로드밸런서 한 대가 죽자 서비스 전체가 같이 멈췄습니다. 예비 서버는 있었지만 VIP가 넘어가지 않아 사용자는 계속 죽은 IP로 접속했습니다.
고가용성은 서버를 두 대 둔다고 끝나지 않습니다. 장애 순간 누가 IP를 들고 응답할지까지 설계해야 합니다.
고가용성(HA) 네트워크와 이중화 구성
로드밸런서를 한 대 구축했더니 이번엔 로드밸런서 자체가 SPOF(Single Point of Failure)가 되었습니다. 로드밸런서 서버가 다운되면 그 뒤에 있는 모든 서버들이 아무리 멀쩡해도 서비스 전체가 중단됩니다.
이 챕터에서는 Keepalived와 VRRP 프로토콜을 사용해 로드밸런서(또는 핵심 서버)를 2대로 이중화하고, 한 대가 장애를 일으키면 자동으로 다른 서버가 역할을 이어받는 Failover 시스템을 구축합니다.
- 1SPOF(단일 장애점) 개념과 고가용성(HA) 설계 목표를 설명할 수 있다
- 2VRRP 프로토콜과 VIP(Virtual IP) 원리를 이해하고 서버 교체 없이 Failover를 구현할 수 있다
- 3Keepalived로 온프레미스 HA를 구현할 수 있다
- 4AWS ALB/NLB가 클라우드에서 HA를 대신 처리하는 방식을 이해할 수 있다
sudo apt-get install -y keepalived # Ubuntu/Debian
sudo yum install -y keepalived # CentOS/RHELsudo sysctl -w net.ipv4.ip_forward=1 && sudo sysctl -w net.ipv4.ip_nonlocal_bind=1ip link showfirewalld 환경에서는 sudo firewall-cmd --add-protocol=vrrp --permanent && sudo firewall-cmd --reload 로 VRRP 패킷을 허용해야 합니다
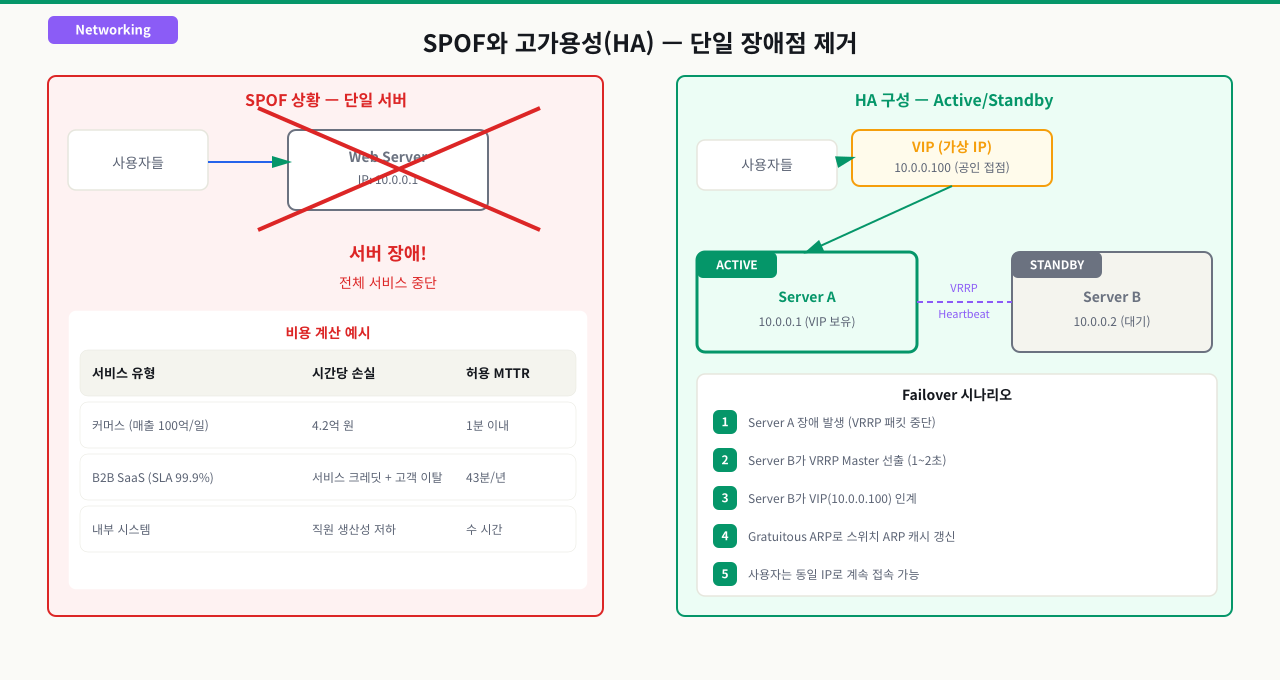
SPOF와 고가용성(HA): 왜 이중화가 필요한가
새벽 2시에 로드밸런서 서버 한 대가 죽었습니다. 그 서버가 모든 트래픽을 받고 있었기 때문에 서비스 전체가 멈췄습니다. 서버가 두 대 있었지만 둘 다 똑같이 로드밸런서 역할이 아니었습니다. 고가용성 구성을 안 한 것이 아니라, SPOF가 어디에 있는지 인식하지 못한 게 문제였습니다.
