해외 사용자만 서비스가 느리다는 신고가 들어왔습니다. 서버와 앱은 정상인데 중간 경로 어딘가에서 지연이나 손실이 생기고 있습니다.
traceroute와 mtr은 목적지까지의 홉을 보여줍니다. 느린 구간을 찾아야 통신사, 클라우드, 내부망 중 누구에게 넘길지 결정할 수 있습니다.
네트워크 장애 구간 추적 (traceroute / mtr)
인터넷이 느리다, 특정 서버에 접속이 안 된다 — 이런 신고를 받았을 때 어디서부터 조사해야 할까요? ping으로 도달 여부는 확인했지만 어느 구간에서 지연이 발생하는지는 알 수 없습니다. 이 챕터에서는 TTL 원리를 이용해 패킷이 거치는 모든 라우터를 열거하고, 지연 구간을 정확히 특정하는 방법을 배웁니다.
- 1TTL(Time To Live) 감소 원리와 ICMP Time Exceeded 메시지를 설명할 수 있다
- 2traceroute가 TTL을 이용해 각 홉을 열거하는 동작 방식을 이해할 수 있다
- 3traceroute 출력의 홉 번호, IP, 3개 RTT, 별표 표시의 의미를 해석할 수 있다
- 4mtr로 실시간 패킷 손실률과 지연 통계를 지속 추적할 수 있다
- 5Linux/Windows/macOS의 기본 프로토콜 차이(UDP vs ICMP)를 구분할 수 있다
- 6지연이 급증한 홉을 분석하고 ICMP 처리 우선순위를 해석할 수 있다
which traceroute || apt-get install -y traceroutewhich mtr || apt-get install -y mtrtraceroute google.commtr --report 모드는 일정 횟수 프로브 후 결과를 출력하며, 간헐적 장애 분석에 유용
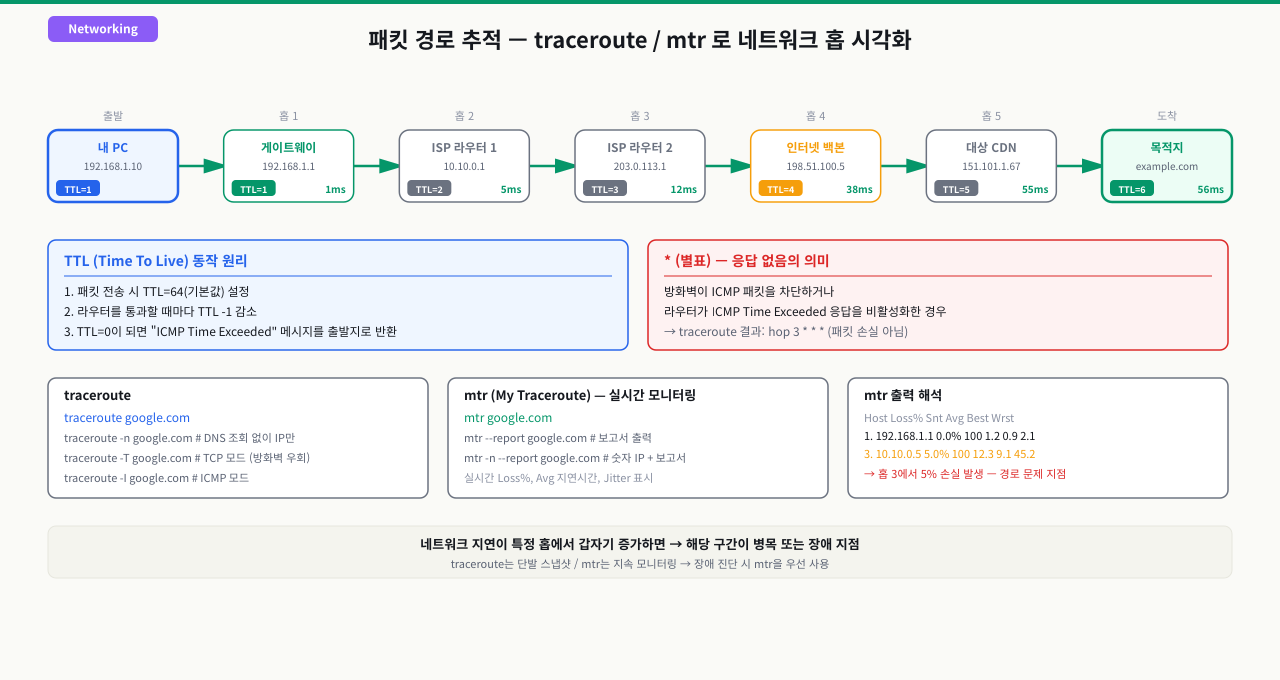
TTL(Time To Live) 감소 원리와 traceroute 동작 방식
외부 API 호출이 간헐적으로 느려집니다. 서버도 정상, 방화벽도 문제없습니다. "네트워크 어딘가에서 지연이 생기는 것 같다"는 말 외에 더 좁힐 수가 없습니다. 이런 상황에서 traceroute를 실행하면 어느 홉(라우터)에서 지연이 발생하는지 즉시 보입니다. 그런데 TTL 동작 원리를 모르면 traceroute가 어떻게 경로를 추적하는지, 출력의 * * *가 무엇을 뜻하는지 해석할 수 없습니다.
