장애 시간에 서버 CPU는 낮은데 연결 수가 폭증했습니다. LISTEN, ESTABLISHED, TIME_WAIT 상태를 구분하지 못해 서비스가 정말 바쁜지 커넥션이 쌓였는지 판단이 늦어졌습니다.
소켓 상태는 서버의 현재 통신 장부입니다. ss 출력만 읽어도 병목의 방향이 보입니다.
소켓 상태와 연결 모니터링 (netstat / ss)
서버가 느려졌다는 신고를 받았을 때, 혹은 포트가 열려있는데 접속이 안 된다는 문의가 왔을 때 가장 먼저 확인해야 할 것은 소켓 상태입니다. 이 챕터에서는 TCP 소켓의 생명주기와 4가지 핵심 상태를 이해하고, netstat와 ss 명령으로 서버의 연결 현황을 점검하는 방법을 배웁니다.
- 1TCP 소켓 생명주기인 3-Way Handshake(연결 수립)와 4-Way Handshake(연결 종료)를 설명할 수 있다
- 2LISTEN, ESTABLISHED, TIME_WAIT, CLOSE_WAIT 등 핵심 소켓 상태의 의미와 발생 원인을 이해할 수 있다
- 3ss 명령 핵심 옵션(-antp, -s, -o)을 활용하고 netstat과 비교할 수 있다
- 4ESTABLISHED 수로 동시 접속자를 파악하고 서버 부하를 점검할 수 있다
- 5CLOSE_WAIT 소켓 누수를 탐지하고 코드 버그를 진단할 수 있다
- 6TIME_WAIT 과다 시 커널 파라미터(tcp_tw_reuse, tcp_fin_timeout)를 튜닝할 수 있다
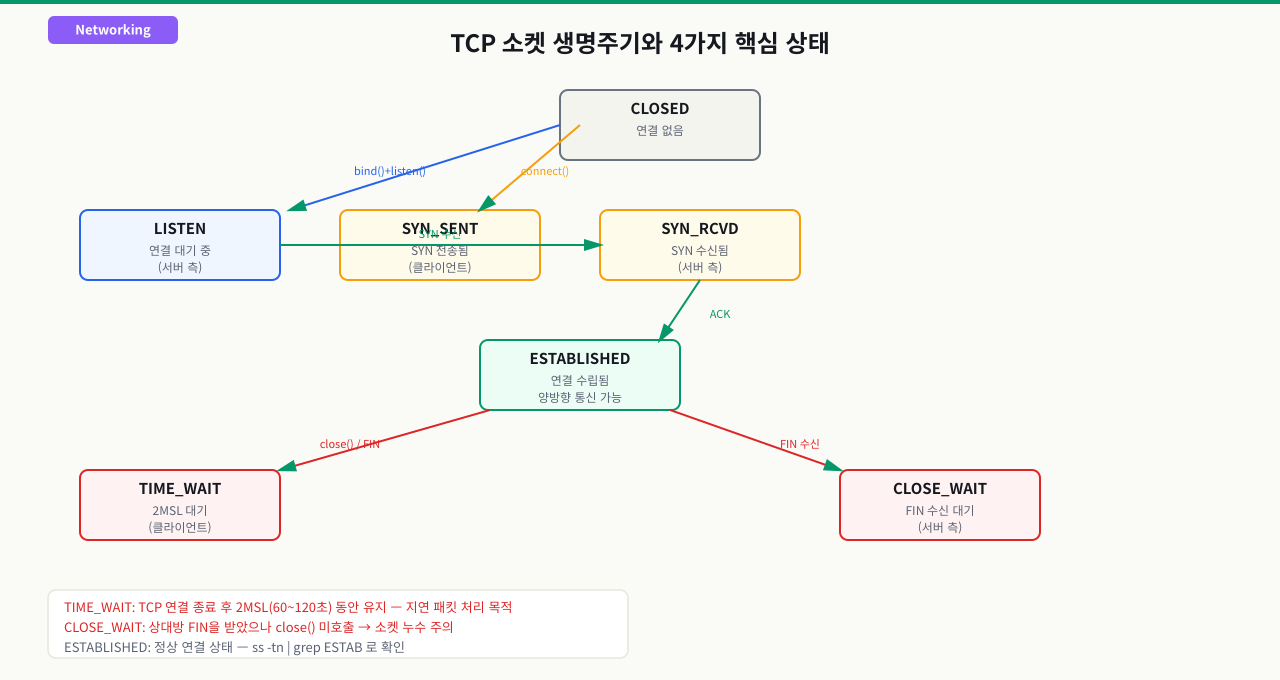
ss --versionnetstat --version || sudo apt-get install -y net-toolspython3 -m http.server 8080 &kill $(lsof -ti:8080)TCP 소켓의 생명주기와 4가지 핵심 상태
포트 8080을 사용하는 애플리케이션을 재시작했는데 "Address already in use" 오류가 납니다. 프로세스를 종료했는데도 왜 포트가 잡혀있는지 이해가 안 됩니다. ss -tan으로 확인하면 TIME_WAIT 상태 소켓이 수십 개 쌓여 있습니다. 소켓 생명주기를 모르면 이 상태가 정상인지 문제인지, 얼마나 기다리면 되는지 알 수 없습니다.
