운영팀에 이미 좋은 도구가 다 있습니다. 모니터링은 Grafana, 티켓은 Jira(또는 Redmine), 소통은 Slack(또는 잔디), 그리고 요약·작성에는 AI까지 씁니다.
그런데도 새벽 장애가 나면 똑같이 헤맵니다. 알람은 Grafana에 뜨지만 아무도 못 보고, 누군가 일어나 로그를 읽고, 손으로 티켓을 만들고, 메신저에 상황을 정리해 올립니다. 도구는 다 있는데 도구들 사이가 비어 있어서 사람이 매번 그 틈을 손으로 잇습니다.
멀티툴 자동화 아키텍처는 이 빈틈을 메웁니다. 각 도구에 역할을 주고, 그 사이를 자동으로 흐르게 만들되 — 위험한 지점에는 사람 승인을 끼워 넣는 설계입니다.
- 1n8n·LLM·Jira·메신저가 자동화 아키텍처에서 각각 어떤 역할을 맡는지 구분할 수 있다
- 2이벤트 구동형 장애 대응 파이프라인(패턴1)의 데이터 흐름을 그릴 수 있다
- 3MCP 기반 대화형 운영 어시스턴트(패턴2)가 정형 자동화와 어떻게 다른지 설명할 수 있다
- 4정기 리포트·거버넌스(패턴3)에서 사람 승인 게이트를 어디에 둘지 판단할 수 있다
- 5세 패턴을 한국 SI/SM 현장(Redmine·잔디·폐쇄망)에 안전하게 치환할 수 있다
먼저: 도구마다 "역할"을 못 박는다
자동화가 엉키는 첫 번째 이유는 도구의 역할이 흐릿해서입니다. "AI한테 다 시키지", "n8n으로 다 하지" 같은 생각이 설계를 망칩니다. 네 종류의 도구는 서로 다른 일을 합니다.
역할 분담: 오케스트레이터 · 판단 엔진 · 기록 · 사람 인터페이스
자동화 아키텍처를 설계할 때 가장 먼저 하는 일은 "이 도구는 무엇을 책임지는가"를 한 단어로 못 박는 것입니다. 역할이 겹치거나 비면 자동화가 깨지거나 사람이 다시 틈을 메우게 됩니다.
| 도구 | 역할(한 단어) | 책임 | 책임지지 않는 것 |
|---|---|---|---|
| n8n | 오케스트레이터(접착제) | 트리거 수신, 데이터 정규화·분기·재시도, 도구 간 연결 | 내용 판단(요약·분류는 LLM에 위임) |
| LLM (Claude·GPT) | 판단·요약 엔진 | 분류·요약·초안 작성, 구조화 출력 | 최종 결정·발행(사람 몫) |
| Jira·Redmine | 기록 시스템(System of Record) | 티켓이 남는 곳, 상태·우선순위·이력 | 실시간 알림(메신저 몫) |
| Slack·잔디·카카오워크 | 사람 인터페이스 | 사람에게 알리고, 사람이 보고 대응 | 영구 기록(티켓 시스템 몫) |
핵심 원칙 한 줄: n8n은 흐름을, LLM은 판단을, 기록 시스템은 영구 보관을, 메신저는 사람과의 접점을 맡는다. 이 역할표를 머리에 박아 두면 아래 세 패턴이 전부 같은 부품의 재배치로 보입니다.
패턴 1 — 이벤트 구동형 장애 대응 파이프라인
가장 흔하고 효과가 즉시 보이는 패턴입니다. 모니터링 알람이 트리거가 되어, 사람이 깨기 전에 분류·요약까지 끝내 둡니다.
알람 → n8n → LLM → (메신저 알림 + 티켓 기록)
야간 무인 모니터링의 약점은 "알람은 뜨는데 아무도 안 본다"입니다. 이 패턴은 알람이 들어오는 순간 자동으로 흐르게 만들어, 사람은 이미 분류·요약된 것만 보게 합니다.
데이터 흐름은 한 방향입니다. 모니터링이 알람 webhook을 쏘면 → n8n이 받아 정규화하고 → LLM이 심각도와 한 줄 요약을 만들고 → 그 결과가 메신저(사람 알림)와 티켓(영구 기록) 두 갈래로 동시에 나갑니다.