 확대
확대
TTL이란 무엇인가
TTL은 IP 패킷 헤더에 포함된 1바이트 정수 필드입니다. 패킷이 라우터를 하나 통과할 때마다 TTL 값이 1씩 감소하며, 값이 0이 되는 순간 해당 라우터는 패킷을 폐기하고 ICMP Type 11 — Time Exceeded 메시지를 출발지로 반환합니다.
이 메커니즘의 원래 목적은 라우팅 루프 방지입니다. 잘못된 라우팅 테이블 설정으로 패킷이 무한히 순환하는 상황을 방지하기 위해, 일정 홉 수를 초과하면 패킷을 강제로 제거합니다.
 확대
확대
traceroute 동작 원리
traceroute는 이 원리를 역이용합니다.
- TTL=1인 패킷을 전송 → 첫 번째 라우터가 ICMP Time Exceeded 반환 → 첫 번째 홉 IP와 응답시간 기록
- TTL=2인 패킷을 전송 → 두 번째 라우터가 ICMP Time Exceeded 반환 → 두 번째 홉 IP와 응답시간 기록
- TTL=N까지 반복 → 최종적으로 목적지에 도달하면 ICMP Port Unreachable(Linux) 또는 ICMP Echo Reply(Windows) 수신
각 TTL 값마다 기본 3개의 프로브 패킷을 보내므로 출력에 3개의 응답 시간이 표시됩니다.
Linux vs Windows 기본 프로토콜 차이
같은 traceroute라도 OS마다 기본 프로토콜이 다릅니다. 방화벽 정책에 따라 UDP가 막히면 ICMP 모드로 전환하면 됩니다.
| OS | 기본 프로토콜 | 목적지 포트 |
|---|---|---|
| Linux | UDP | 33434+n |
| Windows (tracert) | ICMP Echo | — |
| macOS | UDP | 33434+n |
Linux에서 ICMP 모드를 사용하려면 traceroute -I 옵션을 사용합니다. TCP 모드는 traceroute -T -p 80처럼 지정합니다.
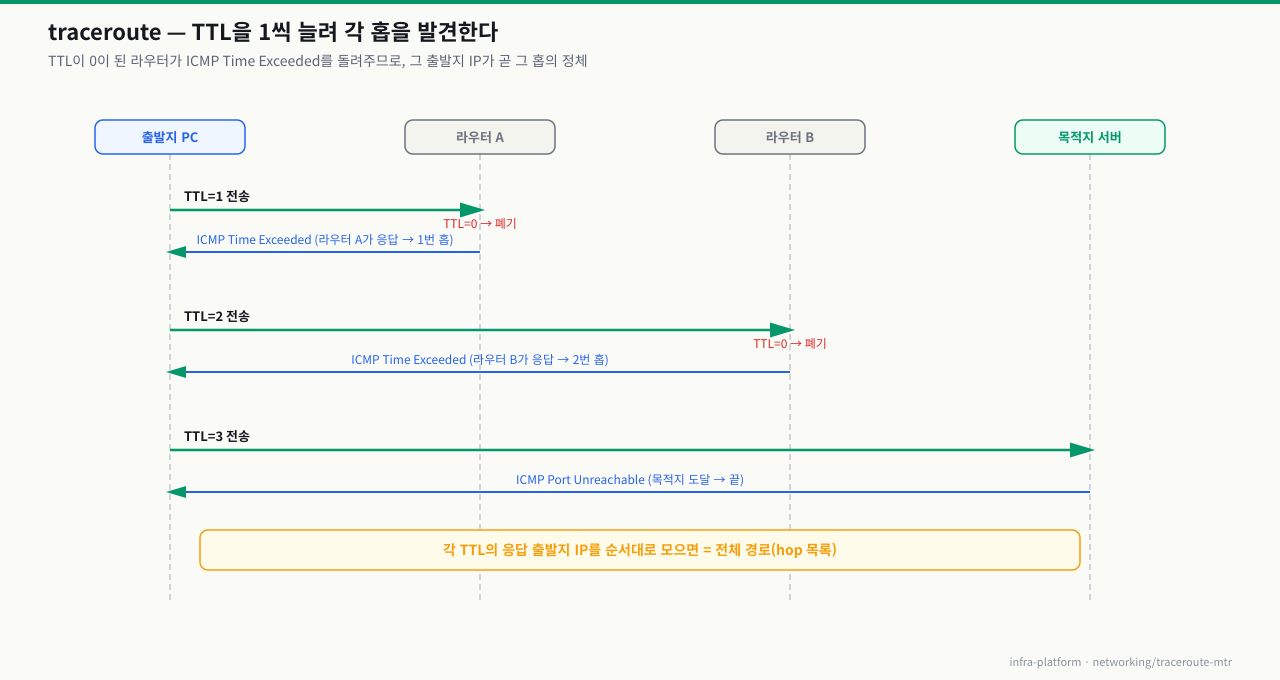
traceroute가 홉을 하나씩 캐내는 실제 과정 — TTL 한 칸씩 5단계
traceroute 한 줄이 경로를 알아내는 실제 과정 — TTL을 한 칸씩 늘리는 반복
traceroute 8.8.8.8 한 줄이면 목적지까지 거치는 라우터가 한 줄씩 나열됩니다. 그런데 traceroute는 경로를 "물어보는" 게 아닙니다 — 일부러 너무 짧게 죽는 패킷을 쏘아, 죽은 지점의 라우터가 자기 정체를 실토하게 만드는 것입니다. 이 반복 과정을 알면 출력의 * * *이나 실행마다 바뀌는 홉이 무엇을 뜻하는지 단계로 해석할 수 있습니다.
