새벽 3시에 서비스 알람이 울립니다. 담당자가 일어나서 systemctl restart app을 치고 다시 잡니다. 한 달 뒤 같은 일이 반복됩니다. 자동 재시작 스크립트를 짜놨더니 이번엔 서비스가 계속 죽으면서 재시작을 무한 반복하고, 디스크가 로그로 가득 차버렸습니다. Prometheus 같은 모니터링 도구를 쓰기엔 환경 제약이 있을 때, 올바르게 설계된 헬스체크 스크립트가 새벽 호출을 막아주는 유일한 방어선이 됩니다.
헬스체크 & 자가복구 스크립트
Prometheus, Grafana, Datadog — 훌륭한 도구들이지만 모든 환경에서 쓸 수 있는 건 아닙니다. 사내 레거시 서버, 고객사 온프레미스 환경, 인터넷이 격리된 망분리 시스템에서는 경량 셸 스크립트가 유일한 모니터링 수단이 되기도 합니다. 이 챕터에서는 외부 의존성 없이 Bash만으로 서비스 상태를 감시하고, 이상이 감지되면 자동으로 복구하는 패턴을 배웁니다.
- 1헬스체크 설계 원칙에 따라 감지(Detection)와 복구(Recovery)를 분리할 수 있다
- 2종료 코드($?)와 curl/nc로 프로세스·포트·HTTP 상태를 확인할 수 있다
- 3디스크·메모리 임계값을 모니터링하는 경고 스크립트를 작성할 수 있다
- 4systemctl OnFailure와 cron으로 자동 재시작 패턴을 구현할 수 있다
- 5멱등성 원칙을 적용하고 재시작 루프를 방지할 수 있다
chmod +x /usr/local/bin/health-check.shsystemctl is-active cron || systemctl is-active crondsudo apt install nginx 또는 sudo yum install nginx — 서비스 감지 실습에 사용
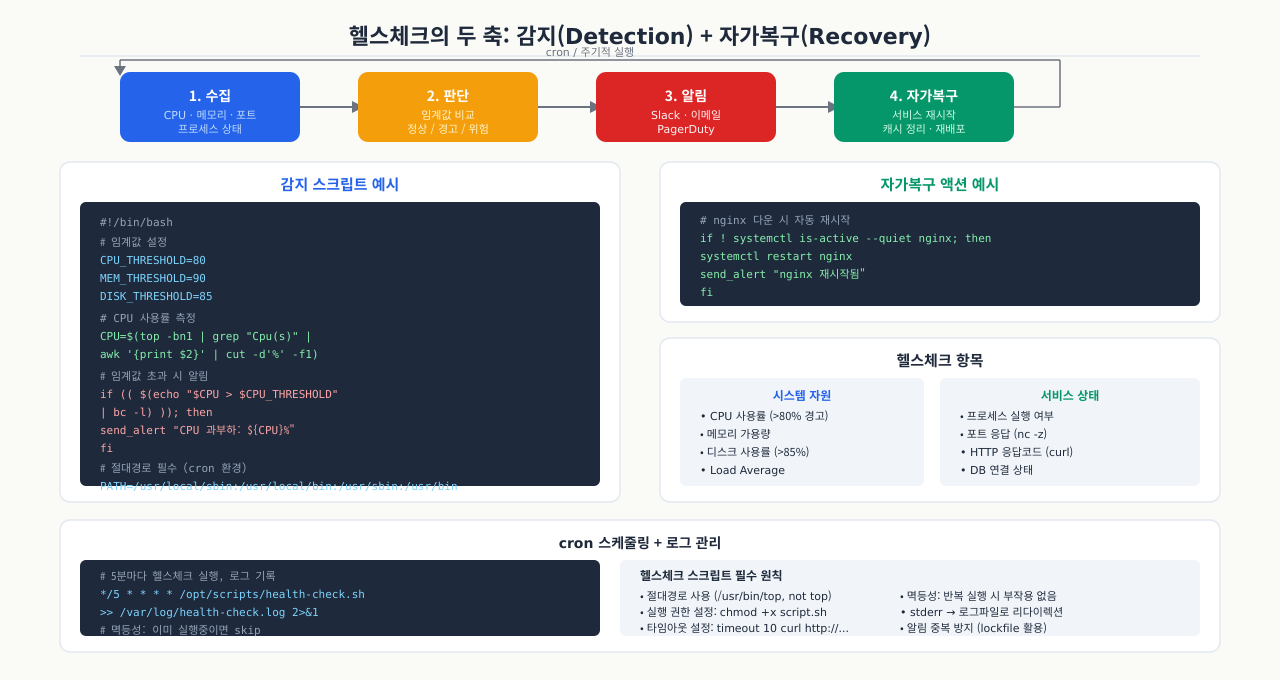
헬스체크의 두 가지 축: 감지와 복구
 확대
확대
새벽 3시에 서비스 알람이 울렸는데 담당자가 일어나서 systemctl restart app을 치고 자리로 돌아가는 상황을 반복하고 있다면, 자동화로 해결할 수 있습니다. 그런데 자동 재시작 스크립트를 짜놨더니 이번엔 서비스가 계속 죽고 재시작을 무한 반복하면서 디스크가 로그로 가득 찼습니다. 헬스체크 스크립트는 "감지"와 "복구"를 분리해서 설계해야 합니다. 감지는 현재 상태가 정상인지 아닌지를 판단하는 것이고, 복구는 그 판단 결과에 따라 어떤 행동을 취할지 결정하는 것입니다. 이 두 가지가 섞이면 디버깅이 어렵고, 복구 정책을 바꾸기도 어렵습니다.
헬스체크 스크립트를 설계할 때는 항상 두 가지 역할을 분리해서 생각해야 합니다.
감지(Detection) — 지금 무언가 잘못되었는가?
- 프로세스가 실행 중인가? (
systemctl is-active,pgrep) - 포트가 열려 있는가? (
nc -zv,/dev/tcp) - HTTP 응답이 정상인가? (
curl상태코드) - 디스크/메모리가 임계값 이하인가? (
df,free)
복구(Recovery) — 문제가 확인됐을 때 어떻게 되돌리는가?
- 서비스 재시작 (
systemctl restart) - 알림 발송 후 사람이 개입하도록 대기
- 임시 파일 정리 후 재시작
- 재시작 횟수 제한으로 루프 방지
이 둘을 하나의 스크립트에 뒤섞으면 나중에 디버깅이 매우 어려워집니다. 감지 로직은 항상 멱등(idempotent)하게, 즉 몇 번을 실행해도 동일한 결과를 반환하도록 작성해야 하고, 복구 액션은 부작용(side-effect)이 있으므로 조건을 엄격하게 걸어야 합니다.
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/linux/part6/exam_31 && cd /tmp/linux/part6/exam_31
# 헬스체크 대상 서비스 목록
cat > services.txt << 'EOF'
nginx Web Server :80
sshd SSH Server :22
EOF
# 기본 헬스체크 템플릿
cat > health_check.sh << 'EOF'
#!/bin/bash
FAILED=0
check_service() {
local name="$1"
if systemctl is-active --quiet "$name" 2>/dev/null; then
echo "✓ $name: running"
else
echo "✗ $name: STOPPED"
FAILED=$((FAILED+1))
fi
}
check_port() {
local name="$1" port="$2"
if ss -tlnp 2>/dev/null | grep -q ":${port} "; then
echo "✓ $name (port $port): listening"
else
echo "✗ $name (port $port): NOT listening"
FAILED=$((FAILED+1))
fi
}
echo "=== Health Check $(date) ==="
check_port "SSH" 22
check_service "cron"
echo "Failures: $FAILED"
exit $FAILED
EOF
chmod +x health_check.sh
이제 실습을 진행합니다.
$? — 종료 코드의 의미
Bash에서 모든 명령어는 종료 코드(exit code)를 반환합니다. 0은 성공, 그 외는 실패입니다.
systemctl is-active nginx
echo $? # 0 이면 active, 그 외면 inactive/failed
systemctl is-active는 특히 유용합니다. --quiet 플래그를 붙이면 출력 없이 종료 코드만 반환하므로 스크립트에서 바로 조건문에 사용할 수 있습니다.
if ! systemctl is-active --quiet nginx; then
echo "nginx가 죽었습니다"
fi
상태코드 참조표
| 종료코드 | 의미 |
|---|---|
| 0 | 성공 / 서비스 active |
| 1 | 일반 오류 |
| 2 | 잘못된 사용법(인자 오류) |
| 3 | systemctl: unit not active |
| 124 | timeout 명령어에 의한 강제 종료 |
| 126 | 실행 권한 없음 |
| 127 | 명령어를 찾을 수 없음 |
헬스체크 스크립트가 정상·경고·위험을 판정하는 법 — 점검부터 조치까지 5단계
*/5 * * * * health-check.sh 한 줄로 등록해 두면, 5분마다 스크립트가 깨어나 "지금 이 서비스는 살았나 죽었나"를 판정하고 조용히 잠듭니다. 그런데 이 판정이 어떻게 이뤄지길래, 어떤 스크립트는 새벽 호출을 막아 주고 어떤 스크립트는 멀쩡한 서버를 재시작 폭풍에 빠뜨릴까요? 헬스체크는 점검(수집) → 조건 평가 → 상태 판정 → 종료코드 반환 → 호출자 조치라는 컨베이어를 탑니다. 이 흐름을 알면 오탐(정상인데 실패로 봄)과 사고(실패인데 정상으로 봄)가 어느 단계에서 생기는지 짚을 수 있습니다.
[cron · 5분마다] health-check.sh 실행
│
① 대상 점검(수집) systemctl is-active · ss :포트 · curl -w %{http_code} · df·free
│ → 프로세스·포트·응답·자원을 '지금' 실제로 잰다
│
② 조건 평가 잰 값을 임계와 비교 (응답이 200? 사용률 ≥ 90%? 타임아웃 넘었나?)
