter
# nf_call_iptables:If != 0, call ip[6]tables for bridged frames (uint)
# nf_call_arptables:If != 0, call arptables for bridged frames (uint)
모듈 로드/언로드: modprobe
# 모듈 로드 (의존 모듈 자동 로드)
sudo modprobe br_netfilter
# 모듈 언로드 (의존 모듈 자동 제거)
sudo modprobe -r br_netfilter
# 파라미터와 함께 로드
sudo modprobe tcp_bbr # BBR TCP 혼잡 제어 알고리즘 로드
# 로드된 모듈의 의존성 트리 확인
modprobe --show-depends nf_conntrack
부팅 시 자동 로드: /etc/modules-load.d/
# 부팅 시 특정 모듈 자동 로드 설정
sudo vi /etc/modules-load.d/custom.conf
# /etc/modules-load.d/custom.conf
# 각 줄에 모듈 이름 하나씩
# Kubernetes/Docker용 네트워크 모듈
br_netfilter
overlay
# BBR TCP 혼잡 제어 (고트래픽 서버 성능 향상)
tcp_bbr
# 네트워크 필터
ip_conntrack
# 파일 적용 확인 (재부팅 없이 수동으로 로드)
sudo systemd-modules-load
# 또는 직접 확인
sudo modprobe br_netfilter
lsmod | grep br_netfilter
모듈 블랙리스트 (특정 모듈 로드 방지)
# 드라이버 충돌이나 보안 문제로 특정 모듈 블랙리스트 처리
sudo vi /etc/modprobe.d/blacklist-nouveau.conf
# /etc/modprobe.d/blacklist-nouveau.conf
# NVIDIA 오픈소스 드라이버 비활성화 (독점 드라이버 설치 시)
blacklist nouveau
options nouveau modeset=0
# initramfs 재생성 후 재부팅 (블랙리스트 완전 적용을 위해)
sudo update-initramfs -u # Debian/Ubuntu
sudo dracut -f # RHEL/CentOS/Rocky
11. 종합 실무 시나리오
상황
월간 트래픽 1억 건, 피크 타임 초당 10,000 요청을 처리하는 API 서버를 새로 배포하는 시나리오.
진단 먼저
# 현재 기본값 스냅샷 저장 (변경 전 백업)
sysctl -a > /tmp/sysctl-before-tuning.txt
# 현재 네트워크 상태 확인
ss -s
cat /proc/sys/net/core/somaxconn
cat /proc/sys/net/ipv4/ip_local_port_range
ulimit -n
# 시스템 리소스 전체 현황
nproc
free -h
cat /proc/sys/fs/file-max
튜닝 파일 작성
sudo tee /etc/sysctl.d/99-api-server-tuning.conf << 'EOF'
# ===== 네트워크 연결 관리 =====
# TCP 연결 backlog 확장 (기본 128 → 65535)
net.core.somaxconn = 65535
net.ipv4.tcp_max_syn_backlog = 65535
# TIME_WAIT 소켓 재사용 허용
net.ipv4.tcp_tw_reuse = 1
# 로컬 포트 범위 확장 (기본 32768-60999 → 10000-65535)
net.ipv4.ip_local_port_range = 10000 65535
# TIME_WAIT 버킷 증가 (기본 8192 → 1440000)
net.ipv4.tcp_max_tw_buckets = 1440000
# FIN_WAIT_2 타임아웃 단축 (기본 60초 → 30초)
net.ipv4.tcp_fin_timeout = 30
# ===== 소켓 버퍼 =====
# 수신/송신 버퍼 최대값 (256MB)
net.core.rmem_max = 268435456
net.core.wmem_max = 268435456
# TCP 자동 버퍼 튜닝 (최소/기본/최대)
net.ipv4.tcp_rmem = 4096 87380 268435456
net.ipv4.tcp_wmem = 4096 65536 268435456
# ===== keepalive =====
# 유휴 연결 keepalive 주기 (기본 7200초 → 300초)
net.ipv4.tcp_keepalive_time = 300
