금요일 오후 4시 12분, 운영팀 채널에 메시지가 뜹니다.
"고객사 A에서 전화 왔습니다. 전자서명 로그인이 안 된다고요. 계약 마감이 오늘 6시랍니다."
당신은 SaaS 전자서명 서비스의 운영(SM) 담당입니다. 화면을 열어 보니 서비스 자체는 살아 있습니다 — 당신 계정으로는 로그인이 됩니다. 다른 고객사도 멀쩡합니다. 그런데 고객사 A의 담당자는 "우리 팀 절반이 못 들어온다"고 합니다.
여기서 두 갈래로 길이 갈립니다. 한쪽은 곧바로 인증 서버에 붙어 이것저것 만지다가, 고객에게는 "확인 중입니다"만 반복하다 6시를 넘깁니다. 다른 한쪽은 티켓을 열고, 영향도와 긴급도로 우선순위를 정하고, "누구는 되고 누구는 안 되는가"로 구간을 좁히고, 고객에게는 다음 안내 시각을 약속하고, 복구 뒤 장애보고서와 재발방지대책까지 남깁니다.
이 모듈은 그 두 번째 길을 처음부터 끝까지 같이 걸어 봅니다. 지금까지 이 트랙에서 따로 배운 인시던트 관리·우선순위·구간 분리·고객 커뮤니케이션·장애보고서·RCA가 하나의 사건 위에서 어떻게 연결되는지를 봅니다.
- 1하나의 실제 장애를 접수부터 재발방지까지 9단계 흐름으로 끝까지 끌고 갈 수 있다
- 2영향도와 긴급도를 분리해 판단하고, 부분 영향이라도 핵심 기능이면 우선순위를 높이는 논리를 설명할 수 있다
- 3"되는 사용자 vs 안 되는 사용자"의 차이로 구간을 좁히는 분리 질문을 직접 만들 수 있다
- 4고객에게는 무엇을·언제·다음 안내 시각을 약속하는 중간 안내문을, 내부에는 구체적 확인 요청을 작성할 수 있다
- 5장애 타임라인 표·장애보고서·재발방지대책 표를 실제 값으로 채워 한 사건의 산출물 세트를 완성할 수 있다
한 사건을 관통하는 9단계
따로 배운 것들이 한 줄로 꿰어진다
이 트랙에서 인시던트 관리, 우선순위·에스컬레이션, 구간 분리, 장애보고서, RCA를 각각의 모듈로 배웠습니다. 실무에서는 이것들이 따로 오지 않습니다 — 하나의 전화에서 시작해 한 흐름으로 이어집니다. 그 흐름을 9단계로 고정해 두면, 처음 겪는 장애에서도 "다음에 뭘 해야 하지"를 헤매지 않습니다.
| 단계 | 하는 일 | 어느 모듈의 적용인가 |
|---|---|---|
| ① 접수 | 신고를 티켓으로 기록(누가·언제·무엇을) | 인시던트 관리 |
| ② 우선순위 | 영향도 × 긴급도로 P등급 결정 | 우선순위·에스컬레이션 |
| ③ 구간 분리 | "되는 것 vs 안 되는 것"으로 원인 구간 좁힘 | 장애 구간 분리 |
| ④ 고객 안내 | 확인 질문 + 다음 안내 시각 약속(중간 보고) | 이해관계자 커뮤니케이션 |
| ⑤ 내부 확인 요청 | 의심 구간 담당자에게 구체적 요청 | 에스컬레이션·문서 |
| ⑥ 복구 | 임시 복구로 서비스 정상화 | 인시던트 관리 |
| ⑦ 타임라인 | 발생·인지·조치·복구 시각 정리 | 장애보고서 |
| ⑧ 장애보고서 | 요약·영향·원인·조치를 한 장으로 | 장애보고서 작성 |
| ⑨ 재발방지 | 근본 원인 제거 대책을 책임자·기한과 함께 | RCA·문제관리 |
①⑥은 "지금 이 불을 끄는" 인시던트 흐름이고, ⑦⑨는 "다시 안 나게 하는" 문제·문서 흐름입니다. 둘을 섞지 않는 것이 핵심입니다 — 복구를 서두르다 기록을 놓치면 ⑨가 비고, 원인 분석을 핑계로 복구를 미루면 고객이 6시를 넘깁니다.
