새벽 2시, 스토리지 한 볼륨이 느려졌습니다.
C는 모니터링 알람만 보고 "스토리지가 느리네" 하고 디스크만 들여다봅니다. 정작 그 볼륨에 주문 DB의 트랜잭션 로그가 얹혀 있다는 걸 아는 사람은 자리에 없는 선임뿐. 30분 뒤 결제가 줄줄이 타임아웃 나고서야 "어, 결제도 죽었네?"를 깨닫습니다.
D는 같은 알람을 받고 CMDB에서 그 스토리지 CI를 클릭합니다. 화면에 "이 볼륨 ← 주문 DB ← 결제 API ← 결제 서비스(전 고객)" 라는 관계가 뜹니다. D는 즉시 "이건 스토리지 장애가 아니라 결제 서비스 장애 직전"이라 판단하고, 결제팀에 선제 통보하고 우선순위를 P1으로 올립니다.
둘의 차이는 손기술이 아니라 "무엇이 무엇과 연결돼 있는지를 아는가" 입니다. C는 머릿속 지도가 비어 있었고, D는 조직이 만들어 둔 지도(CMDB)를 폈습니다. 이 모듈은 그 지도 — 구성 관리와 CMDB — 를 다룹니다.
- 1구성 항목(CI)이 무엇이고, 자산(Asset)과 어떤 렌즈로 다른지 설명할 수 있다
- 2CMDB가 단순한 자산 목록이 아니라 "CI와 그 관계(의존성)를 담는 지도"임을 설명할 수 있다
- 3CMDB와 CMS(구성 관리 시스템)의 포함 관계를 구분할 수 있다
- 4관계(의존성) 정보가 장애 영향 분석과 변경 영향 분석에 어떻게 쓰이는지 위·아래 추적으로 설명할 수 있다
- 5디스커버리(자동 수집)와 베이스라인의 역할을 설명할 수 있다
- 6"완벽한 CMDB의 함정"(과도한 상세→갱신 실패→신뢰 붕괴)을 인지하고 적정 수준을 판단할 수 있다
구성 항목(CI) — 관리의 최소 단위
CI는 '서비스를 구성하고 관계를 맺는 모든 것'
운영을 하다 보면 "그래서 이게 망가지면 뭐가 같이 망가지지?"라는 질문이 끝없이 나옵니다. 이 질문에 답하려면 먼저 무엇을 관리 대상으로 셀지를 정해야 합니다. 그 단위가 구성 항목(CI, Configuration Item) 입니다.
CI는 "서비스를 전달하기 위해 관리되어야 하는 모든 구성요소"입니다. 흔히 떠올리는 하드웨어만이 아닙니다.
| CI 유형 | 예시 | 왜 CI인가 |
|---|---|---|
| 서버(하드웨어/VM) | web-01, db-prod-02 | 위에 서비스가 얹히고, 죽으면 영향이 퍼진다 |
| 애플리케이션 | 결제 API, 주문 서비스 | 사용자에게 직접 기능을 전달한다 |
| 데이터베이스 | 주문 DB, 회원 DB | 여러 앱이 의존하는 핵심 |
| 네트워크 | 방화벽, L4 스위치, VPN | 끊기면 위쪽 전부가 끊긴다 |
| 서비스(논리) | "결제 서비스" 자체 | 위 CI들이 모여 사용자에게 주는 결과 |
| 그 외 | 인증서, 라이선스, 문서, 사람(역할) | 빠지면 서비스가 안 돌아간다 |
여기서 자주 헷갈리는 게 자산(Asset)과의 차이입니다. 같은 서버 한 대를 두고:
- 자산관리의 관심: "얼마짜리인가, 누가 샀나, 감가상각, 보증 만료일" — 소유·금전 렌즈.
- 구성관리의 관심: "이 서버가 어떤 서비스를 떠받치고, 무엇과 연결돼 있나" — 관계·서비스 렌즈.
