백엔드 두 대 중 한 대가 느려졌는데 사용자 요청은 계속 그 서버로 흘러갑니다. 로드밸런서는 살아 있지만 헬스 체크가 부실해 죽은 서버를 빼지 못했습니다.
로드밸런싱은 트래픽을 나누는 것보다 장애 서버를 빨리 제외하는 것이 더 중요합니다.
L4/L7 로드밸런싱과 헬스 체크
트래픽이 서버 한 대에 집중되면 어떻게 될까요? 해당 서버가 과부하로 응답을 못 하거나, 장애가 발생하면 전체 서비스가 멈춥니다. **로드밸런서(Load Balancer)**는 여러 서버에 트래픽을 분산시켜 부하를 나누고, 한 서버가 죽어도 다른 서버가 요청을 이어받도록 합니다.
이 챕터에서는 오픈소스 로드밸런서 HAProxy를 직접 설치하고 설정하며, L4/L7 차이와 다양한 분산 알고리즘, 헬스 체크 동작 원리를 손으로 익힙니다.
- 1L4(전송 계층)와 L7(애플리케이션 계층) 로드밸런서의 차이를 설명할 수 있다
- 2Round Robin, Least Connection, IP Hash 분산 알고리즘을 구분해 적용할 수 있다
- 3HAProxy 설정 파일 구조(global/defaults/frontend/backend)를 작성할 수 있다
- 4헬스 체크 파라미터(inter/rise/fall)와 Failover 동작을 설정할 수 있다
- 5HAProxy 통계 페이지로 실시간 서버 상태를 모니터링할 수 있다
- 6쿠키 기반 세션 고정과 IP Hash NAT 집중 문제를 해결할 수 있다
sudo apt-get install -y haproxy # Ubuntu/Debian
sudo yum install -y haproxy # CentOS/RHELmkdir -p /tmp/backend1 /tmp/backend2 && echo 'Server 1' > /tmp/backend1/index.html && echo 'Server 2' > /tmp/backend2/index.htmlsudo haproxy -c -f /etc/haproxy/haproxy.cfgsudo cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak 으로 백업한 뒤 편집을 시작합니다
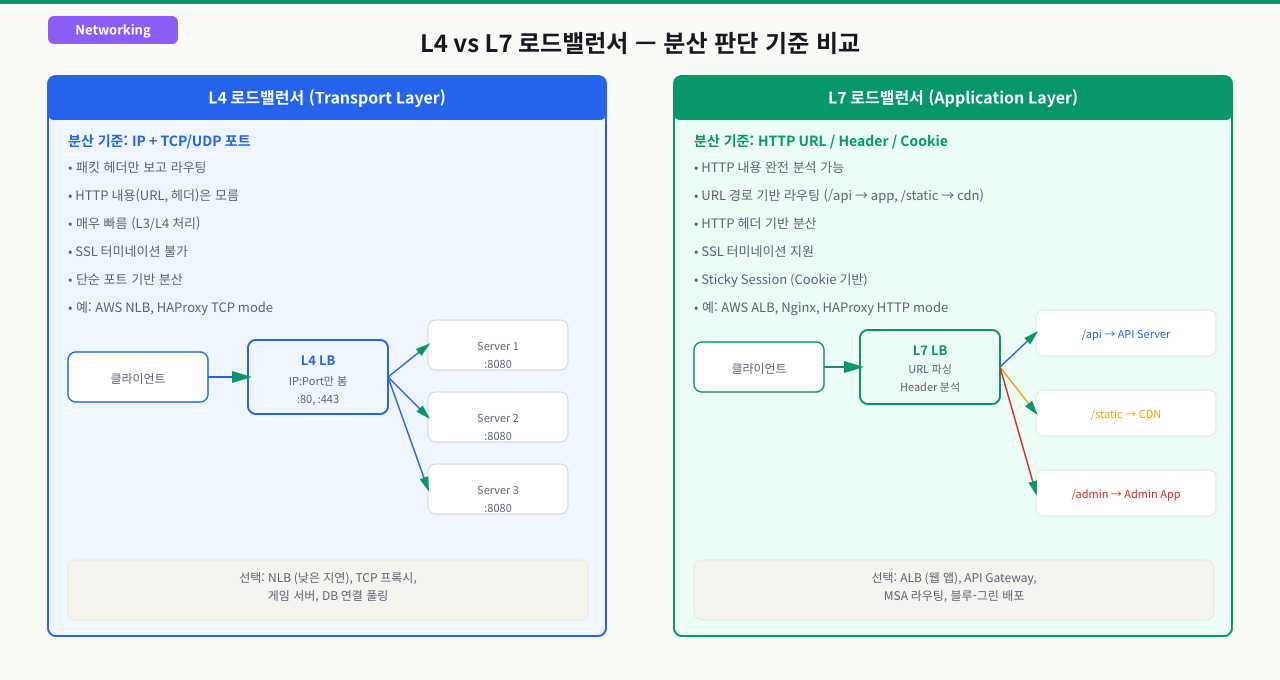
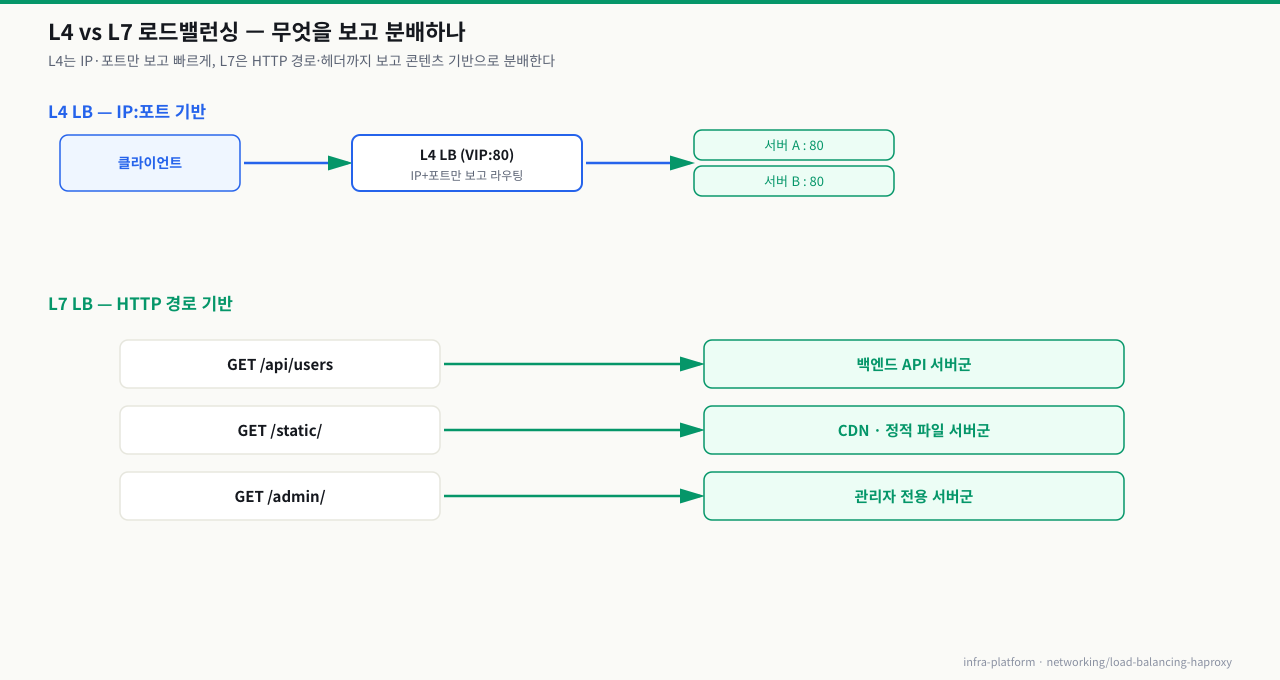
L4 vs L7 로드밸런서: 무엇을 보고 분산하는가