 확대
확대
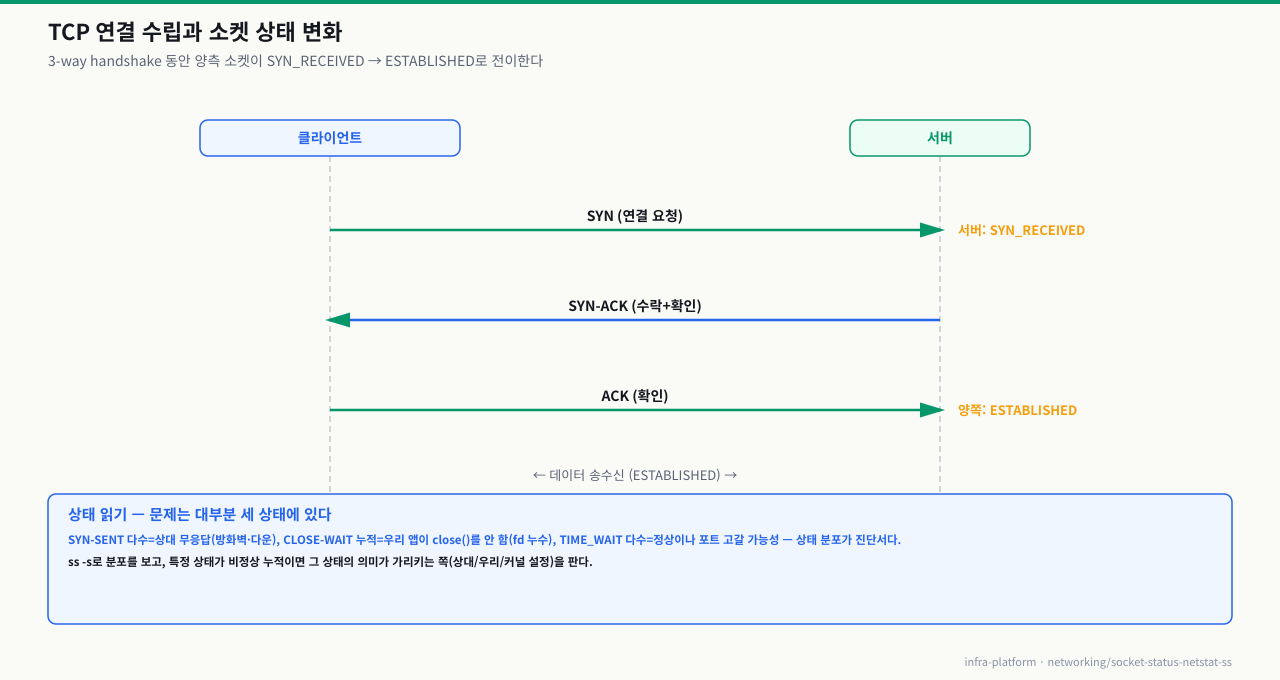
TCP 연결 수립 — 3-Way Handshake
소켓 상태를 이해하려면 TCP 연결 수립과 종료 과정을 알아야 합니다.
 확대
확대
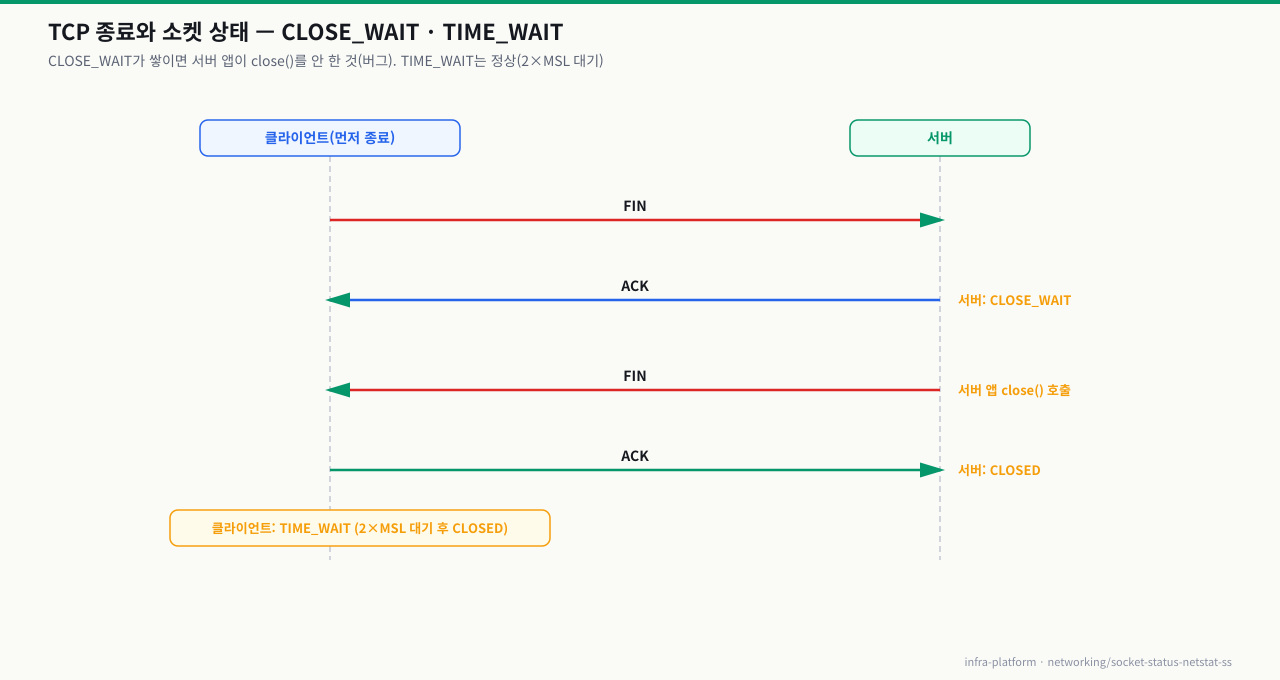
TCP 연결 종료 — 4-Way Handshake
 확대
확대
4가지 핵심 소켓 상태
LISTEN
서버가 특정 포트에 바인딩되어 클라이언트의 연결 요청을 기다리는 상태입니다.
 확대
확대
예: Nginx가 80 포트를 LISTEN → 클라이언트 HTTP 요청 대기 중
ESTABLISHED
3-way handshake 완료 후 양방향 데이터 전송이 가능한 상태입니다. 현재 활성 연결의 수가 ESTABLISHED 소켓 수입니다.
ESTABLISHED 소켓 수 = 현재 서버에 연결된 클라이언트(동시 접속자) 수
TIME_WAIT
TCP 연결 종료 후 일정 시간(기본 60초, 커널 파라미터로 조정) 동안 유지되는 상태입니다.
TIME_WAIT가 필요한 이유:
- 마지막 ACK가 유실됐을 때 재전송할 수 있도록 대기
- 네트워크에 떠돌아다니는 지연 패킷이 새 연결에 영향을 주지 않도록 방지
TIME_WAIT 소켓 고갈 문제: 대용량 요청을 처리하는 서버에서 TIME_WAIT 소켓이 과도하게 쌓이면 사용 가능한 포트(로컬 포트 범위 1024~65535)가 고갈되어 새 연결을 맺지 못합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/networking/part4/exam_18 && cd /tmp/networking/part4/exam_18
# 로컬 포트 범위 확인
cat /proc/sys/net/ipv4/ip_local_port_range
# 32768 60999 (약 28,000개)
- 읽기 순서 A — ss -s 요약 먼저—`ss -s`로 전체 소켓 상태 분포를 먼저 봅니다. timewait 수치가 전체 수의 80% 이상이면 단기 연결 폭증 상황입니다.
- 읽기 순서 B — ESTABLISHED 수 확인—현재 활성 연결(동시 접속자) 수를 확인합니다. 베이스라인 대비 갑자기 2배 이상 증가했다면 트래픽 폭증 또는 연결 누수입니다.
