컨테이너 안에서는 API가 정상인데 호스트에서는 8080 접속이 실패합니다. Docker 네트워크, 포트 바인딩, iptables NAT, Kubernetes Service가 한꺼번에 얽혀 있어 어디서 끊겼는지 보이지 않습니다.
컨테이너 네트워크 장애는 레이어를 나눠 보면 패턴이 있습니다. 컨테이너 내부, 호스트 포트, 서비스 규칙을 차례로 확인해야 합니다.
컨테이너 네트워크 디버깅 — Docker & Kubernetes
docker-compose up을 실행했는데 API 서버에서 DB로 연결이 안 됩니다. 두 컨테이너 모두 실행 중이고, 포트도 맞고, 코드도 어제까지 잘 됐는데 — 갑자기 connection refused입니다. 서버 네트워크라면 ping과 nc로 빠르게 진단하겠지만, 컨테이너 안에는 도구가 없고 어디서부터 봐야 할지 막막합니다. 컨테이너 네트워크는 가상 브릿지, 내장 DNS, 네임스페이스 격리 등 여러 추상화 계층이 쌓여있어 베어메탈 장애와는 다른 접근이 필요합니다. 이 챕터에서는 Docker와 Kubernetes 양쪽에서 통신 장애가 발생했을 때 5분 안에 원인을 특정하는 체계적인 방법을 배웁니다.
학습 목표
- 1Docker bridge 네트워크 구조를 이해하고 docker network inspect, ip addr로 현재 상태를 파악할 수 있다
- 2컨테이너 간 통신 / 호스트→컨테이너 / 컨테이너→외부 각 경로의 차이를 이해할 수 있다
- 3K8s ClusterIP → NodePort → LoadBalancer 타입별 네트워크 경로를 추적할 수 있다
- 4kubectl exec, kubectl port-forward로 Pod 내부를 직접 점검할 수 있다
- 5docker-compose 네트워크 이름 충돌과 --network 누락 시나리오를 진단할 수 있다
- 6dial tcp lookup 127.0.0.11:53 no such host 실제 에러의 원인을 분석하고 해결할 수 있다
docker info | grep 'Server Version'docker network create debug-netdocker pull busybox:latestkubectl config current-contextmkdir -p /tmp/container-net-debug && cd /tmp/container-net-debug1. Docker bridge 네트워크 구조
Docker 네트워크는 어떻게 생겼는가
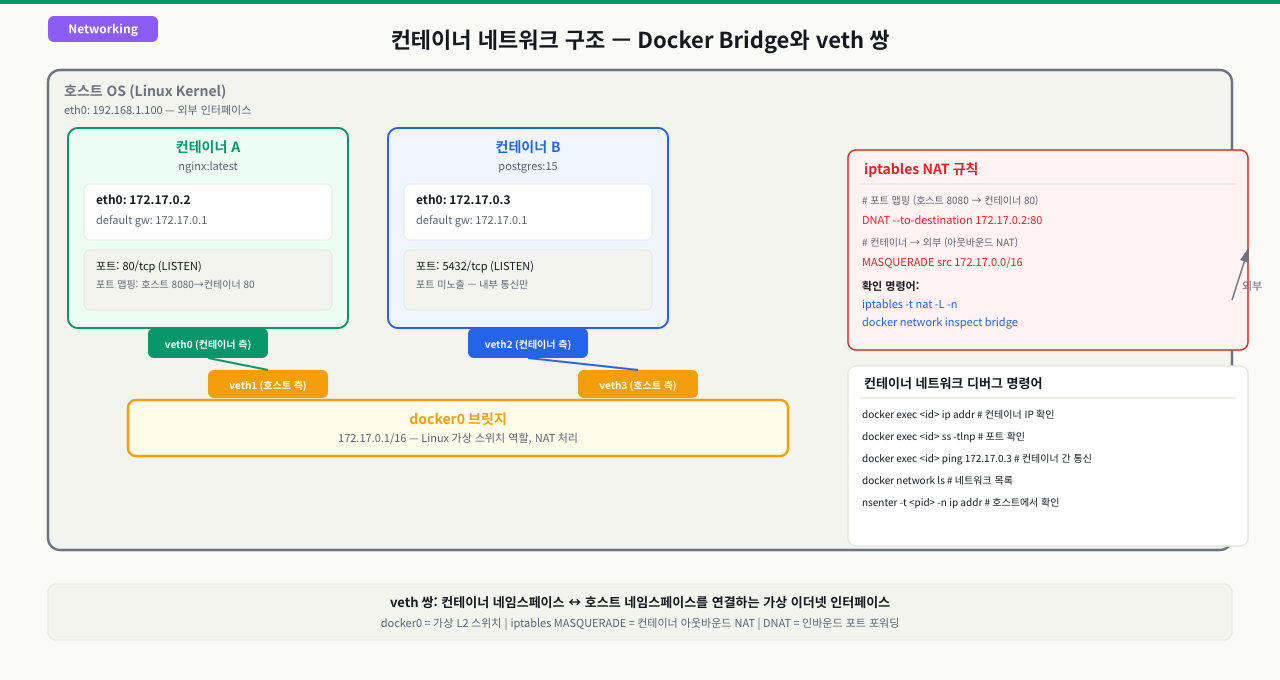
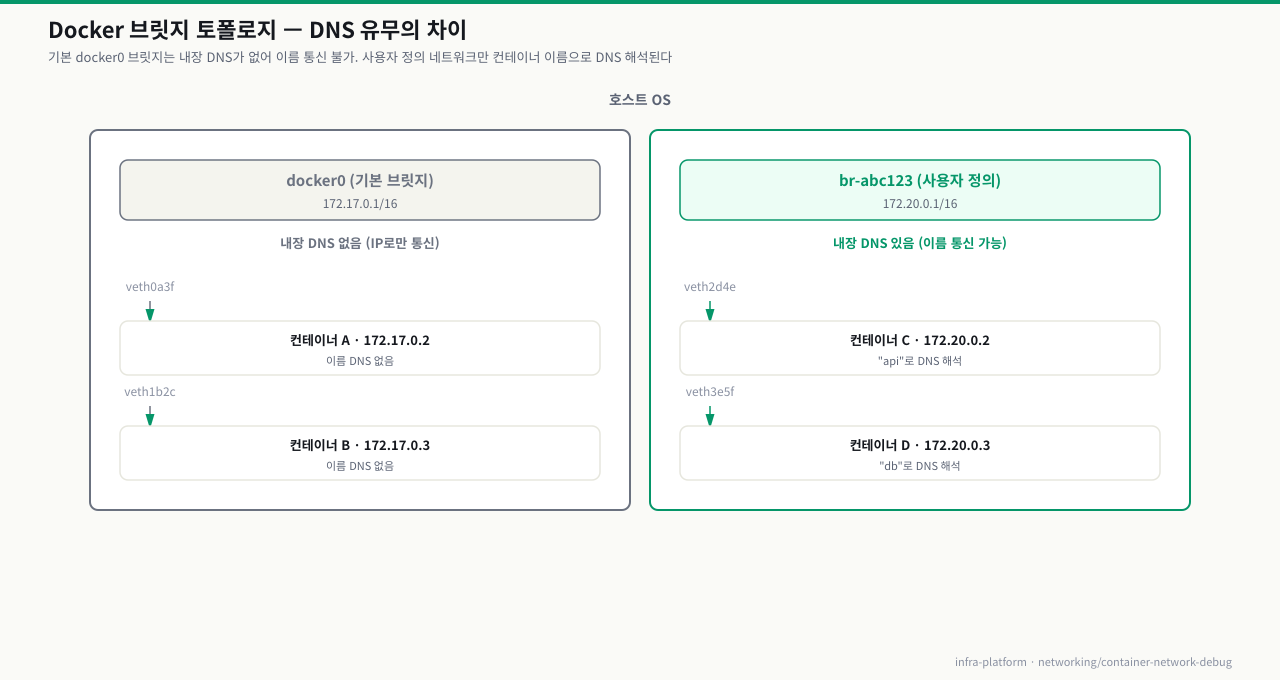
컨테이너가 시작될 때 Docker는 각 컨테이너를 **가상 네트워크 인터페이스(veth pair)**로 호스트의 bridge에 연결합니다. 이 bridge가 같은 네트워크 안의 컨테이너들을 연결하는 가상 스위치 역할을 합니다. 이름으로 서로를 찾을 수 있는 건 Docker가 제공하는 내장 DNS 서버(127.0.0.11) 덕분입니다 — 사용자 정의 네트워크에서만 작동합니다.
 확대
확대
 확대
확대
핵심 차이: 기본 docker0 브릿지는 내장 DNS를 제공하지 않습니다. docker network create로 만든 사용자 정의 네트워크에서만 컨테이너 이름으로 통신할 수 있습니다.
네트워크 현황 파악 — 첫 번째 진단 명령
# 실습 디렉토리 준비
mkdir -p /tmp/networking/part6/exam_34 && cd /tmp/networking/part6/exam_34