트래픽이 늘어서 서버를 두 대로 늘렸는데, 특정 API 경로(/api/upload)는 항상 한 서버로만 몰립니다. 로드밸런서가 단순히 번갈아 분산하는 게 아니라 URL 경로를 보고 라우팅하는 설정이 필요한데, L4와 L7의 차이를 모르면 왜 이런 설정이 필요한지, 어떤 로드밸런서를 선택해야 하는지 판단할 수 없습니다.
 확대
확대
로드밸런서는 OSI 모델의 어느 계층 정보를 활용하느냐에 따라 L4와 L7로 나뉩니다.
L4 로드밸런서 (전송 계층)
L4 로드밸런서는 IP 주소와 포트 번호만 보고 패킷을 분산합니다. HTTP 요청의 내용(URL, 헤더, 바디)은 전혀 열어보지 않습니다.
 확대
확대
L4의 특징
- 처리 속도가 빠릅니다 (패킷을 거의 그대로 전달)
- TCP/UDP 모두 처리 가능합니다
- HTTP 외 모든 TCP 기반 프로토콜에 적용 가능합니다 (DB, SMTP, 게임 서버 등)
- URL 기반 라우팅은 불가능합니다
L7 로드밸런서 (애플리케이션 계층)
L7 로드밸런서는 HTTP 요청 전체를 파싱합니다. URL 경로, 헤더, 쿠키, HTTP 메서드 등을 기반으로 라우팅 결정을 내릴 수 있습니다.
| HTTP 요청 | 라우팅 대상 |
|---|---|
GET /api/users | 백엔드 API 서버군 |
GET /static/ | CDN 또는 정적 파일 서버군 |
GET /admin/ | 관리자 전용 서버군 |
L7의 특징
- 경로(Path) 기반 라우팅 가능합니다
- HTTP 헤더 조작 가능합니다 (
X-Forwarded-For추가 등) - SSL/TLS 종단(Termination) 처리 가능합니다
- 콘텐츠 기반 캐싱 적용 가능합니다
- L4보다 처리 비용이 약간 높습니다 (패킷 내용 파싱 필요)
실무에서의 선택 기준
서비스 유형에 따라 L4와 L7 중 무엇을 선택할지 판단 기준이 달라집니다. HTTP 기반 웹 서비스는 URL 라우팅이 가능한 L7이 유리하고, DB나 게임 서버처럼 TCP를 직접 쓰는 경우는 L4가 적합합니다.
| 상황 | 권장 방식 |
|---|---|
| HTTP/HTTPS 웹 서비스 | L7 (URL 기반 라우팅 가능) |
| DB 클러스터(MySQL, PostgreSQL) | L4 (TCP 레벨 분산) |
| 게임 서버 (UDP) | L4 |
| 마이크로서비스 API 게이트웨이 | L7 |
| 단순 고속 트래픽 분산 | L4 |
HAProxy는 L4와 L7 모두 지원하는 대표적인 오픈소스 로드밸런서입니다. mode tcp로 설정하면 L4, mode http로 설정하면 L7로 동작합니다.
