외부 API 호출이 가끔 30초씩 멈추며 워커가 쌓입니다. HTTP 500도 아니고 로그에는 timeout만 남아 있어 서버 문제인지 네트워크 문제인지 헷갈립니다.
connect timeout과 read timeout을 구분해야 원인 계층이 보입니다. curl 타이밍을 보면 어디서 시간이 사라졌는지 알 수 있습니다.
HTTP 연결·읽기 타임아웃 실전 디버깅
새벽 2시, 슬랙 알림이 연달아 옵니다. "결제 API 호출이 30초 후에 실패한다." 고객은 체크아웃 버튼을 눌렀지만 화면이 멈췄고, 30초 뒤 에러 페이지로 떨어집니다. 로그에는 curl: (28) Operation timed out after 30000 milliseconds가 찍혀 있습니다. 네트워크 문제인지, 서버 문제인지, 아니면 코드 문제인지 — 타임아웃 에러 하나로는 원인을 알 수 없습니다. 이 챕터에서는 타임아웃을 종류별로 정의하고, curl 타이밍 분석과 nc TCP 점검으로 문제의 계층을 정확히 특정하는 방법을 배웁니다.
- 1Connection Timeout, Read Timeout, Gateway Timeout을 정확히 구분할 수 있다
- 2curl --connect-timeout / --max-time 옵션의 차이를 실험으로 이해할 수 있다
- 3curl -w 옵션으로 time_connect / time_starttransfer / time_total을 분석할 수 있다
- 4nc -zv로 TCP 연결만 분리해서 점검할 수 있다
- 5502 / 503 / 504 에러가 각각 어느 계층 문제인지 판별할 수 있다
- 6백엔드 개발자가 외부 API 연동 시 타임아웃을 설정하는 실무 기준을 적용할 수 있다
curl --versionnc -h 2>&1 | head -3 || echo 'nc not found: sudo apt-get install -y netcat-openbsd'printf 'time_namelookup: %%{time_namelookup}\ntime_connect: %%{time_connect}\ntime_starttransfer: %%{time_starttransfer}\ntime_total: %%{time_total}\n' > /tmp/curl-format.txt && cat /tmp/curl-format.txtcurl -s -o /dev/null -w '%{http_code}' https://httpbin.org/gethttpbin.org/delay/{seconds}를 사용하면 지정한 초만큼 응답을 지연시킵니다. 예: https://httpbin.org/delay/5 는 5초 후 응답합니다.
Connection Timeout vs Read Timeout vs Gateway Timeout
타임아웃 에러를 마주했을 때 가장 먼저 할 일은 "어느 단계에서 멈췄는가"를 판별하는 것입니다. 타임아웃에는 종류가 있고, 종류마다 원인이 다른 계층에 있습니다.
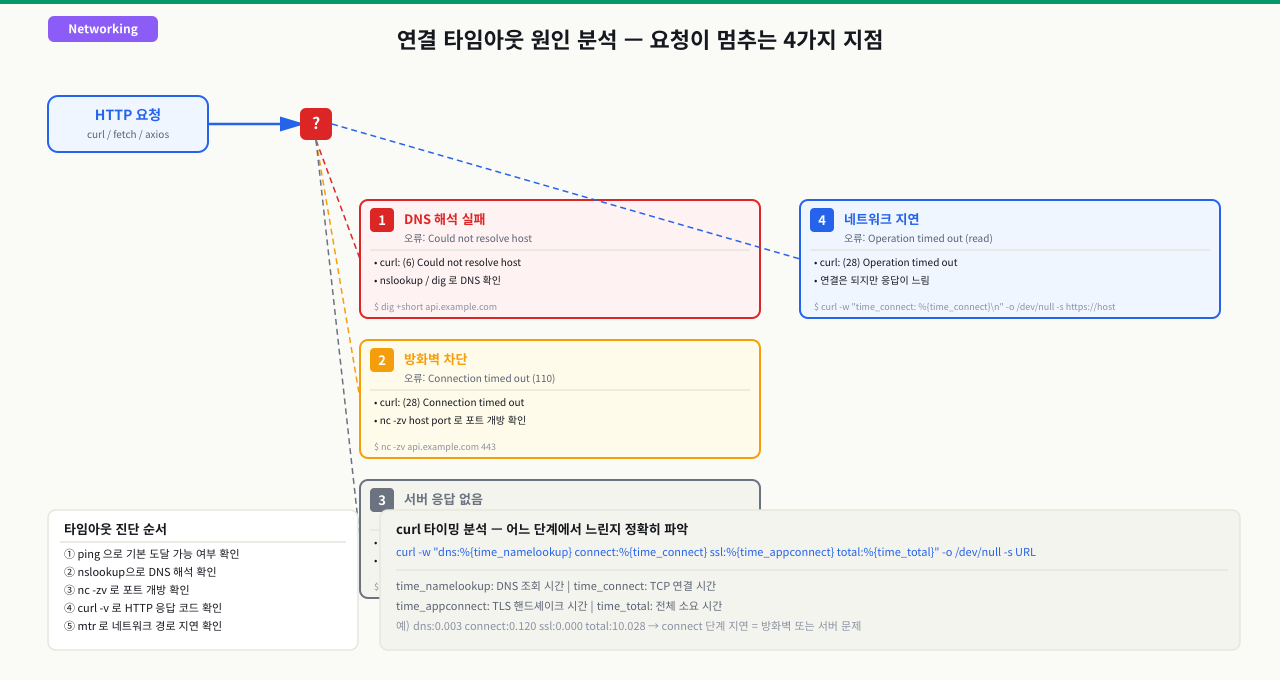 확대
확대
HTTP 요청의 3단계
클라이언트 서버
| |
|--- TCP SYN -----------> | ← 1단계: TCP 연결 (Connection)
|<-- SYN-ACK ----------- |
|--- ACK ---------------> |
| |
|--- HTTP GET /api ----> | ← 2단계: 요청 전송
| |
| [서버 처리 중] | ← 여기서 막히면 Read Timeout
| |
|<-- HTTP 200 OK -------- | ← 3단계: 응답 수신
타임아웃 3종 비교
| 타임아웃 종류 | 어느 단계에서 발생 | curl 옵션 | 원인 |
|---|---|---|---|
| Connection Timeout | TCP 3-way handshake 단계 | --connect-timeout | 서버 다운, 방화벽 차단, 잘못된 IP/포트 |
| Read Timeout (Max-Time) | HTTP 요청 전송 후 응답 대기 단계 | --max-time | 앱 서버 행(hang), DB 쿼리 지연, 스레드 풀 고갈 |
| Gateway Timeout | 프록시/게이트웨이가 업스트림 대기 | 서버(Nginx) 설정 | 클라이언트가 아닌 서버 계층의 타임아웃, 504 응답으로 나타남 |
왜 두 가지를 분리해서 설정해야 하는가