[내 PC] traceroute 8.8.8.8
│
① TTL=1 프로브 발사 (기본 3발, UDP 33434+ 또는 ICMP)
│
② 첫 라우터에서 TTL 0 → 패킷 폐기 (홉을 지나며 TTL 1씩 감소)
│ → 그 라우터가 ICMP Time Exceeded(Type 11) 회신
│
③ 회신의 출발지 IP = 1번째 홉 기록 (RTT 3개도 함께)
│
④ TTL=2, 3, 4... 로 ①~③ 반복 (한 칸씩 더 멀리 죽임 → 다음 홉 노출)
│
⑤ 목적지 도달 → 추적 종료 (Port Unreachable[Linux]·Echo Reply[Win])
▼
1 192.168.1.1 0.8 ms 0.7 ms 0.7 ms
2 10.200.0.1 5.2 ms 5.1 ms 5.2 ms
3 * * *
각 단계가 하는 일과, 어긋날 때의 의미:
| 단계 | 하는 일 | 여기서 막히면(무슨 뜻) |
|---|---|---|
| ① 프로브 발사 | TTL을 낮게 세팅한 패킷을 목적지로 쏨(기본 홉당 3발). 리눅스는 UDP 고포트, -I면 ICMP, -T면 TCP | 방화벽이 UDP 고포트를 막으면 전 홉 무응답 → traceroute -T -p 443처럼 TCP로 바꿔 재시도 |
| ② 중간 홉에서 폐기 | 홉을 지날 때마다 TTL이 1씩 줄고, 0이 된 라우터가 패킷을 버리며 Time Exceeded를 회신 | 라우터가 Time Exceeded를 rate-limit·미회신하면 그 홉만 * * *(정상일 수 있음) |
| ③ 홉 기록 | 회신의 출발지 IP를 그 홉으로 적고 왕복 RTT를 표시 | 한 홉만 RTT가 튀고 이후 정상 = 그 라우터의 ICMP 후순위 처리(제어 평면)일 뿐 포워딩 문제 아님 |
| ④ TTL 증가 반복 | TTL을 1씩 키워 다음 홉을 차례로 노출 | 실행마다 같은 홉 번호에 다른 IP = ECMP 다중경로가 프로브를 분산(경로 불안정 아님) |
| ⑤ 목적지 도달 | 목적지가 Port Unreachable(리눅스)·Echo Reply(윈도우)로 응답하면 추적 종료 | 특정 홉부터 끝까지 * * * 지속 = 그 지점 이후 경로 차단·방화벽 매핑 |
즉 traceroute 한 화면은 "TTL을 한 칸씩 늘려 얻은 여러 번의 죽음"을 세로로 쌓아 놓은 것입니다. 그래서 중간 홉의 * * *나 튀는 RTT는 그 라우터가 자기에게 온 ICMP를 홀대한 흔적일 뿐, 통과 트래픽의 손실이 아닌 경우가 많습니다 — 판단 기준은 항상 목적지(마지막 홉)의 손실률·RTT입니다. 단발 traceroute로는 간헐 문제를 놓치므로 같은 원리를 반복 실행해 홉별 통계를 실시간으로 쌓는 mtr로 지속 측정하고, * * *가 방화벽 탓인지 실제 차단인지는 -T(TCP) 모드로 우회해 가릅니다.
traceroute 출력 해석과 mtr 실시간 분석
traceroute google.com을 실행했더니 3번 홉부터 * * *가 계속 나옵니다. 목적지까지 가는지도 모르겠고, 문제가 있는 건지 정상인지도 판단이 안 됩니다. traceroute 출력을 읽을 줄 알고 mtr로 지속 모니터링하는 방법을 알아야 "어느 구간에서 패킷이 막히는가"를 실제로 답할 수 있습니다.