요청 하나가 백엔드에 닿기까지 — L4 vs L7 로드밸런싱
클라이언트 요청이 백엔드에 배정되는 5단계 — 헬스체크·알고리즘·계층
로드밸런서를 "트래픽을 나눠 주는 상자"로만 알면, 정작 장애가 났을 때 어디를 봐야 할지 막막합니다. 요청 하나가 VIP에 도착해 특정 백엔드에 배정되기까지는 살아있는 후보 추리기 → 알고리즘 선택 → 계층별 전달이 순서대로 일어납니다. 이 5단계를 알면 "왜 한 서버만 쏠리지", "죽은 서버로 왜 아직 가지", "백엔드 로그에 왜 내 IP가 안 남지"가 각각 어느 단계 문제인지 바로 짚힙니다.
[클라이언트] → VIP(가상 IP):443
│
① LB 가 연결 수신 (frontend 의 bind *:443)
│
② 헬스체크 UP 인 백엔드만 후보로 추림
│ inter/rise/fall 판정으로 죽은 서버는 이미 제외됨
│
③ 분산 알고리즘으로 백엔드 하나 선택
│ roundrobin / leastconn / source(IP Hash)
│ 스티키 세션이면 쿠키·IP 로 늘 같은 서버
│
④ 계층에 따라 전달 방식이 갈림
│ ├─ L4(mode tcp): 목적지 IP·포트만 바꿔 그대로 전달 (빠름)
│ └─ L7(mode http): HTTP 파싱 → 경로/헤더로 라우팅,
│ SSL 종료·XFF 헤더 추가 후 백엔드로 새 연결
│
⑤ 백엔드 응답 → LB 경유 → 클라이언트
▼
[클라이언트] ← 어느 백엔드가 처리했는지 모른 채 응답 수신
각 단계에서 무슨 일이 일어나고, 어긋나면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 어긋나면 |
|---|---|---|
| ① 연결 수신 | frontend의 bind *:포트로 VIP에서 Listen | bind 줄이 없으면 포트 자체가 안 열림(netstat에 안 보임) |
| ② 후보 추림 | 헬스체크 UP인 백엔드만 대상. inter/rise/fall로 판정 | timeout이 과민하면 정상 서버를 DOWN 오탐 → 남은 서버 과부하 |
| ③ 백엔드 선택 | 알고리즘으로 하나 고름. 세션 고정이면 쿠키/IP로 같은 서버 | balance source인데 NAT 뒤 다수 사용자면 한 서버로 쏠림 |
| ④ 전달 방식 | L4=IP·포트만 스왑(고속·프로토콜 무관), L7=HTTP 파싱해 경로·헤더 라우팅·SSL 종료 | L4로 /api 경로 분기 시도 불가 — URL 라우팅은 L7만 |
| ⑤ 응답 반환 | 백엔드 응답이 LB 거쳐 클라이언트로. L7은 프록시라 새 연결 | L7 뒤 백엔드는 클라 IP 대신 LB IP를 봄 → X-Forwarded-For로 복원 |
즉 **로드밸런싱의 진짜 값은 "고르게 나누기"보다 ②의 헬스체크로 죽은 백엔드를 빨리 빼는 것과, ④의 계층 선택(L4 속도 vs L7 라우팅)**에 있습니다. 문제가 생기면 stats 페이지에서 백엔드 UP/DOWN을 먼저 보고(②), 쏠림이면 알고리즘을(③), 라우팅이 안 먹으면 L4/L7 모드를(④) 확인하는 순서로 좁힙니다.
