웹 서버에서 DB 연결 실패가 발생했지만 원인은 한 가지가 아닙니다. DNS, 라우팅, 포트, DB 데몬, 방화벽 중 하나만 놓쳐도 같은 에러처럼 보입니다.
장애 대응은 감으로 명령어를 치는 일이 아닙니다. 계층별로 배제하면서 증거를 쌓아야 합니다.
[종합 실습] 웹→DB 연결 장애 격리
"웹 서버에서 DB 연결이 안 됩니다." 이 한 마디로 시작되는 장애 상황. 어디서부터 봐야 할지 막막할 때 논리적인 장애 격리 방법론이 필요합니다. 이 챕터에서는 ping → nc → ss → ip route 순서로 장애 구간을 좁혀나가는 체계적인 접근법을 익히고, 실제 시나리오를 통해 훈련합니다.
1. 장애 격리 방법론
- 1OSI 레이어 기반 4단계 장애 격리 방법론(ping → nc → ss → ip route)을 적용할 수 있다
- 2책임 구간 분리 원칙에 따라 레이어별 담당 팀에 에스컬레이션할 수 있다
- 3ping 성공/실패로 L3 라우팅 생사를 확인할 수 있다
- 4nc로 L4 포트·방화벽 차단 여부를 검증할 수 있다
- 5ss로 데몬 리스닝 여부를 확인하고 디폴트 게이트웨이 장애 시나리오에 대응할 수 있다
실습 환경의 웹 서버와 DB 서버 IP를 미리 메모해 두세요
ping -c 4 <DB_IP>nc -zv -w 3 <DB_IP> 3306ss -tulnp | grep 3306장애 격리 4단계 사고방식
웹 서버에서 DB 서버로 연결이 안 됩니다. 애플리케이션 로그엔 "Connection timeout"이 찍혀있고, 팀 채널은 "왜 안 되나요?" 로 가득합니다. 방화벽인지, DB가 죽었는지, 네트워크가 끊겼는지, 설정이 잘못됐는지 — 동시에 여러 가설을 갖고 뛰어들면 시간만 낭비됩니다. 하위 레이어부터 차례로 좁혀가는 체계적인 방법이 있어야 원인을 30분 안에 찾을 수 있습니다.
 확대
확대
네트워크 장애를 진단할 때 하위 레이어에서 상위 레이어로 올라가는 원칙을 따릅니다. 하위 레이어가 정상임을 확인해야 상위 레이어 문제라고 단정할 수 있기 때문입니다.
OSI 레이어 기반 4단계 진단 순서
하위 레이어가 정상임을 확인한 뒤에야 상위 레이어 문제라고 단정할 수 있습니다. 아래 흐름이 실무에서 쓰는 순서입니다.
[장애 발생] 웹 서버에서 DB 서버(3306) 연결 불가
1단계: ping DB_IP
↓ 목적: L3(네트워크/라우팅) 생사 확인
↓ 성공 → 2단계로
↗ 실패 → 라우팅/물리 연결 문제 → 네트워크팀 에스컬레이션
2단계: nc -zv DB_IP 3306
↓ 목적: L4(방화벽 + 포트 개방) 확인
↓ 성공 → 애플리케이션 레이어 문제 (인증, SQL 등)
↗ 실패 → 3단계로
3단계: DB서버에서 ss -tulnp | grep 3306