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 9
# ===== 파일시스템 =====
# 시스템 전체 FD 최대값
fs.file-max = 2097152
# ===== 가상 메모리 =====
# 스왑 최소화 (응답 지연 방지)
vm.swappiness = 10
EOF
sudo sysctl --system
FD 한도 영구 설정
sudo tee /etc/security/limits.d/99-api-server.conf << 'EOF'
# API 서버 실행 사용자 (예: apiuser)
apiuser soft nofile 1048576
apiuser hard nofile 1048576
apiuser soft nproc 65535
apiuser hard nproc 65535
# root 포함 모든 사용자
* soft nofile 65536
* hard nofile 65536
EOF
systemd 서비스 설정
sudo mkdir -p /etc/systemd/system/api-server.service.d
sudo tee /etc/systemd/system/api-server.service.d/resource-limits.conf << 'EOF'
[Service]
LimitNOFILE=1048576
LimitNPROC=65535
LimitCORE=infinity
EOF
sudo systemctl daemon-reload
sudo systemctl restart api-server
검증
# 적용 결과 확인
sysctl net.core.somaxconn net.ipv4.tcp_tw_reuse net.ipv4.ip_local_port_range
cat /proc/$(pgrep api-server)/limits
# 부하 테스트 중 실시간 모니터링
watch -n 1 'ss -s; echo "---"; cat /proc/sys/fs/file-nr'
심화 — 연결 backlog는 사실 두 개다
심화: SYN 큐와 accept 큐 — somaxconn만 올려선 안 되는 이유
net.core.somaxconn을 올리는 튜닝은 '연결 대기열을 키운다'로 이해되곤 하지만, 실제로는 3-way handshake 과정에서 연결이 두 개의 서로 다른 큐를 거칩니다. 이 둘을 구분하지 못하면 somaxconn을 최대로 올리고도 연결이 계속 드롭됩니다.
- SYN 큐(half-open): 커널이 SYN을 받고 SYN-ACK를 보낸 뒤 클라이언트의 마지막 ACK를 기다리는 미완성 연결의 대기열. 크기는
net.ipv4.tcp_max_syn_backlog가 좌우합니다. 여기가 차면 SYN이 드롭돼 SYN flood와 비슷한 증상이 납니다. - accept 큐(완성): handshake가 끝나 ESTABLISHED가 됐지만 애플리케이션이 아직
accept()로 가져가지 않은 완성 연결의 대기열. 크기는min(somaxconn, 앱이 listen(fd, backlog)에 넘긴 backlog 인자)로 정해집니다. - 함정 — 둘 중 작은 값이 이긴다: somaxconn을 65535로 올려도 앱이
listen()에 511을 주면 accept 큐는 511로 캡됩니다(nginx 기본backlog=511, 많은 런타임 기본도 511/128). 반대도 마찬가지입니다. 그래서 커널값·앱 backlog·tcp_max_syn_backlog를 함께 맞춰야 합니다. - 조용한 드롭: accept 큐가 차면 기본 설정(
tcp_abort_on_overflow=0)에서 커널은 완성된 연결을 RST 없이 조용히 무시하고 클라이언트의 재전송을 유도합니다. 앱 로그엔 아무것도 안 남고, 클라이언트만 지연·재시도를 겪습니다.
# 리스닝 소켓의 큐 상태: Recv-Q=현재 대기 연결 수, Send-Q=accept 큐 상한
ss -lnt
# accept 큐 오버플로 카운터 (증가하면 큐가 넘치는 중)
nstat -az | grep -iE 'ListenOverflows|ListenDrops'
# 또는
netstat -s | grep -i 'listen'
한 가지 더: 큐를 키우는 것은 버스트를 흡수할 뿐입니다. 앱이 accept를 충분히 빨리 못 가져가는 게 근본 원인이라면(워커 부족·느린 이벤트 루프), 큐 확대는 지연을 미룰 뿐 없애지 못합니다.
