오전에 출근해 모니터링을 보니 서버 디스크가 98%입니다. df -h로 확인하니 /var/log가 40GB를 차지하고 있었습니다. nginx 액세스 로그 파일 하나가 30GB였습니다. 지난 6개월치 로그가 압축도 안 된 채 그대로 쌓여 있었던 겁니다. logrotate를 설정했다고 생각했는데, 커스텀 애플리케이션 로그는 설정에서 빠져 있었습니다. 로그는 사고 분석에 반드시 필요하지만, 관리되지 않으면 디스크를 갉아먹어 서비스 장애를 유발합니다.
로그 관리 & logrotate
운영 서버에서 가장 조용하게 장애를 유발하는 원인 중 하나는 디스크 풀(Disk Full) 입니다. 그리고 그 주범은 대부분 통제되지 않은 로그 파일입니다. 로그는 필수적이지만, 관리되지 않으면 수 GB를 순식간에 차지합니다. 이 챕터에서는 Linux 로그 시스템의 구조를 이해하고, logrotate와 journald 보존 정책을 통해 로그를 완전히 통제하는 방법을 배웁니다.
1. Linux 로그 체계 전체 그림
- 1rsyslog, journald, /var/log로 이어지는 Linux 로그 아키텍처와 흐름을 이해할 수 있다
- 2journalctl 핵심 옵션으로 서비스 로그를 조회·필터링할 수 있다
- 3logrotate 설정 파일 계층과 rotate/compress/delaycompress 디렉티브를 다룰 수 있다
- 4Node.js 등 애플리케이션별 커스텀 logrotate 설정을 작성할 수 있다
- 5logrotate -d/-f 옵션으로 설정을 테스트하고 강제 실행할 수 있다
- 6journald.conf 보존 정책(SystemMaxUse, MaxRetentionSec)을 구성할 수 있다
logrotate --version && ls /etc/logrotate.d/journalctl --disk-usage && systemctl status systemd-journalddu -sh /var/log/* 2>/dev/null | sort -rh | head -15logrotate 설정 변경 및 journald.conf 수정은 root 권한이 필요합니다. 테스트는 반드시 -d(dry-run) 옵션으로 먼저 검증하세요.
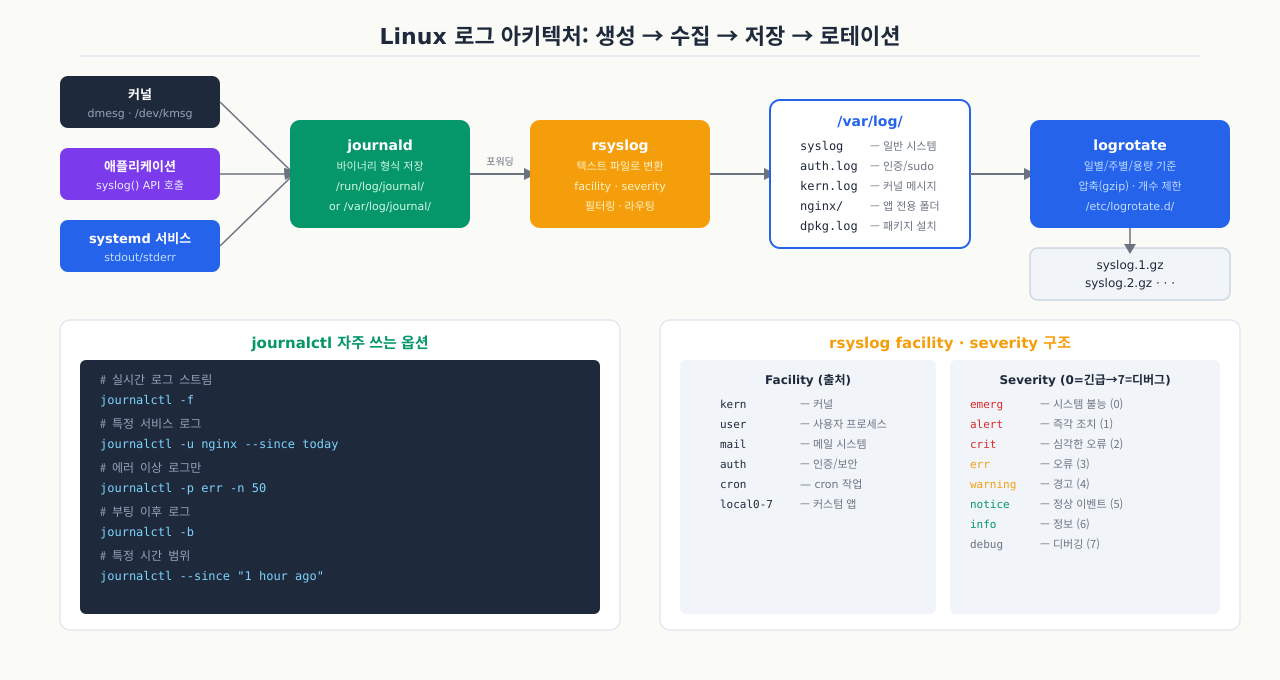
Linux 로그 아키텍처: rsyslog, journald, /var/log
 확대
확대
서비스 장애가 났을 때 journalctl -u nginx로 확인하면 로그가 나오는데, /var/log/nginx/error.log에서 찾으면 없는 경우가 있습니다. 반대로 /var/log/syslog에는 있는데 journalctl에는 없기도 합니다. 두 시스템이 따로 동작하고 있어서 어디를 봐야 하는지 혼란스럽습니다. 현대 Linux에는 systemd-journald와 rsyslog 두 개의 로그 시스템이 병렬로 돌고 있으며, 앱에 따라 둘 중 하나 또는 둘 다 로그를 씁니다. 어떤 서비스가 어디에 로그를 남기는지, 두 시스템의 관계가 어떻게 되는지를 알면 장애 때 찾는 시간을 크게 줄일 수 있습니다.
현대 Linux 배포판은 두 가지 로그 시스템이 병렬로 동작합니다.
 확대
확대
systemd-journald
- systemd 생태계의 기본 로그 수집기
- 모든 서비스의 stdout/stderr를 자동으로 캡처
- 바이너리 포맷으로 저장 — 구조화 필드, 빠른 검색, 변조 감지
journalctl명령으로 조회
rsyslog
- 전통적인 syslog 데몬. 텍스트 파일로
/var/log/에 저장 - journald와 소켓을 통해 연동하여 동일 로그를 텍스트로 변환 저장
- UDP/TCP 514 포트로 원격 로그 서버로 전송 가능
- RHEL/CentOS 계열에서 기본, Ubuntu는 rsyslog 또는 syslog 둘 다 지원
핵심 /var/log 디렉터리 구조 — 주요 로그 파일의 위치와 역할을 파악하는 것이 로그 관리의 시작입니다:
| 경로 | 역할 |
|---|---|
messages | RHEL 계열: 일반 시스템 메시지 (auth 제외) |
syslog | Debian/Ubuntu 계열: messages와 동일 역할 |
auth.log | Debian/Ubuntu: 인증 로그 (SSH, sudo, su) |
secure | RHEL 계열: 인증 로그 |
dmesg | 커널 링 버퍼 (부팅 시 하드웨어 감지 등) |
boot.log | 부팅 과정 서비스 시작/실패 기록 |
cron | cron 작업 실행 기록 |
kern.log | 커널 메시지만 별도 보관 (Debian 계열) |
maillog | 메일 서버 로그 (RHEL 계열) |
dpkg.log | 패키지 설치/제거 이력 (Debian 계열) |
yum.log / dnf.log | 패키지 이력 (RHEL 계열) |
nginx/ | Nginx access.log, error.log |
mysql/ · mariadb/ | DB 로그 |
journal/ | journald 바이너리 저널 (영구 보관 시) |
각 로그 파일이 중요한 이유 — 파일별 주요 용도와 현장에서 어떻게 활용하는지 정리했습니다:
| 파일 | 주요 용도 | 실무 활용 |
|---|---|---|
messages / syslog | 시스템 전반 이벤트 | 장애 첫 진단 시작점 |
secure / auth.log | SSH 로그인, sudo 명령 | 보안 감사, 침입 탐지 |
dmesg | 하드웨어 오류, OOM Killer | 디스크/메모리 장애 진단 |
cron | 배치 작업 실행 여부 | 배치 미실행 원인 파악 |
boot.log | 부팅 시 서비스 실패 | 부팅 불가 원인 추적 |
2. journalctl 심화 사용법
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/linux/part5/exam_24/logs && cd /tmp/linux/part5/exam_24
# 실습용 로그 파일 생성 (크기 있는 파일)
for i in $(seq 1 100); do
echo "$(date): INFO [app] Request processed id=$i status=200" >> /tmp/linux/part5/exam_24/logs/app.log
done
wc -l /tmp/linux/part5/exam_24/logs/app.log
이제 실습을 진행합니다.
