배포 전마다 여러 서버의 DB, Redis, API 포트를 사람이 손으로 확인합니다. 어느 날 한 포트를 빼먹어 장애가 났고, 체크리스트는 있었지만 자동 증거는 없었습니다.
반복 점검은 스크립트로 남겨야 합니다. 성공과 실패를 같은 형식으로 기록하면 장애 전후 비교가 쉬워집니다.
네트워크 통신 점검 쉘 스크립트
"어젯밤에 DB 연결이 잠깐 끊겼는데 언제 어느 서버인지 모르겠다."
자동화된 점검 스크립트가 있다면 이런 문제를 사전에 감지하고 기록할 수 있습니다.
이 챕터에서는 nc와 bash를 활용해 여러 서버의 포트 통신을 자동 점검하는
스크립트를 단계적으로 완성합니다.
1. 핵심 도구와 개념
- 1nc -zv -w 옵션과 종료 코드($?)를 이용한 포트 점검 원리를 이해할 수 있다
- 2타임스탬프 로그 기록과 bash 배열 루프를 활용할 수 있다
- 3단일 포트 점검을 다중 서버 배열 루프 점검으로 확장할 수 있다
- 4crontab 주기 표현식으로 자동 실행을 등록할 수 있다
- 5장애 감지 시 슬랙·이메일 알림을 연동할 수 있다
- 6cron 환경 PATH 문제와 스크립트 실행 권한 문제를 트러블슈팅할 수 있다
which ncmkdir -p /opt/scriptssystemctl status crond || systemctl status cronls -la /var/log/netcheck.log 2>/dev/null || echo '로그 없음 (첫 실행 후 생성됨)'nc(netcat)와 종료 코드($?)를 이용한 포트 점검
매일 아침 출근하면 외부 API 연동 서비스가 죽어있습니다. 새벽에 외부 포트가 일시적으로 막혔다가 복구됐지만 서비스는 재시작되지 않은 것입니다. 이런 상황을 자동으로 감지하고 알람을 보내려면 포트 점검 스크립트가 필요합니다. nc의 종료 코드를 활용하면 조건 분기 없이 포트 열림/닫힘을 판별하는 스크립트를 깔끔하게 만들 수 있습니다.
 확대
확대
네트워크 점검 스크립트의 핵심은 nc의 종료 코드를 활용하는 것입니다.
nc -zv -w 옵션 설명
# 실습 디렉토리 준비
mkdir -p /tmp/networking/part6/exam_32 && cd /tmp/networking/part6/exam_32
nc -zv -w 3 192.168.1.200 3306
- exit code 우선 확인—echo $? 출력이 0이면 성공, 1이면 실패 — 스크립트 분기의 기준값입니다
- 응답 시간 판단—ping RTT가 100ms 이상이면 지연 의심, curl -w "%{time_total}" 결과가 3초 초과면 타임아웃 원인 조사
- HTTP 상태코드 조합—200이면 정상, 5xx이면 서버 오류(서비스 점검), 000이면 TCP 연결 자체가 실패한 것
| 옵션 | 의미 |
|---|---|
-z | 데이터 전송 없이 연결 가능 여부만 확인 (zero I/O) |
-v | 상세 출력 (verbose) |
-w 3 | 연결 타임아웃 3초 (wait) |
종료 코드($?)로 성공/실패 판단
# 포트 점검 후 종료 코드 확인
nc -zv -w 3 192.168.1.200 3306
echo $?
# 0 → 연결 성공 (포트 열려 있음)
# 1 → 연결 실패 (포트 닫힘, 방화벽 차단, 서버 다운 등)
if문과 결합
nc -zv -w 3 192.168.1.200 3306 2>/dev/null
if [ $? -eq 0 ]; then
echo "SUCCESS: DB 포트 정상"
else
echo "FAIL: DB 포트 응답 없음"
fi
# 축약 표현 (더 일반적)
if nc -zv -w 3 192.168.1.200 3306 2>/dev/null; then
echo "SUCCESS"
else
echo "FAIL"
fi
2>/dev/null 의미
nc -v는 상세 메시지를 stderr(2)로 출력합니다.
2>/dev/null은 stderr를 /dev/null로 버려서 화면 출력을 억제합니다.
스크립트 로그에는 직접 작성한 메시지만 남도록 할 때 유용합니다.
타임스탬프 로그와 배열 루프
포트 점검 스크립트가 실패했습니다. 그런데 언제 실패했는지 로그에 시간이 없어서 새벽 3시에 발생한 장애인지 아침 9시에 발생한 건지 알 수 없습니다. 또 점검 대상이 늘어날수록 서버 목록을 일일이 하드코딩해야 합니다. 타임스탬프 로깅과 배열 루프를 활용하면 스크립트를 실무에서 실제로 쓸 수 있는 수준으로 만들 수 있습니다.
