같은 쇼핑몰, 두 번의 다운.
3월. 새벽 2시에 결제 서버가 멈췄습니다. 당직자가 알아채고 재시작하기까지 1시간. 다행히 한밤중이라 주문은 거의 없었지만, 사후 회의에서 누구도 "우리가 약속한 가용성이 얼마였는지" 답하지 못했습니다. 그냥 "어쩌다 한 번 그런 거죠"로 끝났습니다.
11월. 블랙프라이데이 정오, 평소 5배 트래픽이 몰리자 주문 서비스가 응답하지 않습니다. 서버는 살아 있는데 느린 겁니다. 부랴부랴 서버를 늘리려 했지만, 이미지 빌드·승인·반영에 40분이 걸렸고 그 사이 매출이 빠져나갔습니다. 회의에서 누군가 물었습니다. "이 정도 트래픽이 올 줄 정말 몰랐나요?"
두 사건의 공통점은 기술 실패가 아니라 약속과 예측의 부재입니다. 첫 번째는 "얼마나 떠 있기로 했는가"(가용성)를 정하지 않았고, 두 번째는 "얼마나 몰릴지"(용량)를 내다보지 않았습니다. 이 모듈은 이 두 가지 — 약속한 만큼 떠 있게 만드는 가용성 관리와, 모자라기 전에 늘리는 용량 관리 — 를 SLA와 비용의 균형 위에서 다룹니다.
- 1가용성을 가동/(가동+중단) 비율로 계산하고, 99%·99.9%·99.95%가 월 단위로 얼마의 다운타임을 허용하는지 환산할 수 있다
- 2단일장애점(SPOF)을 식별하고, 이중화(redundancy)·HA가 왜 SPOF 제거에서 출발하는지 설명할 수 있다
- 3MTBF·MTTR과 가용성의 관계를 식으로 이해하고, 가용성을 올리는 두 갈래(덜 고장·빨리 복구)를 구분할 수 있다
- 4수요 예측·성능 임계·확장(scale up/out)을 연결해 "모자라기 전에 늘리는" 용량 계획의 흐름을 설명할 수 있다
- 5가용성 목표와 용량 계획이 모두 "비용 대비 약속"이라는 점을 이해하고, 산출물(가용성 목표표·용량 계획표)을 작성할 수 있다
가용성 — "얼마나 떠 있기로 했는가"를 숫자로
가용성은 약속이고, 약속은 숫자다
서비스를 운영할 때 "우리 시스템은 안정적입니다"는 약속이 아닙니다. 측정할 수 없으면 지킬 수도, 어겼는지 따질 수도 없기 때문입니다. **가용성(Availability)**은 이 막연한 '안정'을 숫자로 바꾼 약속입니다.
가용성은 정해진 기간 동안 서비스가 정상 동작한 시간의 비율입니다.
가용성(%) = 가동 시간 / (가동 시간 + 중단 시간) × 100
예를 들어 한 달(720시간) 중 누적 3.6시간이 중단되었다면, 가용성은 (720 − 3.6) / 720 = 0.995, 즉 99.5%입니다. 이 숫자가 곧 고객과의 약속, 즉 SLA(서비스 수준 합의)의 핵심 항목이 됩니다.
여기서 함정은 "9의 개수"가 늘어날수록 허용 다운타임이 급격히 줄어든다는 점입니다. 99%와 99.9%는 한 글자 차이로 보이지만, 허용되는 멈춤 시간은 10배 차이 납니다. 그래서 가용성 목표는 "높을수록 좋다"가 아니라 "이 서비스에 그만한 돈을 쓸 가치가 있는가"의 문제입니다.
