디스크가 90%를 넘었다는 알람을 어제 받았는데, 실제로 100%에 도달해 서비스가 장애를 일으킨 건 오늘 새벽이었습니다. 알람은 받았지만 추이를 보지 못했고, 언제 가득 찰지 예측하지 못했습니다. top이나 df를 수동으로 실행하는 것만으로는 "지난 주에 메모리가 왜 급증했는지"를 알 방법이 없습니다. 시계열 데이터를 수집하고 임계값을 초과하면 즉시 알림을 보내는 시스템이 있었다면, 새벽 장애 전에 조치할 수 있었을 겁니다.
Prometheus & Node Exporter 연동
리눅스 서버를 운영하다 보면 반드시 마주치는 질문이 있습니다. "지금 서버가 얼마나 바쁜가?" "디스크가 언제 꽉 찰까?" "어젯밤에 메모리가 왜 급증했지?" 이 질문들에 답하려면 단순히 top 이나 df 를 실행하는 것만으로는 부족합니다. 시간에 따른 추이를 기록하고, 임계값을 초과하면 알람을 보내는 모니터링 시스템이 필요합니다.
이 챕터에서는 현재 가장 널리 쓰이는 오픈소스 모니터링 스택인 Prometheus + Node Exporter + Grafana 를 직접 설치하고 연동합니다. 단순히 따라 치는 것을 넘어, 왜 이 구조가 만들어졌는지, 현업에서 어떻게 활용되는지까지 이해하는 것이 목표입니다.
- 1Pull vs Push 수집 방식을 비교하고 Prometheus가 Pull을 선택한 이유를 설명할 수 있다
- 2Prometheus·Node Exporter·Grafana를 설치하고 systemd 서비스로 등록할 수 있다
- 3prometheus.yml scrape_configs를 설정하고 타겟 상태를 확인할 수 있다
- 4PromQL 기초(rate()·histogram_quantile()·레이블 필터링)를 작성할 수 있다
- 5Alertmanager를 연동해 Slack·이메일 알림을 라우팅할 수 있다
wget https://github.com/prometheus/prometheus/releases/latest/download/prometheus-*.linux-amd64.tar.gzwget https://github.com/prometheus/node_exporter/releases/latest/download/node_exporter-*.linux-amd64.tar.gzsudo apt install -y grafanaPrometheus :9090, Node Exporter :9100, Grafana :3000 — 방화벽에서 허용 필요
1. Pull 방식과 Push 방식 — 왜 Prometheus는 "가져오는" 방식을 선택했나
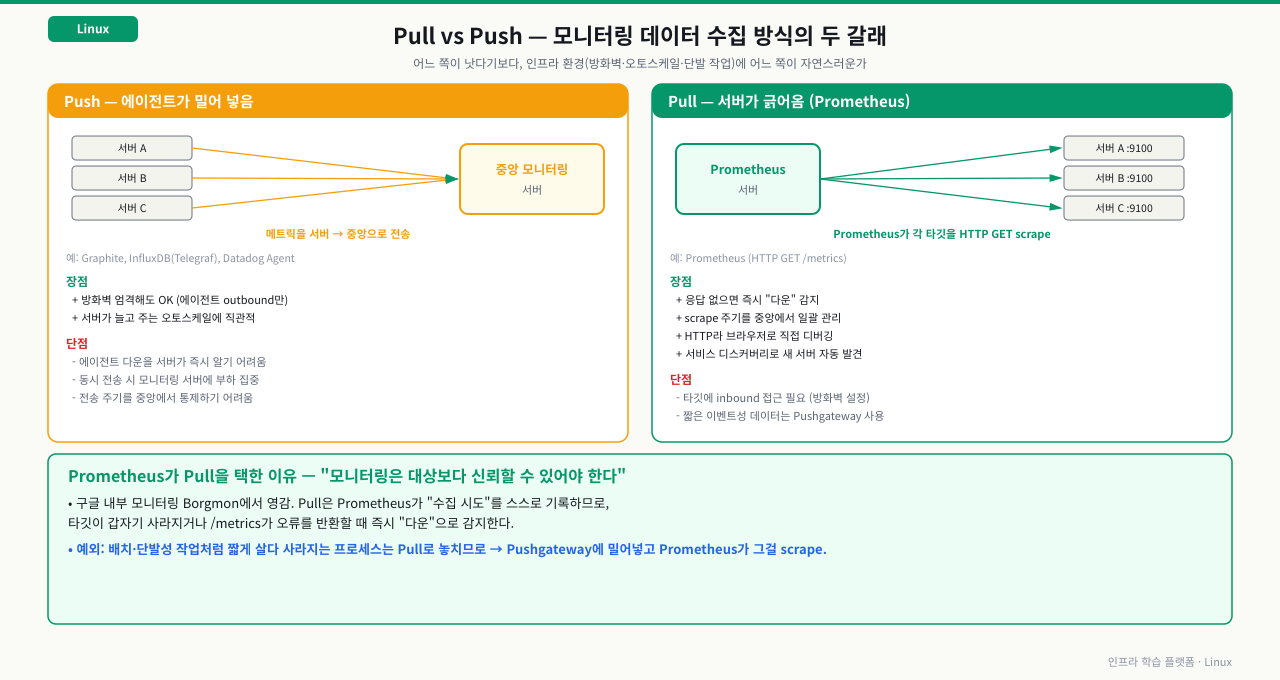
Pull vs Push: 모니터링 데이터 수집 방식의 두 갈래
Prometheus를 쓰다 보면 "왜 Prometheus는 서버가 데이터를 보내는 게 아니라 직접 긁어오는 방식인가?"라는 질문이 생깁니다. 반대로 Datadog이나 AWS CloudWatch는 에이전트가 메트릭을 보내는 Push 방식입니다. 어떤 방식이 더 낫다기보다는, 각 방식이 어떤 인프라 환경에서 더 자연스럽게 맞는지가 다릅니다. 동적으로 서버가 생기고 사라지는 클라우드 환경, 방화벽이 엄격한 온프레미스 환경, 배치 작업처럼 단발성으로 실행되는 작업 — 이런 상황에서 Pull과 Push 중 어느 쪽이 더 맞는지 이해하면 Prometheus가 어떤 문제를 풀기 위해 설계됐는지 보입니다.
 확대
확대
모니터링 시스템이 메트릭 데이터를 수집하는 방식은 크게 두 가지로 나뉩니다.
Push 방식
애플리케이션이나 서버 에이전트가 모니터링 서버 쪽으로 데이터를 밀어 넣는 방식입니다. Graphite, InfluxDB(Telegraf), Datadog Agent 등이 이 방식을 사용합니다.
[서버 A] --메트릭 전송--> [중앙 모니터링 서버]
[서버 B] --메트릭 전송-->
[서버 C] --메트릭 전송-->
장점:
- 방화벽이 엄격한 환경에서도 동작 가능 (에이전트가 outbound 연결만 하면 됨)
- 서버가 일시적으로 증가하거나 감소하는 오토스케일링 환경에서 직관적
단점:
- 에이전트가 다운되어도 모니터링 서버는 "데이터가 안 온다"는 것을 즉시 알기 어려움
- 수많은 서버가 동시에 데이터를 밀어넣으면 모니터링 서버에 부하가 집중됨
- 전송 주기는 각 에이전트가 결정하므로 중앙에서 통제가 어려움
Pull 방식
모니터링 서버가 각 대상 서버에 주기적으로 접속해서 데이터를 긁어오는 방식입니다. Prometheus가 대표적입니다.
[Prometheus 서버] --HTTP GET /metrics--> [서버 A :9100]
--HTTP GET /metrics--> [서버 B :9100]
--HTTP GET /metrics--> [서버 C :9100]
장점:
- 대상 서버가 응답하지 않으면 즉시 "다운"으로 감지 가능
- 수집 주기(scrape interval)를 중앙에서 일괄 관리
- HTTP 엔드포인트만 열면 되므로 디버깅이 쉬움 (브라우저로 직접 확인 가능)
- 서비스 디스커버리와 결합하면 새로운 서버를 자동으로 발견해서 수집 시작
단점:
- Prometheus 서버가 각 타깃에 inbound로 접근 가능해야 함 (방화벽 설정 필요)
- 매우 짧은 간격의 이벤트성 데이터는 기본 Pull 방식으로 놓칠 수 있음 (이 경우 Pushgateway 사용)
Prometheus가 Pull을 선택한 이유
Prometheus는 구글의 내부 모니터링 시스템 Borgmon에서 영감을 받아 설계되었습니다. 구글의 경험에서 나온 핵심 철학은 "모니터링 시스템은 모니터링 대상보다 신뢰할 수 있어야 한다"는 것입니다. Pull 방식에서는 Prometheus 서버가 수집 시도를 기록하기 때문에, 타깃이 갑자기 사라지거나 메트릭 엔드포인트가 오류를 반환할 때 즉각적으로 알 수 있습니다.
2. Prometheus 아키텍처 전체 구조
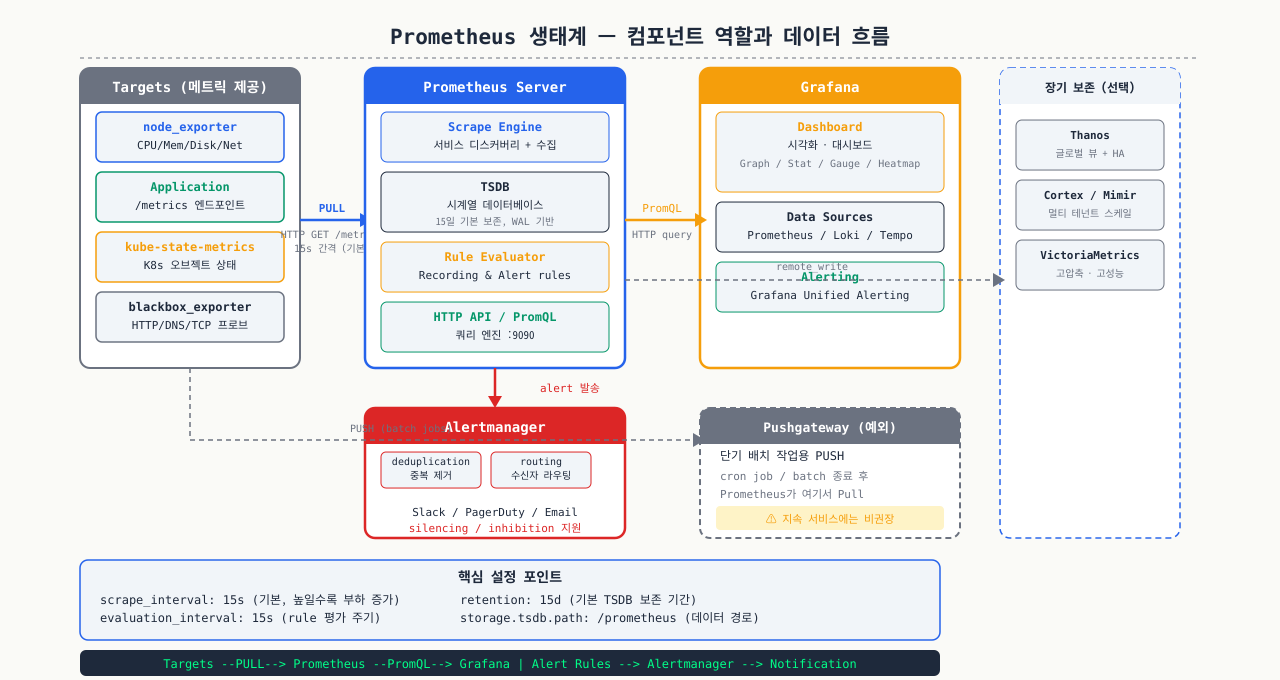
Prometheus 생태계: 각 컴포넌트의 역할과 데이터 흐름
 확대
확대
Prometheus를 처음 설치하면 prometheus 서버 하나에 node_exporter 하나가 전부처럼 보입니다. 그런데 실제 환경에서 설정 가이드를 따라 하면 Alertmanager, Pushgateway, Grafana, blackbox_exporter가 등장합니다. 어느 게 필수이고 어느 게 선택인지, 각각이 왜 분리된 컴포넌트인지 처음엔 파악이 어렵습니다. 메트릭 수집(Prometheus), 알림 라우팅(Alertmanager), 시각화(Grafana)를 분리한 이유는 각자 독립적으로 스케일하거나 교체할 수 있게 하기 위해서입니다. 전체 흐름을 먼저 보면 설정 파일 하나하나가 어디에 속하는지 이해가 됩니다.