# 현재 Docker 네트워크 목록
docker network ls
# NETWORK ID NAME DRIVER SCOPE
# a1b2c3d4e5f6 bridge bridge local ← 기본(docker0)
# b2c3d4e5f6a7 debug-net bridge local ← 사용자 정의
# c3d4e5f6a7b8 host host local
# d4e5f6a7b8c9 none null local
# 특정 네트워크 상세 조회 — 핵심 진단 명령
docker network inspect debug-net
- Containers 항목을 먼저 보고, 통신해야 할 두 컨테이너 이름이 모두 나오는지 확인한다 — 한쪽이 빠져 있으면 네트워크 분리가 원인
- Subnet 값 확인: 두 컨테이너의 IPv4Address가 같은 /16 또는 /24 대역인지 확인 — 대역이 다르면 직접 통신 불가
- Containers가 있는데도 ping 실패 → 이름으로 접근 실패 → IP로는 성공이면 DNS 문제(사용자 정의 네트워크인지 확인); IP도 실패이면 네트워크 자체 단절
docker network inspect 출력에서 봐야 할 세 가지:
{
"Name": "debug-net",
"IPAM": {
"Config": [{ "Subnet": "172.20.0.0/16", "Gateway": "172.20.0.1" }]
},
"Containers": {
"abc123...": {
"Name": "api", // ← 1. 이 컨테이너가 이 네트워크에 있는가?
"IPv4Address": "172.20.0.2/16"
},
"def456...": {
"Name": "db", // ← 2. 함께 통신해야 할 컨테이너가 같은 항목에 있는가?
"IPv4Address": "172.20.0.3/16" // ← 3. IP는 같은 서브넷인가?
}
}
}
컨테이너 내부에서 인터페이스 확인
# 컨테이너 안에서 IP 확인 (ip 명령 있을 경우)
docker exec api ip addr show eth0
# 2: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
# inet 172.20.0.2/16 brd 172.20.255.255 scope global eth0
# ip 명령이 없는 최소 이미지라면
docker exec api cat /etc/hosts
# 127.0.0.1 localhost
# 172.20.0.2 abc123def456 api ← 자기 자신 항목
# DNS 해석 확인
docker exec api cat /etc/resolv.conf
# nameserver 127.0.0.11 ← Docker 내장 DNS
# options ndots:0
# 실제 DNS 해석 테스트
docker exec api nslookup db 2>/dev/null || \
docker exec api getent hosts db
# 172.20.0.3 db ← db 컨테이너 IP로 정상 해석
컨테이너 안에서 밖으로 — netns부터 외부 도달성까지 한 계층씩 짚기
컨테이너 통신이 안 될 때 무작정 설정을 바꾸는 대신, 패킷이 컨테이너 밖으로 나가며 거치는 계층을 순서대로 짚으면 "어디까지 되는지"가 드러납니다. 컨테이너는 호스트와 분리된 네트워크 네임스페이스(netns)를 가지므로, docker exec나 nsenter로 그 안에 들어가 인터페이스 → 게이트웨이 → DNS → 외부 순으로 한 계층씩 확인하는 것이 진단의 뼈대입니다.