traceroute 출력 구조 이해
# 실습 디렉토리 준비
mkdir -p /tmp/networking/part3/exam_14 && cd /tmp/networking/part3/exam_14
$ traceroute google.com
traceroute to google.com (142.250.196.110), 30 hops max, 60 byte packets
1 192.168.1.1 (192.168.1.1) 0.812 ms 0.734 ms 0.698 ms
2 10.200.0.1 (10.200.0.1) 5.234 ms 5.180 ms 5.201 ms
3 203.0.113.1 (203.0.113.1) 8.445 ms 8.502 ms 8.387 ms
4 * * *
5 72.14.232.85 (72.14.232.85) 12.334 ms 12.298 ms 12.411 ms
6 108.170.252.1 (108.170.252.1) 11.987 ms 12.001 ms 11.956 ms
7 142.250.196.110 (142.250.196.110) 13.221 ms 13.189 ms 13.205 ms
- 읽기 순서 1 — Loss% 먼저—각 홉의 Loss%를 위에서 아래로 훑습니다. 중간 홉 100%는 ICMP 차단(정상)이고, 최종 홉 Loss% > 0%가 실제 장애 지표입니다.
- 읽기 순서 2 — Avg(평균 RTT) 확인—홉 간 Avg RTT 차이가 급격히 커지는 구간을 찾습니다. 그 구간이 지연 발생 지점입니다. 같은 AS 내 20ms 이하, 대륙 간 150~200ms가 정상 범위입니다.
- 읽기 순서 3 — StDev(표준편차) 확인—StDev가 큰 홉은 지연이 불규칙하게 변동하는 것입니다. 단순 지연이 아닌 링크 불안정(링크 품질 문제)을 의미합니다.
- Loss% 판단 기준—0%: 정상 / 1~5%: 경미한 손실(재전송으로 보완 가능) / 5~20%: 불안정(서비스 품질 저하) / 20% 이상: 심각(즉시 조치 필요).
- 중간 홉 100% + 최종 홉 0% 해석—해당 라우터가 ICMP Time Exceeded를 rate-limit하는 정상 동작입니다. 실제 트래픽 경로는 정상입니다. 경보 불필요.
- 특정 홉부터 100% 지속 해석—그 홉 이후 경로가 차단되어 있거나 라우팅 경로가 끊긴 것입니다. TCP 모드(`traceroute -T -p 80`)로 재확인합니다.
- 마지막 홉 100% 해석—목적지 서버 다운 또는 방화벽 차단입니다. ping과 curl로 L3/L7을 각각 분리해 확인합니다.
- 조합 해석 — Loss% 높음 + StDev 큼—링크 불안정 상태입니다. 단순 거리 지연(Avg만 높고 StDev 낮음)과 구분됩니다. 통신사에 회선 품질 점검을 요청하세요.
- 조합 해석 — Avg 높음 + StDev 낮음—물리적 거리나 AS 경유 수에 따른 정상적인 지연입니다. 네트워크 품질 자체는 안정적입니다.
각 컬럼의 의미:
| 컬럼 | 설명 |
|---|---|
| 홉 번호(1, 2, 3...) | 출발지로부터 몇 번째 라우터인지 |
| 호스트명/IP | 해당 라우터의 역방향 DNS 이름과 IP |
| ms 값 3개 | 3번 프로브의 각 왕복 지연시간(RTT) |
* * * | ICMP 응답 없음(차단 또는 타임아웃) |
지연 분석 포인트
- 인접 홉 간 ms 차이가 크면 → 해당 구간 링크 또는 라우터에 병목 의심
- 특정 홉만 높고 이후 정상 → 해당 라우터의 ICMP 처리 우선순위가 낮은 것일 뿐, 실제 데이터 경로는 정상일 수 있음
- 모든 홉이 타임아웃 이후부터 응답 없음 → 해당 구간에서 완전한 차단
mtr — 실시간 지속 추적
mtr은 traceroute와 ping을 결합한 도구입니다. 각 홉으로 프로브를 지속 발송하면서 통계를 실시간 갱신합니다.
$ mtr google.com
My traceroute [v0.94]
hostname (192.168.1.100) 2024-01-15T10:30:00+0900
Keys: Help Display mode Restart statistics Order of fields quit
Packets Pings
Host Loss% Snt Last Avg Best Wrst StDev
1. 192.168.1.1 0.0% 50 0.8 0.9 0.7 1.8 0.2
2. 10.200.0.1 0.0% 50 5.1 5.2 4.9 6.3 0.3
3. 203.0.113.1 0.0% 50 8.3 8.4 8.1 9.2 0.2
4. ??? 100.0% 50 0.0 0.0 0.0 0.0 0.0
5. 72.14.232.85 0.0% 50 12.2 12.3 12.0 13.1 0.2
6. 142.250.196.110 0.0% 50 13.1 13.2 12.9 14.0 0.2
mtr 출력 컬럼 설명:
| 컬럼 | 의미 |
|---|---|
| Loss% | 패킷 손실률 |
| Snt | 전송한 프로브 수 |
| Last | 가장 최근 RTT(ms) |
| Avg | 평균 RTT(ms) |
| Best | 최소 RTT(ms) |
| Wrst | 최대 RTT(ms) |
| StDev | 표준편차(지터 지표) |
mtr에서 특정 홉의 Loss%가 높더라도 그 이후 홉에서 Loss%가 0%라면, 해당 라우터가 ICMP를 제한적으로 처리하는 것이며 실제 경로 손실이 아닙니다. 최종 목적지 홉의 Loss%가 진짜 지표입니다.