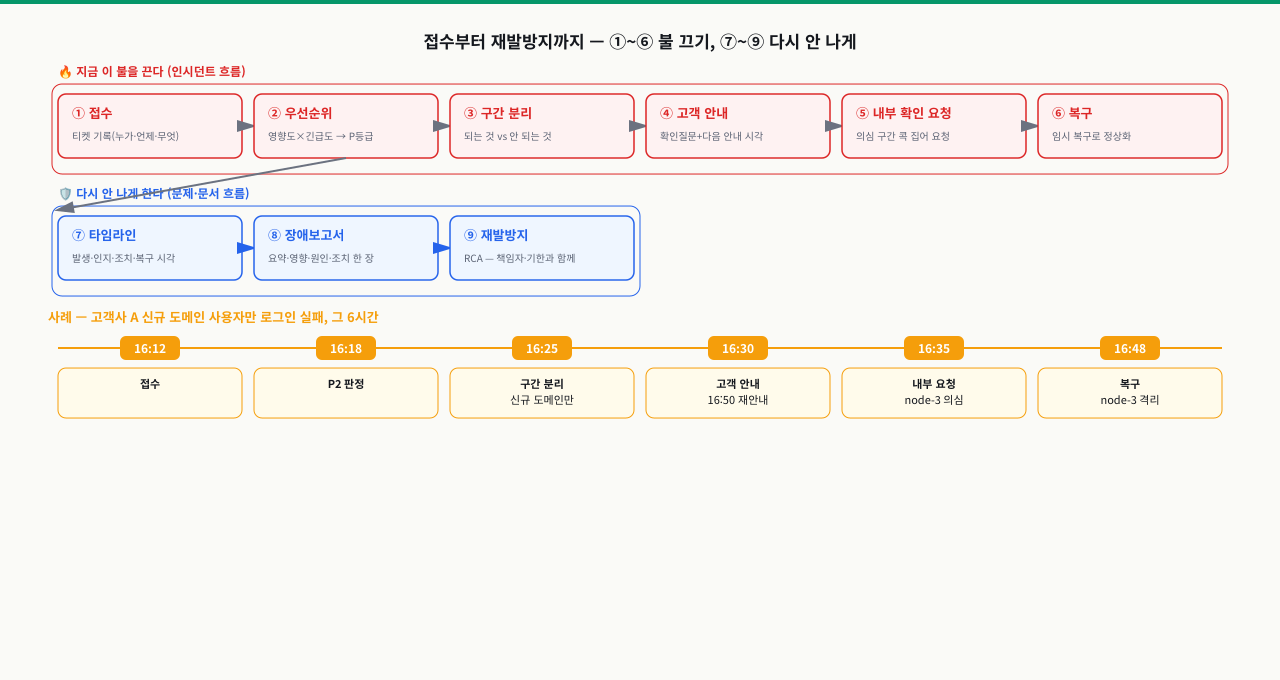
그림: ①⑥은 지금 불을 끄고 ⑦⑨는 다시 안 나게 하며, 아래 6시간 타임라인이 그 흐름의 실제 적용이다.
사건의 전개 — 시간 순서로
고객사 A 일부 사용자 로그인 실패, 그 6시간
사건을 시간 순서로 따라가며 각 단계에서 무엇을 판단했는지 봅니다.
16:12 접수. 고객사 A 담당자의 전화. 티켓을 엽니다. 제목은 "고객사 A 일부 사용자 전자서명 로그인 실패", 신고자·연락처·신고 시각·증상(로그인 후 흰 화면, 일부 사용자)을 그대로 적습니다. 이때 추측("아마 세션 문제")은 적지 않습니다 — 사실과 추정을 섞으면 나중에 타임라인이 오염됩니다.
