서버가 죽었다는 신고가 들어왔지만 HTTP만 실패하는지 네트워크 자체가 끊긴 건지 아직 모릅니다. 가장 먼저 ICMP로 왕복 가능성과 지연, 손실을 확인해야 합니다.
ping은 만능 진단 도구는 아니지만 첫 번째 분기점입니다. 성공과 실패가 의미하는 범위를 정확히 알아야 합니다.
ping과 ICMP — 네트워크 생사 확인
네트워크 문제가 발생했을 때 가장 먼저 실행하는 명령어는 ping입니다. 단 한 줄로 "저쪽 서버가 살아 있나?" 를 확인할 수 있기 때문입니다. 하지만 ping이 실패했다고 해서 서버가 죽은 것이 아닐 수 있고, ping이 성공했다고 해서 서비스가 정상인 것도 아닙니다. 이 챕터에서는 ICMP 프로토콜의 원리를 이해하고, ping 결과를 정확하게 해석하는 방법을 배웁니다.
ICMP 프로토콜 원리
- 1ICMP 프로토콜이 OSI 3계층(네트워크 계층)에서 하는 역할을 설명할 수 있다
- 2Echo Request(Type 8)와 Echo Reply(Type 0)의 ping 동작 원리를 이해할 수 있다
- 3RTT(왕복 지연 시간) 수치를 기준치와 비교해 해석할 수 있다
- 4Packet Loss와 mdev(지터)를 분석할 수 있다
- 5ping의 한계인 ICMP 차단 케이스를 이해하고 L4/L7 확인 도구로 보완할 수 있다
- 6클라우드 환경에서 ICMP 방화벽 정책을 처리할 수 있다
ping -c 4 8.8.8.8ping -c 4 google.comping -c 4 -s 1400 8.8.8.8클라우드 환경(AWS 등)은 보안 그룹에서 ICMP를 명시적으로 허용해야 ping 응답이 가능
ICMP란 무엇인가 — L3 진단 메시지 프로토콜