[컨테이너 netns 안] 요청이 밖으로 나가는 경로 (각 계층을 exec/nsenter로 확인)
│
① netns 진입 — 호스트와 분리된 네트워크 스택
│ docker exec <c> ... / nsenter -t <pid> -n
│
② eth0 인터페이스·IP 확인 (veth pair의 컨테이너 쪽)
│ ip addr show eth0 → 172.x.x.x/16
│
③ 게이트웨이·라우팅 (docker0 브리지 = .1)
│ ip route → default via 172.x.x.1
│
④ DNS 해석 (/etc/resolv.conf의 127.0.0.11 내장 DNS)
│ 이름 → 같은 네트워크 컨테이너 IP로 변환
│
⑤ 외부 도달성 (호스트의 NAT masquerade로 호스트 IP 달고 나감)
▼
[다른 컨테이너 / 외부] 다섯 계층이 다 맞아야 도달
각 계층에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 계층 | 하는 일 · 확인 명령 | 여기서 막히면 |
|---|---|---|
| ① netns 진입 | docker exec·nsenter -t <pid> -n으로 컨테이너 네트워크 스택 안으로 들어감 | 최소 이미지라 ip·nc가 없음 → busybox 사이드카나 getent·cat /etc/*로 대체 |
| ② eth0·IP | ip addr show eth0 — veth 페어의 컨테이너 쪽 인터페이스와 IP 확인 | eth0 없음·IP 없음 → 네트워크 미연결(--network none, 컨테이너 크래시) |
| ③ 게이트웨이·라우팅 | ip route로 default가 docker0 브리지(.1)를 가리키는지 확인 | 기본 경로 없음 → 같은 서브넷은 되는데 외부만 timeout |
| ④ DNS | cat /etc/resolv.conf가 127.0.0.11인지, getent hosts <이름>이 IP를 주는지 확인 | nameserver가 127.0.0.11 아님·다른 네트워크 → no such host (이름만 실패, IP는 성공) |
| ⑤ 외부 도달성 | 컨테이너→외부는 호스트의 NAT(MASQUERADE)로 나감 | MASQUERADE 규칙 없음·상위 방화벽 → 이름 해석은 되는데 외부 연결만 timeout |
즉 각 계층을 순서대로 짚으면 "어디까지 통과하는지"가 곧 원인 계층입니다 — ping <IP>는 되는데 이름이 안 되면 ④(DNS), IP로도 안 되면 ②·③(인터페이스·라우팅), 컨테이너끼리는 되는데 외부만 안 되면 ⑤(NAT)입니다. 상위(로그·재시작)부터 손대지 말고 이 다섯 계층을 아래로 훑는 것이 컨테이너 네트워크 진단의 기본기입니다.
컨테이너 통신에는 세 가지 경로가 있고 장애 증상이 다릅니다. 먼저 같은 네트워크의 두 컨테이너를 띄워 이름으로 통신해보고, 실패하면 IP로 재시도해 "DNS 문제"인지 "네트워크 문제"인지 가릅니다.
# 실습 환경 준비
cd /tmp/container-net-debug
# 사용자 정의 네트워크 생성
docker network create debug-net --subnet=172.20.0.0/16
# 컨테이너 A: 간단한 HTTP 서버 (포트 8080 노출)
docker run -d --name server \
--network debug-net \
-p 8080:80 \
nginx:alpine
# 컨테이너 B: 클라이언트 역할 (busybox)
docker run -d --name client \
--network debug-net \
busybox sleep 3600
경로 1: 컨테이너 → 컨테이너 (같은 네트워크)
# client 컨테이너 안에서 server 컨테이너로 요청
docker exec client wget -qO- http://server/
# <!DOCTYPE html> ← nginx 응답 — 컨테이너 이름 DNS 해석 + 직접 통신 성공
# 이름이 안 된다면 IP로 시도해 DNS 문제인지 네트워크 문제인지 분리
SERVER_IP=$(docker inspect server --format '{{.NetworkSettings.Networks.debug-net.IPAddress}}')
echo "server IP: $SERVER_IP"
docker exec client wget -qO- http://$SERVER_IP/
# 이름은 실패하는데 IP가 된다 → DNS 문제 (네트워크 분리 또는 이름 오타)
# IP도 실패한다 → 네트워크 자체 문제 (같은 네트워크에 없음)
docker exec client wget -qO- http://server/- 이름(http://server/)으로 nginx HTML이 오면 DNS 해석 + 통신 둘 다 정상 — 기본 bridge가 아닌 사용자 정의 네트워크에서만 컨테이너 이름 DNS가 동작한다는 점을 확인
- 이름은 실패하는데 IP는 되면 'DNS 문제'다 — 두 컨테이너가 같은 사용자 정의 네트워크인지(docker network inspect), 이름 오타가 없는지 본다
- IP로도 실패하면 '네트워크 문제'다 — 같은 네트워크에 없거나 서버가 안 떠 있는 것. docker ps와 네트워크 소속을 먼저 확인
- 분리 판단 순서: 이름 실패 → IP 시도 → IP도 실패면 네트워크, IP만 되면 DNS. 이 분기를 습관화하면 원인 계층이 즉시 좁혀진다
경로 2: 호스트 → 컨테이너 (-p 포트 바인딩)
# 호스트에서 포트 바인딩을 통해 접근
curl -s http://localhost:8080/
# <!DOCTYPE html> ← 호스트 포트 8080 → 컨테이너 포트 80 → nginx 응답
# 포트 바인딩 현황 확인
docker port server
# 80/tcp -> 0.0.0.0:8080
# 80/tcp -> :::8080
# 호스트 측 iptables NAT 규칙 확인 (포트 포워딩 구현체)
sudo iptables -t nat -L DOCKER --line-numbers | grep 8080
# DNAT tcp -- anywhere anywhere tcp dpt:8080 to:172.20.0.2:80
# 바인딩은 됐는데 접근이 안 된다면
ss -tlnp | grep 8080
# Docker가 0.0.0.0:8080을 리스닝 중인지 확인
경로 3: 컨테이너 → 외부 인터넷
# 컨테이너에서 외부로 요청 (NAT masquerade 경로)
docker exec client wget -qO- --timeout=5 http://httpbin.org/ip