준비 사항
- Linux 시스템 (traceroute 패키지 설치 필요)
- 인터넷 접속 또는 내부 네트워크 대상 서버
traceroute 설치 확인
# 설치 여부 확인
which traceroute
# 없으면 설치
# RHEL/CentOS/Rocky Linux
sudo dnf install -y traceroute
# Ubuntu/Debian
sudo apt-get install -y traceroute
기본 traceroute 실행
# 기본 UDP 모드로 google.com까지 경로 추적
traceroute google.com
# ICMP 모드로 실행 (방화벽 환경에서 더 잘 통과하기도 함)
traceroute -I google.com
# 최대 홉 수를 15로 제한
traceroute -m 15 google.com
# 각 홉에 프로브를 5번 전송 (기본 3번)
traceroute -q 5 google.com
# DNS 역방향 조회 없이 IP만 표시 (더 빠름)
traceroute -n google.com
내부망 서버 경로 추적
# 내부 서버로 경로 추적
traceroute -n 10.0.0.100
# TCP 모드로 HTTP 포트 경로 추적 (방화벽 통과 테스트에 유용)
traceroute -T -p 80 10.0.0.100
결과 해석 연습
아래와 같은 출력을 보고 문제 구간을 찾아보세요.
1 192.168.1.1 1 ms 1 ms 1 ms
2 10.200.0.1 5 ms 5 ms 5 ms
3 203.0.113.1 9 ms 9 ms 9 ms
4 203.0.114.5 185 ms 190 ms 188 ms ← 지연 급증!
5 72.14.200.1 15 ms 14 ms 15 ms ← 이후 정상
6 142.250.10.1 18 ms 17 ms 18 ms
홉 4에서 지연이 급증했지만 홉 5부터 정상입니다. 이는 홉 4 라우터가 ICMP를 낮은 우선순위로 처리하는 것으로, 실제 데이터 경로에는 문제가 없을 가능성이 높습니다.
# 확인을 위해 목적지에 직접 ping으로 실제 RTT 측정
ping -c 10 142.250.10.1
mtr 설치 및 기본 실행
# 설치
sudo dnf install -y mtr # RHEL 계열
sudo apt-get install -y mtr # Debian 계열
# 대화형 모드로 실행
mtr google.com
# 비대화형(리포트) 모드 — 100개 패킷 후 결과 출력
mtr --report --report-cycles 100 google.com
# DNS 없이 IP만 표시
mtr -n google.com
# TCP 모드로 특정 포트 경로 추적
mtr --tcp --port 443 google.com
mtr 리포트 모드로 결과 파일 저장
# JSON 형태로 저장 (파싱 자동화에 유용)
mtr --json --report --report-cycles 50 google.com > /tmp/mtr_result.json
# 텍스트 리포트를 파일에 저장
mtr --report --report-cycles 100 google.com | tee /tmp/mtr_$(date +%Y%m%d_%H%M%S).txt
패킷 손실이 있는 경우 판별
# 비대화형 모드 실행
mtr --report --report-cycles 100 -n 8.8.8.8
예시 출력:
HOST: myserver.example.com Loss% Snt Last Avg Best Wrst StDev
1. 192.168.1.1 0.0% 100 0.9 0.9 0.7 1.5 0.1
2. 10.200.0.1 0.0% 100 5.1 5.2 4.9 6.1 0.2
3. 203.0.113.1 30.0% 100 8.4 8.3 8.0 9.5 0.3 ← 손실!
4. 203.0.114.5 0.0% 100 12.1 12.2 11.9 13.0 0.2
5. 8.8.8.8 0.0% 100 12.5 12.6 12.2 13.4 0.2
홉 3에서 30% 손실이 있지만 홉 4, 5에서 0%입니다. 이는 홉 3 라우터의 ICMP 속도 제한(rate limiting)이며, 실제 경로는 정상입니다. 목적지(8.8.8.8)의 Loss%가 0%인 것이 핵심입니다.
반면 목적지 홉의 Loss%가 높다면 실제 패킷 손실입니다.
# 지속적으로 모니터링하며 간헐적 손실 파악
watch -n 30 'mtr --report --report-cycles 20 -n 8.8.8.8 | tail -20'
시나리오
본사 직원들로부터 "지점 서버(10.100.5.50)에 접속이 느리다"는 신고가 들어왔습니다. 네트워크 경로를 추적해 병목 구간을 찾아야 합니다.