ping google.com이 안 됩니다. 그런데 curl https://google.com은 됩니다. AWS에서는 ping이 아무 응답도 없습니다. 네트워크가 문제인지, 보안 그룹이 문제인지, 프로토콜이 막힌 건지 알 수 없습니다. ICMP가 어떤 프로토콜이고 TCP/UDP와 어떻게 다른지 알아야 이런 상황에서 "ping 실패 = 네트워크 단절"이 아니라는 판단을 할 수 있습니다.
 확대
확대
**ICMP(Internet Control Message Protocol)**는 IP 네트워크에서 오류 보고와 진단 정보를 전달하기 위한 프로토콜입니다. TCP나 UDP처럼 애플리케이션 데이터를 운반하는 것이 아니라, 네트워크 계층의 상태를 알리는 제어 메시지를 전달합니다.
OSI 모델에서 ICMP의 위치
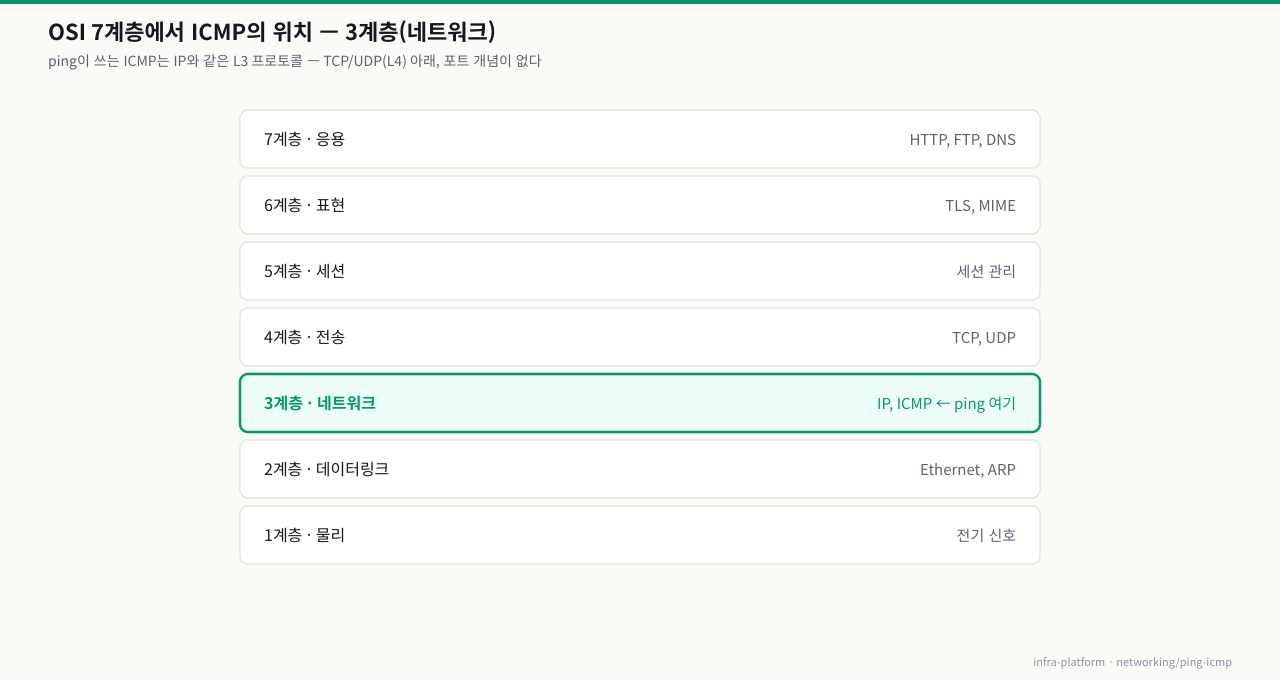 확대
확대
ICMP는 IP와 동일한 3계층에서 동작하며, IP 패킷 안에 캡슐화되어 전송됩니다. IP 헤더의 프로토콜 번호는 1입니다.
ICMP 주요 메시지 타입
| 타입 번호 | 이름 | 용도 |
|---|---|---|
| 0 | Echo Reply | ping 응답 |
| 3 | Destination Unreachable | 목적지 도달 불가 |
| 8 | Echo Request | ping 요청 |
| 11 | Time Exceeded | TTL 초과 (traceroute에서 활용) |
Echo Request / Echo Reply 흐름
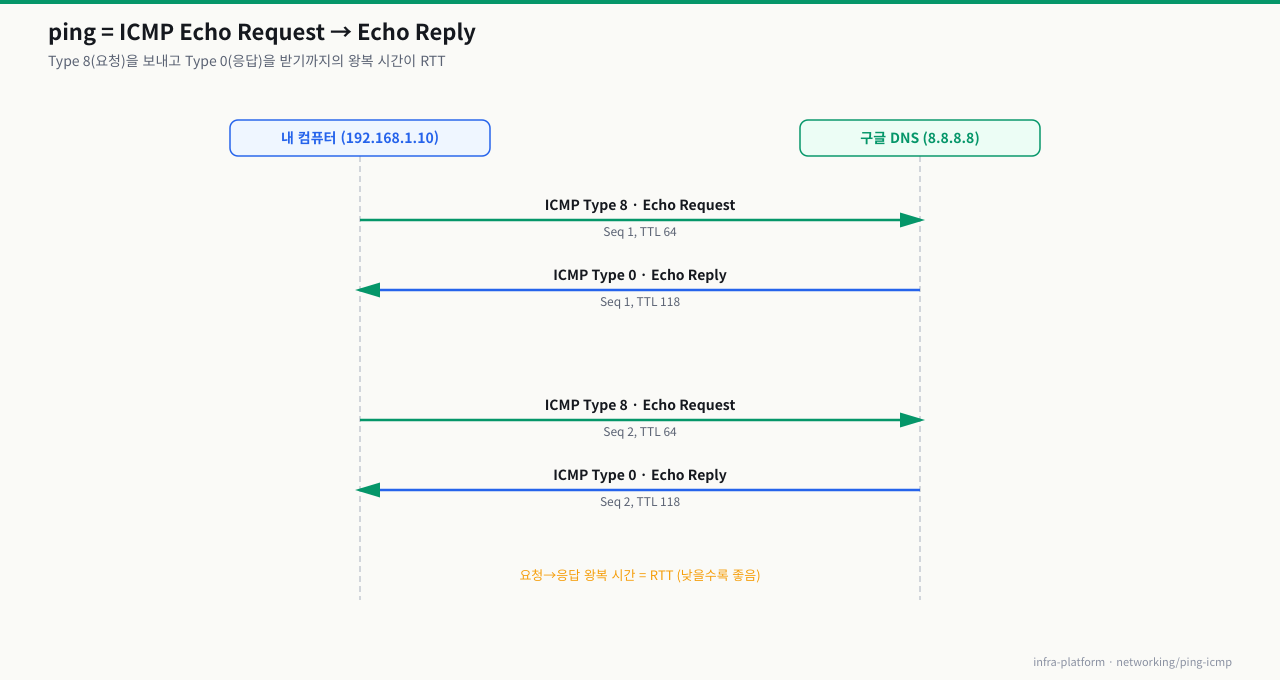 확대
확대
ping을 실행하면 내 컴퓨터는 **Echo Request(Type 8)**를 보내고, 상대방은 **Echo Reply(Type 0)**로 응답합니다. 이 한 쌍의 교환에서 RTT(Round-Trip Time)를 측정합니다.