 확대
확대
SPOF(Single Point of Failure): 단일 장애점
SPOF는 시스템에서 그 하나만 고장나도 전체가 멈추는 구성요소를 말합니다.
인터넷
↓
[로드밸런서 1대] ← SPOF! 이 서버가 죽으면?
↓
[서버A] [서버B] ← 멀쩡해도 클라이언트 접근 불가
로드밸런서가 SPOF인 아키텍처에서는, 로드밸런서가 5분만 다운돼도 전체 서비스가 중단됩니다.
HA(High Availability): 고가용성
HA는 SPOF를 제거해 서비스의 가용성을 높이는 설계 목표입니다. 일반적으로 99.9% (Three Nines) 이상의 가용성을 목표로 합니다.
| 가용성 | 연간 다운타임 |
|---|---|
| 99% | 87.6시간 |
| 99.9% | 8.76시간 |
| 99.99% | 52.6분 |
| 99.999% | 5.26분 |
Active/Standby 이중화 구조
HA의 가장 기본 패턴은 Active/Standby 구성입니다.
인터넷
↓
VIP: 192.168.1.100 ← 클라이언트가 항상 바라보는 가상 IP
↓
[로드밸런서A - Active] ← 평상시 VIP 보유, 트래픽 처리
[로드밸런서B - Standby] ← 대기 중, A 장애 시 VIP 인계받음
↓ A가 장애나면?
VIP: 192.168.1.100 ← 동일한 VIP
↓
[로드밸런서B - Active] ← VIP 인계받아 트래픽 처리 시작
핵심: 클라이언트는 VIP에만 접속합니다. 실제로 어떤 서버가 VIP를 가지고 있는지 알 필요가 없습니다.
Keepalived가 하는 일
Keepalived는 VRRP 프로토콜을 구현한 오픈소스 데몬입니다.
- 두 서버가 주기적으로 VRRP 패킷(Heartbeat)을 교환합니다.
- priority가 높은 서버가 Master가 되어 VIP를 보유합니다.
- Master 서버가 Heartbeat를 보내지 않으면 Backup 서버가 Master로 승격하고 VIP를 가져옵니다.
- 원래 Master 서버가 복구되면 다시 VIP를 회수합니다(preempt 기본 동작).
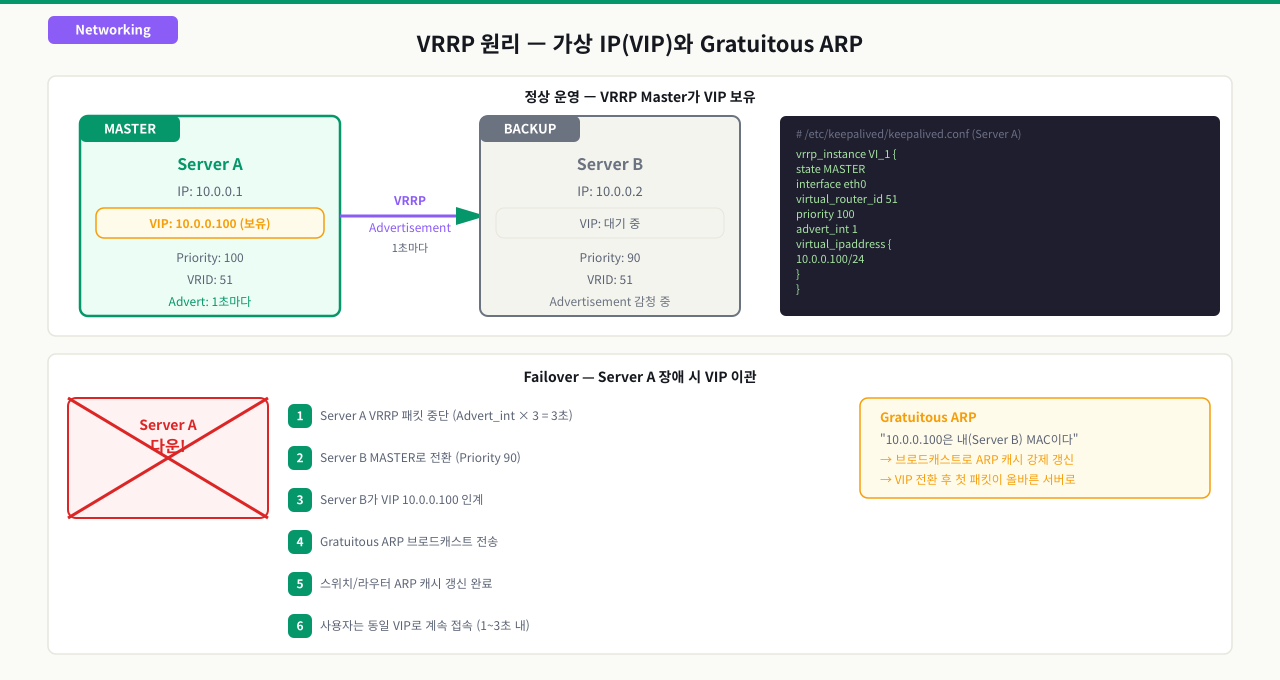
VRRP 프로토콜 원리와 VIP 동작 메커니즘
Keepalived를 설정했는데 Master가 죽어도 Backup이 올라오지 않습니다. 로그를 보면 VRRP 광고 패킷이 수신되지 않는다고 나옵니다. VRRP가 어떤 방식으로 상태를 감지하고 IP를 인계하는지 이해하지 못하면, 이 오류 메시지가 무엇을 뜻하는지 알 수 없고 설정 어디를 고쳐야 하는지 찾을 수가 없습니다.