가용성 목표별 허용 다운타임 — 9 하나의 무게
아래는 같은 가용성 목표가 월(30일=43,200분)·연 단위로 얼마의 다운타임을 허용하는지 환산한 표입니다. 이 표는 가용성 관리의 산출물 1번입니다 — 목표를 정할 때 "그래서 한 달에 몇 분까지 멈춰도 되는가"를 모두가 같은 숫자로 보게 합니다.
| 가용성 목표 | 허용 다운타임(월, 30일 기준) | 허용 다운타임(연) | 통상적 쓰임새 |
|---|---|---|---|
| 99% | 약 7시간 18분 | 약 3.65일 | 내부 도구, 비핵심 배치 |
| 99.9% (three nines) | 약 43분 49초 | 약 8시간 46분 | 일반 사내·고객 웹서비스 |
| 99.95% | 약 21분 54초 | 약 4시간 23분 | 결제·주문 등 매출 직결 서비스 |
| 99.99% (four nines) | 약 4분 23초 | 약 52분 36초 | 금융 코어, 미션 크리티컬 |
| 99.999% (five nines) | 약 26초 | 약 5분 15초 | 통신 교환기 등 극한 영역 |
읽는 법: 목표를 한 칸 올릴 때마다 허용 다운타임은 대략 10분의 1로 줄어들고, 그만큼 이중화·자동화·인력 비용은 급격히 커집니다. 99.99%를 약속한다는 것은 "한 달에 단 4분만 멈춘다"는 뜻이며, 사람이 알아채고 손으로 복구하는 방식으로는 사실상 불가능합니다(자동 페일오버가 필수). 그래서 가용성 목표는 기술 결정이 아니라 비용·매출을 따지는 경영 결정에 가깝습니다.
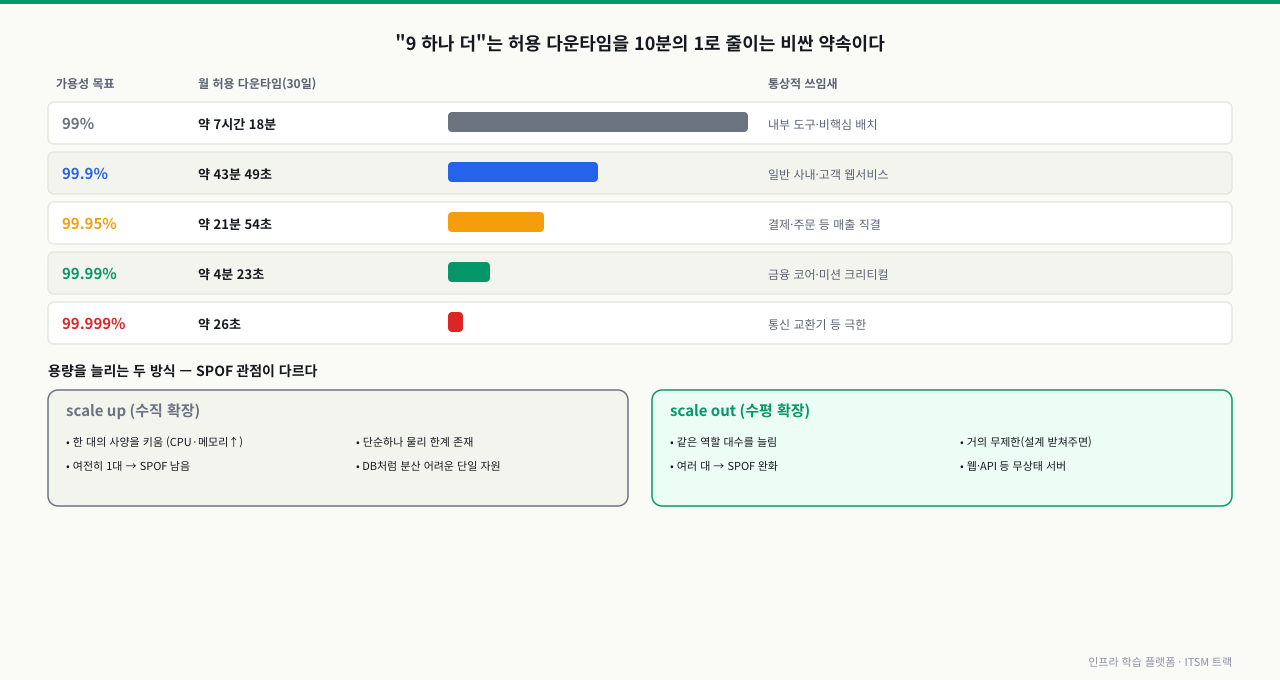
그림: "9 하나 더"는 허용 다운타임을 10분의 1로 줄이는 비싼 약속이고, scale out은 용량과 가용성(SPOF 완화)에 함께 기여한다.