# 실습 디렉토리 준비
mkdir -p /tmp/networking/part3/exam_17 && cd /tmp/networking/part3/exam_17
# 잘못된 설정 — max-time만 설정
curl --max-time 30 https://api.example.com
# 올바른 설정 — 두 단계를 각각 제어
curl --connect-timeout 5 --max-time 30 https://api.example.com
- 핵심 출력—명령 결과에서 성공/실패를 가르는 값을 먼저 확인합니다
- 대상 식별—IP, 포트, 인터페이스, 프로세스명처럼 다음 조치를 결정하는 필드를 봅니다
- 다음 분기—결과가 기대와 다르면 어느 계층을 이어서 점검할지 정합니다
--connect-timeout만 없으면 서버가 다운됐을 때 시스템 기본값(보통 수 분)만큼 TCP 연결 시도를 기다립니다. 두 옵션을 분리하면 "TCP 연결 자체가 안 되는 경우(인프라 문제)"와 "연결은 됐지만 응답이 느린 경우(앱 문제)"를 구분해서 빠르게 원인을 좁힐 수 있습니다.
HTTP 요청이 어느 단계에서 멈추나 — 이름 해석부터 응답 수신까지 6단계
타임아웃 하나로는 "어디서 멈췄는지"를 알 수 없습니다. HTTP 요청 한 번은 DNS 해석 → TCP 연결 → TLS 핸드셰이크 → 요청 전송 → 첫 바이트 대기 → 응답 수신의 여러 구간을 지나고, 구간마다 멈추는 원인과 걸리는 타임아웃이 다릅니다. 뒤에서 실습할 curl -w는 이 구간들을 밀리초로 찍어 주므로, 그 값을 읽으면 어느 구간에서 시간이 사라졌는지 특정할 수 있습니다.
curl https://api.example.com/v1/data
│
① DNS 해석 이름 → IP (time_namelookup)
│
② TCP 연결 3-way handshake (time_connect 까지 누적)
│
③ TLS 핸드셰이크 인증서 검증·키 교환 (time_appconnect 까지 누적)
│
④ 요청 전송 GET 헤더·바디 송신
│
⑤ 첫 바이트 대기 서버가 처리해 첫 응답(TTFB) (time_starttransfer 까지 누적)
│
⑥ 응답 수신 바디 다운로드 (time_total)
▼
[응답 완료]
각 구간이 하는 일과, 거기서 멈출 때의 신호:
| 구간 | 하는 일 · 재는 값 | 여기서 멈추면 |
|---|---|---|
| ① DNS 해석 | 도메인을 IP로. curl -w의 time_namelookup | 이 값이 1초↑면 리졸버가 느리거나 /etc/resolv.conf 문제 (connect-timeout에 포함됨) |
| ② TCP 연결 | 3-way handshake. time_connect − time_namelookup 구간 | 방화벽 DROP이면 Connection timed out(connect-timeout이 여기서 컷), 리스닝 없으면 Connection refused |
| ③ TLS 핸드셰이크 | 인증서·프로토콜 협상. time_appconnect − time_connect 구간 | 인증서 만료·버전 불일치면 handshake에서 실패(HTTPS만 해당) |
| ④ 요청 전송 | 요청 헤더·바디를 서버로 송신 | 큰 바디 업로드면 이 구간이 길어짐 — 회선 상향 대역 영향 |
| ⑤ 첫 바이트 대기 | 서버가 처리해 첫 응답 바이트를 보낼 때까지(TTFB). time_starttransfer − time_appconnect 구간 | 이 값이 max-time에 붙으면 read timeout — 앱 hang·느린 쿼리·스레드 고갈(504의 층위) |
| ⑥ 응답 수신 | 응답 바디 전체를 받는다. time_total − time_starttransfer 구간 | 이 구간이 크면 큰 페이로드거나 느린 네트워크 |
즉 connect-timeout은 ①②(연결까지)를 덮고, max-time(또는 read timeout)은 ⑤⑥까지 전체를 덮습니다 — 그래서 둘을 분리해야 "연결이 안 되는지(①②, 인프라)"와 "연결은 됐는데 응답이 느린지(⑤, 앱)"를 구분할 수 있습니다. 판별의 핵심은 time_starttransfer입니다 — 이 값이 타임아웃값에 딱 붙으면 서버가 첫 바이트조차 못 보낸 것이므로 앱 계층 문제이고, time_namelookup이나 time_connect가 크면 DNS·네트워크 같은 인프라 문제입니다. 타임아웃 에러 한 줄을, curl -w 여섯 값이 구간별 시간표로 풀어 줍니다.