 확대
확대
VRRP(Virtual Router Redundancy Protocol)
VRRP는 RFC 5798에 정의된 네트워크 표준 프로토콜입니다. 원래는 라우터 이중화를 위해 설계되었지만, Keepalived를 통해 일반 Linux 서버에서도 사용합니다.
VRRP 동작 흐름
[서버A - Master] [서버B - Backup]
priority: 101 priority: 100
VIP 보유: 192.168.1.100
→ VRRP Advertisement(1초 간격) →
"나 살아있어요, priority 101"
서버A가 3초간 침묵하면...
→ 서버B가 Master로 승격
→ GARP 전송: "192.168.1.100은 이제 내 MAC"
→ VIP 인계 완료
GARP(Gratuitous ARP): 빠른 VIP 전환의 핵심
Failover 시 새 Master(서버B)는 GARP 패킷을 네트워크에 브로드캐스트합니다.
GARP: "IP 192.168.1.100의 MAC 주소가 변경되었습니다.
이제 MAC AA:BB:CC:DD:EE:FF입니다."
네트워크의 모든 장비(스위치, 라우터, 클라이언트)가 ARP 캐시를 업데이트합니다. 이 과정이 빠르면 Failover는 수 초 내에 완료됩니다.
VRRP ID(Virtual Router ID)
같은 네트워크에 여러 VRRP 그룹이 있을 수 있습니다. virtual_router_id로 그룹을 구분합니다. 같은 그룹의 서버들은 동일한 virtual_router_id를 사용해야 합니다.
# 잘못된 설정: 두 서버의 virtual_router_id가 다르면 HA 불가
서버A: virtual_router_id 51
서버B: virtual_router_id 52 ← 오타! 서로 다른 그룹으로 인식
VRRP 인증
동일 네트워크에 악의적인 서버가 높은 priority로 Master를 가로채는 것을 방지하기 위해 인증을 설정할 수 있습니다.
authentication {
auth_type PASS
auth_pass 비밀번호1234
}
auth_pass는 최대 8자리이며, 같은 VRRP 그룹의 모든 서버에서 동일해야 합니다.
VIP가 장애 순간 Backup으로 넘어가기까지 — VRRP 페일오버 6단계
Keepalived를 켜 두면 "Master가 죽으면 알아서 넘어간다"고 하지만, 정작 넘어가는 그 몇 초 사이에 무슨 일이 순서대로 일어나는지 모르면 "왜 안 넘어가지", "넘어갔는데 왜 트래픽이 안 따라오지"를 구분하지 못합니다. VIP가 이동하는 과정은 우선순위로 Master를 뽑고 → Master가 VIP를 들고 광고를 쏘고 → Backup이 그 광고를 세며 감시하다 → 광고가 끊기면 승격하고 → VIP를 인수해 → GARP로 트래픽을 끌어오는 여섯 단계입니다.