가용성을 결정하는 것 — SPOF·이중화, 그리고 MTBF·MTTR
단일장애점(SPOF) — 가용성의 천장을 정하는 한 점
가용성을 떨어뜨리는 가장 흔한 원인은 **단일장애점(SPOF, Single Point Of Failure)**입니다. SPOF는 "그 하나가 죽으면 서비스 전체가 죽는" 구성요소입니다.
웹 서버를 2대로 늘리고 로드밸런서를 붙여도, 그 뒤의 DB가 1대뿐이면 DB가 SPOF입니다. 앞단을 아무리 두껍게 만들어도 서비스 전체의 가용성은 그 DB 한 대의 가용성에 묶입니다. 사슬의 강도는 가장 약한 고리가 정하듯, 가용성의 천장은 가장 약한 SPOF가 정합니다.
SPOF를 없애는 방법이 **이중화(Redundancy)**입니다. 같은 역할을 하는 구성요소를 둘 이상 두어, 하나가 죽어도 다른 하나가 받아내게 만듭니다. 그리고 "장애를 감지해 자동으로 살아 있는 쪽으로 넘기는" 구조까지 갖춘 것을 **HA(High Availability, 고가용성)**라고 부릅니다.
- 이중화: 같은 것을 둘 이상 둔다(DB 복제본, 전원 이중화).
- 페일오버(Failover): 주(active)가 죽으면 예비(standby)로 자동 전환한다.
- HA: 이중화 + 자동 감지·전환으로 "장애가 나도 사용자가 거의 모르게" 만든다.
핵심 순서는 항상 SPOF를 찾는 것이 먼저입니다. 어디가 약한 고리인지 모른 채 "서버를 더 사자"는 돈만 쓰고 가용성은 그대로일 수 있습니다.
MTBF·MTTR — 가용성을 올리는 두 개의 손잡이
가용성은 두 개의 시간으로 분해됩니다.
- MTBF(Mean Time Between Failures, 평균 무고장 시간): 한 번 고장 난 뒤 다음 고장까지 평균 얼마나 버티는가. 클수록 좋다(덜 고장 난다).
- MTTR(Mean Time To Repair, 평균 복구 시간): 고장 났을 때 정상으로 되돌리기까지 평균 얼마나 걸리는가. 작을수록 좋다(빨리 복구한다).
둘의 관계로 가용성을 다시 쓸 수 있습니다.
가용성 = MTBF / (MTBF + MTTR)
예: MTBF 200시간, MTTR 2시간이면 200/(200+2) ≈ 0.990, 즉 99%입니다. 여기서 MTTR을 2시간에서 0.2시간(12분)으로 줄이면 200/200.2 ≈ 0.999, 즉 99.9%로 올라갑니다. 똑같이 고장 나도 빨리 복구하면 가용성이 올라갑니다.
이것이 현장에서 중요한 이유: MTBF를 늘리는 일(더 안 고장 나게)은 부품·설계·테스트에 큰 투자가 들지만, MTTR을 줄이는 일(이중화·자동 페일오버·복구 자동화·런북)은 상대적으로 빠르게 효과를 냅니다. 그래서 가용성을 단기간에 끌어올려야 할 때, 운영자는 보통 MTTR을 먼저 공략합니다.
