장애가 끝난 뒤 회고에서 "언제부터 느려졌는지" 아무도 답하지 못했습니다. 서버는 살아 있었지만 트래픽 급증, 에러율, 대역폭 사용량이 어디에도 남아 있지 않았습니다.
모니터링은 장애 후 보고서가 아니라 장애 중 판단 근거입니다. 지표와 로그가 있어야 감이 아니라 증거로 대응할 수 있습니다.
온프레미스 시절에는 Nagios나 Zabbix가 서버 한 대씩을 감시하는 구조였습니다. 그런데 서비스가 컨테이너와 오토스케일링으로 전환되면서 "서버 한 대"라는 단위 자체가 흔들리기 시작했습니다. 인스턴스가 수십 개에서 수백 개로 늘어나고 줄어드는 환경에서, 개별 서버를 직접 SSH로 들어가 확인하는 방법은 더 이상 통하지 않습니다. 지난해 블랙프라이데이에 트래픽이 몰렸을 때, 팀이 "어느 서버가 이상한지"를 파악하는 데만 20분을 쓴 회사가 있었습니다. 모니터링 시스템이 없어서가 아니었습니다. 서버별 CPU 그래프는 있었지만, 그 숫자가 실제 사용자 경험과 연결되는 관점이 없었습니다. 이 모듈은 클라우드 환경에서 모니터링을 "서버 감시"가 아닌 "서비스 가시성"으로 전환하는 사고방식을 다룹니다.
- 1Observability의 3요소인 메트릭, 로그, 트레이스를 구분해 설명할 수 있다
- 2CloudWatch로 AWS 네이티브 모니터링을 구성할 수 있다
- 3Datadog로 SaaS 통합 모니터링을 구성할 수 있다
- 4Prometheus와 Grafana 오픈소스 스택을 구축할 수 있다
- 5iftop, nload, vnstat로 실시간 트래픽을 진단할 수 있다
Observability 3요소 — 메트릭, 로그, 트레이스
새벽 2시에 알림이 울립니다. "API 응답 시간 초과". 서버는 살아 있고 에러 로그는 없습니다. CPU 그래프를 봐도 정상입니다. 어디가 느린지 어디서부터 파야 하는지 막막합니다. 이때 메트릭, 로그, 트레이스가 각각 다른 질문에 답하면서 범위를 좁혀줍니다. 세 가지 신호가 어떻게 서로 다른 역할을 하고 어떤 순서로 활용하는지 이해하면, 장애 대응에서 감이 아닌 증거로 판단할 수 있습니다.
 확대
확대
메트릭 (Metrics): "지금 어떤 상태인가?"
숫자로 표현되는 시계열 데이터입니다. CPU 사용률, 초당 요청 수, 응답 시간 P99 같은 값입니다. 집계가 가능하고 알림을 걸기 쉽습니다.
http_requests_total{method="GET", status="200"} 1234567
http_request_duration_seconds{quantile="0.99"} 0.342
로그 (Logs): "무슨 일이 있었나?"
이벤트의 텍스트 기록입니다. "언제 어떤 요청이 들어와서 어떻게 처리됐는지"를 담습니다. 세부 문맥이 있지만 양이 많아 검색과 집계가 필요합니다.
2026-04-26T14:32:01Z ERROR user_id=4892 action=checkout
message="payment gateway timeout after 30s"
order_id=8847291 amount=49800
트레이스 (Traces): "어디서 느려졌나?"
분산 시스템에서 요청 하나가 여러 서비스를 거칠 때, 전체 경로와 각 구간 소요 시간을 기록합니다. "API는 200ms인데 그 중 DB 쿼리가 180ms"라는 사실을 보여줍니다.
Request → API Gateway (5ms)
→ Auth Service (8ms)
→ Product Service (187ms) ← 여기가 느림
→ DB Query: SELECT * FROM products (175ms) ← 병목
실무에서의 사용 패턴:
- 알림 발생 (메트릭): "API P99 응답시간이 2초 초과"
- 로그로 원인 파악: "payment-service에서 타임아웃 에러 급증"
- 트레이스로 병목 위치: "외부 PG 호출이 1.8초 걸림"
세 가지가 연결될 때 장애 대응 시간이 극적으로 줄어듭니다.