[서버A priority 110] [서버B priority 100]
│ │
① 우선순위 비교 → 높은 A가 Master 선출, B는 Backup
│ │
② A가 VIP(192.168.1.100) 보유 + VRRP advertisement 송신 (advert_int 1초)
│ "나 살아있음, priority 110" →→→ B가 수신
│ │
③ B는 광고를 계속 수신하며 감시 (dead interval = advert_int × 3 ≈ 3초)
│ │
══ A 장애 발생 → 광고 끊김 ═══════════════
│ │
④ B가 dead interval 동안 광고 못 받음 → "Master 부재" 판정
│ │
⑤ B가 Master로 승격 + VIP를 자기 인터페이스에 인수
│ │
⑥ B가 GARP 브로드캐스트: "192.168.1.100 = 내 MAC"
│ 스위치·클라이언트 ARP 캐시 갱신 → 트래픽이 B로 이동
▼
[클라이언트] 같은 VIP로 계속 접속, 서버가 바뀐 줄 모름
각 단계에서 무슨 일이 일어나고, 어긋나면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 어긋나면 |
|---|---|---|
| ① Master 선출 | 같은 virtual_router_id 그룹 안에서 priority 높은 노드가 Master, 나머지는 Backup. VIP를 가진 쪽이 Master | 두 노드의 virtual_router_id가 다르거나 auth_pass 불일치 → 서로를 그룹원으로 못 봐 둘 다 Master(이중 Master) |
| ② VIP 보유·광고 송신 | Master가 VIP를 인터페이스에 붙이고 advert_int 주기로 VRRP advertisement를 멀티캐스트(224.0.0.18) 송신 | 방화벽이 VRRP(프로토콜 112)·멀티캐스트를 차단 → 광고가 안 나가/안 들어와 Backup이 오판 |
| ③ Backup 감시 | Backup이 광고를 수신하며 Master 생존 확인. dead interval(≈ advert_int × 3) 동안 안 오면 죽은 것으로 간주 | dead interval이 너무 짧으면 순간 지연에도 플래핑, 너무 길면 절체가 느려짐 |
| ④ Master 부재 판정 | dead interval 초과로 Backup이 승격 트리거. 헬스체크(vrrp_script)가 서비스 실패를 weight로 반영해 priority를 떨궈 조기 절체 유도 | 헬스체크가 없거나 잘못됨 → 프로세스는 죽었는데 VRRP는 살아 있어 절체 안 됨 |
| ⑤ 승격·VIP 인수 | Backup이 Master 상태로 전환하고 VIP를 자기 NIC에 부착. ip addr에 VIP가 나타남 | VRRP 통신이 순간 끊겼다 붙으면 양쪽이 서로 승격 → 둘 다 VIP 보유(split-brain) |
| ⑥ GARP 전파 | 새 Master가 Gratuitous ARP를 뿌려 VIP↔새 MAC 매핑을 강제 갱신, 트래픽을 끌어옴 | 스위치가 GARP를 떨구거나 클라이언트 ARP TTL이 길면 → VIP는 넘어갔는데 트래픽은 옛 서버로 |
즉 "페일오버가 안 된다"와 "페일오버는 됐는데 트래픽이 안 따라온다"는 전혀 다른 단계의 문제입니다. 앞의 셋(①③)이 어긋나면 절체 자체가 안 되거나 split-brain이 나므로 ⑥)은 절체는 됐는데 서비스가 안 이어지는 경우로, journalctl -u keepalived와 tcpdump -i eth0 -n vrrp로 광고가 오가는지·양쪽 상태를 봅니다. 뒤의 셋(④ip addr로 VIP 위치를, tcpdump -i eth0 arp와 클라이언트 arp -n으로 GARP·ARP 캐시를 확인합니다. 로그에 "Entering MASTER STATE"까지 갔다면 ①~⑤는 통과한 것이고, 그런데도 일부 클라이언트가 옛 서버로 가면 ⑥(GARP)이 범인입니다.
이 명령은 실행 중인 서비스 상태를 바꿔 순간적인 중단이나 설정 반영 실패를 만들 수 있습니다. 운영 트래픽 영향과 재시작 후 확인 명령을 먼저 준비하세요.
MASTER 노드의 keepalived.conf(VRRP 인스턴스·VIP·track_script)와 nginx 헬스체크 스크립트를 작성합니다. priority·virtual_router_id·auth_pass가 그룹 내에서 일관되게 들어갔는지 확인하는 단계입니다.
# 실습 디렉토리 준비
mkdir -p /tmp/networking/part6/exam_28 && cd /tmp/networking/part6/exam_28
mkdir -p /tmp/networking/part5/keepalived/config
cat > /tmp/networking/part5/keepalived/config/keepalived.conf << 'EOF'
global_defs {
router_id LVS_MASTER
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
interval 2
weight -20
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass secret123
}
track_script {
check_nginx
}
virtual_ipaddress {
192.168.1.100/24
}
}
EOF
cat > /tmp/networking/part5/keepalived/config/check_nginx.sh << 'EOF'
#!/bin/bash
if systemctl is-active nginx &>/dev/null; then
exit 0
else
systemctl start nginx
sleep 2
if systemctl is-active nginx &>/dev/null; then
exit 0
else
exit 1
fi
fi
EOF
chmod +x /tmp/networking/part5/keepalived/config/check_nginx.sh
cat /tmp/networking/part5/keepalived/config/keepalived.conf- MASTER/BACKUP 상태 먼저 확인—systemctl status keepalived 출력에서 "Entering MASTER STATE" 가 보이면 VIP를 보유한 노드 — 두 노드 모두 MASTER면 split-brain 발생
- VIP 바인딩 여부 확인—ip addr show 에서 VIP(예: 192.168.1.100/32)가 MASTER 노드 인터페이스에만 표시되어야 정상 — BACKUP 노드에도 보이면 즉시 방화벽 VRRP 룰 점검
- 두 노드 비교 해석—MASTER 노드에 VIP 있고 BACKUP에 없으면 정상 HA 구성 — BACKUP이 VIP를 들고 있으면 네트워크 멀티캐스트(224.0.0.18) 차단 의심
트러블슈팅
가상 IP(VIP) 바인딩 경합 및 상태 동기화 장애 해결
가상 IP(VIP)를 활용해 웹 서버나 프록시 이중화를 기동할 때 발생하는 가장 흔한 장애는 마스터와 백업 서버 모두 VIP를 점유해버리는 split-brain 현상입니다.