│
③ 상태 판정 OK(정상) · WARN(경고선) · CRIT(위험) 중 하나로 등급 매김
│
④ 종료코드 반환 exit 0(OK) · 1(WARN·실패) · 2(CRIT) → 판정을 숫자로 넘김
│
⑤ 호출자 조치 cron·모니터링이 $? 를 읽어 알림·자동 재시작·에스컬레이션
▼
[조용히 통과] 또는 [운영자 알림] 또는 [systemctl restart]
각 단계가 하는 일과, 여기서 어긋나면 무엇이 잘못되나:
| 단계 | 하는 일 | 여기서 어긋나면 |
|---|---|---|
| ① 대상 점검 | 프로세스(systemctl is-active)·포트(ss)·HTTP 응답(curl)·자원(df·free)을 실제로 측정 | 얕게만 보면 오판 — 프로세스는 떠 있는데 응답 못 하는 '좀비'를 정상으로 봄. 포트 열림 ≠ 정상 응답 |
| ② 조건 평가 | 잰 값을 임계와 비교. --max-time 타임아웃, 사용률 임계(80·90) 등 | 타임아웃이 너무 짧으면 정상인데 '느림'을 실패로 오탐. 임계가 지나치게 빡세면 알림 폭주 |
| ③ 상태 판정 | 비교 결과를 OK · WARN · CRIT 등급으로 환산 | 한 번 실패에 바로 CRIT면 일시적 깜빡임에 과잉 반응 → 연속 N회 실패를 임계로 삼아 완화 |
| ④ 종료코드 반환 | 등급을 종료코드로 변환해 반환(exit 0·1·2) | 규약을 어겨 실패인데 exit 0이면 호출자가 정상으로 인식 → 장애를 통째로 놓침 |
| ⑤ 호출자 조치 | cron·모니터링이 $?를 읽어 알림·재시작·라우팅 제외 실행 | 재시작을 의존성까지 보는 깊은 체크에 걸면 DB 지연에 전 인스턴스가 동시 재시작(폭풍). 재시작은 얕은 liveness에만 |
즉 헬스체크는 '수집 → 비교 → 등급 → 종료코드 → 조치'로 이어지는 컨베이어이고, 각 단계가 분리돼 있어 감지(①~④)와 복구(⑤)를 따로 설계할 수 있습니다. 오탐의 대부분은 ①의 얕은 점검과 ②의 짧은 타임아웃에서 나오고, 진짜 사고는 ④의 종료코드 규약 위반(실패인데 0 반환)이나 ⑤의 재시작 대상 오선택에서 나옵니다. 그래서 스크립트가 터미널에선 되는데 cron에서만 이상하면 $? 종료코드와 PATH부터 확인하는 것이 진단의 출발점입니다.
1. 단일 서비스 헬스체크 기초
가장 단순한 형태부터 시작합니다. nginx 하나를 감시하고, 죽어 있으면 재시작하는 스크립트입니다.
먼저 스크립트 파일을 만들고 실행 권한을 부여합니다.
sudo mkdir -p /opt/healthcheck
sudo tee /opt/healthcheck/check_nginx.sh > /dev/null << 'EOF'
#!/usr/bin/env bash
# check_nginx.sh — nginx 상태 감시 및 자동 재시작
# 작성일: 2026-03-26
# 실행 환경: Ubuntu 22.04 / RHEL 9
set -euo pipefail
SERVICE="nginx"
LOG_FILE="/var/log/healthcheck/nginx.log"
MAX_RESTART=3
RESTART_COUNT_FILE="/tmp/nginx_restart_count"
# 로그 디렉터리 생성
mkdir -p "$(dirname "$LOG_FILE")"
# 타임스탬프 함수
timestamp() {
date '+%Y-%m-%d %H:%M:%S'
}
# 로그 함수
log() {
local level="$1"
shift
echo "[$(timestamp)] [$level] $*" | tee -a "$LOG_FILE"
}
# 재시작 카운터 읽기
get_restart_count() {
if [[ -f "$RESTART_COUNT_FILE" ]]; then
cat "$RESTART_COUNT_FILE"
else
echo "0"
fi
}
# 재시작 카운터 증가
increment_restart_count() {
local count
count=$(get_restart_count)
echo $((count + 1)) > "$RESTART_COUNT_FILE"
}
# 재시작 카운터 초기화
reset_restart_count() {
echo "0" > "$RESTART_COUNT_FILE"
}
# 메인 헬스체크
main() {
log "INFO" "=== 헬스체크 시작: $SERVICE ==="
if systemctl is-active --quiet "$SERVICE"; then
log "INFO" "$SERVICE 정상 동작 중"
reset_restart_count
exit 0
fi
# 서비스가 비활성 상태
log "WARN" "$SERVICE 비활성 감지"
local count
count=$(get_restart_count)
if [[ "$count" -ge "$MAX_RESTART" ]]; then
log "ERROR" "재시작 횟수($count)가 최대값($MAX_RESTART)을 초과했습니다. 수동 개입이 필요합니다."
exit 1
fi
log "INFO" "재시작 시도 중... (시도 횟수: $((count + 1))/$MAX_RESTART)"
increment_restart_count
if systemctl restart "$SERVICE"; then
log "INFO" "$SERVICE 재시작 성공"
else
log "ERROR" "$SERVICE 재시작 실패"
exit 1
fi
}
main "$@"
EOF
sudo chmod +x /opt/healthcheck/check_nginx.sh
스크립트를 실행해 봅니다.
sudo /opt/healthcheck/check_nginx.sh
nginx를 강제로 중지한 뒤 다시 실행해 자동 재시작이 되는지 확인합니다.
sudo systemctl stop nginx
sudo /opt/healthcheck/check_nginx.sh
systemctl is-active nginx # active 가 출력되어야 합니다
- 먼저 스크립트 exit code($?)를 확인하고(0=정상, 1=경고, 2=위험), 그 다음 /var/log/healthcheck/nginx.log 의 [INFO]/[WARN]/[ERROR] 레벨별 메시지를 읽는다
- CPU 80% 이상이면 [WARN], 90% 이상이면 [ERROR] 로 기록되어야 정상 — 디스크는 95% 이상에서 즉각 exit 2 로 종료
- 재시작 카운터(/tmp/nginx_restart_count)가 MAX_RESTART(보통 3) 이상이고 서비스가 여전히 inactive 이면 → exit 1로 자동 재시작을 포기하고 수동 개입 요청 상태
- 스크립트 exit 0이고 systemctl is-active nginx 가 active 이면 → 정상 상태, cron에 등록해 1분마다 실행해도 안전
2. 다중 서비스 배열 반복 처리
실제 운영 환경에서는 수십 개의 서비스를 동시에 감시해야 합니다. 서비스마다 스크립트를 따로 만드는 것은 유지보수 악몽입니다. 배열(array)과 반복문을 활용해 하나의 스크립트로 여러 서비스를 처리합니다.
sudo tee /opt/healthcheck/check_services.sh > /dev/null << 'EOF'
#!/usr/bin/env bash
# check_services.sh — 다중 서비스 일괄 헬스체크
# 사용법: ./check_services.sh [--dry-run]
set -uo pipefail
# --
# 설정 섹션 — 환경에 맞게 수정하세요
# --
SERVICES=(
"nginx"
"postgresql"
"redis"
"docker"
)
LOG_FILE="/var/log/healthcheck/services.log"
DRY_RUN=false
FAILED_SERVICES=()
# --
# 유틸리티 함수
# --
timestamp() { date '+%Y-%m-%d %H:%M:%S'; }
log() {
local level="$1"; shift
local msg="[$(timestamp)] [$level] $*"
echo "$msg" | tee -a "$LOG_FILE"
}
# 인자 파싱
parse_args() {
for arg in "$@"; do
case "$arg" in
--dry-run) DRY_RUN=true ;;
*) log "WARN" "알 수 없는 인자: $arg" ;;
esac
done
}
# 단일 서비스 체크 및 복구
check_and_recover() {
local service="$1"
# 서비스 존재 여부 확인
if ! systemctl list-units --type=service --all | grep -q "${service}.service"; then
log "SKIP" "$service: 시스템에 등록되지 않은 서비스 (건너뜀)"
return 0
fi
if systemctl is-active --quiet "$service"; then
log "OK" "$service: 정상"
return 0
fi
log "FAIL" "$service: 비활성 상태 감지"
FAILED_SERVICES+=("$service")
if [[ "$DRY_RUN" == "true" ]]; then
log "INFO" "[DRY-RUN] $service 재시작을 시뮬레이션합니다 (실제 실행 안 함)"
return 0
fi
log "INFO" "$service 재시작 시도..."
if systemctl restart "$service" 2>>"$LOG_FILE"; then
log "INFO" "$service 재시작 성공"
else
log "ERROR" "$service 재시작 실패 — 수동 점검 필요"
return 1
fi
}
# 요약 리포트 출력
print_summary() {
log "INFO" "--"
log "INFO" "헬스체크 완료: 총 ${#SERVICES[@]}개 서비스 점검"
if [[ ${#FAILED_SERVICES[@]} -eq 0 ]]; then
log "INFO" "모든 서비스 정상"
else
log "WARN" "이상 감지 서비스: ${FAILED_SERVICES[*]}"
fi
log "INFO" "--"
}
# --
# 메인
# --
main() {
parse_args "$@"
mkdir -p "$(dirname "$LOG_FILE")"
[[ "$DRY_RUN" == "true" ]] && log "INFO" "=== DRY-RUN 모드 ==="
log "INFO" "=== 다중 서비스 헬스체크 시작 ==="
for service in "${SERVICES[@]}"; do
check_and_recover "$service" || true
done
print_summary
}
main "$@"
EOF
sudo chmod +x /opt/healthcheck/check_services.sh
# 정상 실행 테스트
sudo /opt/healthcheck/check_services.sh --dry-run
배열에 서비스를 추가할 때는 SERVICES 섹션만 수정하면 됩니다. --dry-run 플래그로 실제 재시작 없이 어떤 서비스가 문제인지 먼저 파악할 수 있습니다.