ping이 실제로 하는 일 — Echo Request 한 발의 왕복 5단계
ping 한 줄을 치면 실제로 무슨 일이 일어나나 — 패킷 발사부터 손실 판정까지 5단계
ping 8.8.8.8 한 줄. Enter를 누르면 잠시 뒤 64 bytes from 8.8.8.8: ... time=31.4 ms가 뜹니다. 이 짧은 순간에 내 커널은 ICMP Echo Request 패킷을 만들어 목적지까지 라우팅하고, 목적지 커널이 Echo Reply로 돌려주며, ping은 보낸 시각과 받은 시각의 차이로 RTT를 계산합니다. 이 흐름을 단계로 알면 "왜 100% 손실이지", "왜 간헐적으로만 빠지지"를 단계별로 좁혀 진단할 수 있습니다.
[내 PC] ping 8.8.8.8
│
① ICMP Echo Request 생성 (Type 8, seq 번호·타임스탬프를 실음)
│
② 라우팅 테이블 조회 → next-hop 결정 (같은 LAN이면 목적지, 아니면 게이트웨이)
│ → next-hop MAC을 ARP로 해석(캐시 없으면 ARP 요청)
│
③ 목적지까지 홉을 거쳐 전달 (라우터마다 TTL 1씩 감소)
│
④ 목적지 커널이 Echo Reply 회신 (Type 0, 같은 seq·데이터 그대로)
│ → 되돌아오는 경로도 홉을 거침
│
⑤ 내 PC가 Reply 수신 → RTT 계산 (받은 시각 − 보낸 시각)
▼
64 bytes from 8.8.8.8: icmp_seq=1 ttl=118 time=31.4 ms
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① Echo Request 생성 | 커널이 ICMP Type 8 패킷에 순번(seq)과 보낸 시각을 실어 만든다 | 로컬 방화벽이 outbound ICMP를 막으면 아예 못 나감 → 전량 손실 |
| ② 라우팅·ARP | 라우팅 테이블로 next-hop을 정하고 그 MAC을 ARP로 해석. 같은 서브넷이면 목적지 직접·아니면 게이트웨이 | ARP 실패(같은 LAN 상대 꺼짐)·게이트웨이 없음 → Destination Host Unreachable 또는 전량 손실 |
| ③ 홉 전달 | 라우터를 지날 때마다 TTL이 1씩 줄며 목적지로 포워딩 | 경로 없음·루프면 라우터가 Time to live exceeded(TTL exceeded) 회신 = 라우팅 루프 신호 |
| ④ Echo Reply 회신 | 목적지 커널이 같은 seq·데이터로 Type 0 응답을 만들어 돌려보냄 | 목적지·경로 방화벽이 ICMP 차단(가장 흔함) → 요청은 갔는데 응답 없음. 100% 손실이어도 서버는 살아있을 수 있음 |
| ⑤ 수신·RTT 계산 | 돌아온 Reply의 seq를 맞춰 왕복 시간 측정, 안 온 seq는 손실로 집계 | 일부 seq만 빠짐 = 간헐 손실(경로 혼잡·큐 넘침) / RTT가 들쭉날쭉 = 지터 |
즉 ping 결과는 이 5단계 중 어디까지 갔는지를 읽는 것입니다. 전량 손실(100%)이면 대개 ④에서 막힌 것 — 요청은 나갔지만 경로나 목적지 방화벽이 ICMP를 버린 경우가 서버 다운보다 흔하므로, 같은 대상에 curl·telnet으로 L4를 함께 찔러 서비스 생사와 구분합니다. 간헐 손실이면 ⑤에서 일부 seq만 빠진 것이라 경로 혼잡을 의심해 mtr로 어느 홉인지 좁히고, Time to live exceeded가 뜨면 ③의 라우팅 루프입니다. 경로 자체를 눈으로 보려면 ping -R(Record Route, 경유 홉을 패킷에 기록 — 다만 많은 라우터가 무시)이나 traceroute로 넘어갑니다.