| 손잡이 | 방향 | 대표 수단 | 특징 |
|---|---|---|---|
| MTBF(무고장) | 키운다 | 품질 좋은 부품, 부하 여유, 변경 통제 | 효과 크지만 느리고 비쌈 |
| MTTR(복구) | 줄인다 | 이중화·자동 페일오버, 복구 자동화, 런북·모니터링 | 빠르게 가용성 상승 |
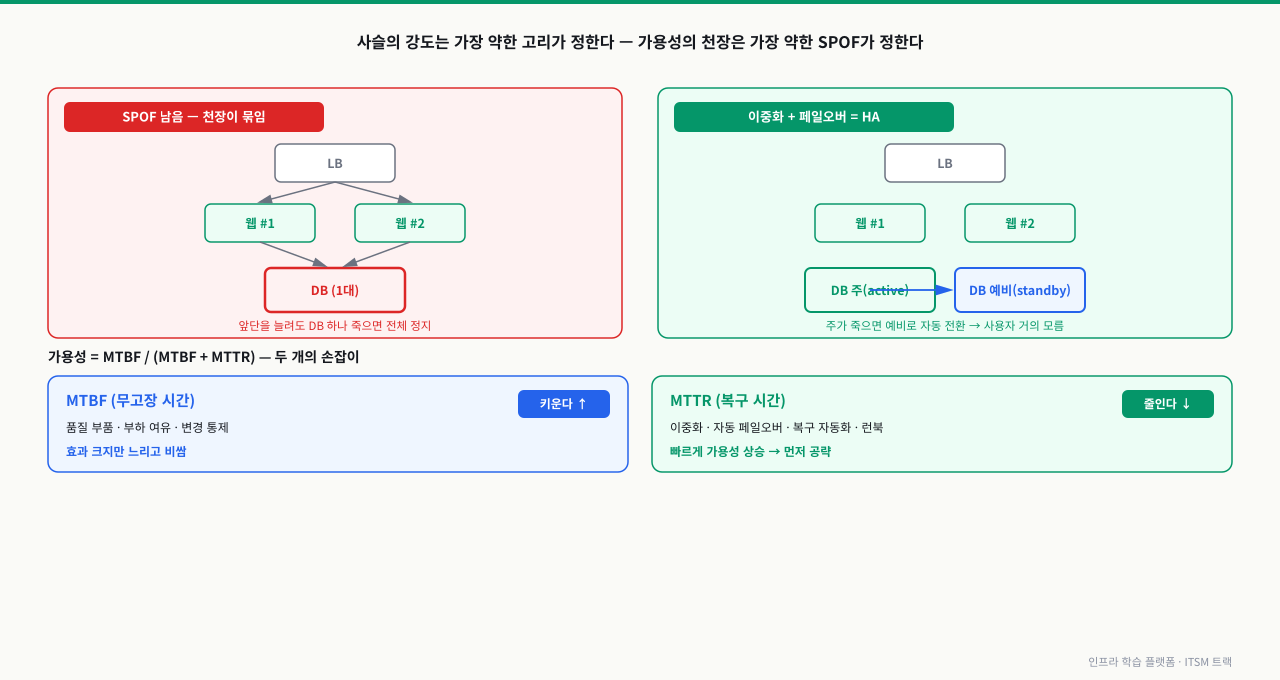
그림: 가용성의 천장은 가장 약한 SPOF가 정한다 — 약한 고리를 이중화·페일오버로 없애고, 가용성 = MTBF/(MTBF+MTTR)에서 단기엔 MTTR 단축을 먼저 공략한다.
용량 관리 — "모자라기 전에 늘린다"
용량 관리는 미래의 수요에 자원을 맞추는 일
가용성이 "약속한 만큼 떠 있는가"라면, **용량 관리(Capacity Management)**는 "수요만큼 받아낼 자원이 있는가"입니다. 서비스가 살아 있어도(가용성 OK) 트래픽이 자원을 넘어서면 느려지거나 거부되고, 결국 사용자에게는 장애처럼 보입니다. 블랙프라이데이에 멈춘 주문 서비스가 그 예입니다.
용량 관리의 목표는 한 문장입니다: 자원이 모자라기 전에, 그러나 너무 일찍 과하게 사지는 않으면서, 수요에 맞춰 자원을 준비한다. 모자라면 장애·매출 손실, 너무 많으면 놀고 있는 자원에 대한 낭비 — 그 사이의 균형을 잡는 일입니다.
흐름은 보통 이렇게 돕니다.
- 수요 예측(Demand): 비즈니스 이벤트(세일·프로모션·신규 고객 유입)와 추세를 근거로 "앞으로 얼마나 쓸지"를 내다본다.
- 성능 임계(Threshold): "이 수치를 넘으면 위험"이라는 선을 미리 정한다(예: CPU 70%, 응답시간 500ms). 100%에서 터지기 전에, 여유를 둔 선에서 신호를 받는다.
- 확장 결정(Scaling): 임계에 다가가면 자원을 늘린다 — 위로(scale up) 또는 옆으로(scale out).