같은 대상이 자산이면서 동시에 CI일 수 있습니다. 중요한 건 CMDB가 보는 것은 가격표가 아니라 연결선이라는 점입니다.
CMDB와 CMS — 지도와 지도책
CMDB는 CI와 '관계'를 담는다 (목록이 아니다)
CMDB(Configuration Management Database) 는 CI들과 그 사이의 관계(의존성) 를 저장하는 데이터베이스입니다. 흔한 오해가 "CMDB = 장비 엑셀 목록"인데, 단순 목록과 CMDB를 가르는 결정적 차이는 관계 입니다.
- 장비 목록: "서버 200대, DB 12개" — 점(node)만 있음.
- CMDB: "결제 API는 주문 DB에 의존하고, 주문 DB는
db-prod-02에 얹혀 있고, 그건 스토리지 볼륨vol-7을 쓴다" — 점 + 선(관계).
이 '선'이 없으면 새벽 2시의 C가 됩니다. 선이 있으면 D가 됩니다.
CMS(Configuration Management System) 는 한 단계 더 넓은 개념입니다. 현실에선 모든 정보가 한 DB에 있지 않습니다 — 자산 시스템, 모니터링, 디스커버리 도구, 문서 저장소 등 여러 출처가 있죠. CMS는 이 여러 CMDB·데이터 소스를 묶어 하나의 일관된 그림으로 보여주는 상위 체계입니다.
| 용어 | 한 줄 정의 | 비유 |
|---|---|---|
| CI | 관리되는 개별 구성요소 | 지도 위의 한 지점 |
| 관계(Relationship) | CI 사이의 의존·연결 | 지점을 잇는 도로 |
| CMDB | CI와 관계를 담는 DB | 한 장의 지도 |
| CMS | 여러 CMDB·소스를 통합한 체계 | 여러 지도를 엮은 지도책 |
실무에서 둘을 엄밀히 구분해 말하지 않는 경우도 많습니다. 시험·문서에서는 "CMDB ⊂ CMS" (CMDB가 CMS의 일부)라는 포함 관계만 기억하면 충분합니다.
관계 정보는 어디에 쓰이는가 — 영향 분석
위로 따라가면 '누가 아파지나', 아래로 따라가면 '무엇이 원인인가'
CMDB에 관계를 채워 넣는 이유는 단 하나, "건드리거나 망가졌을 때 무슨 일이 일어나는지 미리 안다" 입니다. 같은 관계 데이터를 두 방향으로 읽습니다.
- 장애 영향 분석(위로 추적): 어떤 CI가 죽었을 때 그 위에 얹힌 상위 CI·서비스·사용자가 무엇인지 거슬러 올라갑니다. "스토리지 볼륨이 느리다 → 주문 DB → 결제 API → 결제 서비스(전 고객)". 그래서 인시던트 우선순위를 정확히 매길 수 있습니다.
- 변경 영향 분석(아래·옆으로 추적): 어떤 CI를 바꾸려 할 때(배포·패치·증설), 그 변경이 닿는 모든 CI를 미리 펼칩니다. "주문 DB를 점검하려는데, 여기 의존하는 게 결제·정산·배송까지 세 서비스네 → 점검창을 새벽으로, 세 팀에 사전 통보".
이 두 가지가 인시던트 관리와 변경 관리가 CMDB를 떠받치는 토대로 삼는 이유입니다. 관계가 비어 있으면 우선순위도 변경 승인도 '감(感)'으로 하게 됩니다.

그림: CI 의존 관계 체인 — 같은 관계 데이터를 위로 읽으면 영향 분석(누가 아파지나), 아래로 읽으면 원인 추적(무엇이 원인인가)이 된다.
어떻게 채우고 유지하는가 — 디스커버리와 베이스라인
사람이 일일이 못 채운다 — 자동 수집과 기준선
CMDB가 망가지는 1순위 이유는 거창한 게 아니라 "사람이 갱신을 못 따라가서" 입니다. 서버가 매주 늘고 줄고 배포가 하루에도 수십 번인데, 손으로 표를 고칠 수는 없습니다. 그래서 두 가지 장치가 있습니다.