기본 조회 — journalctl 기본 옵션으로 시스템 전체 로그를 조회합니다:
# 전체 저널 조회 (최신 항목이 마지막)
journalctl
# 최근 50줄만 보기 (-n 기본값은 10)
journalctl -n 50
# 실시간 스트리밍 (tail -f 와 동일)
journalctl -f
# 실시간 스트리밍 + 최근 20줄 먼저 표시
journalctl -fn 20
서비스별 필터링 (-u 옵션) — 특정 서비스의 로그만 골라서 확인합니다:
# 특정 서비스 로그만 보기
journalctl -u nginx.service
# 복수 서비스 동시 조회
journalctl -u nginx.service -u php-fpm.service
# 특정 서비스 실시간 모니터링
journalctl -fu sshd.service
우선순위 필터링 (-p 옵션) — err, warning, crit 등 심각도 기준으로 로그를 걸러냅니다:
# syslog 우선순위 레벨:
# 0=emerg, 1=alert, 2=crit, 3=err, 4=warning, 5=notice, 6=info, 7=debug
# warning 이상만 보기 (0~4 포함)
journalctl -p warning
# error 이상만 보기
journalctl -p err
# 특정 범위: info부터 warning까지
journalctl -p info..warning
시간 범위 필터링 (--since / --until) — 장애 발생 시각 전후 구간을 지정해 로그를 추적합니다:
# 오늘 자정부터 현재까지
journalctl --since today
# 어제 하루
journalctl --since yesterday --until today
# 특정 시간 범위
journalctl --since "2026-03-25 09:00:00" --until "2026-03-25 18:00:00"
# 30분 전부터 현재까지
journalctl --since "30 minutes ago"
# 특정 서비스 + 시간 범위 조합
journalctl -u postgresql.service --since "1 hour ago"
출력 포맷 옵션 — JSON, 짧은 형식 등 상황에 맞는 출력 형식을 선택합니다:
# JSON 포맷 출력 (로그 수집 파이프라인용)
journalctl -u myapp.service -o json-pretty
# 간결한 출력 (타임스탬프 + 메시지만)
journalctl -o short
# 카탈로그 메시지 포함 (설명 추가)
journalctl -x
# 현재 부팅 세션만 (-b 0 = 현재, -b -1 = 이전 부팅)
journalctl -b
journalctl -b -1
# 저널 디스크 사용량 확인
journalctl --disk-usage
실전 활용 패턴 — 현장에서 자주 쓰는 journalctl 조합 명령어 모음입니다:
# 최근 에러 빠르게 확인
journalctl -p err --since "1 hour ago" --no-pager
# 배포 직후 모니터링
journalctl -fu myapp.service
# 특정 PID 로그 추적
journalctl _PID=12345
# 커널 메시지만
journalctl -k
# grep과 조합
journalctl -u nginx.service | grep "502"
- 먼저 journalctl --disk-usage 로 저널 크기를 확인하고, 그 다음 ls -lh /var/log/nginx/*.gz 로 로테이션된 .gz 파일이 생성됐는지 확인한다
- 저널 용량이 500MB 이상이면 vacuum 고려 필요 — journalctl --vacuum-size=200M 으로 즉시 축소 가능
- logrotate -d /etc/logrotate.d/nginx 드라이런에서 오류 없이 'rotating' 메시지가 나오고, 실제 실행 후 nginx.log.1 파일이 생성되어야 정상
- journalctl -p err -b 결과가 있고 동시에 logrotate 로그에 오류가 있으면 → 로그 파일 권한(chown) 또는 로테이션 주기 설정 오류를 먼저 점검
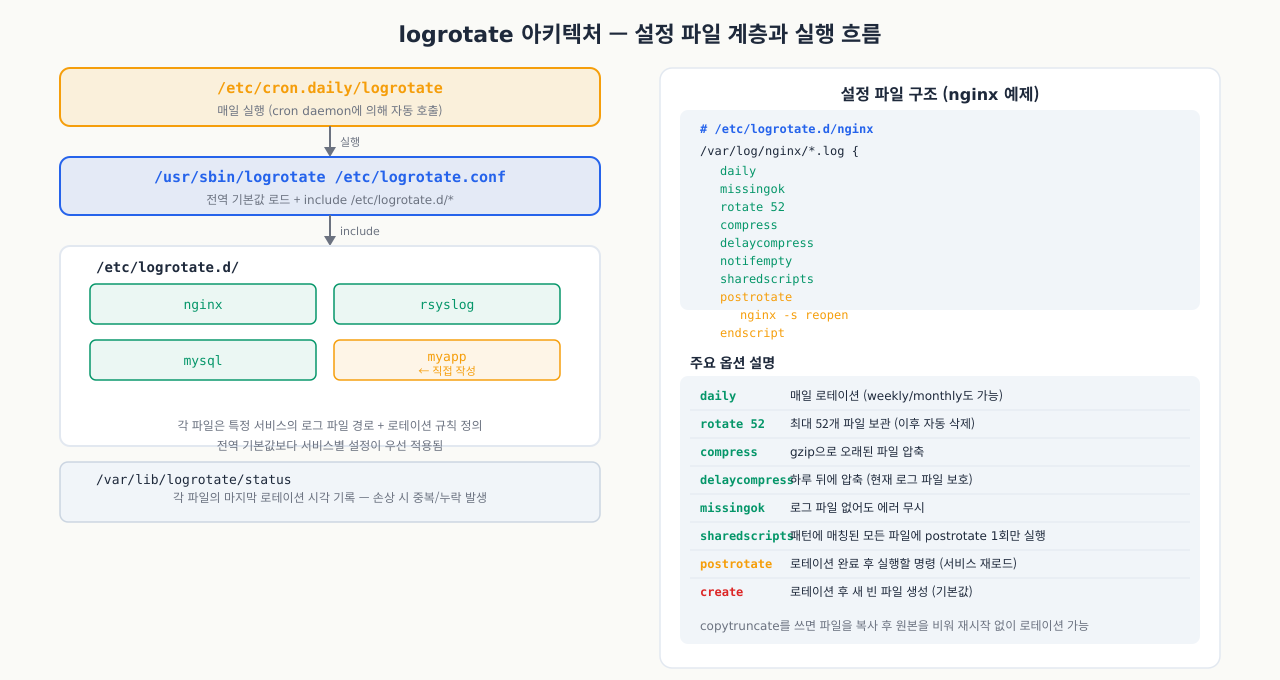
3. logrotate 설정 파일 구조
logrotate 아키텍처와 설정 파일 계층
 확대
확대
Nginx 로그가 단일 파일에 6개월치가 쌓여 있어서 vi /var/log/nginx/access.log를 열면 10GB짜리 파일이 뜹니다. > access.log로 비워버리면 Nginx가 새 파일을 인식하지 못하고 계속 삭제된 inode에 씁니다. 올바른 방법은 logrotate가 주기적으로 파일을 잘라내고 서비스에게 "새 파일로 다시 써라" 신호를 보내는 것입니다. 그런데 logrotate를 설정해도 작동이 안 된다면 설정 파일이 어디에 있는지, 어떤 계층 구조로 읽히는지 모르는 경우가 많습니다.
logrotate는 cron에 의해 주기적으로 실행되어 로그 파일을 회전(rotate)시키는 도구입니다.
실행 방식 — logrotate는 cron이 자동 호출하거나 수동으로 직접 실행할 수 있습니다:
/etc/cron.daily/logrotate가 /usr/sbin/logrotate /etc/logrotate.conf를 호출하고, 이는 다음을 처리합니다.
- 전역 기본값 읽기
include /etc/logrotate.d/*— 개별 설정 파일을 순서대로 적용nginx,rsyslog,mysql(패키지가 설치한 것)myapp← 직접 작성한 커스텀 앱 설정
메인 설정 파일: /etc/logrotate.conf — 시스템 전체 로테이션의 기본값을 정의합니다:
# /etc/logrotate.conf — 전역 기본값
# 기본 주기: 주 1회
weekly
# 4주치 보관
rotate 4
# 로테이션 후 새 빈 파일 생성
create
# 날짜를 파일명에 포함 (예: access.log.2026-03-25)
dateext
# gzip 압축
compress
# 개별 서비스 설정 포함
include /etc/logrotate.d
개별 서비스 설정: /etc/logrotate.d/ 디렉터리
각 파일은 하나 이상의 블록으로 구성됩니다:
파일_패턴 {
옵션1
옵션2
...
스크립트_블록
}
핵심 옵션 전체 참조 — logrotate 설정에서 자주 쓰는 옵션과 사용 예시입니다:
| 옵션 | 설명 | 예시 |
|---|---|---|
daily / weekly / monthly | 로테이션 주기 | daily |
rotate N | 보관할 오래된 파일 수 | rotate 7 |
size N | 지정 크기 초과 시 로테이션 | size 100M |
maxsize N | 주기 전이라도 크기 초과 시 로테이션 | maxsize 500M |
minsize N | 주기가 됐어도 이 크기 미만이면 건너뜀 | minsize 10M |
compress | gzip 압축 | compress |
delaycompress | 이번 로테이션 파일은 다음 번에 압축 | delaycompress |
copytruncate | 복사 후 원본 파일을 0바이트로 truncate | copytruncate |
nocopytruncate | copytruncate 비활성화 (기본값) | |
create MODE OWNER GROUP | 새 로그 파일 생성 시 권한 설정 | create 0640 www-data adm |
nocreate | 새 파일 생성 안 함 | |
missingok | 로그 파일 없어도 에러 무시 | missingok |
nomissingok | 없으면 에러 (기본값) | |
notifempty | 비어 있으면 로테이션 건너뜀 | notifempty |
ifempty | 비어 있어도 로테이션 (기본값) | |
sharedscripts | 여러 파일 매칭 시 스크립트를 한 번만 실행 | sharedscripts |
dateext | 파일명에 날짜 접미사 추가 | dateext |
dateformat | 날짜 형식 지정 | dateformat -%Y%m%d |
su USER GROUP | 다른 권한으로 실행 | su nginx nginx |
 확대
확대
logrotate가 한 번 도는 동안 실제로 일어나는 일 — 트리거부터 삭제까지 6단계
logrotate는 상주 데몬이 아니라 cron/timer가 하루 한 번 깨워야 도는 배치입니다. 그 한 번의 실행 안에서 "조건 확인 → 회전 → 새 파일 → 앱에 알림 → 삭제"가 순서대로 일어나는데, 이 흐름을 알아야 "설정했는데 왜 안 먹지", "회전됐는데 왜 앱이 옛 파일에 계속 쓰지"를 단계로 짚을 수 있습니다.