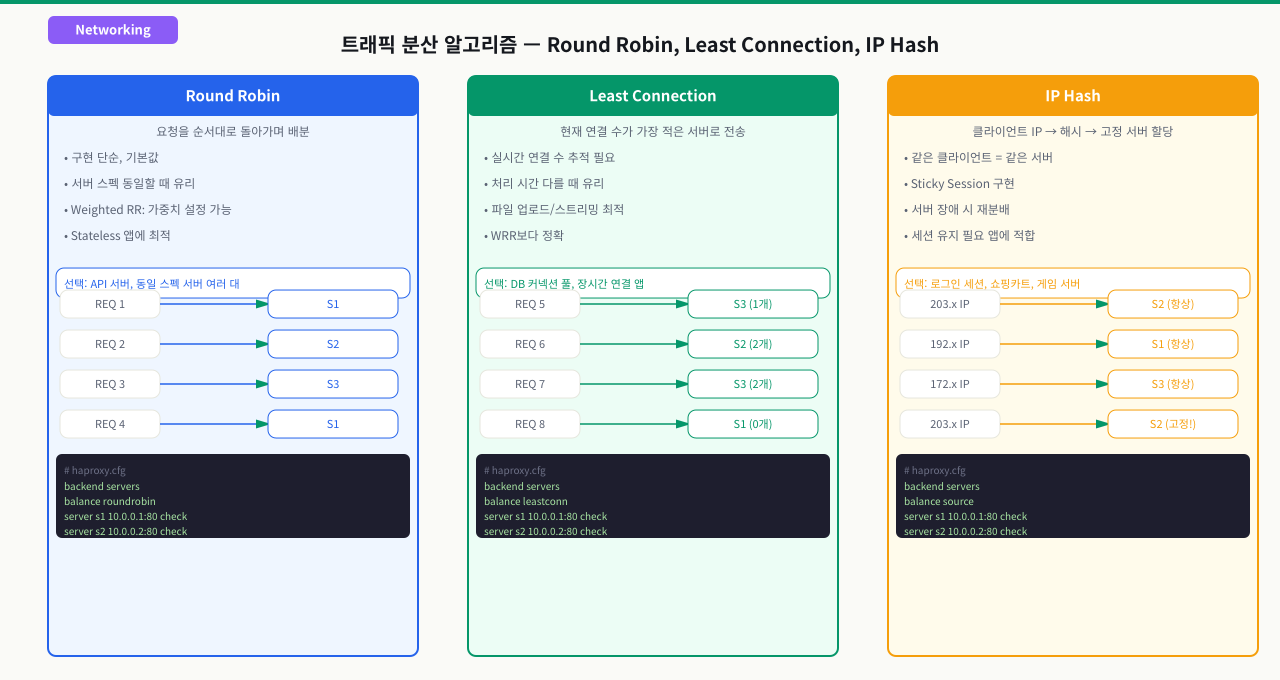
트래픽 분산 알고리즘: Round Robin, Least Connection, IP Hash
로드밸런서를 적용했는데 어떤 서버는 항상 과부하고 어떤 서버는 놀고 있습니다. 기본 Round Robin으로 설정했는데 왜 균등하게 분산이 안 되는지 이해가 안 됩니다. 분산 알고리즘마다 특성이 다르고, 서비스 특성에 맞는 알고리즘을 선택하지 않으면 로드밸런서를 달아도 부하가 쏠리는 문제가 생깁니다.
 확대
확대
로드밸런서가 여러 서버 중 어느 서버로 요청을 보낼지 결정하는 규칙이 분산 알고리즘입니다.
Round Robin (라운드 로빈)
가장 단순한 방식입니다. 서버 목록을 순서대로 돌아가며 요청을 하나씩 배분합니다.
요청 1 → 서버A
요청 2 → 서버B
요청 3 → 서버A
요청 4 → 서버B
...
적합한 상황: 모든 요청의 처리 시간이 비슷하고 서버 스펙이 동일할 때
weight 옵션: 서버 스펙이 다르면 weight 값으로 가중치를 줄 수 있습니다.
server app1 192.168.1.10:8080 weight 2
server app2 192.168.1.11:8080 weight 1
# 요청 분배 비율: app1 66%, app2 33%
Least Connection (최소 연결)
현재 활성 연결이 가장 적은 서버로 새 요청을 보냅니다.
서버A: 현재 연결 100개
서버B: 현재 연결 30개
→ 새 요청은 서버B로 전달
적합한 상황: 요청마다 처리 시간이 크게 다를 때 (짧은 API 요청과 긴 파일 업로드가 혼재)
HAProxy 설정: balance leastconn
IP Hash (소스 해시)
클라이언트의 IP 주소를 해싱해서 항상 같은 서버로 연결합니다. 세션 고정(Session Stickiness)이 필요할 때 사용합니다.
클라이언트 1.2.3.4 → 항상 서버A
클라이언트 5.6.7.8 → 항상 서버B
적합한 상황: 세션을 서버 메모리에 저장하는 레거시 웹 애플리케이션
주의사항: 한 NAT 뒤에 있는 수천 명의 사용자가 같은 공인 IP를 가질 경우, 모두 같은 서버로 집중됩니다.
HAProxy 설정: balance source
알고리즘 비교 요약
| 알고리즘 | HAProxy 설정 | 세션 유지 | 적합 상황 |
|---|---|---|---|
| Round Robin | balance roundrobin | 없음 | 동질적 요청 |
| Least Connection | balance leastconn | 없음 | 처리시간 편차 큼 |
| IP Hash | balance source | IP 기반 | 세션 필요 |
# 실습 디렉토리 준비
mkdir -p /tmp/networking/part5/exam_27 && cd /tmp/networking/part5/exam_27
mkdir -p /tmp/networking/part5/haproxy/{config,logs}
cat > /tmp/networking/part5/haproxy/config/haproxy.cfg << 'EOF'
global
daemon
maxconn 256
log stdout format raw local0
defaults
mode http
timeout connect 5s
timeout client 30s
timeout server 30s
log global
frontend http_front
bind *:80
default_backend web_servers
backend web_servers
balance roundrobin
option httpchk GET /health
server web1 127.0.0.1:8081 check
server web2 127.0.0.1:8082 check
server web3 127.0.0.1:8083 check
listen stats
bind *:8404
stats enable
stats uri /stats
stats refresh 10s
EOF
# 테스트용 백엔드 서버 스크립트
cat > /tmp/networking/part5/haproxy/backend.sh << 'EOF'
#!/bin/bash
PORT=${1:-8081}
ID=${2:-"server-1"}
while true; do
echo -e "HTTP/1.1 200 OK\r\nContent-Type: application/json\r\n\r\n{\"server\":\"$ID\",\"port\":$PORT}" | nc -l -p $PORT -q 1
done
EOF
chmod +x /tmp/networking/part5/haproxy/backend.sh
- 백엔드 UP/DOWN 먼저 확인—HAProxy stats 페이지에서 Status 열이 UP이면 정상, DOWN이면 해당 서버로 트래픽이 가지 않는 상태 — 즉시 원인 서버 점검
- 현재 세션 수 판단—Cur 세션이 Max 세션(maxconn)의 80% 이상이면 포화 위험 — 백엔드 서버 추가 또는 maxconn 값 상향 검토
- 에러율 조합 해석—Hrsp_5xx 값이 증가하는데 Status는 UP이면 서버가 살아는 있지만 애플리케이션 오류 — 해당 서버 로그를 직접 확인
HAProxy가 분산할 가상의 백엔드 서버 2개를 Python의 내장 HTTP 서버로 빠르게 만들겠습니다.
