새벽 세 시, 두 운영팀.
A팀은 조용합니다. 모니터링이 없는 건 아니지만, 알림이 너무 많이 와서 다들 채널 알림을 꺼 두었습니다. 아침 아홉 시, 고객센터로 "결제가 안 돼요" 전화가 빗발치고 나서야 A팀은 새벽 두 시부터 결제 DB 디스크가 꽉 차 있었다는 걸 알게 됩니다. 일곱 시간을 모르고 흘려보낸 겁니다.
B팀은 자정에 모니터링이 보낸 경고를 받았습니다 — "결제 DB 디스크 사용률 85퍼센트 초과". 아직 서비스는 멀쩡합니다. 당직자는 오래된 로그를 정리해 사용률을 60퍼센트대로 내립니다. 아침에 출근한 팀은 아무 일도 없던 것처럼 일을 시작합니다. 고객은 장애가 있었는지조차 모릅니다.
두 팀의 차이는 모니터링 도구의 유무가 아닙니다. 신호를 받고도 살아 있는 체계가 있느냐입니다. A팀은 신호를 꺼 버렸고, B팀은 신호를 분류해 행동으로 연결했습니다. 이 모듈은 '장애를 신고받기 전에 먼저 아는' 이벤트·모니터링 관리 체계를 다룹니다.
- 1이벤트(CI·서비스의 상태 변화 신호)가 사용자 신고와 어떻게 다른지 설명할 수 있다
- 2이벤트를 정보(Information)·경고(Warning)·예외(Exception)로 분류하고 각각에 맞는 대응을 정할 수 있다
- 3능동 모니터링과 수동 모니터링의 차이를 알고, 무엇을 모니터링할지(CPU·메모리·디스크·오류율·지연) 설계할 수 있다
- 4임계치(threshold)와 알림(alert)이 인시던트 자동 생성으로 이어지는 흐름을 그릴 수 있다
- 5알림 피로(alert fatigue)의 위험을 이해하고, 상관분석·중복 억제로 노이즈를 줄이는 방향을 제시할 수 있다
이벤트란 무엇인가 — 신고가 아니라 신호
이벤트는 시스템이 스스로 보내는 상태 변화 신호다
지금까지 운영의 출발점은 대부분 '사람의 신고'였습니다 — "메일이 안 와요", "결제가 느려요". 그런데 사람이 신고할 때쯤이면 이미 고객이 불편을 겪은 뒤입니다. 한 칸 앞으로 가려면, 시스템이 스스로 신호를 보내게 해야 합니다. 그 신호가 바로 **이벤트(Event)**입니다.
이벤트는 "구성요소(CI)나 서비스의 상태 변화 중, 관리상 의미가 있는 것을 알리는 신호"입니다. 핵심은 두 가지입니다.
- 출발점이 사람이 아니다. 디스크가 임계치를 넘거나, 서비스가 응답을 멈추거나, 배치가 끝나는 것 모두 시스템이 자동으로 발생시키는 이벤트입니다.
- 모든 이벤트가 나쁜 건 아니다. "배치 정상 종료", "백업 성공"도 이벤트입니다. 이벤트는 '경보'가 아니라 '신호'이고, 그중 일부만 대응이 필요합니다.
| 구분 | 인시던트(앞 모듈) | 이벤트(이 모듈) |
|---|---|---|
| 출발점 | 사람의 신고 또는 감지된 장애 | 시스템이 보낸 상태 변화 신호 |
| 좋고 나쁨 | 항상 '나쁜 일'(서비스 저하) | 좋을 수도, 나쁠 수도 있음 |
| 시점 | 보통 이미 영향 발생 후 | 영향 발생 전에 받을 수 있음 |
| 관계 | — | 의미 있는 이벤트가 인시던트로 이어질 수 있음 |
그래서 이벤트 관리의 목표는 단순합니다. 고객이 신고하기 전에, 시스템이 먼저 말하게 한다. 이벤트는 사전 감지의 원료입니다.