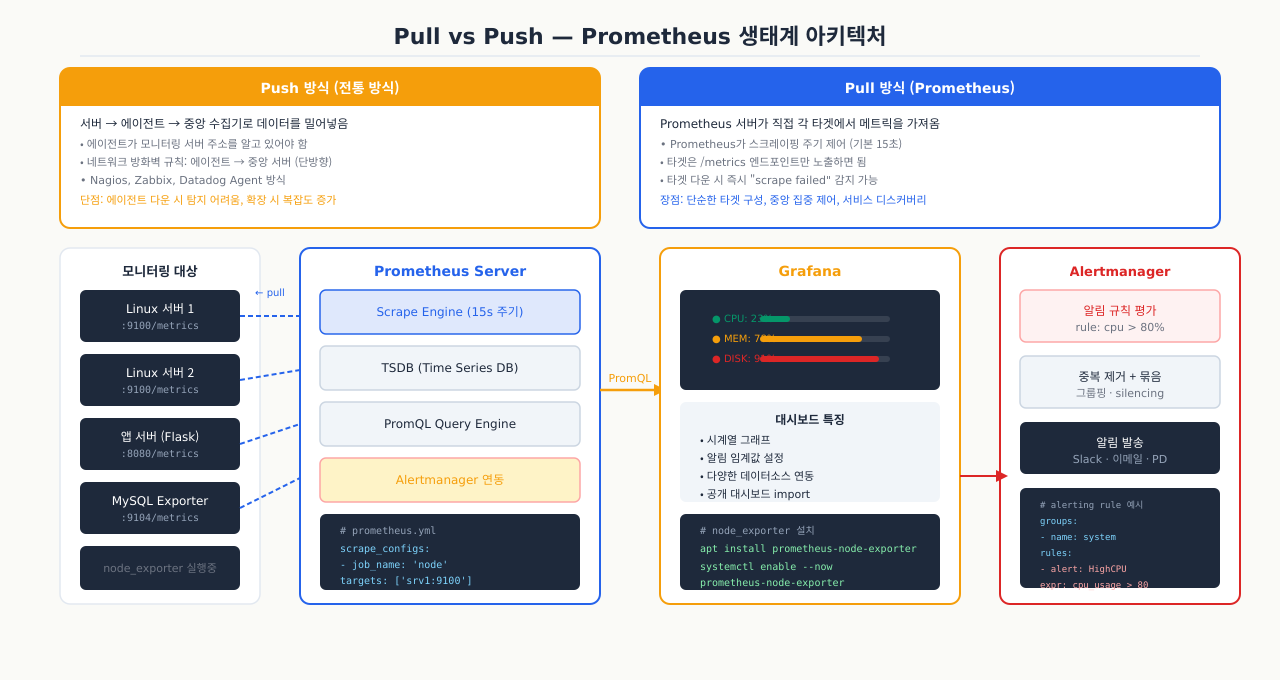
Prometheus는 단일 바이너리로도 동작하지만, 실제 운영 환경에서는 여러 컴포넌트가 함께 동작합니다.
 확대
확대
각 컴포넌트 설명
Prometheus Server
핵심 컴포넌트입니다. 내부적으로 세 부분으로 나뉩니다:
- Retrieval:
prometheus.yml에 정의된 타깃에 주기적으로 HTTP 요청을 보내 메트릭을 수집 - TSDB (Time Series Database): 수집된 메트릭을 타임스탬프와 함께 로컬 디스크에 효율적으로 저장. 기본 보관 기간은 15일
- HTTP API: Grafana나 CLI 도구가 PromQL 쿼리를 보내면 결과를 반환
Node Exporter
리눅스 시스템 메트릭을 HTTP 엔드포인트로 노출하는 에이전트입니다. CPU, 메모리, 디스크, 네트워크, 파일시스템 등 커널 수준의 정보를 /proc, /sys 에서 읽어 Prometheus가 이해하는 형식으로 변환합니다.
Alertmanager
Prometheus에서 발생한 알람을 받아서 중복 제거, 그룹핑, 라우팅을 거쳐 실제 알림(이메일, Slack, PagerDuty 등)을 전송합니다. Prometheus 자체는 알람 조건을 평가하고 발화(fire)만 하며, 실제 발송은 Alertmanager가 담당합니다.
Grafana
Prometheus를 데이터소스로 등록하고 PromQL 쿼리 결과를 그래프, 게이지, 테이블 등으로 시각화합니다. 커뮤니티에서 공유하는 대시보드를 ID 번호로 임포트할 수 있어서, 처음부터 대시보드를 만들 필요가 없습니다.
메트릭 타입
Prometheus는 네 가지 메트릭 타입을 지원합니다:
| 타입 | 설명 | 예시 |
|---|---|---|
| Counter | 단조 증가하는 누적 값 | 총 HTTP 요청 수, 총 바이트 전송량 |
| Gauge | 증가/감소 모두 가능한 현재 값 | 현재 메모리 사용량, 현재 연결 수 |
| Histogram | 버킷별 빈도 분포 | HTTP 응답시간 분포 |
| Summary | 분위수(percentile) 계산 | p50, p95, p99 응답시간 |
지표 한 개가 /proc에서 알림까지 가는 길 — 수집 파이프라인 5단계
앞에서 컴포넌트가 무엇인지(Pull 방식, 각 컴포넌트 역할)를 봤다면, 이제 하나의 숫자(예: CPU 사용률)가 그 컴포넌트들을 순서대로 통과하며 어떻게 알림이 되는지를 봅니다. /proc의 원시 카운터에서 출발해 어디를 거쳐 Slack 메시지가 되는지 전체 경로를 알면, "그래프가 왜 비지", "타깃이 왜 DOWN이지", "알림이 왜 안 오지"를 파이프라인의 특정 구간 문제로 좁힐 수 있습니다. 핵심은 Prometheus가 Pull이라, 각 단계의 성공·실패가 눈에 보이는 신호로 남는다는 점입니다.
[리눅스 커널] /proc, /sys (CPU·메모리·디스크 원시 카운터)
│
① node_exporter가 /proc·/sys를 읽어 Prometheus 텍스트 포맷으로 변환
│ → :9100/metrics 로 노출 (HTTP GET 하면 텍스트 반환)
│
② Prometheus가 scrape_interval(예: 15s)마다 /metrics 를 HTTP GET (Pull)
│ → 수집 성공이면 up=1, 실패면 up=0
│
③ 수집한 샘플을 타임스탬프와 함께 TSDB(로컬 디스크)에 시계열로 저장
│
④ evaluation_interval마다 PromQL 룰·알럿 조건을 평가
│
⑤ 조건이 참이면 알럿 발화(firing) → Alertmanager로 전송
▼
[Alertmanager] 그룹화·중복억제·라우팅 → Slack·이메일 발송
(Grafana는 ③의 TSDB를 PromQL로 조회해 대시보드에 표시)
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① exporter 노출 | node_exporter가 /proc·/sys를 읽어 node_cpu_seconds_total 같은 메트릭으로 변환해 :9100/metrics에 노출 | 프로세스 다운·포트 미기동 → 그 서버 지표가 통째로 사라짐 (curl localhost:9100/metrics로 확인) |
| ② scrape (Pull) | Prometheus가 scrape_interval마다 타깃의 /metrics를 HTTP GET | 방화벽이 9100 인바운드 차단·타깃 주소 오타 → /targets에서 DOWN, up==0 |
| ③ TSDB 저장 | 수집 샘플을 타임스탬프와 함께 로컬 디스크에 시계열로 저장 | 디스크 가득·재시작 중 WAL replay → 쿼리 결과가 잠시 비거나 지연 |
| ④ 룰 평가 | evaluation_interval마다 PromQL 룰·알럿 조건 계산 | 라벨이 매 스크랩마다 달라지면 시계열 폭발(카디널리티) → 메모리 급증·평가 지연 |
| ⑤ 알럿 발화 | 조건이 for 기간 동안 참이면 firing 상태로 Alertmanager에 전송 | Alertmanager 미연결·라우팅 오설정 → 그래프는 빨간데 Slack 알림은 안 옴 |
즉 "모니터링이 안 된다"는 이 다섯 구간 중 어디서 끊겼는지의 문제입니다. 진단은 항상 up 메트릭부터 봅니다 — up==0이면 ②(도달성: 포트·방화벽) 문제라 메트릭 쿼리를 아무리 고쳐도 소용없고, up==1인데 값이 이상하면 ①(exporter가 내놓는 원시값)이나 ④(PromQL·rate 구간)를 의심합니다. 대상이 중앙으로 밀어넣는 Push와 달리, Pull이라 ②의 성공/실패 자체가 up으로 남는 것이 이 파이프라인 진단의 결정적 단서입니다.
3. Node Exporter 설치 및 systemd 등록
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/linux/part6/exam_33/{prometheus,grafana,exporters}
cd /tmp/linux/part6/exam_33
# Prometheus 기본 설정
cat > prometheus/prometheus.yml << 'EOF'
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets: []
rule_files: []
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
- job_name: 'docker'
static_configs:
- targets: ['localhost:9323']
EOF
echo "설정 파일 생성 완료"
이제 실습을 진행합니다.
Node Exporter는 Go로 작성된 단일 바이너리입니다. 패키지 매니저를 사용하지 않고 바이너리를 직접 설치하는 방법을 익힙니다. 이 방식은 버전 관리와 업그레이드가 명확하다는 장점이 있습니다.