3. 리소스 임계값 모니터링
서비스 프로세스가 살아있어도 디스크가 꽉 차거나 메모리가 부족하면 시스템이 정상적으로 동작하지 않습니다. df와 free 출력을 awk로 파싱해 임계값을 체크합니다.
sudo tee /opt/healthcheck/check_resources.sh > /dev/null << 'EOF'
#!/usr/bin/env bash
# check_resources.sh — 디스크 및 메모리 임계값 모니터링
set -uo pipefail
# --
# 임계값 설정 (퍼센트)
# --
DISK_WARN_THRESHOLD=75
DISK_CRIT_THRESHOLD=90
MEM_WARN_THRESHOLD=80
MEM_CRIT_THRESHOLD=95
LOG_FILE="/var/log/healthcheck/resources.log"
ALERT_FLAG=false
timestamp() { date '+%Y-%m-%d %H:%M:%S'; }
log() {
local level="$1"; shift
echo "[$(timestamp)] [$level] $*" | tee -a "$LOG_FILE"
}
# --
# 디스크 사용률 체크
# df 출력 예시:
# Filesystem 1K-blocks Used Available Use% Mounted on
# /dev/sda1 41151808 8033792 31013264 21% /
# --
check_disk() {
log "INFO" "--- 디스크 사용률 점검 ---"
# -x tmpfs: tmpfs(가상 파일시스템) 제외
# NR>1: 헤더 행 건너뜀
# $5: "Use%" 컬럼에서 숫자만 추출
while IFS= read -r line; do
local usage
local mountpoint
usage=$(echo "$line" | awk '{gsub(/%/, "", $5); print $5}')
mountpoint=$(echo "$line" | awk '{print $6}')
if [[ -z "$usage" || -z "$mountpoint" ]]; then
continue
fi
if [[ "$usage" -ge "$DISK_CRIT_THRESHOLD" ]]; then
log "CRIT" "디스크 임계값 초과: $mountpoint 사용률 ${usage}% (임계값: ${DISK_CRIT_THRESHOLD}%)"
ALERT_FLAG=true
elif [[ "$usage" -ge "$DISK_WARN_THRESHOLD" ]]; then
log "WARN" "디스크 경고: $mountpoint 사용률 ${usage}% (경고값: ${DISK_WARN_THRESHOLD}%)"
ALERT_FLAG=true
else
log "OK" "디스크 정상: $mountpoint 사용률 ${usage}%"
fi
done < <(df -h -x tmpfs -x devtmpfs | tail -n +2)
}
# --
# 메모리 사용률 체크
# free -m 출력 예시:
# total used free shared buff/cache available
# Mem: 7822 3241 512 108 4068 4246
# --
check_memory() {
log "INFO" "--- 메모리 사용률 점검 ---"
# total과 used를 읽어 퍼센트 계산
# buff/cache는 실질적으로 사용 가능한 메모리이므로 available 기준으로 판단
local mem_info
mem_info=$(free -m | awk '/^Mem:/ {
total=$2; available=$7;
used=total-available;
pct=int(used*100/total);
print total, used, available, pct
}')
local total used available pct
read -r total used available pct <<< "$mem_info"
log "INFO" "메모리 총계: ${total}MB | 사용: ${used}MB | 가용: ${available}MB | 사용률: ${pct}%"
if [[ "$pct" -ge "$MEM_CRIT_THRESHOLD" ]]; then
log "CRIT" "메모리 임계값 초과: ${pct}% (임계값: ${MEM_CRIT_THRESHOLD}%)"
ALERT_FLAG=true
elif [[ "$pct" -ge "$MEM_WARN_THRESHOLD" ]]; then
log "WARN" "메모리 경고: ${pct}% (경고값: ${MEM_WARN_THRESHOLD}%)"
ALERT_FLAG=true
else
log "OK" "메모리 정상: ${pct}%"
fi
}
main() {
mkdir -p "$(dirname "$LOG_FILE")"
log "INFO" "=== 리소스 헬스체크 시작 ==="
check_disk
check_memory
log "INFO" "=== 리소스 헬스체크 완료 ==="
# ALERT_FLAG가 true면 종료코드 1 반환 (cron에서 메일 알림 활용 가능)
if [[ "$ALERT_FLAG" == "true" ]]; then
exit 1
fi
}
main "$@"
EOF
sudo chmod +x /opt/healthcheck/check_resources.sh
sudo /opt/healthcheck/check_resources.sh
awk의 gsub(/%/, "", $5)는 "Use%" 컬럼에서 % 기호를 제거해 숫자 비교가 가능하게 합니다. df에 -x tmpfs -x devtmpfs 옵션을 주면 항상 100%로 표시되는 가상 파일시스템을 걸러낼 수 있습니다.
4. HTTP & 포트 헬스체크
프로세스가 살아있다고 해서 서비스가 실제로 요청을 처리하는 것은 아닙니다. nginx가 실행 중이지만 502를 반환하고 있을 수도 있습니다. curl로 HTTP 상태코드를, nc로 포트 개방 여부를 직접 확인하는 방법을 살펴봅니다.
sudo tee /opt/healthcheck/check_endpoints.sh > /dev/null << 'EOF'
#!/usr/bin/env bash
# check_endpoints.sh — HTTP 엔드포인트 및 TCP 포트 헬스체크
set -uo pipefail
LOG_FILE="/var/log/healthcheck/endpoints.log"
CURL_TIMEOUT=5 # 연결 타임아웃 (초)
CURL_MAX_TIME=10 # 전체 요청 최대 시간 (초)
# --
# HTTP 엔드포인트 목록
# 형식: "URL 예상_상태코드"
# --
HTTP_ENDPOINTS=(
"http://localhost:80/health 200"
"http://localhost:8080/api/health 200"
"http://localhost:3000/ 200"
)
# --
# TCP 포트 목록
# 형식: "호스트 포트 서비스명"
# --
TCP_PORTS=(
"localhost 5432 postgresql"
"localhost 6379 redis"
"localhost 27017 mongodb"
)
timestamp() { date '+%Y-%m-%d %H:%M:%S'; }
log() { local l="$1"; shift; echo "[$(timestamp)] [$l] $*" | tee -a "$LOG_FILE"; }
# --
# HTTP 헬스체크
# curl 옵션 설명:
# -s : 진행 표시 숨김 (silent)
# -o /dev/null: 응답 본문 버림
# -w "%{http_code}": HTTP 상태코드만 출력
# --connect-timeout: TCP 연결 타임아웃
# --max-time : 전체 요청 타임아웃
# --
check_http() {
log "INFO" "--- HTTP 엔드포인트 점검 ---"
for entry in "${HTTP_ENDPOINTS[@]}"; do
local url expected_code
url=$(echo "$entry" | awk '{print $1}')
expected_code=$(echo "$entry" | awk '{print $2}')
local actual_code
# timeout 명령어로 curl 자체도 감싸서 확실한 타임아웃 보장
actual_code=$(timeout "$CURL_MAX_TIME" curl \
-s \
-o /dev/null \
-w "%{http_code}" \
--connect-timeout "$CURL_TIMEOUT" \
--max-time "$CURL_MAX_TIME" \
"$url" 2>/dev/null) || actual_code="000"
if [[ "$actual_code" == "$expected_code" ]]; then
log "OK" "HTTP $url → $actual_code (예상: $expected_code)"
elif [[ "$actual_code" == "000" ]]; then
log "FAIL" "HTTP $url → 연결 실패 또는 타임아웃"
else
log "FAIL" "HTTP $url → $actual_code (예상: $expected_code)"
fi
done
}
# --
# TCP 포트 헬스체크
# nc (netcat) 옵션:
# -z : 포트 스캔만 수행 (데이터 전송 안 함)
# -v : 상세 출력 (stderr로 나옴)
# -w : 타임아웃 (초)
# 대안: bash /dev/tcp 활용 (nc 없는 환경)
# --
check_ports() {
log "INFO" "--- TCP 포트 점검 ---"
for entry in "${TCP_PORTS[@]}"; do
local host port service_name
host=$(echo "$entry" | awk '{print $1}')
port=$(echo "$entry" | awk '{print $2}')
service_name=$(echo "$entry" | awk '{print $3}')
# nc가 있는지 먼저 확인, 없으면 /dev/tcp 사용
if command -v nc &>/dev/null; then
if nc -z -w 3 "$host" "$port" 2>/dev/null; then
log "OK" "PORT $service_name ($host:$port) → 열려 있음"
else
log "FAIL" "PORT $service_name ($host:$port) → 닫혀 있거나 연결 거부"
fi
else
# nc가 없을 때 bash 내장 /dev/tcp 활용
if timeout 3 bash -c "echo >/dev/tcp/$host/$port" 2>/dev/null; then
log "OK" "PORT $service_name ($host:$port) → 열려 있음 (bash /dev/tcp)"
else
log "FAIL" "PORT $service_name ($host:$port) → 닫혀 있거나 연결 거부 (bash /dev/tcp)"
fi
fi
done
}
main() {
mkdir -p "$(dirname "$LOG_FILE")"
log "INFO" "=== 엔드포인트 헬스체크 시작 ==="
check_http
check_ports
log "INFO" "=== 엔드포인트 헬스체크 완료 ==="
}
main "$@"
EOF
sudo chmod +x /opt/healthcheck/check_endpoints.sh
sudo /opt/healthcheck/check_endpoints.sh
curl의 -w "%{http_code}" 옵션은 응답 본문 대신 HTTP 상태코드 숫자만 stdout으로 출력합니다. 이 값을 변수에 담아 비교하는 패턴은 웹 서비스 헬스체크의 핵심입니다. 연결 자체가 실패하면 000이 반환됩니다.
