새벽 2시 14분, 결제 서비스가 멈췄습니다. 운영팀은 2시 41분에 인지해 3시 20분에 복구했습니다. 다음 날 오전, 발주사 IT팀장이 보고서를 요구합니다.
운영자 A는 메신저에 적던 말투 그대로 보냅니다. "어제 결제 죽어서 재시작했고 지금 정상입니다. 원인은 아마 DB 커넥션 문제 같습니다." 팀장이 되묻습니다. "몇 시부터 몇 시까지 안 됐나? 그동안 결제 몇 건이 실패했나? '아마'면 확실한 건가? 또 안 난다는 보장은?" 답할 게 없습니다.
운영자 B는 한 장으로 정리합니다. 발생 02:14 / 인지 02:41 / 복구 03:20, 영향은 그 66분간 결제 시도 약 240건 실패(전 고객), 조치는 DB 커넥션 풀 소진 확인 후 결제 서비스 재기동(임시 복구), 근본원인은 커넥션 누수로 추정되나 정밀 분석은 RCA 별도 진행, 재발방지는 커넥션 풀 모니터링 알람 추가 + 누수 코드 점검(담당·기한 명시). 팀장은 더 물을 게 없습니다.
둘의 차이는 성실함이 아니라 구조입니다. 장애보고서에는 반드시 들어가야 할 칸이 있고, 그 칸을 사실과 추정을 구분해 채우면 누가 봐도 같은 그림이 그려집니다. 이 모듈은 그 한 장을 만드는 법을 다룹니다.
- 1장애보고서의 목적(고객 신뢰 회복·재발방지·사건 기록)을 설명하고, 왜 "처리했습니다" 한 줄로는 부족한지 말할 수 있다
- 2장애보고서의 표준 구성(개요·시각·영향·타임라인·조치·복구·원인·재발방지·향후계획)을 빠짐없이 채울 수 있다
- 3확인된 사실과 검증 안 된 추정을 구분해 표기하고, 원인 미상일 때 "조사중"을 정직하게 쓸 수 있다
- 4발생·인지·복구 시각으로 타임라인을 만들고, 거기서 지속시간·미인지시간 같은 지표가 왜 나오는지 설명할 수 있다
- 5같은 장애를 고객용(간결·재발방지 중심)과 내부용(기술 상세)으로 깊이를 달리해 작성할 수 있다
장애보고서는 왜 쓰는가
보고서의 세 가지 목적 — 신뢰·재발방지·기록
장애를 끄는 것과 장애보고서를 쓰는 것은 다른 일입니다. 불은 껐는데 보고서가 부실하면, 고객은 "이 회사가 통제하고 있나"를 의심합니다. 장애보고서는 단순 사후 행정이 아니라 세 가지 목적을 동시에 수행하는 산출물입니다.
| 목적 | 무엇을 위한 것인가 | 부실할 때 생기는 일 |
|---|---|---|
| 신뢰 회복 | 고객·경영진에게 "통제되고 있다"를 보여줌 | "재시작했어요" 한 줄 → 불안·추가 추궁·계약 리스크 |
| 재발방지 | 같은 장애가 다시 안 나게 대책·담당·기한을 약속 | 원인·대책이 없으면 다음 주 같은 장애 재발 |
| 사건 기록 | 조직의 자산으로 남겨 패턴 분석·인수인계·감사 대비 | 기록이 없으면 반복 패턴이 안 보이고 문제관리 불가 |
핵심은 **"무엇을 했는가"가 아니라 "무슨 일이 있었고, 어떤 영향을 줬고, 다시 안 나게 무엇을 하는가"**를 쓰는 것입니다. 고객이 알고 싶은 건 당신이 키보드를 얼마나 빨리 쳤는지가 아니라, 자기 비즈니스가 얼마나 멈췄고 또 멈출지입니다.