# {"origin": "203.0.113.xxx"} ← 호스트의 공인 IP로 나가는 것 확인
# 외부 통신이 안 된다면 iptables MASQUERADE 규칙 확인
sudo iptables -t nat -L POSTROUTING | grep MASQUERADE
# MASQUERADE all -- 172.20.0.0/16 !172.20.0.0/16
# DNS 해석 확인 (외부 도메인)
docker exec client nslookup google.com
# Server: 127.0.0.11 ← Docker 내장 DNS
# Non-authoritative answer: google.com → 8.8.8.8 등으로 포워딩
3. K8s Service 타입별 네트워크 경로
ClusterIP → NodePort → LoadBalancer 경로 추적
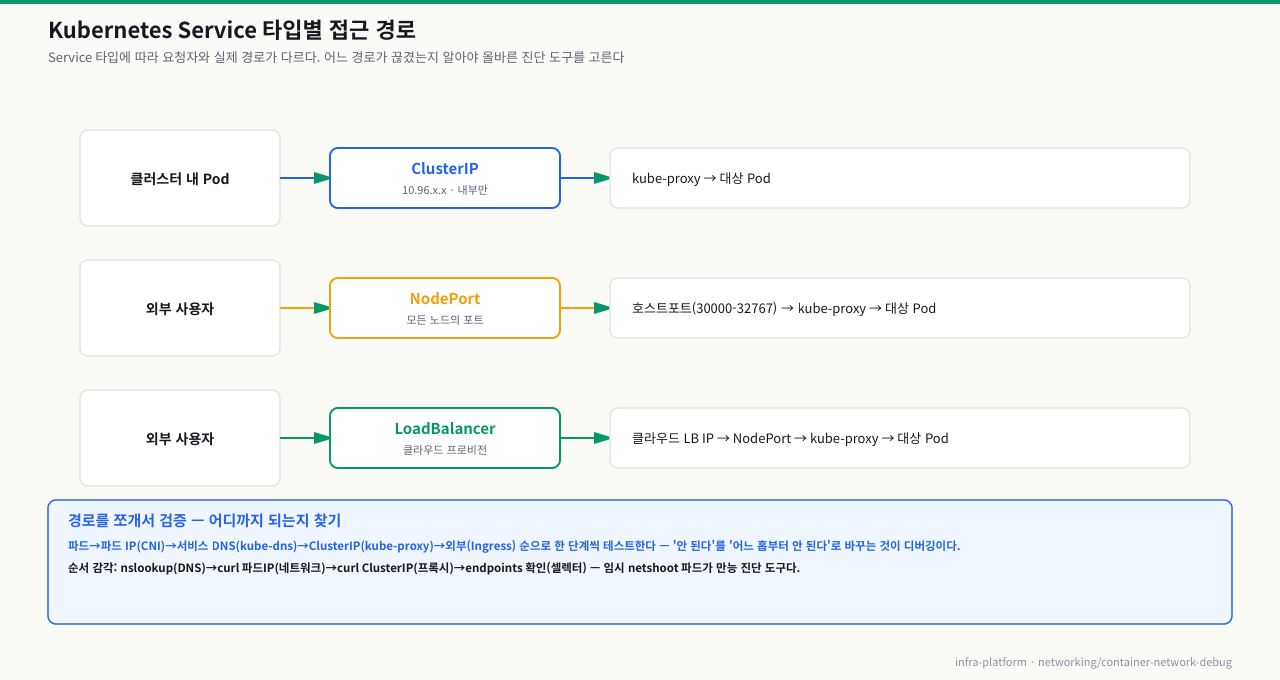
Kubernetes에서 Pod에 접근하는 경로는 Service 타입에 따라 완전히 다릅니다. 장애 상황에서 어느 경로가 끊겼는지 알아야 올바른 도구를 선택할 수 있습니다.
 확대
확대
ClusterIP — 클러스터 내부 DNS 기반 통신
ClusterIP는 <service-name>.<namespace>.svc.cluster.local로 해석됩니다. kube-dns(CoreDNS)가 이 DNS를 제공하고, kube-proxy가 iptables/IPVS 규칙으로 실제 Pod IP로 라우팅합니다.
# Service 목록 확인
kubectl get svc -n my-namespace
# NAME TYPE CLUSTER-IP PORT(S) AGE
# api-svc ClusterIP 10.96.45.12 8080/TCP 2d
# db-svc ClusterIP 10.96.78.34 5432/TCP 2d
# ClusterIP가 실제 Pod와 연결되어 있는지 확인
kubectl get endpoints api-svc -n my-namespace
# NAME ENDPOINTS AGE
# api-svc 10.244.1.5:8080 2d ← Pod IP:Port
# ← Endpoints가 <none>이면 selector 불일치 → Pod label 확인 필요
# Service selector와 Pod label 비교
kubectl describe svc api-svc -n my-namespace | grep Selector
# Selector: app=api,version=v1 ← 이 label이 Pod에 있어야 함
kubectl get pods -n my-namespace --show-labels | grep api
NodePort — 외부→내부 진입점
# NodePort 서비스 확인
kubectl get svc frontend-svc
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# frontend-svc NodePort 10.96.100.1 <none> 3000:31000/TCP 1d
# ↑
# 노드포트 31000
# 노드 IP 확인
kubectl get nodes -o wide
# NAME STATUS INTERNAL-IP EXTERNAL-IP
# node-1 Ready 192.168.1.10 <none>
# 외부에서 노드포트로 접근
curl http://192.168.1.10:31000/
# 노드포트가 안 된다면 노드의 방화벽 규칙 확인
sudo iptables -t nat -L | grep 31000
LoadBalancer — 클라우드 환경 외부 접근
# LoadBalancer External IP 확인 (프로비전 완료 전엔 <pending>)
kubectl get svc my-lb-svc
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# my-lb-svc LoadBalancer 10.96.200.1 52.10.20.30 80:31234/TCP 1h
# <pending>이 계속된다면 클라우드 컨트롤러 로그 확인
kubectl describe svc my-lb-svc | grep Events -A 10
4. 실습: kubectl exec와 port-forward로 Pod 내부 점검
# 실습 환경 준비 (kubectl 접근 가능한 환경 필요)
# 테스트 Pod 생성
kubectl run debug-pod --image=busybox --restart=Never -- sleep 3600
kubectl run api-pod --image=nginx:alpine --restart=Never --port=80
kubectl expose pod api-pod --port=80 --name=api-svc
kubectl exec — Pod 안에서 직접 네트워크 진단
# Pod 내부 쉘 접속
kubectl exec -it debug-pod -- sh
# Pod 안에서 ClusterIP 서비스로 요청
# (아래는 exec 내부에서 실행)
wget -qO- http://api-svc/ # Service 이름으로 접근
wget -qO- http://api-svc.default/ # 네임스페이스 포함
wget -qO- http://api-svc.default.svc.cluster.local/ # 완전한 FQDN
# DNS 해석 직접 확인
nslookup api-svc
# Server: 10.96.0.10 ← kube-dns(CoreDNS) IP
# Address: 10.96.0.10:53
# Name: api-svc.default.svc.cluster.local
# Address: 10.96.45.12 ← ClusterIP
# DNS는 되는데 연결이 안 된다면 → kube-proxy iptables 문제 가능성
# exit 후 호스트에서 확인
exit
# 대상 Pod의 상태 먼저 확인
kubectl get pods -o wide
# NAME READY STATUS IP NODE
# api-pod 1/1 Running 10.244.1.5 node-1
# Endpoint가 Service에 연결됐는지 확인
kubectl get endpoints api-svc
# NAME ENDPOINTS AGE
# api-svc 10.244.1.5:80 5m ← 정상
# Pod 로그로 요청이 실제로 도달했는지 확인
kubectl logs api-pod -f
# 요청이 도달하면 nginx access log 출력됨
kubectl port-forward — 로컬에서 Pod/Service 직접 접근
이 명령은 프로세스를 종료해 연결 중인 사용자나 배치 작업을 중단시킬 수 있습니다. PID와 프로세스 이름이 목표 서비스인지 확인한 뒤 실행하세요.