- 읽기 순서 C — TIME_WAIT와 CLOSE_WAIT 집중—TIME_WAIT 수천 개는 단기 연결이 많은 것(keep-alive 미사용)이고, CLOSE_WAIT 10개 이상 지속은 앱이 소켓을 닫지 않는 버그(메모리 누수 징후)입니다.
- ESTABLISHED 판단 기준—서비스 규모마다 다르지만 베이스라인 대비 갑작스러운 2배 이상 증가 → 부하 급증. 증가 없이 CPU만 높으면 처리 지연(slow query, blocking I/O)입니다.
- TIME_WAIT 판단 기준—수천 개(~5,000) → 단기 연결 빈번, keep-alive 설정 권장. 로컬 포트 범위(약 28,000개)의 70% 초과 → 포트 고갈 위험, 즉시 tcp_tw_reuse 설정.
- CLOSE_WAIT 판단 기준—10개 이상 지속 → 앱 레벨 소켓 누수 의심. 시간이 지나도 줄지 않으면 애플리케이션이 close()를 호출하지 않는 코드 버그입니다. 재시작은 임시 방편.
- 조합 해석 — TIME_WAIT 많음 + ESTABLISHED 적음—연결이 빠르게 열고 닫히는 패턴. HTTP/1.1 keep-alive 미사용 또는 짧은 keepalive timeout이 원인입니다.
- 조합 해석 — CLOSE_WAIT 증가 + CPU 낮음—앱 레벨 소켓 누수. CPU나 네트워크 문제가 아닌 코드 버그입니다. 코드의 finally 블록이나 커넥션 풀 반납 로직을 점검하세요.
- 조합 해석 — SYN_RECV 다수—SYN flood 공격 의심 또는 서버 처리 능력 초과. `ss -antp | grep SYN-RECV | wc -l`로 수량 확인 후 백로그 크기와 비교합니다.
CLOSE_WAIT
상대방이 FIN을 보냈고 내가 ACK로 응답했지만, 내 애플리케이션이 아직 소켓을 close()하지 않은 상태입니다.
CLOSE_WAIT가 누적되는 원인:
- 애플리케이션 코드에서 소켓을 close()하지 않는 버그
- 커넥션 풀(connection pool)에서 반납되지 않는 연결
- 예외 발생 시 finally 블록에서 소켓 정리를 누락
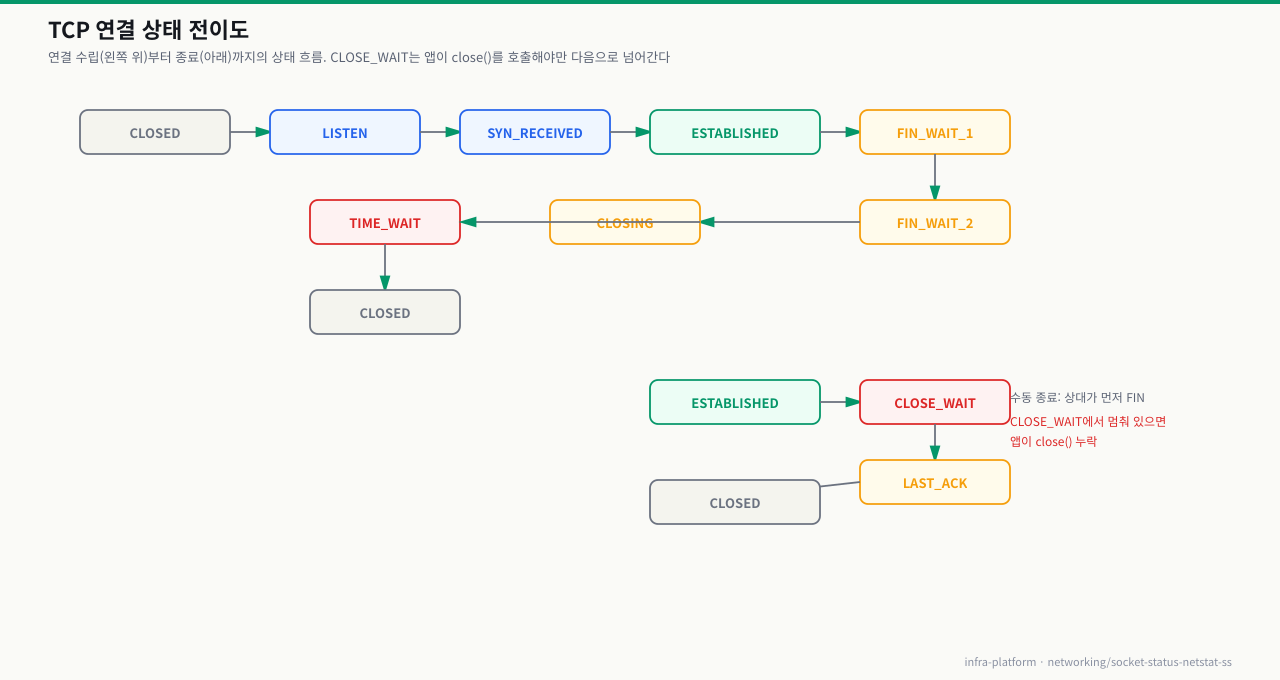
CLOSE_WAIT는 커널이 자동으로 처리하지 않습니다. 오직 애플리케이션이 close()를 호출해야만 LAST_ACK → CLOSED로 전환됩니다.