전제 조건: 이 실습은 단일 서버에서 포트를 다르게 사용해 2대를 시뮬레이션합니다.
1단계: 백엔드 서버 디렉토리 준비
# 각 서버의 루트 디렉토리 생성
mkdir -p /tmp/backend1 /tmp/backend2
# 서버별로 다른 응답 페이지 생성 (어느 서버가 응답했는지 구분용)
echo "Hello from Backend Server 1 (port 8001)" > /tmp/backend1/index.html
echo "Hello from Backend Server 2 (port 8002)" > /tmp/backend2/index.html
2단계: 백엔드 서버 실행
두 개의 터미널 창을 열고 각각 실행합니다.
# 터미널 1: 서버1 실행
cd /tmp/backend1
python3 -m http.server 8001
# 터미널 2: 서버2 실행
cd /tmp/backend2
python3 -m http.server 8002
3단계: 백엔드 서버 직접 접속 확인
# 서버1 응답 확인
curl http://localhost:8001
# 출력: Hello from Backend Server 1 (port 8001)
# 서버2 응답 확인
curl http://localhost:8002
# 출력: Hello from Backend Server 2 (port 8002)
두 서버가 정상 응답한다면 실습 준비 완료입니다.
1단계: HAProxy 설치
# Ubuntu/Debian
sudo apt-get update
sudo apt-get install -y haproxy
# CentOS/RHEL
sudo yum install -y haproxy
# 버전 확인
haproxy -v
# HA-Proxy version 2.x.x
2단계: 설정 파일 백업 및 편집
# 기존 설정 백업
sudo cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
# 설정 파일 편집
sudo nano /etc/haproxy/haproxy.cfg
3단계: haproxy.cfg 기본 구조 이해
HAProxy 설정은 4개의 주요 섹션으로 구성됩니다.
global → HAProxy 프로세스 전체 설정 (로그, 최대 연결 수, 실행 사용자 등)
defaults → frontend/backend에 공통으로 적용될 기본값
frontend → 클라이언트가 접속하는 진입점 (포트, 프로토콜, 라우팅 규칙)
backend → 실제 서버 목록과 분산 알고리즘
4단계: 완전한 설정 파일 작성
/etc/haproxy/haproxy.cfg를 다음 내용으로 교체합니다.
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin expose-fd listeners
stats timeout 30s
user haproxy
group haproxy
daemon
defaults
log global
mode http
option httplog
option dontlognull
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
errorfile 400 /etc/haproxy/errors/400.http
errorfile 503 /etc/haproxy/errors/503.http
frontend web_frontend
bind *:80
mode http
default_backend web_servers
# L7 규칙 예시: /api/ 경로는 별도 백엔드로
# acl is_api path_beg /api/
# use_backend api_servers if is_api
backend web_servers
mode http
balance roundrobin
option httpchk GET /
http-check expect status 200
server backend1 127.0.0.1:8001 check inter 3000 rise 2 fall 3
server backend2 127.0.0.1:8002 check inter 3000 rise 2 fall 3
5단계: 설정 파일 문법 검증
sudo haproxy -c -f /etc/haproxy/haproxy.cfg
# 출력: Configuration file is valid
-c 옵션은 실제로 실행하지 않고 설정 파일만 검증합니다. 반드시 서비스 재시작 전에 실행하세요.
6단계: HAProxy 시작 및 상태 확인
이 명령은 실행 중인 서비스 상태를 바꿔 순간적인 중단이나 설정 반영 실패를 만들 수 있습니다. 운영 트래픽 영향과 재시작 후 확인 명령을 먼저 준비하세요.
sudo systemctl enable haproxy
sudo systemctl start haproxy
sudo systemctl status haproxy
헬스 체크는 HAProxy가 주기적으로 백엔드 서버에 요청을 보내 서버가 살아있는지 확인하는 기능입니다.