1단계: 전용 시스템 사용자 생성
보안 원칙상, 모니터링 에이전트는 루트 권한 없이 실행되어야 합니다. 로그인이 불가능한 시스템 계정을 생성합니다.
# --no-create-home: 홈 디렉토리 생성 안 함
# --shell /bin/false: 로그인 쉘 없음 (로그인 불가)
sudo useradd --no-create-home --shell /bin/false node_exporter
2단계: 최신 버전 확인 및 다운로드
# Prometheus 공식 GitHub에서 최신 버전 번호 확인
# 2024년 기준 최신 안정 버전: 1.8.2
NODE_EXPORTER_VERSION="1.8.2"
ARCH="linux-amd64" # ARM 서버라면 linux-arm64
# 공식 GitHub 릴리즈에서 다운로드
wget https://github.com/prometheus/node_exporter/releases/download/v${NODE_EXPORTER_VERSION}/node_exporter-${NODE_EXPORTER_VERSION}.${ARCH}.tar.gz
# 파일 무결성 확인 (sha256sum 파일도 함께 다운로드)
wget https://github.com/prometheus/node_exporter/releases/download/v${NODE_EXPORTER_VERSION}/sha256sums.txt
sha256sum --check --ignore-missing sha256sums.txt
출력에서 node_exporter-1.8.2.linux-amd64.tar.gz: OK 를 확인합니다. 무결성 확인 실패 시 다운로드를 다시 시도하세요.
3단계: 압축 해제 및 바이너리 배치
# 압축 해제
tar xzf node_exporter-${NODE_EXPORTER_VERSION}.${ARCH}.tar.gz
# 바이너리를 시스템 PATH로 이동
sudo mv node_exporter-${NODE_EXPORTER_VERSION}.${ARCH}/node_exporter /usr/local/bin/
# 소유권 변경: node_exporter 사용자만 실행 가능
sudo chown node_exporter:node_exporter /usr/local/bin/node_exporter
# 다운로드 파일 정리
rm -rf node_exporter-${NODE_EXPORTER_VERSION}.${ARCH}*
# 설치 확인
node_exporter --version
예상 출력:
node_exporter, version 1.8.2 (branch: HEAD, ...)
- 먼저 Prometheus UI /targets 에서 타겟 상태(UP/DOWN)를 확인하고, DOWN이면 curl -s http://<타겟IP>:9100/metrics 로 Prometheus 서버에서 직접 접근 가능 여부를 확인한다
- scrape_interval 기본값 15s 기준으로 /targets 에서 Last Scrape 시각이 30s 이상 경과하면 수집 지연 — 타겟 응답 지연 또는 Prometheus 서버 부하를 의심
- 타겟이 UP이고 node_exporter 프로세스도 실행 중인데 /targets 에서 DOWN이면 → 방화벽이 9100 포트 인바운드를 차단하고 있을 가능성 높음
- PromQL up{job="node"} 값이 1이고 rate(node_cpu_seconds_total[5m]) 조회가 정상이면 → 메트릭 수집 파이프라인 전체가 정상 작동 중임을 의미
Node Exporter 수동 메트릭 검증
프로메테우스 서버 설정 파일에 대상을 등록하기 전에, SRE는 에이전트가 표준 프로메테우스 규격 텍스트를 안전하게 내뿜고 있는지 포트 검증을 먼저 수행해야 합니다.
# Node Exporter 기본 포트인 9100번으로 메트릭 엔드포인트 수동 크롤링
$ curl -s http://localhost:9100/metrics | head -n 15
이 명령을 통해 주석 # HELP 및 # TYPE이 달린 텍스트 메트릭 원본이 정상 노출된다면 에이전트의 데이터 생성 엔진은 안전하게 무결 상태인 것입니다.
바이너리 설치만으로는 서버 재부팅 시 자동으로 시작되지 않습니다. systemd 서비스로 등록해야 합니다. systemd 서비스 작성 방법은 이전 챕터(linux/systemd-services)에서 이미 다뤘으므로 여기서는 모니터링 에이전트 특유의 설정에 집중합니다.
1단계: systemd 유닛 파일 작성
sudo tee /etc/systemd/system/node_exporter.service > /dev/null << 'EOF'
[Unit]
Description=Node Exporter - Prometheus 리눅스 시스템 메트릭 수집기
Documentation=https://prometheus.io/docs/guides/node-exporter/
After=network-online.target
Wants=network-online.target
[Service]
# 전용 사용자로 실행 (루트 권한 없음)
User=node_exporter
Group=node_exporter
Type=simple
# ExecStart: 실행할 바이너리와 옵션
# --collector.disable-defaults: 필요한 컬렉터만 활성화하려면 사용
# 기본 설정으로는 모든 컬렉터가 활성화됨
ExecStart=/usr/local/bin/node_exporter \
--web.listen-address=":9100" \
--collector.filesystem.mount-points-exclude='^/(sys|proc|dev|host|etc)($$|/)' \
--collector.netclass.ignored-devices='^(veth.*|docker.*|br-.*)$$'
# 서비스가 실패하면 5초 후 재시작
Restart=on-failure
RestartSec=5s
# 보안 강화: 파일시스템 쓰기 불가 (읽기 전용)
ProtectSystem=strict
# /proc, /sys 읽기 허용 (메트릭 수집에 필요)
ReadOnlyPaths=/proc /sys
# 메모리 제한 (선택 사항)
MemoryMax=128M
[Install]
WantedBy=multi-user.target
EOF
2단계: 서비스 활성화 및 시작
# systemd 데몬 리로드 (새 유닛 파일 인식)
sudo systemctl daemon-reload
# 부팅 시 자동 시작 활성화
sudo systemctl enable node_exporter
# 서비스 시작
sudo systemctl start node_exporter
# 상태 확인
sudo systemctl status node_exporter
정상 상태 출력 예시:
● node_exporter.service - Node Exporter - Prometheus 리눅스 시스템 메트릭 수집기
Loaded: loaded (/etc/systemd/system/node_exporter.service; enabled; ...)
Active: active (running) since Thu 2026-03-26 09:00:00 KST; 3s ago
Main PID: 12345 (node_exporter)
Tasks: 4 (limit: 4096)
Memory: 12.1M
Active: active (running) 을 확인합니다. failed 상태라면 journalctl -u node_exporter -n 50 으로 로그를 확인하세요.
3단계: 메트릭 엔드포인트 확인
# 로컬에서 메트릭 엔드포인트 접근
curl -s http://localhost:9100/metrics | head -50
출력 예시:
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 4.9351e-05
...
# HELP node_cpu_seconds_total Seconds the CPUs spent in each mode.
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="0",mode="idle"} 12345.67
node_cpu_seconds_total{cpu="0",mode="iowait"} 23.45
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 0.12
node_cpu_seconds_total{cpu="0",mode="softirq"} 45.67
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 234.56
node_cpu_seconds_total{cpu="0",mode="user"} 1234.56
수천 줄의 메트릭이 출력됩니다. grep 으로 원하는 메트릭만 필터링할 수 있습니다:
# 메모리 관련 메트릭만 확인
curl -s http://localhost:9100/metrics | grep "^node_memory"
# 현재 사용 가능한 메모리 (바이트)
curl -s http://localhost:9100/metrics | grep "node_memory_MemAvailable_bytes"
# 디스크 가용 공간
curl -s http://localhost:9100/metrics | grep "node_filesystem_avail_bytes"
4. Prometheus 서버 설치 및 설정
Prometheus 서버를 설치하고 방금 설치한 Node Exporter를 수집 대상으로 등록합니다.
1단계: Prometheus 다운로드 및 설치
PROMETHEUS_VERSION="2.51.0"
ARCH="linux-amd64"
# 전용 사용자 생성
sudo useradd --no-create-home --shell /bin/false prometheus
# 디렉토리 생성
sudo mkdir -p /etc/prometheus /var/lib/prometheus
# 다운로드
wget https://github.com/prometheus/prometheus/releases/download/v${PROMETHEUS_VERSION}/prometheus-${PROMETHEUS_VERSION}.${ARCH}.tar.gz
# 압축 해제
tar xzf prometheus-${PROMETHEUS_VERSION}.${ARCH}.tar.gz
cd prometheus-${PROMETHEUS_VERSION}.${ARCH}
# 바이너리 설치
sudo mv prometheus promtool /usr/local/bin/
# 기본 설정 파일 및 콘솔 파일 복사
sudo mv prometheus.yml /etc/prometheus/
sudo mv consoles/ console_libraries/ /etc/prometheus/
# 소유권 설정
sudo chown -R prometheus:prometheus /etc/prometheus /var/lib/prometheus
sudo chown prometheus:prometheus /usr/local/bin/prometheus /usr/local/bin/promtool
# 정리
cd .. && rm -rf prometheus-${PROMETHEUS_VERSION}.${ARCH}*
# 설치 확인
prometheus --version
2단계: prometheus.yml 스크래프 설정
이 파일이 Prometheus의 핵심 설정입니다. 어떤 대상에서, 얼마나 자주, 어떤 방식으로 메트릭을 수집할지 정의합니다.
sudo tee /etc/prometheus/prometheus.yml > /dev/null << 'EOF'
# 전역 설정: 모든 job에 적용되는 기본값
global:
# 기본 스크래프 주기: 15초마다 메트릭 수집
scrape_interval: 15s
# 알람 규칙 평가 주기
evaluation_interval: 15s
# 스크래프 타임아웃: 이 시간 내에 응답 없으면 실패 처리
scrape_timeout: 10s
# Alertmanager 연결 설정 (나중에 설치 후 활성화)
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# 알람 규칙 파일 경로
rule_files:
- "/etc/prometheus/rules/*.yml"
# 스크래프 설정: 어떤 대상에서 메트릭을 수집할지
scrape_configs:
# Prometheus 자체 메트릭 수집
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
# 라벨 추가: 이 job의 모든 메트릭에 environment="production" 라벨 추가
relabel_configs: []
# Node Exporter: 리눅스 시스템 메트릭
- job_name: "node_exporter"
# 이 job에만 적용되는 스크래프 주기 (전역 설정을 오버라이드)
scrape_interval: 10s
static_configs:
# 같은 서버의 Node Exporter
- targets: ["localhost:9100"]
# 이 타깃에만 적용되는 커스텀 라벨
labels:
instance: "web-server-01"
environment: "production"
datacenter: "seoul-dc1"
# 여러 서버를 모니터링할 경우 추가
# - targets: ["192.168.1.10:9100"]
# labels:
# instance: "db-server-01"
# environment: "production"
# 향후 추가 가능한 job 예시
# - job_name: "mysql_exporter"
# static_configs:
# - targets: ["localhost:9104"]
EOF
3단계: 설정 파일 문법 검증
설정 파일을 잘못 작성하면 Prometheus가 시작되지 않습니다. 시작 전에 반드시 검증합니다.