단계 1 — 기본 연결 상태 확인
# 1. ping으로 지연시간과 손실률 먼저 확인
ping -c 20 10.100.5.50
# 예시 출력
# rtt min/avg/max/mdev = 45.2/180.3/350.1/95.4 ms
# 평균 180ms, 최대 350ms → 비정상적으로 높음
# 정상 기대치: 지점 간 전용선이면 10~30ms
단계 2 — traceroute로 경로 확인
# DNS 없이 빠르게 경로 확인
traceroute -n 10.100.5.50
# 출력 예시
# 1 192.168.1.1 1 ms 1 ms 1 ms (사무실 공유기)
# 2 10.10.0.1 2 ms 2 ms 2 ms (본사 코어 스위치)
# 3 172.16.0.1 3 ms 3 ms 3 ms (본사 엣지 라우터)
# 4 100.64.0.1 145 ms 148 ms 150 ms ← 통신사 구간 지연 급증
# 5 100.64.1.5 147 ms 149 ms 151 ms
# 6 10.100.0.1 148 ms 152 ms 149 ms (지점 엣지 라우터)
# 7 10.100.5.50 152 ms 155 ms 153 ms
홉 4(통신사 구간)에서 지연이 급증합니다. 본사-지점 전용선(MPLS/SD-WAN) 구간 문제가 의심됩니다.
단계 3 — mtr로 손실률 확인
mtr --report --report-cycles 100 -n 10.100.5.50
HOST: hq-server Loss% Snt Last Avg Best Wrst StDev
1. 192.168.1.1 0.0% 100 1.0 1.0 0.8 1.8 0.1
2. 10.10.0.1 0.0% 100 2.1 2.1 1.9 2.8 0.1
3. 172.16.0.1 0.0% 100 3.2 3.2 3.0 3.9 0.1
4. 100.64.0.1 15.0% 100 148.0 150.5 144.0 320.0 28.3 ← 손실+고지연
5. 100.64.1.5 0.0% 100 149.0 151.0 145.0 310.0 27.1
6. 10.100.5.50 0.0% 100 153.0 155.0 148.0 325.0 27.8
홉 4에서 15% 손실과 높은 표준편차(지터)가 확인됩니다. 이 경우 목적지에서도 간헐적 손실이 있을 수 있습니다.
단계 4 — 증거 수집 및 통신사 신고
# 양방향 확인 (지점에서 본사 방향도)
# 지점 서버에 SSH 접속 후
mtr --report --report-cycles 100 -n 192.168.1.100
# 결과를 타임스탬프와 함께 저장
mtr --report --report-cycles 200 -n 10.100.5.50 \
| tee /tmp/mtr_hq_to_branch_$(date +%Y%m%d_%H%M%S).txt
# 홉 4 IP로 통신사 ASN 조회
whois 100.64.0.1 | grep -E "origin|netname|OrgName"
수집된 결과(구간 IP, 손실률, 지연 시간, 타임스탬프)를 통신사 NOC에 제출합니다.
증상
$ traceroute 10.50.0.100
traceroute to 10.50.0.100 (10.50.0.100), 30 hops max, 60 byte packets
1 * * *
2 * * *
3 * * *
...
30 * * *
30홉 내내 응답이 없고 목적지에도 도달하지 못합니다.
원인 분석
가능한 원인 1 — 방화벽이 UDP/ICMP를 전면 차단
기업 방화벽이 UDP(33434~33534)와 ICMP를 모두 차단하는 경우.
# TCP 모드로 전환하여 확인
traceroute -T -p 80 10.50.0.100 # HTTP 포트
traceroute -T -p 443 10.50.0.100 # HTTPS 포트
traceroute -T -p 22 10.50.0.100 # SSH 포트
# 또는 ICMP 모드
traceroute -I 10.50.0.100
# 실제 서비스 접속이 되는지 확인
nc -zv 10.50.0.100 80
curl -v --connect-timeout 5 http://10.50.0.100/
가능한 원인 2 — 라우팅 테이블에 경로 없음
# 라우팅 테이블 확인
ip route show
ip route get 10.50.0.100 # 특정 목적지 경로 조회
# 출력 예: 경로 없음
# RTNETLINK answers: Network is unreachable
가능한 원인 3 — ARP 실패 (같은 서브넷인 경우)
# 같은 서브넷이면 ARP 테이블 확인
arp -n | grep 10.50.0.100
# 또는
ip neigh show | grep 10.50.0.100
해결 방법
- TCP 모드 traceroute로 실제 서비스 포트 경로를 추적합니다.
ip route get [목적지]명령으로 라우팅 경로를 먼저 확인합니다.ping먼저 시도하여 기본 ICMP 연결 여부를 확인합니다.nc -zv [IP] [포트]로 TCP 레벨 연결 가능 여부를 테스트합니다.
증상
mtr 리포트에서 3번 홉의 손실률이 50%로 표시되지만, 실제 서비스는 정상 동작합니다.
HOST: my-server Loss% Snt Last Avg Best Wrst
1. 192.168.1.1 0.0% 50 0.9 0.9 0.8 1.2
2. 10.200.0.1 0.0% 50 5.1 5.2 5.0 5.9
3. 203.0.113.1 50.0% 50 8.5 8.4 8.1 9.2 ← 손실?
4. 72.14.200.1 0.0% 50 12.0 12.1 11.8 12.9
5. 142.250.10.1 0.0% 50 13.2 13.3 13.0 14.0
원인
홉 3 라우터가 ICMP Time Exceeded 응답에 **속도 제한(rate limiting)**을 적용하고 있습니다. 이는 라우터 CPU 보호를 위한 정상적인 운영 정책입니다. 실제 포워딩 경로의 트래픽은 정상적으로 전달됩니다.