헬스 체크 파라미터 상세 설명
server backend1 127.0.0.1:8001 check inter 3000 rise 2 fall 3
↑ ↑ ↑
헬스체크 UP 판정 DOWN 판정
간격(ms) 연속 성공 연속 실패
| 파라미터 | 설명 | 기본값 | 권장값 |
|---|---|---|---|
check | 헬스 체크 활성화 | 비활성 | 항상 설정 |
inter | 체크 간격 (ms) | 2000 | 3000~5000 |
rise | UP 전환에 필요한 연속 성공 횟수 | 2 | 2~3 |
fall | DOWN 전환에 필요한 연속 실패 횟수 | 3 | 3~5 |
1단계: 분산 동작 확인
# 10번 요청을 보내서 Round Robin 확인
for i in $(seq 1 10); do
curl -s http://localhost:80
done
예상 출력:
Hello from Backend Server 1 (port 8001)
Hello from Backend Server 2 (port 8002)
Hello from Backend Server 1 (port 8001)
Hello from Backend Server 2 (port 8002)
...
2단계: 서버 다운 시 Failover 확인
# 터미널에서 서버1(포트 8001)을 강제 종료
# (python3 -m http.server 8001 프로세스를 Ctrl+C)
# HAProxy가 fall 3 기준으로 3번 실패 후 서버1을 DOWN으로 전환
# 잠시 후 다시 요청
for i in $(seq 1 5); do
curl -s http://localhost:80
sleep 1
done
예상 출력: 서버1이 DOWN되면 모든 요청이 서버2로만 전달됩니다.
3단계: HAProxy 통계 페이지 활성화
통계 페이지를 설정하면 웹 브라우저에서 실시간 서버 상태를 볼 수 있습니다.
frontend 섹션 뒤에 다음 설정을 추가합니다.
listen stats
bind *:8404
stats enable
stats uri /stats
stats refresh 5s
stats auth admin:password123
HAProxy 재시작 후 http://서버IP:8404/stats에 접속하면 각 서버의 현재 상태(UP/DOWN), 연결 수, 트래픽량을 실시간으로 확인할 수 있습니다.
4단계: 로그에서 분산 기록 확인
# HAProxy 접근 로그 실시간 확인
sudo tail -f /var/log/haproxy.log
각 요청이 어느 서버로 라우팅되었는지 로그에서 확인할 수 있습니다.
상황
배포 직후 갑자기 HAProxy 통계 페이지에서 백엔드 서버 1대가 빨간색(DOWN)으로 표시됩니다. 해당 서버에 직접 접속하면 멀쩡히 응답합니다.
오류 증상
HAProxy 로그에서 다음과 같은 패턴이 반복됩니다.
[WARNING] Health check for server web_servers/backend1 failed, reason: Layer7 timeout, ...
Server web_servers/backend1 is DOWN, reason: Layer7 timeout
curl http://백엔드서버:8001/ 은 응답을 잘 하는데, HAProxy만 그 서버를 죽었다고 판단합니다.
원인 분석
haproxy.cfg를 확인해 보면:
defaults
timeout connect 500ms ← 너무 짧음!
timeout server 1000ms ← 너무 짧음!
헬스 체크 설정도 확인합니다.
server backend1 127.0.0.1:8001 check inter 1000 rise 2 fall 2
배포 과정에서 서버가 로딩 중이거나, 잠깐의 GC Pause, DB 쿼리 지연 등으로 응답이 1초를 넘는 순간 헬스 체크가 실패합니다. fall 2로 설정되어 있어 2번만 실패하면 바로 DOWN 전환됩니다.
해결 방법
1. timeout 값 현실적으로 조정
defaults
timeout connect 5000ms # 연결 수립 5초
timeout client 60000ms # 클라이언트 응답 대기 1분
timeout server 60000ms # 서버 응답 대기 1분
2. 헬스 체크 파라미터 완화
server backend1 127.0.0.1:8001 check inter 3000 rise 3 fall 5
# ↑ ↑ ↑
# 3초마다 3번 성공 5번 실패
# 체크 시 UP 시 DOWN
3. 헬스 체크에만 별도 timeout 적용
server backend1 127.0.0.1:8001 check inter 3000 fall 5 \
timeout check 5000ms
4. 설정 적용 후 확인
이 명령은 실행 중인 서비스 상태를 바꿔 순간적인 중단이나 설정 반영 실패를 만들 수 있습니다. 운영 트래픽 영향과 재시작 후 확인 명령을 먼저 준비하세요.
sudo haproxy -c -f /etc/haproxy/haproxy.cfg && sudo systemctl reload haproxy
핵심 교훈
헬스 체크의 timeout과 fall 값은 실제 서비스 응답 시간의 최악 케이스를 고려해서 설정해야 합니다. 너무 민감하게 설정하면 일시적 지연을 장애로 오인해 정상 서버를 풀에서 제거하고, 남은 서버에 더 큰 부하를 줘서 연쇄 장애(Cascading Failure)를 유발할 수 있습니다.
상황
세션 유지를 위해 balance source (IP Hash)를 사용 중입니다. 특정 시간대에 서버A의 부하가 90%를 넘고 서버B는 10% 미만인 불균형이 발생합니다.
원인
기업 사무실 내 5,000명의 사용자
→ 모두 같은 NAT 공인 IP: 203.0.113.100 사용
→ IP Hash 결과: 모두 서버A로 매핑
→ 서버A 과부하, 서버B 유휴 상태
IP Hash는 클라이언트의 소스 IP를 기반으로 서버를 결정하므로, 여러 사용자가 동일 공인 IP를 공유하는 환경(기업 NAT, 학교 망, 모바일 통신사)에서 특정 서버로 트래픽이 집중됩니다.
