서비스 응답 시간이 갑자기 치솟았습니다. CPU 사용률이 100%라는 모니터링 알림이 왔고, 온콜 담당자가 서버에 접속했습니다. 어떤 프로세스가 CPU를 잡아먹는지, kill -9로 죽여도 되는지, 아니면 설정을 다시 읽히면 되는지 — 프로세스 상태를 읽을 줄 모르면 잘못 건드려 서비스가 완전히 다운될 수 있습니다. 프로세스를 제대로 보고 제어하는 것이 이 모듈의 시작점입니다.
프로세스 관리와 작업 제어
리눅스에서 실행 중인 모든 프로그램은 프로세스로 관리됩니다. 시스템 관리자는 프로세스 상태를 모니터링하고, 문제 있는 프로세스를 식별하여 적절히 제어해야 합니다. 프로세스 관리는 리눅스마스터 1급 시험의 운영 및 관리 영역에서 중요한 비중을 차지합니다.
프로세스 관리는 시스템 성능 분석과 장애 진단의 핵심입니다. 프로세스 상태, kill 시그널 번호, nice 범위, 좀비 프로세스 처리 방법이 자주 출제됩니다.
- 1프로세스 상태(R/S/D/Z/T)의 의미를 이해하고 ps 출력에서 진단할 수 있다
- 2ps aux와 ps -ef 출력 형식을 비교하고 주요 필드를 해석할 수 있다
- 3kill / killall / pkill로 적절한 시그널을 보내 프로세스를 종료할 수 있다
- 4nice / renice로 프로세스의 CPU 우선순위를 조정할 수 있다
- 5jobs / fg / bg / nohup으로 작업 제어를 수행할 수 있다
- 6/proc/[PID] 파일시스템에서 프로세스 정보를 직접 조회할 수 있다
top 명령어는 q로 종료합니다. htop이 설치되어 있다면 더 직관적인 인터페이스로 프로세스를 모니터링할 수 있습니다.
ps aux | head -5pstree -p | head -10top프로세스 상태(State)
 확대
확대