16:18 우선순위. 서비스 전체는 정상이니 영향도는 '부분'입니다. 그러나 전자서명은 계약 체결을 막는 핵심 기능이고, 고객사 A는 오늘 6시 마감이라 긴급도가 높습니다. 영향도 부분 × 긴급도 높음 → P2로 정하되, 마감 데드라인이 명확하므로 리더에게 즉시 공유(에스컬레이션 예고)합니다.
16:25 구간 분리. "고객사 A의 누구는 되고 누구는 안 되는가"를 묻습니다. 확인 결과: 신규 도메인(@a-corp.kr)으로 가입한 사용자만 실패, 기존 도메인(@acorp.com) 사용자는 정상. 이 한 줄이 범위를 크게 줄입니다 — 인증 자체가 죽은 게 아니라 특정 도메인의 SSO 연동 구간이 의심됩니다.
16:30 고객 안내. 고객에게 확인 질문(어떤 계정이 실패하는지 2~3개 예시)과 함께, "원인 구간을 좁혔고, 16:50에 다시 안내드리겠다"는 다음 안내 시각을 약속합니다. 막연한 "확인 중"이 아니라 시각을 못 박는 것이 신뢰를 만듭니다.
16:35 내부 확인 요청. 인증 담당에게 "신규 SSO 도메인 @a-corp.kr이 어제 변경됐는지, 인증 노드 중 특정 노드만 신규 도메인 설정이 누락됐는지"를 콕 집어 요청합니다. "로그인 좀 봐주세요"가 아니라 의심 구간을 지정합니다.
16:48 원인 확인·복구. 어제 오전 인증 노드 3대 중 1대(node-3)에 신규 도메인 매핑 배포가 누락됐고, 로드밸런서가 사용자를 분산하다 node-3에 걸린 사용자만 실패한 것으로 확인됩니다. 임시 복구로 node-3를 풀에서 격리하니 즉시 정상화. 16:50 고객에게 정상화와 추후 보고를 안내합니다.
16:52 이후. 인시던트는 닫지 않고, 타임라인을 정리하고 장애보고서를 쓰고, node-3 누락의 근본 원인(배포 검증 부재)을 문제로 등록합니다.
직접 해보기 — 단계별 산출물 작성
위 사건을 보고, 접수 티켓의 핵심 5요소를 추측 없이 사실만으로 채워 보세요. 정답 예시는 ObserveBlock에 있습니다.
- 신고자 / 연락처:
- 신고 시각:
- 증상(관찰된 사실만):
- 영향 범위(누가/어디까지):
- 긴급도 판단 근거:
티켓: 신고자 / 시각 / 증상 / 영향 / 긴급도"로그인이 안 된다"를 좁히기 위해, 되는 사용자와 안 되는 사용자를 가르는 질문 3개를 써 보세요. 좋은 질문은 답이 곧바로 범위를 줄입니다(예: 도메인·브라우저·네트워크·시간대·권한 그룹).
질문: 되는 것과 안 되는 것을 가르는가?사건의 사실을 바탕으로, 아래 세 산출물을 실제 값으로 완성하는 것이 이 캡스톤의 최종 목표입니다. 완성 예시는 다음 섹션에 있습니다 — 먼저 스스로 채운 뒤 비교하세요.