↓ 목적: 데몬 기동 여부 확인
↓ 리스닝 있음 → 방화벽 차단 문제 → 방화벽 정책 점검
↗ 리스닝 없음 → MySQL 데몬 다운 → systemctl start mysqld
4단계: ip route show / cat /etc/resolv.conf
목적: 라우팅 설정 꼬임, DNS 오설정 확인
이 방법론의 핵심 가치
- 재현 가능한 검증: 각 단계가 명확한 명령어와 기대 출력을 가짐
- 책임 구간 분리: L3 문제면 네트워크팀, L4 방화벽이면 보안팀, 데몬이면 서버팀
- 불필요한 재작업 방지: "방화벽부터 열자"가 아니라 문제 위치를 먼저 특정
- 에스컬레이션 근거: "ping은 되는데 nc 3306이 안 됩니다"라는 명확한 정보 제공
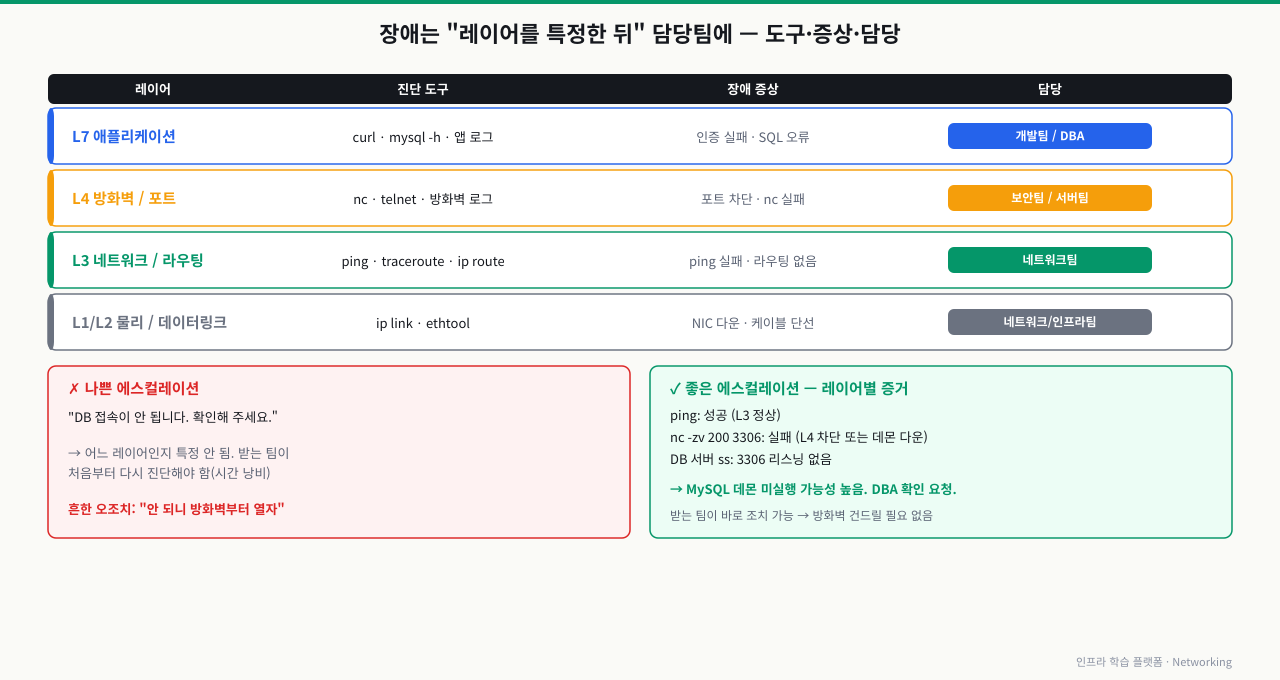
책임 구간 분리 원칙과 레이어별 담당
장애 격리에서 가장 중요한 원칙은 어느 레이어의 문제인지 특정한 뒤 조치하는 것입니다.
레이어마다 진단 도구가 다르고 담당 팀도 다릅니다. "어느 레이어에서 막혔는가"를 특정해야 정확한 팀에 에스컬레이션할 수 있습니다.
 확대
확대
| 레이어 | 진단 도구 | 장애 증상 | 담당 |
|---|---|---|---|
| L1/L2 (물리/데이터링크) | ip link, ethtool | NIC 다운, 케이블 단선 | 네트워크/인프라팀 |
| L3 (네트워크/라우팅) | ping, traceroute, ip route | ping 실패, 라우팅 없음 | 네트워크팀 |
| L4 (방화벽/포트) | nc, telnet, 방화벽 로그 | nc 실패, 포트 차단 | 보안팀/서버팀 |
| L7 (애플리케이션) | mysql -h, curl, 앱 로그 | 인증 실패, SQL 오류 | 개발팀/DBA |
책임 구간 분리 실천 예시
[잘못된 접근]
담당자: "DB 접속이 안 되니 방화벽부터 열겠습니다"
→ 방화벽 열었지만 사실 MySQL이 죽어 있었음
→ 불필요한 보안 정책 변경 발생
[올바른 접근]
담당자: "ping 성공, nc 3306 실패, ss에 3306 없음
→ MySQL 데몬이 죽어 있는 것입니다"
→ systemctl start mysqld 로 즉시 해결
→ 방화벽 건드릴 필요 없음
에스컬레이션 메시지 품질 비교
[나쁜 에스컬레이션]
"DB 접속이 안 됩니다. 확인해 주세요."
[좋은 에스컬레이션]
"웹 서버(192.168.1.100)에서 DB 서버(192.168.1.200)로 연결 실패.
ping: 성공 (L3 정상)
nc -zv 192.168.1.200 3306: 실패 (L4 차단 또는 데몬 다운)
DB 서버 ss 결과: 3306 리스닝 없음
→ MySQL 데몬 미실행 가능성 높음. DBA 확인 요청."