판단 기준
| 상황 | 의미 |
|---|---|
| 중간 홉 Loss% 높음, 목적지 Loss% = 0% | 라우터 ICMP 속도 제한 — 정상 |
| 중간 홉 Loss% 높음, 목적지 Loss% > 0% | 실제 경로 손실 — 장애 조사 필요 |
| 목적지 Loss% = 0%이지만 Wrst(최대 지연) 매우 높음 | 간헐적 지연 — 지터 문제 |
올바른 진단 방법
# 1. 목적지 홉의 Loss%와 Wrst에 집중
mtr --report --report-cycles 200 -n 목적지IP
# 2. 실제 TCP 연결 지연 측정
curl -o /dev/null -s -w \
"DNS: %{time_namelookup}s\nConnect: %{time_connect}s\nTotal: %{time_total}s\n" \
http://목적지IP/
# 3. 애플리케이션 레벨에서 응답 시간 직접 측정
time curl -s http://목적지IP/ > /dev/null
심화 — traceroute가 보여주는 경로를 그대로 믿으면 안 되는 이유
심화: ECMP 다중경로와 왕복 RTT — 홉이 흔들려 보이는 진짜 이유
traceroute 화면을 '패킷이 실제로 가는 하나의 길'로 읽으면 자주 오진합니다. 각 홉의 RTT가 어떻게 측정되는지, 그리고 현대 백본이 트래픽을 어떻게 흩뿌리는지를 알면 '경로가 불안정하다'는 착시가 걷힙니다.
- traceroute는 앞으로 가는 길만 보여줍니다: 각 홉의 RTT는 '내 호스트 → 그 홉 → 다시 내 호스트'의 왕복 시간입니다. 그래서 특정 홉만 RTT가 튀고 이후 홉이 정상이면, 그 홉의 복귀 경로나 제어 평면 응답이 느린 것일 뿐 포워딩 문제는 아닌 경우가 많습니다. 게다가 되돌아오는 길(복귀 경로)은 가는 길과 완전히 다를 수 있어(비대칭 라우팅) traceroute로는 보이지 않습니다.
- ECMP가 프로브를 서로 다른 길로 흩뿌립니다: 백본 라우터는 등가 경로가 여러 개면 트래픽을 5-tuple 해시로 분산합니다(ECMP). 문제는 고전 traceroute가 홉을 구분하려고 프로브마다 목적지 포트를 1씩 증가시킨다는 점 — 각 프로브가 다른 '흐름'이 되어 다른 물리 경로로 해시됩니다. 그래서 같은 홉 번호에서 실행마다 다른 라우터 IP가 보이고, 없던 손실이 오락가락합니다. 실제 경로가 흔들리는 게 아니라 여러 병렬 경로가 섞여 보이는 것입니다.
- rate limiting과 구분하는 법: 중간 홉 손실이 라우터 ICMP 속도 제한이면 IP는 안정적이고 손실률이 꾸준합니다. ECMP 착시면 실행마다 IP가 바뀌고 손실이 들쭉날쭉합니다. 이 차이로 두 원인을 가릅니다.
- 그래서 흐름을 고정합니다: paris-traceroute·dublin-traceroute는 흐름 식별자(포트 등)를 고정해 모든 프로브가 하나의 ECMP 경로만 따르게 하므로, 안정적이고 진실된 단일 경로를 보여줍니다. 사용자 체감은 결국 **목적지 홉의 Loss%**와 end-to-end 응답 시간으로 판단하고, 중간 홉 숫자는 참고로만 씁니다.
상황: 간헐적 지연을 조사하려고 traceroute·mtr을 반복 실행했더니, 5~6번 홉의 라우터 IP가 실행마다 다르게 나오고 그 홉의 손실률이 0%였다 20%였다 흔들립니다. RTT도 이따금 한 홉만 튀고 이후 홉은 정상입니다. 팀은 '경로가 불안정하다'고 결론 내리려 합니다.
원인: ECMP(등가 다중경로) 다중경로입니다. 고전 traceroute가 프로브마다 목적지 포트를 바꾸는 탓에 각 프로브가 다른 흐름으로 해시돼 서로 다른 등가 경로를 타고, 여러 병렬 경로가 한 화면에 섞여 '흔들리는 홉'처럼 보인 것입니다. 손실도 실제 유실이 아니라 경로 변동이고, 한 홉만 튀는 RTT는 왕복·복귀 경로 특성일 뿐입니다.
진단: 중간 홉 IP가 실행마다 바뀌는지(ECMP) 아니면 고정인지(rate limiting)를 먼저 봅니다. paris-traceroute(또는 dublin-traceroute)로 흐름을 고정해 단일 경로를 추적하면 홉이 안정됩니다. 결정적 지표는 목적지 홉의 Loss% — 여기가 0%면 중간 홉 변동은 대개 무해합니다. mtr --report -n 목적지의 마지막 줄과 curl -w end-to-end 타이밍을 함께 봅니다.