실습 1: --connect-timeout vs --max-time 차이 실험
실제로 두 옵션이 어떻게 다르게 동작하는지 확인합니다. httpbin.org/delay/{n}은 n초 후에 응답하는 테스트 엔드포인트입니다.
응답 없는 IP로 TCP 연결을 시도해 connect-timeout이 작동하는 방식을 직접 확인합니다. 3초 후 에러가 발생해야 정상입니다.
# 존재하지 않는 IP로 TCP 연결 시도 — connect-timeout이 작동
curl --connect-timeout 3 http://10.255.255.1/test
# 결과: curl: (28) Connection timed out after 3001 milliseconds
# → TCP handshake가 3초 내에 완료되지 않아 중단
# httpbin.org는 TCP 연결이 빠르므로 connect-timeout 3초 내에 성공
curl --connect-timeout 3 https://httpbin.org/delay/5
# → TCP 연결은 성공, 이후 5초 응답 대기 (connect-timeout은 이미 통과)
# → max-time 없으면 5초 후 정상 응답 수신
curl --connect-timeout 3 http://10.255.255.1/test- 10.255.255.1 요청: curl: (28) Connection timed out after 3001 milliseconds
- httpbin.org/delay/5 요청: TCP 연결 후 5초 기다렸다가 정상 응답 수신 (connect-timeout은 통과)
- 두 결과 차이: connect-timeout은 TCP 연결 단계만 제어함을 확인
응답이 5초 걸리는 엔드포인트에 max-time 3초를 설정합니다. TCP 연결이 성공해도 전체 시간이 초과되면 중단됩니다.
# 응답이 5초 걸리는데, max-time을 3초로 설정
curl --connect-timeout 5 --max-time 3 https://httpbin.org/delay/5
# 결과: curl: (28) Operation timed out after 3001 milliseconds with 0 bytes received
# → TCP 연결은 성공했지만, 전체 시간(연결+응답) 3초 초과로 중단
# max-time을 충분히 주면 정상 응답
curl --connect-timeout 5 --max-time 10 https://httpbin.org/delay/5
# 결과: 5초 후 JSON 응답 수신
curl --connect-timeout 5 --max-time 3 https://httpbin.org/delay/5- max-time 3: curl: (28) Operation timed out after 3001 milliseconds with 0 bytes received
- max-time 10: 5초 대기 후 JSON 응답 수신 성공
- 두 실험으로 connect-timeout(TCP 연결 단계)과 max-time(전체 단계) 차이 명확히 구분
실무 설정인 "연결은 빠르게, 총 시간은 넉넉하게"를 직접 실험합니다. TCP 연결이 성공해도 8초 응답은 10초 max-time 안에 들어오지 못합니다.
# 현장 설정: "연결은 빠르게, 총 시간은 넉넉하게"
curl -v \
--connect-timeout 3 \
--max-time 10 \
https://httpbin.org/delay/8
# 출력 예시:
# * Connected to httpbin.org (...) port 443 (#0) ← connect-timeout 통과
# ...
# curl: (28) Operation timed out after 10001 milliseconds ← max-time 초과
curl -v --connect-timeout 3 --max-time 10 https://httpbin.org/delay/8- Connected to httpbin.org 메시지: TCP 연결 성공 (connect-timeout 통과)
- curl: (28) Operation timed out after 10001 milliseconds: max-time 초과
- --connect-timeout 3 --max-time 10은 '3초 내 연결 + 나머지 7초 내 응답'을 의미
핵심 관찰: TCP 연결이 성공해도 max-time이 짧으면 응답 수신 중에 중단됩니다. --connect-timeout 3 --max-time 10은 "3초 내에 연결되고, 연결 후 남은 7초 내에 응답이 와야 한다"는 의미입니다.
curl -w '@curl-format.txt'로 타이밍 분석하기
curl은 -w 옵션으로 요청의 각 단계별 소요 시간을 밀리초 단위로 측정할 수 있습니다. 이 수치를 보면 "DNS가 느린지, TCP가 느린지, 서버 처리가 느린지"를 정확히 파악할 수 있습니다.
curl-format.txt 내용
time_namelookup: %{time_namelookup}
time_connect: %{time_connect}
time_starttransfer: %{time_starttransfer}
time_total: %{time_total}
파일로 저장해두고 -w "@파일명" 형태로 사용합니다.