상황: 연결 드롭을 막으려 net.core.somaxconn을 65535로 올렸습니다. 그런데 피크 트래픽에서 일부 요청이 응답 없이 몇 초 지연되다 재시도됩니다. FD 한도도 여유가 있고 TIME_WAIT도 정상인데, 정작 nginx 에러 로그엔 관련 흔적이 전혀 없습니다.
원인: accept 큐 오버플로입니다. 앱이 listen()에 넘긴 backlog 인자(nginx 기본 backlog=511)가 somaxconn보다 작아, accept 큐가 커널값이 아니라 그 작은 값으로 캡됐습니다. 큐가 차자 커널은 기본값(tcp_abort_on_overflow=0)대로 완성된 연결을 조용히 무시했고 — 그래서 앱 로그엔 남지 않고 클라이언트만 지연·재시도를 겪은 것입니다.
진단: ss -lnt로 리스닝 소켓의 Recv-Q(대기 중 연결 수)가 Send-Q(큐 상한)에 붙는지 봅니다. nstat -az | grep -i ListenOverflows(또는 netstat -s | grep -i listen)의 카운터가 트래픽 피크와 함께 증가하면 accept 큐 오버플로 확정입니다. 필요하면 진단용으로만 tcp_abort_on_overflow=1을 잠깐 켜 오버플로를 RST로 드러내 볼 수 있습니다(운영 상시 사용은 권장하지 않음).
해결: somaxconn뿐 아니라 앱의 listen backlog도 함께 키웁니다 — nginx라면 listen 80 backlog=65535;, 여기에 tcp_max_syn_backlog도 상향합니다. 그러나 근본 원인이 '앱이 accept를 못 따라가는 것'일 수 있으므로 워커 수·이벤트 루프 처리량을 함께 점검해야 합니다. 큐 확대는 버스트 흡수일 뿐, 처리 능력이 부족하면 지연을 뒤로 미룰 뿐입니다.
12. 실무 관점: OS 튜닝이 실제로 돈이 되는 이유
장애 대응 속도의 차이
OS 레벨 튜닝 지식이 없는 엔지니어는 Too many open files 에러가 나면 "애플리케이션 버그인가?" 또는 "서버를 더 늘려야 하나?"를 먼저 생각합니다. OS 튜닝을 아는 엔지니어는 30초 안에 원인을 찾고 5분 안에 서비스를 복구합니다.
# 진단 루틴 (1분 안에 끝낼 수 있어야 함)
cat /proc/$(pgrep 서비스명 | head -1)/limits # FD 한도 확인
ss -s # 소켓 상태 한눈에
sysctl net.core.somaxconn # backlog 확인
cat /proc/sys/fs/file-nr # 시스템 FD 현황
인프라 비용 절감
AWS EC2 m5.xlarge (4코어/16GB) 기준:
| 튜닝 전 | 튜닝 후 | 절감 |
|---|---|---|
| 동시 연결 2,000개 처리 (FD 한도 막힘) | 동시 연결 50,000개 처리 | 서버 25대 → 1대 |
| TIME_WAIT 포트 고갈로 초당 200req | 포트 확장 후 초당 5,000req | 서버 25대 → 1대 |
실제로 OS 기본값 그대로 쓰는 것과 잘 튜닝된 서버의 처리량은 수십 배 차이가 날 수 있습니다.
면접에서 자주 나오는 질문
Q: Nginx에서 동시 접속자 수를 높이려면 어떻게 하나요?
A: (단순) worker_connections만 늘리면 됩니다.
A: (심화) worker_connections, worker_rlimit_nofile, net.core.somaxconn,
/etc/security/limits.conf, LimitNOFILE 를 함께 조정해야 합니다.
각 레이어가 독립적으로 병목이 될 수 있기 때문입니다.
Q: TIME_WAIT가 많으면 왜 문제가 되나요?
A: 로컬 포트를 점유하고 있어 새 연결 시 포트 고갈이 발생할 수 있습니다.