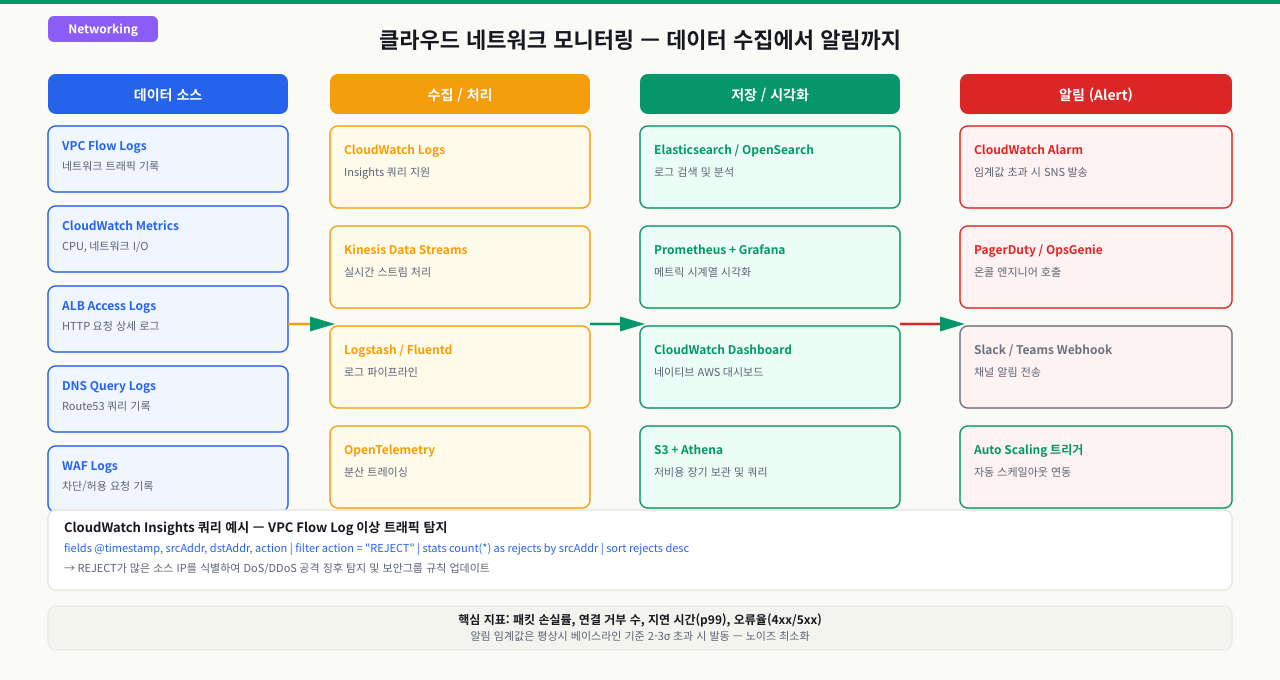
네트워크 지표와 Flow Log가 방출돼 알람이 울리기까지 — 관측 파이프라인 6단계
대시보드의 그래프 한 줄, 새벽의 알람 한 통은 저절로 생기지 않습니다. 리소스가 지표·Flow Log를 방출하고 → 수집 서비스가 모으고 → 집계·저장하고 → 임계값과 견주고 → 알림을 쏘고 → 사람이 조치합니다. 이 파이프라인을 단계로 알면 "그래프가 왜 비었지(No data)", "왜 알람이 안 울렸지", "왜 오탐이 터졌지"가 각각 다른 단계의 문제임을 알 수 있습니다. 네트워크 관점에서는 특히 VPC Flow Logs가 이 파이프라인에 실려 "연결이 되긴 되나"(ACCEPT)와 "무엇이 막혔나"(REJECT)를 지표로 바꿔줍니다.
[리소스] EC2 · ALB · VPC 서브넷/ENI (지표 방출 · Flow Logs: ACCEPT/REJECT 기록)
│
① 방출/수집 (자동 지표 · 에이전트 지표 · Flow Logs 배출)
│
② 수집 서비스로 전송 (CloudWatch · Prometheus pull · agent push)
│
③ 집계·저장 (시계열 저장 · 라벨/차원별 집계 · 보존기간)
│
④ 임계값 평가 (rate · p99 · 5xx 비율이 for 기간 동안 임계 초과?)