RTT와 Packet Loss — ping 결과 수치 해석
ping google.com을 쳤더니 응답이 오긴 하는데 가끔 느립니다. 평균 RTT가 200ms인데 이게 정상인지 이상한지 모르겠습니다. Packet Loss 5%가 나왔는데 심각한 건지 일시적인 건지도 판단이 안 됩니다. ping 수치를 해석할 줄 알아야 "네트워크 느리다"는 막연한 증상을 구체적인 문제로 좁힐 수 있습니다.
 확대
확대
RTT (Round-Trip Time)
RTT는 패킷이 출발지에서 목적지까지 갔다가 돌아오는 데 걸린 시간입니다. 단위는 **밀리초(ms)**입니다.
ping -c 4 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=118 time=31.4 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=118 time=30.8 ms
64 bytes from 8.8.8.8: icmp_seq=3 ttl=118 time=32.1 ms
64 bytes from 8.8.8.8: icmp_seq=4 ttl=118 time=31.0 ms
--- 8.8.8.8 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3004ms
rtt min/avg/max/mdev = 30.8/31.3/32.1/0.5 ms
각 항목의 의미:
| 항목 | 값 | 의미 |
|---|---|---|
icmp_seq | 1, 2, 3, 4 | 순서 번호 (빠지면 유실) |
ttl | 118 | 남은 홉 수 (64 또는 128로 시작) |
time | 31.4 ms | 이 패킷의 RTT |
rtt min/avg/max/mdev | 30.8/31.3/32.1/0.5 | 최소/평균/최대/표준편차 |
RTT 기준치 해석
< 1ms : 같은 L2 네트워크 (스위치 내부)
1~5ms : 같은 데이터센터 내
10~30ms : 국내 인터넷 (서울 ↔ 부산)
100ms~ : 해외 인터넷 (한국 ↔ 미국)
500ms~ : 심각한 지연, 사용자 체감 불편
Packet Loss
패킷 손실률은 전체 전송 패킷 대비 응답이 없는 패킷의 비율입니다.
4 packets transmitted, 3 received, 25% packet loss
- 0%: 정상
- 1~5%: 경미한 네트워크 불안정 (무선 환경에서 간헐적으로 발생)
- 5% 이상: 의미 있는 네트워크 품질 문제
- 100%: ICMP 차단 또는 목적지 완전 단절
mdev (평균 편차)가 중요한 이유
mdev가 크면 RTT가 불규칙하게 변동한다는 의미입니다. 평균 RTT가 낮아도 mdev가 크면 **네트워크 지터(jitter)**가 심한 것으로, 실시간 통신(VoIP, 게임) 품질에 문제를 일으킬 수 있습니다.
실습 — ping 분석
가장 기본적인 ping 명령어로 외부 DNS 서버에 연결을 테스트합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/networking/part3/exam_11 && cd /tmp/networking/part3/exam_11
# -c 4: 4개 패킷만 보내고 종료 (무한 루프 방지)
ping -c 4 8.8.8.8
- packet loss — 먼저 확인—0%: 정상. 1% 이하: 허용 범위(무선 환경). 5% 이상: 네트워크 품질 문제(즉시 조사). 100%: ICMP 차단 또는 목적지 단절.
- RTT 판단 기준표—루프백(127.0.0.1): 0.1ms 이하 / 같은 데이터센터·AZ: 1ms 이하 / 같은 리전(수백km): 5~20ms / 대륙 내(한국-일본): 20~50ms / 대륙 간(한국-미국): 150~200ms / 위성 연결: 600ms 이상.
- mdev(표준편차) 판단—mdev 1ms 이하: 안정적. mdev 10ms 이상: 지터 심함(VoIP, 게임 품질 저하). RTT 평균이 낮아도 mdev가 크면 실시간 서비스에 문제 발생.
- DNS 분리—IP ping 성공 + 도메인 ping 실패 → DNS 설정 문제(/etc/resolv.conf 확인). IP ping 실패 → L3 네트워크 문제로 DNS 불필요.