타임스탬프 기록
# date 명령으로 현재 시각 형식 지정
date '+%Y-%m-%d %H:%M:%S'
# 출력: 2024-01-15 14:30:25
# 변수에 저장
TIMESTAMP=$(date '+%Y-%m-%d %H:%M:%S')
echo "[$TIMESTAMP] 점검 시작"
# 로그 파일에 기록 (>>: 이어쓰기, >: 덮어쓰기)
echo "[$TIMESTAMP] 포트 점검 결과" >> /var/log/netcheck.log
배열 선언과 루프
# bash 배열 선언
SERVERS=("192.168.1.100" "192.168.1.200" "192.168.1.201")
PORTS=(3306 6379 8080)
# 배열 순회
for server in "${SERVERS[@]}"; do
echo "점검 중: $server"
done
# 인덱스와 함께 순회
for i in "${!SERVERS[@]}"; do
echo "서버 $i: ${SERVERS[$i]}"
done
# 배열 길이
echo "서버 수: ${#SERVERS[@]}"
로그 파일 관리
LOG_FILE="/var/log/netcheck.log"
# 로그 디렉터리 생성 (없으면)
mkdir -p $(dirname $LOG_FILE)
# 로그 크기 제한 (7일 이상 된 항목 삭제)
find /var/log/ -name "netcheck*.log" -mtime +7 -delete
# logrotate 설정 파일 예시
# /etc/logrotate.d/netcheck
# /var/log/netcheck.log {
# daily
# rotate 7
# compress
# missingok
# notifempty
# }
점검 스크립트가 한 번 돌 때 무슨 일이 일어나나 — 대상 목록부터 호출자 조치까지 5단계
netcheck.sh 한 번 실행. 로그에 OK/FAIL이 쌓이고 종료코드가 남습니다. 이 사이에 스크립트는 대상 목록을 읽고 → 각 대상을 점검하고 → 성공/실패를 판정하고 → 종료코드·리포트로 요약하고 → 호출자(cron·모니터링)가 조치하는 5단계를 밟습니다. 이 흐름을 단계로 알면 "왜 스크립트가 멈췄지", "왜 거짓 OK지", "왜 cron이 안 잡지"가 각각 다른 단계의 문제임을 알 수 있습니다. 점검이 "잘 돈다"는 것은 아래 다섯 단계가 모두 성립했다는 뜻입니다.
[호출자] cron: */5 * * * * netcheck.sh
│
① 대상 목록 로드 (배열/파일: "host:port:desc" 순회 준비)
│
② 각 대상 점검(순차) (nc -zw3 · ping · dig · curl /health)
│ → -w 타임아웃으로 무응답 대상에서 매달리지 않음
│
③ 결과 판정 (직후 $? 로 성공/실패 · 연속 실패 카운트)
│
④ 종료코드·리포트 (로그에 타임스탬프+대상+결과 · exit N)
│
⑤ 호출자 조치 (cron 메일 · Slack/메일 알림 · Nagios 코드 규약)
▼
[운영자] "03:47 App-Server FAIL" 로그·알림 수신
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① 목록 로드 | 점검 대상을 배열이나 파일로 읽어 순회 준비. bash 배열은 TARGETS=("h:p:desc" ...) 소괄호 구조만 정상 순회 | 파이썬·JS식 대괄호·콤마 표기 → 문법 오류로 루프가 한 덩어리로 돌거나 아예 안 돎 |
| ② 각 점검(순차) | 대상마다 점검을 순차 실행. nc -zw3로 포트, ping으로 호스트, dig로 DNS, curl로 HTTP. -w 타임아웃이 핵심 | -w 누락 + 방화벽 DROP → 그 대상에서 수십 초 매달려 다음 점검·다음 주기와 겹침 / ICMP만 막힌 곳을 ping으로 재면 서비스는 멀쩡한데 거짓 실패 |
| ③ 결과 판정 | 점검 직후 $?로 성공(0)·실패(비0) 판정. 오탐 줄이려 연속 N회 실패를 카운트 | nc와 판정 사이에 echo 등이 끼면 $?가 그 명령 코드로 덮여 오판 / nc -z OK를 서비스 정상으로 오인(L4≠L7, UDP 거짓 OK) |
| ④ 코드·리포트 | 타임스탬프+대상+결과를 로그에 남기고, 실패 건수를 종료코드로 반환(exit $FAIL_COUNT) | 상태 전이(OK↔FAIL) 무시하고 매번 알림 → 폭주 / 종료코드 규약(0·1·2) 안 지키면 Nagios·모니터링이 상태를 오해 |
| ⑤ 호출자 조치 | cron·모니터링이 종료코드·리포트를 받아 메일·Slack·에스컬레이션. 복구(FAIL→OK)도 알림 | cron PATH에 nc 없음·실행권한 없음 → 스크립트가 아예 안 돎(로그 무변화) |
즉 "점검이 제대로 돌았다"는 다섯 단계가 모두 성립한 결과입니다 — 목록을 읽었고(①), 타임아웃 안에 각 대상을 쟀고(②), $?를 정확히 잡아 판정했고(③), 규약대로 요약해(④) 호출자가 받았습니다(⑤). 고장은 층으로 갈립니다 — 로그가 아예 없으면 ⑤(cron·권한·PATH), 스크립트가 멈추면 ②(타임아웃 누락), FAIL이 거짓이면 ③($? 덮임), OK가 거짓이면 ②③(L4만 확인·UDP)입니다. 점검 스크립트의 진짜 실력은 "연결되나"가 아니라 "이 다섯 단계 중 어디서 속는가"를 아는 데서 나옵니다.