│
⑤ 알림 발송 (SNS · Alertmanager → Slack · PagerDuty)
│
⑥ 사람이 조치 (대시보드 → 로그 → Flow Log로 원인 좁힘 → 대응)
▼
[운영자] "REJECT 급증 → 보안그룹/NACL 오설정" 같은 결론
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① 방출·수집 | 리소스가 지표를 낸다. CPU·네트워크 I/O는 자동, 메모리·디스크·앱 지표는 에이전트가 필요. VPC Flow Logs는 서브넷·ENI의 허용/거부를 ACCEPT·REJECT로 남김 | 에이전트 미설치·IAM 권한 부족 → 그 지표만 No data(0이 아니라 NULL) / Flow Logs 미활성 → 트래픽 흐름 자체가 기록 안 됨 |
| ② 전송 | 수집 서비스가 데이터를 가져오거나(pull, Prometheus) 에이전트가 밀어 넣는다(push, Datadog·CloudWatch agent) | pull인데 인바운드 방화벽이 /metrics 포트를 막음 → connection refused, 타깃 DOWN / push인데 아웃바운드 443 차단 → 지표 유실 |
| ③ 집계·저장 | 시계열로 저장하고 라벨·차원별로 집계. 보존기간·카디널리티가 저장 규모를 좌우 | 고카디널리티 라벨(path·user_id) → 메모리 폭발·쿼리 타임아웃 / 보존기간 초과 → 과거 구간 조회 불가 |
| ④ 임계 평가 | 규칙이 rate·p99·5xx 비율 등을 계산해 임계값과 견줌. 순간 스파이크 오탐을 막으려 for(지속시간) 조건을 건다 | 수집 주기보다 짧은 for → 2개 샘플로 판단해 오탐 / 최소 요청수 조건 없음 → 트래픽 적은 새벽 1건이 100%로 오탐 |
| ⑤ 알림 | 조건 충족 시 SNS·Alertmanager가 Slack·PagerDuty로 통지 | 라우팅·연동 오류 → 조건은 맞았는데 알림 안 옴 / 중복 억제 없음 → 알림 폭주(alert fatigue) |
| ⑥ 조치 | 사람이 대시보드→로그→Flow Log 순으로 원인을 좁혀 대응. Flow Log의 REJECT로 어디서 차단됐는지 추적 | 관측 공백(①~③ 누락) → "느린 건 아는데 왜인지 모름"에서 멈춤 |
즉 알람 한 통은 여섯 단계가 모두 성립한 결과입니다 — 지표가 방출됐고(①), 수집됐고(②③), 임계를 넘겼고(④), 라우팅이 살아 있었습니다(⑤). 그래서 "값이 정상"과 "값이 없음(No data)"은 다른 신호입니다 — 스크랩 실패·에이전트 다운 자체를 up==0·absent()로 알람해야 ①②의 공백을 장애로 잡습니다. 네트워크 관점에서 Flow Logs의 ACCEPT/REJECT 비율은 "연결이 되긴 되나"를 그래프로 만들어줘, 보안그룹·NACL 오설정을 사용자 신고보다 먼저 발견하게 해줍니다.
CloudWatch — AWS 네이티브 모니터링
EC2를 쓰기 시작했는데 메모리가 얼마나 쓰이는지 CloudWatch에서 보이지 않습니다. CPU와 네트워크는 보이는데 메모리는 없습니다. 알고 보니 CloudWatch가 자동 수집하는 항목과 Agent를 따로 설치해야 하는 항목이 나뉩니다. 이 차이를 모르면 장애 순간에 정작 필요한 지표가 비어 있는 상황이 됩니다. CloudWatch의 구조와 에이전트 역할을 이해해야 AWS 환경에서 모니터링 공백 없이 운영할 수 있습니다.
AWS 인프라를 쓴다면 CloudWatch가 기본 출발점입니다. EC2, RDS, ALB, Lambda 등 AWS 서비스에서 자동으로 메트릭을 수집하고, 로그를 중앙 집중화하며, 알림을 설정할 수 있습니다.