# promtool로 문법 검사
promtool check config /etc/prometheus/prometheus.yml
출력:
Checking /etc/prometheus/prometheus.yml
SUCCESS: /etc/prometheus/prometheus.yml is valid prometheus config file syntax
4단계: Prometheus systemd 서비스 등록
sudo tee /etc/systemd/system/prometheus.service > /dev/null << 'EOF'
[Unit]
Description=Prometheus - 오픈소스 시계열 모니터링 시스템
Documentation=https://prometheus.io/docs/introduction/overview/
After=network-online.target
Wants=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/var/lib/prometheus \
--storage.tsdb.retention.time=30d \
--web.listen-address=":9090" \
--web.enable-lifecycle \
--web.console.templates=/etc/prometheus/consoles \
--web.console.libraries=/etc/prometheus/console_libraries
# 설정 파일 변경 시 재시작 없이 리로드 가능 (--web.enable-lifecycle 필요)
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
RestartSec=5s
[Install]
WantedBy=multi-user.target
EOF
sudo systemctl daemon-reload
sudo systemctl enable prometheus
sudo systemctl start prometheus
sudo systemctl status prometheus
5단계: 웹 UI에서 타깃 확인
Prometheus 웹 UI에 접속해 Node Exporter가 정상적으로 수집되고 있는지 확인합니다.
# 웹 UI 접근 가능 여부 확인 (텍스트로)
curl -s http://localhost:9090/-/healthy
# 출력: Prometheus Server is Healthy.
# 현재 스크래프 대상 목록 확인 (JSON)
curl -s http://localhost:9090/api/v1/targets | python3 -m json.tool | grep -A5 '"health"'
브라우저에서 http://서버IP:9090 접속 → 상단 메뉴 Status → Targets 에서 node_exporter job이 UP 상태인지 확인합니다.
5. PromQL 기초 — 메트릭 조회 언어
PromQL(Prometheus Query Language)은 Prometheus에 저장된 시계열 데이터를 조회하고 연산하는 언어입니다. SQL과 다르게 시계열 데이터에 특화되어 있습니다.
CPU 사용률 계산
node_cpu_seconds_total 은 CPU가 각 모드(user, system, idle, iowait 등)에서 보낸 누적 시간(초)입니다. Counter 타입이므로 계속 증가합니다. 실제 CPU 사용률을 계산하려면 일정 기간의 변화율을 구해야 합니다.
# CPU별, 모드별 누적 시간 (raw counter)
node_cpu_seconds_total
# 5분간 변화율 (초당 증가량, 0~1 사이 값)
rate(node_cpu_seconds_total[5m])
# idle 모드를 제외한 모든 모드의 변화율 합계 → CPU 사용률
# 1 - (idle 비율) = 사용률
1 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m]))
# 퍼센트로 표현 (0~100)
100 * (1 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])))
Prometheus 웹 UI의 Graph 탭에서 위 쿼리를 입력하고 Execute를 클릭하면 시간 그래프를 볼 수 있습니다.
메모리 사용률 계산
node_memory_MemAvailable_bytes 는 현재 사용 가능한 메모리 크기(바이트)입니다. Gauge 타입이므로 직접 사용 가능합니다.
# 현재 사용 가능한 메모리 (바이트)
node_memory_MemAvailable_bytes
# 전체 메모리
node_memory_MemTotal_bytes
# 메모리 사용률 (%)
100 * (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes))
# 사용 중인 메모리 (GB 단위로 변환)
(node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / 1024 / 1024 / 1024
디스크 사용률 계산
# 파일시스템별 가용 공간 (바이트)
node_filesystem_avail_bytes
# 루트 파티션(/)의 가용 공간만 필터링
node_filesystem_avail_bytes{mountpoint="/"}
# 디스크 사용률 (%)
100 * (1 - (
node_filesystem_avail_bytes{fstype!~"tmpfs|fuse.lxcfs|overlay"}
/
node_filesystem_size_bytes{fstype!~"tmpfs|fuse.lxcfs|overlay"}
))
# 디스크 사용률 80% 초과인 파티션만 표시
(100 * (1 - (node_filesystem_avail_bytes / node_filesystem_size_bytes))) > 80
네트워크 트래픽
node_network_receive_bytes_total 은 네트워크 인터페이스별 수신 총 바이트 수입니다. Counter 타입이므로 rate() 를 사용합니다.
# 인터페이스별 수신 속도 (바이트/초)
rate(node_network_receive_bytes_total[5m])
# eth0 인터페이스만 (Mbps 단위)
rate(node_network_receive_bytes_total{device="eth0"}[5m]) * 8 / 1024 / 1024
# 송수신 합계
(
rate(node_network_receive_bytes_total{device!~"lo|veth.*|docker.*"}[5m])
+
rate(node_network_transmit_bytes_total{device!~"lo|veth.*|docker.*"}[5m])
)
유용한 PromQL 함수 요약
| 함수 | 용도 | 예시 |
|---|---|---|
rate(v[5m]) | Counter의 초당 평균 증가율 | CPU 사용률, 네트워크 속도 |
irate(v[5m]) | 가장 최근 두 샘플의 순간 변화율 | 급격한 스파이크 탐지 |
increase(v[1h]) | 지정 기간 동안의 총 증가량 | 1시간 동안의 요청 수 |
avg by (label) | 라벨로 그룹화해서 평균 | 서버별 CPU 평균 |
sum by (label) | 라벨로 그룹화해서 합계 | 전체 네트워크 합계 |
topk(5, v) | 상위 k개 값 | 가장 바쁜 5개 서버 |
predict_linear(v[1h], 3600*4) | 선형 예측 | 4시간 후 디스크 가용량 예측 |
6. 방화벽 포트 설정
Prometheus(9090)와 Node Exporter(9100) 포트는 외부에서 접근 가능해야 하지만, 보안상 신중하게 제어해야 합니다. 특히 Node Exporter의 /metrics 엔드포인트는 서버의 민감한 정보를 노출하므로 Prometheus 서버에서만 접근 가능하도록 제한하는 것이 바람직합니다.
시나리오 1: 단일 서버 (Prometheus와 Node Exporter가 같은 서버)
# 현재 방화벽 상태 확인
sudo firewall-cmd --state
sudo firewall-cmd --list-all
# Prometheus 웹 UI 포트 (관리자 IP에서만 접근 허용)
# 관리자 IP 대역이 10.0.0.0/24 라고 가정
sudo firewall-cmd --permanent --add-rich-rule='
rule family="ipv4"
source address="10.0.0.0/24"
port port="9090" protocol="tcp"
accept'
# Node Exporter는 localhost에서만 접근 (외부 차단)
# 기본적으로 firewalld는 외부 접근을 차단하므로, 로컬호스트 접근은 항상 허용됨
# 추가로 외부에서 9100 접근을 명시적으로 차단하려면:
sudo firewall-cmd --permanent --add-rich-rule='
rule family="ipv4"
source address="0.0.0.0/0"
port port="9100" protocol="tcp"
reject'
# 설정 적용
sudo firewall-cmd --reload
# 확인
sudo firewall-cmd --list-rich-rules
시나리오 2: 멀티 서버 (Prometheus 서버와 Node Exporter 서버가 분리)
# [Node Exporter 서버에서 실행]
# Prometheus 서버(192.168.1.5)에서만 9100 포트 접근 허용
sudo firewall-cmd --permanent --add-rich-rule='
rule family="ipv4"
source address="192.168.1.5/32"
port port="9100" protocol="tcp"
accept'
# 그 외 모든 소스에서 9100 접근 차단
sudo firewall-cmd --permanent --add-rich-rule='
rule family="ipv4"
source address="0.0.0.0/0"
port port="9100" protocol="tcp"
reject'
sudo firewall-cmd --reload
# [Prometheus 서버에서 실행]
# Grafana 서버(192.168.1.6)에서 9090 접근 허용
sudo firewall-cmd --permanent --add-rich-rule='
rule family="ipv4"
source address="192.168.1.6/32"
port port="9090" protocol="tcp"
accept'
sudo firewall-cmd --reload
방화벽 설정 테스트
# 허용된 IP에서 접근 테스트
curl -s http://192.168.1.5:9090/-/healthy
# 차단된 포트 접근 테스트 (타임아웃이나 Connection refused 반환해야 함)
# 다른 서버에서:
# curl --connect-timeout 3 http://192.168.1.10:9100/metrics
# curl: (28) Connection timed out after 3001 milliseconds
iptables 직접 사용하는 경우 (CentOS 6 이하 또는 firewalld 미사용 환경)
# Prometheus 접근 허용 (관리자 IP만)
sudo iptables -A INPUT -p tcp --dport 9090 -s 10.0.0.0/24 -j ACCEPT
sudo iptables -A INPUT -p tcp --dport 9090 -j DROP
# Node Exporter는 Prometheus 서버에서만
sudo iptables -A INPUT -p tcp --dport 9100 -s 192.168.1.5 -j ACCEPT
sudo iptables -A INPUT -p tcp --dport 9100 -j DROP
# 영구 저장
sudo service iptables save
7. Grafana 연동
Grafana는 Prometheus 데이터를 아름다운 대시보드로 시각화합니다. 커뮤니티에서 만든 대시보드를 ID만 입력하면 바로 사용할 수 있습니다.
1단계: Grafana 설치
# RHEL/CentOS 계열
sudo tee /etc/yum.repos.d/grafana.repo > /dev/null << 'EOF'
[grafana]
name=grafana
baseurl=https://rpm.grafana.com
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://rpm.grafana.com/gpg.key
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
EOF
sudo dnf install -y grafana
# Debian/Ubuntu 계열
# wget -q -O /usr/share/keyrings/grafana.key https://apt.grafana.com/gpg.key
# echo "deb [signed-by=/usr/share/keyrings/grafana.key] https://apt.grafana.com stable main" | \
# sudo tee /etc/apt/sources.list.d/grafana.list
# sudo apt-get update && sudo apt-get install -y grafana
# 서비스 시작
sudo systemctl daemon-reload
sudo systemctl enable grafana-server
sudo systemctl start grafana-server
sudo systemctl status grafana-server
Grafana는 기본적으로 3000 포트에서 실행됩니다. 방화벽에서 3000 포트를 허용해야 합니다:
sudo firewall-cmd --permanent --add-port=3000/tcp
sudo firewall-cmd --reload
2단계: 초기 접속 및 비밀번호 변경
브라우저에서 http://서버IP:3000 접속합니다.
- 기본 계정:
admin/admin - 첫 로그인 시 비밀번호 변경 요구 → 강력한 비밀번호로 변경
3단계: Prometheus 데이터소스 등록
CLI로 API를 통해 데이터소스를 등록할 수 있습니다 (자동화 시 유용):
# Grafana API로 데이터소스 등록
curl -s -X POST \
-H "Content-Type: application/json" \
-u admin:새비밀번호 \
http://localhost:3000/api/datasources \
-d '{
"name": "Prometheus",
"type": "prometheus",
"url": "http://localhost:9090",
"access": "proxy",
"isDefault": true,
"jsonData": {
"httpMethod": "POST",
"timeInterval": "15s"
}
}'
또는 UI에서: 왼쪽 메뉴 → Connections → Data sources → Add data source → Prometheus → URL에 http://localhost:9090 입력 → Save & test 클릭
"Data source connected and labels found." 메시지가 나오면 성공입니다.