- SRE의 고가용성 네트워크 문제 극복 방법:
- VRRP 멀티캐스트 포트 방화벽 오픈: Keepalived 데몬 간의 심장박동(Heartbeat) 패킷은 멀티캐스트 IP(224.0.0.18)를 사용합니다. 방화벽에서 이 VRRP 패킷 통신이 막혀있으면 양측 노드가 서로를 죽었다고 판단하여 동시 VIP를 들게 되므로 UFW 정책을 반드시 열어야 합니다.
- VIP 점유 확인:
ip addr show명령어를 통해 VIP 주소가 올바른 마스터 노드에만 단독 바인딩되어 있는지 점검합니다.
상황
모니터링에서 VIP에 대한 ARP 응답이 두 곳에서 오고 있다는 경보가 발생합니다. 양쪽 서버 모두 ip addr로 확인하면 VIP를 가지고 있습니다.
# 서버A에서
ip addr show eth0 | grep 192.168.1.100
# inet 192.168.1.100/24 scope global secondary eth0 ← A가 VIP 보유
# 서버B에서도 동시에
ip addr show eth0 | grep 192.168.1.100
# inet 192.168.1.100/24 scope global secondary eth0 ← B도 VIP 보유!
원인 분석
두 서버 사이의 VRRP 통신이 차단되었습니다.
# 서버A에서 서버B의 실제 IP로 ping 시도
ping 192.168.1.11
# Request timeout... ← 두 서버 간 통신 차단!
VRRP는 멀티캐스트(224.0.0.18) 또는 유니캐스트를 통해 Heartbeat를 교환합니다. 이 통신이 차단되면:
- 서버B는 서버A의 Advertisement를 못 받음
- "서버A가 죽었나?" 판단하고 Master로 승격
- 서버A는 계속 동작 중, 서버B도 Master 선언
- 두 서버가 동일 VIP를 사용 → IP 충돌
즉시 해결 방법
이 명령은 실행 중인 서비스 상태를 바꿔 순간적인 중단이나 설정 반영 실패를 만들 수 있습니다. 운영 트래픽 영향과 재시작 후 확인 명령을 먼저 준비하세요.
# 1. 둘 중 하나를 즉시 Standby로 강제 변경
# priority를 낮춰서 재시작
sudo systemctl stop keepalived
# keepalived.conf의 priority를 낮춤 (서버B의 경우)
sudo sed -i 's/priority 100/priority 50/' /etc/keepalived/keepalived.conf
sudo systemctl start keepalived
근본 원인 제거: 방화벽 규칙 수정
VRRP 멀티캐스트 허용:
이 명령은 방화벽 정책을 변경해 현재 접속 중인 세션이나 운영 트래픽에 즉시 영향을 줄 수 있습니다. 적용 전 허용 대상 IP·포트와 롤백 명령을 확인하세요.
# iptables 기반
sudo iptables -A INPUT -p vrrp -j ACCEPT
sudo iptables -A OUTPUT -p vrrp -j ACCEPT
# firewalld 기반
sudo firewall-cmd --add-protocol=vrrp --permanent
sudo firewall-cmd --reload
또는 유니캐스트 모드로 전환 (멀티캐스트가 막힌 환경에서):
# keepalived.conf에 추가
vrrp_instance VI_1 {
...
unicast_src_ip 192.168.1.10 # 자신의 실제 IP
unicast_peer {
192.168.1.11 # 상대방 실제 IP
}
...
}
재발 방지를 위한 모니터링
# VIP를 가진 서버를 주기적으로 점검하는 스크립트
# /usr/local/bin/check-vip.sh
#!/bin/bash
VIP="192.168.1.100"
SERVER_A="192.168.1.10"
SERVER_B="192.168.1.11"
A_HAS_VIP=$(ssh $SERVER_A "ip addr show | grep $VIP" && echo "yes" || echo "no")
B_HAS_VIP=$(ssh $SERVER_B "ip addr show | grep $VIP" && echo "yes" || echo "no")
if [ "$A_HAS_VIP" = "yes" ] && [ "$B_HAS_VIP" = "yes" ]; then
echo "CRITICAL: Split-Brain detected! Both servers hold VIP!"
# 알림 전송 로직
fi
상황
Keepalived를 시작했는데 서버A에 VIP가 생성되지 않습니다. systemctl status keepalived는 active(running)을 보여줍니다.
진단 과정
# 1. Keepalived 상세 로그 확인
sudo journalctl -u keepalived -n 50
# 예시 오류 메시지:
# VRRP_Instance(VI_1) Cant find interface eth0 for vrrp_instance VI_1 !!!
오류 1: 인터페이스 이름 불일치 — 설정 파일의 interface 값이 실제 NIC 이름과 다릅니다.
이 명령은 실행 중인 서비스 상태를 바꿔 순간적인 중단이나 설정 반영 실패를 만들 수 있습니다. 운영 트래픽 영향과 재시작 후 확인 명령을 먼저 준비하세요.