2. 실습: 4단계 장애 격리 수행
# 실습 디렉토리 준비
mkdir -p /tmp/networking/part6/exam_33 && cd /tmp/networking/part6/exam_33
mkdir -p /tmp/networking/part6/isolation && cd /tmp/networking/part6/isolation
cat > scenario.sh << 'EOF'
#!/bin/bash
# 웹→DB 연결 장애 시뮬레이션 환경 구성
echo "=== 장애 시나리오 환경 설정 ==="
# 로컬 mock 서비스 포트 정보
echo "Web layer: :8080 → Backend: :3000 → DB: :5432"
cat > check_layers.sh << 'INNER'
#!/bin/bash
echo "--- Layer 1: DNS ---"
nslookup localhost 2>/dev/null || echo "DNS: using /etc/hosts"
echo "--- Layer 2: Network Reachability ---"
ping -c 1 -W 1 127.0.0.1 &>/dev/null && echo "Loopback: OK" || echo "Loopback: FAIL"
echo "--- Layer 3: Port Check ---"
for port in 8080 3000 5432; do
if nc -z -w1 127.0.0.1 $port 2>/dev/null; then
echo "Port $port: OPEN"
else
echo "Port $port: CLOSED (service not running)"
fi
done
echo "--- Layer 4: HTTP Check ---"
curl -sf --max-time 2 http://127.0.0.1:8080/health && echo "HTTP: OK" || echo "HTTP: not responding"
INNER
chmod +x check_layers.sh
echo "준비 완료. ./check_layers.sh 로 각 레이어 점검 시작"
EOF
chmod +x /tmp/networking/part6/isolation/scenario.sh
- 핵심 출력—명령 결과에서 성공/실패를 가르는 값을 먼저 확인합니다
- 대상 식별—IP, 포트, 인터페이스, 프로세스명처럼 다음 조치를 결정하는 필드를 봅니다
- 다음 분기—결과가 기대와 다르면 어느 계층을 이어서 점검할지 정합니다
가장 먼저 DB 서버에 L3(IP) 레이어로 도달 가능한지 확인합니다. ping이 성공하면 물리 연결, 라우팅, ARP는 모두 정상입니다.
# 웹 서버에서 실행
ping -c 4 192.168.1.200
# 성공 케이스 — L3 정상
# PING 192.168.1.200 (192.168.1.200) 56(84) bytes of data.
# 64 bytes from 192.168.1.200: icmp_seq=1 ttl=64 time=0.412 ms
# 64 bytes from 192.168.1.200: icmp_seq=2 ttl=64 time=0.389 ms
# ...
# 4 packets transmitted, 4 received, 0% packet loss
# → ping 성공 → L3 정상 → 2단계로 진행
# 실패 케이스 — L3 문제
# PING 192.168.1.200 (192.168.1.200) 56(84) bytes of data.
# ...
# 4 packets transmitted, 0 received, 100% packet loss
# → ping 실패 → L3 문제 확인 필요
ping 실패 시 추가 진단
# 라우팅 테이블 확인 — DB IP로 가는 경로 있는지
ip route show
ip route get 192.168.1.200
# 같은 서브넷인데 ping 실패라면 ARP 확인
arp -n | grep 192.168.1.200
# 항목 없음 → ARP 미해석 → 스위치/VLAN 문제
# 다른 서브넷이면 게이트웨이 경로 확인
ip route show | grep default
# default via 192.168.1.1 dev eth0 → 게이트웨이 확인
# 게이트웨이로 ping 테스트
ping -c 2 192.168.1.1
판정 기준
- ping 성공 → "L3 정상, 2단계(L4)로 진행"
- ping 실패 + 같은 서브넷 → "L2/스위치 문제 가능, 네트워크팀 확인"
- ping 실패 + 다른 서브넷 → "게이트웨이/라우팅 문제, 네트워크팀 확인"
ping이 성공했다면 실제 3306 포트로 TCP 연결이 가능한지 확인합니다.
# 웹 서버에서 실행
nc -zv -w 3 192.168.1.200 3306
# 성공 케이스 — 포트 열려 있음
# Connection to 192.168.1.200 3306 port [tcp/mysql] succeeded!
# → L4 정상 → 이 단계에서 문제가 없으면 애플리케이션 레이어(L7) 확인
# 실패 케이스 — 방화벽 차단 (DROP)
# nc: connect to 192.168.1.200 port 3306 (tcp) timed out: Operation now in progress
# → 타임아웃 = 방화벽 DROP → 방화벽 점검
# 실패 케이스 — 포트 닫힘 (REJECT 또는 데몬 없음)
# nc: connect to 192.168.1.200 port 3306 (tcp) failed: Connection refused
# → 즉시 거부 = 포트에 리스닝 없음 → 데몬 확인(3단계)
타임아웃 vs Connection Refused 구분이 중요한 이유
타임아웃 → 방화벽 DROP → DB 서버에서 패킷 자체를 못 받음
→ 방화벽 담당자에게 "3306 인바운드 허용" 요청
Connection Refused → 패킷은 DB 서버에 도달함 → DB 서버 OS가 거부
→ 데몬이 없거나 다른 바인딩 주소 → 3단계로 진행
여러 포트 한번에 점검
# MySQL 기본 포트 외 다른 포트도 확인
for port in 3306 33060 33061; do
echo -n "포트 $port: "
nc -zv -w 3 192.168.1.200 $port 2>/dev/null && echo "열림" || echo "닫힘"
done
nc가 실패했을 때 DB 서버에 직접 접속해 MySQL 프로세스가 3306 포트에서 리스닝 중인지 확인합니다.