해결 방법
방법 1: 쿠키 기반 세션 고정으로 전환 (권장)
backend web_servers
balance roundrobin
cookie SERVERID insert indirect nocache
server backend1 127.0.0.1:8001 check cookie srv1
server backend2 127.0.0.1:8002 check cookie srv2
HAProxy가 응답에 Set-Cookie: SERVERID=srv1 쿠키를 심어 재방문 시 같은 서버로 보내줍니다. IP와 무관하게 개별 세션을 유지할 수 있습니다.
방법 2: 애플리케이션 세션을 Redis로 외부화
가장 근본적인 해결책은 세션을 서버 메모리가 아닌 Redis 같은 공유 스토리지에 저장해, 어느 서버로 요청이 가도 세션을 읽을 수 있게 하는 것입니다. 이렇게 하면 Round Robin을 자유롭게 사용할 수 있습니다.
핵심 교훈
balance source는 세션 고정의 마지막 수단입니다. 쿠키 기반 고정이나 외부 세션 스토리지를 우선 검토하세요.
심화 — 프록시가 숨기는 진짜 IP와 바닥나는 소스 포트
심화: L7 프록시 뒤에서 사라지는 클라이언트 IP와 X-Forwarded-For
백엔드의 접속 로그·IP 레이트리밋·IP 차단이 모두 "같은 IP 한 곳(로드밸런서)"에서 온 것으로 보이면, IP 기반 보안이 통째로 무력화됩니다. 왜 진짜 IP가 사라지는지 알아야 그것을 되살릴 수 있습니다.
- 프록시는 연결을 둘로 쪼갠다: L7 로드밸런서는 클라이언트의 TCP 연결을 자기가 종단(terminate)하고, 백엔드로는 자기 IP로 새 연결을 다시 맺습니다. 그래서 백엔드가 보는 소스 IP는 진짜 사용자가 아니라 항상 LB의 IP입니다.
- L7의 해법 — X-Forwarded-For(XFF): HTTP를 이해하는 L7 LB는 원래 클라이언트 IP를
X-Forwarded-For헤더에 실어 보내고, 백엔드가 그 값을 신뢰해 진짜 IP로 로깅·제한합니다. HAProxy에서는option forwardfor로 이 헤더를 붙입니다. - L4의 해법 — PROXY 프로토콜: L4(TCP 모드)는 HTTP 헤더를 못 다루므로 XFF를 쓸 수 없습니다. 대신 PROXY 프로토콜로 원래 출발지
IP:포트를 연결의 맨 앞머리에 실어 보내고, 백엔드가 이를 파싱해 진짜 IP를 복원합니다. - 신뢰 경계 함정:
X-Forwarded-For는 클라이언트가 위조할 수 있습니다. 맨 앞 LB가 붙인 값만 신뢰하도록 처리하지 않으면, 공격자가 헤더를 조작해 IP 레이트리밋·차단을 우회할 수 있습니다.
상황: 초당 연결 수가 급증한 순간부터 백엔드 연결 실패와 5xx가 늘고, HAProxy 로그에 Cannot assign requested address가 반복됩니다. 정작 CPU·메모리·대역폭은 여유가 있습니다.
원인: 이 에러는 EADDRNOTAVAIL — 새 연결에 붙일 소스 포트가 없다는 뜻입니다. LB는 고정된 백엔드 IP:포트로 요청마다 새 연결을 맺는데, 소스 포트는 약 2.8만 개(ip_local_port_range)뿐이고 끝난 연결도 한동안 TIME_WAIT로 포트를 붙잡습니다. 초당 연결 생성률이 높으면 CPU가 남아도 포트가 먼저 바닥납니다.
진단: ss -tan state time-wait | wc -l로 TIME_WAIT 수를, sysctl net.ipv4.ip_local_port_range로 포트 범위를, conntrack을 쓴다면 nf_conntrack_count/nf_conntrack_max를 확인합니다. 실패가 시작된 시각과 포트 소진 시점이 겹치면 확정입니다.
해결: HAProxy의 http-reuse로 백엔드 연결을 재사용해 연결당 포트 소모를 줄이는 것이 근본책입니다. 더해서 ip_local_port_range를 넓히고, 필요하면 net.ipv4.tcp_tw_reuse를 켜며, 백엔드 대상 IP:포트를 다중화해 포트 풀을 늘립니다.
실무 환경의 HAProxy
현업에서는 HAProxy를 직접 서버에 설치하는 경우보다 클라우드 관리형 로드밸런서(AWS ALB/NLB, GCP Cloud Load Balancing, Azure Load Balancer)를 사용하는 경우가 많습니다. 그러나 HAProxy는 온프레미스 환경, 비용 최적화가 필요한 환경, Kubernetes Ingress 컨트롤러(HAProxy Ingress) 등에서 여전히 널리 사용됩니다.