핵심 기능:
- Metrics — AWS 서비스 + 커스텀 메트릭
- Logs — 로그 수집, 저장, 검색 (Logs Insights)
- Alarms — 임계값 기반 알림 (SNS → Slack/PagerDuty)
- Dashboards — 메트릭 시각화
CloudWatch Agent 설치 (EC2):
# 실습 디렉토리 준비
mkdir -p /tmp/networking/part6/exam_30 && cd /tmp/networking/part6/exam_30
# CloudWatch Agent 설치
wget https://s3.amazonaws.com/amazoncloudwatch-agent/ubuntu/amd64/latest/amazon-cloudwatch-agent.deb
sudo dpkg -i amazon-cloudwatch-agent.deb
# 설정 파일 생성
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard
# 메모리/디스크 메트릭은 기본 수집 안됨 — agent 필요
# 설정 예시 (/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.json)
{
"metrics": {
"namespace": "MyApp/System",
"metrics_collected": {
"mem": { "measurement": ["mem_used_percent"] },
"disk": { "measurement": ["disk_used_percent"],
"resources": ["/", "/data"] }
}
},
"logs": {
"logs_collected": {
"files": {
"collect_list": [{
"file_path": "/var/log/myapp/app.log",
"log_group_name": "/myapp/application",
"log_stream_name": "{instance_id}"
}]
}
}
}
}
- CloudWatch 대시보드 패널 확인 순서: 먼저 NULL(데이터 없음)과 0(실제 0값)을 구분 — NULL은 Agent 미설치 또는 IAM 권한 부족, 0은 메트릭 정상 수집 중
- Prometheus scrape_interval 기준: 15s(기본)이면 알람 평가 주기 for: 2m은 최소 8회 수집 후 발동, 수집 주기가 60s이면 같은 for: 2m이 실제로는 2개 샘플만 보고 판단하므로 노이즈 알람 위험
- rate(metric[5m]) 값이 급증했는데 대시보드에 반영이 늦으면 → scrape_interval과 대시보드 갱신 주기 합산 지연(최대 90초); 알람이 울렸는데 그래프가 정상이면 for 조건 미충족 직전에 복구된 것
CloudWatch Logs Insights — 로그 빠른 분석:
# 최근 1시간 HTTP 5xx 에러가 가장 많은 엔드포인트
fields @timestamp, path, status, duration
| filter status >= 500
| stats count(*) as errors, avg(duration) as avg_ms by path
| sort errors desc
| limit 10
# 특정 사용자의 최근 요청 흐름
fields @timestamp, user_id, action, status
| filter user_id = "4892"
| sort @timestamp desc
| limit 50
# 에러율이 급증한 시간대
fields @timestamp, status
| filter status >= 500
| stats count(*) as errors by bin(5m)
| sort @timestamp asc
알람 설정 (AWS CLI):
# P99 응답시간 1초 초과 시 알림
aws cloudwatch put-metric-alarm \
--alarm-name "API-HighLatency" \
--metric-name "TargetResponseTime" \
--namespace "AWS/ApplicationELB" \
--statistic "p99" \
--period 60 \
--threshold 1.0 \
--comparison-operator "GreaterThanThreshold" \
--evaluation-periods 3 \
--alarm-actions "arn:aws:sns:ap-northeast-2:123456:alerts"
EC2 메모리/디스크는 자동 수집 안 됩니다. AWS가 하이퍼바이저 수준에서 볼 수 없는 데이터라 CloudWatch Agent를 별도 설치해야 합니다. 이걸 모르고 "메모리가 터졌는데 CloudWatch에 안 보여요"라고 하는 팀이 많습니다.
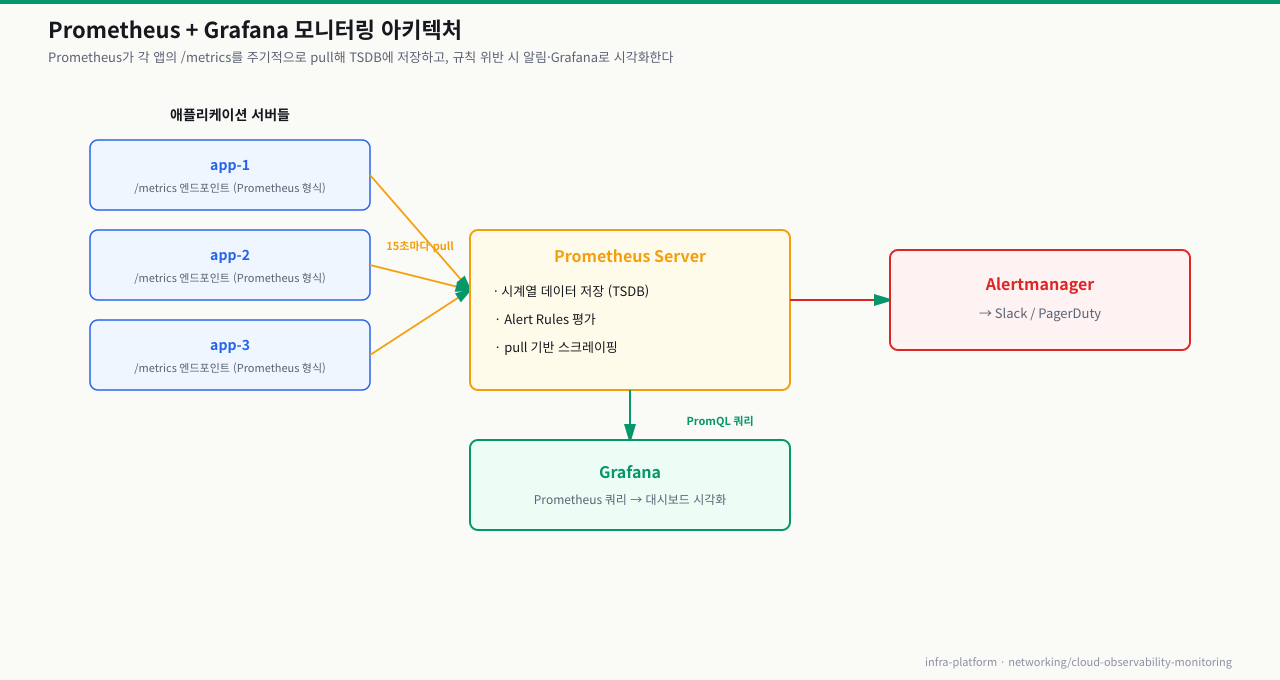
Prometheus + Grafana — 오픈소스 모니터링 스택
AWS 밖에서도 쓰고 싶거나, 메트릭을 직접 컨트롤하고 싶다면 Prometheus + Grafana 조합이 사실상 표준입니다. 쿠버네티스 환경에서 특히 강점이 있습니다.