[cron.daily / systemd timer] 하루 1회 logrotate /etc/logrotate.conf 호출
│
① 트리거 → cron이 logrotate 실행 (logrotate 자체는 상주 데몬 아님)
│
② 조건 확인 → 로그별로 회전할 때인가? (daily 주기 · size/maxsize 임계)
│ status 파일(마지막 회전 시각)과 대조 → 조건 미달이면 건너뜀
│
③ 회전 → app.log → app.log.1 (rename) 또는 dateext로 app.log-YYYYMMDD
│ compress면 이전 회전본을 gzip (delaycompress면 한 사이클 미룸)
│
④ 새 파일 → create로 새 빈 app.log 생성 (지정 권한·소유자)
│
⑤ 앱에 알림 ┬ postrotate: 앱에 신호(USR1/HUP)·reload → 새 파일로 재오픈
│ └ copytruncate: 원본 복사 후 원본을 0바이트로 잘라 재사용
│
⑥ 오래된 것 삭제 → rotate N 초과분(app.log.N+1) 제거
▼
[새 app.log에 로그가 다시 쌓이기 시작]
각 단계가 하는 일과, 막히면 나타나는 증상:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① 트리거 | cron.daily·timer가 하루 한 번 logrotate 호출. 데몬이 아니라 배치라 실시간 아님 | cron·timer가 죽으면 회전이 아예 안 됨 → 로그 무한 증가. size만 걸어도 실행돼야 검사됨 |
| ② 조건 확인 | 로그별로 daily·size·maxsize를 status 파일과 대조해 회전 여부 결정 | 주기 미달·notifempty로 빈 파일 건너뜀. size 없이 daily만이면 폭증해도 다음 실행까지 대기 |
| ③ 회전 | app.log를 .1로 rename(또는 dateext) 후 compress로 이전 본 gzip | rename 방식은 앱 fd가 옛 inode를 계속 가리킴 → ⑤에서 신호가 없으면 로그 유실 |
| ④ 새 파일 생성 | create MODE OWNER로 빈 새 로그 파일을 만든다 | 권한·소유자가 틀리면 앱이 새 파일에 못 씀(Permission denied). su·create 지정 확인 |
| ⑤ 앱에 알림 | postrotate 신호(USR1·HUP)로 앱이 새 파일 재오픈 · 신호 없는 앱은 copytruncate | 신호 누락 → 앱이 rename된 옛 파일에 계속 씀(새 파일은 0). copytruncate는 복사~자르기 사이 유실 가능 |
| ⑥ 삭제 | rotate N 초과 회전본을 제거해 보존량 상한 유지 | rotate가 너무 크거나 compress 누락이면 디스크 초과. 회전본 크기×개수로 용량 추산 |
그래서 "logrotate를 설정했는데 안 먹는다"는 대개 두 계단에서 끊깁니다. 하나는 ①·② — logrotate는 상주 데몬이 아니라 cron/timer가 깨워야 도는 배치라, 타이머가 죽었거나 실행 자체가 안 되면 size 임계를 걸어도 검사되지 않아 파일이 계속 자랍니다(logrotate -d로 "왜 회전 안 하는지"를 먼저 봅니다). 다른 하나는 ⑤ — 파일을 rename해도 앱의 열린 fd는 옛 inode를 그대로 가리키므로, postrotate로 재오픈 신호(nginx는 USR1)를 보내지 않으면 회전된 빈 파일만 남고 앱은 사라진 파일에 계속 씁니다(디스크는 안 줄고 새 로그는 유실). 신호 수단이 없는 앱만 copytruncate로 우회하되 복사~자르기 창의 유실을 감수합니다. 요컨대 logrotate의 성패는 "제때 실행되는가(①②)"와 "회전 후 앱을 새 파일로 돌려세우는가(⑤)"에 달려 있고, 나머지(③④⑥)는 그 사이의 파일 조작·정리입니다.
4. 기본 logrotate 설정 파일 분석
실제 배포판에 설치된 설정을 읽으며 각 옵션의 의미를 파악합니다.
Nginx 기본 설정 (/etc/logrotate.d/nginx) — Nginx 로그를 매일 로테이션하고 compress로 공간을 절약합니다:
/var/log/nginx/*.log {
# 매일 로테이션
daily
# nginx 프로세스가 root가 아닐 때 권한 문제 방지
su root adm
# 파일 없어도 에러 무시 (서비스 시작 전 로그 없을 수 있음)
missingok
# 52주(약 1년)치 보관
rotate 52
# gzip 압축 활성화
compress
# 직전 로테이션 파일은 아직 압축하지 않음
# (rsyslog 등이 아직 읽을 수 있도록)
delaycompress
# 비어 있으면 건너뜀
notifempty
# 여러 *.log 파일이 있어도 postrotate 스크립트는 한 번만 실행
sharedscripts
postrotate
# nginx에게 로그 파일 재오픈 신호 전송
if [ -f /var/run/nginx.pid ]; then
kill -USR1 `cat /var/run/nginx.pid`
fi
endscript
}
MySQL 기본 설정 (/etc/logrotate.d/mysql-server) — MySQL slow 쿼리 로그도 logrotate로 관리합니다:
/var/log/mysql/mysql.log /var/log/mysql/mysql-slow.log /var/log/mysql/error.log {
# 매일
daily
# 7일치 보관
rotate 7
# 없어도 오류 무시
missingok
# 새 파일 생성 (660 권한, mysql 사용자)
create 660 mysql adm
compress
delaycompress
notifempty
sharedscripts
postrotate
# MySQL에 FLUSH LOGS 명령으로 파일 재오픈
test -x /usr/bin/mysqladmin && \
/usr/bin/mysqladmin --defaults-file=/etc/mysql/debian.cnf \
flush-logs 2>/dev/null || true
endscript
}
rsyslog 설정 확인 — rsyslog와 logrotate가 협력해 로그를 기록하고 정리하는 구조를 파악합니다:
# 현재 시스템의 logrotate 설정 목록
ls -la /etc/logrotate.d/
# 특정 설정 파일 내용 확인
cat /etc/logrotate.d/rsyslog
# logrotate 상태 파일 (마지막 실행 기록)
cat /var/lib/logrotate/logrotate.status
# 또는
cat /var/lib/logrotate.status
logrotate 상태 파일 예시 — /var/lib/logrotate/status에 마지막 로테이션 시각이 기록됩니다:
logrotate state -- version 2
"/var/log/nginx/access.log" 2026-3-25-6:0:0
"/var/log/nginx/error.log" 2026-3-25-6:0:0
"/var/log/syslog" 2026-3-25-6:0:1
"/var/log/auth.log" 2026-3-25-6:0:1
"/var/log/dpkg.log" 2026-3-25-6:0:1
5. 커스텀 앱 logrotate 설정 작성
/opt/myapp에 배포된 Node.js 애플리케이션이 /var/log/myapp/ 에 로그를 남기는 상황을 가정합니다.
애플리케이션 로그 구조 — 커스텀 앱 로그 경로와 권한 구조를 설정합니다:
/var/log/myapp/ 아래에 용도별 로그를 둡니다.
app.log— 일반 애플리케이션 로그error.log— 에러 전용access.log— HTTP 요청 로그
설정 파일 작성 — 앱 전용 logrotate 설정 파일을 /etc/logrotate.d에 추가합니다:
sudo tee /etc/logrotate.d/myapp << 'EOF'
/var/log/myapp/*.log {
# 매일 로테이션
daily
# 30일치 보관
rotate 30
# 압축
compress
# 직전 파일은 다음 번에 압축 (진행 중인 분석 툴이 읽을 수 있도록)
delaycompress
# 파일 없어도 무시
missingok
# 비어 있으면 건너뜀
notifempty
# 파일명에 날짜 추가: app.log-20260325.gz
dateext
dateformat -%Y%m%d
# 새 로그 파일을 640 권한으로 생성
create 0640 myapp myapp
# 여러 파일 있어도 스크립트는 한 번만 실행
sharedscripts
postrotate
# systemd 서비스에 SIGUSR1 신호 → 로그 파일 재오픈
/bin/systemctl kill -s USR1 myapp.service 2>/dev/null || true
endscript
}
EOF
파일 크기 기반 로테이션 (고트래픽 환경) — 날짜보다 파일 크기를 기준으로 로테이션해 디스크 초과를 방지합니다:
/var/log/myapp/access.log {
# 크기 기반: 100MB 초과 시 즉시 로테이션
size 100M
# 주기와 크기 병행: 주기가 됐어도 10MB 미만이면 건너뜀
# size 대신 아래 조합을 사용할 수도 있음
# daily
# minsize 10M
# maxsize 500M
# 90개 파일 보관 (size 기반이면 날짜 무관하게 개수 제한)
rotate 90
compress
delaycompress
missingok
notifempty
dateext
create 0640 myapp myapp
sharedscripts
postrotate
/bin/systemctl kill -s USR1 myapp.service 2>/dev/null || true
endscript
}
설정 검증 — 실제 로테이션 전에 설정 파일 오류를 검사합니다:
# 문법 오류 확인 (실제 실행하지 않음)
sudo logrotate -d /etc/logrotate.d/myapp
# 강제 실행 (날짜 조건 무시하고 즉시 로테이션)
sudo logrotate -f /etc/logrotate.d/myapp
# 결과 확인
ls -la /var/log/myapp/
6. logrotate 강제 실행 및 디버그
실제 운영 환경에서 logrotate 설정을 배포하기 전에 반드시 디버그 모드로 검증해야 합니다.