5. Slack Webhook 알림 연동
이상을 감지했을 때 단순히 로그 파일에 기록하는 것으로는 부족합니다. 운영자에게 즉각 알림을 보내야 합니다. Slack의 Incoming Webhook은 별도의 SDK 없이 curl 한 줄로 메시지를 전송할 수 있어 셸 스크립트와 궁합이 좋습니다.
sudo tee /opt/healthcheck/notify.sh > /dev/null << 'EOF'
#!/usr/bin/env bash
# notify.sh — Slack Webhook 알림 모듈
# 다른 스크립트에서 source ./notify.sh 로 불러와 사용합니다
# --
# 환경변수로 Webhook URL 설정
# export SLACK_WEBHOOK_URL="https://hooks.slack.com/services/T.../B.../..."
# 스크립트에 하드코딩하지 마세요!
# --
SLACK_TIMEOUT=10
HOSTNAME_SHORT=$(hostname -s)
# --
# Slack 메시지 전송 함수
# 인자:
# $1 — 레벨 (OK / WARN / CRIT / INFO)
# $2 — 서비스명 또는 체크 대상
# $3 — 메시지 내용
# --
slack_notify() {
local level="$1"
local target="$2"
local message="$3"
# Webhook URL이 설정되지 않으면 조용히 종료
if [[ -z "${SLACK_WEBHOOK_URL:-}" ]]; then
echo "[NOTIFY] SLACK_WEBHOOK_URL 미설정 — 알림 생략" >&2
return 0
fi
# 레벨별 이모지 및 색상 설정
local emoji color
case "$level" in
OK) emoji=":white_check_mark:"; color="#36a64f" ;;
WARN) emoji=":warning:"; color="#ffcc00" ;;
CRIT) emoji=":rotating_light:"; color="#ff0000" ;;
*) emoji=":information_source:"; color="#439fe0" ;;
esac
local ts
ts=$(date '+%Y-%m-%d %H:%M:%S')
# Slack Block Kit JSON 페이로드 구성
# printf를 사용해 특수문자 이스케이프 문제 최소화
local payload
payload=$(printf '{
"attachments": [{
"color": "%s",
"blocks": [
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "%s *[%s]* `%s` — %s"
}
},
{
"type": "context",
"elements": [{
"type": "mrkdwn",
"text": "호스트: `%s` | 시각: %s"
}]
}
]
}]
}' "$color" "$emoji" "$level" "$target" "$message" "$HOSTNAME_SHORT" "$ts")
# curl로 전송, 타임아웃 설정
local http_code
http_code=$(timeout "$SLACK_TIMEOUT" curl \
-s \
-o /dev/null \
-w "%{http_code}" \
-X POST \
-H "Content-Type: application/json" \
-d "$payload" \
"${SLACK_WEBHOOK_URL}" 2>/dev/null) || http_code="000"
if [[ "$http_code" == "200" ]]; then
echo "[NOTIFY] Slack 알림 전송 성공 [$level] $target"
else
echo "[NOTIFY] Slack 알림 전송 실패 (HTTP $http_code)" >&2
fi
}
# --
# 사용 예시 (직접 실행 시 데모)
# --
if [[ "${BASH_SOURCE[0]}" == "${0}" ]]; then
echo "=== Slack 알림 모듈 데모 ==="
echo "SLACK_WEBHOOK_URL 환경변수를 설정한 뒤 아래 함수를 호출하세요:"
echo ' slack_notify "CRIT" "nginx" "서비스 다운 — 자동 재시작 실패"'
echo ' slack_notify "OK" "nginx" "서비스 복구 완료"'
echo ""
# 실제 Webhook URL이 있으면 테스트 메시지 전송
if [[ -n "${SLACK_WEBHOOK_URL:-}" ]]; then
slack_notify "INFO" "test" "헬스체크 시스템 알림 테스트 메시지입니다"
fi
fi
EOF
sudo chmod +x /opt/healthcheck/notify.sh
notify.sh를 독립 모듈로 분리해두면, 다른 헬스체크 스크립트에서 source /opt/healthcheck/notify.sh로 불러와 slack_notify 함수를 바로 사용할 수 있습니다.
check_services.sh에 알림 연동하기:
# check_services.sh 상단에 추가
source /opt/healthcheck/notify.sh
# check_and_recover 함수 실패 시 알림 호출
if ! systemctl restart "$service" 2>>"$LOG_FILE"; then
log "ERROR" "$service 재시작 실패"
slack_notify "CRIT" "$service" "자동 재시작 실패 — 수동 점검 필요"
return 1
fi
6. Cron 등록과 절대경로 문제
스크립트가 터미널에서는 잘 동작하는데 cron에서 실행하면 실패하는 경우가 매우 흔합니다. cron은 최소한의 환경변수만 가진 새 셸에서 실행되기 때문에 PATH가 달라집니다.
Cron 환경과 절대경로 원칙
 확대
확대
터미널에서 직접 실행하면 잘 되는 헬스체크 스크립트가 cron에서는 command not found로 조용히 실패하는 경우가 있습니다. python3이 /usr/bin/python3에 있어도 cron의 PATH에는 없어서 못 찾는 것입니다. ~/config.yaml로 된 경로도 cron 환경에서는 HOME이 다르게 설정되어 파일을 못 찾습니다. cron은 일반 로그인 세션과 전혀 다른 최소한의 환경으로 실행되기 때문에, 이 차이를 모르면 스크립트가 왜 cron에서만 실패하는지 원인을 찾기 어렵습니다.
cron 작업이 실행될 때의 환경은 일반 사용자 세션과 크게 다릅니다.
| 항목 | 일반 터미널 | Cron 환경 |
|---|---|---|
$PATH | /usr/local/bin:/usr/bin:/bin:... | /usr/bin:/bin (최소) |
$HOME | /home/username | /root 또는 /home/username |
$USER | 로그인 사용자 | root 또는 cron 실행 사용자 |
.bashrc | 로드됨 | 로드되지 않음 |
.bash_profile | 로드됨 | 로드되지 않음 |
이 때문에 cron에서 실행되는 스크립트에는 모든 명령어를 절대경로로 작성해야 합니다.
# 잘못된 예 — cron에서 실패할 수 있음
systemctl restart nginx
curl -s http://localhost/health
# 올바른 예 — 절대경로 명시
/usr/bin/systemctl restart nginx
/usr/bin/curl -s http://localhost/health
또는 스크립트 맨 위에서 PATH를 명시적으로 재정의합니다.
#!/usr/bin/env bash
export PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
Cron 표현식 빠른 참조
cron 표현식 * * * * * 명령어의 다섯 자리는 각각 다음 시간 단위입니다.
| 위치 | 필드 | 범위 |
|---|---|---|
| 1번째 | 분 | 0-59 |
| 2번째 | 시 | 0-23 |
| 3번째 | 일 | 1-31 |
| 4번째 | 월 | 1-12 |
| 5번째 | 요일 | 0=일, 7=일 |
| 표현식 | 의미 |
|---|---|
*/5 * * * * | 5분마다 |
0 * * * * | 매시간 정각 |
0 2 * * * | 매일 새벽 2시 |
0 2 * * 0 | 매주 일요일 새벽 2시 |
*/1 * * * * | 1분마다 (최소 단위) |
Cron보다 짧은 주기가 필요할 때
cron의 최소 단위는 1분입니다. 30초마다 실행하려면 다음 패턴을 씁니다.
# crontab -e
* * * * * /opt/healthcheck/check_services.sh
* * * * * sleep 30 && /opt/healthcheck/check_services.sh
또는 systemd timer를 활용하면 초 단위 정밀도로 스케줄링할 수 있습니다.
# 현재 crontab 확인
crontab -l
# crontab 편집
crontab -e
crontab에 다음 내용을 추가합니다:
# 환경변수 설정 (cron 전용)
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
SLACK_WEBHOOK_URL=https://hooks.slack.com/services/YOUR/WEBHOOK/URL
# 5분마다 서비스 헬스체크
*/5 * * * * /opt/healthcheck/check_services.sh >> /var/log/healthcheck/cron.log 2>&1
# 10분마다 리소스 체크
*/10 * * * * /opt/healthcheck/check_resources.sh >> /var/log/healthcheck/cron.log 2>&1
# 3분마다 HTTP 엔드포인트 체크
*/3 * * * * /opt/healthcheck/check_endpoints.sh >> /var/log/healthcheck/cron.log 2>&1
cron 로그가 무한히 커지는 걸 막기 위해 logrotate를 설정합니다:
sudo tee /etc/logrotate.d/healthcheck > /dev/null << 'EOF'
/var/log/healthcheck/*.log {
daily
rotate 14
compress
delaycompress
missingok
notifempty
create 0640 root root
}
EOF
cron 실행 여부를 확인하려면 시스템 로그를 확인합니다:
# Ubuntu / Debian
grep CRON /var/log/syslog | tail -20
# RHEL / CentOS
grep cron /var/log/cron | tail -20
# systemd 기반
journalctl -u cron --since "1 hour ago"
트러블슈팅
증상: 터미널에서 직접 실행하면 정상 동작하지만 cron에서는 오류 없이 조용히 실패하거나 "command not found" 오류가 발생합니다.
원인 1 — PATH 불일치
cron은 /usr/bin:/bin 정도의 최소 PATH만 가집니다. systemctl, curl, nc 등은 /usr/sbin이나 /usr/local/bin에 있을 수 있습니다.
# 먼저 명령어의 실제 위치를 확인
which systemctl # /usr/bin/systemctl
which curl # /usr/bin/curl
which nc # /usr/bin/nc 또는 /bin/nc
# crontab 상단에 PATH 명시
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
원인 2 — 상대경로 사용
스크립트 내부에서 source ./notify.sh처럼 상대경로를 쓰면, cron은 작업 디렉터리가 다르기 때문에 파일을 찾지 못합니다.
# 잘못된 예
source ./notify.sh
LOG_FILE="logs/healthcheck.log"
# 올바른 예
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
source "${SCRIPT_DIR}/notify.sh"
LOG_FILE="/var/log/healthcheck/healthcheck.log"
원인 3 — 환경변수 미설정
SLACK_WEBHOOK_URL 같은 환경변수는 crontab 파일에서 직접 설정하거나, /etc/environment 또는 별도의 설정 파일을 source해야 합니다.
# /opt/healthcheck/env.conf
SLACK_WEBHOOK_URL="https://hooks.slack.com/..."
