새벽 3시, 사용자들이 "느리다"고 항의하는데 대시보드는 평온합니다. 알고 보니 알림이 50개나 걸려 있어 다들 무시하던 와중에 진짜 신호가 묻혔습니다. 며칠 뒤엔 누군가 운영 계정에서 보안그룹을 열었는데 "누가 했는지" 기록이 없습니다. 보이지 않으면 고칠 수 없고, 통제하지 않으면 누구나 사고를 낼 수 있습니다. 관측과 거버넌스는 클라우드 운영의 안전망입니다.
- 1지표·로그·추적이 각각 무엇을 보여주는지 구분할 수 있다
- 2실행 가능한 알림을 적게 거는 원칙을 안다
- 3멀티계정과 가드레일로 사고 범위를 제한하는 법을 이해한다
- 4감사 추적의 역할과 보호 필요성을 안다
- 5이 트랙의 조각들이 하나의 운영 체계로 이어짐을 본다
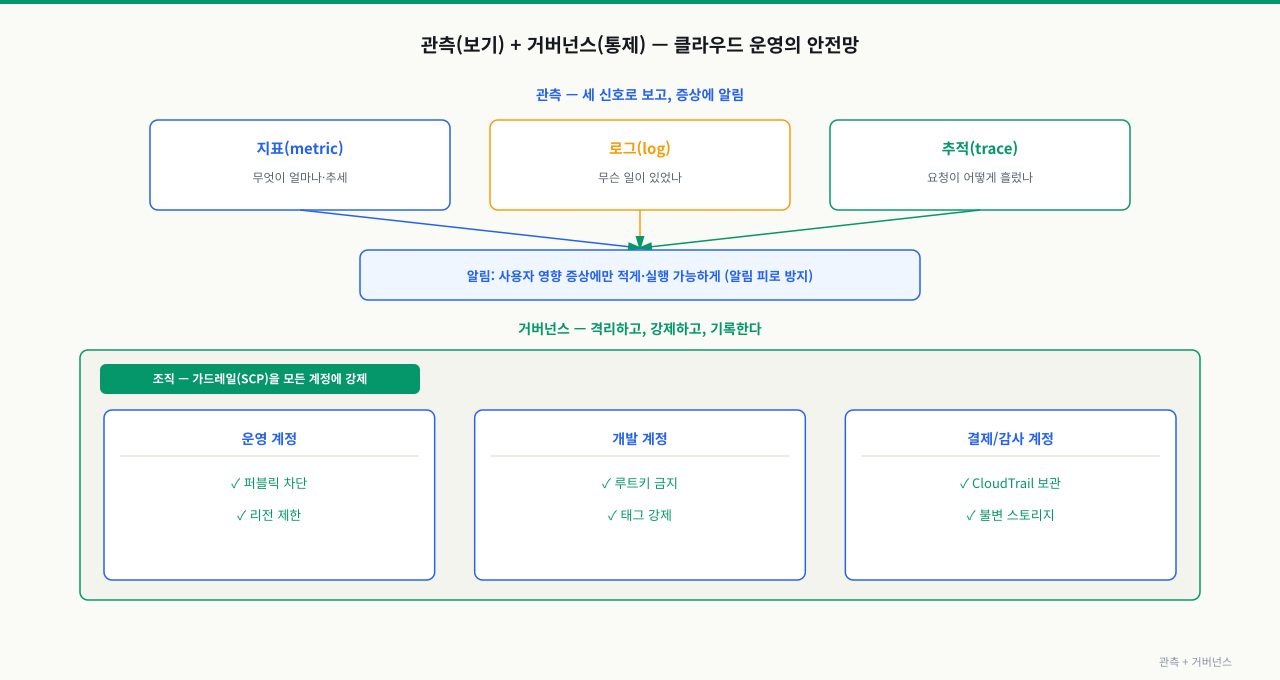
보기 — 관측의 세 신호
지표·로그·추적 — 함께 봐야 원인까지
- 지표(metric): CPU·요청수·지연·에러율 같은 수치 추세. '이상이 있다'를 빠르게 감지. 알림의 근거.
- 로그(log): 그 시점의 상세 이벤트. '무슨 일이 있었나'.
- 추적(trace): 한 요청이 여러 서비스를 거친 경로·구간별 지연. '어디서 느렸나'(특히 MSA 모놀리식 vs 마이크로서비스).