디버그 모드 (-d): 실제 실행 없이 시뮬레이션 — 실제로 실행되지 않고 어떤 동작을 할지 미리 보여줍니다:
# 특정 설정 파일 디버그
sudo logrotate -d /etc/logrotate.d/myapp
# 예상 출력:
# reading config file /etc/logrotate.d/myapp
# Allocating hash table for state file, size 64 entries
#
# Handling 1 logs
#
# rotating pattern: /var/log/myapp/*.log after 1 days (30 rotations)
# empty log files are not rotated, old logs are removed
# considering log /var/log/myapp/app.log
# log does not need rotating (log has been already rotated)
강제 실행 (-f): 날짜 조건 무시하고 즉시 로테이션 — 로테이션 조건이 충족되지 않아도 지금 당장 실행합니다:
# 특정 설정만 강제 실행
sudo logrotate -f /etc/logrotate.d/myapp
# 전체 설정 강제 실행
sudo logrotate -f /etc/logrotate.conf
# 상세 출력과 함께 강제 실행
sudo logrotate -vf /etc/logrotate.d/myapp
# 상세 출력 예:
# reading config file /etc/logrotate.d/myapp
# rotating log /var/log/myapp/app.log, log->rotateCount is 30
# dateext suffix '-20260325'
# glob pattern '-[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]'
# renaming /var/log/myapp/app.log.1 to /var/log/myapp/app.log.2 (rotatecount 1, logstart 1, i 1),
# old log /var/log/myapp/app.log.30 doesn't exist
# rotating log /var/log/myapp/app.log, log->rotateCount is 30
# renamed /var/log/myapp/app.log to /var/log/myapp/app.log-20260325
# running postrotate script
로테이션 결과 확인 — 로테이션 후 파일이 제대로 압축·보관됐는지 확인합니다:
# 로테이션 후 파일 목록
ls -lh /var/log/myapp/
# 예상 결과:
# -rw-r----- 1 myapp myapp 0 Mar 25 10:30 app.log ← 새 빈 파일
# -rw-r----- 1 myapp myapp 2.3M Mar 25 10:29 app.log-20260325 ← 로테이션된 파일
# -rw-r----- 1 myapp myapp 4.1M Mar 24 06:00 app.log-20260324.gz ← 압축된 파일
# 상태 파일에서 마지막 실행 시각 확인
grep myapp /var/lib/logrotate/logrotate.status
cron 설정 확인 — logrotate를 자동 실행하는 cron 스케줄을 확인합니다:
# logrotate가 cron.daily에 등록되어 있는지 확인
ls -la /etc/cron.daily/logrotate
# cron.daily 실행 시각 확인 (아나크론 설정)
cat /etc/anacrontab | grep daily
# 수동으로 cron.daily 전체 실행
sudo run-parts /etc/cron.daily
7. journald 보존 정책 설정
journald의 로그 보존 정책은 /etc/systemd/journald.conf에서 관리합니다.
기본 설정 파일 구조 — journald 전역 설정 파일(/etc/systemd/journald.conf)의 핵심 항목입니다:
# /etc/systemd/journald.conf
[Journal]
# 저장 위치: "persistent" = /var/log/journal/, "volatile" = /run/log/journal/
# "auto" = /var/log/journal/이 있으면 persistent, 없으면 volatile
Storage=auto
# 바이너리 압축 여부
Compress=yes
# 디스크 사용량 제한
SystemMaxUse=1G
# 최솟값 보장 (다른 항목이 SystemMaxUse를 넘어도 이 공간은 확보)
SystemKeepFree=100M
# 개별 저널 파일 최대 크기
SystemMaxFileSize=128M
# 최대 파일 개수
SystemMaxFiles=100
# 런타임(RAM) 저널 제한 (Storage=volatile 시)
RuntimeMaxUse=200M
RuntimeKeepFree=50M
# 보존 기간 (0 = 제한 없음)
MaxRetentionSec=3month
# 동기화 주기 (로그 유실 방지 vs 성능 tradeoff)
SyncIntervalSec=5m
# 속도 제한 (서비스당 초당 메시지 수)
RateLimitIntervalSec=30s
RateLimitBurst=10000
실전 권장 설정 (중소규모 서버) — 중소 규모 서버에서 저널 크기와 보존 기간을 실무 기준으로 설정합니다:
sudo tee /etc/systemd/journald.conf << 'EOF'
[Journal]
Storage=persistent
Compress=yes
# 전체 저널 최대 2GB
SystemMaxUse=2G
# 항상 500MB 여유 공간 유지
SystemKeepFree=500M
# 개별 파일 최대 256MB
SystemMaxFileSize=256M
# 3개월치 보관
MaxRetentionSec=3month
# 속도 제한 완화 (기본값이 너무 엄격한 경우)
RateLimitIntervalSec=30s
RateLimitBurst=10000
EOF
# 설정 적용 (journald 재시작)
sudo systemctl restart systemd-journald
# 적용 확인
journalctl --disk-usage
영구 저널 활성화 (재부팅 후에도 로그 유지) — /var/log/journal 디렉터리를 만들면 재부팅 후에도 저널이 유지됩니다:
# /var/log/journal/ 디렉터리 생성 (없으면 휘발성으로 동작)
sudo mkdir -p /var/log/journal
sudo systemd-tmpfiles --create --prefix /var/log/journal
# journald 재시작
sudo systemctl restart systemd-journald
# 확인
ls -la /var/log/journal/
journalctl -b -1 # 이전 부팅 로그가 보이면 영구 저널 활성화됨
저널 수동 정리 — 오래된 저널을 디스크에서 직접 삭제해 공간을 확보합니다:
# 디스크 사용량 확인
journalctl --disk-usage
# 2주 이상 된 로그 삭제
sudo journalctl --vacuum-time=2weeks
# 총 용량을 500MB로 축소
sudo journalctl --vacuum-size=500M
# 파일 수를 10개로 제한
sudo journalctl --vacuum-files=10
# 정리 후 확인
journalctl --disk-usage
8. 실무 트러블슈팅
증상 — 로테이션 후 서비스가 기존 파일 디스크립터를 그대로 사용해 로그가 유실되는 상황입니다:
# logrotate 실행 후 파일 확인
ls -la /var/log/myapp/
# -rw-r----- 1 myapp myapp 4.5M Mar 25 10:00 app.log ← 새 파일인데 계속 커짐?
# -rw-r----- 1 myapp myapp 0B Mar 25 06:00 app.log-20260325 ← 로테이션된 파일이 비어있음
# 어디에 쓰고 있는지 확인
sudo lsof /var/log/myapp/app.log-20260325
# myapp 1234 myapp 3w REG 8,1 4718592 ... /var/log/myapp/app.log-20260325
원인 분석:
Linux에서 파일 이름은 inode에 대한 포인터일 뿐입니다. 프로세스가 파일 디스크립터(fd)로 파일을 열면, 파일 이름이 바뀌어도 같은 inode를 계속 참조합니다. logrotate가 app.log를 app.log-20260325로 이름을 바꾸면, 데몬은 여전히 이름이 바뀐 파일(구 inode)에 계속 씁니다.
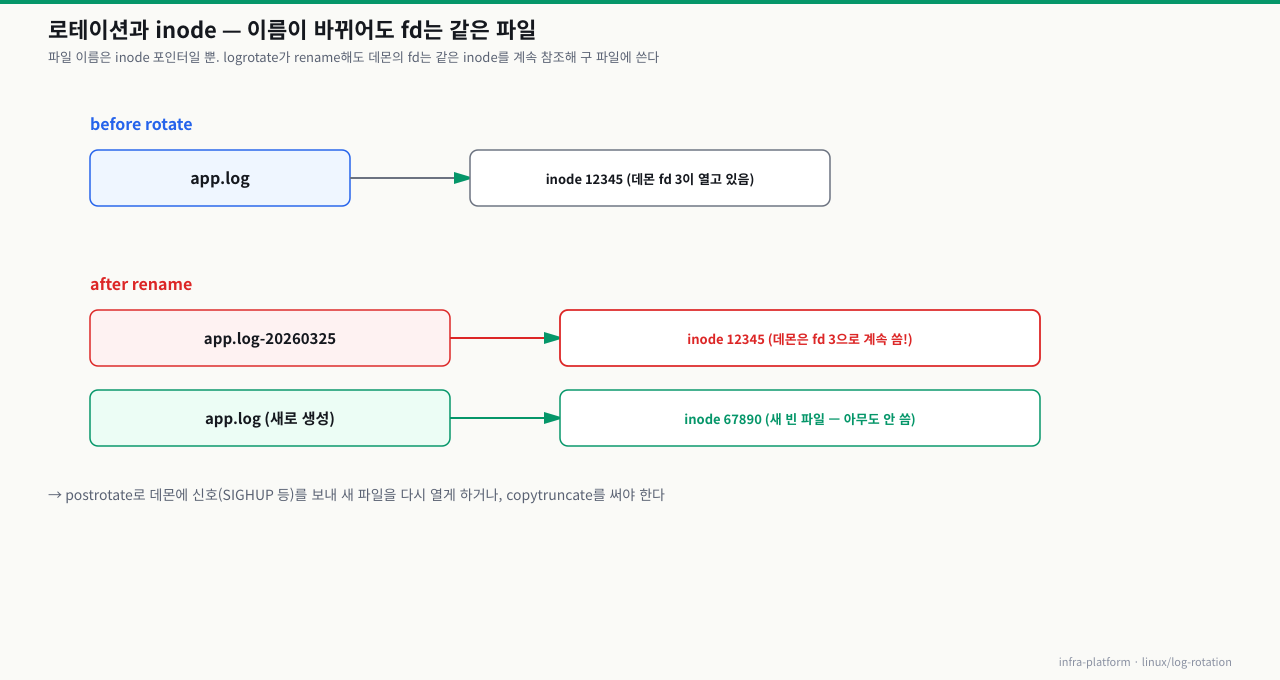 확대
확대
해결 방법 1: postrotate로 서비스 재시작 / 시그널 — 로테이션 직후 서비스에 HUP 신호를 보내 새 파일로 전환합니다:
/var/log/myapp/*.log {
daily
rotate 30
compress
delaycompress
sharedscripts
postrotate
# SIGUSR1: 많은 데몬이 이 신호를 받으면 로그 파일을 재오픈
/bin/systemctl kill -s USR1 myapp.service 2>/dev/null || true
# 또는 HUP 신호 (일부 데몬은 설정 재로드 + 로그 재오픈)
# /bin/systemctl reload myapp.service 2>/dev/null || true
# 또는 완전 재시작 (서비스 중단 발생 가능 — 마지막 수단)
# /bin/systemctl restart myapp.service 2>/dev/null || true
endscript
}
해결 방법 2: copytruncate (재시작 불가 데몬에 한해) — 파일을 복사한 뒤 원본을 비워 서비스 재시작 없이 로테이션합니다:
/var/log/myapp/*.log {
daily
rotate 30
compress
delaycompress
# 파일을 복사한 후 원본을 0바이트로 truncate
# 데몬은 같은 fd(같은 inode)를 계속 사용하지만, 파일 내용이 비워짐
copytruncate
}
copytruncate의 주의사항: 복사와 truncate 사이에 짧은 시간 간격이 있어 그 사이에 쓴 로그가 유실될 수 있습니다. 가능하면 postrotate + 시그널 방식을 권장합니다.