2. 기본 5줄 점검 스크립트
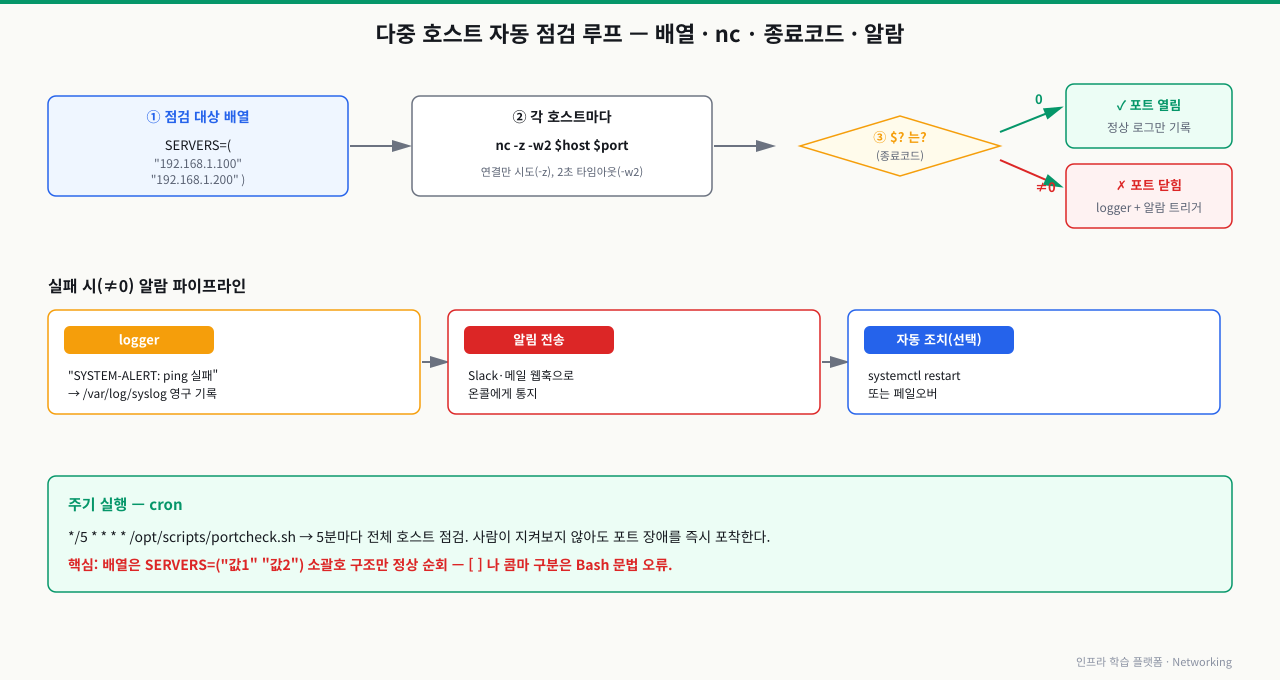 확대
확대
쉘 스크립트 작성 시 필수적인 Bash 리스트 핸들링과 logger 활용
네트워크 점검 자동화 스크립트를 작성할 때 다수의 호스트 IP를 일괄 루프로 돌리기 위해 SRE는 다음과 같은 문법적 디테일을 준수해야 합니다.
- 올바른 Bash 1차원 배열 선언:
SERVERS=("192.168.1.100" "192.168.1.200")- 공백으로 항목을 구분하고 소괄호
()로 감싸 선언해야 루프 내부에서 정상 순회합니다. SERVERS=["192.168.1.100", "192.168.1.200"](파이썬/JS 리스트 표기법) 또는SERVERS:192.168.1.100,192.168.1.200등은 문법 오류를 일으키며, 오직SERVERS=("값1" "값2")처럼 소괄호 구조만 정상 인식합니다.