# crontab에서 source
*/5 * * * * . /opt/healthcheck/env.conf && /opt/healthcheck/check_services.sh
디버깅 방법 — cron 환경 그대로 시뮬레이션:
# cron이 사용하는 환경과 동일하게 실행
env -i HOME=/root SHELL=/bin/bash PATH=/usr/bin:/bin /opt/healthcheck/check_services.sh
증상: 헬스체크 스크립트가 5분마다 nginx를 재시작하는데, nginx가 실제로는 설정 파일 오류로 계속 시작 실패합니다. 재시작 시도가 무한 반복되고 로그가 폭증합니다.
원인 — 재시작 횟수 제한 미구현 또는 카운터 파일이 cron 실행 간에 초기화됨
앞서 작성한 check_nginx.sh의 RESTART_COUNT_FILE=/tmp/nginx_restart_count를 보면, /tmp는 재부팅 시 초기화됩니다. 하지만 더 큰 문제는 서비스가 정상화되지 않아도 스크립트가 다음 실행 시 카운터를 초기화하는 경우입니다.
해결책 — 시간 기반 카운터와 backoff 전략:
# /opt/healthcheck/lib/restart_guard.sh
RESTART_LOG="/var/log/healthcheck/restart_history.log"
MAX_RESTARTS_PER_HOUR=3
# 최근 1시간 내 재시작 횟수 계산
count_recent_restarts() {
local service="$1"
local one_hour_ago
one_hour_ago=$(date -d '1 hour ago' '+%s' 2>/dev/null || date -v-1H '+%s')
if [[ ! -f "$RESTART_LOG" ]]; then
echo "0"
return
fi
awk -v svc="$service" -v cutoff="$one_hour_ago" '
$3 == svc && $1 > cutoff { count++ }
END { print count+0 }
' "$RESTART_LOG"
}
# 재시작 기록
record_restart() {
local service="$1"
echo "$(date '+%s') $(date '+%Y-%m-%d %H:%M:%S') $service" >> "$RESTART_LOG"
}
# 가드: 재시작 가능 여부 확인
can_restart() {
local service="$1"
local count
count=$(count_recent_restarts "$service")
if [[ "$count" -ge "$MAX_RESTARTS_PER_HOUR" ]]; then
echo "false"
return
fi
echo "true"
}
systemd의 재시작 제한과 연계:
systemd 자체도 재시작 제한 기능이 있습니다. /etc/systemd/system/nginx.service.d/restart-limit.conf를 만들어 두 겹으로 보호합니다.
[Service]
# 10초 내에 5번 재시작 시도 후 포기
StartLimitIntervalSec=10
StartLimitBurst=5
Restart=on-failure
RestartSec=5
증상: check_endpoints.sh가 특정 시간대에 완료되지 않고 cron 프로세스가 쌓입니다. ps aux를 보면 같은 스크립트가 여러 개 실행 중입니다.
원인 — curl 타임아웃 미적용 또는 timeout 명령어 미사용
curl에 --connect-timeout과 --max-time을 지정했더라도 일부 엣지 케이스(TCP 연결은 됐지만 응답이 안 오는 경우)에서 행이 발생할 수 있습니다. 또한 스크립트 자체에 timeout 래퍼가 없으면 해당 cron 주기 내내 프로세스가 살아있게 됩니다.
해결책 1 — timeout 명령어로 스크립트 전체를 감쌈:
# crontab에서
*/3 * * * * timeout 120 /opt/healthcheck/check_endpoints.sh >> /var/log/healthcheck/cron.log 2>&1
timeout 120은 120초(2분) 후 스크립트를 강제 종료합니다. cron 주기가 3분이면 이전 실행이 반드시 2분 안에 종료되므로 프로세스 중첩이 방지됩니다.
해결책 2 — 잠금 파일(lock file)로 중복 실행 방지:
#!/usr/bin/env bash
LOCK_FILE="/tmp/check_endpoints.lock"
# 잠금 파일 존재 확인 (이미 실행 중인지 체크)
if [ -f "$LOCK_FILE" ]; then
# 잠금 파일 내 PID가 실제 실행 중인지 확인
OLD_PID=$(cat "$LOCK_FILE")
if kill -0 "$OLD_PID" 2>/dev/null; then
echo "이미 실행 중 (PID: $OLD_PID). 종료합니다."
exit 0
else
echo "이전 잠금 파일 제거 (PID $OLD_PID 는 종료됨)"
rm -f "$LOCK_FILE"
fi
fi
# 현재 PID로 잠금 파일 생성
echo $$ > "$LOCK_FILE"
# 스크립트 종료 시 잠금 파일 자동 제거
trap 'rm -f "$LOCK_FILE"' EXIT
# ... 실제 작업 ...
해결책 3 — curl에 추가 옵션 적용:
curl \
-s \
-o /dev/null \
-w "%{http_code}" \
--connect-timeout 3 \
--max-time 8 \
--retry 0 \ # 재시도 비활성화 (헬스체크에서는 직접 관리)
--no-keepalive \ # Keep-Alive 비활성화로 연결 빠르게 종료
"$url"
심화 — 무엇을 '죽음'으로 볼 것인가: liveness와 의존성
심화: 얕은 liveness와 깊은 헬스체크 — 재시작을 붙일 곳과 붙이면 안 되는 곳
지금까지의 스크립트는 '문제를 감지하면 재시작한다'였습니다. 그런데 무엇을 '문제'로 볼지에 따라, 같은 자동 복구가 서비스를 살리기도 하고 오히려 전체를 무너뜨리기도 합니다. 그 경계가 liveness(살아 있나)와 readiness/의존성(지금 일할 준비가 됐나) 의 구분입니다.
- 얕은(shallow) 체크 = liveness: 프로세스가 떠 있는가, 포트를 듣고 있는가, 자기 자신의
/ping이 응답하는가 — 오직 이 서비스 자신의 생사만 봅니다. 여기서 '죽음'은 재시작으로 고칠 수 있는 상태이므로, 자동 재시작을 붙여도 되는 유일한 신호입니다. - 깊은(deep) 체크 = 의존성 포함:
/health가 내부에서 DB·캐시·외부 API까지 확인합니다. 서비스가 실제로 트래픽을 처리할 수 있는지 알려주지만, 여기서의 실패는 이 서비스 잘못이 아닐 수 있습니다(DB가 느린 것). - 치명적 안티패턴: 깊은 체크 결과에 재시작을 연결하는 것. DB가 느려지면 모든 앱 인스턴스의 깊은 체크가 동시에 실패하고, 스크립트가 멀쩡한 앱들을 일제히 재시작합니다. 재시작해도 DB는 그대로라 복구되지 않고, 재시작 폭풍이 남은 자원까지 갉아먹어 장애가 증폭됩니다.
- 원칙: 재시작(복구 액션)은 얕은 liveness에만. 깊은 체크는 **알림·라우팅에서 제외(트래픽 차단)**에만 연결합니다. 오케스트레이터의 liveness probe와 readiness probe가 분리된 이유가 바로 이것입니다.
정리하면, 자가복구 스크립트를 강하게 만드는 것은 더 많은 재시작이 아니라 '언제 재시작하면 안 되는가'를 아는 것입니다.
상황: 특정 시각 이후 여러 앱 서버가 동시에 재시작을 반복합니다. 각 앱의 프로세스·설정은 정상이고, 앱 로그에도 크래시 흔적이 없습니다. 공통점은 그 시각에 공유 데이터베이스 응답이 느려졌다는 것뿐입니다.
원인: 헬스체크가 /health 안에서 DB 쿼리까지 수행하는 깊은 체크였고, 스크립트가 그 결과에 재시작을 연결해 두었습니다. DB 지연으로 /health가 5xx·타임아웃을 반환하자, 스크립트는 이를 '앱이 죽었다'로 오판해 전 인스턴스를 동시에 재시작했습니다. 재시작해도 DB는 그대로여서 다음 주기에 또 실패하고 — 재시작 폭풍이 반복됩니다.
진단: 재시작 로그의 시각이 여러 서버에서 동시에 찍히는지 확인합니다(개별 크래시라면 시각이 흩어짐). /health가 무엇을 확인하는지 열어 DB·외부 의존성 호출이 들어 있는지 봅니다. 그 시간대의 DB 지표(연결 수·슬로우쿼리)와 재시작 시각을 겹쳐 보면 인과가 드러납니다.
해결: 재시작 트리거를 얕은 liveness(프로세스 생존·자기 포트 응답)로 교체합니다. 깊은 체크는 유지하되 그 결과는 재시작이 아니라 알림과 라우팅 제외로만 연결합니다. 근본 원인인 DB 지연은 커넥션 풀·슬로우쿼리 튜닝으로 따로 해결하고, 재시작 가드(시간당 N회 제한)를 함께 걸어 폭풍을 물리적으로 차단합니다.
실무 적용 패턴
금융권이나 공공기관의 온프레미스 서버는 Prometheus 같은 외부 도구를 설치하기 위해 별도의 보안 심사를 받아야 하는 경우가 많습니다. 이런 환경에서 헬스체크 스크립트는 사실상 유일한 자동화 수단입니다.
실무에서 자주 마주치는 시나리오:
-
Java 웹 애플리케이션 서버(Tomcat/JBoss) — 프로세스는 살아있지만 메모리 부족(OOM)으로 응답이 없는 상태.
curl로/health엔드포인트를 직접 확인하는 방법만 신뢰할 수 있습니다. -
야간 배치 작업 후 데몬 비활성화 — 야간 배치가 끝나면서 부산물로 웹 서버가 함께 내려가는 버그. cron으로 새벽 5시부터 30분마다 서비스 상태를 체크하고, 개발팀 Slack 채널로 알림을 보냅니다.
-
디스크 풀(full)로 인한 서비스 장애 예방 — 로그 파티션이 100%가 되면 nginx가 접근 로그를 쓰지 못해 502를 반환합니다. 디스크 임계값 알림으로 90%가 되는 시점에 미리 정리합니다.