# Service를 로컬 포트로 포워딩 (외부 IP 없이 테스트 가능)
kubectl port-forward svc/api-svc 8080:80 &
# Forwarding from 127.0.0.1:8080 -> 80
# Forwarding from [::1]:8080 -> 80
# 로컬에서 직접 요청
curl http://localhost:8080/
# nginx 응답 → Service, Pod 모두 정상
# 특정 Pod를 직접 포워딩 (Service 우회, Pod 자체 확인)
kubectl port-forward pod/api-pod 9090:80 &
curl http://localhost:9090/
# 응답 있음 → Pod 자체는 정상 → Service 문제로 범위 좁힘
# 백그라운드 포워딩 종료
kill %1 %2 2>/dev/null
5. docker-compose 네트워크 충돌 시나리오
--network 누락과 이름 충돌이 일으키는 문제
docker-compose는 프로젝트 이름 기반으로 자동으로 네트워크를 생성합니다. 하지만 여러 프로젝트를 동시에 운영하거나, --network 옵션을 잘못 지정하면 통신이 단절됩니다.
자동 생성 네트워크 이름 규칙
# docker-compose.yml이 있는 디렉터리 이름이 프로젝트명이 됨
# /home/user/myapp/docker-compose.yml → 네트워크: myapp_default
# 이름을 명시적으로 지정하지 않으면
docker network ls | grep default
# NETWORK ID NAME DRIVER
# a1b2c3d4e5f6 myapp_default bridge ← compose가 생성
# b2c3d4e5f6a7 otherapp_default bridge ← 다른 프로젝트
문제 케이스 1: --network 누락으로 기본 네트워크에 연결됨
# 잘못된 docker-compose.yml 예시
version: "3.8"
services:
api:
image: myapp:latest
# network 미지정 → myapp_default 자동 연결
db:
image: postgres:14
networks:
- external-net # ← api와 다른 네트워크!
networks:
external-net:
external: true
name: shared-db-net
# 위 구성 시 api는 myapp_default에, db는 shared-db-net에 연결됨
docker network inspect myapp_default
# Containers: { api: ... } ← api만 있고 db 없음
docker network inspect shared-db-net
# Containers: { db: ... } ← db만 있음
# api에서 db 이름으로 접근 시 DNS 해석 실패
# dial tcp: lookup db on 127.0.0.11:53: no such host
문제 케이스 2: 서브넷 충돌
# 두 프로젝트가 같은 서브넷을 사용하는 경우
docker network inspect projectA_default | grep Subnet
# "Subnet": "172.20.0.0/16"
docker network inspect projectB_default | grep Subnet
# "Subnet": "172.20.0.0/16" ← 충돌!
# 이 경우 projectB의 컨테이너가 projectA의 컨테이너로 라우팅되거나
# 둘 다 통신 이상 발생
# 해결: 명시적 서브넷 지정
# docker-compose.yml networks 섹션에 ipam 설정 추가
문제 케이스 3: docker run --network와 compose 네트워크 혼용
# compose로 띄운 서비스와 docker run으로 띄운 컨테이너 연결 시도
docker run -d --name monitor \
--network bridge \ # ← 기본 bridge 지정
prom/prometheus # compose 서비스들은 myapp_default에 있음
# monitor에서 compose 서비스 접근 불가
# 해결: compose 네트워크를 명시적으로 지정
docker run -d --name monitor \
--network myapp_default \ # ← compose 네트워크에 연결
prom/prometheus
6. 실습: 두 컨테이너 통신 안 될 때 5분 진단 플로우
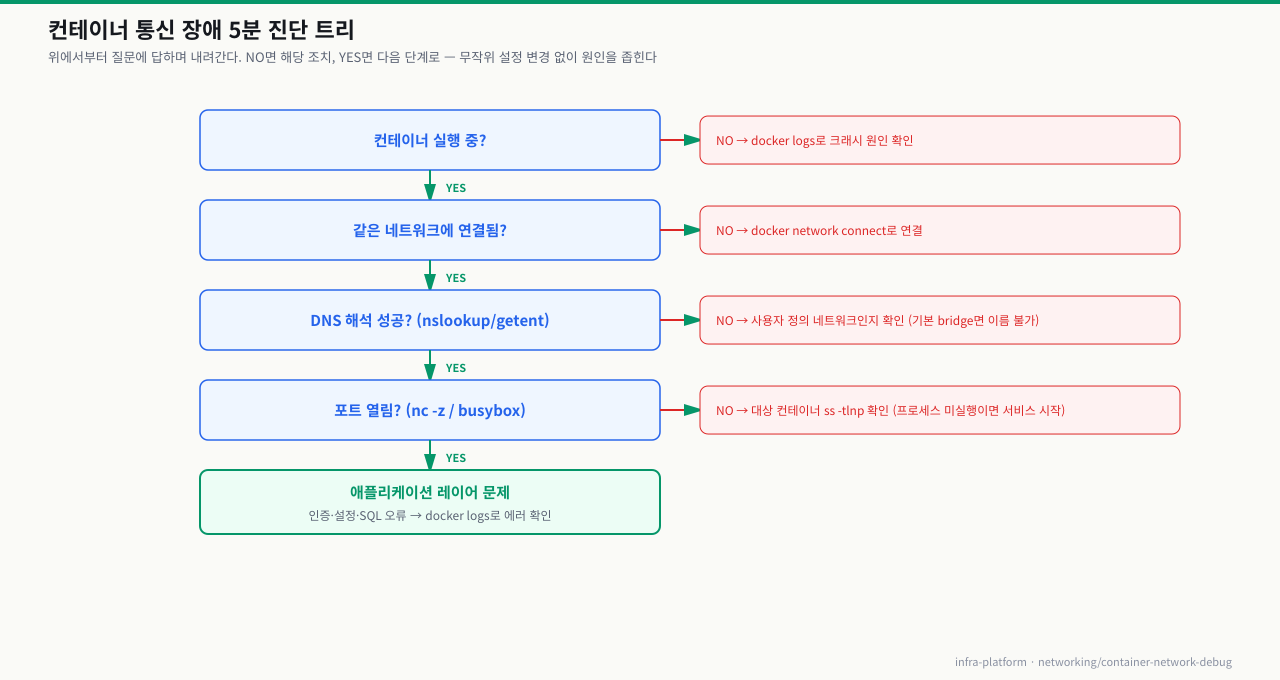
통신 장애 신고가 들어왔을 때 5분 안에 원인을 특정하는 플로우입니다. 이 순서를 따르면 무작위로 설정을 바꾸지 않고도 원인을 찾을 수 있습니다.
# 시나리오: api 컨테이너에서 db 컨테이너로 통신 안 됨
# 진단 대상: api → db
# -- Step 1: 두 컨테이너 실행 중인지 확인 (30초) --
docker ps --filter name=api --filter name=db
# 두 컨테이너 모두 STATUS가 Up이어야 함
# 한쪽이 Exited라면 docker logs <name>으로 크래시 원인 확인
# -- Step 2: 같은 네트워크에 있는지 확인 (1분) --
# api가 연결된 네트워크 목록
docker inspect api --format '{{json .NetworkSettings.Networks}}' | python3 -m json.tool
# 출력에서 네트워크 이름 확인
# db가 연결된 네트워크 목록
docker inspect db --format '{{json .NetworkSettings.Networks}}' | python3 -m json.tool
# 두 컨테이너가 같은 네트워크에 있는지 비교
# 같은 네트워크 이름이 없다면 → 원인 확정: 네트워크 분리
docker network connect <network-name> db # 또는 api
# -- Step 3: DNS 해석 테스트 (1분) --
# api 컨테이너 안에서 db 이름 해석 확인
docker exec api nslookup db 2>/dev/null || \
docker exec api getent hosts db 2>/dev/null || \
docker exec api cat /etc/resolv.conf
# DNS 실패 → 127.0.0.11이 nameserver인지 확인
# DNS 성공 → Step 4로
# -- Step 4: 포트 연결 테스트 (1분) --
# DB_IP 추출 후 포트 직접 테스트
DB_IP=$(docker inspect db --format '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}')
echo "db IP: $DB_IP"
# nc가 없으면 busybox 활용
docker run --rm --network $(docker inspect api --format '{{range $k,$v := .NetworkSettings.Networks}}{{$k}}{{end}}') \
busybox sh -c "nc -z -w3 $DB_IP 5432 && echo 'PORT OPEN' || echo 'PORT CLOSED'"
# PORT CLOSED → db 컨테이너 내부에서 프로세스 확인
docker exec db ss -tlnp | grep 5432
# 5432 리스닝 없음 → DB 프로세스 미실행
# -- Step 5: 애플리케이션 레이어 확인 (30초) --
# 포트는 열려 있지만 인증/설정 문제인 경우
docker logs db --tail=20
docker logs api --tail=20 | grep -i "connect\|error\|refused"
 확대
확대
7. 실제 에러 해부
에러 메시지가 알려주는 것
dial tcp: lookup web on 127.0.0.11:53: no such host
↑ ↑ ↑
요청한 이름 Docker DNS DNS는 응답했으나
"web" 서버 주소 이름이 등록 안 됨
127.0.0.11은 Docker 내장 DNS 서버 주소입니다. 이 서버 자체가 죽은 게 아니라, DNS 서버는 정상 응답했지만 "web"이라는 이름이 현재 네트워크에 등록되어 있지 않다는 뜻입니다.
가능한 원인 세 가지
# 원인 1: web 컨테이너가 현재 컨테이너와 다른 네트워크에 있음
docker network inspect <current-network> | grep -A5 '"Containers"'
# Containers에 "web" 항목이 없다면 → 이것이 원인
# 확인 후 해결
docker network connect <current-network> web
# 원인 2: docker-compose 서비스 이름과 컨테이너 이름 불일치
# docker-compose.yml
services:
frontend: # ← 서비스 이름 (DNS로 사용 가능)
container_name: my-web-app # ← 컨테이너 이름 (docker ps에 표시)
# 같은 네트워크라면 "frontend"로 접근해야 함
# "my-web-app"은 컨테이너 이름이지만 docker-compose 네트워크에서
# DNS로 해석되는 건 서비스 이름 "frontend"
# 원인 3: scale-out 후 이름 변경
# docker-compose up --scale web=2 실행 시
# web 컨테이너 이름이 web_1, web_2로 변경됨
# "web"으로는 여전히 접근 가능하지만 일부 환경에서 이름 해석 실패
# 현재 등록된 이름 직접 확인
docker exec <현재-컨테이너> cat /etc/hosts
docker exec <현재-컨테이너> nslookup web
재현 후 해결 실습
# 의도적으로 에러 재현
docker network create net-a
docker network create net-b
docker run -d --name web --network net-a nginx:alpine
docker run -d --name api --network net-b busybox sleep 3600
# api에서 web 접근 시도 → 에러 발생
docker exec api wget -qO- http://web/
# wget: bad address 'web'
# → no such host 계열 에러
# 해결: web을 api의 네트워크(net-b)에도 연결
docker network connect net-b web
# 재시도 → 성공
docker exec api wget -qO- http://web/
# <!DOCTYPE html> ← nginx 응답
# 정리
docker stop web api && docker rm web api
docker network rm net-a net-b
증상
docker-compose up으로 서비스를 올렸는데, 한 컨테이너에서 다른 컨테이너를 서비스 이름으로 부르면 실패합니다.