- 디스커버리(Discovery, 자동 수집): 에이전트·네트워크 스캔으로 실재하는 CI와 그 연결을 주기적으로 탐지해 CMDB에 자동 반영합니다. "지금 실제로 무엇이 돌고 있고 무엇과 통신하는가"를 기계가 채웁니다. 다만 디스커버리가 알 수 없는 게 하나 있습니다 — 비즈니스 의미. "이 서버가 '결제'를 떠받친다"는 맥락은 사람이 입혀야 합니다.
- 베이스라인(Baseline): 특정 시점의 '승인된 정상 구성 상태'를 스냅샷으로 박아 둔 것입니다. "릴리스 직전의 운영 구성"을 베이스라인으로 잡아 두면, 나중에 "지금 구성이 그때와 뭐가 다르지?"(드리프트)를 비교하고, 문제가 생겼을 때 돌아갈 기준점으로 씁니다.
정리하면, 현재 상태는 디스커버리가 자동으로 채우고, 정상 상태의 기준점은 베이스라인으로 박아 둔다 — 이 둘이 CMDB를 살아 있게 합니다.
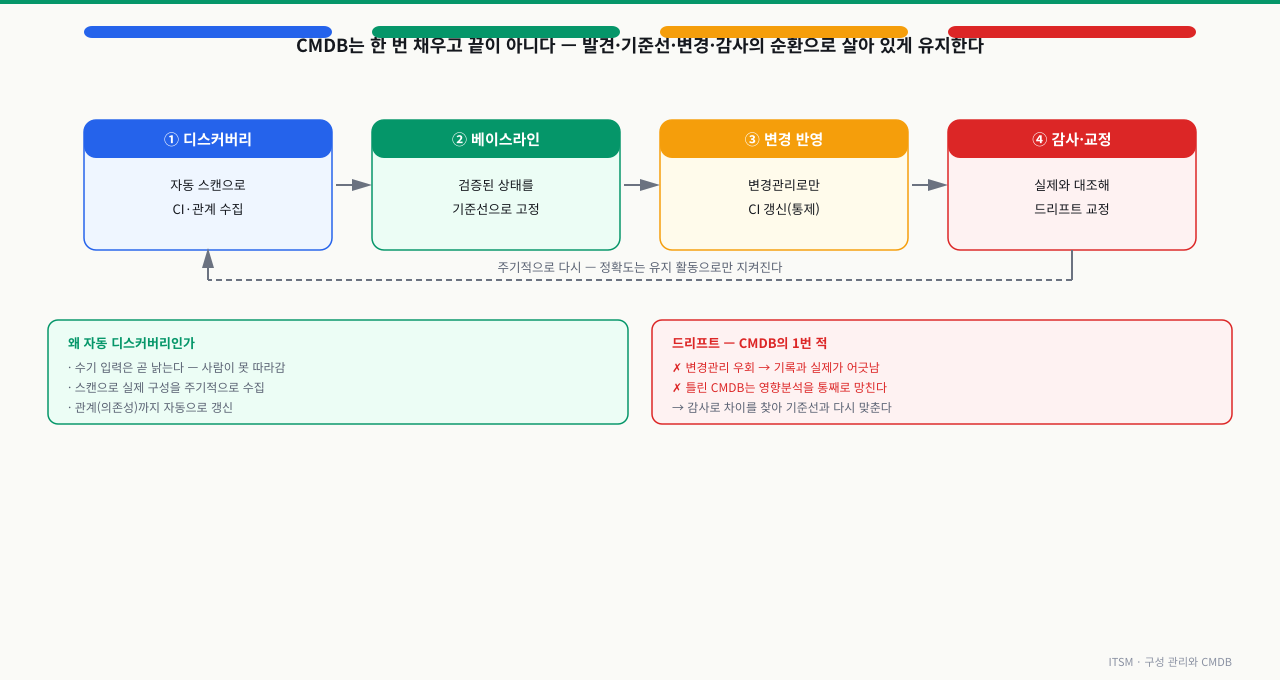
여기서 한 걸음 더 나아가면, 디스커버리와 베이스라인은 한 번 하고 끝나는 작업이 아니라 돌아가는 순환의 일부입니다. ① 디스커버리로 수집하고 → ② 검증된 상태를 베이스라인으로 고정한 뒤 → ③ 이후 변경은 변경관리를 통해서만 CI에 반영하고 → ④ 주기적으로 실제와 기록을 대조해 어긋난 부분(드리프트)을 교정하고, 다시 ①로 돌아옵니다. CMDB의 1번 적은 바로 이 드리프트 — 변경관리를 우회한 변경으로 기록과 실제가 어긋나는 것입니다. 틀린 CMDB는 앞서 본 영향 분석을 통째로 망치기 때문에, 정확도는 이 유지 순환을 도는 활동으로만 지켜집니다.