전체 상태 전이도
 확대
확대
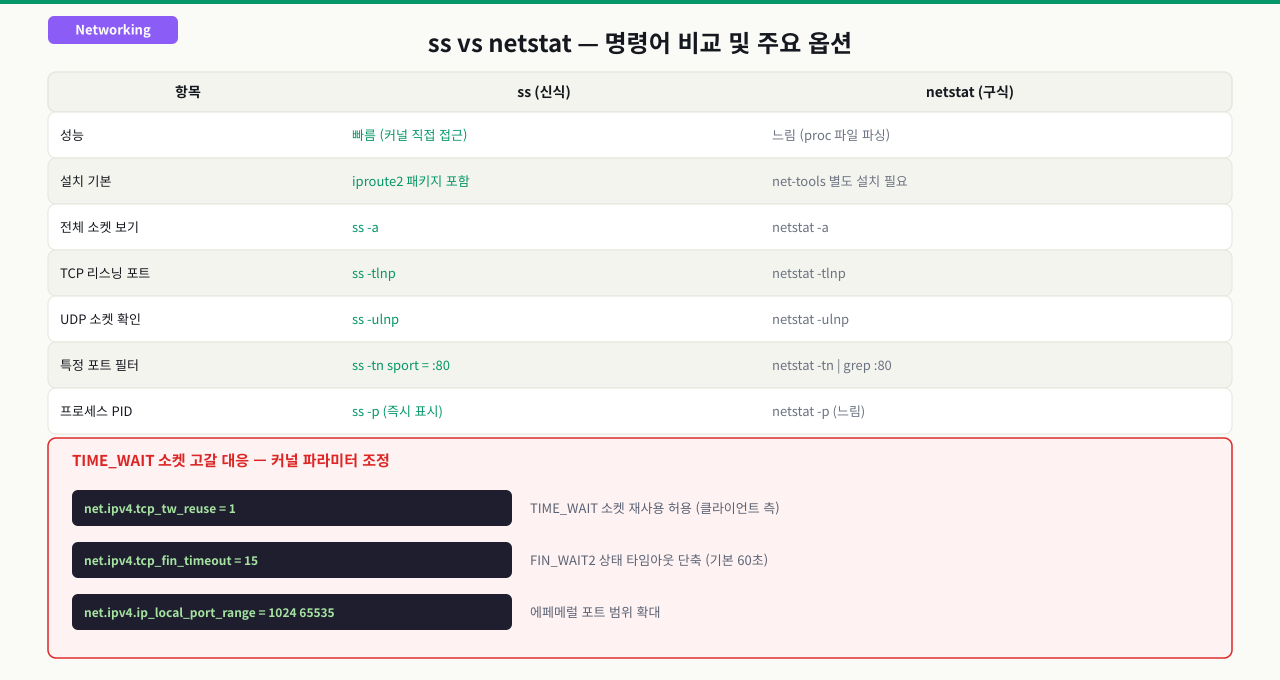
ss와 netstat 명령 비교 및 TIME_WAIT 소켓 관리
장애 상황에서 "지금 이 서버에 열린 연결이 몇 개야?" 를 빠르게 확인해야 합니다. 구형 서버에는 netstat밖에 없고 최신 서버엔 ss만 있습니다. 두 명령어의 출력 형식이 달라서 같은 정보를 보는데 명령어마다 다른 옵션을 외워야 합니다. 그리고 TIME_WAIT 소켓이 수천 개 쌓이면 새 연결이 안 생기는 문제가 발생하는데, 이걸 관리하는 방법을 모르면 재부팅 외에 해결책이 없습니다.
 확대
확대
ss vs netstat
| 항목 | ss | netstat |
|---|---|---|
| 속도 | 빠름 (커널 직접 조회) | 느림 (/proc 파일 파싱) |
| 패키지 | iproute2 (기본 설치) | net-tools (별도 설치 필요) |
| 권장 | RHEL 7+ 기본 도구 | 레거시 |
| 대용량 | 수만 개 소켓도 빠름 | 소켓 많으면 느려짐 |
현대 Linux 배포판에서는 ss를 기본으로 사용하고, 익숙함을 위해 netstat 옵션도 알아두는 것이 좋습니다.
ss 주요 옵션
# 기본 — TCP 소켓 전체 (숫자, 프로세스 포함)
ss -antp
# 플래그 설명
# -a: 모든 상태 (LISTEN 포함)
# -n: 숫자로 표시 (DNS/포트 이름 변환 안 함)
# -t: TCP만
# -p: 프로세스 정보 (PID, 프로세스명)
# -u: UDP만
# -l: LISTEN 상태만
# LISTEN 포트만 확인
ss -tlnp
# UDP 소켓 확인
ss -ulnp
# 요약 통계
ss -s
netstat 주요 옵션
# 리스닝 포트 + UDP + 프로세스
netstat -tulnp
# 플래그 설명
# -t: TCP
# -u: UDP
# -l: LISTEN 상태만
# -n: 숫자로 표시
# -p: 프로세스 정보
# 전체 소켓 (ESTABLISHED 포함)
netstat -antp
TIME_WAIT 소켓 고갈 대응 — 커널 파라미터
# 현재 TIME_WAIT 소켓 수 확인
ss -antp | grep TIME-WAIT | wc -l
# 또는 ss -s 요약에서 확인
ss -s
# Total: 1245
# TCP: 1189 (estab 45, closed 1100, orphaned 0, timewait 1100)
TIME_WAIT 소켓 고갈 방지를 위한 커널 파라미터:
# 현재 설정 확인
sysctl net.ipv4.tcp_tw_reuse
sysctl net.ipv4.tcp_fin_timeout
# net.ipv4.tcp_tw_reuse: TIME_WAIT 소켓을 새 연결에 재사용 허용
# 1로 설정하면 TIME_WAIT 상태의 포트를 outbound 연결에 재사용
sudo sysctl -w net.ipv4.tcp_tw_reuse=1
# net.ipv4.tcp_fin_timeout: FIN_WAIT_2 타임아웃(초), 기본 60
sudo sysctl -w net.ipv4.tcp_fin_timeout=30
# 영구 적용 (/etc/sysctl.conf 또는 /etc/sysctl.d/)
echo "net.ipv4.tcp_tw_reuse = 1" | sudo tee -a /etc/sysctl.d/99-tcp-tuning.conf
echo "net.ipv4.tcp_fin_timeout = 30" | sudo tee -a /etc/sysctl.d/99-tcp-tuning.conf
sudo sysctl -p /etc/sysctl.d/99-tcp-tuning.conf
참고:
net.ipv4.tcp_tw_recycle은 커널 4.12에서 제거됐습니다. 사용하지 마세요.
ss 한 줄이 소켓 상태를 보여주기까지 — 커널 장부에서 진단까지 6단계
ss -antp가 ESTABLISHED·TIME_WAIT·CLOSE_WAIT를 표시할 수 있는 건, 그 상태를 ss가 계산하는 게 아니라 커널이 이미 관리하고 있는 것을 읽어 오기 때문입니다. 커널은 열린 모든 연결을 소켓 테이블이라는 장부에 적어 두고 연결마다 지금 어느 상태인지를 실시간으로 갱신합니다. 이 경로 — 커널이 상태를 기록하고, 도구가 읽고, 우리가 원인으로 매핑하는 — 를 알면 "이 상태가 왜 보이는지"와 "이 상태가 쌓이면 누구 잘못인지"를 단계로 짚을 수 있습니다.