표준 구성 — 한 장에 들어가야 할 칸
장애보고서는 자유 작문이 아니라 정해진 칸을 채우는 양식입니다. 칸이 정해져 있어야 누가 써도 빠지는 정보가 없고, 받는 사람도 어디에 무엇이 있는지 압니다. 표준 구성은 다음과 같습니다.
| 섹션 | 담는 내용 | 작성 포인트 |
|---|---|---|
| 개요(요약) | 한 문단으로 "무엇이·언제·얼마나·지금 상태" | 바쁜 경영진은 이 한 문단만 읽는다 |
| 발생/인지 시각 | 장애 발생 시각, 우리가 인지한 시각 | 분 단위로, 추정이면 추정 표시 |
| 영향 범위 | 영향받은 서비스·고객 수·실패 건수·금액 | "전 고객" vs "일부" 명확히 |
| 타임라인 | 발생→인지→조치→복구의 시각별 흐름 | 시각 + 행동을 시간순으로 |
| 조치 내역 | 인지 후 취한 행동들(에스컬레이션 포함) | "누가 무엇을" 구체적으로 |
| 복구 | 복구 시각, 복구 방법(임시/영구), 검증 | 임시 복구인지 영구 해결인지 구분 |
| 근본원인 | 왜 발생했나 (또는 "조사중") | 확정/추정 구분, 모르면 정직하게 |
| 재발방지 대책 | 다시 안 나게 할 구체 조치 | 담당자·기한 반드시 |
| 향후 계획 | RCA 일정, 후속 보고 시점 | "추가 보고 예정일" 명시 |
이 칸들을 모두 채우면, 처음 보는 사람도 "사건의 전말과 앞으로의 약속"을 한눈에 이해합니다. 칸이 비어 있어도 됩니다 — 단, "조사중", "확인 예정"처럼 비어 있는 이유를 적어야 합니다. 빈칸을 침묵으로 두는 것과 "조사중"으로 명시하는 것은 신뢰에서 큰 차이입니다.
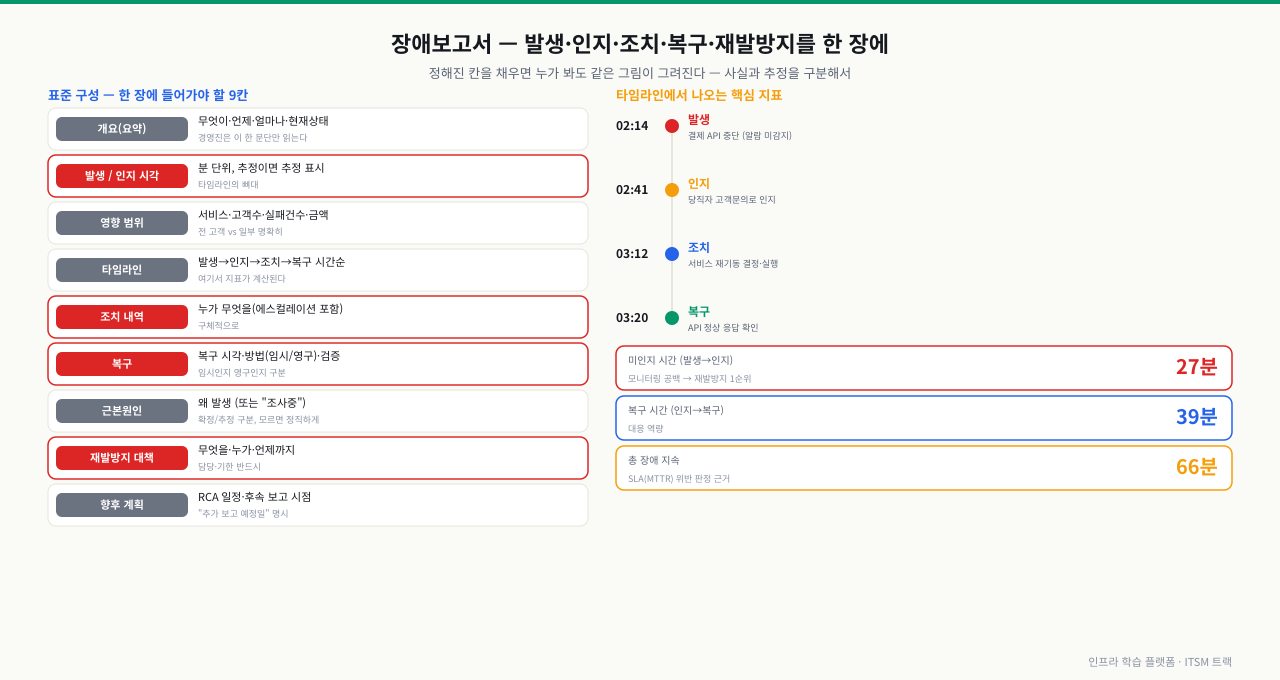
그림: 정해진 9칸을 채우면 누가 봐도 같은 그림이 그려지고, 시각으로 만든 타임라인에서 SLA 판정과 재발방지 우선순위가 자동으로 나온다.