지표로 알아채고, 로그·추적으로 원인을 좁힙니다. 클라우드는 CloudWatch(지표·로그) 등으로 이를 기본 제공하고, 표준 도구(Prometheus/Grafana)도 연동됩니다(Kubernetes 트랙의 관측과 동일 철학).
알림은 적게, 실행 가능하게
"모든 지표에 알림"은 곧 알림 피로로 이어져 진짜 장애를 놓치게 합니다. 좋은 알림은:
- 증상 중심: 사용자 영향이 있는 것(에러율↑, 지연↑, 가용성↓)에 페이징
- 원인 지표는 대시보드로: CPU 70% 같은 건 알림 말고 차트로
- 실행 가능: 받으면 '무엇을 할지' 분명한 것만
이는 SLO·에러버짓·포스트모템의 'SLO 위반 시 알림' 원칙과 직접 연결됩니다.
 확대
확대
 확대
위 그림처럼 지표는 '무엇이 비정상인지', 로그는 '왜 그런지', 추적은 '어디서 느린지'를 각각 담당합니다. 세 신호를 함께 봐야 장애 원인까지 연결됩니다.
확대
위 그림처럼 지표는 '무엇이 비정상인지', 로그는 '왜 그런지', 추적은 '어디서 느린지'를 각각 담당합니다. 세 신호를 함께 봐야 장애 원인까지 연결됩니다.
신호 하나가 대응으로 이어지기까지 — 방출부터 자동 조치까지 6단계
대시보드가 비어 있거나 알람이 안 울릴 때 "관측이 안 된다"고 뭉뚱그리면 고칠 수 없습니다. 리소스가 낸 신호 한 줄이 실제 대응으로 이어지려면 방출 → 수집 → 평가 → 알림 → 조치 → 회고가 순서대로 성립해야 하고, 어느 칸에서 끊겼는지를 알면 "왜 안 보이지"를 단계로 좁힐 수 있습니다.
[리소스] EC2·앱·로드밸런서·DB
│ ① 방출(emit): 메트릭(수치)·로그(이벤트)·트레이스(요청 경로)를 낸다
▼
[수집] 에이전트/SDK → (IAM 권한) → CloudWatch Logs·Metrics / X-Ray
│ ② 집계(collect): 신호를 모아 저장·시계열화
▼
[평가] 대시보드 시각화 + 알람이 임계값을 주기적으로 평가
│ ③ 판정(evaluate): 예) p99 지연 > 500ms 가 5분 지속되나?
▼
[알림] 임계 위반 → SNS → PagerDuty·Slack·이메일로 라우팅
│ ④ 통지(notify): '증상'에 건 알람만 사람을 깨운다
▼
[조치] 오토스케일 정책 발동 · Lambda 자동 복구
│ ⑤ 대응(act): 또는 사람이 로그·트레이스로 원인을 좁힘
▼
[회고] ⑥ 사후 분석 → 알람 임계·런북 갱신 → 다시 ①로
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① 방출 | 리소스가 메트릭·로그·트레이스를 낸다. 커스텀 지표는 앱이 직접 코드로 내보내야 함 | 계측 코드·앱 로깅이 없음 → 애초에 신호가 없어 뒤 단계가 전부 공백 |
| ② 수집 | 에이전트/SDK가 신호를 수집 서비스로 전송·집계. logs:PutLogEvents 같은 IAM 권한 필요 | 에이전트 미설치·IAM 권한 부족 → 콘솔에 no data, 대시보드가 빈다(가장 흔한 오인 지점) |
| ③ 평가 | 대시보드로 보이고, 알람이 임계값을 주기 평가. 지속시간(for) 조건으로 순간 스파이크 무시 | 원인 지표(CPU)에 걸거나 기간 조건 없음 → 오탐 폭주 / 데이터 공백 시 INSUFFICIENT_DATA |
| ④ 알림 | 임계 위반을 SNS 등으로 담당자·채널에 라우팅 | 구독·라우팅 미설정 → 알람은 ALARM인데 아무도 못 받음('울렸는데 조용') |
| ⑤ 조치 | 오토스케일·함수로 자동 대응하거나, 사람이 로그·트레이스로 원인을 좁힘 | 트레이스 전파 헤더 누락 → 구간이 끊겨 '어디서 느린지' 못 짚음 |
| ⑥ 회고 | 사후 분석으로 임계·런북·대시보드를 갱신해 다음을 개선 | 회고 없음 → 같은 알람 반복, 알림 피로 누적 |
즉 "관측이 대응으로 이어진다"는 여섯 칸이 모두 이어졌다는 뜻입니다. 대시보드가 비어 있다면 ①②(계측·수집 권한), 알람이 안 울리거나 너무 울린다면 ③(대상 지표·임계·기간), 울렸는데 아무도 모른다면 ④(라우팅), 어디가 느린지 못 짚는다면 ⑤의 트레이스 전파를 먼저 의심합니다 — 뒤의 비용 심화에서 보듯 이 신호들은 공짜가 아니므로, '많이'가 아니라 '답할 수 있게' 남기는 것이 원칙입니다.