- 공백으로 항목을 구분하고 소괄호
- logger 명령어를 통한 시스템 로그 수집:
스크립트 진단 결과나 타임스탬프가 가미된 경고 메시지를 로컬 파일 외에 시스템 표준 중앙 로그 데몬에 전송할 때는
logger명령어를 사용해/var/log/syslog(또는/var/log/messages)에 영구 기록시킵니다.로컬 터미널# 시스템 syslog에 실시간 네트워크 진단 경고 기록 $ logger "SYSTEM-ALERT: Network ping check failed for database server!"
mkdir -p /tmp/networking/part6/scripts && cd /tmp/networking/part6/scripts
cat > targets.txt << 'EOF'
8.8.8.8 Google DNS
1.1.1.1 Cloudflare DNS
192.168.1.1 Gateway
EOF
cat > check_base.sh << 'EOF'
#!/bin/bash
# 네트워크 점검 기본 템플릿
TARGETS_FILE="${1:-targets.txt}"
LOG_FILE="network_check_$(date +%Y%m%d_%H%M%S).log"
check_host() {
local ip="$1"
local name="$2"
if ping -c 1 -W 2 "$ip" &>/dev/null; then
echo "✓ $name ($ip): reachable"
else
echo "✗ $name ($ip): UNREACHABLE"
fi
}
echo "=== Network Check $(date) ===" | tee "$LOG_FILE"
while read -r ip name; do
check_host "$ip" "$name" | tee -a "$LOG_FILE"
done < "$TARGETS_FILE"
EOF
chmod +x check_base.sh
먼저 가장 단순한 형태의 포트 점검 스크립트를 작성합니다.
#!/bin/bash
# 파일: /opt/scripts/netcheck-simple.sh
# 기본 5줄 포트 점검 스크립트
TARGET_HOST="192.168.1.200"
TARGET_PORT="3306"
LOG_FILE="/var/log/netcheck.log"
TIMESTAMP=$(date '+%Y-%m-%d %H:%M:%S')
nc -zv -w 3 "$TARGET_HOST" "$TARGET_PORT" 2>/dev/null \
&& echo "[$TIMESTAMP] OK ${TARGET_HOST}:${TARGET_PORT}" >> "$LOG_FILE" \
|| echo "[$TIMESTAMP] FAIL ${TARGET_HOST}:${TARGET_PORT}" >> "$LOG_FILE"
실행 권한 부여 및 테스트
chmod +x /opt/scripts/netcheck-simple.sh
# 직접 실행
/opt/scripts/netcheck-simple.sh
# 로그 확인
cat /var/log/netcheck.log
# [2024-01-15 14:30:25] OK 192.168.1.200:3306
# [2024-01-15 14:35:25] FAIL 192.168.1.200:3306 ← 장애 발생 시
&& 와 || 연산자 이해
명령A && 명령B # 명령A가 성공(0)일 때만 명령B 실행
명령A || 명령B # 명령A가 실패(non-0)일 때만 명령B 실행
# nc 성공 → && 이후 OK 기록
# nc 실패 → || 이후 FAIL 기록
여러 서버와 포트를 배열로 관리하는 확장 버전을 작성합니다.