# 디스크 정리 + 알림을 결합한 자동 복구 예시
check_and_cleanup_disk() {
local usage
usage=$(df -h / | awk 'NR==2 {gsub(/%/,""); print $5}')
if [[ "$usage" -ge 90 ]]; then
slack_notify "WARN" "disk" "루트 파티션 ${usage}% — 자동 정리 시작"
# journald 로그 정리 (2주 이상 된 것)
journalctl --vacuum-time=14d
# 오래된 도커 이미지 정리 (도커 환경일 경우)
if command -v docker &>/dev/null; then
docker image prune -f --filter "until=720h"
fi
local usage_after
usage_after=$(df -h / | awk 'NR==2 {gsub(/%/,""); print $5}')
slack_notify "INFO" "disk" "정리 완료 — ${usage}% → ${usage_after}%"
fi
}
운영 팁: 스크립트를 Git으로 관리하고, 변경 시마다 /opt/healthcheck/ 서버에 자동 배포하는 파이프라인을 구성하면 여러 서버에 동일한 스크립트를 일관되게 유지할 수 있습니다.
Kubernetes나 ECS 같은 컨테이너 오케스트레이터는 자체 헬스체크(liveness probe, readiness probe)를 가지고 있지만, 외부에서 바라보는 시각이 필요할 때가 있습니다. 또한 서비스 메시(Istio 등)를 사용하더라도 사이드카 외부의 호스트 레벨 체크는 별도로 필요합니다.
실제 활용 예 — 다중 서비스 통합 헬스체크 대시보드:
#!/usr/bin/env bash
# dashboard.sh — 터미널 헬스 대시보드 (watch 명령어와 조합)
# 사용법: watch -n 5 /opt/healthcheck/dashboard.sh
export PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
GREEN='\033[0;32m'
RED='\033[0;31m'
YELLOW='\033[1;33m'
NC='\033[0m' # No Color
SERVICES=("nginx" "postgresql" "redis" "docker" "sshd")
HTTP_CHECKS=(
"Gateway:http://localhost:8080/health"
"Auth:http://localhost:3001/health"
"Catalog:http://localhost:3002/health"
"Cart:http://localhost:3003/health"
)
echo "========================================"
echo " 서버 헬스 대시보드 | $(hostname -s)"
echo " $(date '+%Y-%m-%d %H:%M:%S')"
echo "========================================"
echo ""
echo "[ SYSTEMD 서비스 ]"
for svc in "${SERVICES[@]}"; do
if systemctl is-active --quiet "$svc" 2>/dev/null; then
printf " ${GREEN}%-20s ACTIVE${NC}\n" "$svc"
else
printf " ${RED}%-20s INACTIVE${NC}\n" "$svc"
fi
done
echo ""
echo "[ HTTP 엔드포인트 ]"
for entry in "${HTTP_CHECKS[@]}"; do
name="${entry%%:*}"
url="${entry#*:}"
code=$(timeout 3 curl -s -o /dev/null -w "%{http_code}" --connect-timeout 2 "$url" 2>/dev/null || echo "000")
if [[ "$code" == "200" ]]; then
printf " ${GREEN}%-20s %s${NC}\n" "$name" "$code"
else
printf " ${RED}%-20s %s${NC}\n" "$name" "$code"
fi
done
echo ""
echo "[ 리소스 ]"
disk=$(df -h / | awk 'NR==2 {print $5}')
mem=$(free -m | awk '/^Mem:/ {printf "%.0f%%", ($2-$7)/$2*100}')
load=$(uptime | awk -F'load average:' '{print $2}' | awk '{print $1}' | tr -d ',')
printf " %-20s %s\n" "디스크 (/):" "$disk"
printf " %-20s %s\n" "메모리 사용률:" "$mem"
printf " %-20s %s\n" "1분 로드 평균:" "$load"
echo "========================================"
# 5초마다 갱신되는 라이브 대시보드
watch -n 5 /opt/healthcheck/dashboard.sh
이 대시보드는 Grafana가 없는 환경에서도 SSH 접속만으로 전체 서비스 상태를 한눈에 파악할 수 있게 해줍니다. CI/CD 파이프라인에서 배포 후 검증 단계에 통합해 모든 서비스가 200 응답을 반환할 때까지 대기하는 용도로도 활용됩니다.
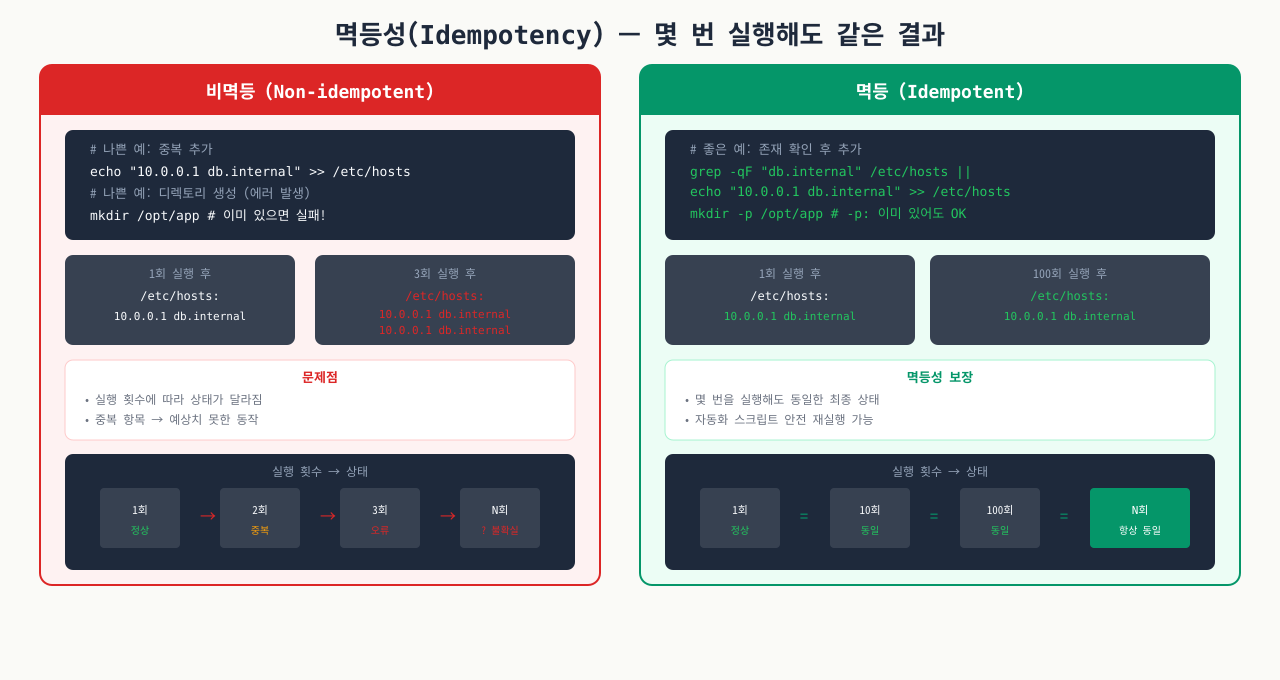
멱등성 원칙과 안전한 스크립트 설계
멱등성(Idempotency) — 몇 번을 실행해도 같은 결과
 확대
확대
복구 스크립트를 두 번 실행했더니, 첫 번째는 서비스가 정상 복구됐고 두 번째는 이미 실행 중인 프로세스를 또 시작하려다 포트 충돌이 났습니다. 헬스체크 스크립트는 이상 감지 때마다 반복 실행되기 때문에, 이미 정상 상태인 서버에서 실행되더라도 부작용이 없어야 합니다. 이 성질을 멱등성이라 하며, 운영 자동화 스크립트 설계의 핵심 원칙입니다.
멱등성은 수학 개념에서 온 말이지만, 운영 자동화에서 핵심 원칙입니다. 같은 스크립트를 n번 실행해도 결과가 1번 실행한 것과 동일해야 한다는 뜻입니다.
멱등하지 않은 예 — 실행할 때마다 상태가 달라짐:
# 나쁜 예: 실행할 때마다 재시작
systemctl restart nginx # 정상이어도 무조건 재시작
멱등한 예 — 이상 있을 때만 동작:
# 좋은 예: 이상 상태일 때만 재시작
if ! systemctl is-active --quiet nginx; then
systemctl restart nginx
fi
안전한 스크립트 작성 체크리스트
#!/usr/bin/env bash
# 1. 엄격한 오류 처리
set -euo pipefail
# -e : 오류 발생 시 즉시 종료
# -u : 미정의 변수 사용 시 오류
# -o pipefail : 파이프 내 오류도 감지
# 2. 함수 내에서는 set -e가 의도대로 동작하지 않을 수 있으므로
# 명시적 || 처리
systemctl restart nginx || { echo "재시작 실패"; exit 1; }
# 3. 임시 파일은 trap으로 반드시 정리
TMPFILE=$(mktemp)
trap 'rm -f "$TMPFILE"' EXIT
# 4. 커맨드 치환에서 공백/개행 처리
# 안전한 방법: 큰따옴표로 감쌈
SERVICE_STATUS="$(systemctl is-active nginx)"
# 5. 숫자 비교는 -eq/-gt/-lt, 문자열 비교는 == 사용
if [[ "$count" -gt 0 ]]; then ...
if [[ "$status" == "active" ]]; then ...
# 6. 스크립트에 버전/날짜 주석
# version: 1.2.0
# last-modified: 2026-03-26
timeout 명령어 활용 패턴
외부 명령어가 얼마나 걸릴지 모를 때 timeout으로 상한을 설정합니다.