이벤트 분류 — 정보·경고·예외
모든 신호를 똑같이 대하면 진짜 신호를 놓친다
이벤트가 하루 수천 건씩 쏟아지는데 전부 똑같이 본다면, 백업 성공 알림과 결제 서버 다운 알림이 같은 줄에 섞입니다. 그래서 이벤트는 대응의 시급함에 따라 세 등급으로 나눕니다. 이것이 이벤트 관리의 가장 기본적인 분류입니다.
| 유형 | 뜻 | 예 | 조치 |
|---|---|---|---|
| 정보(Information) | 정상 동작의 기록. 대응 불필요, 추세·감사용으로 보관 | "야간 배치 정상 종료", "사용자 로그인 성공", "백업 완료" | 기록만 한다. 알림은 보내지 않거나 모아서 본다 |
| 경고(Warning) | 아직 정상이지만 곧 한계에 닿을 수 있는 예측 신호 | "디스크 사용률 85퍼센트 초과", "응답 지연 증가 추세", "큐 적체 증가" | 예방 조치를 계획한다. 비상 대응은 아니다 |
| 예외(Exception) | 이미 정상 범위를 벗어남. 즉시 대응이 필요 | "결제 서비스 응답 없음", "오류율 급증", "디스크 가득 참" | 인시던트로 연결해 즉시 대응·에스컬레이션 |
분류의 실전 감각:
- 정보를 알림으로 쏘지 마라. "로그인 성공" 같은 정보를 매번 알림으로 보내면, 그게 곧 알림 피로의 시작입니다. 정보는 '기록'하되 '깨우지'는 않습니다.
- 경고는 '시간을 버는 신호'다. 경고가 왔을 때 손을 쓰면 예외(=실제 장애)를 막을 수 있습니다. 경고를 무시하는 조직은 늘 예외 단계에서야 움직입니다.
- 예외는 인시던트의 입구다. 예외 이벤트는 대부분 인시던트 생성으로 이어집니다. 다음 절에서 이 자동 연결을 봅니다.
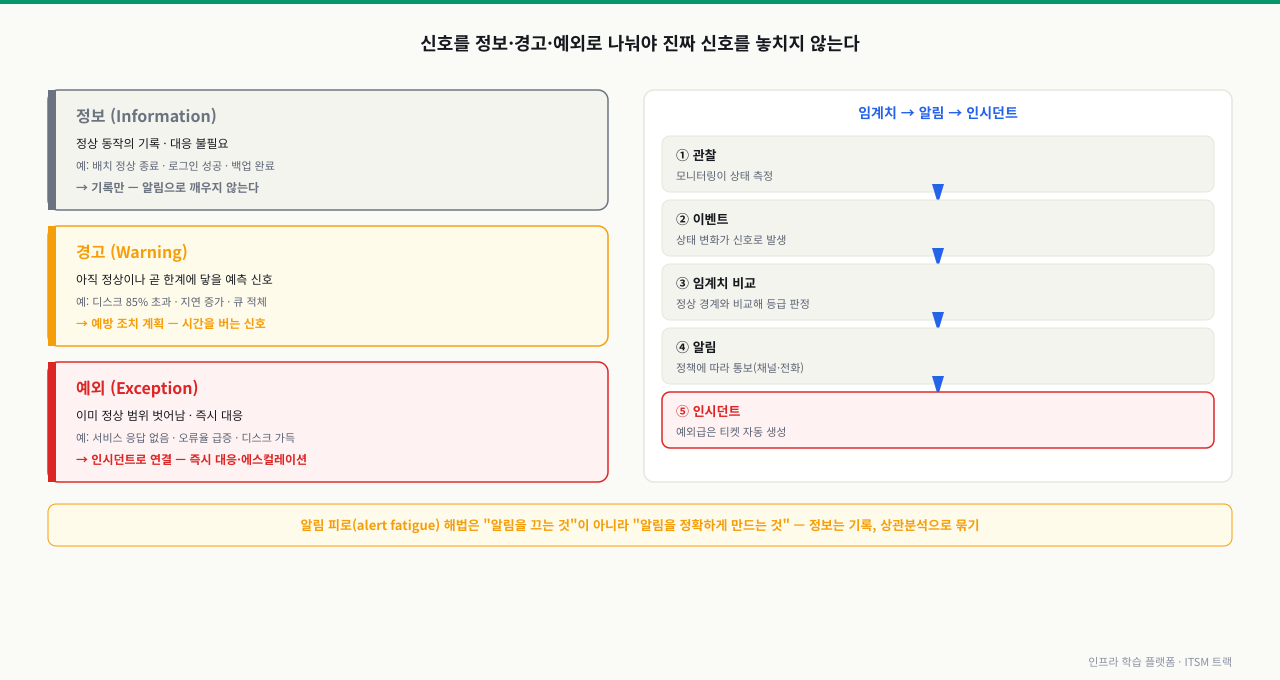
그림: 신호를 정보·경고·예외로 나눠야 진짜 신호를 놓치지 않는다 — 알림 피로의 해법은 알림을 끄는 것이 아니라 정확하게 만드는 것이다.