각 변수의 의미
 확대
확대
타이밍으로 병목 계층 판별
| 패턴 | 의미 | 원인 |
|---|---|---|
time_namelookup이 1초 이상 | DNS 조회 지연 | DNS 서버 느림, /etc/resolv.conf 문제 |
time_connect - time_namelookup이 큼 | TCP 연결 지연 | 방화벽, 네트워크 경로 문제 |
time_starttransfer - time_connect이 큼 | 서버 처리 지연 | 앱 로직 느림, DB 쿼리 지연, TLS 협상 포함 |
time_total - time_starttransfer이 큼 | 응답 바디 전송 지연 | 큰 페이로드, 느린 네트워크 |
실습 2: curl 타이밍 분석으로 병목 구간 찾기
타이밍 분석용 포맷 파일을 만들고 정상 상태의 각 단계별 소요 시간을 측정합니다. 이 수치가 이후 비교의 기준선이 됩니다.
cat > /tmp/curl-format.txt << 'EOF'
time_namelookup: %{time_namelookup}
time_connect: %{time_connect}
time_starttransfer: %{time_starttransfer}
time_total: %{time_total}
EOF
curl -s -o /dev/null \
-w "@/tmp/curl-format.txt" \
https://httpbin.org/get
# 예시 출력:
# time_namelookup: 0.004521
# time_connect: 0.089234
# time_starttransfer: 0.312456
# time_total: 0.312901
curl -s -o /dev/null -w '@/tmp/curl-format.txt' https://httpbin.org/get- time_namelookup: DNS 조회 시간 — 정상 범위 1~10ms
- time_connect: TCP 연결까지 누적 시간 — 국내 서버는 보통 10ms 미만
- time_starttransfer: 첫 바이트 수신까지 시간 — 서버 처리 시간의 핵심 지표
- time_total: 전체 완료 시간
응답이 3초 걸리는 엔드포인트에서 타이밍을 측정합니다. time_starttransfer - time_connect 값이 크면 서버 처리 단계가 병목입니다.
curl -s -o /dev/null \
--connect-timeout 5 \
--max-time 15 \
-w "@/tmp/curl-format.txt" \
https://httpbin.org/delay/3
# 예시 출력:
# time_namelookup: 0.004210
# time_connect: 0.088901
# time_starttransfer: 3.091234 ← 서버 처리에 3초 소요
# time_total: 3.091678
curl -s -o /dev/null --connect-timeout 5 --max-time 15 -w '@/tmp/curl-format.txt' https://httpbin.org/delay/3- time_starttransfer - time_connect ≈ 3.00초: DNS도 TCP도 정상, 서버 처리만 느림
- 이 패턴은 백엔드 앱 지연 또는 DB 쿼리 지연을 의심해야 하는 신호
- time_namelookup이 1초 이상이면 DNS 문제, time_connect가 크면 네트워크/방화벽 문제
5회 반복 측정으로 간헐적 지연(특정 요청만 느린 패턴)을 찾아냅니다. 한 번만 측정하면 놓치는 이상값을 발견할 수 있습니다.
for i in {1..5}; do
curl -s -o /dev/null \
-w "run$i: connect=%.3f starttransfer=%.3f total=%.3f\n" \
--connect-timeout 5 --max-time 10 \
https://httpbin.org/get \
2>/dev/null
done
for i in {1..5}; do curl -s -o /dev/null -w 'run$i: connect=%.3f starttransfer=%.3f total=%.3f\n' --connect-timeout 5 --max-time 10 https://httpbin.org/get 2>/dev/null; done- 5회 중 특정 회차만 starttransfer가 크면 간헐적 앱 서버 지연
- 모든 회차에서 connect가 크면 네트워크 경로 문제
- 전체가 일정하면 서버 부하는 안정적인 상태
실습 3: nc -zv로 TCP 연결만 분리해서 점검
curl이 타임아웃된 상황에서 가장 먼저 해야 할 질문은 "TCP 연결 자체가 되는가?"입니다. nc(netcat)는 HTTP 없이 순수 TCP 연결만 시도하므로 계층을 분리할 수 있습니다.
nc는 TCP 3-way handshake만 시도하고 HTTP는 보내지 않습니다. curl이 타임아웃됐을 때 TCP 계층 문제인지 앱 계층 문제인지 구분하는 첫 번째 단계입니다.
# nc -zv <호스트> <포트>
# -z: 연결만 하고 데이터는 보내지 않음 (zero I/O mode)
# -v: verbose — 결과를 터미널에 출력
# -w 3: 3초 내에 연결 안 되면 포기
nc -zv -w 3 httpbin.org 443
# 성공: Connection to httpbin.org 443 port [tcp/https] succeeded!
# 실패: nc: connect to httpbin.org port 443 (tcp) failed: Connection refused
# nc: connect to httpbin.org port 443 (tcp) timed out
nc -zv -w 3 httpbin.org 443- succeeded: TCP 연결 정상 — curl 타임아웃이라면 앱 계층(HTTP/앱서버) 문제
- Connection refused: 서버 도달했으나 포트가 닫힘 — 앱 프로세스 미실행 확인
- timed out: 패킷이 사라짐 — 방화벽 DROP 또는 서버 다운
여러 포트를 순서대로 점검해 어떤 포트가 열려 있는지 한눈에 파악합니다. 장애 초기 대응에서 서비스 포트 상태를 빠르게 확인할 때 사용합니다.