아키텍처:
 확대
확대
Docker Compose로 빠른 시작:
# docker-compose.yml
version: '3'
services:
prometheus:
image: prom/prometheus:latest
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin123
# prometheus.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'node-exporter'
static_configs:
- targets: ['node-exporter:9100']
- job_name: 'myapp'
static_configs:
- targets: ['myapp:8080'] # /metrics 엔드포인트
# Node Exporter 설치 (서버 메트릭 수집)
docker run -d \
--name node-exporter \
--pid="host" \
-v "/:/host:ro,rslave" \
prom/node-exporter \
--path.rootfs=/host
PromQL 핵심 쿼리 패턴:
# 초당 요청 수 (5분 평균)
rate(http_requests_total[5m])
# 에러율 (%)
rate(http_requests_total{status=~"5.."}[5m])
/ rate(http_requests_total[5m]) * 100
# P99 응답시간
histogram_quantile(0.99,
rate(http_request_duration_seconds_bucket[5m])
)
# 서비스별 초당 에러 수 비교
sum by (service) (
rate(http_requests_total{status=~"5.."}[5m])
)
# 메모리 사용률 (Node Exporter)
(1 - node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100
알림 규칙 예시:
# alert.rules.yml
groups:
- name: api_alerts
rules:
- alert: HighErrorRate
expr: |
rate(http_requests_total{status=~"5.."}[5m])
/ rate(http_requests_total[5m]) > 0.05
for: 2m
labels:
severity: warning
annotations:
summary: "에러율 5% 초과: {{ $labels.service }}"
description: "현재 에러율: {{ $value | humanizePercentage }}"
pull vs push 방식의 실무 함의: Prometheus는 타깃 서버의
/metrics엔드포인트에 접속해서 데이터를 가져갑니다(pull). 서버가 방화벽으로 인바운드가 모두 막힌 환경이라면 Prometheus가 접속할 수 없습니다. 이 경우 Pushgateway를 중간에 두거나, 아웃바운드만 되는 Datadog agent 방식을 택해야 합니다.
서버에서 "트래픽이 갑자기 늘었다"는 알림을 받았을 때, 무슨 트래픽인지 빠르게 파악해야 합니다. iftop으로 어느 IP가 대역폭을 먹는지 실시간으로 보고, s/d 키로 출발지·목적지 집계를 전환해 범인을 좁힙니다.
iftop — IP별 실시간 대역폭
# 설치
sudo apt install iftop -y
# eth0 인터페이스 모니터링
sudo iftop -i eth0
# IP 대신 호스트명 표시 (-n 끄면 DNS 역조회)
sudo iftop -i eth0
# 특정 포트만 필터
sudo iftop -i eth0 -f "port 443"
# 실행 중 키보드 단축키:
# n — IP/호스트명 전환
# s — 출발지 집계
# d — 목적지 집계
# t — 전송/수신 토글
# p — 포트 표시 토글
# q — 종료
iftop 화면 읽기:
12.5Kb 25.0Kb 37.5Kb 50.0Kb
-----------------------------------------------------------------------
server-01.example.com => 52.95.121.30 3.42Kb 2.87Kb 2.45Kb
<= 1.23Kb 1.01Kb 987b
server-01.example.com => 10.0.0.15 15.3Kb 12.1Kb 8.9Kb
<= 890b 756b 623b
-----------------------------------------------------------------------
TX: cum: 45.2KB peak: 22.4Kb rates: 18.7Kb 14.9Kb 11.3Kb
RX: 12.1KB 8.9Kb 2.1Kb 1.7Kb 1.3Kb
TOTAL: 57.3KB 31.3Kb 20.8Kb 16.6Kb 12.6Kb
=> 아웃바운드, <= 인바운드. 오른쪽 세 숫자는 2초/10초/40초 평균입니다.