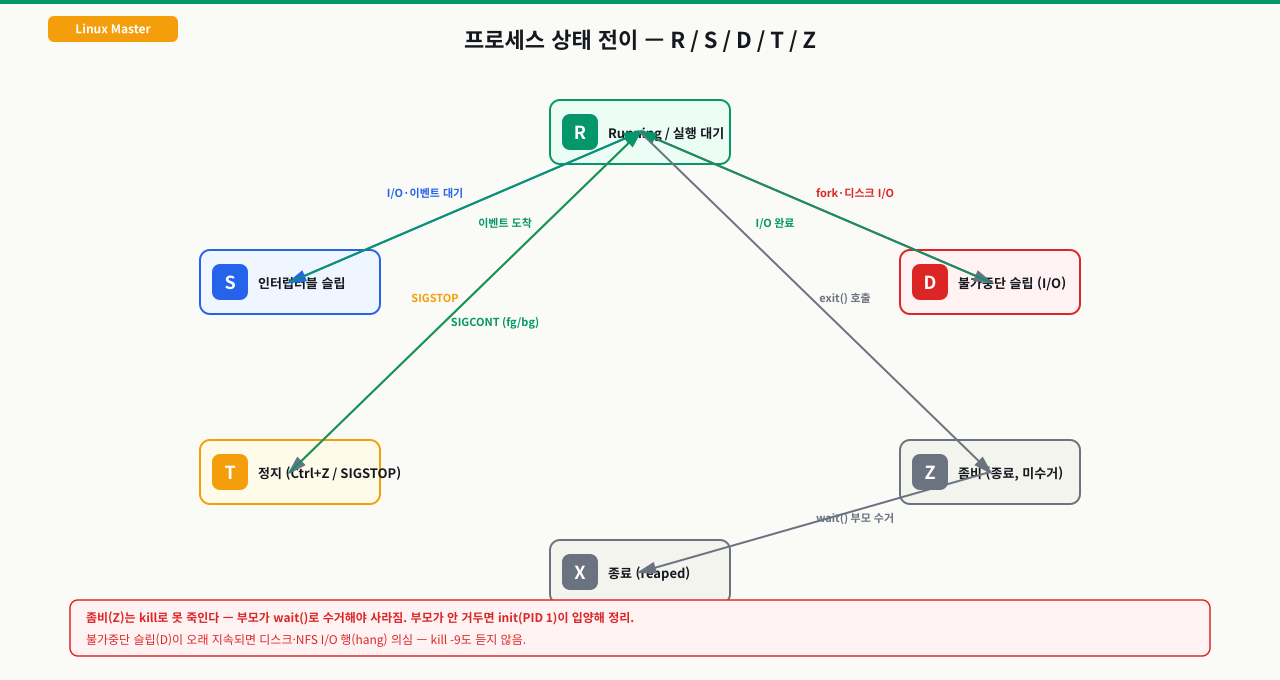
프로세스 상태 코드
프로세스 상태 전이도
생성(fork)
↓
R (Running/Runnable) ←→ S (Sleeping)
CPU 실행 중 또는 인터럽트 가능한
실행 대기 중 슬립 (I/O 대기 등)
↓ ↓
↓ D (Disk Sleep)
↓ 인터럽트 불가 슬립
↓ I/O 완료 대기
↓
T (Stopped) Z (Zombie)
SIGSTOP으로 중지 종료됐지만
SIGCONT로 재개 부모가 wait() 미호출
상태 코드 상세
| 코드 | 이름 | 설명 | 대응 방법 |
|---|---|---|---|
R | Running | CPU 실행 중 또는 실행 대기 | 정상 |
S | Sleeping | I/O 대기 등 인터럽트 가능 슬립 | 정상 |
D | Disk Sleep | I/O 완료 대기, kill -9 불가 | 디스크/NFS 점검 |
Z | Zombie | 종료됐지만 프로세스 테이블에 잔존 | 부모 프로세스 확인 |
T | Stopped | SIGSTOP으로 일시 중지 | SIGCONT로 재개 |
I | Idle | 유휴 커널 스레드 | 정상 |
추가 상태 플래그 (ps aux STAT 필드)
STAT 필드 예시: Ss+, Rl, Zs
S = Sleeping (기본 상태)
s = Session leader (세션 리더)
l = 멀티스레드 프로세스
+ = 포그라운드 프로세스 그룹
< = 우선순위 높음 (nice < 0)
N = 우선순위 낮음 (nice > 0)
ps 명령어 — 프로세스 상태 조회
ps aux (BSD 스타일)
ps aux
# USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
# root 1 0.0 0.1 171704 12844 ? Ss Mar27 0:02 /usr/lib/systemd/systemd
# root 956 0.0 0.0 41936 3200 ? Ss Mar27 0:00 /usr/sbin/sshd -D
# nginx 1234 0.1 0.5 124000 42000 ? S 09:00 0:01 nginx: worker process
# john 2345 0.0 0.1 23456 8000 pts/0 Ss 10:00 0:00 -bash
| 필드 | 의미 |
|---|---|
| USER | 프로세스 소유자 |
| PID | 프로세스 ID |
| %CPU | CPU 사용률 |
| %MEM | 메모리 사용률 |
| VSZ | 가상 메모리 크기 (KB) |
| RSS | 실제 물리 메모리 사용량 (KB) |
| TTY | 터미널 (?=데몬, pts/0=원격터미널) |
| STAT | 프로세스 상태 |
| TIME | 누적 CPU 사용 시간 |
| COMMAND | 실행 명령어 |
ps -ef (System V 스타일)
ps -ef
# UID PID PPID C STIME TTY TIME CMD
# root 1 0 0 Mar27 ? 00:00:02 /usr/lib/systemd/systemd
# root 956 1 0 Mar27 ? 00:00:00 /usr/sbin/sshd -D
# john 2345 2344 0 10:00 pts/0 00:00:00 -bash
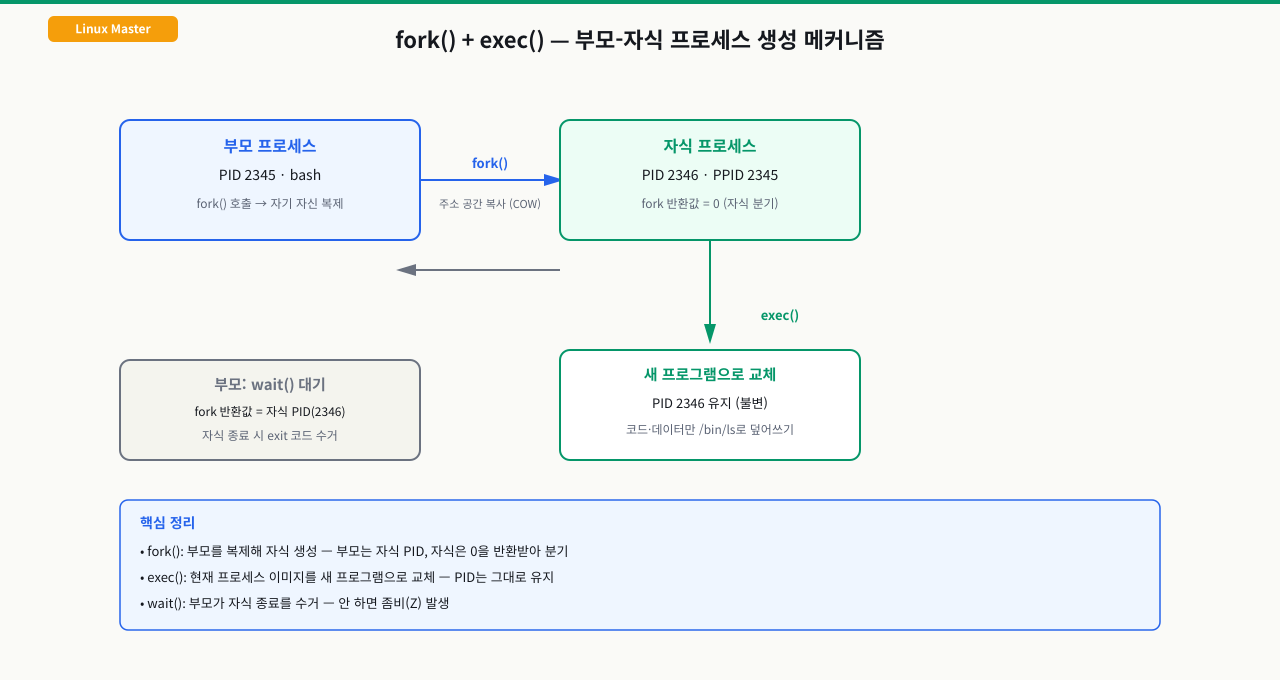
# PPID(Parent PID) 필드가 추가됨 — 부모-자식 관계 파악에 유용
모든 프로세스는 부모 프로세스가 fork()로 복제한 뒤 exec()로 새 프로그램을 덮어쓰며 생성됩니다. PPID는 이 부모-자식 관계를 추적하는 핵심 필드입니다.