- 비용 균형(Cost): 늘리는 데는 돈이 든다. 항상 과하게 두는 대신, 예측·자동 확장으로 "필요할 때 필요한 만큼"에 가깝게 맞춘다.
scale up vs scale out — 위로 키울까, 옆으로 늘릴까
자원을 늘리는 방법은 크게 두 가지이고, 둘은 성격이 다릅니다.
| 구분 | scale up(수직 확장) | scale out(수평 확장) |
|---|---|---|
| 방식 | 한 대의 사양을 키움(CPU·메모리↑) | 같은 역할의 대수를 늘림 |
| SPOF | 여전히 1대 → SPOF 남음 | 여러 대 → SPOF 완화 |
| 한계 | 한 대의 물리 한계까지만 | 사실상 무제한(설계만 받쳐주면) |
| 난이도 | 단순(끄고 사양 변경) | 로드밸런싱·상태 공유 설계 필요 |
| 잘 맞는 곳 | DB처럼 분산이 어려운 단일 자원 | 웹·API처럼 무상태(stateless) 서버 |
중요한 연결: scale out은 용량을 늘리면서 동시에 가용성(SPOF 완화)에도 기여합니다. 그래서 가용성과 용량은 따로 노는 주제가 아니라, 같은 아키텍처 결정의 두 얼굴인 경우가 많습니다. 다만 scale out은 "여러 대가 같은 데이터를 일관되게 보게" 만드는 설계가 따라야 하고, scale up은 단순하지만 한 대의 천장과 SPOF가 남습니다. 용량 계획은 비용·아키텍처 제약에 맞춰 둘을 섞습니다.
직접 해보기 — 가용성 환산과 용량 계획표 작성
종이나 메모장에 직접 계산해 보세요. 계산기만 있으면 됩니다.
[상황]
- 주문 서비스의 SLA 목표: 월 가용성 99.9%
- 지난달 실측: 한 번 장애, MTBF 360시간, MTTR 3시간
- 한 달 = 720시간 = 43,200분
[풀 것]
1. 실측 가용성 = 360 / (360 + 3) = ? (%로)
2. 99.9% 목표의 월 허용 다운타임 = 43,200 × 0.001 = ? 분
3. 이번 달 실제 다운타임(MTTR 3시간 = 180분)은 목표를 지켰는가?
4. 지키지 못했다면, MTTR을 몇 분까지 줄였어야 했는가?
힌트: 목표 다운타임(분)을 먼저 구하고, 실제 다운타임과 비교하세요. SLA를 어겼다면 "덜 고장(MTBF↑)"보다 "빨리 복구(MTTR↓)"가 더 빠른 처방이라는 점을 떠올리면 됩니다.
가용성 = MTBF / (MTBF + MTTR)다음 항목으로 주문 서비스의 **용량 계획표(산출물 2번)**를 작성해 보세요. 빈칸을 자기 가정으로 채우면 됩니다.
[용량 계획 항목]
- 대상 자원 : 예) 주문 API 서버
- 현재 용량 : 예) 4대 (각 CPU 4코어)
- 측정 지표 : 예) CPU 사용률, 평균 응답시간
- 성능 임계(경고/위험): 예) CPU 70% / 85%
- 수요 예측 근거 : 예) 다음 분기 가입자 +30%, 블프 정오 평소 5배
- 확장 방식 : 예) scale out (무상태 서버라 대수 증설)
- 확장 트리거 : 예) 5분 평균 CPU 70% 초과 시 +2대
- 예상 비용 : 예) 1대당 월 X만 원 × 증설 대수
- 검토 주기 : 예) 분기 1회 + 대형 이벤트 직전
수요 예측 → 임계 → 확장 방식 → 비용- 실측 가용성 = 360/363 ≈ 0.99174 → 약 99.17%. 목표 99.9%에 미달했다
- 99.9%의 월 허용 다운타임 = 43,200 × 0.001 = 43.2분. 실제는 180분이었으니 약 4배 초과 — SLA 위반
- SLA를 지키려면 한 번 장애 시 MTTR을 약 43분 이내로 줄였어야 한다(자동 페일오버·복구 자동화가 답). 고장 횟수를 줄이는 것보다 복구 시간 단축이 더 직접적인 처방
- 용량 계획표의 핵심은 "임계(70/85%)를 100%보다 낮게 잡아 여유를 두는 것" — 터지기 전에 신호를 받아야 모자라기 전에 늘릴 수 있다
- 확장 트리거를 미리 정해두면, 블랙프라이데이에 "지금 늘릴까 말까"를 회의로 결정하지 않고 자동/사전 합의된 기준으로 움직일 수 있다
- 핵심 감각: 가용성은 "약속한 시간만큼 떠 있게", 용량은 "약속한 부하만큼 받아내게" — 둘 다 사후 대응이 아니라 사전 약속·예측의 문제다
현장에서 자주 보는 함정
증상: (1) "가용성을 올리겠다"며 웹 서버를 2배로 늘렸는데 SLA 위반이 계속된다. (2) 평소 CPU는 30%로 한가한데, 프로모션만 시작하면 응답이 느려지고 타임아웃이 난다.