# DB 서버에서 실행
ss -tulnp | grep 3306
# 정상 케이스 — MySQL 리스닝 중
# tcp LISTEN 0 128 0.0.0.0:3306 0.0.0.0:* users:(("mysqld",pid=1234,fd=21))
# → 데몬 정상 기동 → 방화벽이 차단 중인 것
# 문제 케이스 — 아무 출력 없음
# (출력 없음)
# → MySQL 데몬 미실행 → 서비스 시작 필요
# 문제 케이스 — 루프백에만 바인딩
# tcp LISTEN 0 128 127.0.0.1:3306 0.0.0.0:*
# → 바인딩 주소 문제 → bind-address = 0.0.0.0 으로 변경 필요
데몬 미실행 시 복구
이 명령은 실행 중인 서비스 상태를 바꿔 순간적인 중단이나 설정 반영 실패를 만들 수 있습니다. 운영 트래픽 영향과 재시작 후 확인 명령을 먼저 준비하세요.
# MySQL 상태 확인
systemctl status mysqld
# MySQL 시작
systemctl start mysqld
# 시작 후 리스닝 확인
ss -tulnp | grep 3306
# 자동 시작 설정
systemctl enable mysqld
# 시작 실패 시 오류 로그 확인
journalctl -u mysqld -n 50
# 또는
tail -50 /var/log/mysqld.log
tail -50 /var/log/mysql/error.log
포트는 리스닝 중인데 nc가 타임아웃인 경우 — 방화벽 확인
이 명령은 방화벽 정책을 변경해 현재 접속 중인 세션이나 운영 트래픽에 즉시 영향을 줄 수 있습니다. 적용 전 허용 대상 IP·포트와 롤백 명령을 확인하세요.
# DB 서버에서 방화벽 규칙 확인
firewall-cmd --list-all # CentOS
ufw status verbose # Ubuntu
iptables -L INPUT -n -v | grep 3306
# 방화벽에 3306 추가 (CentOS)
firewall-cmd --zone=public --add-port=3306/tcp --permanent
firewall-cmd --reload
앞선 3단계로 해결이 안 되거나, 간헐적 장애 또는 특정 방향만 안 되는 복잡한 상황에서는 라우팅과 DNS 설정을 확인합니다.
이 명령은 서버의 라우팅 또는 인터페이스 설정을 바꿔 원격 접속이 끊길 수 있습니다. 콘솔 접근과 현재 라우팅 백업을 확보한 뒤 실행하세요.
# [라우팅 확인]
# 웹 서버에서 DB 서버로 가는 경로 확인
ip route show
# 기대 출력:
# default via 192.168.1.1 dev eth0 ← 기본 게이트웨이
# 192.168.1.0/24 dev eth0 proto kernel ← 로컬 서브넷
ip route get 192.168.1.200
# 192.168.1.200 dev eth0 src 192.168.1.100 ← 직접 연결
# 또는
# 192.168.1.200 via 10.0.0.1 dev eth0 ← 게이트웨이 경유
# 비정상 케이스 — 기본 게이트웨이 없음
ip route show | grep default
# (아무 출력 없음)
# → 기본 게이트웨이 누락 → 다른 서브넷으로 못 감
# 게이트웨이 임시 추가
ip route add default via 192.168.1.1 dev eth0
# 영구 설정 (CentOS — /etc/sysconfig/network-scripts/ifcfg-eth0)
# GATEWAY=192.168.1.1
# 영구 설정 (nmcli)
nmcli connection modify eth0 ipv4.gateway 192.168.1.1
nmcli connection up eth0
# [DNS 확인]
cat /etc/resolv.conf
# nameserver 8.8.8.8 ← DNS 서버
# search company.com ← 도메인 검색 접미사
# DNS로 DB 서버 이름 해석 테스트
nslookup db.internal
dig db.internal
# 호스트명으로 접속 시 IP 매핑 확인
cat /etc/hosts | grep db
# 192.168.1.200 db.internal ← /etc/hosts에 직접 등록
3. 롤플레잉 시나리오
상황: 웹 서버를 새 서버로 이전 후 DB 연결 장애 발생
환경:
웹 서버: 192.168.1.100 (신규)