[앱] socket() → listen() 또는 connect()
│
① 커널이 연결마다 소켓 구조체(TCB) 생성 → 상태 필드에 LISTEN·SYN-SENT 기록
│
② 패킷 이벤트마다 TCP 상태머신을 전이 (SYN·ACK·FIN 도착 → 상태 갱신)
│ ESTABLISHED → FIN_WAIT → TIME_WAIT / ESTABLISHED → CLOSE_WAIT → ...
│
③ 갱신된 상태·큐 길이가 커널 소켓 테이블에 상주 (sock_diag · /proc/net/tcp)
│
④ ss는 sock_diag 넷링크로, netstat는 /proc 파싱으로 이 테이블을 읽음
│
⑤ State · Recv-Q · Send-Q · 프로세스 열로 화면에 표시
│
⑥ 상태 분포를 원인으로 매핑 → 진단
▼
[운영자] "CLOSE_WAIT 30개 = 앱이 close()를 안 함"
각 단계가 하는 일과, 그 단계가 어긋날 때의 신호:
| 단계 | 하는 일 | 여기서 어긋나면 |
|---|---|---|
| ① 소켓 생성 | 앱이 소켓을 열면 커널이 연결마다 구조체를 만들어 상태를 기록. LISTEN 소켓이 있어야 그 포트로 온 연결을 받는다 | LISTEN 소켓이 없으면 그 포트로 온 SYN에 커널이 RST로 응답 → 클라이언트는 Connection refused |
| ② 상태 전이 | 패킷이 오갈 때마다 상태머신을 전이시킨다. 정상 종료는 FIN 교환으로 TIME_WAIT까지 진행 | 앱이 close()를 호출 안 하면 CLOSE_WAIT에서 전이가 멈춰 소켓이 잔류(누수) |
| ③ 테이블 상주 | 상태와 함께 Recv-Q·Send-Q(LISTEN이면 accept 큐 깊이·backlog)가 테이블에 남는다 | LISTEN 소켓의 Recv-Q가 Send-Q(backlog)까지 차면 커널이 완성 연결을 드랍 |
| ④ 도구가 읽기 | ss는 sock_diag 넷링크로 커널에 직접 질의, netstat는 /proc/net/tcp를 한 줄씩 파싱 | 소켓이 수만 개면 /proc 파싱(netstat)이 느려짐 — 대규모는 ss가 수십 배 빠름 |
| ⑤ 화면 표시 | State·주소·큐·소유 프로세스(PID)를 열로 출력 | -n을 빼면 포트를 서비스명으로 바꿔 표시해 grep 필터가 어긋남 |
| ⑥ 원인 매핑 | 상태별 개수의 이상 패턴을 원인으로 해석 | CLOSE_WAIT 누적 = 내 앱이 close 안 함 · TIME_WAIT 과다 = 단명 연결 폭주 · Recv-Q 상주 = 앱이 accept·read를 못 따라감 |
즉 ss가 보여주는 상태는 커널이 실시간으로 갱신하는 장부의 스냅샷입니다. 그래서 상태 하나하나가 곧 진단 단서가 됩니다 — CLOSE_WAIT은 커널이 못 지우는 게 아니라 내 앱이 마지막 close()를 호출해야 사라지므로 '내 코드' 문제를, TIME_WAIT 과다는 연결을 짧게 맺고 끊는 '연결 패턴' 문제를, LISTEN 소켓의 Recv-Q 상주는 accept·read가 밀린 '처리 속도' 문제를 가리킵니다. 상태를 읽는다는 것은 결국 커널의 장부를 읽어 원인 계층을 좁히는 일입니다.
기본 소켓 상태 확인
# 1. LISTEN 중인 TCP 포트 확인 (어떤 서비스가 어느 포트를 점유했나)
ss -tlnp
# 출력 예시
# State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
# LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=1234,fd=3))
# LISTEN 0 511 0.0.0.0:80 0.0.0.0:* users:(("nginx",pid=5678,fd=6))
# LISTEN 0 128 127.0.0.1:3306 0.0.0.0:* users:(("mysqld",pid=9012,fd=23))
# LISTEN 0 511 [::]:443 [::]:* users:(("nginx",pid=5678,fd=7))
# 확인 포인트
# - 0.0.0.0: 모든 인터페이스에서 수신
# - 127.0.0.1: 로컬 루프백만 (외부에서 접근 불가)
# - [::]: IPv6 와일드카드
# - Recv-Q: 수신 큐에 쌓인 바이트 수 (큰 값이면 처리 지연)
전체 소켓 상태 현황 파악
# 모든 TCP 소켓 목록
ss -antp
# 상태별 소켓 수 집계
ss -antp | awk 'NR>1 {print $1}' | sort | uniq -c | sort -rn
# 출력 예시
# 1100 TIME-WAIT
# 45 ESTAB
# 10 LISTEN
# 3 CLOSE-WAIT
# 1 FIN-WAIT-1
동시 접속자 수 확인
# ESTABLISHED 소켓 수 = 현재 활성 연결 수
ss -antp | grep ESTAB | wc -l
# 특정 포트의 연결 수 (예: HTTP 80포트)
ss -antp | grep ':80' | grep ESTAB | wc -l
# 연결 중인 원격 IP별 집계 (어떤 IP에서 많이 붙어있나)
ss -antp | grep ESTAB | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -rn | head -20
# netstat으로 동일하게 확인
netstat -antp | grep ESTABLISHED | wc -l
실시간 모니터링
# 1초마다 소켓 현황 갱신
watch -n 1 'ss -s'
# ESTABLISHED와 TIME_WAIT만 실시간 추적
watch -n 2 'echo "ESTABLISHED: $(ss -antp | grep ESTAB | wc -l) TIME_WAIT: $(ss -antp | grep TIME-WAIT | wc -l)"'
# 특정 프로세스의 소켓만 확인 (예: nginx PID 5678)
ss -antp | grep 'pid=5678'
TIME_WAIT 상황 진단
# 1. TIME_WAIT 소켓 수 확인
ss -s
# TCP: 2100 (estab 50, closed 2010, orphaned 0, timewait 2010)
# timewait 값이 수천~수만이면 고갈 위험
# 2. 로컬 포트 가용 범위 확인
cat /proc/sys/net/ipv4/ip_local_port_range
# 32768 60999
# 최대 사용 가능한 포트: 60999 - 32768 = 28,231개
# 3. 현재 사용 중인 포트 수
ss -antp | wc -l
# 4. 에러 카운터 확인 (포트 고갈 발생 시 증가)
netstat -s | grep -i "failed\|overflow\|reuse"
커널 파라미터 단계별 튜닝
이 명령은 시스템 설정 파일을 변경합니다. 기존 파일 백업과 적용 후 검증 방법을 준비하지 않으면 재부팅이나 서비스 재시작 때 장애가 반복될 수 있습니다.