 확대
확대
특정 프로세스 찾기
# 프로세스명으로 검색
ps aux | grep nginx
# 또는
pgrep -la nginx
# 1234 nginx: master process /usr/sbin/nginx
# 1235 nginx: worker process
# 프로세스 트리 보기
pstree -p 1234 # PID 1234의 트리
# CPU 사용량 순 정렬
ps aux --sort=-%cpu | head -10
# 메모리 사용량 순 정렬
ps aux --sort=-%mem | head -10
top 명령어 핵심 사용법
top
# top - 10:30:00 up 1 day, 2:30, 2 users, load average: 0.15, 0.20, 0.18
# Tasks: 156 total, 1 running, 155 sleeping, 0 stopped, 0 zombie
# %Cpu(s): 2.3 us, 0.5 sy, 0.0 ni, 97.0 id, 0.2 wa, 0.0 hi, 0.0 si
# MiB Mem : 7981.0 total, 3000.0 free, 2500.0 used, 2481.0 buff/cache
# MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 4800.0 avail Mem
# top 내부 단축키
# k: 프로세스 종료 (kill)
# r: renice (우선순위 변경)
# u: 특정 사용자 필터
# M: 메모리 사용률 순 정렬
# P: CPU 사용률 순 정렬
# 1: CPU 코어별 사용률
# q: 종료
시그널(Signal)과 프로세스 종료
주요 시그널
| 번호 | 이름 | 기본 동작 | 무시 가능 | 설명 |
|---|---|---|---|---|
| 1 | SIGHUP | 종료 | O | 터미널 끊김, 데몬 설정 재읽기 |
| 2 | SIGINT | 종료 | O | Ctrl+C (인터럽트) |
| 3 | SIGQUIT | 코어덤프+종료 | O | Ctrl+\ |
| 9 | SIGKILL | 강제 종료 | X | 무적 종료 (무시 불가) |
| 15 | SIGTERM | 종료 | O | 정상 종료 요청 (kill 기본값) |
| 17 | SIGCHLD | 무시 | O | 자식 프로세스 종료 알림 |
| 18 | SIGCONT | 재개 | O | 중지된 프로세스 재개 |
| 19 | SIGSTOP | 중지 | X | 프로세스 일시 중지 |
| 20 | SIGTSTP | 중지 | O | Ctrl+Z (터미널 중지) |
kill / killall / pkill
# PID로 시그널 전송 (기본: SIGTERM)
kill 1234
kill -15 1234 # SIGTERM (동일)
kill -TERM 1234 # SIGTERM (동일)
# 강제 종료
kill -9 1234
kill -KILL 1234
# 설정 파일 재읽기 (nginx, sshd 등)
kill -1 $(cat /var/run/nginx.pid)
kill -HUP 1234
# 프로세스명으로 시그널 전송
killall nginx # nginx 이름의 모든 프로세스에 SIGTERM
killall -9 nginx # 강제 종료
# 패턴으로 시그널 전송
pkill -f "python.*script.py" # 명령줄 패턴 매칭
pkill -u john # 특정 사용자의 모든 프로세스 종료
# 시그널 전송 없이 PID만 찾기
pgrep -l nginx
# 1234 nginx
우선순위 제어 — nice와 renice
CPU 스케줄링 우선순위
nice 값: -20 .......0....... 19
↑ ↑
최고 우선순위 최저 우선순위
(root만 가능) (일반 사용자 가능)
우선순위(PR) = 20 + nice 값
PR 범위: 0(최고) ~ 39(최저)
nice — 시작 시 우선순위 지정
# 기본 우선순위(0)로 실행
./backup.sh
# nice 10으로 시작 (낮은 우선순위)
nice -n 10 ./backup.sh
# root: 음수 nice로 높은 우선순위
sudo nice -n -15 ./critical_service
renice — 실행 중인 프로세스 우선순위 변경
# PID 1234의 nice 값을 10으로 변경
renice -n 10 -p 1234
# 1234 (process ID) old priority 0, new priority 10
# 특정 사용자의 모든 프로세스 변경
renice -n 5 -u john