#!/bin/bash
# 파일: /opt/scripts/netcheck.sh
# 다중 서버 포트 점검 스크립트
LOG_FILE="/var/log/netcheck.log"
TIMEOUT=3
# 점검 대상: "호스트:포트:설명" 형식
TARGETS=(
"192.168.1.200:3306:MySQL-DB"
"192.168.1.200:6379:Redis-Cache"
"192.168.1.100:8080:App-Server"
"192.168.1.100:80:Nginx"
"10.0.0.10:5432:PostgreSQL"
)
# 로그 디렉터리 생성
mkdir -p $(dirname "$LOG_FILE")
TIMESTAMP=$(date '+%Y-%m-%d %H:%M:%S')
FAIL_COUNT=0
echo "[$TIMESTAMP] ===== 네트워크 점검 시작 =====" >> "$LOG_FILE"
for target in "${TARGETS[@]}"; do
# "호스트:포트:설명" 파싱
HOST=$(echo "$target" | cut -d: -f1)
PORT=$(echo "$target" | cut -d: -f2)
DESC=$(echo "$target" | cut -d: -f3)
# 포트 점검
if nc -zv -w "$TIMEOUT" "$HOST" "$PORT" 2>/dev/null; then
echo "[$TIMESTAMP] OK ${HOST}:${PORT} (${DESC})" >> "$LOG_FILE"
else
echo "[$TIMESTAMP] FAIL ${HOST}:${PORT} (${DESC})" >> "$LOG_FILE"
FAIL_COUNT=$((FAIL_COUNT + 1))
fi
done
echo "[$TIMESTAMP] ===== 점검 완료 (실패: ${FAIL_COUNT}건) =====" >> "$LOG_FILE"
# 실패가 있으면 비정상 종료 코드 반환 (cron에서 메일 발송 트리거 가능)
exit $FAIL_COUNT
실행 및 로그 확인
chmod +x /opt/scripts/netcheck.sh
/opt/scripts/netcheck.sh
# 로그 확인
tail -20 /var/log/netcheck.log
# [2024-01-15 14:30:00] ===== 네트워크 점검 시작 =====
# [2024-01-15 14:30:00] OK 192.168.1.200:3306 (MySQL-DB)
# [2024-01-15 14:30:00] OK 192.168.1.200:6379 (Redis-Cache)
# [2024-01-15 14:30:00] FAIL 192.168.1.100:8080 (App-Server)
# [2024-01-15 14:30:00] OK 192.168.1.100:80 (Nginx)
# [2024-01-15 14:30:00] FAIL 10.0.0.10:5432 (PostgreSQL)
# [2024-01-15 14:30:00] ===== 점검 완료 (실패: 2건) =====
5분마다 자동으로 점검이 실행되도록 cron에 등록합니다.
# crontab 편집
crontab -e
# 다음 내용 추가:
# 5분마다 점검 스크립트 실행
*/5 * * * * /opt/scripts/netcheck.sh
# 매시간 정각에 실행
# 0 * * * * /opt/scripts/netcheck.sh
# 매일 오전 9시에 실행
# 0 9 * * * /opt/scripts/netcheck.sh
cron 표현식 이해
*/5 * * * * 명령은 5분마다 실행을 의미합니다. 다섯 자리는 각각 다음 시간 단위입니다.
| 위치 | 필드 | 범위 |
|---|---|---|
| 1번째 | 분 | 0-59 |
| 2번째 | 시 | 0-23 |
| 3번째 | 일 | 1-31 |
| 4번째 | 월 | 1-12 |
| 5번째 | 요일 | 0-7 (0과 7은 일요일) |
*/5는 5의 배수 분마다(0, 5, 10, 15 …)를 뜻합니다.
cron 등록 후 확인
# 현재 crontab 확인
crontab -l
# */5 * * * * /opt/scripts/netcheck.sh
# cron 서비스 상태 확인
systemctl status crond # CentOS
systemctl status cron # Ubuntu
# cron 실행 로그 확인
grep netcheck /var/log/cron # CentOS
grep netcheck /var/log/syslog # Ubuntu
journalctl -u cron | grep netcheck # systemd 환경
cron 실행 환경 주의사항
# cron은 PATH가 제한되어 있어 전체 경로 사용 필수
# /etc/nc → nc 대신 /usr/bin/nc 또는 /bin/nc
which nc # nc의 전체 경로 확인
# 스크립트 상단에 PATH 명시하거나 스크립트 내에서 절대 경로 사용
NC=/usr/bin/nc
$NC -zv -w 3 "$HOST" "$PORT"
장애 감지 시 즉시 알림이 가도록 스크립트를 확장합니다.
#!/bin/bash
# 파일: /opt/scripts/netcheck-alert.sh
# 장애 감지 시 알림 포함 버전
LOG_FILE="/var/log/netcheck.log"
TIMEOUT=3
SLACK_WEBHOOK="https://hooks.slack.com/services/YOUR/WEBHOOK/URL"
ALERT_EMAIL="ops-team@company.com"
TARGETS=(
"192.168.1.200:3306:MySQL-DB"
"192.168.1.200:6379:Redis-Cache"
"192.168.1.100:8080:App-Server"
)
TIMESTAMP=$(date '+%Y-%m-%d %H:%M:%S')
HOSTNAME=$(hostname)
FAILED_SERVICES=""
for target in "${TARGETS[@]}"; do
HOST=$(echo "$target" | cut -d: -f1)
PORT=$(echo "$target" | cut -d: -f2)
DESC=$(echo "$target" | cut -d: -f3)
if nc -zv -w "$TIMEOUT" "$HOST" "$PORT" 2>/dev/null; then
echo "[$TIMESTAMP] OK ${HOST}:${PORT} (${DESC})" >> "$LOG_FILE"
else
echo "[$TIMESTAMP] FAIL ${HOST}:${PORT} (${DESC})" >> "$LOG_FILE"
FAILED_SERVICES="${FAILED_SERVICES}\n- ${DESC} (${HOST}:${PORT})"
fi
done
# 장애 발생 시 알림
if [ -n "$FAILED_SERVICES" ]; then
ALERT_MSG="[$HOSTNAME] 네트워크 장애 감지 (${TIMESTAMP}):\n${FAILED_SERVICES}"
# 슬랙 알림
if command -v curl &>/dev/null; then
curl -s -X POST "$SLACK_WEBHOOK" \
-H 'Content-type: application/json' \
--data "{\"text\":\"$ALERT_MSG\"}" > /dev/null
fi
# 이메일 알림 (mailx 필요)
if command -v mail &>/dev/null; then
echo -e "$ALERT_MSG" | mail -s "[ALERT] 네트워크 장애 감지" "$ALERT_EMAIL"