# 실제 인터페이스 이름 확인
ip link show
# eth0이 아닌 ens3, enp0s3 등일 수 있음
# keepalived.conf 수정
sudo sed -i 's/interface eth0/interface ens3/' /etc/keepalived/keepalived.conf
sudo systemctl restart keepalived
오류 2: virtual_router_id 충돌 — 같은 네트워크의 다른 Keepalived 인스턴스와 ID가 겹칩니다.
# 같은 네트워크에 다른 VRRP 그룹이 virtual_router_id 51을 이미 사용 중일 수 있음
# tcpdump로 VRRP 패킷 확인
sudo tcpdump -i eth0 -n vrrp
# 사용 중인 router_id 확인 후 다른 값으로 변경
오류 3: auth_pass 불일치
두 서버의 auth_pass가 다르면 VRRP 패킷을 무시하고 둘 다 Master가 됩니다.
# 두 서버에서 현재 auth_pass 확인
sudo grep auth_pass /etc/keepalived/keepalived.conf
# 다르면 통일 후 재시작
설정 파일 문법 검증
# keepalived 설정 파일 문법 체크
sudo keepalived -t -f /etc/keepalived/keepalived.conf
# Configuration is valid ← 정상
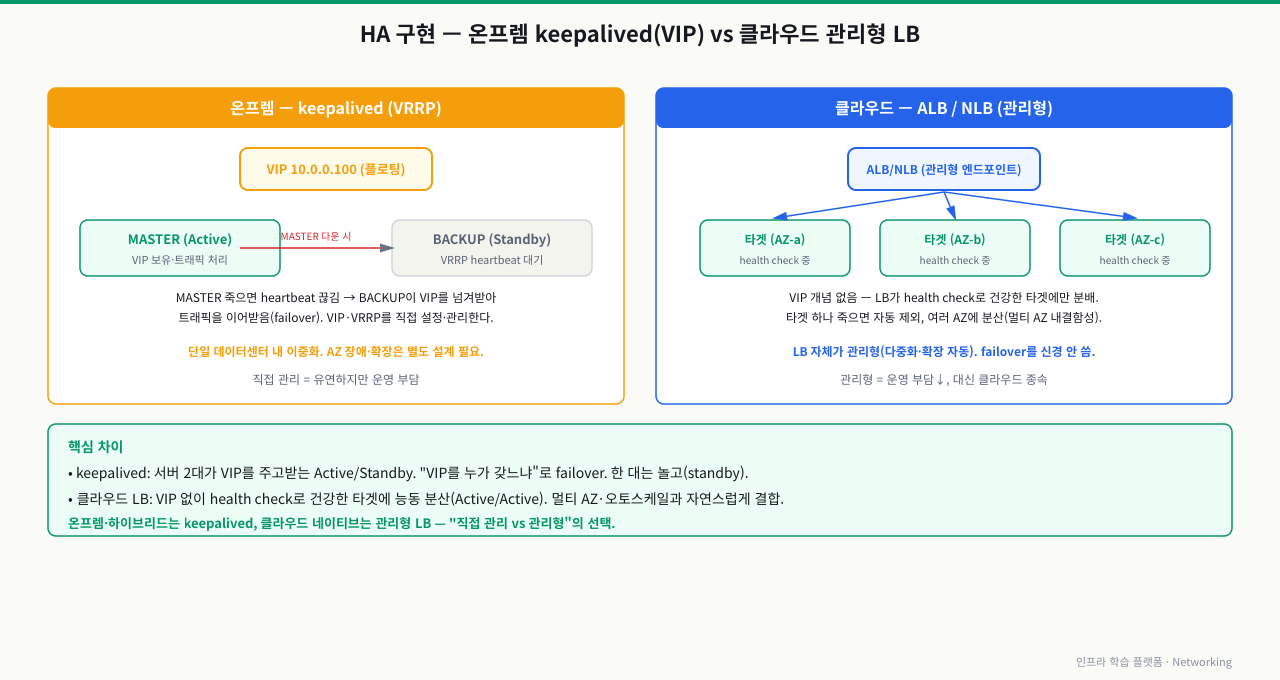
클라우드에서 HA — AWS ALB/NLB가 Keepalived를 대신하는 방식
온프레미스에서 Keepalived로 3~5시간을 써야 구현할 것을, AWS는 체크박스 하나로 제공합니다.
 확대
확대
온프레미스 HA 구성:
서버 2대 + Keepalived 설치 + VRRP 설정 + VIP 할당
→ Failover 시간: ~5~10초
→ Split-Brain 방지 설정 별도 필요
AWS Application Load Balancer (ALB):
콘솔에서 "Multi-AZ" 체크 → 자동으로 여러 AZ에 분산
→ AZ 장애 시 수 초 내 자동 전환
→ Split-Brain 걱정 없음 (AWS 관리형)
| 기능 | 온프레미스 (Keepalived) | AWS (ALB/NLB) |
|---|---|---|
| VIP 이중화 | VRRP + VIP 수동 설정 | 자동 (Elastic Load Balancer) |
| Failover | ~수 초 (헬스체크 주기) | |
| 헬스체크 | vrrp_script 직접 작성 | 콘솔에서 경로/임계값 설정 |
| Split-Brain 방지 | Fencing, 쿼럼 직접 설정 | AWS 인프라가 처리 |
| 유지보수 | 직접 패치, 설정 관리 | 관리형 서비스 |
언제 Keepalived를 직접 쓰는가:
- 온프레미스 또는 IDC 환경
- 클라우드 LB 비용이 부담되는 소규모 환경
- 특수한 네트워크 요구사항 (Anycast, BGP 연동 등)
개발자 관점에서 중요한 것: 내가 배포하는 서버 앞에 HA가 설정되어 있는지, Failover 시간이 어느 정도인지 파악하는 것입니다.