직접 해보기 — 영향 분석을 손으로 따라가기
아래는 작은 결제 서비스의 CMDB를 표로 옮긴 것입니다. CI 속성 표(점)와 CI 관계 표(선)를 함께 봅니다.
CI 속성 표:
CI ID | 이름 | 유형 | 상태 | 담당팀
-----------|---------------|------------|--------|--------
SVC-PAY | 결제 서비스 | 서비스(논리) | 운영중 | 결제팀
APP-PAY | 결제 API | 애플리케이션 | 운영중 | 결제팀
DB-ORDER | 주문 DB | 데이터베이스 | 운영중 | DBA팀
SRV-DB02 | db-prod-02 | 서버(VM) | 운영중 | 인프라팀
VOL-7 | 스토리지 vol-7 | 네트워크/스토리지 | 저하 | 인프라팀
CI 관계(의존성) 표 — "A는 B에 의존한다" 방향:
상위 CI(A) → 의존 대상(B) | 관계 의미
-----------|----------------|------------------------
SVC-PAY → APP-PAY | 결제 서비스는 결제 API로 동작
APP-PAY → DB-ORDER | 결제 API는 주문 DB를 읽고 쓴다
DB-ORDER → SRV-DB02 | 주문 DB는 db-prod-02 위에서 돈다
SRV-DB02 → VOL-7 | 그 서버는 스토리지 vol-7을 쓴다
지금 VOL-7이 "저하" 상태입니다. VOL-7에서 출발해 화살표를 거꾸로(위로) 따라가며, 어떤 CI와 어떤 서비스·사용자가 영향권에 드는지 종이에 적어 보세요. 정답·해석은 아래 ObserveBlock에 있습니다.
추적: 아래 CI 죽으면 위로 무엇이 영향받나- VOL-7(저하) → SRV-DB02 → DB-ORDER → APP-PAY → SVC-PAY 순으로 영향이 위로 전파된다 — 즉 스토리지 한 줄의 문제가 결국 "결제 서비스(전 고객)" 장애로 번질 수 있다
- 이것이 장애 영향 분석(위로 추적): 가장 아래 CI에서 출발해, 의존하는 상위 CI를 거슬러 올라가 "누가 아파지나"를 본다
- 반대로 SVC-PAY에서 아래로 따라가면 원인 후보를 좁히는 원인 추적이 된다 — 같은 관계 데이터, 읽는 방향만 다르다
- 실무 판단: VOL-7은 단순 "스토리지 저하"가 아니라 "결제 서비스 장애 직전"으로 우선순위를 올려야 한다 — 관계 데이터가 우선순위를 바꾼다
- 변경 관점으로도 동일: 누군가 SRV-DB02를 점검하려 한다면, 이 표만 보면 결제까지 멈춘다는 걸 미리 알고 점검창·통보를 잡을 수 있다
- 관계 표가 비어 있었다면? VOL-7만 들여다보다 결제가 죽고 나서야 연결을 깨닫는다 — 새벽 2시의 C가 된다
현장에서 자주 보는 함정
증상: 프로젝트 초기에 "이왕 만들 거 제대로"라며 모든 CI의 모든 속성(구입처, 펌웨어 버전, 랙 위치, 담당자 연락처…)을 수동으로 빼곡히 채웠습니다. 처음엔 뿌듯했는데, 6개월 뒤 운영자들은 "CMDB? 그거 어차피 틀려요. 그냥 서버에 직접 붙어서 봐요"라고 말합니다.