fi
fi
3. 장애 사례 분석
증상
/opt/scripts/netcheck.sh
# [2024-01-15 14:30:00] 점검 시작
# [2024-01-15 14:30:00] OK 192.168.1.200:3306 (MySQL-DB)
# (여기서 스크립트가 수 분 동안 멈춤...)
원인 분석
-w 타임아웃 옵션 없이 nc를 사용하면,
방화벽이 패킷을 DROP하는 서버에 대해 기본 타임아웃(수십 초)만큼 대기합니다.
# 잘못된 예 — 타임아웃 없음
nc -zv 192.168.1.201 3306 # DROP 구간에서 멈춤
# 올바른 예 — 3초 타임아웃
nc -zv -w 3 192.168.1.201 3306
스크립트 실행 시간 측정
# 타임아웃 없이 5개 서버 점검 시
# → 각 DROP 서버에서 ~30초 × 5 = 150초 소요
# -w 3 설정 시
# → 각 DROP 서버에서 3초 × 5 = 15초 소요
# → 10배 빠른 점검 완료
수정 후 스크립트
# TIMEOUT 변수를 환경에 맞게 조정
TIMEOUT=3 # 내부망: 3초, 인터넷 구간: 5-10초
nc -zv -w "$TIMEOUT" "$HOST" "$PORT" 2>/dev/null
교훈: 네트워크 점검 스크립트에서 -w(타임아웃)는 선택이 아닌 필수입니다.
cron에서 실행되는 스크립트가 멈추면 다음 실행 시 겹쳐서 프로세스가 쌓입니다.
증상
# crontab에 등록했는데 로그가 쌓이지 않음
crontab -l
# */5 * * * * /opt/scripts/netcheck.sh
# 5분 후에도 /var/log/netcheck.log 변화 없음
원인 확인 및 해결
이 명령은 실행 중인 서비스 상태를 바꿔 순간적인 중단이나 설정 반영 실패를 만들 수 있습니다. 운영 트래픽 영향과 재시작 후 확인 명령을 먼저 준비하세요.
# [원인 1] 실행 권한 없음
ls -la /opt/scripts/netcheck.sh
# -rw-r--r-- 1 root root ... ← 실행 권한 없음!
# 해결
chmod +x /opt/scripts/netcheck.sh
# [원인 2] cron 서비스 미실행
systemctl status crond
# inactive (dead)
# 해결
systemctl start crond
systemctl enable crond
# [원인 3] nc가 cron 환경 PATH에 없음
# cron은 /usr/bin:/bin 정도만 PATH에 포함
# 스크립트 첫 줄에 PATH 추가
head -3 /opt/scripts/netcheck.sh
#!/bin/bash
export PATH=/usr/bin:/bin:/usr/local/bin:$PATH
# ...
# [원인 4] cron 실행 오류 로그 확인
grep CRON /var/log/syslog | tail -20 # Ubuntu
journalctl -u crond | tail -20 # CentOS systemd
# [원인 5] cron 출력을 파일로 리다이렉션
# crontab 항목에 출력 리다이렉션 추가
# */5 * * * * /opt/scripts/netcheck.sh >> /var/log/netcheck-cron.log 2>&1
cron 디버깅 팁
# cron 환경에서 수동 테스트
env -i HOME=/root SHELL=/bin/bash /bin/bash /opt/scripts/netcheck.sh
# 이렇게 실행해서 오류가 나면 cron에서도 동일하게 오류 발생
교훈: cron 등록 후 반드시 실제로 실행되는지 로그로 확인하세요. 실행 권한, PATH, cron 서비스 상태를 순서대로 점검합니다.