# 그룹 단위 변경
renice -n 5 -g devteam
# top에서 r 키로 renice
# 또는
ps -el | awk '{print $8, $14}' # NI(nice값) 열 확인
작업 제어 (Job Control)
포그라운드와 백그라운드
# 포그라운드 실행 (기본)
./long_script.sh
# ← 터미널이 blocking 됨
# 백그라운드 실행 (&)
./long_script.sh &
# [1] 2345 ← 작업번호와 PID
# 실행 중인 작업 목록 확인
jobs
# [1]+ Running ./long_script.sh &
# [2]- Stopped vim config.txt
# 포그라운드 작업을 백그라운드로 전환
# 1. Ctrl+Z로 일시 중지 (SIGTSTP)
# 2. bg 명령으로 백그라운드 재개
./backup.sh
# [Ctrl+Z]
# [1]+ Stopped ./backup.sh
bg %1
# [1]+ ./backup.sh &
# 백그라운드 작업을 포그라운드로 전환
fg %1
# ./backup.sh ← 포그라운드로 전환됨
# 특정 작업 종료
kill %1
nohup — 터미널 종료 후에도 실행
# 기본 사용 (출력은 nohup.out으로)
nohup ./long_process.sh &
# [1] 3456
# nohup: ignoring input and appending output to 'nohup.out'
# 출력 파일 지정
nohup ./process.sh > /var/log/myprocess.log 2>&1 &
# 실행 확인
jobs
ps aux | grep long_process
# 로그아웃 후에도 살아있는지 확인
tail -f nohup.out
/proc/[PID] 구조
# PID 1234의 프로세스 정보
ls /proc/1234/
# cmdline cwd environ exe fd maps mem mounts net ...
# 실행 명령어 확인
cat /proc/1234/cmdline | tr '\0' ' '
# /usr/sbin/nginx -g daemon off;
# 실행 파일 경로
ls -la /proc/1234/exe
# /proc/1234/exe -> /usr/sbin/nginx
# 열린 파일 목록
ls -la /proc/1234/fd/
# 0 -> /dev/null (stdin)
# 1 -> /var/log/nginx/access.log (stdout)
# 2 -> /var/log/nginx/error.log (stderr)
# 메모리 맵
cat /proc/1234/maps | head -5
# 환경변수
cat /proc/1234/environ | tr '\0' '\n' | head -5
실제 프로세스를 생성하고 모니터링하며 제어하는 실습을 진행합니다.
mkdir -p /tmp/linux-master/part1/process && cd /tmp/linux-master/part1/process
# 프로세스 실습용 스크립트들
cat > cpu_worker.sh << 'EOF'
#!/bin/bash
# CPU 부하 생성 스크립트
PID_FILE="/tmp/linux-master/part1/process/cpu_worker.pid"
echo $$ > "$PID_FILE"
echo "CPU worker started (PID: $$)"
while true; do
for i in $(seq 1 10000); do echo $i > /dev/null; done
sleep 0.1
done
EOF
cat > mem_worker.sh << 'EOF'
#!/bin/bash
# 메모리 점진적 사용 스크립트
DATA=""
for i in $(seq 1 100); do
DATA="$DATA$(head -c 1024 /dev/urandom | base64)"
echo "Allocated: ${i}KB"
sleep 0.5
done
EOF
chmod +x *.sh
1단계: 테스트 프로세스 생성
# CPU를 많이 사용하는 테스트 프로세스 생성
# yes 명령: 계속 'y'를 출력하여 CPU 사용
yes > /dev/null &
yes > /dev/null &
echo "생성된 PID: $!"
# 두 번째 프로세스도 생성
sleep 1000 &
echo "sleep PID: $!"