장애보고서 — 빈 양식·작성 예시 다운로드
사실과 추정을 가르는 선 — 보고서 신뢰의 핵심
장애 직후에는 원인을 확신하기 어렵습니다. 그런데 보고서에서 가장 위험한 실수는 추정을 사실처럼 단정하는 것입니다. "DB 커넥션 누수 같습니다"를 "DB 커넥션 누수입니다"로 적는 순간, 그 추정은 조직 안에서 사실로 굳어집니다.
- 잘못된 추정이 사실로 굳으면 → 엉뚱한 곳에 재발방지 자원을 쓰고, 진짜 원인은 그대로 남아 재발합니다.
- 나중에 진짜 원인이 다르면 → 보고서를 정정해야 하고, 고객은 "그럼 처음 보고는 뭐였나"라며 신뢰를 거둡니다.
그래서 보고서는 확인된 사실과 현재 추정/가설을 명시적으로 분리합니다.
| 구분 | 예시 표현 | 성격 |
|---|---|---|
| 확인된 사실 | "02:41에 결제 API 5xx 급증을 모니터링에서 확인" | 로그·시각·관측치로 검증됨 |
| 확인된 사실 | "결제 서비스 재기동 후 03:20에 정상 응답 복구" | 행동과 결과가 관측됨 |
| 현재 추정 | "원인은 커넥션 풀 소진으로 추정, 누수 여부는 RCA에서 검증 예정" | 아직 검증 안 된 가설 |
추정을 쓰지 말라는 게 아닙니다. 추정은 추정이라고 밝혀 쓰는 것이 핵심입니다. "현재까지 파악된 바로는", "추정되며", "조사중"이라는 단어가 보고서의 정직함을 지킵니다.
타임라인이 보고서의 뼈대인 이유
타임라인은 장식이 아니라 보고서에서 지표가 계산되는 원천입니다. 시각을 분 단위로 적으면 거기서 핵심 숫자가 자동으로 나옵니다.
- 발생 → 인지 간격 = 우리가 얼마나 늦게 알았나. 길면 모니터링·알람 문제입니다.
- 인지 → 복구 간격 = 얼마나 빨리 껐나. 대응 역량과 절차의 문제입니다.
- 전체 장애 지속시간 = 고객이 실제로 멈춰 있던 시간. SLA의 복구목표시간(MTTR) 위반 여부가 여기서 판정됩니다.
02:14 발생 결제 API 응답 중단 (모니터링 미감지)
02:41 인지 당직자가 고객 문의로 인지, 알람은 울리지 않음
02:48 조치 결제팀 에스컬레이션, DB 커넥션 풀 상태 점검 시작
03:05 원인 커넥션 풀 소진 확인 (사용 가능 커넥션 0)
03:12 조치 결제 서비스 재기동 결정·실행
03:20 복구 결제 API 정상 응답 확인, 모니터링 정상화
→ 미인지 시간(발생→인지): 27분 (모니터링 공백 = 재발방지 1순위)
→ 복구 시간(인지→복구): 39분
→ 총 장애 지속: 66분
시각이 모호하면("새벽에 발생, 아침에 복구") 이 모든 숫자가 사라지고, SLA 판정도 재발방지 우선순위도 정할 수 없습니다. 타임라인은 보고서에서 가장 먼저 단단히 잡아야 할 뼈대입니다.