어떤 신호를 써야 하는지 확인 — 서비스마다 로그 재오픈에 사용하는 신호가 다르므로 먼저 확인합니다:
# 해당 데몬의 man 페이지나 공식 문서 확인
man myapp
# 또는 실행 중 프로세스가 처리하는 신호 확인
cat /proc/$(pgrep myapp)/status | grep -i sig
# Nginx: USR1으로 로그 재오픈
kill -USR1 $(cat /var/run/nginx.pid)
# Apache: SIGUSR1 또는 graceful
apachectl graceful
증상 — 디스크 사용량이 임계치를 초과하기 직전의 전형적인 징후입니다:
df -h
# Filesystem Size Used Avail Use% Mounted on
# /dev/sda1 50G 50G 0 100% /
# 로그 쓰기 실패 메시지
tail -f /var/log/syslog
# Mar 25 10:30:01 server kernel: [12345.678] EXT4-fs error: No space left on device
즉각 조치 — 로그 공간 확보 순서 — 디스크 풀 상황에서 빠르게 공간을 만드는 우선순위 순서입니다:
# 1단계: 어디서 공간을 먹는지 확인
df -h
du -sh /var/log/* | sort -rh | head -20
# 2단계: 가장 큰 로그 파일 식별
find /var/log -name "*.log" -size +100M -ls 2>/dev/null | sort -k7 -rn
# 3단계: journald 즉시 정리 (빠르고 안전)
sudo journalctl --vacuum-size=100M
# 4단계: 압축되지 않은 오래된 로그 즉시 압축
sudo find /var/log -name "*.log.[0-9]" -exec gzip {} \;
# 5단계: 너무 오래된 로테이션 파일 삭제 (7일 이상)
sudo find /var/log -name "*.gz" -mtime +7 -delete
# 6단계: logrotate 강제 실행
sudo logrotate -f /etc/logrotate.conf
# 7단계: 특정 서비스 로그 직접 비우기 (서비스 중단 없이)
# 주의: 이미 열려있는 파일은 truncate로만 비울 것, rm 하면 안 됨
sudo truncate -s 0 /var/log/myapp/app.log
대용량 로그 파일 긴급 처리 — 서비스를 중단하지 않고 대용량 로그 파일을 안전하게 정리합니다:
# 현재 열려있는 파일인지 확인
sudo lsof /var/log/myapp/app.log
# 열려있는 파일: truncate 사용 (데몬 중단 없음)
sudo truncate -s 0 /var/log/myapp/app.log
# 열려있지 않은 파일: 안전하게 삭제 가능
sudo rm /var/log/myapp/app.log.3.gz
# 공간 확보 확인
df -h
재발 방지 — logrotate 설정 즉시 강화 — 디스크 풀 이후 로테이션 주기와 압축 설정을 강화합니다:
# maxsize 옵션 추가하여 크기 기반 로테이션 활성화
sudo tee /etc/logrotate.d/myapp << 'EOF'
/var/log/myapp/*.log {
daily
maxsize 200M # 200MB 초과 시 즉시 로테이션
rotate 7 # 7일치만 보관으로 줄임
compress
delaycompress
missingok
notifempty
sharedscripts
postrotate
/bin/systemctl kill -s USR1 myapp.service 2>/dev/null || true
endscript
}
EOF
모니터링 설정 — 사전 경보 — 디스크 사용량이 임계치를 넘기 전에 알림을 받도록 설정합니다:
# 디스크 사용률 80% 초과 시 경보하는 스크립트
sudo tee /usr/local/bin/disk-alert.sh << 'EOF'
#!/bin/bash
THRESHOLD=80
USAGE=$(df / | awk 'NR==2 {print $5}' | tr -d '%')
if [ "$USAGE" -gt "$THRESHOLD" ]; then
echo "ALERT: Disk usage is ${USAGE}% on $(hostname)" | \
mail -s "Disk Alert" admin@example.com
fi
EOF
sudo chmod +x /usr/local/bin/disk-alert.sh
# cron에 등록 (매 시간 체크)
echo "0 * * * * root /usr/local/bin/disk-alert.sh" | \
sudo tee /etc/cron.d/disk-alert
증상 — logrotate가 예상 시각에 실행되지 않아 로그 파일이 로테이션되지 않는 상황입니다:
# 로그가 수 GB인데 logrotate가 전혀 실행된 흔적이 없음
cat /var/lib/logrotate/logrotate.status
# (비어있거나 오래된 날짜)
# 수동 실행은 잘 됨
sudo logrotate -f /etc/logrotate.conf # ← 이건 됨
원인 1: cron 데몬이 실행 중이지 않음 — crond/cron 서비스가 중단되면 logrotate 자동 실행도 멈춥니다:
# cron 상태 확인
sudo systemctl status cron # Debian/Ubuntu
sudo systemctl status crond # RHEL/CentOS
# 실행 중이지 않으면 시작
sudo systemctl start cron
sudo systemctl enable cron
원인 2: /etc/cron.daily 실행 시각 문제 — 서버 다운 시각과 cron.daily 실행 시각이 겹치면 skip됩니다:
# cron.daily는 기본적으로 매일 특정 시각(보통 06:25)에 실행됨
# 해당 시각에 서버가 꺼져있거나 부하가 높으면 건너뜀
grep daily /etc/crontab
# 25 6 * * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily )
# anacron 사용 여부 확인 (서버가 꺼져있어도 재부팅 후 실행)
which anacron
sudo systemctl status anacron
# anacron 설정 확인
cat /etc/anacrontab
원인 3: 권한 문제 — logrotate 스크립트 실행 불가 — 스크립트 권한이 잘못되면 cron이 실행하지 못합니다:
# /etc/cron.daily/logrotate 권한 확인
ls -la /etc/cron.daily/logrotate
# 반드시 실행 권한이 있어야 하고, 소유자는 root여야 함
# -rwxr-xr-x 1 root root ... /etc/cron.daily/logrotate
# 권한 수정
sudo chmod 755 /etc/cron.daily/logrotate
sudo chown root:root /etc/cron.daily/logrotate
원인 4: 설정 파일 권한이 너무 넓음 — 그룹/타인이 쓸 수 있는 설정 파일은 logrotate가 보안 이유로 거부합니다:
# logrotate는 보안상 world-writable 설정 파일을 거부함
ls -la /etc/logrotate.d/myapp
# -rw-rw-rw- 1 root root ... ← world-writable이면 logrotate가 무시!
# 올바른 권한으로 수정
sudo chmod 644 /etc/logrotate.d/myapp
sudo chown root:root /etc/logrotate.d/myapp
원인 5: SELinux / AppArmor 차단 — SELinux가 logrotate의 파일 접근이나 postrotate 실행을 막을 수 있습니다:
# SELinux 관련 거부 로그 확인 (RHEL 계열)
sudo ausearch -m avc -ts recent | grep logrotate
# SELinux를 끄지 않고 먼저 AVC 원인과 컨텍스트를 확인한다.
# setenforce 0은 보호 기능을 비활성화하므로 운영 서버에서 실행하지 않는다.
sudo ausearch -m avc -ts recent | audit2why
ls -Z /var/log/myapp /etc/logrotate.d/myapp
종합 진단 스크립트 — logrotate 미실행 원인을 자동으로 점검하는 진단 스크립트입니다:
#!/bin/bash
echo "=== logrotate 진단 ==="
echo ""
echo "[1] logrotate 바이너리"
which logrotate && logrotate --version
echo ""
echo "[2] cron 데몬 상태"
systemctl is-active cron 2>/dev/null || systemctl is-active crond 2>/dev/null
echo ""
echo "[3] /etc/cron.daily/logrotate 권한"
ls -la /etc/cron.daily/logrotate
echo ""
echo "[4] logrotate 상태 파일 최신 항목"
tail -5 /var/lib/logrotate/logrotate.status 2>/dev/null || \
tail -5 /var/lib/logrotate.status 2>/dev/null
echo ""
echo "[5] 설정 파일 권한 이상 확인"
find /etc/logrotate.d/ -not -perm -o-w -ls 2>/dev/null | head -5
find /etc/logrotate.d/ -perm /o+w -ls 2>/dev/null | \
awk '{print "WARNING: world-writable:", $NF}'
echo ""
echo "[6] 디버그 모드 실행"
logrotate -d /etc/logrotate.conf 2>&1 | tail -20
심화 — truncate -s 0이 공간을 안 돌려줄 때
심화: truncate의 함정 — 파일 오프셋과 sparse 파일
디스크 풀 대응에서 '열려 있는 로그는 rm 대신 truncate -s 0으로 비우라'고 했습니다. 맞는 말이지만, 이게 항상 공간을 돌려주지는 않습니다. 여기엔 파일 오프셋과 O_APPEND라는 내부 동작이 숨어 있습니다.
- 파일 오프셋은 fd에 남는다: 프로세스가 로그 파일을 열면 커널은 그 열린 파일(fd)마다 '다음에 쓸 위치'인 파일 오프셋을 유지합니다.
truncate -s 0은 파일 내용을 0바이트로 만들지만, 이미 열려 있는 fd의 오프셋은 그대로 둡니다. - O_APPEND로 열었다면 안전: 매
write마다 커널이 오프셋을 '현재 파일 끝'으로 재설정한 뒤 쓰므로, truncate 후엔 0바이트 끝(=처음)부터 다시 쌓입니다. 공간이 정상적으로 회수됩니다. - O_APPEND 없이 열었다면 sparse 파일: 앱의 오프셋이 예전 위치(예: 30GB)에 그대로 남아, truncate 후 첫
write가 오프셋 30GB 지점에 기록됩니다. 그 앞 0~30GB는 데이터가 없는 구멍(hole) 인 sparse 파일이 되고,ls -l은 여전히 30GB로 보입니다.du로 보면 실제 블록은 작지만, 앱이 계속 쓰면 구멍이 실제 블록으로 채워지며 진짜로 다시 커집니다 — "truncate 했는데 파일이 도로 커져요"의 정체입니다. - 그래서 truncate는 임시방편: '앱이 O_APPEND로 연 로그'에만 안전한 응급 조치이고, 근본 해결은 로테이션 + 서비스에 재오픈 신호(USR1/reopen) 입니다. 앱이 어떻게 여는지 모르면, truncate 후
ls -l과du를 함께 확인해 sparse가 됐는지 봐야 합니다.