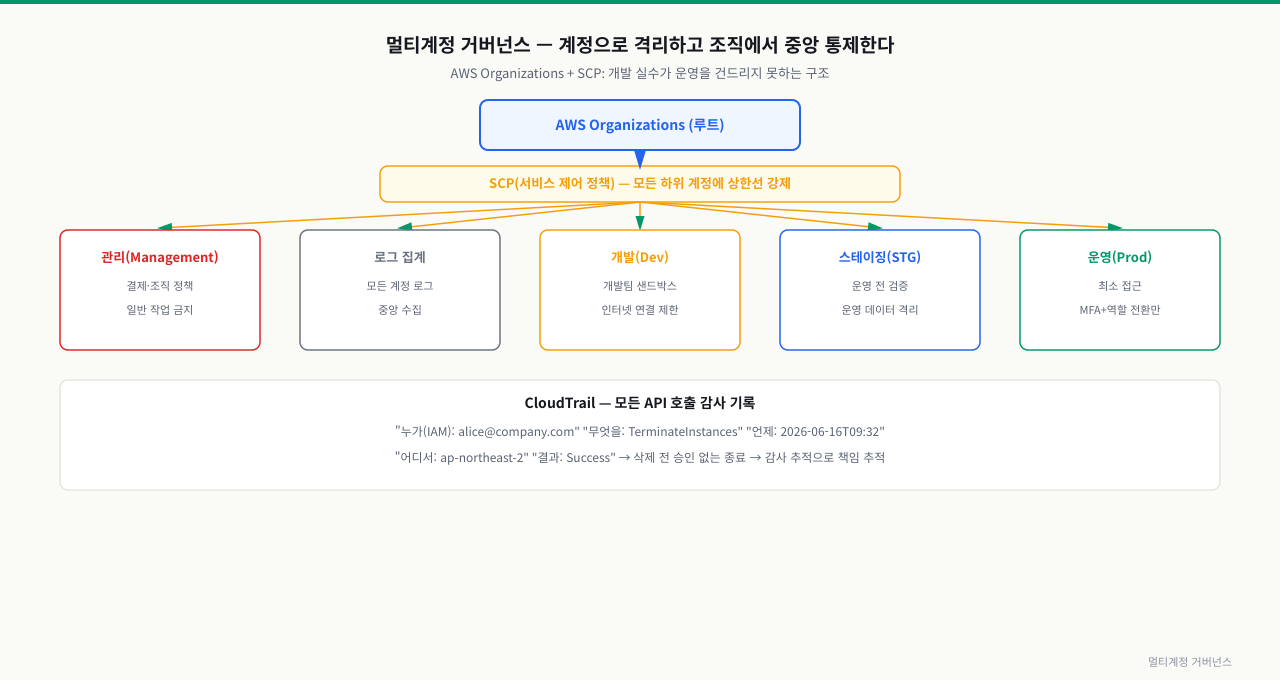
통제 — 멀티계정과 가드레일
계정으로 격리하고, 중앙에서 강제한다
조직이 커지면 단일 계정에 모든 걸 넣는 건 위험합니다. 한 실수가 전체로 번지고(blast radius), 권한 분리가 어렵습니다.
멀티계정은 운영/개발/결제 등을 별도 계정으로 격리해 사고 범위를 제한합니다. 동시에 중앙(조직)에서 가드레일(SCP 등) 로 정책을 모든 계정에 일괄 강제합니다:
- 허용되지 않은 리전 사용 금지(데이터 주권 IaaS·PaaS·SaaS와 리전·AZ)
- 퍼블릭 S3 버킷 생성 금지(오브젝트·블록·파일 스토리지)
- 루트 액세스 키 생성 금지(계정과 IAM)
- 필수 태그 없으면 생성 차단(클라우드 비용 최적화)
개별 계정의 실수를 사전에 막는 안전망입니다.