# 현재 설정 전체 확인
sysctl -a | grep tcp | grep -E "tw_reuse|fin_timeout|port_range|max_syn"
# --- 단계 1: FIN_WAIT_2 타임아웃 단축 ---
# 기본 60초 → 30초로 단축
sudo sysctl -w net.ipv4.tcp_fin_timeout=30
echo "net.ipv4.tcp_fin_timeout = 30" | sudo tee /etc/sysctl.d/99-tcp.conf
# --- 단계 2: TIME_WAIT 소켓 재사용 허용 ---
# Outbound 연결에서 TIME_WAIT 소켓 재사용 (클라이언트 역할 서버에 적용)
sudo sysctl -w net.ipv4.tcp_tw_reuse=1
echo "net.ipv4.tcp_tw_reuse = 1" | sudo tee -a /etc/sysctl.d/99-tcp.conf
# --- 단계 3: 로컬 포트 범위 확장 ---
# 기본 32768-60999 → 1024-65535로 확장 (약 64,511개)
sudo sysctl -w net.ipv4.ip_local_port_range="1024 65535"
echo "net.ipv4.ip_local_port_range = 1024 65535" | sudo tee -a /etc/sysctl.d/99-tcp.conf
# 설정 적용
sudo sysctl -p /etc/sysctl.d/99-tcp.conf
# 적용 확인
sysctl net.ipv4.tcp_tw_reuse net.ipv4.tcp_fin_timeout net.ipv4.ip_local_port_range
효과 검증
# 튜닝 전후 비교를 위해 현재 TIME_WAIT 수 기록
BEFORE=$(ss -antp | grep TIME-WAIT | wc -l)
echo "튜닝 전 TIME_WAIT: $BEFORE"
# ... 파라미터 설정 ...
# 60초 후 다시 확인
sleep 60
AFTER=$(ss -antp | grep TIME-WAIT | wc -l)
echo "튜닝 후 TIME_WAIT: $AFTER"
CLOSE_WAIT 소켓 존재 확인
# CLOSE_WAIT 소켓 확인
ss -antp | grep CLOSE-WAIT
# 출력 예시
# CLOSE-WAIT 1 0 10.0.0.1:8080 192.168.1.100:54321 users:(("java",pid=12345,fd=42))
# CLOSE-WAIT 1 0 10.0.0.1:8080 192.168.1.101:54322 users:(("java",pid=12345,fd=43))
# CLOSE-WAIT 1 0 10.0.0.1:8080 192.168.1.102:54323 users:(("java",pid=12345,fd=44))
# 개수 집계
CLOSE_WAIT_COUNT=$(ss -antp | grep CLOSE-WAIT | wc -l)
echo "CLOSE_WAIT 소켓 수: $CLOSE_WAIT_COUNT"
# 10개 이상이면 누수 의심
if [ "$CLOSE_WAIT_COUNT" -gt 10 ]; then
echo "경고: CLOSE_WAIT 소켓 누수 의심!"
fi
누수 프로세스 특정
# CLOSE_WAIT 소켓을 가진 프로세스 확인
ss -antp | grep CLOSE-WAIT | grep -oP 'pid=\K[0-9]+' | sort | uniq -c | sort -rn
# 해당 PID의 프로세스 정보 확인
ps aux | grep 12345
# 해당 프로세스의 열린 파일/소켓 수 확인
ls /proc/12345/fd | wc -l
# 수천 개면 소켓 누수 확인
# 어떤 소켓들인지 확인
ls -la /proc/12345/fd | grep socket
애플리케이션 레벨 확인
Java Spring Boot 애플리케이션의 커넥션 풀 상태 확인 예시:
# Actuator가 활성화된 경우 커넥션 풀 통계 조회
curl -s http://localhost:8080/actuator/metrics/hikaricp.connections.active
curl -s http://localhost:8080/actuator/metrics/hikaricp.connections.idle
# JVM 힙 덤프 → 소켓 객체 분석 (심층 분석 시)
jmap -dump:format=b,file=/tmp/heap.hprof 12345
임시 해결책 (서비스 재시작 없이)
이 명령은 실행 중인 서비스 상태를 바꿔 순간적인 중단이나 설정 반영 실패를 만들 수 있습니다. 운영 트래픽 영향과 재시작 후 확인 명령을 먼저 준비하세요.
# CLOSE_WAIT 소켓을 강제로 닫는 방법은 없음 (커널 설계상)
# 유일한 해결책: 애플리케이션이 close()를 호출하도록 수정
# 임시: 해당 프로세스 재시작 (소켓 모두 정리됨)
systemctl restart myapp
# 또는 graceful reload가 지원되면
kill -HUP 12345
증상
# 서버에서 확인: 80 포트 LISTEN 중
ss -tlnp | grep :80
# LISTEN 0 511 127.0.0.1:80 0.0.0.0:* users:(("nginx",pid=5678))
# 외부에서 접속 시 실패
curl http://서버IP/
# curl: (7) Failed to connect to 서버IP port 80: Connection refused
원인 분석
원인: 127.0.0.1에만 바인딩됨
출력에서 Local Address가 127.0.0.1:80이므로 루프백 인터페이스에만 바인딩되어 있습니다. 외부 IP에서는 접근할 수 없습니다.
# 어떤 IP에 바인딩되어 있는지 정확히 확인
ss -tlnp | awk '{print $4}' | grep -v "Local"
# 127.0.0.1:80 ← 외부 접근 불가
# 0.0.0.0:80 ← 모든 인터페이스에서 접근 가능
# [::]:80 ← IPv6 와일드카드 (IPv4 포함되기도 함)
해결 방법
Nginx 설정 수정 — worker_connections와 keepalive 값을 조정합니다.
# /etc/nginx/nginx.conf 또는 /etc/nginx/conf.d/default.conf
server {
# 변경 전
listen 127.0.0.1:80;
# 변경 후 — 모든 인터페이스
listen 0.0.0.0:80;
# 또는 그냥
listen 80;
}
이 명령은 실행 중인 서비스 상태를 바꿔 순간적인 중단이나 설정 반영 실패를 만들 수 있습니다. 운영 트래픽 영향과 재시작 후 확인 명령을 먼저 준비하세요.