2단계: ps 명령으로 확인
# 실행 중인 yes 프로세스 확인
ps aux | grep yes | grep -v grep
# user 2345 98.5 0.0 1234 512 pts/0 R 10:00 0:05 yes
# 프로세스 트리
pstree -p $$ | head -5
# bash(2344)---yes(2345)
# ---yes(2346)
# ---sleep(2347)
# top으로 실시간 확인 (q로 종료)
top -n 1 -b | head -20
3단계: 우선순위 변경
# yes 프로세스 PID 확인
YES_PID=$(pgrep -n yes)
echo $YES_PID
# 현재 nice 값 확인
ps -o pid,ni,comm -p $YES_PID
# PID NI COMMAND
# 2345 0 yes
# nice 값 변경 (낮은 우선순위로)
sudo renice -n 19 -p $YES_PID
# 2345 (process ID) old priority 0, new priority 19
# 변경 확인
ps -o pid,ni,comm -p $YES_PID
# PID NI COMMAND
# 2345 19 yes
4단계: 시그널 전송
# SIGSTOP으로 일시 중지
kill -STOP $YES_PID
ps aux | grep yes | grep -v grep
# user 2345 0.0 0.0 ... T ... yes ← T(Stopped) 상태
# SIGCONT로 재개
kill -CONT $YES_PID
ps aux | grep yes | grep -v grep
# user 2345 98.5 0.0 ... R ... yes ← R(Running) 상태
# SIGTERM으로 정상 종료
kill -15 $YES_PID
# 종료 확인
ps aux | grep yes | grep -v grep
# (출력 없음)
5단계: 작업 제어 실습
# 백그라운드에서 여러 작업 실행
sleep 200 &
sleep 300 &
sleep 400 &
# 작업 목록 확인
jobs
# [1] Running sleep 200 &
# [2]- Running sleep 300 &
# [3]+ Running sleep 400 &
# 작업 2를 포그라운드로
fg %2
# sleep 300
# [Ctrl+Z]로 중지
# [2]+ Stopped sleep 300
# 백그라운드로 재개
bg %2
# [2]+ sleep 300 &
# 모든 백그라운드 작업 종료
kill %1 %2 %3
좀비 프로세스의 발생 원인을 이해하고 처리하는 방법을 실습합니다.
1단계: 좀비 프로세스 생성 확인
# 좀비 프로세스 확인
ps aux | awk '$8 == "Z" {print}'
# user 5678 0.0 0.0 0 0 ? Z 10:30 0:00 [defunct]
# 좀비의 부모 프로세스 찾기
ps -o pid,ppid,stat,comm | grep Z
# 5678 5677 Z [process_name]
# 부모 프로세스 확인
ps -p 5677 -o pid,ppid,comm
# PID PPID COMMAND
# 5677 2344 bad_parent_app
2단계: 좀비 처리
# 방법 1: 부모 프로세스에게 SIGCHLD 전송 (wait() 호출 유도)
kill -SIGCHLD 5677
# 방법 2: 부모 프로세스 종료 (init이 입양하여 수거)
kill -15 5677 # 먼저 정상 종료 시도
kill -9 5677 # 안 되면 강제 종료
# 방법 3: 재부팅 (최후 수단)
# 좀비는 메모리를 차지하지 않으므로 소수는 무해
# 프로세스 테이블 슬롯만 차지함
- ps aux 출력에서 먼저 STAT 컬럼으로 D/Z 상태 프로세스를 찾고, 그 다음 %CPU 컬럼에서 90% 이상 프로세스를 확인 — D 상태는 kill -9도 통하지 않으므로 I/O 원인 파악이 우선
- 프로세스 위험 기준: nice 값이 -10 이하(음수)이면 root가 높은 우선순위 부여 중, Z 상태가 10개 이상이면 부모 프로세스 버그 의심, D 상태가 30초 이상 지속되면 디스크/NFS 장애 확인
- CPU가 98% 이상인데 load average도 높으면 → 실제 연산 과부하(renice로 우선순위 조정), CPU는 낮은데 D 상태 프로세스가 많고 load average만 높으면 → I/O 대기(iostat -x로 디스크 확인)를 의미