sudo iftop -i eth0- 화면에서 대역폭이 가장 큰 행의 상대 IP를 먼저 본다 — 그 IP가 외부 공인 IP면 외부 유입/유출, 10.x·172.16~31.x·192.168.x면 내부 통신이다
- =>(아웃바운드)가 큰지 <=(인바운드)가 큰지 구분 — 아웃바운드 급증은 데이터 유출·대량 응답, 인바운드 급증은 트래픽 폭주/공격 가능성
- 오른쪽 세 숫자 중 첫 값(2초 평균)이 치솟고 셋째(40초)는 낮으면 방금 시작된 스파이크 — 지속/일시 여부를 이 추세로 판단
- -f "port 443" 으로 좁혔을 때 트래픽이 사라지면 해당 포트가 원인이 아니다 — 포트를 바꿔가며 범위를 좁힌다
nload — 전체 대역폭 현황
# 설치 후 실행
sudo apt install nload -y
nload eth0
# 여러 인터페이스 동시 확인 (화살표 키로 전환)
nload
# 단위 변경 (기본 kbit/s)
nload -u h # human-readable
vnstat — 누적 트래픽 통계
이 명령은 실행 중인 서비스 상태를 바꿔 순간적인 중단이나 설정 반영 실패를 만들 수 있습니다. 운영 트래픽 영향과 재시작 후 확인 명령을 먼저 준비하세요.
# 설치 및 초기화
sudo apt install vnstat -y
sudo systemctl enable --now vnstat
# 오늘/이번 달 사용량
vnstat -d # 일별
vnstat -m # 월별
vnstat -h # 시간별
vnstat -l # 라이브 (nload와 유사)
# 특정 인터페이스
vnstat -i eth0 -m
이상 트래픽 추적 워크플로우
# 1. 어떤 IP가 많은 트래픽을 쓰는지 확인 (iftop)
sudo iftop -i eth0
# 2. 의심 IP가 보이면, 어느 프로세스가 연결을 만들었는지 확인
ss -tnp | grep "52.95.121.30"
# 또는
netstat -tnp | grep "52.95.121.30"
# 출력: tcp ESTABLISHED 10.0.0.5:52341 52.95.121.30:443 users:(("node",pid=1234,fd=12))
# 3. PID로 프로세스 확인
ps aux | grep 1234
ls -la /proc/1234/exe # 실행 파일 경로
# 4. 해당 프로세스가 열고 있는 모든 연결
ss -tnp | grep "pid=1234"
상황: Prometheus가 타깃 서버의 /metrics를 수집하지 못합니다.
원인 1 — 타깃 서버에서 exporter가 실행 중이지 않음:
이 명령은 실행 중인 서비스 상태를 바꿔 순간적인 중단이나 설정 반영 실패를 만들 수 있습니다. 운영 트래픽 영향과 재시작 후 확인 명령을 먼저 준비하세요.
# 타깃 서버에서 확인
ss -tlnp | grep 9100 # node-exporter 포트
# 아무것도 나오지 않으면 exporter가 꺼진 것
# 재시작
sudo systemctl start node-exporter
sudo systemctl status node-exporter
원인 2 — 방화벽이 9100 포트 차단:
이 명령은 방화벽 정책을 변경해 현재 접속 중인 세션이나 운영 트래픽에 즉시 영향을 줄 수 있습니다. 적용 전 허용 대상 IP·포트와 롤백 명령을 확인하세요.
# Prometheus 서버에서 직접 테스트
curl http://TARGET_IP:9100/metrics
# 타깃 서버 방화벽 확인
sudo ufw status
sudo firewall-cmd --list-all
# 9100 포트 열기 (Ubuntu)
sudo ufw allow from PROMETHEUS_IP to any port 9100
원인 3 — prometheus.yml의 타깃 주소 오타:
# Prometheus 웹 UI → Status → Targets 에서 실제 연결 시도 주소 확인
# http://localhost:9090/targets
# 설정 파일 확인
cat prometheus.yml | grep -A5 "static_configs"
상황: CloudWatch 콘솔에서 메트릭을 보려 하는데 "No data" 상태입니다.