4단계: Node Exporter Full 대시보드 임포트 (ID: 1860)
Grafana 커뮤니티에서 가장 인기 있는 Node Exporter 대시보드는 ID 1860 입니다. 이 대시보드 하나로 CPU, 메모리, 디스크, 네트워크, 시스템 부하 등을 한눈에 볼 수 있습니다.
# API로 대시보드 임포트
curl -s -X POST \
-H "Content-Type: application/json" \
-u admin:새비밀번호 \
http://localhost:3000/api/dashboards/import \
-d '{
"dashboardId": 1860,
"overwrite": true,
"inputs": [{
"name": "DS_PROMETHEUS",
"type": "datasource",
"pluginId": "prometheus",
"value": "Prometheus"
}],
"folderId": 0
}'
또는 UI에서: 왼쪽 메뉴 → Dashboards → Import → "Import via grafana.com" 에 1860 입력 → Load → Prometheus 데이터소스 선택 → Import
5단계: 대시보드 확인
임포트가 완료되면 "Node Exporter Full" 대시보드가 자동으로 열립니다. 상단에서 모니터링할 서버 인스턴스를 선택하면 실시간으로 그래프가 갱신됩니다.
주요 확인 항목:
- CPU Busy: CPU 전체 사용률 게이지
- RAM Used: 메모리 사용률
- Disk Space Used Basic: 파티션별 디스크 사용률
- Network Traffic Basic: 송수신 트래픽
8. 디스크 80% 알람 — Alertmanager 기초
모니터링의 핵심 가치는 "문제가 생기기 전에 알림을 받는 것"입니다. 디스크가 꽉 찼을 때 알람을 받으면 이미 늦습니다. 80% 시점에 알림을 받아 여유 있게 대응하는 것이 목표입니다.
1단계: Alertmanager 설치
ALERTMANAGER_VERSION="0.27.0"
ARCH="linux-amd64"
# 전용 사용자 생성
sudo useradd --no-create-home --shell /bin/false alertmanager
# 다운로드
wget https://github.com/prometheus/alertmanager/releases/download/v${ALERTMANAGER_VERSION}/alertmanager-${ALERTMANAGER_VERSION}.${ARCH}.tar.gz
tar xzf alertmanager-${ALERTMANAGER_VERSION}.${ARCH}.tar.gz
cd alertmanager-${ALERTMANAGER_VERSION}.${ARCH}
# 설치
sudo mv alertmanager amtool /usr/local/bin/
sudo mkdir -p /etc/alertmanager /var/lib/alertmanager
sudo mv alertmanager.yml /etc/alertmanager/
# 소유권
sudo chown -R alertmanager:alertmanager /etc/alertmanager /var/lib/alertmanager
sudo chown alertmanager:alertmanager /usr/local/bin/alertmanager /usr/local/bin/amtool
cd .. && rm -rf alertmanager-${ALERTMANAGER_VERSION}.${ARCH}*
2단계: Alertmanager 설정 (이메일 알림)
sudo tee /etc/alertmanager/alertmanager.yml > /dev/null << 'EOF'
global:
# SMTP 서버 설정 (Gmail 예시)
smtp_smarthost: 'smtp.gmail.com:587'
smtp_from: '모니터링계정@gmail.com'
smtp_auth_username: '모니터링계정@gmail.com'
smtp_auth_password: 'Gmail앱비밀번호'
smtp_require_tls: true
# 알람 라우팅 규칙
route:
# 기본 수신자
receiver: 'team-email'
# 같은 알람은 5분간 그룹핑 후 한 번에 전송
group_wait: 30s
group_interval: 5m
# 같은 알람이 반복될 경우 4시간마다 재전송
repeat_interval: 4h
# 심각도에 따른 라우팅 예시
routes:
- match:
severity: critical
receiver: 'team-pagerduty'
continue: true
# 수신자 정의
receivers:
- name: 'team-email'
email_configs:
- to: '담당자@회사.com'
subject: '[알람] {{ .GroupLabels.alertname }} - {{ .Status }}'
send_resolved: true # 알람 해소 시에도 이메일 전송
# PagerDuty (선택 사항)
# - name: 'team-pagerduty'
# pagerduty_configs:
# - routing_key: 'YOUR_PAGERDUTY_KEY'
EOF
3단계: 알람 규칙 파일 작성
# 규칙 파일 디렉토리 생성
sudo mkdir -p /etc/prometheus/rules
sudo chown prometheus:prometheus /etc/prometheus/rules
sudo tee /etc/prometheus/rules/node-alerts.yml > /dev/null << 'EOF'
groups:
- name: node_filesystem_alerts
# 이 그룹의 규칙은 1분마다 평가
interval: 1m
rules:
# 디스크 사용률 80% 경고
- alert: DiskSpaceWarning
# 조건: tmpfs, overlay 등 가상 파일시스템 제외하고
# 디스크 사용률이 80% 초과하면 발화
expr: |
(
100 * (1 - (
node_filesystem_avail_bytes{fstype!~"tmpfs|fuse.lxcfs|overlay|devtmpfs"}
/
node_filesystem_size_bytes{fstype!~"tmpfs|fuse.lxcfs|overlay|devtmpfs"}
))
) > 80
# for: 이 조건이 5분 동안 지속되어야 알람 발화 (일시적 스파이크 무시)
for: 5m
labels:
severity: warning
annotations:
summary: "디스크 공간 부족 경고 ({{ $labels.instance }})"
description: |
{{ $labels.instance }}의 {{ $labels.mountpoint }} 파티션
사용률이 {{ $value | printf "%.1f" }}% 입니다.
현재 남은 공간: {{ with query (printf "node_filesystem_avail_bytes{instance='%s',mountpoint='%s'}" $labels.instance $labels.mountpoint) }}{{ . | first | value | humanize1024 }}B{{ end }}
# 디스크 사용률 90% 위험
- alert: DiskSpaceCritical
expr: |
(
100 * (1 - (
node_filesystem_avail_bytes{fstype!~"tmpfs|fuse.lxcfs|overlay|devtmpfs"}
/
node_filesystem_size_bytes{fstype!~"tmpfs|fuse.lxcfs|overlay|devtmpfs"}
))
) > 90
for: 2m
labels:
severity: critical
annotations:
summary: "디스크 공간 위험 ({{ $labels.instance }})"
description: "{{ $labels.instance }}의 {{ $labels.mountpoint }} 파티션이 {{ $value | printf \"%.1f\" }}% 사용 중입니다. 즉시 조치 필요!"
# 4시간 후 디스크가 꽉 찰 것으로 예측될 경우
- alert: DiskSpaceRunningOut
expr: |
predict_linear(node_filesystem_avail_bytes{fstype!~"tmpfs|fuse.lxcfs|overlay|devtmpfs"}[1h], 4 * 3600) < 0
for: 30m
labels:
severity: warning
annotations:
summary: "디스크 공간 4시간 내 소진 예측 ({{ $labels.instance }})"
description: "{{ $labels.instance }}의 {{ $labels.mountpoint }} 파티션이 현재 추세로는 4시간 내에 꽉 찰 것으로 예측됩니다."
- name: node_memory_alerts
rules:
# 메모리 사용률 90% 이상
- alert: MemoryHigh
expr: |
100 * (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) > 90
for: 5m
labels:
severity: warning
annotations:
summary: "메모리 사용률 높음 ({{ $labels.instance }})"
description: "{{ $labels.instance }} 메모리 사용률 {{ $value | printf \"%.1f\" }}%"
- name: node_cpu_alerts
rules:
# CPU 사용률 95% 이상이 10분 지속
- alert: CPUHighUsage
expr: |
100 * (1 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m]))) > 95
for: 10m
labels:
severity: warning
annotations:
summary: "CPU 사용률 지속 높음 ({{ $labels.instance }})"
description: "{{ $labels.instance }} CPU 사용률 {{ $value | printf \"%.1f\" }}%가 10분 이상 지속되고 있습니다."
EOF
# 소유권 설정
sudo chown prometheus:prometheus /etc/prometheus/rules/node-alerts.yml
# 알람 규칙 파일 문법 검증
promtool check rules /etc/prometheus/rules/node-alerts.yml
4단계: prometheus.yml에 Alertmanager 연결 활성화
sudo tee /etc/prometheus/prometheus.yml > /dev/null << 'EOF'
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093 # Alertmanager 주소 활성화
rule_files:
- "/etc/prometheus/rules/*.yml"
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "node_exporter"
scrape_interval: 10s
static_configs:
- targets: ["localhost:9100"]
labels:
instance: "web-server-01"
environment: "production"
EOF
# 설정 검증
promtool check config /etc/prometheus/prometheus.yml
# Prometheus 설정 리로드 (재시작 없이)
curl -s -X POST http://localhost:9090/-/reload
echo "설정 리로드 완료"
5단계: Alertmanager 서비스 시작
sudo tee /etc/systemd/system/alertmanager.service > /dev/null << 'EOF'
[Unit]
Description=Alertmanager
After=network-online.target
[Service]
User=alertmanager
Group=alertmanager
Type=simple
ExecStart=/usr/local/bin/alertmanager \
--config.file=/etc/alertmanager/alertmanager.yml \
--storage.path=/var/lib/alertmanager \
--web.listen-address=":9093"
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
sudo systemctl daemon-reload
sudo systemctl enable alertmanager
sudo systemctl start alertmanager
# 알람 상태 확인
curl -s http://localhost:9093/api/v2/alerts | python3 -m json.tool
알람 테스트
실제 디스크를 채우지 않고 테스트하는 방법:
# amtool로 테스트 알람 발송
amtool alert add \
alertname="DiskSpaceWarning" \
instance="web-server-01" \
mountpoint="/" \
severity="warning" \
--annotation=summary="테스트 알람입니다" \
--alertmanager.url=http://localhost:9093
# 알람 목록 확인
amtool alert --alertmanager.url=http://localhost:9093
9. 문제 해결 가이드
Prometheus 웹 UI(Status → Targets)에서 node_exporter job이 DOWN 또는 UNKNOWN 상태로 표시되는 경우입니다.