증상
# 특정 프로세스가 D 상태로 장시간 지속
ps aux
# root 1234 0.0 0.0 0 0 ? D 09:00 0:30 [kworker/u8:2]
# app 5678 0.0 0.2 ... ? D 09:00 0:15 python app.py
# kill -9 5678 → 효과 없음!
원인 분석
# D 상태 프로세스의 I/O 대기 원인 파악
# 방법 1: 열린 파일 확인
lsof -p 5678
# 방법 2: strace로 시스템 콜 추적 (실행 가능한 경우)
strace -p 5678
# 방법 3: NFS 마운트 확인 (NFS 서버 문제 시 D 상태 빈발)
mount | grep nfs
df -h # 응답하는지 확인
주요 원인과 해결
# 원인 1: NFS 서버 장애
# NFS 마운트 해제 (강제)
umount -f -l /mnt/nfs_share
# 원인 2: 디스크 I/O 포화
# I/O 대기 상태 확인
iostat -x 1 5
# %util이 100%에 가까우면 디스크 포화
# 원인 3: 디스크 오류
dmesg | grep -i error | tail -20
# [12345.678] ata1.00: error: { UNC } ← 디스크 오류
# 해결: 디스크 교체 또는 시스템 재부팅
증상
top
# %Cpu(s): 99.8 us, 0.1 sy, 0.0 ni, 0.0 id
# PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
# 9999 www-data 20 0 500m 200m 10m R 99.5 2.5 30:00.00 php-fpm
진단
# 1. 어떤 함수에서 CPU 소비하는지 확인
sudo strace -p 9999 -c 2>/dev/null &
sleep 5
kill %1
# 2. 프로세스의 CPU 사용 이력
cat /proc/9999/stat
# 3. 스레드별 CPU 사용 확인
ps -L -p 9999 -o pid,tid,pcpu,comm
# 4. 열린 파일 수 확인 (무한루프로 파일 생성 중일 수도)
ls /proc/9999/fd | wc -l
해결
# 임시: nice 값 올려 다른 프로세스 보호
sudo renice -n 19 -p 9999
# 근본: 프로세스 재시작
kill -15 9999 # 정상 종료 시도
kill -9 9999 # 안 되면 강제 종료
# 재발 방지: ulimit으로 CPU 시간 제한
ulimit -t 3600 # 최대 3600초(1시간) CPU 시간
프로세스 모니터링 스크립트
실무에서는 주요 서비스 프로세스가 죽었을 때 자동으로 감지하고 재시작하는 모니터링이 필요합니다.
#!/bin/bash
# 프로세스 생존 모니터링 (cron으로 실행)
SERVICE="nginx"
if ! pgrep -x "$SERVICE" > /dev/null; then
echo "$(date): $SERVICE 프로세스 없음, 재시작" >> /var/log/monitor.log
systemctl start $SERVICE
fi
top 배치 모드로 스냅샷 수집
# CPU/메모리 상위 10개 프로세스 기록
top -bn1 | head -20 >> /var/log/top_snapshot.log
# 매 5분마다 cron으로 수집
# */5 * * * * /usr/bin/top -bn1 >> /var/log/perf/top_$(date +\%H\%M).log
/proc를 활용한 메모리 누수 탐지
# 특정 프로세스의 메모리 사용량 추적
while true; do
PID=$(pgrep myapp)
if [ -n "$PID" ]; then
RSS=$(cat /proc/$PID/status | grep VmRSS | awk '{print $2}')
echo "$(date +%H:%M:%S) RSS: ${RSS}kB" >> /tmp/mem_trace.log
fi
sleep 60
done &
systemd를 통한 프로세스 자동 재시작
현대 리눅스 환경에서는 직접 모니터링 스크립트보다 systemd의 Restart=on-failure 정책을 활용합니다.
# /etc/systemd/system/myapp.service
[Service]
ExecStart=/usr/bin/myapp
Restart=on-failure
RestartSec=5
StartLimitInterval=60
StartLimitBurst=3
다음 모듈에서는 디스크 관리와 LVM — 파티션 구성부터 논리 볼륨 확장까지 스토리지를 유연하게 다루는 방법을 다룹니다.