해결: 경로 판단은 흐름을 고정하는 도구(paris/dublin-traceroute)로 하고, 홉 RTT는 '그 홉까지의 왕복'임을 감안해 한 홉의 스파이크만으로 그 구간을 범인으로 몰지 않습니다. 사용자 체감 지연은 중간 홉이 아니라 end-to-end 측정(curl 타이밍·애플리케이션 응답)으로 확정하고, 목적지 홉에서 실제 손실이 잡힐 때만 회선/통신사 조사로 넘어갑니다.
실무에서 traceroute/mtr을 사용하는 상황
1. 사용자 민원 대응
"인터넷이 느리다", "특정 사이트가 느리다"는 신고를 받으면 가장 먼저 traceroute와 mtr로 어느 구간에서 지연이 발생하는지 확인합니다. ISP 구간 문제인지, 내부망 문제인지, 목적지 서버 문제인지 신속하게 구분할 수 있습니다.
2. 신규 회선 개통 검증
새로운 인터넷 전용선이나 MPLS 회선을 개통했을 때 traceroute로 경로가 의도한 대로 구성되었는지, 지연 시간이 SLA에 부합하는지 검증합니다.
3. 통신사 장애 신고 근거 자료
통신사 NOC(Network Operations Center)에 장애를 신고할 때 mtr 리포트(타임스탬프 포함)를 첨부하면 정확한 구간 정보를 제공할 수 있어 처리가 빨라집니다.
4. 정기 모니터링 자동화
#!/bin/bash
# 매시간 mtr 리포트를 저장하는 cron 스크립트
TARGETS="8.8.8.8 10.100.5.50 203.0.113.100"
LOG_DIR="/var/log/mtr"
mkdir -p "$LOG_DIR"
for target in $TARGETS; do
filename="${LOG_DIR}/mtr_${target}_$(date +%Y%m%d_%H%M%S).txt"
mtr --report --report-cycles 50 -n "$target" > "$filename"
done
크론탭에 등록:
# crontab -e
0 * * * * /usr/local/bin/mtr-monitor.sh
자격증 시험 관련 포인트
- CCNA / CCNP: TTL 원리, ICMP Time Exceeded 메시지 구조는 필수 지식
- Linux LPIC / RHCE: traceroute, mtr 명령 옵션과 출력 해석
- AWS/GCP 인증: 클라우드 VPC 내 경로 추적, Transit Gateway 홉 분석에도 동일 원리 적용
클라우드 환경에서의 주의사항
AWS, Azure, GCP 등 클라우드 환경에서는 ICMP를 보안 그룹/방화벽 규칙으로 차단하는 경우가 많습니다. 이 경우 traceroute -T -p 443처럼 TCP 모드를 사용하거나, 클라우드 콘솔의 Network Reachability Analyzer 같은 전용 도구를 활용합니다.
핵심 명령어 정리
| 명령 | 설명 |
|---|---|
traceroute 목적지 | 기본 UDP 모드로 경로 추적 |
traceroute -n 목적지 | DNS 역조회 없이 IP로만 표시 |
traceroute -I 목적지 | ICMP 모드 |
traceroute -T -p 80 목적지 | TCP 80 포트 모드 |
traceroute -m 20 목적지 | 최대 홉 수 20으로 제한 |
mtr 목적지 | 실시간 대화형 추적 |
mtr --report -n 목적지 | 비대화형 리포트 모드 |
mtr --report-cycles 100 목적지 | 100개 패킷 후 리포트 |
mtr --tcp --port 443 목적지 | TCP 모드 mtr |
정리
- TTL 감소 원리를 이용해 traceroute는 각 홉의 라우터 IP와 응답시간을 수집합니다.
* * *는 ICMP 차단을 의미하며 반드시 장애는 아닙니다. TCP 모드로 우회 테스트합니다.- mtr은 지속적인 통계 수집으로 간헐적 패킷 손실과 지터를 파악하는 데 유용합니다.
- 중간 홉의 높은 Loss%는 ICMP 속도 제한일 수 있으며, 목적지 홉의 Loss%가 실제 장애 판단 기준입니다.
- 실무에서는 mtr 리포트를 파일로 저장하여 통신사 신고 근거로 활용합니다.
관련 모듈로 더 깊이:
- ping과 ICMP 프로토콜을 이용한 초동 경로 진단 — 경로 추적 전 ICMP로 기본 도달성을 먼저 확인하는 법
- 라우팅 테이블(Route Table) 조회와 게이트웨이 추가/삭제 — traceroute가 드러낸 경로가 라우팅 테이블과 맞는지 검증하는 법
- 웹 서버에서 DB 접속 실패 시 원인 격리 프로세스 — 어느 구간에서 끊겼는지 경로 추적을 장애 격리에 활용하는 법
다음 모듈에서는 curl로 HTTP 응답 코드와 헤더를 분석하고 서버 사이드 에러(5xx)를 진단하는 방법을 다룹니다.