원인 1 — EC2 메모리/디스크 메트릭 (CloudWatch Agent 미설치):
이 명령은 실행 중인 서비스 상태를 바꿔 순간적인 중단이나 설정 반영 실패를 만들 수 있습니다. 운영 트래픽 영향과 재시작 후 확인 명령을 먼저 준비하세요.
# AWS 기본 제공 메트릭은 CPU, 네트워크, 디스크 I/O만 포함
# 메모리, 디스크 사용률은 Agent 필요
# Agent 상태 확인
sudo systemctl status amazon-cloudwatch-agent
# Agent 시작
sudo systemctl start amazon-cloudwatch-agent
# 로그 확인
sudo tail -f /opt/aws/amazon-cloudwatch-agent/logs/amazon-cloudwatch-agent.log
원인 2 — IAM 권한 부족:
# EC2 인스턴스 역할에 CloudWatchAgentServerPolicy 있는지 확인
aws iam list-attached-role-policies \
--role-name YOUR_EC2_ROLE_NAME
# 없으면 추가
aws iam attach-role-policy \
--role-name YOUR_EC2_ROLE_NAME \
--policy-arn arn:aws:iam::aws:policy/CloudWatchAgentServerPolicy
원인 3 — Namespace/MetricName 불일치:
# Agent 설정에서 namespace 확인
grep "namespace" /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.json
# CLI로 실제 수집된 메트릭 목록 확인
aws cloudwatch list-metrics --namespace "MyApp/System"
심화 — 카디널리티 폭발: 라벨 하나가 시계열을 곱한다
심화: 카디널리티 — Prometheus의 메모리·쿼리를 좌우하는 진짜 축
Prometheus가 스크레이프 대상도 늘지 않았는데 메모리가 계속 차오르고 쿼리가 느려진다면, 원인은 수집 빈도가 아니라 시계열 카디널리티입니다. 관측 도구가 관측 대상보다 무거워지는 함정입니다.
- 시계열은 라벨 조합마다 하나씩 생긴다:
http_requests_total하나라도method·status·path라벨의 조합마다 별개의 시계열이 됩니다.path에 사용자 ID·주문 ID 같은 무한히 다양한 값이 들어가면 시계열 수가 폭발합니다. - 카디널리티가 메모리를 지배한다: Prometheus는 활성 시계열의 최근 데이터를 메모리(head block)에 들고 있습니다. 그래서 스케일의 1차 한계는 스크레이프 양이 아니라 동시에 살아 있는 시계열 수입니다. 고카디널리티 라벨 하나가 head series를 수십만·수백만으로 불립니다.
- 증상: 메모리가 우상향하다 OOM으로 재시작을 반복하고, 범위 쿼리가 타임아웃 나며, 컴팩션이 밀립니다. 대상 수는 그대로인데 말입니다.
- 피하는 법:
user_id·request_id·전체 URL 경로처럼 값이 무한한(unbounded) 라벨을 메트릭 라벨로 쓰지 않습니다. 경로는/order/:id처럼 템플릿으로 정규화하고, 무거운 집계는 recording rule로 미리 굴려 쿼리 시 카디널리티를 낮춥니다. 상세한 개별 값은 메트릭이 아니라 로그·트레이스가 담당할 몫입니다.
상황: 새 서비스나 타깃을 추가하지 않았는데도 Prometheus의 메모리 사용량이 우상향하다 한계에서 죽고 재시작되기를 반복합니다. Grafana 패널도 로딩이 느려집니다.
원인: 어떤 메트릭에 고카디널리티 라벨이 붙어 시계열 수가 폭증했습니다. 대개 최근 배포에서 path·user_id·request_id 같은 값을 라벨로 넣기 시작한 것이 원인이며, 값 종류가 늘수록 시계열이 곱으로 증가합니다.
진단: 웹 UI의 TSDB Status(/status/tsdb)에서 head series 수와 카디널리티 상위 메트릭·라벨을 확인합니다. topk(10, count by (__name__)({__name__=~".+"}))로 시계열이 많은 메트릭을 찾고, scrape_series_added로 급증 시점을 짚습니다. 급증한 메트릭의 라벨을 열어 값이 무한한 라벨을 특정합니다.
해결: 문제 라벨을 metric_relabel_configs로 드롭하거나 경로를 템플릿으로 정규화해 카디널리티를 낮춥니다. 자주 쓰는 집계는 recording rule로 미리 만들어 쿼리 부하를 줄이고, 개별 식별자는 로그·트레이스로 옮깁니다. 재발 방지로 head series 수에 알람을 겁니다.