DB 서버: 192.168.1.200
단계별 진단 실행
# 웹 서버에서 실행
# 1단계: ping
ping -c 3 192.168.1.200
# 64 bytes from 192.168.1.200: icmp_seq=1 ttl=64 time=0.4 ms
# → ping 성공 ✓ L3 정상
# 2단계: nc
nc -zv -w 3 192.168.1.200 3306
# nc: connect to 192.168.1.200 port 3306 (tcp) timed out
# → 타임아웃! → 방화벽 DROP 의심
# 3단계: DB 서버에서 ss 확인 (DB 서버 로그인 후)
ss -tulnp | grep 3306
# tcp LISTEN 0 128 0.0.0.0:3306 0.0.0.0:*
# → 데몬 정상 리스닝 ✓
# 방화벽 확인
firewall-cmd --list-all
# ports: 22/tcp ← 3306이 없다!
# 진단 결론: DB 서버 방화벽에서 3306이 차단됨
# 단, 예전 웹 서버(구 IP)는 rich rule로 허용되어 있었을 수 있음
firewall-cmd --list-rich-rules
# rule family="ipv4" source address="192.168.1.50" port port="3306" protocol="tcp" accept
# → 192.168.1.50(구 웹 서버)만 허용, 신규 192.168.1.100은 없음!
해결
이 명령은 방화벽 정책을 변경해 현재 접속 중인 세션이나 운영 트래픽에 즉시 영향을 줄 수 있습니다. 적용 전 허용 대상 IP·포트와 롤백 명령을 확인하세요.
# DB 서버에서 신규 웹 서버 IP 허용 추가
firewall-cmd --zone=public \
--add-rich-rule='rule family="ipv4" source address="192.168.1.100" port protocol="tcp" port="3306" accept' \
--permanent
firewall-cmd --reload
# 웹 서버에서 연결 재테스트
nc -zv -w 3 192.168.1.200 3306
# Connection to 192.168.1.200 3306 port [tcp/mysql] succeeded!
상황: 새벽 정기 배치 작업 후 오전에 웹 서비스 DB 연결 오류 발생
# 웹 서버에서 단계별 진단
# 1단계: ping
ping -c 3 192.168.1.200
# 64 bytes from ... time=0.3 ms
# → ping 성공 ✓
# 2단계: nc
nc -zv -w 3 192.168.1.200 3306
# nc: connect to 192.168.1.200 port 3306 (tcp) failed: Connection refused
# → 즉시 거부! → DROP이 아니라 REJECT → 포트에 아무것도 없음
# 3단계: DB 서버에서 ss 확인
ss -tulnp | grep 3306
# (출력 없음)
# → MySQL이 전혀 리스닝하지 않음!
# MySQL 서비스 상태 확인
systemctl status mysqld
# ● mysqld.service - MySQL Server
# Loaded: loaded (/usr/lib/systemd/system/mysqld.service)
# Active: failed (Result: exit-code) since Mon 2024-01-15 03:42:11
# ...
# → 오전 3시 42분에 MySQL이 비정상 종료됨
# MySQL 오류 로그 확인
journalctl -u mysqld --since "2024-01-15 03:00:00" -n 50
# InnoDB: Table space file './ib_logfile0' size ...
# InnoDB: Could not find a valid checkpoint
# → 디스크 꽉 참으로 인한 InnoDB 손상 의심
해결
이 명령은 실행 중인 서비스 상태를 바꿔 순간적인 중단이나 설정 반영 실패를 만들 수 있습니다. 운영 트래픽 영향과 재시작 후 확인 명령을 먼저 준비하세요.
# 디스크 확인
df -h
# /dev/sda1 100G 100G 0 100% / ← 꽉 참!
# 먼저 삭제 대상 목록만 확인하고 보존 정책·백업 여부를 검토합니다.
find /var/log -xdev -type f -name "*.log" -mtime +30 -print
# 승인한 파일만 별도 절차로 정리합니다. journalctl vacuum도 오래된 로그를 삭제하므로
# 중앙 수집과 보존 기간을 확인한 뒤 실행하세요.
journalctl --vacuum-time=7d
# 공간 확보 후 MySQL 시작
systemctl start mysqld
# 시작 확인
ss -tulnp | grep 3306
# tcp LISTEN 0 128 0.0.0.0:3306 0.0.0.0:* ← 복구됨
# 웹 서버에서 연결 확인
nc -zv -w 3 192.168.1.200 3306
# Connection to 192.168.1.200 3306 port [tcp/mysql] succeeded!
상황: 네트워크 설정 변경 후 일부 서버에서 DB 접속 불가. 웹 서버와 DB 서버가 서로 다른 서브넷에 있는 경우.
환경:
웹 서버: 10.0.1.100/24 (서브넷 A)
DB 서버: 10.0.2.200/24 (서브넷 B — 다른 서브넷!)