# docker-compose.yml
# services:
# api:
# ...
# db:
# image: postgres:15
# api 컨테이너에서 db에 연결 시도
docker exec -it myproject_api_1 bash
curl http://db:5432 # 실패
ping db # ping: db: Name or service not known
원인 진단
# 컨테이너 이름과 서비스 이름 구분
docker ps --format "table {{.Names}}\t{{.Image}}"
# myproject_api_1 myapi:latest
# myproject_db_1 postgres:15
# 네트워크 확인 — 어떤 네트워크에 붙어 있나
docker inspect myproject_api_1 | grep -A 20 '"Networks"'
# "myproject_default": { ← 같은 네트워크 확인
# DNS 확인 — 실제 resolv 대상
docker exec myproject_api_1 cat /etc/resolv.conf
# nameserver 127.0.0.11 ← Docker 내부 DNS 서버
# 서비스 이름으로 DNS 쿼리 테스트
docker exec myproject_api_1 nslookup db
# Server: 127.0.0.11
# Address: 127.0.0.11#53
# Name: db
# Address: 172.20.0.3 ← 정상이면 이렇게 나와야 함
해결
# 같은 네트워크에 있는지 확인
docker network inspect myproject_default
# 문제: api 컨테이너가 default 네트워크에 없는 경우
# → docker-compose.yml에서 networks 명시 여부 확인
# docker-compose.yml 수정
services:
api:
networks:
- backend
db:
networks:
- backend
networks:
backend:
# 재시작
docker-compose down && docker-compose up -d
# 서비스 이름으로 연결 재확인
docker exec myproject_api_1 curl http://db:5432
심화 — 오버레이 네트워크의 MTU: ping은 되는데 큰 전송만 멈춘다
심화: 캡슐화가 갉아먹는 50바이트 — 오버레이 MTU와 조용한 블랙홀
컨테이너끼리 ping도 되고 작은 요청도 되는데 큰 응답·큰 업로드·TLS 핸드셰이크에서만 멈춘다면, 이름 해석이 아니라 MTU 문제입니다. 패킷 계층의 함정이라 상위 디버깅으로는 안 잡힙니다.
- 오버레이는 패킷을 한 번 더 감싼다: Docker overlay나 많은 K8s CNI는 컨테이너 패킷을 VXLAN 같은 헤더로 캡슐화합니다. 이 헤더가 약 50바이트를 더 먹습니다.
- 1500 그대로 두면 초과한다: 컨테이너 인터페이스 MTU를 언더레이와 같은
1500으로 두면, 가득 찬 패킷은 캡슐화 후1550이 되어 언더레이 MTU(1500)를 넘습니다. 그러면 조각화되거나 드롭됩니다. - PMTUD가 막히면 조용히 사라진다: 경로 MTU 발견(PMTUD)은 ICMP
fragmentation needed메시지에 기대는데, 클라우드 보안그룹·방화벽이 이 ICMP를 막는 경우가 많습니다. 그러면 큰 패킷이 로그 없이 사라지는 블랙홀이 됩니다. - 그래서 증상이 이렇다: ping(작은 패킷)과 짧은 요청은 통과하지만, 큰 페이로드나 TLS 인증서 교환처럼 MTU를 꽉 채우는 순간 연결이 멈춥니다.
- 해결: 컨테이너/CNI MTU를 언더레이보다 낮게(예:
1450) 맞추거나, MSS 클램핑으로 TCP가 처음부터 작은 세그먼트를 쓰게 합니다. 클라우드라면 ICMPfragmentation needed가 통과되도록 보안그룹을 열어 둡니다.
상황: 서비스 이름 해석도 되고 curl로 작은 헬스체크 응답은 잘 받는데, 큰 응답을 주는 API나 HTTPS로 붙는 순간 응답이 오다 멈추거나 타임아웃 납니다.
원인: 오버레이 네트워크의 캡슐화 오버헤드(약 50바이트) 때문에 MTU를 꽉 채운 패킷이 언더레이 MTU를 초과하고, ICMP fragmentation needed가 막혀 PMTUD가 실패하는 MTU 블랙홀입니다. 작은 패킷은 초과하지 않아 멀쩡해 보입니다.
진단: ping -M do -s 1472처럼 DF 비트를 세운 채 크기를 키워 어느 크기부터 통과가 안 되는지 찾습니다. ip link show로 컨테이너·호스트 인터페이스의 MTU를 비교하고, tcpdump로 큰 패킷이 재전송만 반복되는지 확인합니다.
해결: 컨테이너/CNI의 MTU를 언더레이보다 낮게(예: 1450) 설정하거나 iptables의 TCPMSS 클램핑(--clamp-mss-to-pmtu)으로 세그먼트를 줄입니다. 클라우드 환경이면 보안그룹·방화벽에서 ICMP fragmentation needed(type 3 code 4)를 허용해 PMTUD가 정상 동작하게 합니다.
8. 실무 시나리오
상황: 월요일 오전, 백엔드 팀에서 슬랙 메시지가 옵니다.
"K8s 스테이징에서 order-service가 payment-service ClusterIP로 요청을 못 보내고 있습니다. 어제 금요일까지는 됐는데 오늘 갑자기 안 됩니다. 아무것도 바꾼 게 없는데요."