원인: 상세함과 신뢰성을 혼동했습니다. 속성이 많을수록 갱신해야 할 양도 많은데, 변경 속도를 수동 갱신이 못 따라갔습니다. 한 번 "틀린 DB"로 인식되면 사람들은 더 이상 보지 않고, 안 보니 더 안 고치는 악순환 — 갱신 실패 → 신뢰 붕괴입니다. 너무 상세한 CMDB는 정확한 CMDB가 아니라 빨리 썩는 CMDB입니다.
해결 방향:
- "이 데이터가 어떤 결정에 쓰이는가" 를 기준으로 담을 항목을 줄인다. 안 쓰는 필드는 빼는 게 이득.
- 채울 수 있는 건 디스커버리로 자동화 — 사람 손 갱신을 최소화한다.
- 관계(의존성)처럼 영향 분석에 직접 쓰이는 정보부터 정확히 유지한다(다 채우려 하지 말고).
- 각 필드에 갱신 책임자(주인) 를 둔다. 주인 없는 필드는 반드시 썩는다.
- 목표를 "완벽"이 아니라 "사람들이 믿고 보는 적정 수준" 으로 재설정한다. 70% 정확하지만 매일 보는 CMDB가, 한때 100%였지만 죽은 CMDB보다 백 배 낫다.
국내 SI/SM 현장에서 CMDB는 흔히 운영 이관(전환) 시점과 정기 감사에서 그 진가가 드러납니다. 발주사·원청은 "구성도 최신화", "CI 관계도 제출", "변경 시 영향 CI 명시"를 산출물로 요구하고, 운영(SM) 계약서의 SLA 보고에도 "장애 영향 범위"가 들어갑니다 — 이 모든 게 결국 CMDB(또는 그 자리를 대신하는 구성도·관리대장)에서 나옵니다.
관리자 입장에서 당신이 통제할 핵심은 두 가지입니다. 첫째, 협력사가 변경 작업을 신청할 때 "영향받는 CI와 서비스"를 명시하게 강제하는 것 — 그래야 통제 없는 변경으로 인한 장애를 막습니다. 둘째, CMDB를 '완벽한 문서'가 아니라 '신뢰되는 의사결정 도구'로 유지하도록 갱신 책임과 디스커버리 자동화를 설계하는 것입니다. 현장에서 자주 보는 실패가 "이관 때 만든 멋진 구성도가 1년 뒤 현실과 전혀 다른" 경우인데, 기술을 아는 관리자는 "이 구성도, 디스커버리로 검증된 거냐, 누가 갱신 책임지냐"를 물어 그 함정을 미리 막습니다.
관련 모듈로 더 깊이:
- 변경요청서와 영향도 분석 — CMDB 관계로 변경 영향 범위를 산정하는 영향도 분석
- 변경 관리(변경 활성화) — CI 의존 관계를 근거로 변경 리스크를 통제하는 변경관리
- 인시던트 관리 — 장애 영향 범위 파악에 CMDB를 활용하는 인시던트 대응
다음 모듈에서는 이 CMDB와 관계 정보를 가장 직접적으로 활용하는 활동 — 시스템을 의도적으로 바꿀 때 리스크를 통제하는 변경 관리(Change Management)를 다룹니다.