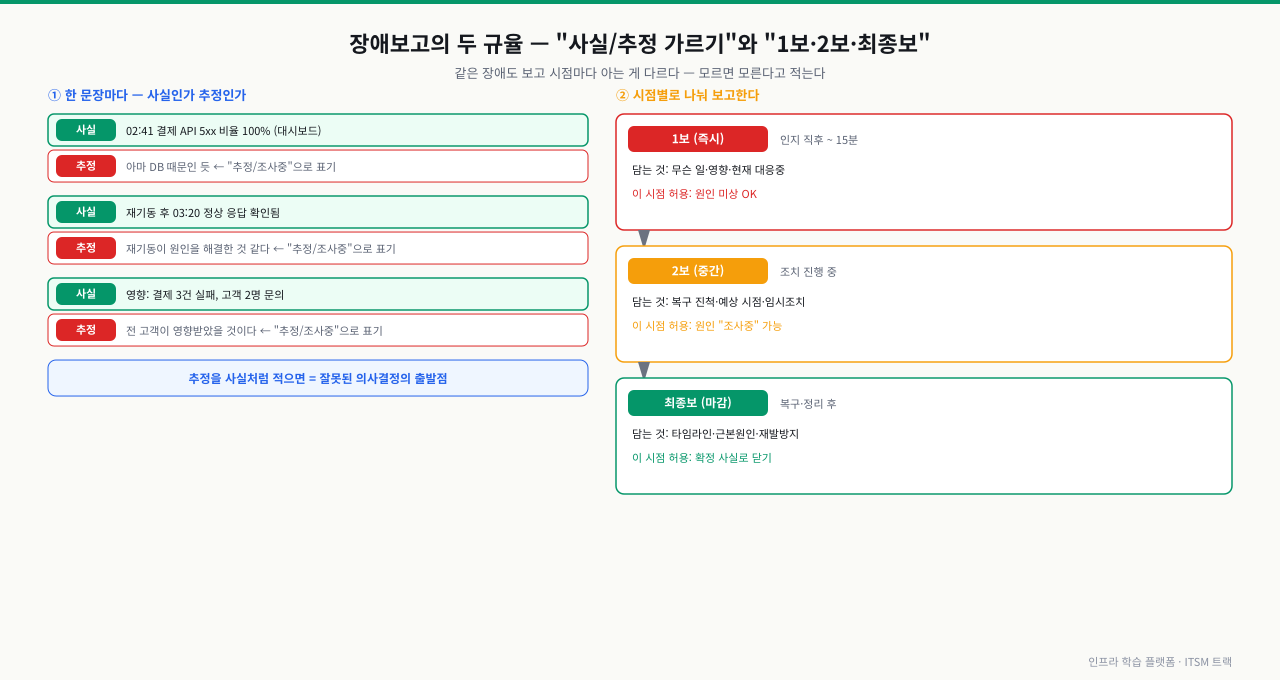
장애보고를 망치는 두 가지를 막는 규율입니다. 첫째, 한 문장마다 "이건 확인된 사실인가, 아직 추정인가"를 가릅니다 — 추정을 사실처럼 적으면 그 보고서를 읽은 사람의 의사결정이 어긋납니다. 둘째, 보고는 한 번에 완성되지 않습니다. 1보(즉시·원인 미상 허용) → 2보(조치 중·조사중 허용) → 최종보(확정 사실로 마감) 로 시점을 나누면, 빠르게 알리면서도 모르는 것을 모른다고 정직하게 적을 수 있습니다.
직접 해보기 — 한 장짜리 장애보고서 채우기
아래 사건 정보를 보고, 표준 장애보고서 양식의 각 칸을 채워 보세요. 특히 사실/추정 구분과 타임라인에서 나오는 지표에 주의하세요. 예시 답안은 ObserveBlock에 있습니다.