모니터링 — 능동과 수동, 그리고 무엇을 볼까
이벤트를 만들어내는 눈, 모니터링
이벤트가 '신호'라면, **모니터링(Monitoring)**은 그 신호를 만들어내는 '눈'입니다. 모니터링이 상태를 관찰하다가 의미 있는 변화를 발견하면 이벤트가 발생합니다. 모니터링은 관찰 방식에 따라 둘로 나뉩니다.
- 능동 모니터링(Active): 시스템이 대상에게 주기적으로 '말을 걸어' 상태를 확인합니다. 헬스 체크 요청을 보내 응답·응답시간을 보고, 합성 거래(synthetic, 가짜 사용자 시나리오)를 돌려 결제가 실제로 되는지 확인합니다. 장점은 사용자가 겪기 전에 먼저 안다는 것입니다.
- 수동 모니터링(Passive): 대상이 흘려보내는 신호(로그·메트릭·실제 트래픽)를 받아서 관찰합니다. 실제 사용자 요청의 오류율·지연을 보는 방식이라 '현실'을 반영하지만, 사용자가 이미 겪은 뒤일 수 있습니다.
둘은 경쟁이 아니라 보완입니다. 능동으로 사용자보다 먼저 감지하고, 수동으로 실제 사용자 경험을 확인합니다.
그렇다면 무엇을 모니터링해야 할까요? 깊은 도구 설정은 cloud·kubernetes 트랙의 영역이고, 여기서는 '관리자가 무엇을 봐야 하는가'의 목록을 잡습니다.
| 대상 | 무엇을 보나 | 왜 보나 |
|---|---|---|
| CPU 사용률 | 지속적으로 높은지(예: 90퍼센트 초과 지속) | 처리 한계 임박, 응답 지연의 전조 |
| 메모리 사용률 | 점유율·스왑 발생 | 메모리 고갈 시 프로세스 강제 종료 위험 |
| 디스크 사용률 | 남은 공간(예: 85퍼센트 초과) | 가득 차면 로그·DB 쓰기 실패로 서비스 정지 |
| 오류율(5xx 등) | 전체 요청 중 서버 오류 비율 | 사용자가 실제로 실패를 겪고 있다는 직접 신호 |
| 응답 지연(latency) | 평균보다 상위 백분위(p95·p99) | 평균은 멀쩡해도 일부 사용자는 느릴 수 있음 |
| 가용성(up/down) | 서비스가 응답하는가 | 가장 기본적인 '살아 있나' 신호 |
지연은 평균이 아니라 **상위 백분위(p95·p99)**로 보는 게 핵심입니다. 평균 응답이 0.2초여도 상위 1퍼센트 사용자가 5초를 기다린다면, 그 1퍼센트에게 서비스는 고장 난 것입니다.
임계치에서 인시던트까지 — 자동 연결의 흐름
임계치를 넘으면 알림, 알림이 인시던트가 된다
이벤트가 의미 있는 행동으로 이어지려면 세 단계를 거칩니다. 이 흐름을 설계하는 것이 이벤트 관리의 실체입니다.
- 임계치(Threshold): "어디까지가 정상인가"의 경계선입니다. 디스크 사용률 85퍼센트 초과를 경고, 95퍼센트 초과를 예외로 정하는 식입니다. 임계치가 너무 빡빡하면 알림 폭주, 너무 헐겁면 놓침이 생깁니다.