심화 — 점검이 찍는 OK를 의심하라
심화: 포트가 열렸다 ≠ 서비스가 정상 — 체크가 만드는 착시
점검 스크립트의 진짜 위험은 '멈추는 것'보다 '거짓으로 OK를 찍는 것'입니다. 멈추면 눈에 띄지만, 거짓 OK는 장애를 조용히 덮어 정작 필요한 순간에 알림이 오지 않게 합니다. nc -z 성공이 실제로 무엇을 증명하는지 한 겹 더 파고들어야 합니다.
- L4 성공은 L7 정상을 보장하지 않는다:
nc -z가 OK여도 그 위 앱이 커넥션 풀 고갈·데드락으로 요청을 못 받을 수 있습니다. 진짜 헬스체크는 실제 프로토콜 요청(HTTP GET /health, DB SELECT 1)까지 보내 응답 내용을 봐야 합니다. - UDP는 핸드셰이크가 없어 거짓 OK가 난다:
nc -zu로 DNS(53)·NTP(123)·syslog(514) 같은 UDP 포트를 점검하면, 서버가 죽어 있어도 대개 성공으로 뜹니다 — UDP는 연결 확립 절차가 없어 ICMP port-unreachable 같은 명시적 거부가 없으면 nc가 성공으로 판정하기 때문입니다. - 규모가 커지면 점검이 부작용을 만든다: 수백 대를 짧은 주기로 두드리면, 대상의 연결 레이트 제한·SYN 방어·fail2ban이 점검을 공격으로 오인해 차단하거나, 점검 호스트의 로컬 임시 포트가 TIME_WAIT로 쌓여 점검 자신이 실패합니다.
- 닫힘의 종류를 구분하라: Connection refused(RST)는 서비스만 없다는 신호로 즉시 실패하고, 무응답(DROP)은 방화벽·호스트 다운으로 타임아웃까지 대기합니다. 둘을 같은 FAIL로 뭉치면 원인 판단이 흐려집니다.
그래서 성숙한 점검은 '연결이 되나'를 넘어 '정확한 응답이 오나'까지, 프로토콜에 맞는 실제 질의로 검증합니다.
상황
TCP 포트 점검 스크립트를 확장해 DNS(53/udp)·NTP(123/udp)도 nc -zu로 점검하도록 했습니다. 그런데 실제로 named를 내려도 스크립트는 계속 OK를 찍어, 장애를 며칠 동안 놓쳤습니다.
원인
UDP는 3-way handshake가 없습니다. nc -zu는 UDP 패킷을 하나 보내고, ICMP port-unreachable 같은 명시적 거부가 돌아오지 않는 한 성공(종료 코드 0)으로 판정합니다. 서버가 죽어도 방화벽이 조용히 DROP하거나 응답이 없으면 nc는 이를 '열림'으로 착각합니다. TCP식 열림 판정 논리를 UDP에 그대로 옮긴 것이 원인입니다.
진단
# 서버를 내린 상태에서도 0을 반환하는지 확인 (거짓 OK 재현)
nc -zu 192.168.1.53 53; echo "exit=$?"
# exit=0 ← 서비스가 죽었는데도 성공
# 실제 프로토콜 질의로 대조하면 진짜 상태가 드러난다
dig +short +time=2 +tries=1 @192.168.1.53 health.example.com
# (응답 없음 → 실제로는 죽어 있음)
해결
UDP 서비스는 실제 프로토콜 질의로 점검합니다 — DNS는 dig +time=2 +tries=1 @대상의 응답 유무, NTP는 ntpdate -q 대상, 그 밖의 UDP는 애플리케이션 레벨 프로브로 응답 내용까지 검증합니다. TCP 서비스도 가능하면 L4(nc) 대신 HTTP GET /health 같은 L7 요청으로 승격해 '진짜 살아 있음'을 확인합니다.
4. 실무 현장 관점
실무에서 이 스크립트가 필요한 순간
-
정기 배포/패치 후 확인: 배포 후 모든 서비스 간 연결이 정상인지 자동으로 확인하는 스모크 테스트로 활용
-
24시간 모니터링: 모니터링 도구(Zabbix, Prometheus 등)가 없는 소규모 환경에서 간단한 가용성 모니터링 역할
-
장애 보고서 근거: 장애 발생 시 정확한 시각과 영향 받은 서버를 로그 파일에서 바로 확인 가능
완성된 프로덕션 수준 스크립트
#!/bin/bash
# /opt/scripts/netcheck-production.sh
# 프로덕션 수준 네트워크 점검 스크립트
set -euo pipefail
# === 설정 ===
LOG_FILE="/var/log/netcheck.log"
LOG_MAX_DAYS=30
TIMEOUT=3
HOSTNAME=$(hostname -f)
# === 점검 대상 (환경에 맞게 수정) ===
TARGETS=(
"db-primary.internal:3306:MySQL-Primary"
"db-replica.internal:3306:MySQL-Replica"
"cache.internal:6379:Redis"
"app1.internal:8080:App-Server-1"
"app2.internal:8080:App-Server-2"
"lb.internal:80:Load-Balancer"
)
# === 함수 정의 ===
log() {
local level=$1
shift
echo "[$(date '+%Y-%m-%d %H:%M:%S')] [$level] $*" >> "$LOG_FILE"
}
check_port() {
local host=$1
local port=$2
nc -zv -w "$TIMEOUT" "$host" "$port" 2>/dev/null
return $?