[사건 정보]
- 03:02 사내 그룹웨어 로그인 전면 불가 시작 (인증 서버 응답 없음)
- 03:25 당직자가 사용자 문의로 인지 (자동 알람 없었음)
- 03:30 인프라팀 에스컬레이션, 인증 서버 CPU 100% 확인
- 03:48 인증 서버 재기동
- 03:55 로그인 정상화 확인
- 영향: 전 직원(약 1,200명), 출근 전 시간대라 실제 로그인 시도는 적었음
- 로그상 인증 프로세스 무한 루프 흔적 발견되나, 유발 조건은 아직 미확인
채울 칸: (1) 개요 한 문단 (2) 발생/인지/복구 시각 (3) 영향 범위 (4) 타임라인과 거기서 나오는 지표(미인지 시간·지속시간) (5) 조치·복구(임시/영구 구분) (6) 근본원인(사실/추정 구분) (7) 재발방지(담당·기한 포함) (8) 향후계획.
장애보고서: 개요 → 시각 → 영향 → 타임라인 → 조치 → 복구 → 원인 → 재발방지 → 향후계획- 개요: "03:02부터 03:55까지 약 53분간 사내 그룹웨어 로그인이 전면 불가했습니다. 인증 서버 과부하로 추정되며, 재기동으로 복구 완료, 근본원인은 RCA 진행 중입니다." — 한 문단에 무엇·언제·얼마나·현재상태가 다 들어간다
- 시각: 발생 03:02 / 인지 03:25 / 복구 03:55 — 분 단위로, 추정 없이 관측된 시각
- 영향: 대상은 전 직원 약 1,200명(전사)이나, 출근 전 시간대로 실제 영향 사용자는 제한적 — "대상 범위"와 "실제 체감 영향"을 함께 적으면 과장도 축소도 없다
- 타임라인 지표: 미인지 시간(발생→인지) 23분 = 자동 알람 부재가 드러남(재발방지 1순위) / 복구 시간 30분 / 총 지속 53분
- 조치·복구: 인증 서버 재기동은 임시 복구임을 명시 — 무한 루프 유발 조건 제거(코드/설정)는 영구 조치로 향후계획에
- 근본원인: [사실] 로그에서 인증 프로세스 무한 루프 흔적 확인, CPU 100% 관측 / [추정] 특정 요청 패턴이 루프를 유발한 것으로 추정되나 유발 조건 미확인 — 사실과 추정을 분리해 적었는가
- 재발방지: (1) 인증 서버 CPU·응답 알람 추가 — 담당 인프라팀, 기한 명시 (2) 무한 루프 유발 조건 분석 후 코드 수정 — 담당 개발팀, RCA 후 / 담당·기한 없는 대책은 약속이 아니라 희망사항
- 향후계획: RCA 완료 예정일과 상세 보고서 제출 시점을 적었는가 — "추가 보고 예정"이 있어야 고객이 기다릴 수 있다
현장에서 자주 보는 함정
증상: 장애는 빠르게 복구했고 보고서도 제때 냈는데, 고객·경영진의 반응이 싸늘합니다. (1) "복구됐다"는 알겠는데 "또 안 난다는 보장"을 못 느끼거나, (2) 초기 보고에 단정한 원인이 RCA 결과 틀려서 보고서를 두세 번 정정하게 됩니다.
원인:
- (1)은 재발방지가 비어 있거나 추상적입니다. "주의하겠습니다", "모니터링 강화하겠습니다"는 담당도 기한도 없어 약속이 아닙니다. 고객은 "다음에 같은 장애가 나면 무엇이 달라지는가"를 묻는데, 답이 없습니다.
- (2)는 추정을 사실로 단정한 결과입니다. 급한 마음에 "원인은 X입니다"라고 못 박았다가, 진짜 원인이 Y로 밝혀지면 보고서 전체의 신뢰가 흔들립니다.
해결 방향:
- 재발방지는 "무엇을 / 누가 / 언제까지" 세 가지를 반드시 채운다. "인증 서버 응답시간 알람 추가 — 인프라팀, 6/30까지"처럼 검증 가능하게.