# 설정 검증 후 리로드
nginx -t && systemctl reload nginx
# 변경 확인
ss -tlnp | grep :80
# LISTEN 0 511 0.0.0.0:80 0.0.0.0:* users:(("nginx",pid=5678))
방화벽도 함께 확인 — 포트가 열려 있어도 방화벽이 막으면 LISTEN 상태가 의미 없습니다.
이 명령은 방화벽 정책을 변경해 현재 접속 중인 세션이나 운영 트래픽에 즉시 영향을 줄 수 있습니다. 적용 전 허용 대상 IP·포트와 롤백 명령을 확인하세요.
# firewalld
firewall-cmd --list-all | grep 80
# iptables
iptables -L INPUT -n | grep 80
# 방화벽이 차단 중이면 허용
firewall-cmd --permanent --add-port=80/tcp
firewall-cmd --reload
증상
# 서버 로그
[ERROR] bind: address already in use
[ERROR] connect: Cannot assign requested address
# ss로 확인
ss -s
# TCP: 32000 (estab 50, closed 31900, orphaned 0, timewait 31900)
# timewait이 3만 개를 넘어섬
클라이언트 역할을 하는 서버(예: 내부 API 서버가 DB나 외부 API를 반복 호출)에서 자주 발생합니다.
원인
# 로컬 포트 가용 범위 확인
cat /proc/sys/net/ipv4/ip_local_port_range
# 32768 60999 → 최대 28,231개
# TIME_WAIT 소켓이 28,231개를 넘으면 포트 고갈
ss -antp | grep TIME-WAIT | wc -l
# 28500 ← 초과!
연결을 짧게 끊고 새로 맺는 패턴(HTTP keep-alive 미사용, 커넥션 풀 없음)에서 TIME_WAIT가 누적됩니다.
해결 방법
단기 해결 — 커널 파라미터 튜닝 — TIME_WAIT 소켓이 쌓이는 것을 줄이는 즉각적 조치입니다.
이 명령은 시스템 설정 파일을 변경합니다. 기존 파일 백업과 적용 후 검증 방법을 준비하지 않으면 재부팅이나 서비스 재시작 때 장애가 반복될 수 있습니다.
# TIME_WAIT 소켓 재사용
sudo sysctl -w net.ipv4.tcp_tw_reuse=1
# FIN_WAIT_2 타임아웃 단축
sudo sysctl -w net.ipv4.tcp_fin_timeout=30
# 포트 범위 확장
sudo sysctl -w net.ipv4.ip_local_port_range="10000 65535"
# 영구 저장
cat << 'EOF' | sudo tee /etc/sysctl.d/99-tcp-tuning.conf
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.ip_local_port_range = 10000 65535
EOF
sudo sysctl -p /etc/sysctl.d/99-tcp-tuning.conf
근본적 해결 — 애플리케이션 개선 — Connection Pool을 쓰면 소켓 생성 빈도 자체가 줄어듭니다.
# HTTP 클라이언트에서 Keep-Alive 활성화 (연결 재사용)
# curl의 경우
curl --keepalive-time 60 http://internal-api/endpoint
# 애플리케이션 레벨에서 Connection Pool 사용:
# Python requests.Session, Java HikariCP, Node.js http.Agent(keepAlive:true)
모니터링 알림 설정
#!/bin/bash
# /usr/local/bin/check-timewait.sh
THRESHOLD=20000
COUNT=$(ss -antp | grep TIME-WAIT | wc -l)
if [ "$COUNT" -gt "$THRESHOLD" ]; then
echo "TIME_WAIT 경고: 현재 ${COUNT}개 (임계값: ${THRESHOLD})" \
| mail -s "[ALERT] TIME_WAIT 고갈 위험" admin@example.com
fi
# crontab -e
*/5 * * * * /usr/local/bin/check-timewait.sh
심화 — LISTEN 소켓의 Recv-Q/Send-Q가 말해주는 것
심화: accept 큐 넘침 — LISTEN인데도 접속이 튕기는 이유
'LISTEN이면 접속 OK'는 절반만 맞습니다. LISTEN 소켓 뒤에는 커널이 관리하는 두 개의 큐가 있고, 부하가 몰리면 이 큐가 넘쳐 이미 완성된 연결조차 버려집니다. ss -tlnp가 정상으로 보여도 접속이 간헐적으로 튕기는 전형적 원인입니다.
- LISTEN 소켓에는 두 개의 큐가 있습니다: SYN 큐(반연결, SYN_RECV)는 SYN을 받고 SYN-ACK을 보낸 뒤 상대의 ACK를 기다리는 half-open 연결을 담습니다. accept 큐(완성 큐)는 3-way 핸드셰이크가 끝나 애플리케이션이
accept()로 가져가기만 기다리는 완성된 연결을 담습니다. ss -ltn의 두 열이 바로 accept 큐입니다: LISTEN 소켓에서 Recv-Q는 '현재 accept 큐에 쌓여(아직 accept()되지 않은) 대기 중인 완성 연결 수', Send-Q는 'accept 큐의 최대치(backlog)'입니다. Recv-Q가 Send-Q에 닿으면 큐가 꽉 찬 것입니다. (같은 두 열이 ESTABLISHED 소켓에서는 수신·송신 버퍼 바이트를 뜻하니, LISTEN이냐 ESTABLISHED냐로 의미가 달라집니다.)- 큐가 넘치면 완성된 연결이 버려집니다: 커널은 accept 큐가 꽉 차면 완성된 연결을 드랍하거나 리셋합니다. 클라이언트는 타임아웃이나 connection reset을 겪지만, 서버는 멀쩡히 LISTEN 중이라 원인을 놓치기 쉽습니다. accept 루프가 느리거나 워커가 고갈되면 CPU가 남아도 이 현상이 납니다.
- backlog는 두 곳이 함께 정합니다: 앱의
listen(fd, backlog)인자와 커널의net.core.somaxconn중 작은 값이 실제 상한입니다. somaxconn만 올리고 앱 backlog가 낮으면 소용없습니다(반대도 마찬가지). 넘침 여부는nstat -az | grep -i ListenOverflows(또는netstat -s | grep -i listen)의 카운터 증가로 확정합니다.
상황: 평소엔 멀쩡한데 프로모션처럼 트래픽이 튀는 순간 일부 요청이 접속 타임아웃 또는 connection reset을 겪습니다. ss -tlnp로 보면 서비스는 정상 LISTEN, CPU·메모리도 한가한 편이고 방화벽도 손댄 적이 없습니다.