심화 — 페일오버는 끝났는데 트래픽이 옛 서버로 가는 이유
심화: VIP는 옮겨졌는데 왜 옛 서버로 갈까 — ARP 캐시와 GARP
Keepalived 로그상 Standby가 즉시 Master로 승격하고 ip addr에도 VIP가 붙었는데, 클라이언트 일부가 한동안 죽은 옛 서버로 계속 접속해 에러가 이어질 수 있습니다. VIP는 L3 개념이고, 실제 전달은 L2의 MAC 주소로 이뤄지기 때문입니다.
- VIP는 IP, 전달은 MAC: 같은 L2에 있는 클라이언트와 스위치는
IP→MAC매핑을 ARP 캐시(스위치는 CAM 테이블)에 담아 둡니다. VIP가 Standby로 옮겨가면 그 VIP 뒤의 MAC이 Standby NIC의 MAC으로 바뀝니다. - 캐시는 즉시 갱신되지 않는다: 클라이언트·스위치가 옛 MAC을 캐시에 들고 있는 동안에는, VIP로 보낸 프레임이 여전히 죽은 옛 서버의 MAC으로 향합니다. ARP 캐시 타임아웃까지 이 상태가 이어질 수 있습니다.
- 그래서 GARP를 쏜다: Keepalived는 VIP를 인수하는 순간 Gratuitous ARP(GARP)를 브로드캐스트해 "이 VIP는 이제 내 MAC"이라고 모두의 캐시를 강제 갱신합니다. 정상이라면 전환이 수 초로 끝나는 이유가 이것입니다.
- GARP가 유실되면 전환이 길어진다: 스위치의 IGMP 스누핑·포트 시큐리티·Dynamic ARP Inspection(DAI)이 GARP를 떨구거나, 클라이언트 ARP 캐시 TTL이 길면 갱신이 늦어져 트래픽이 옛 서버로 계속 흐릅니다. 이때는 GARP 재전송(
garp_master_refresh)과 스위치 정책 확인이 필요합니다.
상황: 페일오버 자체는 성공했습니다. 새 Master의 ip addr에 VIP가 보이고 로그도 정상인데, 유독 일부 클라이언트만 한동안 이전(죽은) 서버로 연결을 시도하며 타임아웃·연결 거부가 이어집니다.
원인: 클라이언트나 중간 스위치의 ARP 캐시가 옛 서버의 MAC을 아직 들고 있습니다. VIP는 새 서버로 옮겨졌지만, 캐시가 갱신되기 전까지 프레임이 옛 MAC으로 향하는 것입니다. Keepalived가 보낸 GARP가 유실됐거나 캐시 TTL이 긴 상황입니다.
진단: 새 Master에서 tcpdump -i eth0 arp로 승격 순간 GARP가 실제로 나갔는지 확인하고, 문제 클라이언트에서 arp -n(또는 ip neigh)으로 VIP가 옛 MAC을 가리키는지 봅니다. 스위치 쪽에서는 IGMP 스누핑·포트 시큐리티·DAI가 GARP를 차단하는지 점검합니다.
해결: GARP가 확실히, 그리고 여러 번 나가도록 garp_master_refresh·garp_master_delay를 설정합니다. 스위치에서 GARP가 통과되도록 정책을 조정하고, 필요하면 문제 클라이언트의 과도한 ARP 캐시 TTL을 낮춰 전환이 수 초 안에 반영되게 합니다.
실무 적용 사례
1. HAProxy + Keepalived 조합 (온프레미스 표준 구성) — 온프레미스에서 가장 많이 쓰는 HA 아키텍처입니다.
인터넷
↓
VIP (Keepalived 관리)
↓
[HAProxy A - Active] [HAProxy B - Standby]
↓
[앱서버 1] [앱서버 2] [앱서버 3]
HAProxy와 Keepalived를 묶으면 로드밸런서 자체의 HA를 달성할 수 있습니다. vrrp_script로 HAProxy 프로세스 상태를 감시하다가 HAProxy가 죽으면 Keepalived가 자동으로 Failover를 실행합니다.
2. 클라우드에서의 동등한 개념 — 각 클라우드가 Keepalived에 해당하는 기능을 자체 서비스로 제공합니다.
| 온프레미스 | AWS | GCP |
|---|---|---|
| Keepalived + VIP | Elastic IP + Route 53 상태 체크 | Cloud DNS + 헬스체크 정책 |
| Active/Standby | Multi-AZ 배포 | Multi-region 배포 |
| VRRP Heartbeat | ELB Health Check | Load Balancer Health Check |
클라우드 환경에서는 Keepalived를 직접 쓰는 경우가 줄었지만, 온프레미스 데이터센터, 하이브리드 클라우드, 비용 최적화 환경에서는 여전히 핵심 기술입니다.