- 장애 타임라인 표(발생·인지·조치·복구 시각)
- 장애보고서 요약(증상·영향·원인·조치)
- 재발방지대책 표(대책·책임자·기한)
산출물 3종 세트 완성- 접수 티켓 예시 — 신고자: 고객사 A 김OO 차장 / 시각: 16:12 / 증상: 로그인 후 흰 화면, A사 일부 사용자 / 영향: 서비스 전체 정상, A사 신규 도메인 사용자에 국한 / 긴급도: 당일 18:00 계약 마감으로 높음
- 좋은 구간 분리 질문 예시 — (1) "되는 분과 안 되는 분의 이메일 도메인이 다른가요?" (2) "특정 브라우저에서만 그런가요, 전부 그런가요?" (3) "어제까지는 되던 분도 오늘 안 되나요?"(변경 시점 추적)
- 나쁜 질문 예시 — "서버 상태가 어떤가요?"(고객이 답할 수 없는 관리자 영역), "급하신가요?"(우선순위는 우리가 영향×긴급도로 판단)
- 복구는 node-3 격리(임시)였고, 근본 복구(배포 누락 방지)는 재발방지대책으로 분리한다 — 임시와 근본을 섞지 않는 것이 핵심
- 타임라인에 발생(어제 오전 배포)과 인지(16:12 고객 신고)의 간격이 크다 = 우리가 늦게 알았다 = 모니터링 개선 항목이 도출된다

이 사건을 다룬 방식의 핵심은 두 가지입니다. 접수는 추측 없이 사실 5요소(신고자·시각·증상·영향·긴급도 근거)로 채우고, 좁히기는 되는 쪽과 안 되는 쪽을 가르는 질문으로 합니다. 위 그림 오른쪽처럼 "도메인이 다른가요? 특정 브라우저만인가요? 어제는 되던 분도 안 되나요?"는 답이 곧바로 모집단을 절반으로 가르지만, "서버 상태가 어떤가요?"(고객이 답할 수 없음)나 "급하신가요?"(우선순위는 우리가 영향×긴급도로 판단)는 범위를 줄이지 못합니다.
완성된 산출물 세트
세 산출물을 실제 값으로 채우면 이렇게 됩니다. 이것이 한 사건을 책임 있게 마감한 증거 묶음입니다.
장애 타임라인
| 시각 | 구분 | 내용 |
|---|---|---|
| 어제 09:40 | 발생(원인 유입) | 인증 노드 신규 도메인 매핑 배포 시 node-3 누락 |
| 16:12 | 인지 | 고객사 A 신고로 최초 인지(자체 탐지 실패) |
| 16:18 | 분류 | 인시던트 P2 지정, 리더 공유 |
| 16:25 | 구간 분리 | 신규 도메인(@a-corp.kr) 사용자만 실패 확인 |
| 16:35 | 에스컬레이션 | 인증 담당에 node별 도메인 설정 점검 요청 |
| 16:48 | 원인 확정 | node-3 도메인 매핑 누락 확인 |
| 16:50 | 복구 | node-3 풀 격리, 로그인 정상화 |
| 17:30 | 근본 복구 | node-3 매핑 재배포·검증 후 풀 복귀 |
장애보고서 (요약)
| 항목 | 내용 |
|---|---|
| 증상 | 고객사 A 신규 도메인(@a-corp.kr) 사용자 로그인 실패(로그인 후 흰 화면) |
| 영향 | 서비스 전체 정상. A사 신규 도메인 약 18명 한정, 38분간(16:12~16:50) 로그인 불가 |
| 근본 원인 | 인증 노드 도메인 매핑 배포가 node-3에 누락. LB가 분산한 사용자 중 node-3에 걸린 신규 도메인 사용자만 실패 |
| 조치 | (임시) node-3 풀 격리로 즉시 정상화 → (근본) node-3 매핑 재배포·검증 후 복귀 |
| 탐지 공백 | 발생(어제)과 인지(고객 신고)의 간격 큼. 인증 실패율 알람 부재 |
재발방지대책
| 대책 | 유형 | 책임자 | 기한 |
|---|---|---|---|
| 인증 노드 도메인 매핑 배포 후 전 노드 일관성 자동 검증 추가 | 근본(배포) | 인증팀 박OO | 6/30 |
| 노드별 인증 실패율 알람 설정(임계 초과 시 자동 통보) | 탐지 개선 | 모니터링팀 이OO | 6/27 |
| 신규 도메인 온보딩 시 전 노드 적용 체크리스트 도입 | 프로세스 | SM팀 본인 | 6/25 |
| 고객사 A 대상 사과·경위 안내 및 마감 영향 확인 | 커뮤니케이션 | SM팀 본인 | 6/20 |
타임라인이 사실을, 장애보고서가 해석을, 재발방지대책이 약속을 담습니다. 세 장이 모이면 "잘 처리했다"는 말이 아니라 증거가 됩니다.