증상:
node_exporter (1/1 up)
Endpoint: http://localhost:9100/metrics State: DOWN
Error: Get "http://localhost:9100/metrics": dial tcp 127.0.0.1:9100: connect: connection refused
원인 1: Node Exporter가 실행되지 않음
# 서비스 상태 확인
sudo systemctl status node_exporter
# 실행 중이 아니라면 시작
sudo systemctl start node_exporter
# 포트 리스닝 여부 확인
ss -tlnp | grep 9100
# 출력 예: LISTEN 0 128 0.0.0.0:9100 0.0.0.0:* users:(("node_exporter",pid=12345,...))
원인 2: 방화벽이 9100 포트를 차단
# 방화벽에서 로컬호스트 연결이 차단되는 경우는 드물지만 확인
sudo firewall-cmd --list-all
# 직접 curl 테스트
curl -v http://localhost:9100/metrics 2>&1 | head -20
# 방화벽 일시 중단 테스트 (테스트 후 반드시 재시작!)
sudo systemctl stop firewalld
curl http://localhost:9100/metrics | head -5
sudo systemctl start firewalld
원인 3: prometheus.yml 설정 오류
# 설정 파일 검증
promtool check config /etc/prometheus/prometheus.yml
# node_exporter job 설정 확인
grep -A10 "job_name.*node_exporter" /etc/prometheus/prometheus.yml
# Prometheus 로그 확인
journalctl -u prometheus -n 50 --no-pager
원인 4: 다른 서버의 Node Exporter를 수집하는 경우 네트워크 연결 문제
# Prometheus 서버에서 Node Exporter 서버로 연결 테스트
curl -v http://192.168.1.10:9100/metrics --connect-timeout 5
# 라우팅 확인
traceroute 192.168.1.10
# Node Exporter 서버의 방화벽에서 Prometheus 서버 IP 허용 여부 확인
# (Node Exporter 서버에서 실행)
sudo firewall-cmd --list-rich-rules
Prometheus 웹 UI나 Grafana에서 쿼리 결과가 빈 값, NaN, 또는 예상치 못한 값으로 나타나는 경우입니다.
증상 1: rate() 함수가 NaN 반환
rate(node_cpu_seconds_total{mode="idle"}[5m]) → NaN
원인: Counter가 리셋된 직후(서버 재부팅 등) 또는 수집 데이터가 부족할 때 발생합니다.
# rate()에 필요한 최소 샘플 수 = 2개
# [5m] 범위에 2개 이상의 샘플이 있어야 함
# scrape_interval이 15s라면 5분에 약 20개 샘플 → 정상
# 해결: 서비스 시작 후 최소 2 * scrape_interval 만큼 대기
# 현재 수집된 샘플 수 확인
curl -s "http://localhost:9090/api/v1/query?query=count_over_time(node_cpu_seconds_total[5m])" | \
python3 -m json.tool | grep '"value"'
증상 2: 라벨 필터가 동작하지 않음
# 예상: 루트 파티션만 반환
node_filesystem_avail_bytes{mountpoint="/"}
# 실제: 빈 결과
원인: 라벨 값이 예상과 다를 수 있습니다.
# 실제 라벨 값 확인
curl -s "http://localhost:9090/api/v1/label/mountpoint/values" | python3 -m json.tool
# 또는 라벨 없이 쿼리해서 실제 라벨 확인
curl -s "http://localhost:9090/api/v1/query?query=node_filesystem_avail_bytes" | \
python3 -m json.tool | grep '"mountpoint"' | sort -u
증상 3: Grafana 대시보드에서 데이터가 없음
# 1. 데이터소스 연결 확인 (Grafana UI: Configuration → Data sources → Test)
# 2. 시간 범위 확인 (우상단 시간 선택기가 "Last 5 minutes" 로 너무 짧게 설정된 경우)
# 3. 인스턴스 변수 확인 (대시보드 상단 드롭다운에서 올바른 인스턴스 선택)
# 직접 Prometheus에서 쿼리 테스트
curl -s "http://localhost:9090/api/v1/query?query=node_memory_MemAvailable_bytes" | \
python3 -m json.tool
일반적인 PromQL 디버깅 순서:
- 메트릭 이름 오타 확인:
curl -s http://localhost:9100/metrics | grep -i "memavail" - 라벨 값 정확성 확인: Prometheus UI → Graph →
metric_name입력 후 라벨 확인 - 시계열 데이터 존재 여부:
count(metric_name) > 0 - 범위 벡터 충분성:
rate()의[]범위가scrape_interval의 2배 이상인지 확인
Prometheus에서 알람이 발화(firing)되어 Alertmanager로 전달됐는데, 이메일이 도착하지 않는 경우입니다.
1단계: 알람이 Prometheus에서 정상 발화 중인지 확인
# Prometheus에서 현재 발화 중인 알람 목록
curl -s http://localhost:9090/api/v1/alerts | python3 -m json.tool | grep -A5 '"state"'
# 예상 출력:
# "state": "firing",
# "activeAt": "2026-03-26T09:00:00Z"
# 알람 규칙 평가 상태
curl -s http://localhost:9090/api/v1/rules | python3 -m json.tool | grep -A3 '"health"'
2단계: Alertmanager가 알람을 받았는지 확인
# Alertmanager에서 현재 알람 목록
curl -s http://localhost:9093/api/v2/alerts | python3 -m json.tool
# 빈 배열 []이 반환되면 Prometheus에서 Alertmanager로 전달이 안 된 것
# prometheus.yml의 alerting 섹션 확인
grep -A5 "alertmanagers" /etc/prometheus/prometheus.yml
3단계: Alertmanager 로그에서 SMTP 오류 확인
journalctl -u alertmanager -n 100 --no-pager | grep -i "error\|smtp\|email\|fail"
자주 보이는 오류:
| 오류 메시지 | 원인 | 해결 |
|---|---|---|
535 Authentication failed | Gmail 비밀번호 오류 | Gmail 앱 비밀번호 생성해서 사용 (2단계 인증 필요) |
connection refused on port 587 | SMTP 포트 막힘 | 서버의 outbound 25/587 포트 허용 여부 확인 |
tls: failed to verify certificate | TLS 인증서 문제 | smtp_require_tls: false 로 테스트 (프로덕션에서는 비권장) |
no route to host | DNS/네트워크 문제 | nslookup smtp.gmail.com 으로 DNS 확인 |
4단계: amtool 로 알람 발송 직접 테스트
# Alertmanager 설정 파일 문법 검증
amtool check-config /etc/alertmanager/alertmanager.yml
# 테스트 알람으로 이메일 발송 강제 시도
amtool alert add \
alertname="TestAlert" \
severity="critical" \
--annotation=summary="설정 테스트" \
--alertmanager.url=http://localhost:9093
# 잠시 후 알람 발송 여부 확인 (Alertmanager 로그)
journalctl -u alertmanager -f
5단계: Gmail 앱 비밀번호 생성 방법
일반 Gmail 비밀번호는 보안 정책상 거부됩니다. 앱 비밀번호를 사용해야 합니다:
- Google 계정 → 보안 → 2단계 인증 활성화
- 보안 → 앱 비밀번호 → "메일" + "Linux 컴퓨터" 선택
- 생성된 16자리 비밀번호를
smtp_auth_password에 입력
9-1. textfile Collector — 배치/스크립트 메트릭 노출
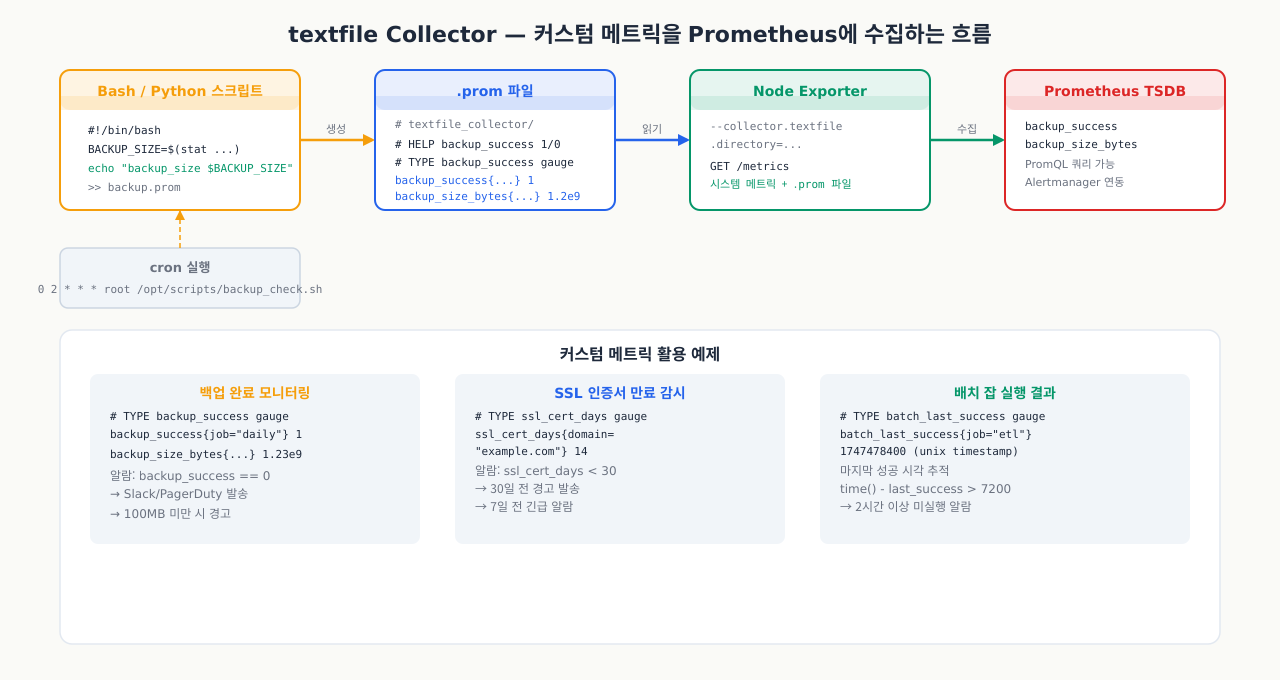
textfile Collector로 커스텀 메트릭 수집하기
 확대
확대
Prometheus로 서버 CPU·메모리·디스크는 잘 모니터링하고 있는데, 새벽 배치 잡이 실패했는지는 아침에 확인해보기 전까지 모릅니다. SSL 인증서가 7일 후 만료된다는 알림도 없어서 서비스 중단이 나기도 합니다. textfile collector를 쓰면 스크립트로 생성한 어떤 숫자든 Prometheus 메트릭으로 만들 수 있어서, 이런 커스텀 상태 지표를 기존 알림 체계에 통합할 수 있습니다.
Node Exporter는 시스템 메트릭만 수집합니다. 백업 완료 여부, 배치 잡 실행 결과, SSL 인증서 만료일 등 스크립트로 생성하는 커스텀 메트릭은 textfile collector를 활용합니다.
원리: Node Exporter가 지정 디렉토리(/var/lib/node_exporter/textfile_collector/)의 .prom 파일을 주기적으로 읽어 /metrics 엔드포인트에 포함시킵니다.