# 기본 사용법
timeout 10 curl http://localhost/health
# 종료 시그널 지정 (-k: KILL 시그널 추가 전송)
# 5초 후 TERM, 추가로 2초 후 KILL
timeout -k 2 5 some_slow_command
# 종료 코드 확인
if ! timeout 5 curl -s http://localhost/health > /dev/null; then
if [[ $? -eq 124 ]]; then
echo "타임아웃 (5초 초과)"
else
echo "연결 실패"
fi
fi
전체 통합 스크립트
지금까지 배운 내용을 하나로 통합한 엔터프라이즈급 헬스체크 스크립트입니다.
sudo tee /opt/healthcheck/master_check.sh > /dev/null << 'MASTEREOF'
#!/usr/bin/env bash
# master_check.sh — 통합 헬스체크 & 자가복구 스크립트
# version: 2.0.0
# 사용법: ./master_check.sh [--dry-run] [--silent] [--report]
export PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
set -uo pipefail
# --
# 설정
# --
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
LOG_DIR="/var/log/healthcheck"
LOG_FILE="$LOG_DIR/master.log"
LOCK_FILE="/tmp/master_check.lock"
RESTART_LOG="$LOG_DIR/restart_history.log"
SERVICES=("nginx" "postgresql" "redis")
HTTP_CHECKS=("http://localhost:80/health:200" "http://localhost:8080/api/health:200")
TCP_CHECKS=("localhost:5432:postgresql" "localhost:6379:redis")
DISK_CRIT=90
MEM_CRIT=95
MAX_RESTARTS_PER_HOUR=3
CURL_TIMEOUT=5
DRY_RUN=false
SILENT=false
REPORT=false
PASS_COUNT=0
FAIL_COUNT=0
SKIP_COUNT=0
# --
# 초기화
# --
init() {
mkdir -p "$LOG_DIR"
# 잠금 파일로 중복 실행 방지
if [[ -f "$LOCK_FILE" ]]; then
local old_pid
old_pid=$(cat "$LOCK_FILE")
if kill -0 "$old_pid" 2>/dev/null; then
log "WARN" "이미 실행 중 (PID: $old_pid). 종료합니다."
exit 0
fi
rm -f "$LOCK_FILE"
fi
echo $$ > "$LOCK_FILE"
trap 'rm -f "$LOCK_FILE"' EXIT
# 인자 파싱
for arg in "$@"; do
case "$arg" in
--dry-run) DRY_RUN=true ;;
--silent) SILENT=true ;;
--report) REPORT=true ;;
esac
done
}
# --
# 로깅
# --
log() {
local level="$1"; shift
local msg="[$(date '+%Y-%m-%d %H:%M:%S')] [$level] $*"
echo "$msg" >> "$LOG_FILE"
[[ "$SILENT" == "false" ]] && echo "$msg"
}
# --
# Slack 알림
# --
notify() {
local level="$1" target="$2" message="$3"
[[ -z "${SLACK_WEBHOOK_URL:-}" ]] && return 0
[[ "$DRY_RUN" == "true" ]] && { log "INFO" "[DRY-RUN] Slack 알림: [$level] $target — $message"; return 0; }
local emoji
case "$level" in OK) emoji=":white_check_mark:" ;; WARN) emoji=":warning:" ;; CRIT) emoji=":rotating_light:" ;; *) emoji=":info:" ;; esac
timeout 10 curl -s -o /dev/null -X POST \
-H "Content-Type: application/json" \
-d "{\"text\":\"${emoji} *[$level]* \`$(hostname -s)\` | ${target}: ${message}\"}" \
"${SLACK_WEBHOOK_URL}" 2>/dev/null || true
}
# --
# 재시작 가드
# --
can_restart() {
local service="$1"
local cutoff
cutoff=$(date -d '1 hour ago' '+%s' 2>/dev/null || date -v-1H '+%s' 2>/dev/null || echo "0")
local count=0
if [[ -f "$RESTART_LOG" ]]; then
count=$(awk -v svc="$service" -v t="$cutoff" '$3==svc && $1>t {c++} END{print c+0}' "$RESTART_LOG")
fi
[[ "$count" -lt "$MAX_RESTARTS_PER_HOUR" ]]
}
record_restart() {
echo "$(date '+%s') $(date '+%Y-%m-%d %H:%M:%S') $1" >> "$RESTART_LOG"
}
# --
# 체크 함수들
# --
check_service() {
local svc="$1"
if systemctl is-active --quiet "$svc" 2>/dev/null; then
log "OK" "SERVICE $svc: active"; ((PASS_COUNT++)); return 0
fi
log "FAIL" "SERVICE $svc: inactive"
((FAIL_COUNT++))
if ! can_restart "$svc"; then
log "ERROR" "$svc: 시간당 재시작 한도 초과 — 수동 점검 필요"
notify "CRIT" "$svc" "재시작 한도 초과, 수동 점검 요망"
return 1
fi
[[ "$DRY_RUN" == "true" ]] && { log "INFO" "[DRY-RUN] $svc 재시작 시뮬레이션"; return 0; }
record_restart "$svc"
if systemctl restart "$svc" 2>>"$LOG_FILE"; then
log "INFO" "$svc 재시작 성공"
notify "WARN" "$svc" "비활성 감지 → 자동 재시작 완료"
else
log "ERROR" "$svc 재시작 실패"
notify "CRIT" "$svc" "재시작 실패 — 즉시 점검 필요"
return 1
fi
}
check_http() {
local entry="$1"
local url="${entry%%:*}"
local expected="${entry##*:}"
local code
code=$(timeout "$CURL_TIMEOUT" curl -s -o /dev/null -w "%{http_code}" \
--connect-timeout 3 --max-time "$CURL_TIMEOUT" "$url" 2>/dev/null) || code="000"
if [[ "$code" == "$expected" ]]; then
log "OK" "HTTP $url: $code"; ((PASS_COUNT++))
else
log "FAIL" "HTTP $url: $code (예상: $expected)"; ((FAIL_COUNT++))
notify "WARN" "$url" "HTTP $code (예상: $expected)"
fi
}
check_tcp() {
local entry="$1"
IFS=':' read -r host port name <<< "$entry"
if timeout 3 bash -c "echo >/dev/tcp/$host/$port" 2>/dev/null; then
log "OK" "TCP $name ($host:$port): open"; ((PASS_COUNT++))
else
log "FAIL" "TCP $name ($host:$port): closed"; ((FAIL_COUNT++))
notify "WARN" "$name" "포트 $port 응답 없음"
fi
}
check_disk() {
while IFS= read -r line; do
local usage mp
usage=$(echo "$line" | awk '{gsub(/%/,"",$5); print $5}')
mp=$(echo "$line" | awk '{print $6}')
[[ -z "$usage" ]] && continue
if [[ "$usage" -ge "$DISK_CRIT" ]]; then
log "CRIT" "DISK $mp: ${usage}%"; ((FAIL_COUNT++))
notify "CRIT" "disk:$mp" "${usage}% 사용 중"
else
log "OK" "DISK $mp: ${usage}%"; ((PASS_COUNT++))
fi
done < <(df -h -x tmpfs -x devtmpfs | tail -n +2)
}
check_memory() {
local pct
pct=$(free -m | awk '/^Mem:/ {printf "%.0f", ($2-$7)/$2*100}')
if [[ "$pct" -ge "$MEM_CRIT" ]]; then
log "CRIT" "MEMORY: ${pct}%"; ((FAIL_COUNT++))
notify "CRIT" "memory" "${pct}% 사용 중"
else
log "OK" "MEMORY: ${pct}%"; ((PASS_COUNT++))
fi
}
print_report() {
[[ "$REPORT" == "false" ]] && return
local total=$((PASS_COUNT + FAIL_COUNT + SKIP_COUNT))
log "INFO" "=============================="
log "INFO" "최종 리포트: 총 ${total}건 | 정상 ${PASS_COUNT} | 실패 ${FAIL_COUNT} | 건너뜀 ${SKIP_COUNT}"
log "INFO" "=============================="
}
# --
# 메인
# --
main() {
init "$@"
log "INFO" "=== 통합 헬스체크 시작 (DRY_RUN=$DRY_RUN) ==="
for svc in "${SERVICES[@]}"; do check_service "$svc" || true; done
for ep in "${HTTP_CHECKS[@]}"; do check_http "$ep" || true; done
for tcp in "${TCP_CHECKS[@]}"; do check_tcp "$tcp" || true; done
check_disk || true
check_memory || true
print_report
log "INFO" "=== 통합 헬스체크 완료 ==="
}
main "$@"
MASTEREOF
sudo chmod +x /opt/healthcheck/master_check.sh
# 테스트 실행
sudo /opt/healthcheck/master_check.sh --dry-run --report
재시작 루프 방지 — 횟수 제한·쿨다운·systemd StartLimit 연계
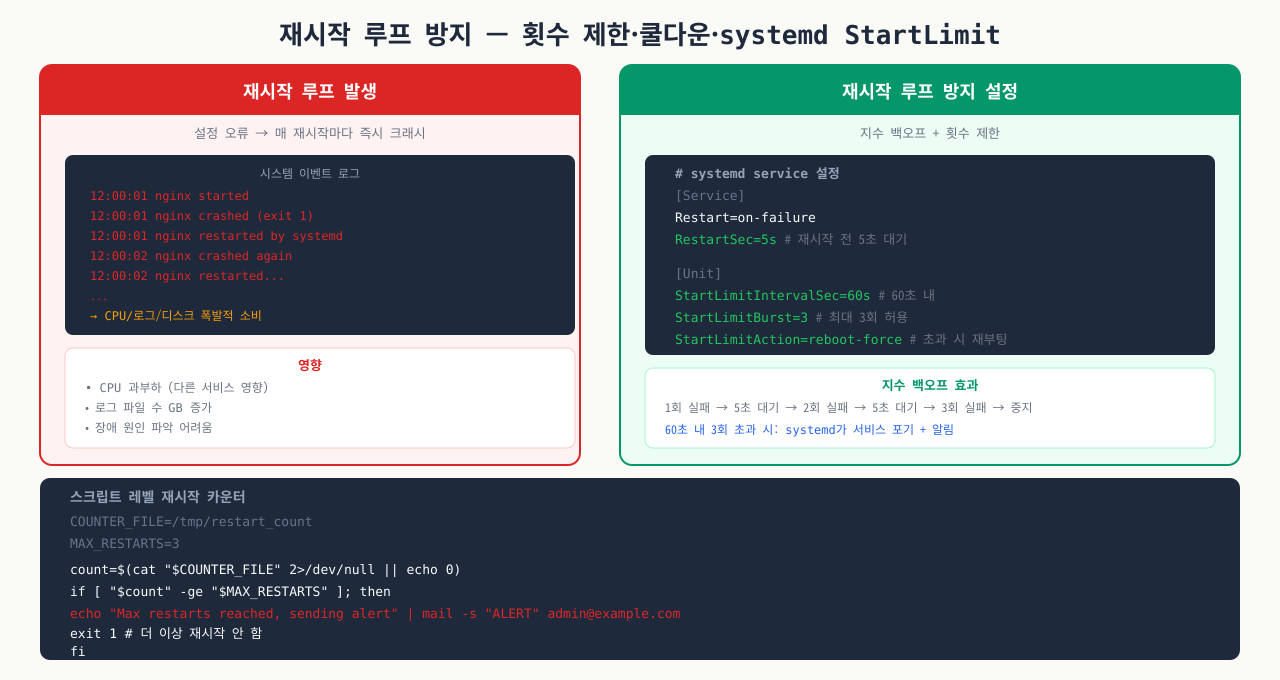 확대
확대
헬스체크 스크립트가 서비스를 자동으로 재시작할 때 재시작 루프에 빠지지 않도록 반드시 횟수와 쿨다운을 제한해야 합니다.