해결 방법은 포트 범위 확장, tcp_tw_reuse 활성화, keepalive 설정입니다.
자동화: 서버 프로비저닝 스크립트에 OS 튜닝 포함
#!/bin/bash
# server-tuning.sh — 신규 서버 배포 시 자동 실행
set -euo pipefail
echo "=== OS 튜닝 적용 시작 ==="
# sysctl 설정
cat > /etc/sysctl.d/99-production-tuning.conf << 'EOF'
net.core.somaxconn = 65535
net.ipv4.tcp_tw_reuse = 1
net.ipv4.ip_local_port_range = 10000 65535
net.ipv4.tcp_max_tw_buckets = 1440000
net.ipv4.tcp_fin_timeout = 30
net.core.rmem_max = 268435456
net.core.wmem_max = 268435456
fs.file-max = 2097152
vm.swappiness = 10
EOF
sysctl --system
# ulimit 설정
cat > /etc/security/limits.d/99-production.conf << 'EOF'
* soft nofile 1048576
* hard nofile 1048576
* soft nproc 65535
* hard nproc 65535
EOF
echo "=== OS 튜닝 완료 ==="
sysctl net.core.somaxconn net.ipv4.tcp_tw_reuse
이런 스크립트를 Ansible playbook, Terraform user_data, 또는 AWS Systems Manager에 통합하면 모든 서버가 동일한 OS 설정으로 프로비저닝됩니다.
13. 커널 모듈과 BBR TCP 혼잡 제어 — 보너스 튜닝
Google이 개발한 BBR(Bottleneck Bandwidth and Round-trip propagation time) 알고리즘은 기존 CUBIC 대비 고지연/고손실 네트워크에서 처리량을 극적으로 향상시킵니다. Linux 4.9+에 포함되어 있으며, 커널 모듈 로드와 sysctl 설정만으로 활성화할 수 있습니다.
# 현재 혼잡 제어 알고리즘 확인
sysctl net.ipv4.tcp_congestion_control
# net.ipv4.tcp_congestion_control = cubic ← 기본값
# 사용 가능한 알고리즘 목록
sysctl net.ipv4.tcp_available_congestion_control
# net.ipv4.tcp_available_congestion_control = reno cubic
# BBR 모듈 로드
sudo modprobe tcp_bbr
# 로드됐는지 확인
lsmod | grep bbr
# tcp_bbr 20480 0
# BBR 활성화
sudo sysctl -w net.ipv4.tcp_congestion_control=bbr
sudo sysctl -w net.core.default_qdisc=fq # BBR과 함께 권장되는 큐 규칙
# 영구 적용
cat >> /etc/sysctl.d/99-bbr.conf << 'EOF'
net.core.default_qdisc = fq
net.ipv4.tcp_congestion_control = bbr
EOF
# 모듈 부팅 시 자동 로드
echo "tcp_bbr" | sudo tee /etc/modules-load.d/bbr.conf
sudo sysctl --system
# 최종 확인
sysctl net.ipv4.tcp_congestion_control
# net.ipv4.tcp_congestion_control = bbr
BBR이 특히 효과적인 환경:
- 클라이언트와 서버 간 RTT가 100ms 이상인 경우
- 전송 중 패킷 손실이 있는 환경 (모바일, 위성)
- CDN 원본 서버와 엣지 서버 간 통신
정리: 커널 파라미터 튜닝 핵심 요약
| 목적 | 설정 항목 | 권장값 |
|---|---|---|
| 연결 backlog 확장 | net.core.somaxconn | 65535 |
| TIME_WAIT 재사용 | net.ipv4.tcp_tw_reuse | 1 |
| 로컬 포트 확장 | net.ipv4.ip_local_port_range | 10000 65535 |
| 소켓 버퍼 확장 | net.core.rmem_max / wmem_max | 268435456 |
| 스왑 최소화 | vm.swappiness | 10 |
| FD 한도 (시스템) | fs.file-max | 2097152 |
| FD 한도 (프로세스) | ulimit -n / LimitNOFILE | 1048576 |
설정 우선순위 (낮은 번호가 우선 적용):
1. 커널 기본값 (부팅 시)
2. /etc/sysctl.d/*.conf (알파벳 순)
3. /etc/sysctl.conf
4. /etc/security/limits.conf (PAM 로그인 시)
5. /etc/security/limits.d/*.conf
6. systemd Unit의 Limit* (서비스 시작 시)
7. 애플리케이션 자체 설정 (nginx worker_rlimit_nofile 등)
각 레이어는 독립적으로 병목이 될 수 있습니다. 한 곳만 올려도 다른 레이어가 막혀 있으면 효과가 없습니다. 모든 레이어를 일관성 있게 설정하는 것이 OS 튜닝의 핵심입니다.