설정 방법:
# textfile collector 디렉토리 생성
sudo mkdir -p /var/lib/node_exporter/textfile_collector
sudo chown node_exporter:node_exporter /var/lib/node_exporter/textfile_collector
# Node Exporter 서비스 파일에 collector 옵션 추가
sudo systemctl edit node_exporter
# 아래 내용 추가:
# [Service]
# ExecStart=
# ExecStart=/usr/local/bin/node_exporter \
# --collector.textfile.directory=/var/lib/node_exporter/textfile_collector
sudo systemctl restart node_exporter
백업 완료 여부 메트릭 예제:
# /opt/scripts/backup_check.sh
#!/bin/bash
BACKUP_FILE="/backup/daily_$(date +%Y%m%d).tar.gz"
METRIC_FILE="/var/lib/node_exporter/textfile_collector/backup.prom"
if [ -f "$BACKUP_FILE" ]; then
BACKUP_SUCCESS=1
BACKUP_SIZE=$(stat -c%s "$BACKUP_FILE")
else
BACKUP_SUCCESS=0
BACKUP_SIZE=0
fi
cat > "$METRIC_FILE" << EOF
# HELP backup_success 오늘 백업 파일 존재 여부 (1=성공, 0=실패)
# TYPE backup_success gauge
backup_success{job="daily_backup"} ${BACKUP_SUCCESS}
# HELP backup_size_bytes 백업 파일 크기 (bytes)
# TYPE backup_size_bytes gauge
backup_size_bytes{job="daily_backup"} ${BACKUP_SIZE}
# HELP backup_last_run_timestamp 스크립트 마지막 실행 Unix 타임스탬프
# TYPE backup_last_run_timestamp gauge
backup_last_run_timestamp{job="daily_backup"} $(date +%s)
EOF
# cron에 등록 (매일 새벽 2시 실행)
echo "0 2 * * * root /opt/scripts/backup_check.sh" | sudo tee /etc/cron.d/backup-metrics
# 메트릭 확인
curl -s http://localhost:9100/metrics | grep backup_
# backup_success{job="daily_backup"} 1
# backup_size_bytes{job="daily_backup"} 1.23e+09
PromQL 활용 — Alertmanager 알람 연동:
# prometheus/rules/backup.yml
groups:
- name: backup_alerts
rules:
- alert: BackupFailed
expr: backup_success{job="daily_backup"} == 0
for: 1h
labels:
severity: critical
annotations:
summary: "오늘 백업이 생성되지 않았습니다"
description: "{{ $labels.job }} 백업 실패 — 즉시 확인 필요"
- alert: BackupTooSmall
expr: backup_size_bytes{job="daily_backup"} < 100 * 1024 * 1024
for: 30m
labels:
severity: warning
annotations:
summary: "백업 파일이 100MB 미만 — 데이터 누락 가능성"
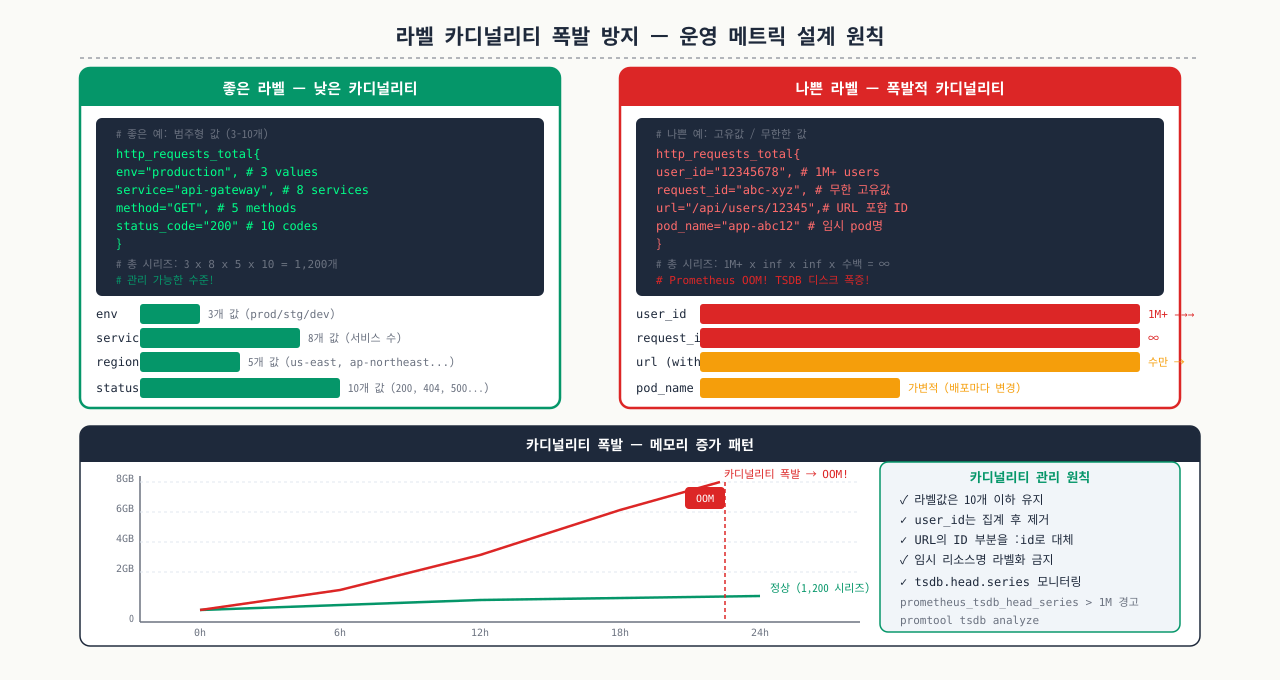
라벨 카디널리티 폭발 방지 — 운영 메트릭 설계 원칙
 확대
확대
Prometheus에서 가장 흔한 성능 문제는 라벨 카디널리티 폭발입니다. 라벨 조합 수가 기하급수적으로 늘어나면 메모리와 쿼리 속도에 직접 영향을 줍니다.
라벨로 삼으면 안 되는 값:
# 절대 안 됨 — 무한히 증가하는 값
user_id, session_id, request_id, timestamp, IP 주소
trace_id, UUID, 임의 문자열
# 예시: 이렇게 하면 시계열이 수백만 개 생성됨
http_requests_total{user_id="12345", path="/api/v1/users/12345"} ← 위험!
올바른 라벨 설계:
# 좋음 — 유한하고 예측 가능한 값
http_requests_total{method="GET", status="200", service="api"} ← 안전
http_requests_total{method="POST", status="500", service="payment"} ← 안전
# 경로 정규화 필수 (파라미터 제거)
# /api/v1/users/12345 → /api/v1/users/:id
# /api/v1/items/99 → /api/v1/items/:id
카디널리티 확인 명령:
# 현재 Prometheus 시계열 수 확인
curl -s http://localhost:9090/api/v1/query?query=prometheus_tsdb_head_series | \
python3 -c "import sys,json; d=json.load(sys.stdin); print('시계열 수:', d['data']['result'][0]['value'][1])"
# 메트릭별 라벨 조합 수 확인 (카디널리티가 높은 메트릭 탐지)
curl -s http://localhost:9090/api/v1/label/__name__/values | \
python3 -c "import sys,json; d=json.load(sys.stdin); print('메트릭 종류:', len(d['data']))"
Recording Rules로 비용 절감:
# prometheus/rules/recording.yml
groups:
- name: precomputed
interval: 1m
rules:
# 5분 평균 CPU 사용률을 미리 계산 (매번 계산 X)
- record: job:node_cpu_utilization:avg5m
expr: |
100 - (avg by (instance, job) (
rate(node_cpu_seconds_total{mode="idle"}[5m])
) * 100)
# HTTP 에러율 미리 계산
- record: job:http_error_rate:5m
expr: |
sum by (service) (rate(http_requests_total{status=~"5.."}[5m]))
/
sum by (service) (rate(http_requests_total[5m]))
기준: 시계열이 100만 개 이상이면 성능 저하 시작. 10만 개 이하를 목표로 설계하세요.
심화 — 추정값과 재시작, Prometheus 내부의 속사정
심화: rate()·increase()가 실제로 계산하는 값 — 외삽과 카운터 리셋 보정
이 트랙에서 rate()로 CPU 사용률을, increase()로 기간 요청 수를 구했습니다. 그런데 increase()가 딱 떨어지는 정수가 아니라 소수를 돌려줄 때 "버그인가?" 싶어집니다. 이 함수들이 내부에서 무엇을 하는지 알면, 그 값이 왜 관측이 아니라 추정인지, 언제는 믿을 수 없는지가 보입니다.
- 경계 외삽(extrapolation): rate·increase는 구간의 첫 샘플과 마지막 샘플을 단순히 빼지 않습니다. 스크랩이 15초 간격이면 [1h] 구간의 양 끝에 샘플이 정확히 걸리는 일은 거의 없습니다. 그래서 두 끝 샘플의 기울기를 구간의 정확한 경계(정확히 1시간 전과 현재)까지 늘려서(외삽) 추정합니다. 이 때문에 increase()는 정확한 횟수가 아니라 추정치이고, 그래서 소수가 나옵니다.
- 카운터 리셋 보정: Counter는 프로세스가 재시작하면 0으로 돌아갑니다. rate는 구간 안에서 값이 감소하면 리셋이 일어났다고 보고, 감소 직전 값을 더해 이어 붙입니다. 덕분에 재시작이 있어도 rate가 음수로 튀지 않습니다. 단, 한 번의 스크랩 간격 사이에 두 번 리셋되면(아주 짧게 두 번 재시작) 하나는 놓칠 수 있습니다.
- 최소 2 샘플 규칙의 근거: 외삽도 리셋 판정도 구간 안에 최소 2개의 샘플을 필요로 합니다. rate 구간을 scrape_interval의 4배 이상으로 잡으라는 규칙은 여기서 나옵니다 — 스크랩을 한두 번 놓쳐도 계산이 성립하도록 여유를 두는 것입니다.
- 평활화라는 한계: rate는 구간 평균이라 짧고 뾰족한 스파이크를 뭉갭니다. 잠깐 튄 순간을 잡아야 한다면 rate가 아니라 irate(마지막 두 샘플)나 max_over_time을 써야 합니다. 알림에 rate를 쓰는 이유(스파이크에 안 흔들림)가 이 경우엔 그대로 단점이 됩니다.
정리하면 rate·increase의 값은 관측이 아니라 추정입니다. 그래서 임계값 근처에서 결과가 경계를 오르내리면 알림이 깜빡일 수 있고, 이때 for: 지속 조건이 그 떨림을 걸러 주는 안전장치가 됩니다.
상황: prometheus.yml을 고치고 systemctl restart prometheus를 실행했습니다. 상태는 곧 active (running)으로 돌아왔는데, 그 뒤로도 몇 분 동안 Grafana 대시보드가 전부 비어 있고 웹 UI 쿼리도 응답이 없습니다. 그동안 메모리 사용량은 평소의 두세 배로 치솟습니다.
원인: Prometheus는 최근 약 2시간치 샘플을 메모리의 head block에 두고, 그 변경을 디스크의 WAL(Write-Ahead Log)에 함께 기록합니다. 재시작하면 저장된 WAL을 전부 다시 재생(replay)해 head block을 메모리로 복원하는데, 시계열이 많고 WAL이 크면 이 과정이 수 분 걸리고 그동안 메모리가 정점을 찍습니다. 즉 죽은 게 아니라 replay 중이라 아직 쿼리를 받을 준비가 안 된 상태입니다.
진단: journalctl -u prometheus에서 replaying WAL 로그와 완료까지 걸린 시간을 확인합니다. 그리고 살아있음을 뜻하는 /-/healthy와 서비스 준비를 뜻하는 /-/ready를 구분해서 봅니다 — replay 중에는 healthy는 200을, ready는 아직 준비 안 됨을 반환합니다. prometheus_tsdb_head_series로 시계열 규모를, WAL 디렉터리 크기(du -sh)로 replay 부담을 가늠합니다.