# 여러 포트를 한 번에 점검
for port in 80 443 8080 8443; do
result=$(nc -zv -w 2 api.example.com $port 2>&1)
if echo "$result" | grep -q "succeeded"; then
echo "PORT $port: OPEN"
else
echo "PORT $port: CLOSED/FILTERED"
fi
done
for port in 80 443 8080 8443; do result=$(nc -zv -w 2 api.example.com $port 2>&1); if echo "$result" | grep -q 'succeeded'; then echo "PORT $port: OPEN"; else echo "PORT $port: CLOSED/FILTERED"; fi; done- OPEN 포트와 CLOSED/FILTERED 포트 목록 확인
- 예상 포트가 CLOSED이면 방화벽/Security Group 또는 앱 미실행 확인
- nc + curl 조합 진단: nc 성공 + curl 타임아웃 = 앱 계층 문제로 범위 좁힘
502 / 503 / 504 — 어느 계층 문제인지 판별 플로우
게이트웨이(Nginx, API Gateway, 로드밸런서)가 있는 환경에서 5xx 에러는 "게이트웨이가 업스트림 서버와의 통신에서 겪은 문제"를 나타냅니다. 에러 코드별로 문제의 계층이 다릅니다.
5xx 에러 계층 구분
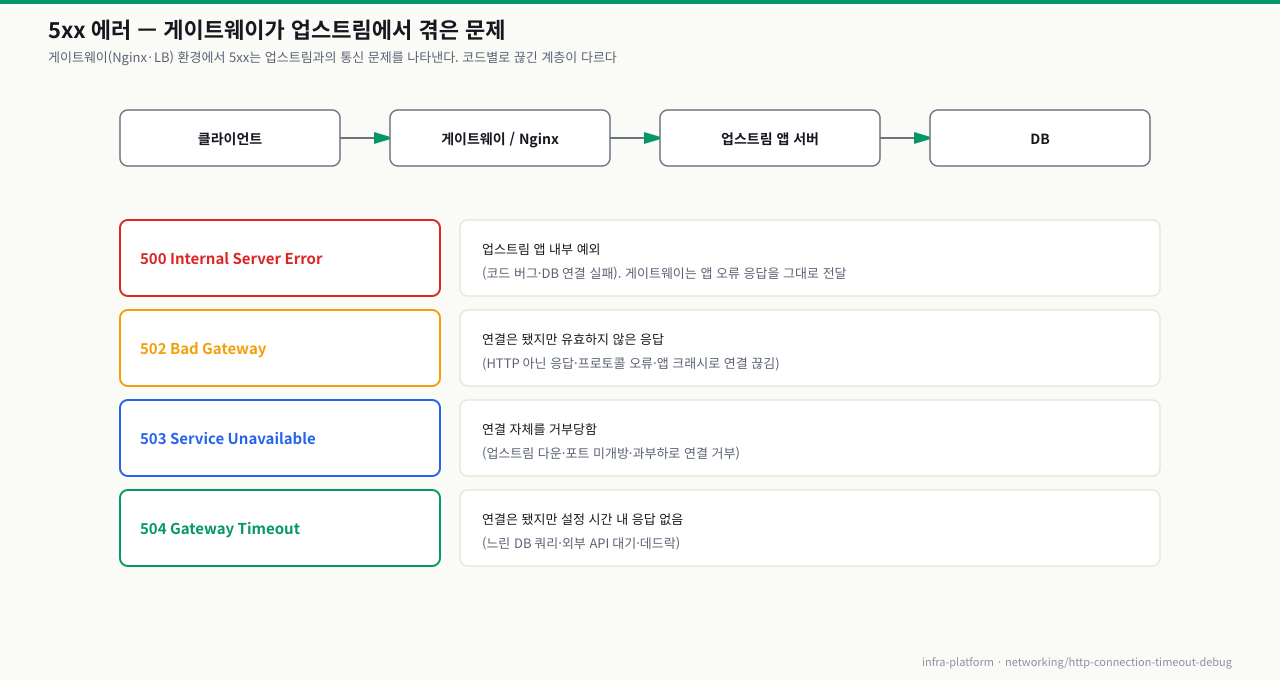 확대
확대
판별 플로우차트
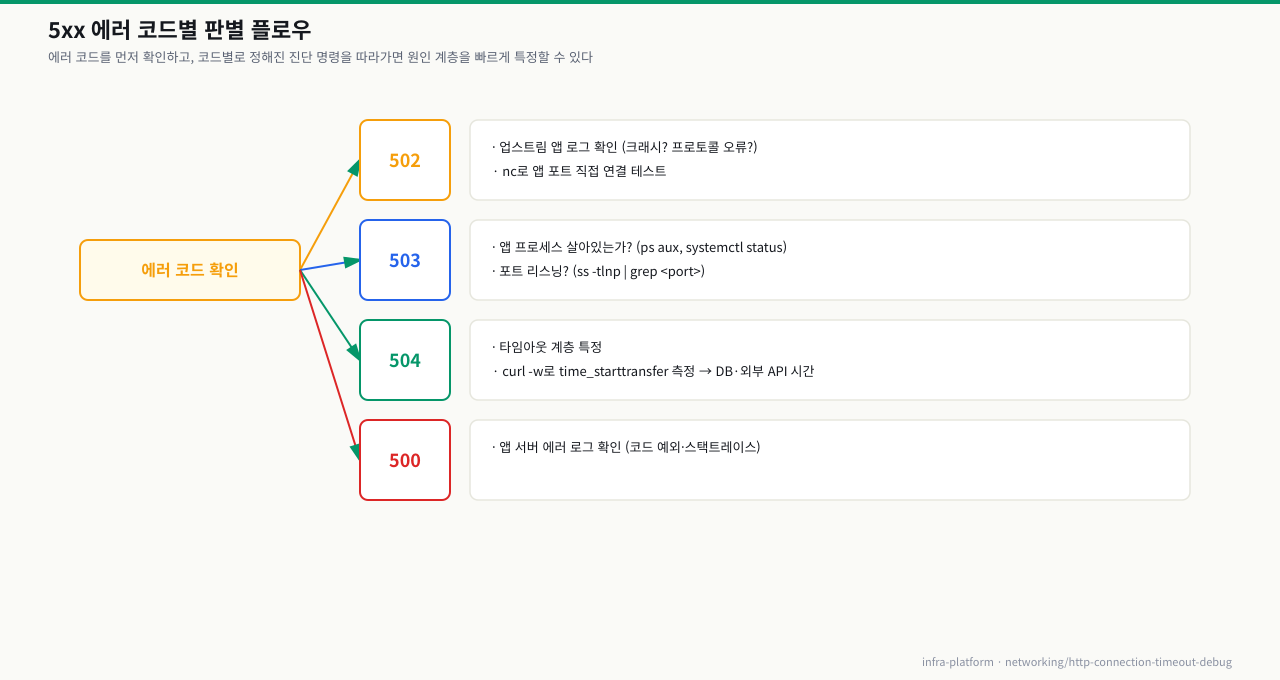 확대
확대
Nginx proxy_read_timeout과 504의 관계
Nginx 기본값은 proxy_read_timeout 60s입니다. 업스트림이 60초 내에 응답하지 않으면 클라이언트에게 504를 반환합니다. 이 값을 늘려도 업스트림의 실제 처리 시간이 줄지는 않습니다 — 근본 원인(느린 쿼리, 외부 API 지연)을 해결해야 합니다.
# Nginx 설정 예시 (근본 해결 전 임시 조치)
proxy_connect_timeout 5s; # 업스트림 TCP 연결 제한
proxy_read_timeout 60s; # 업스트림 응답 대기 제한
proxy_send_timeout 60s; # 업스트림 요청 전송 제한
상황
결제 서비스가 외부 PG사 API를 호출하는 코드에서 curl: (28) Operation timed out after 10000 milliseconds with 0 bytes received 에러가 발생하고 있습니다. 0 bytes received는 응답 바디가 전혀 오지 않았음을 뜻합니다.
단계별 진단
1단계: TCP 연결 분리 점검
nc -zv -w 3 pg-api.example.com 443
# 결과: Connection to pg-api.example.com 443 port [tcp/https] succeeded!
# → TCP는 열림. 포트 차단이나 서버 다운은 아님
2단계: curl 타이밍으로 어느 단계에서 멈추는지 확인
curl -s -o /dev/null \