정리하면, truncate는 '파일 크기'만 건드리고 '앱이 쓰는 위치'는 못 건드립니다. 로그를 진짜로 새로 시작하게 하려면 앱이 파일을 다시 열게 만들어야 합니다.
상황: 디스크 풀 긴급 대응으로 rm 대신 안전하게 truncate -s 0 app.log를 실행했습니다. 그런데 df로 확인하니 공간이 조금밖에 안 늘고, ls -l을 보니 app.log가 곧 다시 수십 GB로 표시됩니다. 서비스는 계속 로그를 쓰는 중입니다.
원인: 앱이 로그 파일을 O_APPEND 없이 열어 두었습니다. truncate는 파일 내용만 0으로 만들 뿐 이미 열린 fd의 파일 오프셋(예: 30GB 지점)은 건드리지 않습니다. 그래서 truncate 직후 첫 write가 오프셋 30GB에 기록되며, 0~30GB 구간이 데이터 없는 구멍(hole)인 sparse 파일이 됩니다. ls -l은 논리 크기(30GB)를 보여주지만, 앱이 계속 쓰면 그 구멍이 실제 블록으로 채워지며 진짜로 다시 커집니다.
진단: ls -l app.log(논리 크기)와 du -h app.log(실제 블록)를 함께 봅니다 — 둘이 크게 차이나면 sparse 파일, 즉 오프셋이 남아 생긴 문제로 확정합니다. lsof로 그 파일을 어느 프로세스가 fd로 붙들고 있는지, 가능하면 앱이 O_APPEND로 여는지(로깅 설정·문서)를 확인합니다.
해결: 진짜로 비우려면 truncate가 아니라 로테이션 + 서비스 재오픈을 씁니다 — logrotate의 postrotate에서 앱에 로그 재오픈 신호(nginx의 USR1 등)를 보내거나 systemctl reload하면, 앱이 새 fd로 오프셋 0부터 씁니다. 근본적으로는 앱이 O_APPEND로 로그를 열도록 하고(대부분의 로깅 라이브러리 기본), 긴급 상황에서 truncate를 썼다면 반드시 재오픈 신호를 함께 보냅니다.
9. 실무 적용 패턴
새 서버를 프로비저닝할 때 반드시 수행해야 할 로그 관련 설정입니다.
1. journald 영구 저장 활성화 및 용량 제한 — 재부팅 후에도 로그가 유지되도록 영구 저장을 설정합니다:
# 영구 저장 디렉터리 생성
sudo mkdir -p /var/log/journal
sudo chown root:systemd-journal /var/log/journal
sudo chmod 2755 /var/log/journal
# 보존 정책 설정
sudo tee /etc/systemd/journald.conf.d/storage-policy.conf << 'EOF'
[Journal]
Storage=persistent
SystemMaxUse=2G
SystemKeepFree=500M
MaxRetentionSec=3month
RateLimitBurst=10000
EOF
sudo systemctl restart systemd-journald
2. 시스템 로그 보존 기간 설정 — 오래된 로그를 자동으로 정리하는 보존 기간을 설정합니다:
# /etc/logrotate.conf 전역 설정 확인 및 조정
sudo tee /etc/logrotate.conf << 'EOF'
# 전역 기본값
weekly
rotate 4
create
dateext
compress
include /etc/logrotate.d
EOF
3. 애플리케이션별 logrotate 설정 배포 — 각 앱의 로그 경로와 정책에 맞는 logrotate 설정을 배포합니다:
# 각 애플리케이션 배포 시 함께 배포할 logrotate 설정
sudo install -m 644 -o root -g root \
deploy/logrotate/myapp.conf \
/etc/logrotate.d/myapp
# 즉시 테스트
sudo logrotate -d /etc/logrotate.d/myapp
4. 디스크 모니터링 cron 추가 — 디스크 사용량이 임계값을 넘으면 알림을 보내는 cron을 설정합니다:
# 로그 디렉터리 크기 모니터링
sudo tee /etc/cron.d/log-monitor << 'EOF'
# 매일 오전 9시에 로그 디렉터리 크기 리포트
0 9 * * * root du -sh /var/log/* 2>/dev/null | sort -rh | head -10 | logger -t log-size-report
EOF
체크리스트:
-
/var/log/journal/디렉터리 존재 (영구 저널) -
journald.conf에SystemMaxUse설정 -
journald.conf에MaxRetentionSec설정 -
/etc/logrotate.d/에 앱별 설정 파일 존재 - logrotate 설정 파일 권한 644, 소유자 root
-
logrotate -d디버그 모드로 설정 검증 완료 - cron/anacron 서비스 실행 중
- 디스크 사용률 모니터링 알림 설정
Ansible 또는 셸 스크립트로 서버 프로비저닝 시 로그 설정을 자동화하는 패턴입니다.
Ansible Task 예시 — logrotate 설정 파일을 여러 서버에 일괄 배포하는 Ansible 태스크입니다:
# roles/log-management/tasks/main.yml
- name: journald 설정 디렉터리 생성
file:
path: /etc/systemd/journald.conf.d
state: directory
mode: '0755'
- name: journald 보존 정책 설정
copy:
dest: /etc/systemd/journald.conf.d/storage-policy.conf
content: |
[Journal]
Storage=persistent
SystemMaxUse={{ journald_max_use | default('2G') }}
SystemKeepFree={{ journald_keep_free | default('500M') }}
MaxRetentionSec={{ journald_retention | default('3month') }}
notify: restart journald
- name: 영구 저널 디렉터리 생성
file:
path: /var/log/journal
state: directory
owner: root
group: systemd-journal
mode: '2755'
- name: 애플리케이션 logrotate 설정 배포
template:
src: logrotate-app.conf.j2
dest: /etc/logrotate.d/{{ app_name }}
owner: root
group: root
mode: '0644'
- name: logrotate 설정 검증
command: logrotate -d /etc/logrotate.d/{{ app_name }}
changed_when: false
logrotate 설정 템플릿 (logrotate-app.conf.j2) — 앱마다 변수만 바꿔 재사용할 수 있는 Jinja2 템플릿입니다:
/var/log/{{ app_name }}/*.log {
daily
rotate {{ log_rotate_count | default(30) }}
maxsize {{ log_max_size | default('500M') }}
compress
delaycompress
missingok
notifempty
dateext
create 0640 {{ app_user }} {{ app_group }}
sharedscripts
postrotate
/bin/systemctl kill -s USR1 {{ app_name }}.service 2>/dev/null || true
endscript
}
배포 후 검증 스크립트 — logrotate 설정 배포 후 실제로 동작하는지 자동으로 검증합니다:
#!/bin/bash
# verify-log-setup.sh
set -euo pipefail
APP_NAME="${1:-myapp}"
echo "=== 로그 설정 검증: $APP_NAME ==="
# 1. logrotate 설정 문법 검증
echo "[1] logrotate 문법 검증..."
logrotate -d "/etc/logrotate.d/$APP_NAME" 2>&1 | \
grep -E "(error|warning|rotating)" || echo "OK: 문법 이상 없음"
# 2. journald 상태 확인
echo ""
echo "[2] journald 디스크 사용량..."
journalctl --disk-usage
# 3. 로그 디렉터리 권한 확인
echo ""
echo "[3] 로그 디렉터리 권한..."
ls -la "/var/log/$APP_NAME/" 2>/dev/null || echo "디렉터리 없음"
# 4. cron 서비스 상태
echo ""
echo "[4] cron 서비스..."
systemctl is-active cron 2>/dev/null || systemctl is-active crond 2>/dev/null
echo ""
echo "=== 검증 완료 ==="
10. 전체 흐름 요약
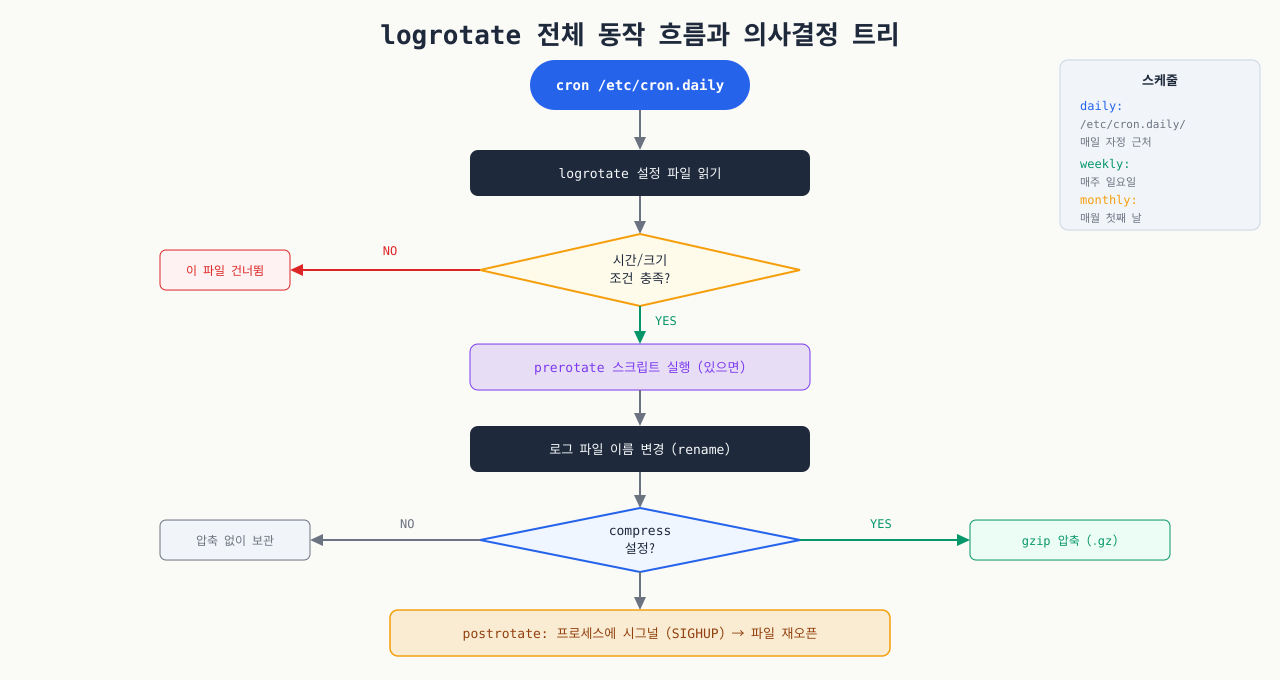
logrotate 전체 동작 흐름과 의사결정 트리
 확대
확대
logrotate -d로 dry run을 해보면 "would rotate"가 나오는데 실제 cron에서는 돌지 않거나, 강제 실행은 되는데 자동 실행이 왜 안 되는지 파악이 안 되는 경우가 있습니다. 설정 파일을 아무리 봐도 어디서 조건을 확인하고 어느 단계에서 건너뛰는지 흐름이 보이지 않기 때문입니다. logrotate가 내부적으로 어떤 순서로 조건을 평가하는지 알면, 설정 문제인지 실행 환경 문제인지 빠르게 구분할 수 있습니다.