현장에서 자주 보는 함정
증상: (1) node-3를 격리해 로그인이 되자 안도하며 티켓을 종료합니다. 누락 배포라는 근본 원인은 그대로 남아, 다음 도메인 온보딩 때 같은 장애가 재발합니다. (2) 복구하는 동안 고객에게는 "확인 중입니다"만 세 번 보냈고, 고객은 마감이 다가올수록 불안에 전화를 반복합니다.
원인: (1) 인시던트(빠른 복구)와 문제(근본 제거)를 분리하지 못했습니다. 임시 복구를 근본 해결로 착각한 것입니다. (2) 중간 안내의 핵심인 다음 안내 시각 약속이 빠졌습니다. 정보가 없을 때도 "16:50에 진행 상황을 다시 알려드리겠습니다"가 신뢰를 지킵니다.
해결 방향:
- 복구 후에도 티켓을 유지하고, 근본 원인을 문제(Problem)로 등록 → 재발방지대책에 책임자·기한을 박는다.
- 임시 복구와 근본 복구를 타임라인에 따로 적는다(16:50 임시 / 17:30 근본).
- 고객 안내는 매번 "무엇을 알아냈고 / 무엇을 하고 있고 / 다음에 언제 알려줄지" 세 줄로 보낸다.
- 발생과 인지의 간격을 보고 탐지 개선(실패율 알람)을 재발방지에 반드시 포함한다.
이 함정을 피하면, 같은 사건이 두 번 일어나지 않고 고객은 "이 팀은 통제되고 있다"고 느낍니다.
한국의 SaaS·SI 운영(SM) 현장에서 이 9단계 흐름은 곧 당신의 평판입니다. 발주사·고객사는 장애 자체보다 장애를 다루는 방식으로 협력사를 평가합니다 — 얼마나 빨리 영향을 파악했는가, 고객에게 약속한 시각을 지켰는가, 장애보고서가 책임 회피 없이 명확한가, 재발방지대책이 말뿐이 아니라 책임자·기한이 있는가.
운영관리자·기술지원·서비스데스크·PM/PMO 자리에서 당신은 직접 node-3를 만지는 사람이 아닐 수 있습니다. 그러나 접수·우선순위·구간 분리 질문·고객 안내·내부 요청·복구 판단·타임라인·보고서·재발방지를 설계하고 통제하는 사람입니다. 협력사 엔지니어가 손을 움직이더라도, "이 장애가 무엇이고 누가 언제까지 무엇으로 막는가"의 한 장은 관리자가 씁니다. 이 캡스톤에서 채운 세 산출물(타임라인·장애보고서·재발방지대책)은 면접에서 "장애를 어떻게 다루느냐"는 질문에 말이 아니라 양식으로 답하게 해 줍니다.
기술을 아는 관리자는 "신규 도메인 사용자만 실패한다"는 한 줄에서 SSO 노드 불일치를 의심할 수 있고, 그래서 협력사와 대등하게 대화하며 잘못된 보고에 속지 않습니다. 이것이 이 트랙 전체가 향한 지점입니다.
관련 모듈로 더 깊이:
- 인시던트 관리 — 접수·분류·해결의 인시던트 관리 기본 절차
- 메이저 인시던트와 워룸 — 대형 장애에서 워룸을 꾸리고 통제하는 법
- 장애보고서 작성 — 캡스톤에서 만든 타임라인·장애보고서를 양식으로 다듬기
다음 모듈에서는 계획된 작업이 사고로 번지는 반대편 — 정기 보안 패치를 적용하는 운영 패치 PM 시뮬레이션을 다룹니다. 점검창 공지·승인(CAB)·롤백 계획·작업 후 검증까지, 변경(Change)을 사고 없이 통제하는 흐름을 한 사건으로 종합합니다.