--connect-timeout 3 \
--max-time 10 \
-w "@/tmp/curl-format.txt" \
https://pg-api.example.com/v1/charge
# 결과:
# time_namelookup: 0.003210
# time_connect: 0.045678 ← TCP 연결 45ms, 정상
# time_starttransfer: 10.000000 ← 10초 후 강제 종료 (starttransfer 미도달)
# time_total: 10.001234
# curl: (28) Operation timed out
해석: time_starttransfer가 타임아웃값과 일치합니다. 즉, 첫 번째 바이트가 전혀 오지 않았습니다. TCP는 연결됐지만 서버가 HTTP 응답을 시작조차 하지 않고 있습니다.
3단계: 원인 가설과 확인
# 가능한 원인 1: PG사 서버 측 장애
# → PG사 상태 페이지 확인, 다른 엔드포인트 테스트
curl -s -o /dev/null -w "%{http_code}" https://pg-api.example.com/health
# 가능한 원인 2: 특정 IP에서만 차단 (화이트리스트)
# → 서버에서와 로컬에서 같은 명령 실행 후 비교
# → PG사에 서버 출구 IP 화이트리스트 등록 여부 확인
# 가능한 원인 3: 요청 헤더 누락으로 서버가 응답 보류
curl -v --connect-timeout 3 --max-time 10 \
-H "Authorization: Bearer <token>" \
-H "Content-Type: application/json" \
https://pg-api.example.com/v1/charge
해결
PG사 서버가 특정 API 키 없이 들어오는 요청을 응답 없이 연결만 유지(hang)시키고 있었습니다. 올바른 인증 헤더를 추가하자 즉시 응답이 왔습니다.
예방: 코드 레벨 타임아웃 설정
// Node.js: axios 타임아웃 설정
const response = await axios.post(url, data, {
timeout: 10000, // 전체 10초 (max-time 역할)
// axios는 connect-timeout을 별도로 노출하지 않음
// → httpAgent로 세밀하게 제어 가능
});
// Python: requests 타임아웃 설정 (튜플로 분리 가능)
response = requests.post(url, json=data, timeout=(3, 10))
# (connect_timeout=3초, read_timeout=10초)
# Java Spring: RestTemplate 타임아웃
SimpleClientHttpRequestFactory factory = new SimpleClientHttpRequestFactory();
factory.setConnectTimeout(3000); // 3초
factory.setReadTimeout(10000); // 10초
증상
평소에는 잘 되다가 트래픽이 몰리는 시간대(오전 9시, 점심)에만 타임아웃이 납니다. 로그에는 같은 에러가 반복됩니다.