- 조합 해석 — RTT 높음 + loss% 낮음—물리적 거리 또는 네트워크 혼잡에 의한 정상적 지연입니다. 링크 품질 자체는 양호합니다.
- 조합 해석 — RTT 높음 + loss% 높음—링크 품질 문제입니다. 재전송과 지연이 복합적으로 발생합니다. mtr로 어느 홉에서 발생하는지 추적하세요.
- 조합 해석 — RTT 매우 낮음(0.01ms 이하)—루프백으로 응답하는 것입니다. 실제 목적지 서버까지 패킷이 도달하지 않았습니다. 라우팅 문제 또는 로컬호스트 설정 확인이 필요합니다.
예상 출력: 정상 응답 시 이런 형태로 출력됩니다.
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=118 time=31.2 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=118 time=30.9 ms
64 bytes from 8.8.8.8: icmp_seq=3 ttl=118 time=31.5 ms
64 bytes from 8.8.8.8: icmp_seq=4 ttl=118 time=31.1 ms
--- 8.8.8.8 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3003ms
rtt min/avg/max/mdev = 30.9/31.1/31.5/0.2 ms
결과 체크리스트:
-
0% packet loss확인 -
time값이 예상 범위인지 확인 -
icmp_seq번호에 빈 칸이 없는지 확인 (순서 유실)
추가 옵션 실습: -c, -i, -s 옵션으로 ping 동작을 제어합니다.
# -i 0.2: 0.2초 간격으로 전송 (기본 1초)
ping -c 10 -i 0.2 8.8.8.8
# -s 1400: 패킷 크기 1400바이트 (MTU 테스트용)
ping -c 4 -s 1400 8.8.8.8
# -W 1: 응답 대기 시간 1초로 제한
ping -c 4 -W 1 192.168.1.1
IP 주소 대신 도메인 이름으로 ping을 실행하면 DNS 해석이 선행됩니다.
ping -c 4 google.com
예상 출력:
PING google.com (142.250.196.110) 56(84) bytes of data.
64 bytes from kix07s05-in-f14.1e100.net (142.250.196.110): icmp_seq=1 ttl=118 time=32.1 ms
...
중요 관찰 포인트: TTL과 응답 시간(ms)으로 네트워크 상태를 판단합니다.
ping google.com → 성공 (DNS + ICMP 모두 정상)
ping 8.8.8.8 → 성공 / ping google.com 실패 → DNS 문제
ping 8.8.8.8 → 실패 → L3 네트워크 문제
진단 흐름 정리: ping 결과 유형별로 다음 조치가 달라집니다.
IP ping 실패?
YES → 라우팅/물리 연결 문제 (L1~L3 확인)
NO → 도메인 ping 실패?
YES → DNS 설정 문제 (/etc/resolv.conf 확인)
NO → 서비스 포트 문제 가능성 (telnet/curl로 L4 확인)
ping이 성공해도 서비스가 동작하지 않을 수 있습니다. 각 계층별 확인 도구를 사용해야 합니다.
# ping: L3 도달 가능성 확인
ping -c 2 192.168.1.100
# → 성공해도 HTTP 서비스가 죽어있을 수 있음
# telnet: TCP 포트 열려있는지 확인 (L4)
telnet 192.168.1.100 80
# → "Connected" 나오면 80 포트 열려있음
# → "Connection refused" 나오면 포트 닫힘
# curl: HTTP 응답 확인 (L7)
curl -v http://192.168.1.100/
# → HTTP 상태 코드 확인 (200, 404, 500 등)
# nc (netcat): 포트 스캔
nc -zv 192.168.1.100 80 443
계층별 진단 도구 정리: 문제 계층에 맞는 도구를 선택하면 진단 속도가 빨라집니다.
L3 (네트워크): ping, traceroute, mtr
L4 (전송): telnet, nc, nmap
L7 (응용): curl, wget, httpie
트러블슈팅
증상
웹 브라우저로 서버에 접속되고 SSH도 되는데, ping만 응답이 없습니다.
ping -c 4 my-server.example.com
# PING my-server.example.com (203.0.113.10): 56 data bytes
# Request timeout for icmp_seq 0
# Request timeout for icmp_seq 1
# Request timeout for icmp_seq 2
# Request timeout for icmp_seq 3
# --- my-server.example.com ping statistics ---
# 4 packets transmitted, 0 packets received, 100.0% packet loss
하지만 서비스는 살아있습니다:
curl -I http://my-server.example.com
# HTTP/1.1 200 OK
# ...
원인
ICMP 패킷이 방화벽이나 보안 정책에 의해 차단되고 있습니다.