원인:
- (1) 가용성 문제와 용량 문제를 혼동했습니다. 웹 서버를 늘려도 그 뒤 DB가 SPOF로 남아 있으면 가용성의 천장은 그대로입니다. 늘려야 할 곳은 약한 고리(SPOF)이지, 이미 충분한 앞단이 아닙니다.
- (2) 평균값에 속았습니다. **평소 평균 CPU 30%**는 "여유 있다"가 아니라 "피크를 못 보고 있다"는 신호일 수 있습니다. 이벤트 정오의 순간 피크는 100%를 치고 있는데, 하루 평균으로 뭉개면 안 보입니다. 용량은 평균이 아니라 피크와 추세로 계획해야 합니다.
해결 방향(이 트랙·인접 모듈에서 깊어짐):
- 먼저 SPOF를 그려서 찾는다 — 구성도에서 "이게 죽으면 다 죽나?"를 지점마다 묻는다. 가용성은 그 약한 고리부터.
- 가용성이 부족하면 이중화·MTTR 단축, 용량이 부족하면 scale up/out — 둘을 먼저 구분한다.
- 용량은 피크·추세 기반으로 예측하고, 임계(70/85%)를 여유 있게 잡아 모자라기 전에 신호를 받는다.
- 확장 트리거와 비용을 계획표로 미리 합의해, 이벤트 당일 즉흥 결정에 의존하지 않는다.
가용성·용량은 운영(SM) 담당자와 프로젝트·서비스 관리자가 발주사·협력사와 가장 자주 부딪히는 숫자입니다. SLA 협상 테이블에서 "99.9%로 합시다"는 한마디가 곧 "월 43분까지만 멈출 수 있고, 그걸 지키려면 이중화·자동화에 이만큼 든다"는 비용 약속이라는 것을 아는 관리자와, 분위기로 "최대한 안정적으로"라고 적는 관리자는 결과가 완전히 다릅니다.
이런 자리에서 당신은 직접 서버를 이중화하기보다, "이 서비스는 가용성 몇 %가 적정한가, 그 비용은 매출에 비해 타당한가, 다가올 이벤트에 용량은 충분한가" 를 판단하고 협력사에 요구사항으로 내립니다. 협력사 엔지니어가 "서버 늘리면 됩니다"라고 할 때, "그건 용량 문제 답이지 SPOF는 그대로 아닌가요?"라고 되물을 수 있는 관리자는 잘못된 보고에 속지 않습니다.
그래서 이 모듈의 산출물 두 가지 — 가용성 목표·허용 다운타임 표와 용량 계획표 — 는 단순 연습이 아니라, 실무에서 SLA 합의서·운영 이관 문서·증설 품의에 그대로 들어가는 양식입니다. 숫자로 약속하고 숫자로 검증하는 습관이 관리 직무의 신뢰를 만듭니다.
관련 모듈로 더 깊이:
- 서비스 연속성·재해복구(DR) — 평상시 가용성을 넘어 재해 시 복구를 설계하는 연속성·DR
- 서비스 수준 관리 — 가용성 목표가 곧 비용 약속이 되는 SLA의 구조
- 이벤트·모니터링 관리 — 가용성·용량 지표를 실제로 측정하는 모니터링
다음 모듈에서는 평상시의 가용성·용량을 넘어, 재해처럼 큰 사고가 났을 때도 서비스를 이어가기 위한 서비스 연속성·DR(재해복구) — RTO·RPO와 백업·복구 전략 — 를 다룹니다.