시나리오: 서비스 성능 저하 대응 — 모니터링 3요소 활용
새벽 2시, PagerDuty 알림이 울렸습니다. Prometheus 알림: "결제 API P99 응답시간 4초 초과 (정상: 200ms)".
1단계 — 메트릭으로 범위 파악 (2분 이내):
Grafana 대시보드를 열고 결제 서비스, DB, 외부 PG(Payment Gateway) 메트릭을 동시에 확인합니다. histogram_quantile(0.99, rate(http_request_duration_seconds_bucket{service="payment"}[5m])) 그래프에서 03:47부터 급증한 것을 확인. DB 메트릭은 정상, 외부 PG 호출 시간이 3.8초로 폭등.
2단계 — 로그로 확인 (5분 이내): CloudWatch Logs Insights:
fields @timestamp, pg_response_time, error_code
| filter service = "payment" and pg_response_time > 1000
| sort @timestamp desc
| limit 100
결과: 특정 카드사 API가 03:47부터 타임아웃 반환 중. error_code=TIMEOUT 패턴.
3단계 — 조치:
- 해당 카드사를 일시 비활성화 (서킷브레이커 발동)
- 담당 팀 에스컬레이션
- 30분 후 카드사 측 장애 복구 확인 후 복원
모니터링 시스템이 없었다면 사용자 신고 접수 → 원인 추적 → 조치까지 최소 30-40분 걸렸을 상황을 6분 만에 처리했습니다.
실무 모니터링 스택 선택 기준:
| 상황 | 권장 |
|---|---|
| AWS 인프라 중심, 빠른 시작 | CloudWatch + CloudWatch Agent |
| 멀티클라우드 or 온프레미스 포함 | Datadog (agent push) |
| 쿠버네티스 환경, 자체 구축 | Prometheus + Grafana |
| 소규모, 비용 최소화 | Prometheus + Grafana (오픈소스) |
| 분산 트레이싱 필요 | Jaeger or AWS X-Ray 추가 |
대부분의 팀은 CloudWatch(기본 인프라) + Prometheus/Grafana(앱 메트릭) 조합을 사용합니다. Datadog은 All-in-one이지만 비용이 상당합니다.
다음 모듈에서는 온프레미스 네트워크 개념이 AWS VPC, 서브넷, 인터넷 게이트웨이로 어떻게 매핑되는지 다룹니다.
클라우드 차원의 관측·알림·멀티계정 거버넌스를 지표·로그·추적으로 체계화하는 방법은 관측과 거버넌스(Cloud Engineering 트랙)에서 다룹니다.
명령어·단축키 빠른 참조
이 모듈에서 다룬 실시간 트래픽 진단·모니터링 명령을 실전 옵션과 함께 모았습니다. "예" 열의 조합을 그대로 써도 됩니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
iftop -i | IP별 실시간 대역폭 진단 | sudo iftop -i eth0 -f "port 443" |
iftop 키 s/d/n | 출발지·목적지 집계·이름 전환 | s=출발지, d=목적지, n=IP/호스트명 토글 |
nload | 인터페이스 전체 대역폭(상·하행) | nload eth0 / nload -u h (human) |
vnstat | 누적 트래픽 통계(일/월/시) | vnstat -d / vnstat -m / vnstat -l (라이브) |
ss -tnp | 특정 IP 연결의 프로세스 찾기 | ss -tnp | grep 52.95.121.30 (범인 PID) |
ss -tlnp | exporter 포트 LISTEN 확인 | ss -tlnp | grep 9100 (node-exporter) |
netstat -tnp | ss 대체(연결↔프로세스 매핑) | netstat -tnp | grep <IP> |
curl <target>:9100/metrics | Prometheus 수집 대상 직접 확인 | connection refused=exporter 꺼짐/방화벽 |
aws cloudwatch put-metric-alarm | 임계값 알람 생성 | --metric-name TargetResponseTime --statistic p99 --threshold 1.0 |
aws cloudwatch list-metrics | 실제 수집된 메트릭 확인 | --namespace "MyApp/System" (No data 진단) |
rate(...[5m]) (PromQL) | 초당 증가율(에러율·요청수) | rate(http_requests_total{status=~"5.."}[5m]) |
histogram_quantile(...) (PromQL) | P99 등 분위수 응답시간 | histogram_quantile(0.99, rate(...bucket[5m])) |