운영 시 주의사항
Failover 시간 계산 — advert_int와 preempt_delay 조합으로 전환 속도를 튜닝합니다.
VRRP dead interval = advert_int × 3 = 1초 × 3 = 3초 (기본값)
GARP 전파 시간 = 약 1~2초
HAProxy 재기동 = 약 1초
총 Failover 시간 ≈ 5~10초
이 시간 동안 기존 연결은 끊어집니다. SLA에서 이 시간을 허용하는지 확인해야 합니다.
정기적인 Failover 드릴
실제 장애가 발생했을 때 처음으로 Failover를 테스트하면 안 됩니다. 월 1회 이상 정기적으로 Active 서버를 내리는 드릴을 수행해 Failover 시간과 서비스 영향을 측정합니다.
면접에서 자주 나오는 질문
- "HA와 DR(Disaster Recovery)의 차이는 무엇인가요?"
- HA: 같은 데이터센터 내 빠른 장애 복구 (초~분 단위)
- DR: 데이터센터 전체 재해 시 다른 위치로 복구 (분~시간 단위)
- "Split-Brain을 어떻게 방지하나요?"
- Fencing(STONITH): 상대 노드를 강제로 전원 차단
- 쿼럼(Quorum): 홀수 노드에서 과반수 동의 필요
- 네트워크 이중화: Heartbeat 경로를 여러 개 구성
정리
| 개념 | 핵심 요약 |
|---|---|
| SPOF | 하나의 고장이 전체를 중단시키는 단일 취약점 |
| VRRP | Active/Standby 서버 간 VIP를 자동으로 관리하는 프로토콜 |
| VIP | 클라이언트가 바라보는 가상 IP, Failover 시에도 변하지 않음 |
| priority | 높은 서버가 Master(Active) 역할 |
| Failover | Active 장애 시 Standby가 VIP 인계, 수 초 내 완료 |
| Split-Brain | VRRP 통신 차단 시 두 서버가 동시에 Master 주장 |
명령어·단축키 빠른 참조
이 모듈에서 다룬 Keepalived·VRRP·VIP 진단 명령을 실전 옵션과 함께 모았습니다.
| 명령어 | 용도 | 자주 쓰는 예 |
|---|---|---|
apt-get install keepalived | Keepalived 설치(두 노드) | sudo apt-get install -y keepalived (RHEL은 yum install -y keepalived) |
sysctl -w net.ipv4.ip_nonlocal_bind=1 | VIP 바인딩 허용(nonlocal bind) | net.ipv4.ip_forward=1 과 함께 설정 |
keepalived -t -f <conf> | 설정 파일 문법 검증 | sudo keepalived -t -f /etc/keepalived/keepalived.conf |
systemctl status keepalived | MASTER/BACKUP 상태 확인 | 출력에 Entering MASTER STATE 면 VIP 보유 노드 |
systemctl stop keepalived | VRRP 참여 중단(안전한 수동 절체) | Active를 내려 Standby 승격 유도 |
ip addr show | VIP 바인딩 위치 확인 | ip addr show eth0 | grep 192.168.1.100 (한 노드에만 있어야 정상) |
ip link show | 실제 NIC 이름 확인 | interface eth0 오류 시 ens3·enp0s3 대조 |
journalctl -u keepalived | VRRP 로그·오류 추적 | sudo journalctl -u keepalived -n 50 |
tcpdump … vrrp | VRRP 광고 패킷 캡처 | sudo tcpdump -i eth0 -n vrrp (split-brain·차단 확인) |
tcpdump … arp / arp -n | GARP 송출·ARP 캐시 확인 | 절체 후 tcpdump -i eth0 arp, arp -n 으로 옛 MAC 확인 |
firewall-cmd --add-protocol=vrrp | VRRP 방화벽 허용(firewalld) | sudo firewall-cmd --add-protocol=vrrp --permanent && sudo firewall-cmd --reload |
iptables -p vrrp -j ACCEPT | VRRP 허용(iptables) | sudo iptables -A INPUT -p vrrp -j ACCEPT |
관련 모듈로 더 깊이:
- HAProxy 기반 L4/L7 로드밸런싱과 헬스 체크 설정 — VIP 뒤에서 실제 트래픽을 분산하는 HAProxy 구성
- ARP 캐시 원리와 네트워크 IP 충돌 추적 및 해결 — VIP Failover가 의존하는 ARP(Gratuitous ARP) 동작
- tcpdump 사용법과 Wireshark 연동 트러블슈팅 — VRRP·heartbeat 트래픽을 패킷 레벨에서 확인하는 법
다음 챕터에서는 tcpdump로 패킷을 직접 캡처하고 TCP 3-Way Handshake와 재전송 이슈를 분석합니다.