# 애플리케이션 로그 (Spring Boot)
# 09:03:12 ERROR - HikariPool-1 - Connection is not available, request timed out after 30000ms
# 09:03:15 ERROR - Read timed out
# 09:03:18 ERROR - HikariPool-1 - Connection is not available, request timed out after 30000ms
# curl로 직접 테스트하면 바로 응답됨
curl -v --max-time 5 https://api.external-service.com/v1/data
# 200 OK, 123ms
원인 진단
# DB 연결 풀 상태 확인 (HikariCP의 경우)
# 애플리케이션 actuator 엔드포인트로 확인
curl http://localhost:8080/actuator/metrics/hikaricp.connections.active
curl http://localhost:8080/actuator/metrics/hikaricp.connections.pending
# 또는 DB에서 직접 확인
# PostgreSQL
SELECT count(*), wait_event_type, wait_event
FROM pg_stat_activity
WHERE datname = 'mydb'
GROUP BY wait_event_type, wait_event;
해결
# 연결 풀 크기 조정 (application.yml)
spring:
datasource:
hikari:
maximum-pool-size: 20 # 기본값 10 → 늘림
connection-timeout: 5000 # 5초 (기본 30초에서 줄임)
idle-timeout: 300000 # 5분
# 근본 원인 파악 — 느린 쿼리가 연결을 오래 붙잡는 경우
# PostgreSQL slow query log 확인
# log_min_duration_statement = 1000 # 1초 이상 쿼리 로깅
핵심: curl이 빠른데 앱이 느리다면 외부 서버 문제가 아니라 앱 내부 자원(DB 연결 풀, 스레드 풀) 고갈입니다.
심화 — 연결은 살아 있어 보여도 이미 끊겨 있다
심화: TCP는 '조용히 끊긴' 연결을 모른다 — 재전송 타임아웃의 함정
타임아웃 디버깅의 마지막 벽은 "연결은 분명히 맺어졌는데 응답이 없다"는 상황입니다. connect()가 성공했다는 건 그 순간 3-way handshake가 됐다는 뜻일 뿐, 그 연결이 지금도 살아 있다는 보장이 아닙니다. 경로 중간의 방화벽·NAT·로드밸런서가 연결을 조용히 버려도, 양쪽 커널은 한동안 그 사실을 모릅니다.
- ESTABLISHED는 상태일 뿐, 확인이 아니다: TCP는 데이터를 보낼 때만 상대의 생존을 알 수 있습니다. 경로 중간 장비가 FIN/RST 없이 연결 상태(conntrack 엔트리)를 삭제하면, 보낸 쪽은 응답이 없어 재전송을 시작합니다.
- 재전송은 지수적으로 늘어난다: 커널은 RTO(재전송 타임아웃)를 두 배씩 늘리며
tcp_retries2(기본 15회)만큼 재시도합니다. 이 총합이 약 15분이라, 애플리케이션 타임아웃이 없으면 스레드가 그만큼 매달립니다. - stateful 미들박스의 idle 타임아웃: 방화벽·NAT·로드밸런서는 유휴 연결의 상태 테이블을 일정 시간 뒤 지웁니다(예: 로드밸런서 60초, NAT 5분). 커넥션 풀이 그보다 오래 소켓을 재사용하면, 다음 요청이 '이미 죽은' 소켓으로 나가 응답을 못 받습니다.
- 방어선은 두 겹: 애플리케이션 read timeout으로 상한을 못 박고, TCP keepalive를 미들박스 idle 타임아웃보다 짧게 켜 죽은 연결을 미리 감지·정리합니다.
그래서 "connect는 되는데 가끔 오래 매달린다"는 신고는 서버가 아니라 경로 중간의 상태 만료를 의심해야 합니다.
상황
트래픽이 한산한 시간대(새벽, 점심 직후 첫 요청)에만 외부 API 호출이 read timeout으로 끊깁니다. 곧바로 재시도하면 정상입니다. 부하가 없는데 실패한다는 점이 연결 풀 고갈(반대 상황)과 정반대라 헷갈립니다.
원인
앞단 로드밸런서의 idle 타임아웃(예: 60초)이 커넥션 풀의 유휴 소켓 유지 시간보다 짧았습니다. 트래픽이 뜸하면 풀 안의 소켓이 60초 넘게 놀다가 로드밸런서에서 조용히 폐기되는데, RST가 전달되지 않아 풀은 그 소켓을 살아 있다고 착각합니다. 다음 요청이 이 '반쯤 열린' 소켓으로 나가면 응답이 오지 않아 read timeout까지 매달립니다.
진단
# 유휴 established 소켓과 타이머 확인
ss -o state established '( dport = :443 )'
# 실패 순간: 같은 seq 데이터 재전송만 반복되고 ACK가 없다
sudo tcpdump -ni any 'tcp port 443 and host api.external-service.com'
로드밸런서의 idle 타임아웃 값과 커넥션 풀의 keep-alive/max-idle 값을 나란히 비교하면 대소가 뒤집혀 있습니다.