쉘 스크립트 레벨 횟수 제한:
# /opt/healthcheck/restart_nginx.sh
STATE_FILE="/tmp/nginx_restart_state"
MAX_RESTARTS=3
COOLDOWN_SECONDS=300 # 5분 이내 MAX_RESTARTS 초과 시 중단
NOW=$(date +%s)
# 상태 파일에서 재시작 이력 읽기
if [ -f "$STATE_FILE" ]; then
source "$STATE_FILE"
else
RESTART_COUNT=0
WINDOW_START=$NOW
fi
# 5분 윈도우가 지났으면 카운터 초기화
if [ $((NOW - WINDOW_START)) -gt $COOLDOWN_SECONDS ]; then
RESTART_COUNT=0
WINDOW_START=$NOW
fi
# 최대 재시작 횟수 초과 시 알람만 발송하고 중단
if [ $RESTART_COUNT -ge $MAX_RESTARTS ]; then
echo "[CRITICAL] nginx 5분 내 ${MAX_RESTARTS}회 재시작 실패 — 수동 개입 필요"
# 알림 발송 (예: curl로 Slack/PagerDuty webhook)
exit 1
fi
# 재시작 실행
sudo systemctl restart nginx
RESTART_COUNT=$((RESTART_COUNT + 1))
# 상태 저장
echo "RESTART_COUNT=$RESTART_COUNT" > "$STATE_FILE"
echo "WINDOW_START=$WINDOW_START" >> "$STATE_FILE"
systemd StartLimit 연계 (권장):
직접 재시작 루프를 제어하는 것보다 systemd의 StartLimit을 활용하면 더 안정적입니다.
# /etc/systemd/system/nginx.service.d/restart-limit.conf
[Unit]
StartLimitIntervalSec=300 # 5분 안에
StartLimitBurst=3 # 3번 재시작 실패 시 → failed 상태로 전환
[Service]
Restart=on-failure
RestartSec=10 # 재시작 전 10초 대기
# StartLimit 도달 후 수동 복구
sudo systemctl reset-failed nginx
sudo systemctl start nginx
쿨다운 없는 재시작 루프의 위험:
| 시나리오 | 결과 |
|---|---|
| DB 연결 실패 → 헬스체크 fail → 즉시 재시작 반복 | 초당 수십 번 재시작, DB에 연결 폭탄 |
| 설정 파일 오류 → 서비스 시작 실패 → 즉시 재시작 | 로그 폭발, 디스크 가득 참 |
| 네트워크 일시 단절 → 헬스체크 timeout → 재시작 | 정상 서비스를 불필요하게 중단 |
스크립트 동시 실행 방지 — flock(lockfile) + 타임아웃/재시도 정책
 확대
확대
cron이 1분마다 헬스체크를 실행할 때, 이전 실행이 끝나기 전에 새 실행이 시작되면 동시에 서비스를 재시작하거나 상태 파일이 꼬일 수 있습니다.
flock으로 동시 실행 방지:
#!/bin/bash
# /opt/healthcheck/check_nginx.sh — flock으로 단일 실행 보장
LOCKFILE="/var/lock/check_nginx.lock"
TIMEOUT=30 # 30초 이내 락 획득 실패 시 종료
# flock: -n은 즉시 실패, -w는 대기 후 실패
exec 200>"$LOCKFILE"
if ! flock -w "$TIMEOUT" 200; then
echo "[WARN] 이전 헬스체크가 아직 실행 중 — 이번 실행 건너뜀"
exit 0
fi
# 락 획득 성공 — 실제 헬스체크 수행
if ! systemctl is-active --quiet nginx; then
echo "[$(date)] nginx 중단 감지 — 재시작 시도"
sudo systemctl restart nginx
fi
# flock은 스크립트 종료 시 자동 해제
curl 헬스체크 타임아웃 설정:
# 타임아웃 없는 curl은 영원히 hang할 수 있음
# --max-time: 전체 최대 시간, --connect-timeout: 연결 최대 시간
HTTP_CODE=$(curl -s -o /dev/null -w "%{http_code}" \
--max-time 10 \
--connect-timeout 3 \
http://localhost/health)
if [ "$HTTP_CODE" != "200" ]; then
echo "[WARN] 헬스체크 실패: HTTP $HTTP_CODE"
fi
재시도 정책 표준:
# 일시적 장애와 지속적 장애를 구분하는 재시도 패턴
MAX_RETRY=3
RETRY_INTERVAL=5
for i in $(seq 1 $MAX_RETRY); do
if curl -sf --max-time 5 http://localhost/health > /dev/null; then
exit 0 # 성공
fi
echo "[WARN] 시도 $i/$MAX_RETRY 실패"
sleep $RETRY_INTERVAL
done
# MAX_RETRY 모두 실패 시에만 장애로 판단
echo "[ERROR] 헬스체크 ${MAX_RETRY}회 모두 실패 — 서비스 이상"
정리
이 챕터에서 배운 핵심 패턴을 요약합니다.
| 목적 | 도구 | 핵심 옵션 |
|---|---|---|
| 서비스 상태 확인 | systemctl is-active | --quiet |
| HTTP 응답 코드 확인 | curl | -s -o /dev/null -w "%{http_code}" |
| TCP 포트 확인 | nc 또는 /dev/tcp | -z -w 3 |
| 디스크 사용률 | df | awk | -h -x tmpfs |
| 메모리 사용률 | free | awk | -m |
| 타임아웃 설정 | timeout | timeout 10 <명령어> |
| Slack 알림 | curl | -X POST -H "Content-Type: application/json" |
| 중복 실행 방지 | 잠금 파일 + trap | trap 'rm -f "$LOCK"' EXIT |
기억해야 할 원칙 세 가지:
- 멱등성 — 몇 번을 실행해도 부작용이 없어야 합니다
- 절대경로 — cron 환경에서는 모든 명령어를 절대경로로 사용합니다
- 재시작 루프 방지 — 시간 기반 카운터로 무한 재시작을 차단합니다
명령어·단축키 빠른 참조
이 모듈의 헬스체크·자가복구 스크립트에서 실제로 쓴 감지·복구·스케줄링 명령을 실전 옵션과 함께 모았습니다. "예" 열의 조합을 스크립트에 그대로 넣어도 됩니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
systemctl is-active | 서비스 활성 여부 감지(멱등) | systemctl is-active --quiet nginx || systemctl restart nginx |
curl | HTTP 상태코드로 엔드포인트 헬스체크 | curl -s -o /dev/null -w "%{http_code}" --max-time 5 http://localhost/health |
nc | TCP 포트 개방 여부 확인 | nc -z -w 3 localhost 5432 && echo open |
bash /dev/tcp | nc 없는 환경의 포트 체크(내장) | timeout 3 bash -c 'echo >/dev/tcp/localhost/6379' |
df | 디스크 사용률 임계값 감시 | df -h -x tmpfs / | awk 'NR==2{gsub(/%/,"",$5);print $5}' |
free | 메모리 사용률 계산 | free -m | awk '/^Mem:/{printf "%.0f%%",($2-$7)/$2*100}' |
timeout | 명령 hang 방지(실행 시간 상한) | timeout 10 curl -s http://localhost/health → 초과 시 종료코드 124 |
flock | 스크립트 중복 실행 방지(락) | exec 200>/var/lock/hc.lock; flock -n 200 || exit 0 |
crontab | 헬스체크 주기 실행 등록 | crontab -e → */5 * * * * /opt/healthcheck/check.sh |
journalctl | cron·서비스 로그 확인 | journalctl -u cron --since "1 hour ago" |
trap | 종료 시 락·임시파일 정리 | trap 'rm -f "$LOCK_FILE"' EXIT |
ss | 리스닝 포트 직접 확인 | ss -tlnp | grep ':80 ' |
watch | 대시보드 주기 갱신 | watch -n 5 /opt/healthcheck/dashboard.sh |
관련 모듈로 더 깊이:
- 백엔드 개발자를 위한 실전 Bash 쉘 스크립트 핵심 가이드 — 헬스체크 스크립트를 구성하는 조건문·함수·종료 코드의 기본기
- cron으로 리눅스 주기적 반복 작업(배치) 예약 및 백업 자동화 — 작성한 헬스체크를 주기적으로 안정 실행시키는 스케줄링
- vmstat, iostat, sar로 CPU/디스크 IO 성능 병목 진단 — 단발 체크를 넘어 지표를 지속 수집·관측하는 모니터링으로 확장
다음 모듈에서는 systemd timer를 활용해 cron보다 정밀한 스케줄링과, 실패 시 자동 알림이 내장된 모니터링 유닛을 작성하는 방법을 다룹니다.