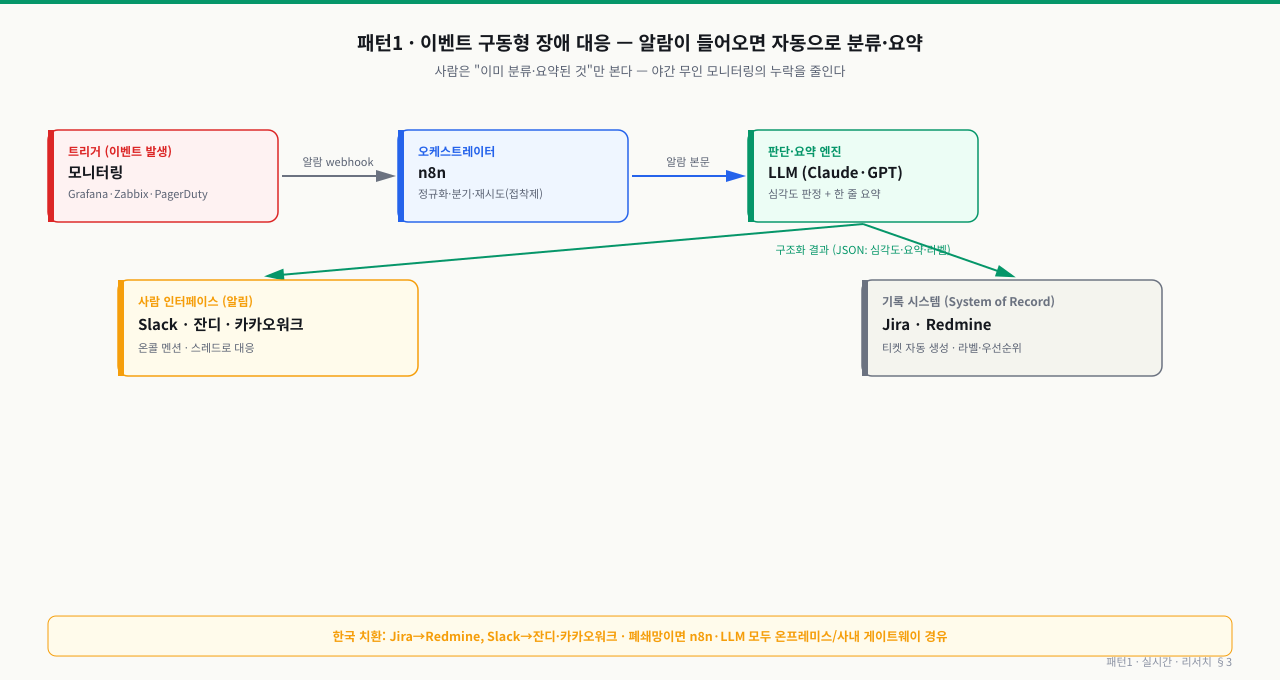
그림: 알람 한 건이 n8n을 거쳐 LLM에서 분류·요약된 뒤, 사람 알림(메신저)과 영구 기록(티켓)으로 갈라지는 실시간 흐름. 사람은 "분류된 것"만 검토한다.
패턴 2 — 대화형 운영 어시스턴트 (MCP 기반)
패턴1이 "미리 짜 둔 흐름이 자동으로 도는" 정형 자동화라면, 패턴2는 운영자가 자연어로 그때그때 시키는 비정형 자동화입니다.
자연어 지시 → LLM이 도구를 골라 호출 → 종합 응답
매번 워크플로우를 짜 두기엔 운영 업무가 너무 다양합니다. "지난주 P1 티켓 모아서 RCA 표 만들어줘" 같은 즉석 요청은 미리 자동화하기 어렵습니다.
MCP(Model Context Protocol, "AI를 위한 USB-C"로 불리는 오픈 표준)는 이 빈틈을 메웁니다. 운영자가 Host(Slack 봇이나 Claude Desktop)에 자연어로 지시하면, LLM이 맥락을 보고 어떤 도구(MCP 서버)를 호출할지 스스로 결정합니다. Jira MCP로 티켓을 조회하고, Monitoring MCP로 지표를 읽고, Wiki MCP로 런북을 찾아 — 결과를 종합해 사람에게 답합니다.
여기서 각 MCP 서버는 도구 어댑터(특정 기능만 노출하는 작은 프로그램), LLM은 추론·도구선택 에이전트, 메신저/데스크톱은 대화 UI입니다.