클라우드 환경에서의 대응 역할
| HAProxy 개념 | AWS 대응 | GCP 대응 |
|---|---|---|
| L7 frontend/backend | ALB (Application LB) | HTTP(S) Load Balancing |
| L4 mode tcp | NLB (Network LB) | TCP/UDP Load Balancing |
| Health check | Target Group 헬스체크 | Backend Service 헬스체크 |
| ACL/routing rule | Listener Rules | URL Map |
인프라 엔지니어가 알아야 할 실무 포인트
1. 헬스 체크 엔드포인트 설계
운영 서비스에서는 / 대신 /healthz 또는 /health 같은 전용 헬스 체크 엔드포인트를 만듭니다. 이 엔드포인트는 DB 연결, 외부 의존성 등을 빠르게 확인하고 200 또는 503을 반환합니다.
2. 드레이닝(Draining) 배포
서버를 점검하거나 배포할 때 갑자기 내리지 않고, 먼저 HAProxy 풀에서 제거(server backend1 ... weight 0 또는 maintenance 모드)해 기존 연결이 자연스럽게 끊기길 기다린 후 서버를 내립니다. 이를 **그레이스풀 셧다운(Graceful Shutdown)**이라 합니다.
3. 로그 분석과 SLA 모니터링
HAProxy 로그에는 각 요청의 처리 시간(Tt, Tw, Tc, Tr)이 기록됩니다. 이 값을 Prometheus로 수집하고 Grafana로 시각화해 P95, P99 응답 시간을 모니터링하는 것이 일반적입니다.
4. 면접에서 자주 나오는 질문
- "L4와 L7 로드밸런서의 차이를 설명해 주세요"
- "HAProxy의 헬스 체크가 실패했을 때 트래픽은 어떻게 처리되나요?"
- "세션 고정이 필요한 상황에서 어떤 방법을 선택하겠습니까?"
이 챕터에서 직접 설정하고 테스트한 경험이 있다면 이런 질문에 자신 있게 답할 수 있습니다.
정리
이 챕터에서 다룬 핵심 내용을 정리합니다.
| 개념 | 핵심 요약 |
|---|---|
| L4 로드밸런서 | IP + 포트만 보고 분산. 빠르지만 URL 기반 라우팅 불가 |
| L7 로드밸런서 | HTTP 전체를 파싱해 분산. URL, 헤더 기반 세밀한 라우팅 가능 |
| Round Robin | 순서대로 고르게 분산. 처리시간이 균일할 때 적합 |
| Least Connection | 활성 연결 최소 서버로 분산. 처리시간 편차 클 때 적합 |
| IP Hash | 동일 IP는 항상 같은 서버. NAT 환경에서 집중 주의 |
| 헬스 체크 | inter/rise/fall로 UP/DOWN 판정. timeout은 현실적으로 설정 |
명령어·단축키 빠른 참조
이 모듈에서 다룬 HAProxy 운영 명령과 핵심 설정 지시어를 실전 예와 함께 모았습니다.
| 명령어/설정 | 용도 | 자주 쓰는 예 |
|---|---|---|
haproxy -c -f <cfg> | 설정 문법 검증(재시작 전 필수) | sudo haproxy -c -f /etc/haproxy/haproxy.cfg → Configuration file is valid |
systemctl reload haproxy | 무중단 설정 반영 | haproxy -c … && sudo systemctl reload haproxy |
balance <알고리즘> | 분산 방식 지정(설정) | balance roundrobin / leastconn(편차 큼) / source(세션 고정) |
option httpchk + http-check expect | L7 헬스체크(설정) | option httpchk GET /health + http-check expect status 200 |
server … check inter rise fall | 서버 등록·헬스체크 민감도(설정) | server web1 127.0.0.1:8001 check inter 3000 rise 2 fall 3 |
cookie … insert | 쿠키 기반 세션 고정(설정) | cookie SERVERID insert indirect nocache + server … cookie srv1 |
option forwardfor / http-reuse | 원본 IP 전달 / 백엔드 연결 재사용(설정) | XFF로 진짜 IP 로깅, http-reuse로 소스 포트 고갈 완화 |
curl 반복 요청 | 분산·Failover 동작 확인 | for i in $(seq 1 10); do curl -s http://localhost:80; done |
tail -f /var/log/haproxy.log | 라우팅·헬스체크 로그 추적 | DOWN / Layer7 timeout 원인 확인 |
ss -tan state time-wait | wc -l | 소스 포트 고갈 진단 | sysctl net.ipv4.ip_local_port_range로 범위 확인 |
stats 페이지(stats uri /stats) | 실시간 서버 상태(UP/DOWN)·연결 수 | http://서버IP:8404/stats 접속 |
관련 모듈로 더 깊이:
- Keepalived와 가상 IP(VIP) 기반 고가용성(HA) 구성 — 로드밸런서 자체가 죽었을 때를 대비한 이중화(HA) 구성
- telnet과 nc(netcat) 명령어로 L4 포트 통신 상태 점검 — 헬스 체크가 실패할 때 백엔드 포트가 살아 있는지 확인하는 법
- 서비스 바인딩 주소 127.0.0.1 vs 0.0.0.0 실무 — 백엔드가 127.0.0.1에만 바인딩돼 LB가 못 붙는 함정 피하기
다음 챕터에서는 HAProxy 앞단에 Keepalived를 붙여 로드밸런서 자체의 고가용성(HA)을 구성합니다.