logrotate 실행 흐름 — logrotate가 내부적으로 처리하는 단계별 흐름을 시각화합니다:
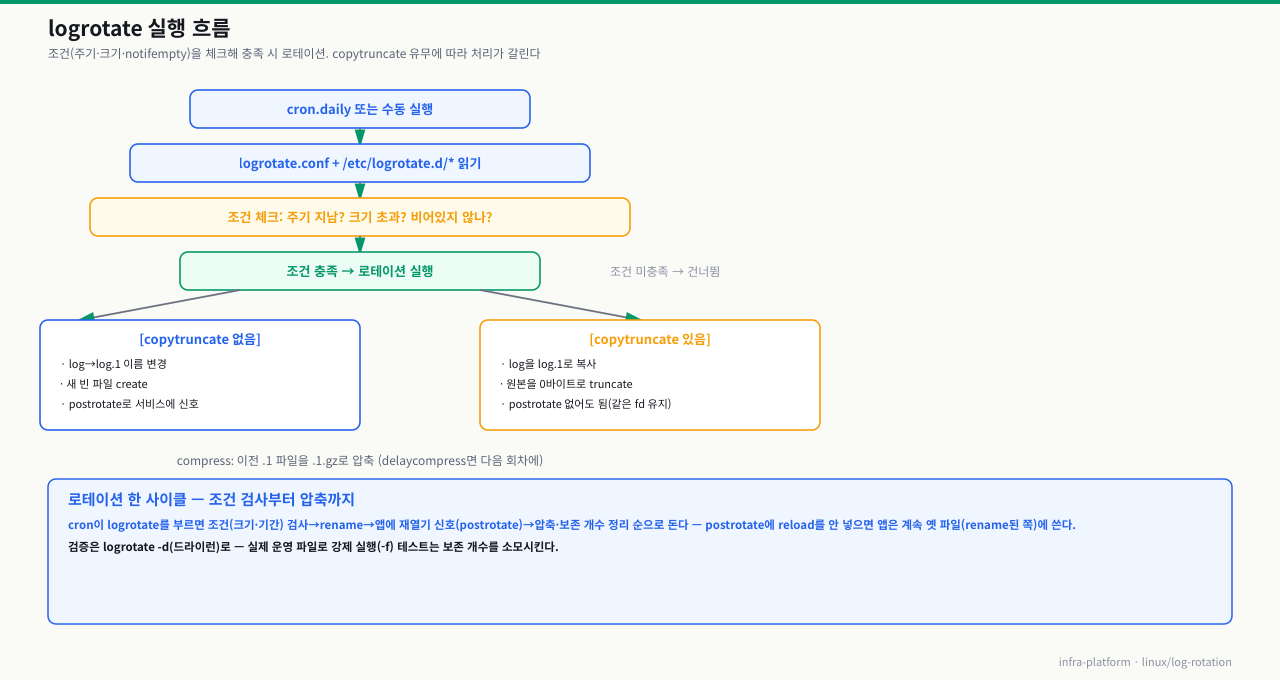 확대
확대
옵션 선택 가이드 — 서비스 재시작 가능 여부에 따라 copytruncate vs postrotate 중 선택합니다:
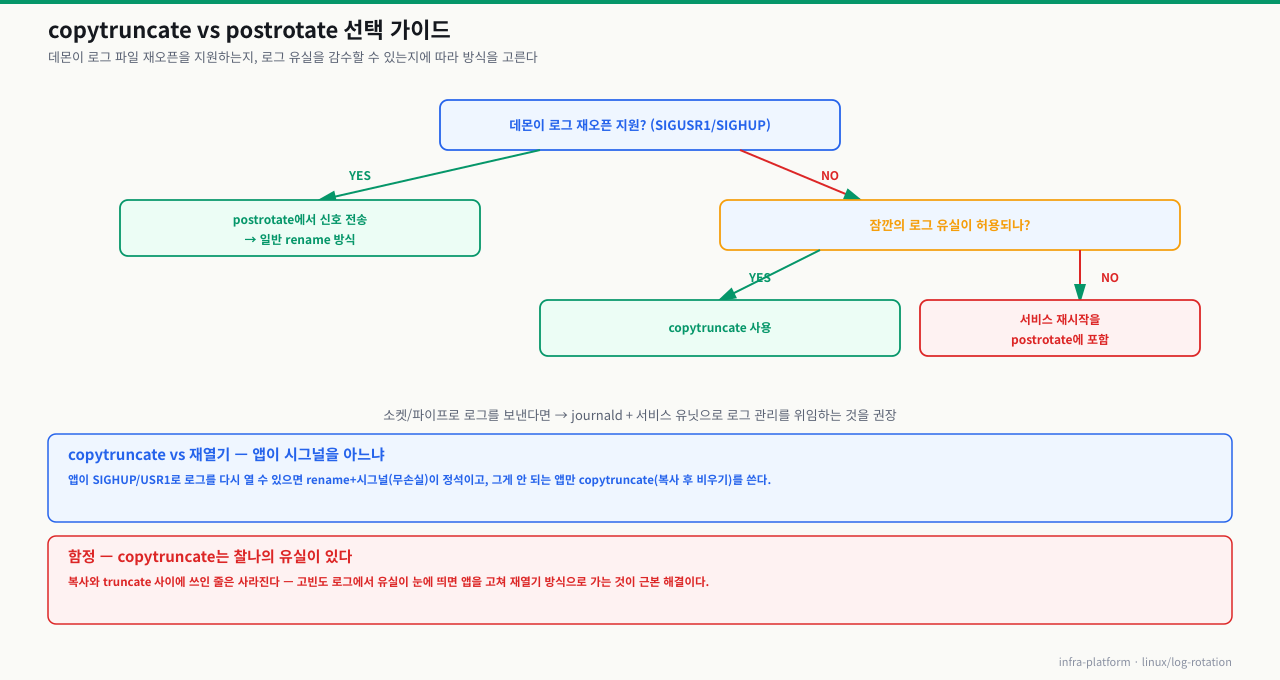 확대
확대
주요 옵션 조합 패턴 — 자주 쓰는 상황별 옵션 조합을 정리했습니다:
| 상황 | 권장 옵션 조합 |
|---|---|
| Nginx, HAProxy 등 시그널 지원 | compress, delaycompress, postrotate (kill -USR1) |
| 레거시 데몬 (재시작 불가) | copytruncate, compress |
| 고트래픽 빠르게 커지는 로그 | maxsize 500M, daily, rotate 14 |
| 감사 로그 (장기 보관) | monthly, rotate 24, compress, dateext |
| 개발 환경 (최소 보관) | daily, rotate 3, compress, missingok |
journald vs logrotate 역할 분리 — 두 도구의 역할 분담을 이해해야 로그를 중복 설정하지 않습니다:
| 항목 | journald | logrotate |
|---|---|---|
| 대상 | systemd 서비스의 stdout/stderr | 파일로 직접 쓰는 로그 |
| 설정 위치 | /etc/systemd/journald.conf | /etc/logrotate.d/ |
| 보존 정책 | MaxRetentionSec, SystemMaxUse | rotate N, size, maxsize |
| 조회 방법 | journalctl | cat, less, grep |
| 압축 | 내장 (Compress=yes) | compress 옵션 |
logrotate 실무 함정 — state 파일 손상·동시 실행·postrotate 선택
 확대
확대
logrotate를 설정하고 logrotate -f로 강제 실행했을 때는 잘 됐는데, cron에서 자동으로 돌 때는 왜인지 안 됩니다. 또는 로테이션은 됐는데 Nginx 로그 파일이 계속 이전 파일에 쌓이고 있습니다. 이런 증상에는 몇 가지 공통적인 함정이 있습니다. state 파일이 손상되어 실행 이력을 못 읽는 경우, cron에서 다른 사용자로 실행되어 파일 권한이 안 맞는 경우, postrotate 스크립트에서 서비스 신호(USR1)를 잘못 보낸 경우입니다. 운영 환경에서 logrotate가 조용히 실패하는 패턴들을 정리합니다.
logrotate state 파일 손상 복구:
logrotate는 /var/lib/logrotate/status에 마지막 실행 이력을 기록합니다. 이 파일이 손상되면 로테이션이 중복 실행되거나 건너뛰어집니다.