해결: 근본 원인은 시계열 수(카디널리티)라, 앞의 카디널리티 설계 원칙으로 head series를 줄이는 것이 정공법입니다. 당장 설정만 바꾸는 경우라면 재시작 대신 --web.enable-lifecycle을 켠 상태에서 kill -HUP(리로드)로 replay 자체를 피합니다. 그리고 replay 정점의 메모리를 감당하지 못하면 OOM으로 죽고 → 재시작 → 또 replay하는 악순환에 빠지므로, head series 규모에 맞게 메모리를 넉넉히 잡아 둡니다.
10. 현업 관점
언제 Prometheus를 선택하는가
현업에서 모니터링 솔루션을 선택할 때는 기술적 우수성만이 아니라 팀의 역량, 비용, 운영 복잡도를 함께 고려합니다.
Prometheus가 유리한 상황:
- 쿠버네티스 환경: Prometheus는 쿠버네티스 에코시스템의 사실상 표준입니다. kube-state-metrics, cadvisor 등 대부분의 쿠버네티스 컴포넌트가
/metrics엔드포인트를 기본 제공합니다. - 오픈소스 스택 선호: Datadog/New Relic 같은 SaaS의 비용이 부담될 때 (서버가 많아질수록 비용 차이가 극심해짐)
- 커스텀 메트릭이 많은 경우: 비즈니스 메트릭(주문 수, 결제 성공률 등)을 직접 노출해야 할 때 클라이언트 라이브러리가 풍부함
- 알람 로직이 복잡한 경우: PromQL의 표현력이 매우 강력함
다른 솔루션이 유리한 상황:
- 팀이 운영 도구에 시간을 쓰기 어려운 초기 스타트업: Datadog이나 CloudWatch처럼 관리형 서비스가 운영 부담을 줄여줌
- 장기 히스토리 분석이 중요한 경우: Prometheus는 기본 15-30일 보관. 장기 보관이 필요하면 Thanos나 Cortex 같은 원격 스토리지 솔루션을 추가해야 함
현업에서 자주 받는 질문들
"Prometheus는 HA(고가용성)를 어떻게 구성하나요?"
단일 Prometheus 서버는 SPOF(단일 장애점)가 됩니다. 현업에서는 두 가지 방법을 주로 사용합니다:
- 두 개의 독립 Prometheus 인스턴스가 동일한 타깃을 수집 (데이터 중복, 단순함)
- Thanos 또는 Cortex: 분산 장기 스토리지로 Prometheus를 확장
"메트릭이 너무 많아서 성능 문제가 생기는데요?"
recording rules 를 사용해 자주 사용하는 복잡한 쿼리를 미리 계산해서 저장합니다. Grafana 대시보드 로딩 속도가 크게 향상됩니다.
커리어에서의 활용
인프라/SRE 직군 면접에서 "Prometheus를 운영해봤나요?"라는 질문은 매우 흔합니다. 단순히 "설치해봤다"가 아니라:
- PromQL로 어떤 알람 규칙을 작성했는지
- 메트릭 카디널리티 문제를 어떻게 해결했는지
- 팀에 모니터링 문화를 어떻게 정착시켰는지
이런 경험을 구체적으로 이야기할 수 있으면 차별화됩니다. 이 챕터를 실제 서버에 구축하고 운영하면서 경험을 쌓으세요.
사건 배경
2023년 한 국내 스타트업에서 실제로 있었던 사례(익명화)입니다. 배치 서비스 서버에 Prometheus 모니터링이 없었고, 로그 파일이 순환(rotation) 설정 없이 계속 쌓이고 있었습니다.
장애 전개
09:00 배치 작업이 평소보다 2시간 늦게 완료됨 (원인 불명으로 넘어감)
11:30 개발자가 로그를 확인하려고 SSH 접속 → 명령어가 느림
12:00 서비스 에러율 급증, on-call 엔지니어 호출
12:05 원인 파악: /var 파티션 디스크 사용률 100%
12:10 /var/log 아래 오래된 로그 파일 삭제 → 서비스 정상화
근본 원인 분석:
- 로그 파일이 6개월간 rotation 없이 쌓임
- 디스크 사용률 모니터링 없음
- 배치 작업 완료 후 임시 파일도 정리되지 않음
사후 조치:
# 1. logrotate 설정 추가
sudo tee /etc/logrotate.d/app-service > /dev/null << 'EOF'
/var/log/app-service/*.log {
daily
rotate 30
compress
delaycompress
missingok
notifempty
sharedscripts
postrotate
systemctl reload app-service
endscript
}
EOF
# 2. Prometheus + Node Exporter 설치 (이 챕터의 내용)
# 3. 디스크 80% 알람 규칙 설정
# 4. Slack 채널에 알람 연동
이 챕터에서 배운 내용의 실무 가치
- DiskSpaceWarning (80%): 여유를 갖고 대응 가능 (업무 시간 내 처리)
- DiskSpaceCritical (90%): 긴급 대응 필요 (야간이라도 즉시)
- predict_linear 알람: 아직 임계값은 넘지 않았지만 추세가 위험한 경우 선제 대응
모니터링은 "문제를 찾는 도구"가 아니라 "문제가 생기기 전에 알려주는 도구"입니다. 이 차이가 야간 장애와 조용한 밤의 차이를 만듭니다.
체크리스트: 프로덕션 Prometheus 도입 전 확인 사항
- Node Exporter가 모든 서버에 설치되어 있는가
- 디스크 알람 임계값이 각 서버의 특성에 맞게 설정되어 있는가 (로그 서버는 더 빨리 경고)
- Alertmanager가 실제 담당자에게 알림을 전송하는가 (테스트 완료)
- Prometheus 데이터 보관 기간이 비즈니스 요구사항에 맞는가
- Prometheus 서버 자체에 대한 모니터링도 있는가 (메타 모니터링)
- Grafana 접근이 인증 없이 외부에 노출되지 않는가
- 운영 팀 모두가 기본 PromQL을 읽고 이해할 수 있는가
요약
이 챕터에서 다룬 내용을 정리합니다:
| 항목 | 핵심 내용 |
|---|---|
| Pull vs Push | Prometheus는 Pull 방식으로 대상 서버의 HTTP 엔드포인트를 직접 호출해 메트릭 수집 |
| 아키텍처 | Prometheus Server + Node Exporter + Alertmanager + Grafana 4개 컴포넌트 |
| Node Exporter | 바이너리 설치 → 전용 사용자 → systemd 등록 → :9100/metrics |
| prometheus.yml | scrape_configs 에 job과 타깃 정의, evaluation_interval 로 알람 평가 주기 설정 |
| 핵심 메트릭 | CPU: node_cpu_seconds_total + rate(), 메모리: node_memory_MemAvailable_bytes, 디스크: node_filesystem_avail_bytes, 네트워크: node_network_receive_bytes_total |
| 방화벽 | Prometheus(9090)는 관리자 대역에서만, Node Exporter(9100)는 Prometheus 서버에서만 접근 허용 |
| Grafana | 데이터소스 등록 후 대시보드 ID 1860 임포트로 즉시 시각화 |
| Alertmanager | rule_files 에 알람 규칙 정의, for 로 지속 시간 설정, 이메일/Slack으로 발송 |
다음 단계
- Pushgateway: 배치 작업처럼 단명하는 프로세스의 메트릭 수집
- ServiceMonitor (쿠버네티스): Prometheus Operator를 통한 자동 서비스 디스커버리
- Thanos: Prometheus 장기 스토리지 및 고가용성
- 카스텀 Exporter 작성: Go나 Python으로 비즈니스 메트릭 직접 노출
명령어·단축키 빠른 참조
이 모듈에서 다룬 Prometheus 운영 명령과 PromQL을 실전 옵션과 함께 모았습니다. "자주 쓰는 예" 열의 명령·쿼리를 그대로 써도 됩니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
promtool check config | prometheus.yml 문법 검증(시작 전 필수) | promtool check config /etc/prometheus/prometheus.yml |
promtool check rules | 알람 규칙 파일 문법 검증 | promtool check rules /etc/prometheus/rules/node-alerts.yml |
curl .../metrics | Node Exporter 메트릭 원본 확인 | curl -s http://localhost:9100/metrics | grep node_memory |
curl .../-/healthy | 살아있음(healthy)·준비(ready) 상태 확인 | curl -s http://localhost:9090/-/healthy (준비 여부는 /-/ready) |
curl -X POST .../-/reload | 재시작 없이 설정 리로드(WAL replay 회피) | curl -s -X POST http://localhost:9090/-/reload |
curl .../api/v1/targets | 스크랩 타깃 UP/DOWN 상태 조회 | curl -s http://localhost:9090/api/v1/targets | python3 -m json.tool |
journalctl -u | Prometheus·exporter 서비스 로그 확인 | journalctl -u prometheus -n 50 --no-pager (replaying WAL 확인) |
ss -tlnp | exporter 포트 리스닝 여부 확인 | ss -tlnp | grep 9100 |
amtool | Alertmanager 설정 검증·테스트 알람 발송 | amtool check-config /etc/alertmanager/alertmanager.yml |
up{job="..."} | 타깃 생사 확인(0=스크랩 실패) | up{job="node"} → 0이면 포트·방화벽부터 점검 |
rate(v[5m]) | Counter의 초당 평균 증가율(CPU·트래픽) | 100 * (1 - avg by (instance)(rate(node_cpu_seconds_total{mode="idle"}[5m]))) |
predict_linear() | 추세로 소진 시점 예측(디스크) | predict_linear(node_filesystem_avail_bytes[1h], 4*3600) < 0 |
node_memory_MemAvailable_bytes | 가용 메모리 Gauge(메모리 사용률 계산) | 100 * (1 - node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) |
topk(k, v) | 상위 k개 시계열 추출 | topk(5, rate(node_network_receive_bytes_total[5m])) |
관련 모듈로 더 깊이:
- vmstat, iostat, sar로 CPU/디스크 IO 성능 병목 진단 — Prometheus가 수집하는 메트릭의 원천인 vmstat/sar 진단법
- 주기적 서버 헬스체크와 장애 데몬 자동 재시작 스크립트 — 메트릭 임계값을 넘었을 때 자동 감지·복구하는 스크립트
- 리눅스 부팅 시 데몬 프로세스 자동 실행 및 관리 가이드 — Node Exporter를 systemd 서비스로 등록·운영하는 법
이것으로 Linux 트랙의 마지막 모듈입니다. 프로세스·권한·파일시스템·네트워크·서비스·로그·모니터링까지, 서버 한 대를 제대로 다루는 기본기를 갖췄습니다. 여러 서버를 코드로 일관되게 구성하는 자동화는 앞선 Ansible과 스크립트로 여러 대의 리눅스 서버 한 번에 구축하기 모듈에서 다뤘고, 이 운영 기반 위에서 컨테이너와 오케스트레이션으로 확장하는 것이 다음 여정입니다.