클라우드 환경 (AWS 예시): AWS Security Group에서 ICMP를 명시적으로 허용해야 합니다.
AWS 보안 그룹 인바운드 규칙 확인:
- HTTP (80): 0.0.0.0/0 허용 ← 웹은 됨
- SSH (22): 내 IP 허용 ← SSH는 됨
- ICMP: (규칙 없음) ← ping 안 됨!
리눅스 OS 방화벽 (iptables/firewalld): 호스트 자체 방화벽이 ICMP를 차단하는 경우입니다.
# 현재 iptables 규칙 확인
sudo iptables -L -n | grep icmp
# firewalld 확인
sudo firewall-cmd --list-all | grep icmp
해결책
AWS 보안 그룹에서 ICMP 허용: 보안 그룹 인바운드 규칙에 다음을 추가합니다:
- 유형:
All ICMP - IPv4 - 소스:
0.0.0.0/0(또는 특정 IP)
리눅스 iptables에서 ICMP 허용: 인바운드 ICMP echo-request를 허용하는 규칙입니다.
이 명령은 방화벽 정책을 변경해 현재 접속 중인 세션이나 운영 트래픽에 즉시 영향을 줄 수 있습니다. 적용 전 허용 대상 IP·포트와 롤백 명령을 확인하세요.
# ICMP Echo Request 허용
sudo iptables -A INPUT -p icmp --icmp-type echo-request -j ACCEPT
sudo iptables -A OUTPUT -p icmp --icmp-type echo-reply -j ACCEPT
firewalld에서 ICMP 허용: firewalld를 사용하는 RHEL 계열 설정 방법입니다.
이 명령은 방화벽 정책을 변경해 현재 접속 중인 세션이나 운영 트래픽에 즉시 영향을 줄 수 있습니다. 적용 전 허용 대상 IP·포트와 롤백 명령을 확인하세요.
sudo firewall-cmd --add-icmp-block-inversion --permanent
sudo firewall-cmd --reload
# 또는 특정 존에만 허용
sudo firewall-cmd --zone=public --remove-icmp-block=echo-request --permanent
중요 원칙
ping 실패 ≠ 서버 다운
ping 성공 ≠ 서비스 정상
ping은 ICMP(L3) 도달 가능성만 확인합니다.
서비스 가용성은 해당 프로토콜(L4~L7)로 직접 확인해야 합니다.
증상
대부분의 ping은 성공하지만 간헐적으로 유실됩니다.
ping -c 20 192.168.1.1
# ...
# 20 packets transmitted, 17 received, 15% packet loss
# rtt min/avg/max/mdev = 0.5/2.3/45.2/9.8 ms
mdev가 9.8ms로 크고 최대 RTT가 45.2ms로 튀었습니다.
원인 분석
# 더 긴 시간 동안 모니터링
ping -c 100 -i 0.5 192.168.1.1
# mtr로 각 홉별 패킷 손실 위치 특정
mtr --report --report-cycles 20 8.8.8.8
mtr 출력 예시: 각 홉의 패킷 손실률과 지연 시간을 한 번에 볼 수 있습니다.
HOST: myserver Loss% Snt Last Avg Best Wrst StDev
1. 192.168.1.1 0.0% 20 0.6 0.7 0.5 1.1 0.2
2. 10.0.0.1 0.0% 20 5.2 5.1 4.8 5.9 0.3
3. 203.0.113.1 15.0% 20 8.3 12.4 7.1 45.2 9.8 ← 여기서 손실!
4. 8.8.8.8 0.0% 20 31.2 31.1 30.8 31.6 0.2
3번 홉에서 15% 손실이 발생하고 있습니다. 이 구간의 라우터나 링크에 문제가 있습니다.
해결 방향
- ISP 구간 문제: 인터넷 서비스 제공업체에 장애 신고
- 스위치/라우터 문제: 해당 장비의 인터페이스 에러 카운터 확인
- 무선 환경: 채널 간섭, 신호 약화 확인 (
iwconfig,iwlist)
심화 — mtr 중간 홉의 손실에 속지 마라
심화: ICMP는 특별 대우를 받지 않는다 — 중간 홉 손실의 착시
mtr에서 경로 중간 홉에 빨간 손실이 뜨면 '저기가 범인'이라 결론짓기 쉽지만, 그 손실은 진짜 장애가 아니라 라우터가 ICMP를 홀대한 흔적일 때가 더 많습니다. ping·traceroute·mtr이 의존하는 ICMP가 라우터에서 어떻게 처리되는지 알아야 오진과 잘못된 ISP 신고를 피합니다.