- 초기 보고에서는 **"현재 추정 / 조사중"**을 당당하게 쓴다. 빠르게 단정하는 것보다, 정직하게 추정 표시하고 RCA 후속 보고로 확정하는 편이 신뢰를 지킨다.
- 대형 장애는 1차(즉시·요약) + 2차(상세·확정) 보고를 분리한다. 1차에서 모든 걸 확정하려다 틀리는 것보다, 단계적으로 정확도를 높이는 것이 정석이다.
장애보고서의 신뢰는 "얼마나 빨리 원인을 단정했나"가 아니라 **"얼마나 정직하게 사실과 약속을 적었나"**에서 나옵니다.
한국 SI/SM 현장에서 장애보고서는 계약상 의무인 경우가 많습니다. SLA 문서나 운영 계약에 "장애 등급별 보고 수준과 보고 기한"이 명시되어 있고, 이를 어기면 페널티나 신뢰 손상으로 이어집니다. 보통 다음과 같이 등급화됩니다.
| 장애 등급 | 대략적 기준 | 보고 수준 | 보고 기한(예시) |
|---|---|---|---|
| 1등급(심각) | 전사·핵심서비스 중단, 매출/대외 영향 | 즉시 구두/메신저 1차 보고 + 상세 보고서 | 인지 즉시 1차, 24시간 내 상세 |
| 2등급(주요) | 일부 서비스 중단·중대 저하 | 요약 보고 + 보고서 | 당일 내 |
| 3등급(경미) | 제한적 영향, 우회 가능 | 정기 보고에 포함 | 주간/월간 운영보고에 합산 |
실제 등급 기준·기한은 계약·SLA마다 다르므로 반드시 해당 사업의 운영 계약을 확인해야 합니다. 위 표는 전형적인 형태일 뿐입니다.
관리자(PM·PMO·SM 담당)로서 당신의 역할은 협력사 엔지니어가 키보드를 치는 것이 아니라, **"이 장애가 몇 등급이고, 누구에게, 언제까지, 어떤 보고서로 알려야 하는가"**를 판단하고 통제하는 것입니다. 협력사가 작성한 보고서를 받더라도, 사실/추정이 구분됐는지·재발방지에 담당과 기한이 있는지·타임라인이 명확한지를 검토하는 책임은 관리자에게 있습니다. 부실한 보고서를 그대로 발주사에 올리면, 그 책임은 협력사가 아니라 관리자가 집니다.
좋은 보고와 나쁜 보고는 다음과 같이 갈립니다.
| 항목 | 나쁜 보고 | 좋은 보고 |
|---|---|---|
| 시각 | "새벽에 발생, 아침에 복구" | "발생 03:02 / 인지 03:25 / 복구 03:55" |
| 영향 | "결제가 안 됐음" | "66분간 전 고객 결제 시도 약 240건 실패" |
| 원인 | "아마 DB 문제인 듯" (단정) | "[사실] 커넥션 풀 소진 확인 / [추정] 누수 의심, RCA 검증 예정" |
| 복구 | "재시작함" | "재기동(임시 복구), 영구 조치는 향후계획에" |
| 재발방지 | "주의하겠습니다" | "커넥션 풀 알람 추가 — 인프라팀, 6/30까지" |
| 후속 | (없음) | "RCA 완료 후 6/25 상세 보고 예정" |
관련 모듈로 더 깊이:
- RCA 보고서 작성 — "조사중"으로 남긴 근본원인을 끝까지 파고드는 다음 단계 문서
- RCA 보고서 작성 — 보고서의 근본원인·재발방지를 증명하는 RCA 보고서
- 인시던트 관리 — 보고서를 만들어 내는 인시던트 처리 프로세스 전체
다음 모듈에서는 이 장애보고서에서 "조사중"으로 남겨 둔 근본원인을 끝까지 파고드는 RCA 보고서 — 5Why·피시본 등으로 진짜 원인을 규명하고, 비난 없는(blameless) 사후분석으로 정리하는 법을 다룹니다.