 확대
위 그림처럼 AWS Organizations 아래 계정을 역할별로 격리하고, SCP로 모든 계정에 가드레일을 일괄 강제합니다. CloudTrail은 모든 API 호출을 감사합니다.
확대
위 그림처럼 AWS Organizations 아래 계정을 역할별로 격리하고, SCP로 모든 계정에 가드레일을 일괄 강제합니다. CloudTrail은 모든 API 호출을 감사합니다.
감사 추적 — 누가 무엇을 바꿨나
감사 추적(CloudTrail 등) 은 '누가 언제 어떤 API로 무엇을 바꿨는지'를 기록합니다. 침해 조사, 변경 추적, 컴플라이언스에 필수입니다. 단, 이 로그가 지워지거나 변조되면 무용지물이므로 별도 계정·쓰기방지(불변) 스토리지에 보관해 보호합니다.
어떤 경보가 어떤 상태인지 봅니다. 너무 많거나 항상 ALARM/INSUFFICIENT면 손봐야 합니다.
aws cloudwatch describe-alarms \
--query "MetricAlarms[].{Name:AlarmName,Metric:MetricName,State:StateValue}" --output table
+---------------------------+------------------+--------+
| api-5xx-rate-high | 5xxErrorRate | OK |
| api-latency-p99-high | TargetResponse | ALARM | ← 사용자 영향
| cpu-70 (원인지표) | CPUUtilization | OK | ← 대시보드로 충분
+---------------------------+------------------+--------+
aws cloudwatch describe-alarms보안그룹 변경 같은 민감 작업을 누가 했는지 확인합니다.
aws cloudtrail lookup-events \
--lookup-attributes AttributeKey=EventName,AttributeValue=AuthorizeSecurityGroupIngress \
--max-results 3 --query "Events[].{Time:EventTime,User:Username,Event:EventName}"
[ { "Time": "2026-06-15T18:02Z", "User": "dev-kim", "Event": "AuthorizeSecurityGroupIngress" } ]
aws cloudtrail lookup-events- describe-alarms에 경보가 수십 개·항상 ALARM/INSUFFICIENT — 알림 피로 신호. 증상 중심으로 정리하고 원인 지표는 대시보드로
- 사용자 영향 증상(5xx·p99 지연·가용성)에 페이징 경보가 걸려 있는지 — 없으면 진짜 장애를 못 받음
- CloudTrail이 모든 리전·계정에서 켜져 있고 별도 보호 스토리지에 보관되는지 — 꺼져 있거나 변조 가능하면 사고 조사 불가
- 가드레일(SCP) 적용 여부 — 퍼블릭 차단·리전 제한·루트키 금지가 조직 차원에서 강제되는지
상황: 알림이 신호 역할을 못 함(과소 또는 과다).
원인: ① 사용자 영향 증상이 아니라 원인 지표(CPU 등)에만 알림을 걸어 진짜 장애를 못 잡음, ② 모든 것에 알림을 걸어 피로 누적→무시, ③ 알림 라우팅(누구에게·어떤 채널)이 미설정.
진단: 경보 목록을 '증상 vs 원인'으로 분류 → 최근 장애 때 어떤 알림이 울렸는지 회고(SLO·에러버짓·포스트모템 관점) → 알림 수신·라우팅 확인.
해결: 페이징은 사용자 영향 증상(SLO 위반 SLO·에러버짓·포스트모템)에만, 원인 지표는 대시보드로. 알림마다 '대응 절차(runbook)'를 연결해 실행 가능하게. 정기적으로 알림을 솎아내(노이즈 제거) 신호 대비 잡음을 낮춥니다.
심화 — 관측에도 청구서가 온다
심화: 로그·지표·추적의 비용 구조 — 신호는 공짜가 아니다
관측을 '많이 남길수록 좋다'로 운영하면 어느 날 관측 비용이 워크로드 비용을 추월합니다. 세 신호는 과금 구조가 서로 다릅니다.