- 라우터는 통과 트래픽과 자기에게 온 트래픽을 다르게 처리한다: 데이터 포워딩은 하드웨어(빠른 경로)로 처리하지만, 자신을 목적지로 하는 ICMP(에코, TTL 만료 응답)는 CPU(제어 평면, 느린 경로)로 올려 처리하고 rate-limit을 겁니다.
- 그래서 중간 홉 손실·지연은 과장된다: mtr 중간 홉의 손실률·RTT는 '그 라우터가 ICMP 응답을 얼마나 후순위로 미뤘나'를 반영할 뿐, 실제 데이터 포워딩 성능이 아닙니다.
- 진짜 손실을 구별하는 규칙: 중간 홉에서 손실이 보여도 그 다음 홉·최종 목적지의 손실이 0이면 무시해도 됩니다(ICMP 홀대). 반대로 손실이 어떤 홉부터 끝까지 계속 이어지면 그 지점이 진짜 문제입니다.
- 목적지(끝 홉)의 손실만이 서비스 품질을 말한다: 최종 홉의 손실률·지터가 실제 사용자 경험과 직결됩니다. 중간 홉 숫자에 휘둘리지 마세요.
즉 mtr을 읽을 때는 '어느 홉이 빨간가'가 아니라 '손실이 목적지까지 전파되는가'를 봐야 합니다.
상황
특정 서비스가 느리다는 신고에 mtr을 돌렸더니 경로 중간(3번 홉)이 20% 손실로 빨갛게 표시됩니다. "저 홉이 범인"이라며 ISP에 신고하려는데, 정작 그 아래 홉들과 최종 목적지는 손실 0%입니다.
원인
3번 홉 라우터가 자신을 향한 ICMP(TTL 만료 알림)를 제어 평면에서 rate-limit한 것입니다. 통과하는 실제 데이터는 하드웨어 빠른 경로로 정상 포워딩되므로, 그 뒤 홉과 목적지에는 손실이 없습니다. 3번의 20%는 '그 라우터가 ICMP 응답을 후순위로 미룬 흔적'이지 데이터 손실이 아닙니다.
진단
# 표본을 늘려 손실이 지속되는지, 산발적인지 확인
mtr --report --report-cycles 100 8.8.8.8
손실이 특정 홉에서만 반짝하고 다음 홉부터 0으로 돌아오면 착시입니다. 진짜 손실이라면 문제 홉부터 최종 목적지까지 손실이 이어집니다.
해결
중간 홉 손실이 목적지로 전파되지 않으면 정상으로 판단하고, 다른 원인(애플리케이션·L4/L7)을 찾습니다. 목적지까지 손실이 이어질 때만 그 첫 손실 홉을 근거로 경로·ISP 문제를 제기합니다. ICMP를 홀대하는 홉을 '장애'로 오인해 엉뚱한 곳에 신고하지 않는 것이 핵심입니다.
실무 맥락
장애 대응 시 첫 번째 확인
서버 모니터링 알람이 울렸을 때 인프라 엔지니어의 첫 번째 행동은 ping입니다.
# 1단계: 네트워크 도달 가능성 확인
ping -c 4 prod-web-01.internal
# → 실패하면 네트워크/전원 문제
# → 성공하면 서비스 레이어 문제
# 2단계: 서비스 포트 확인
curl -s -o /dev/null -w "%{http_code}" http://prod-web-01.internal/health
# → 200이면 서비스 정상
# → 타임아웃이면 애플리케이션 문제
# 3단계: 여러 서버 동시 확인 (배시 루프)
for host in web-01 web-02 web-03; do
ping -c 1 -W 1 ${host}.internal > /dev/null 2>&1 \
&& echo "${host}: UP" \
|| echo "${host}: DOWN"
done
SLA 모니터링에서의 RTT
클라우드 서비스에서는 리전 간 레이턴시가 SLA에 영향을 줍니다.