}
cleanup_old_logs() {
find "$(dirname "$LOG_FILE")" -name "netcheck*.log" -mtime +"$LOG_MAX_DAYS" -delete 2>/dev/null
}
# === 메인 로직 ===
mkdir -p "$(dirname "$LOG_FILE")"
cleanup_old_logs
FAIL_COUNT=0
FAIL_LIST=""
log "INFO" "=== 점검 시작 (호스트: $HOSTNAME, 대상: ${#TARGETS[@]}개) ==="
for target in "${TARGETS[@]}"; do
HOST=$(echo "$target" | cut -d: -f1)
PORT=$(echo "$target" | cut -d: -f2)
DESC=$(echo "$target" | cut -d: -f3)
if check_port "$HOST" "$PORT"; then
log "OK " "${HOST}:${PORT} [${DESC}]"
else
log "FAIL" "${HOST}:${PORT} [${DESC}]"
FAIL_COUNT=$((FAIL_COUNT + 1))
FAIL_LIST="${FAIL_LIST} ${DESC}(${HOST}:${PORT})"
fi
done
if [ "$FAIL_COUNT" -gt 0 ]; then
log "WARN" "점검 완료 — 실패 ${FAIL_COUNT}건:${FAIL_LIST}"
else
log "INFO" "점검 완료 — 전체 정상"
fi
exit "$FAIL_COUNT"
Nagios/Zabbix 등과의 연동
# Nagios 플러그인 형태로 변환
# 종료 코드 규칙: 0=OK, 1=WARNING, 2=CRITICAL, 3=UNKNOWN
if [ "$FAIL_COUNT" -eq 0 ]; then
echo "OK: 전체 ${#TARGETS[@]}개 서버 정상"
exit 0
elif [ "$FAIL_COUNT" -le 1 ]; then
echo "WARNING: ${FAIL_COUNT}개 서버 응답 없음"
exit 1
else
echo "CRITICAL: ${FAIL_COUNT}개 서버 응답 없음"
exit 2
fi
5. 핵심 명령어 요약
| 목적 | 명령어/표현 |
|---|---|
| 타임아웃 포함 포트 점검 | nc -zv -w 3 192.168.1.200 3306 |
| 종료 코드 확인 | echo $? (0=성공, 비0=실패) |
| 타임스탬프 생성 | $(date '+%Y-%m-%d %H:%M:%S') |
| 로그 파일에 기록 | echo "메시지" >> /var/log/netcheck.log |
| bash 배열 선언 | TARGETS=("host1:port1:desc1" "host2:port2:desc2") |
| 배열 순회 | for item in "${TARGETS[@]}"; do ...; done |
| 문자열 파싱 | echo "$item" | cut -d: -f1 |
| cron 5분 주기 | */5 * * * * /opt/scripts/netcheck.sh |
| cron 등록 확인 | crontab -l |
정리
nc -zv -w 3의-w 3은 타임아웃 3초 설정 — 스크립트 무한 대기 방지 필수$?로 nc의 성공/실패 판단 (0=성공, 1=실패)- 배열(
TARGETS=())과for루프로 여러 서버를 간결하게 점검 $(date '+%Y-%m-%d %H:%M:%S')로 타임스탬프를 로그에 함께 기록- crontab
*/5 * * * *으로 5분마다 자동 실행 - cron 실행 전 실행 권한, PATH, 로그 리다이렉션 확인 필수
관련 모듈로 더 깊이:
- telnet과 nc(netcat) 명령어로 L4 포트 통신 상태 점검 — 스크립트가 쓰는 nc 포트 점검을 수동으로 해보며 원리 익히기
- 웹 서버에서 DB 접속 실패 시 원인 격리 프로세스 — 스크립트가 잡아낸 이상을 단계별로 고립해 원인을 좁히는 법
- 서비스 안정성을 지키는 메트릭, 로그, 알림 구축 전략 — 단발 스크립트를 넘어 상시 모니터링·알림으로 확장하기
다음 모듈에서는 웹 서버와 DB 사이의 통신 장애를 단계별로 고립·진단하는 troubleshooting-isolation 방법론을 다룹니다.