원인: accept 큐(백로그) 넘침입니다. 순간적으로 몰린 연결을 애플리케이션의 accept 루프가 제때 비우지 못했거나 backlog/somaxconn이 너무 작아, 3-way 핸드셰이크까지 끝난 완성 연결이 큐에 쌓이다 넘쳐 커널이 버린 것입니다. 서비스가 '떠 있는 것'과 '연결을 제때 받아 처리하는 것'은 다릅니다.
진단: 부하 시점에 ss -ltn으로 해당 LISTEN 소켓의 Recv-Q가 Send-Q(백로그 상한)에 붙는지 관찰합니다. nstat -az | grep -i ListenOverflows(또는 ListenDrops) 카운터가 부하와 함께 증가하면 넘침 확정입니다. accept 루프가 동기 DNS·블로킹 I/O 같은 초기 처리에 붙잡혀 있지 않은지도 함께 봅니다.
해결: net.core.somaxconn과 애플리케이션의 listen() backlog를 둘 다 상향합니다(둘 중 작은 값이 상한). Nginx는 listen ... backlog=, Node는 server.listen(port, backlog), JVM 서버는 acceptCount/backlog로 조정합니다. 근본은 accept를 지연시키는 느린 초기 처리를 걷어내 큐가 빨리 비도록 하는 것이고, 절대 규모가 문제라면 워커·인스턴스를 늘립니다.
용량 계획과 임계값 설정
운영 서버에서 소켓 상태를 정기적으로 수집하면 서버 용량 계획의 근거가 됩니다.
#!/bin/bash
# /usr/local/bin/socket-metrics.sh
# Prometheus textfile collector 형식으로 메트릭 출력
OUTPUT_FILE="/var/lib/node_exporter/textfile_collector/socket_stats.prom"
ESTAB=$(ss -antp | grep -c ESTAB)
TIMEWAIT=$(ss -antp | grep -c TIME-WAIT)
CLOSEWAIT=$(ss -antp | grep -c CLOSE-WAIT)
LISTEN=$(ss -tlnp | tail -n +2 | wc -l)
cat > "$OUTPUT_FILE" << EOF
# HELP socket_established_total Current ESTABLISHED TCP connections
# TYPE socket_established_total gauge
socket_established_total $ESTAB
# HELP socket_timewait_total Current TIME_WAIT TCP sockets
# TYPE socket_timewait_total gauge
socket_timewait_total $TIMEWAIT
# HELP socket_closewait_total Current CLOSE_WAIT TCP sockets
# TYPE socket_closewait_total gauge
socket_closewait_total $CLOSEWAIT
# HELP socket_listen_total Current LISTEN ports
# TYPE socket_listen_total gauge
socket_listen_total $LISTEN
EOF
실무 점검 체크리스트
서버 신규 오픈 전 점검:
# 1. 의도한 포트만 LISTEN 중인지 확인 (불필요한 포트 차단)
ss -tlnp
# → 모든 LISTEN 포트가 서비스 목적에 부합하는지 리뷰
# 2. 0.0.0.0 vs 127.0.0.1 바인딩 적절성 확인
# → DB(3306), Redis(6379)는 127.0.0.1에만 바인딩되어야 함
# 3. CLOSE_WAIT 소켓 없음 확인
ss -antp | grep CLOSE-WAIT
# → 배포 직후 CLOSE_WAIT가 0이어야 정상
# 4. 동시 접속자 수 베이스라인 측정
ss -antp | grep -c ESTAB
장애 대응 시나리오별 확인 명령
| 장애 신고 | 확인 명령 |
|---|---|
| "서버 접속이 안 돼요" | `ss -tlnp |
| "서버가 느려요" | `ss -antp |
| "주기적으로 연결이 끊겨요" | `ss -antp |
| "새벽마다 장애가 나요" | ss -s로 TIME_WAIT 추이 모니터링 |
| "특정 IP에서만 접속 안 돼요" | `ss -antp |
자격증 및 면접 포인트
- RHCE / LFCS:
ss와netstat명령을 이용한 포트 점검은 필수 실기 항목 - CKA (Kubernetes 관리자): Pod 간 통신 문제 디버깅에
ss를 사용 - 백엔드 개발 면접: TIME_WAIT 원인과
tcp_tw_reuse튜닝, CLOSE_WAIT 코드 버그 진단 능력 - 시스템 설계 면접: ESTABLISHED 소켓 수로 서버 용량을 추정하고 스케일아웃 시점을 결정하는 근거
핵심 명령어 정리
| 명령 | 설명 |
|---|---|
ss -tlnp | LISTEN 중인 TCP 포트와 프로세스 |
ss -antp | 모든 TCP 소켓 상태 |
ss -s | 소켓 요약 통계 |
ss -antp | grep ESTAB | wc -l | 현재 ESTABLISHED 소켓 수 |
ss -antp | grep CLOSE-WAIT | CLOSE_WAIT 소켓 목록 |
netstat -tulnp | LISTEN 포트와 프로세스 (레거시) |
sysctl net.ipv4.tcp_tw_reuse | TIME_WAIT 재사용 설정 확인 |
sysctl net.ipv4.tcp_fin_timeout | FIN_WAIT_2 타임아웃 확인 |
정리
- LISTEN은 연결 대기, ESTABLISHED는 활성 연결, TIME_WAIT는 종료 후 대기, CLOSE_WAIT는 앱이 close()를 아직 호출하지 않은 상태입니다.
ss -antp는 모든 TCP 소켓 상태를 빠르게 확인하는 현대적 도구입니다.- ESTABLISHED 소켓 수가 서버의 실제 동시 접속자 수입니다.
- TIME_WAIT 소켓 폭증은
tcp_tw_reuse=1설정과 Keep-Alive/Connection Pool 사용으로 해결합니다. - CLOSE_WAIT 누수는 커널이 자동 해결하지 않으므로 반드시 코드에서 소켓 close()를 보장해야 합니다.
관련 모듈로 더 깊이:
- ss/lsof로 포트를 점유한 좀비 프로세스 찾아 강제 종료하기 — LISTEN 소켓을 점유한 프로세스를 찾아 안전하게 종료하는 법
- 3-Way Handshake 원리와 신뢰성 높은 포트 체계 —
ss로 보이는 TCP/UDP 포트 상태의 의미를 프로토콜 관점에서 이해하기 - telnet과 nc(netcat) 명령어로 L4 포트 통신 상태 점검 — 내가 본 LISTEN이 외부에서도 실제로 연결되는지 확인하는 법
다음 모듈에서는 ARP 프로토콜 동작 원리와 IP 충돌(중복 IP) 상황을 arping으로 진단하는 방법을 다룹니다.