# state 파일 확인
cat /var/lib/logrotate/status
# 손상 여부 확인 (파싱 에러)
logrotate -d /etc/logrotate.conf 2>&1 | grep -i "error\|cannot"
# 복구: state 파일 삭제 후 재실행 (다음 실행 시 재생성됨)
sudo rm /var/lib/logrotate/status
sudo logrotate -f /etc/logrotate.conf
# 동시 실행 방지 확인 (cron에서 실행될 때)
# /etc/cron.daily/logrotate 내부에 flock 사용 여부 확인
cat /etc/cron.daily/logrotate | grep flock
postrotate: systemctl reload vs kill -HUP 선택 기준 — 두 방법의 동작 차이와 어떤 상황에 쓸지 설명합니다:
# 서비스별 올바른 로그 파일 재오픈 방법
# Nginx — SIGUSR1 권장 (graceful log reopen)
postrotate
/bin/kill -USR1 $(cat /var/run/nginx.pid 2>/dev/null) 2>/dev/null || true
endscript
# Apache — graceful 재시작
postrotate
/usr/sbin/apachectl graceful
endscript
# rsyslog — SIGHUP (설정 리로드 + 파일 재오픈)
postrotate
/usr/bin/kill -HUP $(cat /var/run/rsyslogd.pid 2>/dev/null) 2>/dev/null || true
endscript
# systemd 관리 서비스 — systemctl reload (권장)
postrotate
systemctl reload nginx 2>/dev/null || true
endscript
systemctl reload vs kill -HUP 비교 — 각 방법의 장단점과 적합한 상황을 비교합니다:
| 방법 | 장점 | 단점 |
|---|---|---|
systemctl reload | 서비스 등록 여부 확인, 실패 시 에러 반환 | 서비스가 reload를 지원해야 함 |
kill -HUP $(cat pid) | 빠름, PID 파일이 있으면 작동 | PID 파일이 없으면 실패, 보안 이슈 |
pkill -HUP nginx | 이름으로 찾으므로 PID 파일 불필요 | 여러 프로세스가 있으면 모두에 전송 |
journald vs /var/log 파일 — 어디에 무엇을 보관할지 정책 가이드
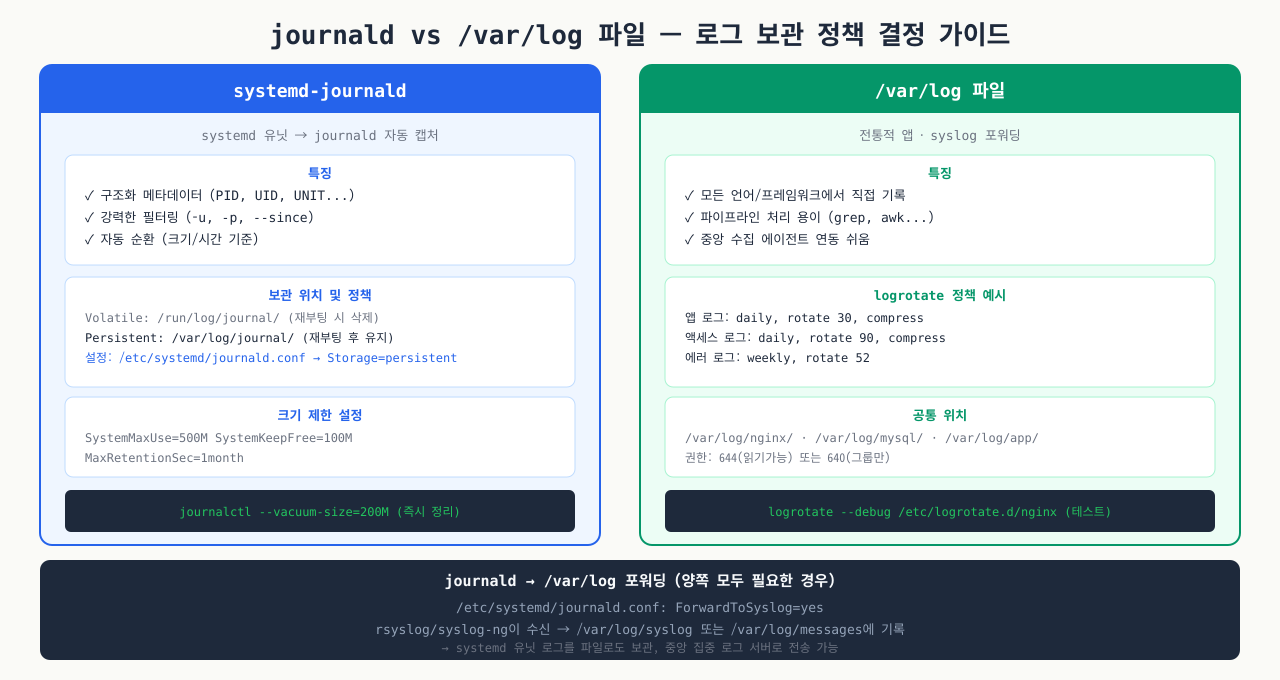 확대
확대
새 서비스를 배포할 때 로그를 journald에 맡길지, 직접 파일로 쓸지 결정해야 합니다. systemd 서비스로 등록하면 stdout이 자동으로 journald에 수집되지만, Elastic Stack으로 로그를 보낼 때나 logrotate로 보존 정책을 직접 제어해야 할 때는 파일이 유리합니다. 팀마다 "journald에 다 넣어" vs "파일로 써야 편해"로 의견이 갈리는데, 로그 유형별로 기준을 정해두면 서비스마다 같은 고민을 반복하지 않아도 됩니다.
언제 journald, 언제 /var/log 파일을 사용할지 — 로그 유형별로 적합한 저장 방식을 선택하는 기준입니다:
| 로그 유형 | 권장 저장 방식 | 이유 |
|---|---|---|
| systemd 서비스 stdout/stderr | journald | 자동 수집, 구조화된 메타데이터 |
| 애플리케이션 자체 로그 파일 | /var/log/앱명/ | 로그 포맷 제어, 외부 도구 연동 |
| 보안 감사 로그 | /var/log/audit/ (auditd) | 별도 권한, 장기 보관 |
| 시스템 부팅/커널 로그 | journald (영구화) | dmesg 이력 보존 |
| 중앙 집중 로그 | rsyslog/Fluentd → ELK/Loki | 여러 서버 통합 |
# journald 영구화 설정 (재부팅 후에도 보존)
sudo mkdir -p /var/log/journal
sudo systemd-tmpfiles --create --prefix /var/log/journal
sudo systemctl restart systemd-journald
# journald 로그를 /var/log 파일로 포워딩 (하이브리드)
# /etc/systemd/journald.conf
# ForwardToSyslog=yes # rsyslog로 전달
# rsyslog가 파일로 기록
# /etc/rsyslog.d/50-default.conf 에서 /var/log/syslog 등으로 기록
# 검색: journalctl vs grep
journalctl -u nginx --since "1 hour ago" # 구조화 검색 (빠름)
grep "ERROR" /var/log/nginx/error.log # 전통적 방법
마무리
로그 관리는 시스템이 조용할 때 설정해두어야 장애 상황에서 빛을 발합니다. 디스크 풀 상황에서 허겁지겁 로그를 지우는 것이 아니라, 처음부터 logrotate와 journald 정책을 올바르게 설정하면 로그는 자동으로 통제됩니다.
핵심 원칙:
- 모든 서비스 로그에는 반드시 logrotate 설정이 있어야 합니다
postrotate와copytruncate의 차이를 이해하고 상황에 맞게 선택하세요journald는 영구 저장 + 용량 제한을 반드시 설정하세요- 설정 배포 후에는 항상
logrotate -d로 검증하세요 - 디스크 사용률 모니터링과 임계값 알림을 병행하세요
명령어·단축키 빠른 참조
이 모듈에서 다룬 로그 관리·로테이션 명령을 실전 옵션과 함께 모았습니다. "자주 쓰는 예" 열의 조합을 그대로 써도 됩니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
logrotate -d | 설정 검증(dry-run, 실제 실행 안 함) | logrotate -d /etc/logrotate.d/myapp (배포 전 필수) |
logrotate -f | 조건 무시하고 강제 로테이션 | logrotate -vf /etc/logrotate.conf (-v로 상세 출력) |
journalctl | 저널 로그 조회·필터 | journalctl -u nginx -p err --since "1 hour ago" |
journalctl -f | 저널 실시간 스트리밍 | journalctl -fu myapp.service (배포 직후 모니터링) |
journalctl --disk-usage | 저널이 차지한 디스크 확인 | journalctl --disk-usage → 크면 vacuum 고려 |
journalctl --vacuum-* | 오래된 저널 즉시 정리 | journalctl --vacuum-size=200M 또는 --vacuum-time=2weeks |
du | 로그 디렉터리 용량 상위 확인 | du -sh /var/log/* | sort -rh | head |
df -h | 파티션 사용률 확인 | df -h /var/log (rotate 개수 산정 전 여유 확인) |
find | 큰·오래된 로그 탐색/삭제 | find /var/log -name "*.gz" -mtime +7 -delete |
lsof | 로그 파일을 연 프로세스 확인 | lsof /var/log/myapp/app.log (fd 잡은 데몬 추적) |
truncate -s 0 | 열린 로그를 비움(rm 금지) | truncate -s 0 /var/log/myapp/app.log |
kill -USR1 | 데몬에 로그 재오픈 신호 전송 | kill -USR1 $(cat /var/run/nginx.pid) |
systemctl | journald 재시작·서비스 reload | systemctl restart systemd-journald / systemctl reload nginx |
systemd-tmpfiles | 영구 저널 디렉터리 활성화 | systemd-tmpfiles --create --prefix /var/log/journal |
관련 모듈로 더 깊이:
- journalctl로 모든 커널/서비스 로그 검색 및 실시간 모니터링 — journald 보존 정책 다음 단계인 정밀 로그 쿼리·포스트모텀
- 디스크·스토리지 관리 기본 명령어 — 로그가 갉아먹는 디스크 용량을 모니터링하고 파티션을 설계하는 법
- 리눅스 부팅 시 데몬 프로세스 자동 실행 및 관리 가이드 — postrotate에서 재시작/리로드할 서비스의 동작 원리
다음 모듈에서는 journalctl 고급 필터와 구조화 필드 쿼리를 사용해 장애 시점의 로그를 정밀하게 추적하고 포스트모텀 보고서를 작성하는 방법을 다룹니다.