# 서울 → 도쿄 리전 레이턴시
ping -c 10 ap-northeast-1.aws.example.com
# 약 30~35ms가 정상
# 서울 → 버지니아 리전 레이턴시
ping -c 10 us-east-1.aws.example.com
# 약 180~200ms가 정상
모니터링 시스템에서의 ICMP 활용
Prometheus + Blackbox Exporter를 사용하면 ping을 지속적으로 모니터링하고 알람을 설정할 수 있습니다.
# blackbox.yml 예시
modules:
icmp_check:
prober: icmp
timeout: 5s
icmp:
preferred_ip_protocol: ip4
현업에서 알아두면 좋은 것들
- 클라우드 환경에서 ICMP는 기본 차단: AWS, GCP, Azure 모두 보안 그룹에서 명시적으로 허용해야 ping이 됩니다.
- ping 성공 = 서비스 가용성이 아님: 장애 원인 파악은 L4~L7까지 계층별로 내려가야 합니다.
- 대용량 트래픽 경고: 프로덕션 서버에
ping -f(flood ping)는 절대 사용하지 마세요. 네트워크 부하를 유발합니다. - 방화벽 정책 문서화: ICMP 허용/차단 정책을 팀 Wiki에 명확히 기록해두면 장애 시 빠른 판단이 가능합니다.
정리
이 챕터에서 배운 핵심 내용입니다.
ICMP (L3 프로토콜)
- Echo Request (Type 8): ping 보내기
- Echo Reply (Type 0): ping 응답
- 기타: Destination Unreachable, Time Exceeded
ping 결과 해석
- RTT: 왕복 지연 시간 (낮을수록 좋음)
- Packet Loss: 유실률 (0%가 정상)
- mdev: 지터 (낮을수록 안정적)
ping 한계
- ICMP 차단 = ping 실패 ≠ 서버 다운
- ping 성공 ≠ L4/L7 서비스 정상
계층별 진단 도구
- L3: ping, traceroute, mtr
- L4: telnet, nc, nmap
- L7: curl, wget
명령어·단축키 빠른 참조
이 모듈에서 다룬 ping·ICMP 경로 진단 명령을 실전 옵션과 함께 모았습니다. "예" 열의 조합을 그대로 써도 됩니다.
| 명령어/옵션 | 용도 | 자주 쓰는 예 |
|---|---|---|
ping -c <N> | 지정 횟수만 보내고 종료(무한 방지) | ping -c 4 8.8.8.8 |
ping -i <초> | 전송 간격 조절(촘촘히 관찰) | ping -c 10 -i 0.2 8.8.8.8 |
ping -s <바이트> | 패킷 크기 지정(MTU 테스트) | ping -c 4 -s 1400 8.8.8.8 |
ping -W <초> | 응답 대기(타임아웃) 제한 | ping -c 4 -W 1 192.168.1.1 |
mtr --report | 홉별 손실·지연 위치 추적 | mtr --report --report-cycles 100 8.8.8.8 |
traceroute <host> | 목적지까지 경로(홉) 추적 | traceroute 8.8.8.8 |
telnet <host> <port> | 포트 열림(L4) 확인 — ping 보완 | telnet 192.168.1.100 80 |
nc -zv <host> <ports> | 데이터 없이 포트 스캔(L4) | nc -zv 192.168.1.100 80 443 |
curl -I <url> | 서비스 응답(L7) 확인 | curl -I http://my-server.example.com |
iptables … --icmp-type echo-request | 호스트 방화벽에서 ICMP 허용 | sudo iptables -A INPUT -p icmp --icmp-type echo-request -j ACCEPT |
firewall-cmd --list-all | firewalld의 ICMP 차단 여부 확인 | sudo firewall-cmd --list-all | grep icmp |
관련 모듈로 더 깊이:
- traceroute와 mtr로 해외망/사내망 패킷 병목 지점 찾기 — ping이 실패한 지점을 경로 단위로 추적해 어디서 끊겼는지 찾는 법
- OSI 7계층과 TCP/IP 4계층 모델 실무적 관점 분석 — ping이 검증하는 L3와 상위 계층의 차이를 모델로 이해하기
- telnet과 nc(netcat) 명령어로 L4 포트 통신 상태 점검 — ping은 되는데 서비스가 안 될 때 L4 포트를 확인하는 법
다음 챕터에서는 traceroute를 사용하여 패킷이 목적지까지 어떤 경로를 거치는지 추적하는 방법을 배웁니다.