해결
커넥션 풀의 유휴 유지 시간을 미들박스 idle 타임아웃보다 짧게 잡거나, TCP keepalive를 그보다 짧은 주기로 켜 죽은 소켓을 미리 걸러냅니다. 재사용 전 유효성 검사(validate-on-borrow)나 짧은 read timeout + 멱등 보장 재시도도 함께 둡니다.
백엔드 개발자가 외부 API 연동할 때 항상 이렇게 설정한다
외부 API(결제, SMS, 지도, 소셜로그인 등)를 연동하는 코드에 타임아웃을 설정하지 않으면, 외부 서비스가 응답하지 않을 때 내 서버의 스레드가 영원히 대기합니다. 스레드가 쌓이면 내 서비스 전체가 응답 불능 상태가 됩니다. 외부 API 하나의 장애가 내 서비스 전체 장애로 번지는 가장 흔한 패턴입니다.
타임아웃 설정 기준
Connection Timeout: 1~5초
- 정상 서버라면 TCP 연결은 수백ms 내에 완료됩니다
- 3초를 넘는다면 인프라 문제입니다
- 기본값: 3초
Read Timeout: 외부 API SLA의 2배 또는 최대 30초
- 결제 API가 "평균 500ms, 최대 3초"를 보장한다면 → 6~10초 설정
- 명세에 SLA가 없다면 5~15초 사이에서 보수적으로 설정
- 절대 무한(0) 설정 금지
재시도 정책과 함께 사용:
- 타임아웃 후 무조건 재시도하면 멱등하지 않은 API(결제)에서 중복 처리 위험
- 재시도 전 idempotency key 사용 또는 조회 API로 상태 확인 필요
장애 상황에서 curl로 먼저 확인하는 루틴
외부 API 장애 신고를 받으면 코드를 보기 전에 이것부터 실행합니다:
# 1. TCP 연결 점검
nc -zv -w 3 <외부_API_호스트> <포트>
# 2. curl 타이밍 분석
curl -s -o /dev/null \
--connect-timeout 3 --max-time 15 \
-w "@/tmp/curl-format.txt" \
<외부_API_엔드포인트>
# 3. 결과 판독
# nc 실패 → "저희 서버에서 해당 호스트의 포트가 막혀있습니다"
# nc 성공, time_starttransfer ≈ max-time → "API 서버가 응답을 안 하고 있습니다"
# nc 성공, time_starttransfer 정상 → "HTTP 응답은 오는데 내용 문제 — curl -v로 헤더 확인"
이 3단계로 "내 코드 문제인가, 외부 서버 문제인가, 네트워크 문제인가"를 5분 안에 좁힐 수 있습니다. 원인 계층이 명확해야 외부 업체에 정확한 보고서를 보낼 수 있고, 내부에서 코드를 고칠지 인프라 팀을 부를지 결정할 수 있습니다.
명령어·단축키 빠른 참조
이 모듈에서 다룬 타임아웃 디버깅 명령(curl 타이밍·nc·ss)을 실전 옵션과 함께 모았습니다.
| 명령어 | 용도 | 자주 쓰는 예 |
|---|---|---|
curl --connect-timeout N | TCP 연결(핸드셰이크) 단계만 제한 | curl --connect-timeout 3 http://10.255.255.1/ (연결 안 되면 3초 컷) |
curl --max-time N | 연결+응답 전체 시간 제한 | curl --connect-timeout 3 --max-time 10 URL (두 단계 분리 제어) |
curl -w "@file" | 단계별 타이밍 측정 | -w "@/tmp/curl-format.txt" 로 time_connect·time_starttransfer 분해 |
curl -w "%{...}" | 특정 타이밍/코드만 출력 | -w "%{http_code}", -w "%{time_starttransfer}" |
curl -v | 요청 단계·연결 상세 로그 | curl -v --connect-timeout 3 --max-time 10 URL |
nc -zv -w N host port | HTTP 없이 순수 TCP 연결만 점검 | nc -zv -w 3 httpbin.org 443 (succeeded면 L4 정상) |
for port in …; nc -zv | 여러 포트 일괄 개방 점검 | for p in 80 443 8080; do nc -zv -w 2 host $p; done |
ss -o state established | 유휴 established 소켓·타이머 확인 | ss -o state established '( dport = :443 )' |
tcpdump -ni any | 재전송·무응답 패킷 확인 | sudo tcpdump -ni any 'tcp port 443 and host api...' |
관련 모듈로 더 깊이:
- curl 명령어로 HTTP 상태 코드 및 헤더 분석하기 — curl로 HTTP 헤더·상태 코드·타이밍을 분해하는 기본기
- telnet과 nc(netcat) 명령어로 L4 포트 통신 상태 점검 — nc로 TCP 포트 도달 가능 여부를 점검하는 법
- 웹 서버에서 DB 접속 실패 시 원인 격리 프로세스 — 타임아웃 원인을 L1~L7 계층별로 좁히는 방법론
다음 모듈에서는 네트워크 장애 전반을 체계적으로 고립시키는 troubleshooting-isolation 방법론을 다루며, L1부터 L7까지 계층별 점검 절차를 완성합니다.