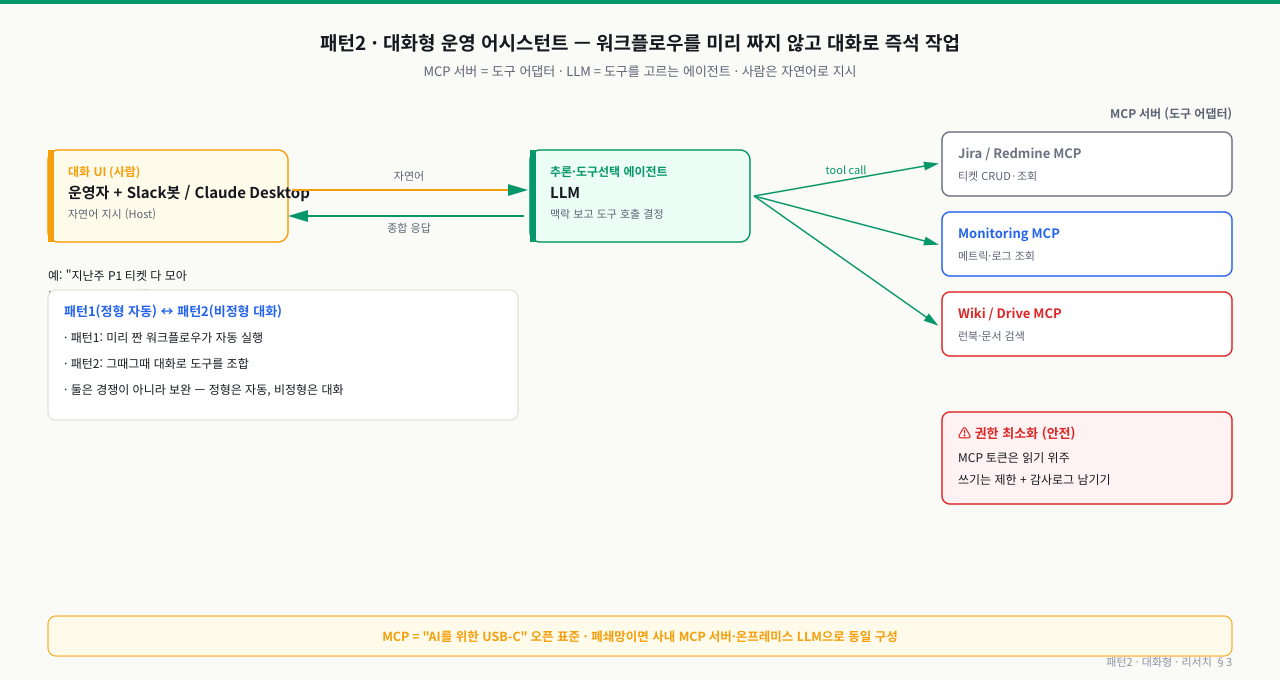
그림: 운영자의 자연어 지시를 LLM이 받아 필요한 MCP 서버들을 골라 호출하고 결과를 종합한다. 도구를 미리 엮어 두는 패턴1과 달리 "대화로 즉석 조합"이 핵심이며, 권한 최소화가 안전의 관건이다.
패턴 3 — 정기 리포트·거버넌스 (사람 승인 게이트)
세 번째 패턴은 정기적으로 데이터를 모아 리포트 초안을 만드는 것입니다. 여기서 결정적인 차이는 발행 전에 사람이 반드시 검토하는 관문이 들어간다는 점입니다.
Cron 수집 → LLM 초안 → 🛑 사람 승인 → 발행
주간 운영 리포트, 경영진 보고처럼 대외/상향 보고는 환각 한 번이 신뢰에 직접 타격을 줍니다. SLA 수치, 고객명, 금액, 담당자 — 이런 값이 틀린 채 발행되면 자동화가 오히려 사고를 키웁니다.
그래서 이 패턴은 흐름 중간에 사람을 끼웁니다. n8n Cron이 정해진 시각(예: 매주 월 09:00)에 Jira·모니터링 API에서 데이터를 모으고 → LLM이 "초안"(위험 하이라이트 포함, "검토 필요" 표시)을 만들고 → 여기서 멈춥니다. 담당자가 원본과 대조해 수정·승인한 뒤에야 팀 공유(메신저)와 문서 페이지(Confluence·Notion) 자동 생성이 일어납니다.
이 사람 승인 게이트가 5장 안전수칙의 핵심("AI는 초안 작성자, 결정권자가 아니다")이 아키텍처에 박히는 지점입니다.