개발자들은 애플리케이션 코드만 담당하고, 인프라 담당자는 지금 자리를 비웠습니다. 이런 상황에서 개발자가 직접 할 수 있는 K8s ClusterIP 장애 진단 방법입니다.
1단계: Service와 Endpoint 상태 확인
# payment-service의 Service와 Endpoint 확인
kubectl get svc payment-service -n staging
# NAME TYPE CLUSTER-IP PORT(S) AGE
# payment-service ClusterIP 10.96.45.12 8080/TCP 30d
kubectl get endpoints payment-service -n staging
# NAME ENDPOINTS AGE
# payment-service <none> 30d ← Endpoints가 비어 있음! 원인 발견
2단계: Endpoint가 비어 있는 이유 추적
# Service selector 확인
kubectl describe svc payment-service -n staging | grep Selector
# Selector: app=payment,env=staging
# 해당 label을 가진 Pod가 있는지 확인
kubectl get pods -n staging -l app=payment,env=staging
# No resources found ← Pod가 없거나 label이 다름
# 전체 payment 관련 Pod 확인
kubectl get pods -n staging | grep payment
# payment-service-v2-abc123 0/1 CrashLoopBackOff 15 2h
# ↑ Pod가 있지만 CrashLoopBackOff — 실행 중이 아니라 Endpoint에 없음
3단계: Pod 크래시 원인 확인
kubectl logs payment-service-v2-abc123 -n staging --previous
# Error: DATABASE_URL environment variable not set
# ← 배포 시 환경변수 누락이 원인
kubectl describe pod payment-service-v2-abc123 -n staging | grep -A5 Environment
# Environment: DATABASE_URL <set to the key 'database-url' in secret 'payment-secret'> Optional: false
# 시크릿이 삭제되었거나 이름이 변경된 경우
kubectl get secret payment-secret -n staging
# Error from server (NotFound): secrets "payment-secret" not found
# ← 시크릿이 없음 — 금요일 정리 작업 중 실수로 삭제된 것
결과 보고:
"payment-service ClusterIP의 Endpoint가 비어 있었고, 원인은 payment-service Pod가 CrashLoopBackOff 상태였습니다. Pod 로그에서 DATABASE_URL 환경변수 누락 에러를 확인했고, payment-secret 시크릿이 삭제된 것을 발견했습니다. 시크릿 재생성 후 Pod가 정상 기동되면 Endpoint가 복구되고 ClusterIP 통신이 재개될 것입니다."
kubectl exec와 port-forward만 알아도 개발자가 직접 K8s 네트워크 장애의 원인을 특정할 수 있습니다. 인프라팀 없이도 "어디가 문제인지"는 찾을 수 있어야 빠른 에스컬레이션이 가능합니다.
정리
컨테이너 네트워크 디버깅의 핵심은 어느 계층에서 끊겼는지 순서대로 좁혀나가는 것입니다.
| 증상 | 확인 명령 | 가장 많은 원인 |
|---|---|---|
| 이름으로 못 찾음 | docker network inspect | 다른 네트워크에 있음 |
| IP로는 되는데 이름이 안 됨 | /etc/resolv.conf 확인 | 기본 bridge 사용 중 |
| ClusterIP 응답 없음 | kubectl get endpoints | Endpoint 비어 있음 |
| Endpoint 비어 있음 | kubectl get pods -l <selector> | Pod 크래시 또는 label 불일치 |
| Pod는 정상인데 Service 응답 없음 | kubectl port-forward pod/... | kube-proxy 또는 NetworkPolicy |
도구는 단순합니다. docker network inspect, docker exec, kubectl exec, kubectl port-forward — 이 네 가지만 능숙하게 쓸 수 있으면 대부분의 컨테이너 네트워크 장애를 혼자 진단할 수 있습니다.
명령어·단축키 빠른 참조
이 모듈에서 다룬 컨테이너 네트워크 디버깅 명령을 실전 옵션과 함께 모았습니다. "예" 열의 조합을 그대로 써도 됩니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
docker network inspect | 두 컨테이너가 같은 네트워크인지 | docker network inspect debug-net (Containers·Subnet) |
docker exec ... cat /etc/resolv.conf | 내장 DNS(127.0.0.11) 확인 | 이름 해석 실패 시 nameserver 확인 |
docker exec ... getent hosts | 컨테이너 이름 DNS 해석 테스트 | docker exec api getent hosts db |
docker inspect --format | 컨테이너 IP·네트워크 추출 | docker inspect db --format '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' |
docker port | 호스트↔컨테이너 포트 바인딩 | docker port server (80/tcp -> 0.0.0.0:8080) |
docker network connect | 컨테이너를 다른 네트워크에 추가 | docker network connect net-b web (no such host 해결) |
iptables -t nat -L DOCKER | 포트포워딩(DNAT) 규칙 확인 | sudo iptables -t nat -L DOCKER --line-numbers | grep 8080 |
kubectl get endpoints | Service가 Pod에 연결됐는지 | <none>이면 selector 불일치/Pod 크래시 |
kubectl exec -it ... -- | Pod 안에서 직접 통신 검증 | kubectl exec -it debug-pod -- wget -qO- http://api-svc/ |
kubectl port-forward | Service/Pod 우회 로컬 접근 | kubectl port-forward svc/api-svc 8080:80 |
nc -z -w3 | 컨테이너 간 포트 도달성 | busybox sh -c "nc -z -w3 $DB_IP 5432" |
ping -M do -s / ip link show | 오버레이 MTU 블랙홀 확인 | ping -M do -s 1472 <대상>, ip link show로 MTU 비교 |
관련 모듈로 더 깊이:
- 웹 서버에서 DB 접속 실패 시 원인 격리 프로세스 — 계층별로 장애 지점을 좁혀가는 고립 방법론
- 서브넷, 라우팅 테이블, 인터넷 게이트웨이 설계 가이드 — 컨테이너가 올라가는 클라우드 VPC 네트워크 구조
- DNS 질의 실패 극복 및 resolv.conf 수동 복구 가이드 — 컨테이너가 이름으로 못 찾는 문제의 DNS 설정 원인
다음 모듈에서는 HTTP 연결 타임아웃 디버깅을 다루며, curl로 연결 단계를 분해하고 외부 API 장애와 내 서버 문제를 구분하는 방법을 배웁니다.