- 로그: 저장보다 수집(ingestion) 이 비쌉니다 — GB당 과금이라 DEBUG 레벨 하나, 루프 안의 로그 한 줄이 그대로 요금이 됩니다. 보존기간 기본값이 '무기한'인 것도 함정이라, 로그 그룹마다 retention을 명시해야 저장비가 무한 누적되지 않습니다.
- 지표: 커스텀 지표는 지표 개수당 과금입니다. 사용자 ID·요청 ID처럼 값이 무한한 것을 차원(dimension)으로 넣으면 조합 수만큼 지표가 폭증합니다(카디널리티 폭발). 차원에는 유한한 값(서비스·환경·리전)만 씁니다.
- 추적: 전 요청 기록이 아니라 샘플링이 기본입니다. 평상시 1~10%만 수집하고, 에러·특정 경로만 100%로 올리는 식으로 가치 있는 trace에 예산을 씁니다.
원칙은 알림 설계와 같습니다 — 많이가 아니라, 답할 수 있게. "이 로그·지표로 어떤 질문에 답하는가"에 답하지 못하는 신호는 정보가 아니라 비용입니다.
상황: 2주 전 장애 조사를 위해 운영 API 서버의 로그 레벨을 DEBUG로 올렸고, 원인 해결 후 되돌리는 것을 잊었습니다. 서비스는 정상인데 월 청구서의 로깅 항목만 6배가 됐습니다.
원인: DEBUG는 요청당 로그 줄 수를 수십 배로 늘립니다. 로그는 수집량(GB) 기준 과금이라 하루 수십 GB가 수백 GB로 커지면 그대로 비용이 됩니다. 보존기간도 무기한이어서 수집비 위에 저장비까지 계속 쌓입니다.
진단: 비용 도구에서 로깅 서비스 항목을 분해하고, 로그 그룹별 수집량 지표(IncomingBytes)를 기간 비교해 어느 그룹이 언제부터 쏟아냈는지 특정합니다 — 급증 시작일이 로그 레벨을 올린 배포일과 일치하면 확정입니다.
해결: 로그 레벨 원복은 응급 처치이고, 재발 방지가 본질입니다. ① 모든 로그 그룹에 retention 설정(무기한 금지), ② 조사용 레벨 변경에는 만료 시간을 함께 걸어 며칠 뒤 자동 원복, ③ 로그 수집량 자체에 예산 알림을 걸어(클라우드 비용 최적화) 폭증을 청구서가 아니라 알림으로 먼저 알게 합니다.
관측·거버넌스는 'SRE 성숙도'를 가르는 지점입니다. 면접에서 "장애를 어떻게 감지·대응하나요?"에 "지표로 SLO 기반 알림, 로그·추적으로 원인 좁히고, 사후 회고로 재발 방지"라 답하면 탄탄합니다. "모든 것에 알림 건다"는 오히려 미성숙 신호입니다.
거버넌스는 조직이 커질수록 중요해집니다. "보안을 어떻게 강제하나요?"에 "멀티계정으로 격리하고 SCP 가드레일로 퍼블릭 차단·리전 제한을 일괄 강제, CloudTrail로 감사"면 좋은 답입니다.
이 트랙을 마치며: 왜 클라우드인가에서 '왜 클라우드인가'로 시작해 IAM·VPC·컴퓨트·스토리지·서버리스·컨테이너·IaC·비용을 거쳐 여기 관측·거버넌스에 닿았습니다. 이 조각들은 따로가 아니라 하나의 운영 체계입니다 — 코드로 선언하고(IaC와 Terraform), 안전하게 배포하고(오토스케일링 + 로드밸런서), 비용을 보고(클라우드 비용 최적화), 관측·통제하는. 더 깊은 컨테이너 오케스트레이션은 Kubernetes, 네트워크 트러블슈팅은 Networking 트랙으로 이어집니다.
관련 모듈로 더 깊이:
- 시크릿·키 관리 — 거버넌스로 통제하는 핵심 자산인 시크릿의 보관·교체·주입
- 계정과 IAM — 다계정·조직 단위 통제의 출발점인 계정·권한 관리
- 클라우드 비용 최적화 — 관측으로 드러나는 비용을 줄이는 최적화
관측·거버넌스로 "보고 통제하는" 체계를 세웠다면, 다음 모듈에서는 그 통제의 핵심 자산 — API 키·인증서·DB 암호 같은 시크릿을 안전하게 보관·교체·주입하는 방법을 다룹니다.