- 알림(Alert): 이벤트가 임계치를 넘으면 정해진 사람·채널에 알림이 발송됩니다. 누구에게(당직자), 어떤 채널로(메신저·전화), 얼마나 급하게(경고는 채널, 예외는 전화 호출) 보낼지가 정책입니다.
- 인시던트 자동 생성: 예외급 알림은 사람이 받아 적기 전에 자동으로 인시던트 티켓을 생성할 수 있습니다. 이렇게 하면 신고를 기다리지 않고, 알림 시각·대상 서비스·원인 신호가 티켓에 자동 기록됩니다.
정리하면 이렇게 흐릅니다.
| 단계 | 무슨 일이 일어나나 | 예 |
|---|---|---|
| 1. 관찰 | 모니터링이 상태를 측정 | 디스크 사용률을 일 분마다 측정 |
| 2. 이벤트 | 상태 변화가 신호로 발생 | "사용률 96퍼센트" 이벤트 발생 |
| 3. 임계치 비교 | 정상 경계와 비교해 등급 판정 | 95퍼센트 초과 → 예외 |
| 4. 알림 | 정책에 따라 통보 | 당직자에게 전화 호출 |
| 5. 인시던트 | 예외급은 티켓 자동 생성 | "결제 DB 디스크 임박" 인시던트 자동 등록 |
이 자동화가 앞 모듈에서 배운 인시던트 관리와 만나는 지점입니다. 사람의 신고만 기다리던 인시던트의 입구에, 이제 모니터링이 만든 자동 입구가 하나 더 생기는 것입니다.
직접 해보기 — 이벤트 분류와 대응 설계
아래 5건은 모니터링이 발생시킨 이벤트입니다. 각각 (1) 정보·경고·예외 중 무엇이고, (2) 어떤 대응이 적절한지 정해 보세요. 정답은 아래 ObserveBlock에 있습니다.
가. "결제 API 헬스체크 응답 없음 — 연속 3회 실패" (능동 모니터링)
나. "일일 데이터 백업 정상 완료" (배치)
다. "주문 서비스 p99 응답시간이 평소 0.4초에서 2.1초로 증가" (수동 모니터링)
라. "웹서버 CPU 사용률 92퍼센트가 십 분째 지속" (메트릭)
마. "신규 사용자 회원가입 성공" (애플리케이션 로그)
판단 직관: '지금 깨졌나(예외)' / '곧 깨질 신호인가(경고)' / '정상 기록인가(정보)' 세 질문을 순서대로 던집니다.
분류: 정보 / 경고 / 예외 → 대응- 가 = 예외(Exception). 결제는 핵심 서비스이고 응답이 없으므로 즉시 인시던트 자동 생성·당직 호출. 영향 큰 서비스라 우선순위 높게
- 나 = 정보(Information). 정상 동작 기록이므로 대응 불필요. 알림으로 깨우지 말고 기록만 — 단, 백업 실패였다면 예외가 된다
- 다 = 경고(Warning). 아직 동작하지만 p99가 다섯 배로 악화. 추세를 보고 원인(부하·쿼리)을 조사해 예외(장애)로 번지기 전에 손을 쓴다
- 라 = 경고(Warning) 또는 예외 진입 직전. 지속적 고부하는 곧 응답 지연·실패로 이어질 전조. 부하 원인 확인·증설 검토
- 마 = 정보(Information). 정상 동작 기록. 추세 분석용으로 보관하되 개별 알림은 보내지 않는다
- 핵심 감각: 같은 이벤트라도 대상 서비스의 중요도와 정상 경계(임계치)에 따라 등급과 우선순위가 달라진다 — 분류 기준을 미리 합의해 두는 것이 운영의 절반이다
현장에서 자주 보는 함정
증상: 모니터링은 잘 갖춰져 있는데, 알림이 하루 수백 건씩 쏟아집니다. 처음엔 다 보던 팀이 점점 둔감해지고, 결국 메신저 알림을 음소거하거나 채널을 떠납니다. 그러다 진짜 예외 알림(결제 다운)이 그 속에 섞여 들어와도 아무도 즉시 반응하지 못합니다. 이것이 **알림 피로(alert fatigue)**입니다.