게이트웨이: 10.0.1.1
# 웹 서버에서 단계별 진단
# 1단계: ping
ping -c 3 10.0.2.200
# PING 10.0.2.200 (10.0.2.200) 56(84) bytes of data.
# ...
# 3 packets transmitted, 0 received, 100% packet loss
# → ping 실패! → L3 문제
# 같은 서브넷은 되는지 확인
ping -c 2 10.0.1.1 # 게이트웨이
# 64 bytes from 10.0.1.1 ... → 게이트웨이 ping 성공
ping -c 2 10.0.1.50 # 같은 서브넷의 다른 서버
# 64 bytes from 10.0.1.50 ... → 같은 서브넷 ping 성공
# 다른 서브넷(10.0.2.x)만 안 됨 → 라우팅 문제
# 4단계: 라우팅 테이블 확인
ip route show
# 10.0.1.0/24 dev eth0 proto kernel
# (default 항목 없음! 또는 게이트웨이가 다른 IP로 설정됨)
# → 기본 게이트웨이 누락!
ip route get 10.0.2.200
# RTNETLINK answers: Network is unreachable
# → 경로 없음 확인됨
# 라우팅 이력 확인
ip route show table all
journalctl -u NetworkManager --since "1 hour ago" | grep gateway
해결
이 명령은 서버의 라우팅 또는 인터페이스 설정을 바꿔 원격 접속이 끊길 수 있습니다. 콘솔 접근과 현재 라우팅 백업을 확보한 뒤 실행하세요.
# 현재 설정된 게이트웨이 확인 (영구 설정 파일)
# CentOS
cat /etc/sysconfig/network-scripts/ifcfg-eth0 | grep GATEWAY
# (설정 없음 또는 잘못된 IP)
# nmcli로 확인
nmcli connection show eth0 | grep gateway
# 임시 게이트웨이 추가 (즉시 적용)
ip route add default via 10.0.1.1 dev eth0
# ping 재테스트
ping -c 3 10.0.2.200
# 64 bytes from 10.0.2.200 ... → 복구됨!
# 영구 적용
nmcli connection modify eth0 ipv4.gateway 10.0.1.1
nmcli connection up eth0
# DB 접속 최종 확인
nc -zv -w 3 10.0.2.200 3306
# Connection to 10.0.2.200 3306 port [tcp/mysql] succeeded!
4. 장애 사례 분석
증상
웹 개발자 신고: "DB 연결 오류납니다. jdbc:mysql://db.internal:3306"
단계별 진단
# 웹 서버에서
ping db.internal # 성공 (DNS 해석 + L3 정상)
nc -zv -w 3 db.internal 3306
# timed out (타임아웃 — 방화벽 DROP)
# DB 서버에서
ss -tulnp | grep 3306
# (아무 출력 없음 — MySQL도 죽어 있음)
# 방화벽 상태
firewall-cmd --list-ports
# 22/tcp (3306 없음)
분석
두 가지 문제가 동시 발생:
- MySQL 데몬 다운
- 방화벽에서 3306 미허용
타임아웃이 나타난 이유: 방화벽이 DROP하므로 MySQL 데몬 상태와 무관하게 타임아웃.
해결 순서
이 명령은 방화벽 정책을 변경해 현재 접속 중인 세션이나 운영 트래픽에 즉시 영향을 줄 수 있습니다. 적용 전 허용 대상 IP·포트와 롤백 명령을 확인하세요.
# 1. MySQL 시작
systemctl start mysqld
# 2. 방화벽 3306 허용
firewall-cmd --zone=public --add-port=3306/tcp --permanent
firewall-cmd --reload
# 3. 최종 확인
ss -tulnp | grep 3306
nc -zv -w 3 db.internal 3306
교훈: 장애는 단일 원인이 아닐 수 있습니다. 각 단계를 모두 검증한 후 모든 문제를 확인하고 한꺼번에 해결해야 같은 작업을 반복하지 않습니다.
증상
# 웹 서버에서
ping 192.168.1.200 # 성공
nc -zv -w 3 192.168.1.200 3306 # 성공
# 그런데 앱 서버 로그
# Access denied for user 'appuser'@'192.168.1.100' (using password: YES)
원인 분석
L3, L4 레이어는 모두 정상입니다. MySQL의 사용자 권한 문제입니다 — L7 레이어.