명령어·단축키 빠른 참조
이 모듈에서 다룬 커널 파라미터 조회·튜닝과 리소스 한도 관리 명령을 실전 옵션과 함께 모았습니다. "예" 열의 조합을 그대로 써도 됩니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
sysctl | 커널 파라미터 조회·임시 변경 | sysctl net.core.somaxconn (조회), sudo sysctl -w net.ipv4.tcp_tw_reuse=1 (임시) |
sysctl -a | 전체 파라미터 목록 조회 | sysctl -a | grep tcp_tw (관련 항목만) |
sysctl --system / -p | 설정 파일 반영(재부팅 없이) | sudo sysctl --system (/etc/sysctl.d/ 전체), sudo sysctl -p (/etc/sysctl.conf) |
cat /proc/sys/... | 파라미터 파일 직접 읽기 | cat /proc/sys/fs/file-nr (현재·미반환·최대 FD 수) |
ulimit | 쉘·프로세스 리소스 한도 조회·설정 | ulimit -a (전체), ulimit -n 65536 (FD 한도) |
ulimit -Sn / -Hn | soft·hard 파일 한도 분리 조회 | ulimit -Sn (soft), ulimit -Hn (hard) |
cat /proc/PID/limits | 실행 중 프로세스의 실제 한도 확인 | cat /proc/$(pgrep -o nginx)/limits |
prlimit | 실행 중 프로세스 한도 변경(재시작 없이) | sudo prlimit --nofile=1048576:1048576 --pid PID |
lsof -p | 프로세스가 연 파일·소켓 나열 | lsof -p $(pgrep -o nginx) | wc -l (열린 수) |
ss | 소켓·연결 큐 상태 확인 | ss -s (요약·timewait), ss -lnt (리스닝 Recv-Q/Send-Q) |
nstat / netstat -s | accept 큐 오버플로 카운터 확인 | nstat -az | grep -i ListenOverflows |
systemctl edit | systemd 서비스 리소스 한도 override | sudo systemctl edit nginx → LimitNOFILE=1048576 |
lsmod | 로드된 커널 모듈 목록 | lsmod | grep bbr (특정 모듈 확인) |
modprobe | 커널 모듈 로드·언로드 | sudo modprobe tcp_bbr (로드), modprobe -r br_netfilter (언로드) |
modinfo | 모듈 상세·파라미터 조회 | modinfo -p br_netfilter (파라미터만) |
관련 모듈로 더 깊이:
- OOM Killer 방지를 위한 Swap 메모리 파티션 튜닝 —
vm.swappiness등 메모리 관련 커널 파라미터의 배경이 되는 메모리 동작 - vmstat, iostat, sar로 CPU/디스크 IO 성능 병목 진단 — 튜닝 전후 효과를 지표로 측정·검증하는 관측 기법
- Prometheus & Node Exporter 연동으로 실시간 대시보드 구축 — 커널 지표를 시계열로 수집해 대시보드로 시각화하기
다음 모듈에서는 Prometheus와 Node Exporter를 연동해 커널 튜닝 전후의 성능 지표를 시계열로 수집하고 Grafana 대시보드로 시각화하는 방법을 다룹니다.