원인: 보통 세 가지가 겹칩니다.
- 정보를 알림으로 쐈다 — "로그인 성공", "배치 시작" 같은 정상 신호까지 알림으로 보냄.
- 임계치가 너무 빡빡하다 — 일시적으로 잠깐 넘었다 돌아오는 값에도 매번 알림.
- 상관분석이 없다 — DB 한 대가 죽으면 그에 의존하는 모든 서비스가 각자 알림을 쏴, 한 원인이 수십 건의 중복 알림이 됨.
해결 방향(노이즈를 줄이되, 신호는 살린다):
- 정보는 알림에서 빼고 기록으로 돌린다. 깨우는 알림은 경고·예외에만.
- 임계치를 '지속 조건'과 함께 건다 — "92퍼센트를 십 분 이상 지속" 같은 식으로, 순간 스파이크에 반응하지 않게.
- 상관분석(Correlation)으로 묶는다 — 시간·토폴로지·근본 원인이 같은 알림을 하나로 합쳐, "DB 다운 한 건"으로 보게 한다.
- 중복 억제(de-duplication) — 같은 알림이 반복되면 한 건으로 묶고 횟수만 누적.
알림 피로의 해법은 '알림을 끄는 것'이 아니라 **'알림을 정확하게 만드는 것'**입니다. 알림을 끄면 신호 자체가 사라지지만, 정확하게 만들면 적은 수의 알림이 모두 의미를 갖습니다. 운영자가 알림 하나하나를 신뢰할 수 있을 때, 비로소 모니터링은 제 역할을 합니다.

그림: 노이즈를 줄이되 신호는 살린다 — 정보 알림 제거·지속 조건 임계치·상관분석·중복 억제로 적은 알림이 모두 의미를 갖게 만든다.
이벤트·모니터링 관리는 운영(SM) 담당과 서비스데스크가 '수동적 신고 접수'에서 '능동적 사전 감지'로 넘어가는 지점입니다. 발주사·원청의 운영 담당자라면, 협력사(하도급) 엔지니어가 도구를 설치·운영하더라도, **"무엇을 모니터링하고, 임계치는 얼마이며, 어떤 알림을 누가 언제 받고, 알림 노이즈는 어떻게 관리하는가"**를 정의하고 점검하는 것은 관리자의 몫입니다.
현장에서 관리자가 실제로 던지는 질문은 이렇습니다. "핵심 서비스의 가용성·오류율·지연을 보고 있는가?" "경고 단계에서 예방 조치가 실제로 이뤄지는가, 아니면 늘 예외(장애) 단계에서야 움직이는가?" "알림 피로 때문에 진짜 알림을 놓치고 있지는 않은가?" 이 질문에 데이터로 답할 수 있는 운영 조직은 장애를 신고받기 전에 끄고, 그렇지 못한 조직은 늘 고객 전화로 장애를 알게 됩니다.
이 역량은 SLA(서비스 수준 협약)와도 직결됩니다. 가용성 99.9퍼센트를 약속했다면, 그 수치를 '측정'하는 것이 바로 모니터링이고, 위반 전조를 잡는 것이 이벤트 관리입니다. 보고서에 "이번 달 가용성 99.95퍼센트, 경고 12건 중 11건 예방 조치 완료"라고 쓸 수 있는 근거가 여기서 나옵니다.
관련 모듈로 더 깊이:
- 가용성·용량 관리 — 모니터링 데이터로 가용성·용량을 관리하는 활동
- 인시던트 관리 — 이벤트 감지에서 인시던트 대응으로 이어지는 흐름
- 서비스 수준 관리 — 모니터링이 측정하는 SLA 가용성·대응 지표
다음 모듈에서는 이렇게 모니터링으로 모은 데이터를 바탕으로, 서비스가 약속한 수준을 유지하도록 관리하는 가용성·용량 관리(서비스가 필요할 때 동작하고, 부하를 감당할 자원을 미리 확보하는 일)를 다룹니다.