# DB 서버에서 MySQL 접속
mysql -u root -p
mysql> SELECT user, host FROM mysql.user WHERE user = 'appuser';
# +----------+-----------+
# | user | host |
# +----------+-----------+
# | appuser | localhost | ← localhost만 허용!
# +----------+-----------+
# 192.168.1.100(웹 서버)에서의 접속 권한이 없음
해결
# MySQL에서 외부 접속 권한 추가
mysql> CREATE USER 'appuser'@'192.168.1.100' IDENTIFIED BY 'yourpassword';
mysql> GRANT SELECT, INSERT, UPDATE, DELETE ON appdb.* TO 'appuser'@'192.168.1.100';
mysql> FLUSH PRIVILEGES;
# 또는 서브넷 전체 허용
mysql> CREATE USER 'appuser'@'192.168.1.%' IDENTIFIED BY 'yourpassword';
교훈: L3~L4 점검만으로 충분하지 않은 경우도 있습니다. "연결은 되지만 거부됨"은 L7(애플리케이션) 레이어 문제입니다. 장애 격리 4단계를 끝까지 수행하되, 앱 로그의 오류 메시지를 꼼꼼히 읽는 습관이 중요합니다.
심화 — 격리 테스트는 통과하는데 부하 때만 끊길 때
심화: conntrack 테이블 포화 — 계층 격리의 사각지대
계층별 격리는 강력하지만 한 가지 사각이 있습니다. ping·nc 같은 프로브는 '한 번, 저부하'로 쏘는 단발 검사라, 부하가 있을 때만 나타나는 상태 기반(stateful) 문제를 놓칩니다. 그 대표가 커널의 연결 추적 테이블 포화입니다.
- stateful 방화벽은 모든 연결을 추적합니다: Linux netfilter(iptables/nftables)의 상태 추적(conntrack)은 통과하는 모든 연결을 커널 테이블(
nf_conntrack)에 기록해 '응답 패킷은 자동 허용' 같은 상태 규칙을 구현합니다. 이 테이블에는 상한net.netfilter.nf_conntrack_max가 있습니다. - 테이블이 차면 새 연결이 조용히 드랍됩니다: 초당 새 연결 수가 많거나(마이크로서비스 폭주·헬스체크 폭풍) TIME_WAIT류 항목이 오래 남으면 테이블이 상한에 닿고, 커널은 새 연결의 첫 패킷(SYN)을 드랍하며
dmesg에nf_conntrack: table full, dropping packet을 남깁니다. 방화벽 규칙은 그대로 '허용'인데도 연결이 안 됩니다. - 왜 격리 테스트로 안 잡히나:
ping·nc -zv는 한두 개의 저부하 프로브라 테이블에 여유가 생기는 순간엔 통과합니다. 그래서 '테스트는 되는데 실서비스만 간헐적으로 끊기는' 착시가 생깁니다 — 계층은 다 정상으로 보이지만 문제는 '상태 테이블 용량'이라는 다른 축에 있습니다. - 확인·대응:
/proc/sys/net/netfilter/nf_conntrack_count를..._max와 비교해 포화도를 보고,dmesg | grep conntrack으로 드랍 로그를 확인합니다. 대응은nf_conntrack_max상향과nf_conntrack_tcp_timeout_*·TIME_WAIT 계열 타임아웃 단축, 또는 추적이 불필요한 대량 트래픽에NOTRACK적용입니다. 근본은 연결 재사용(keep-alive·커넥션 풀)으로 초당 새 연결 수를 줄이는 것입니다.
상황: 평소엔 멀쩡한 웹→DB(또는 API 게이트웨이) 연결이 트래픽 피크에만 일부 요청에서 connection timeout으로 실패합니다. 장애 격리 4단계(ping→nc→ss→앱)를 그 순간에 돌려도 전부 정상이고, 방화벽 규칙도 3306 허용 그대로입니다.
원인: 방화벽/게이트웨이 노드의 conntrack 테이블 포화입니다. 피크에 초당 새 연결이 폭증해 nf_conntrack 테이블이 nf_conntrack_max에 닿았고, 커널이 새 연결의 SYN을 드랍한 것입니다. 격리 프로브는 저부하 단발이라 그 틈에 통과해 '정상'으로 보였을 뿐입니다.
진단: 피크 시점에 cat /proc/sys/net/netfilter/nf_conntrack_count를 nf_conntrack_max와 비교합니다(사용률이 상한에 근접하면 위험). dmesg -T | grep -i conntrack에 table full, dropping packet이 찍혔는지, conntrack -S의 drop·insert_failed 카운터가 증가하는지 확인합니다. 어느 노드가 상태를 추적하는지(방화벽·NAT 게이트웨이·k8s 노드)를 짚는 게 관건입니다.
해결: 즉시는 sysctl -w net.netfilter.nf_conntrack_max= 상향과 nf_conntrack_tcp_timeout_time_wait·..._established 등 타임아웃 단축으로 항목 회전을 빠르게 합니다. 근본은 애플리케이션이 연결을 재사용(HTTP keep-alive·DB 커넥션 풀)하도록 해 초당 새 연결 수를 줄이는 것입니다. 대량의 무상태 트래픽은 raw 테이블 NOTRACK으로 추적에서 제외할 수 있습니다. 격리 테스트에 '부하가 있을 때 반복 측정' 관점을 더하면 이런 상태 기반 문제도 걸립니다.
5. 실무 현장 관점
실무 현장에서의 장애 격리 습관
경험 많은 인프라 엔지니어들은 장애 신고를 받으면 무작정 "재시작해 보자"나 "방화벽 열어 보자"부터 하지 않습니다.
[시니어 엔지니어의 사고 흐름]
신고 접수: "DB 연결 안 됨"
↓
"언제부터? 변경 사항 있었나?" → 장애 시각 특정
↓
"ping부터 확인" → L3 결과 확인
↓
"nc로 포트 확인" → L4 결과 확인
↓
(결과에 따라) "DB 서버 ss 확인" 또는 "방화벽 확인"
↓
근본 원인(Root Cause) 특정 → 조치 → 재발 방지
장애 대응 중 기록 습관
# 실시간으로 기록하며 진단 (임시 파일)
exec > >(tee -a /tmp/incident-$(date +%Y%m%d-%H%M%S).log) 2>&1
echo "=== 장애 조사 시작: $(date) ==="
echo "신고 내용: 웹→DB 연결 불가"
echo "[1] ping 테스트"
ping -c 4 192.168.1.200
echo "[2] nc 포트 테스트"
nc -zv -w 3 192.168.1.200 3306
echo "[3] 라우팅 확인"
ip route show
# 이렇게 기록해 두면 사후 장애 보고서 작성이 쉬워짐
장애 보고서(Post-Mortem)에 포함되는 항목
- 장애 발생 시각 및 복구 시각 (분 단위)
- 영향 범위 (어떤 서비스, 몇 명의 사용자)
- 발견 경위 (자동 알림? 사용자 신고?)
- 진단 과정 (어떤 명령어로 원인을 찾았는지)
- 근본 원인 (방화벽 미설정, 디스크 부족, 게이트웨이 날아감 등)
- 조치 내용 (무엇을 어떻게 해결했는지)
- 재발 방지 (모니터링 추가, 자동화, 문서화 등)
커리어 관점에서
장애 격리 능력은 주니어와 시니어를 구분하는 핵심 역량 중 하나입니다. 논리적인 진단 과정을 문서화해서 보여줄 수 있는 엔지니어는 팀에서 신뢰를 얻습니다. 이 챕터의 4단계 방법론을 실제 장애 상황에서 반복 훈련하면 자연스럽게 몸에 배게 됩니다.
6. 장애 격리 4단계 명령어 요약
| 단계 | 목적 | 명령어 | 성공 기준 |
|---|---|---|---|
| 1단계 | L3 라우팅 확인 | ping -c 4 [DB_IP] | 0% packet loss |
| 2단계 | L4 방화벽+포트 | nc -zv -w 3 [DB_IP] 3306 | succeeded! |
| 3단계 | 데몬 기동 확인 | ss -tulnp | grep 3306 | 리스닝 항목 있음 |
| 4단계 | 라우팅/DNS 설정 | ip route show + cat /etc/resolv.conf | default via 항목 있음 |
추가 진단 명령어
| 목적 | 명령어 |
|---|---|
| 특정 IP로 가는 경로 확인 | ip route get [IP] |
| DNS 이름 해석 | nslookup [호스트명] |
| 게이트웨이 임시 추가 | ip route add default via [GW_IP] dev eth0 |
| MySQL 재시작 | systemctl start mysqld |
| 방화벽 3306 허용 (CentOS) | firewall-cmd --add-port=3306/tcp --permanent && firewall-cmd --reload |
정리
- 장애 격리는 L3(ping) → L4(nc) → L7(ss/앱 로그) 순서로 올라간다
- ping 성공 + nc 타임아웃 = 방화벽 DROP
- ping 성공 + nc Connection Refused = 포트에 리스닝 없음
- ss에 3306 없음 = 데몬 미실행 → systemctl start mysqld
ip route show에 default 없음 = 게이트웨이 누락 → 라우팅 추가- 책임 구간 분리: 정확한 레이어 특정 후 해당 담당자에게 에스컬레이션
- 진단 과정을 기록하는 습관이 사후 보고서와 팀 신뢰를 만든다
관련 모듈로 더 깊이:
- ping과 ICMP 프로토콜을 이용한 초동 경로 진단 — L3 도달성 확인의 첫 단계인 ICMP 진단을 정밀하게 다루는 법
- telnet과 nc(netcat) 명령어로 L4 포트 통신 상태 점검 — L4 단계에서 Refused/Timeout을 구분하는 포트 점검 도구
- netstat과 ss 명령어로 커넥션 상태(ESTABLISHED 등) 분석 — 데몬이 실제로 LISTEN 중인지
ss로 확인하는 법
다음 모듈에서는 Docker/Kubernetes 컨테이너 환경의 네트워크 디버깅 — veth, 브리지, CNI 플러그인 장애를 다룹니다.