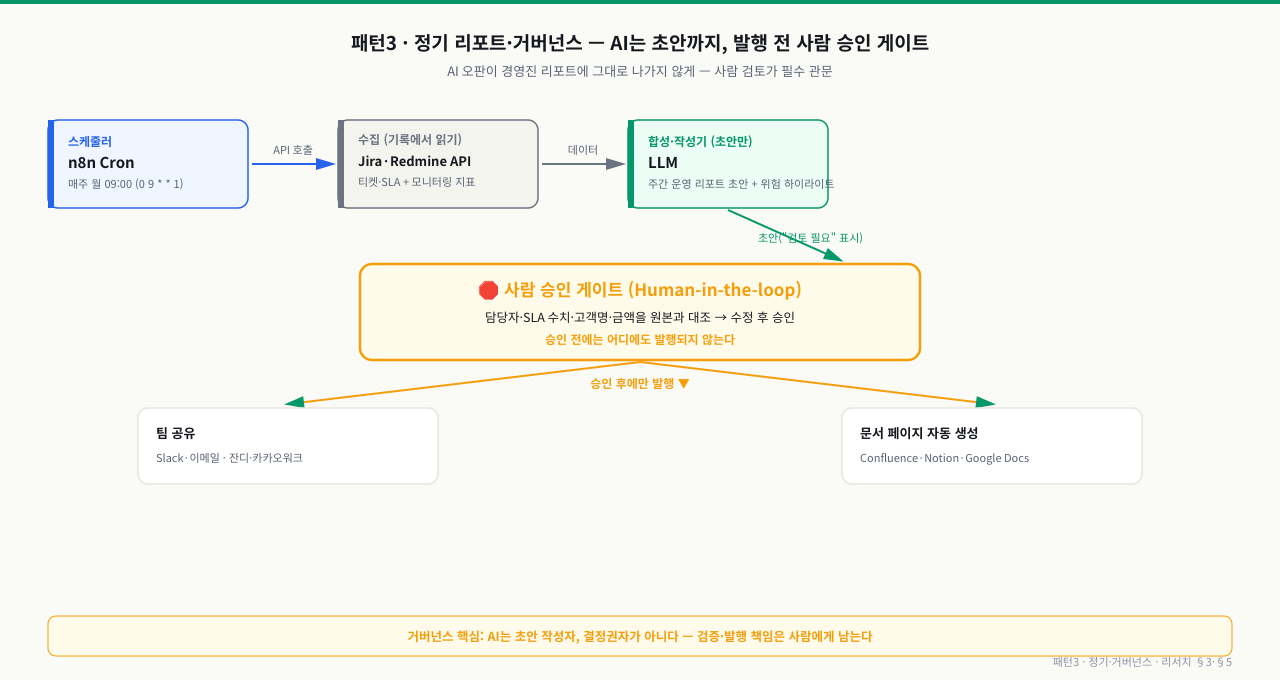
그림: 수집·초안까지는 자동이지만, 발행 직전에 사람 승인 게이트(앰버)가 가로막는다. 승인 전에는 어떤 채널로도 나가지 않는다 — 이것이 거버넌스의 핵심이다.
지금 맡고 있거나 본 적 있는 운영 업무 하나를 골라, 세 패턴 중 어디에 해당하는지 정하고 데이터 흐름을 직접 그려 봅니다.
- 업무 선택 — 예: "야간 디스크 풀 알람 대응" / "주간 SLA 리포트" / "지난주 장애 티켓 모아서 회고"
- 패턴 판정 — 트리거가 이벤트면 패턴1, 자연어 즉석 요청이면 패턴2, 정기 스케줄+보고면 패턴3
- 역할 배치 — 각 단계에 n8n / LLM / 기록 시스템 / 메신저 중 무엇이 들어가는지 박스로
- 승인 게이트 위치 — "여기서 AI 오판이 시스템에 직접 반영되면 위험한가?"를 물어 사람 승인을 끼울 지점 표시
# 종이/화이트보드에 직접 그려봅니다 (도구 설치 불필요)- 고른 업무가 세 패턴 중 정확히 하나로 분류되는가? (애매하면 트리거가 이벤트/대화/스케줄 중 무엇인지 다시 본다)
- 각 박스에 "한 단어 역할"이 붙었는가 — 오케스트레이터/판단/기록/사람 인터페이스가 겹치지 않는가?
- 승인 게이트를 둔 지점이 "대외 발행·쓰기 작업·민감 수치"와 맞닿아 있는가?
- 한국 현업이라면 Jira→Redmine, Slack→잔디/카카오워크로 치환해도 흐름이 그대로 성립하는가?
자동화의 전형적인 사고입니다. "AI 오판이 시스템에 직접 반영"되는 위험(패턴3의 승인 게이트가 막으려던 바로 그것)이 패턴1에서도 나타난 경우입니다. 원인은 보통 둘입니다.
- 승인 없는 쓰기: LLM 분류 결과가 곧바로 티켓·알림으로 발행됨 → 오판이 그대로 사고가 됨
- 디바운스 없음: 같은 원인의 알람이 반복 트리거 → 중복 티켓·알람 폭주
해결 방향:
1. 초기에는 "자동 발행" 대신 "초안/제안"만 — 고심각도(P1/P2)는 사람 승인 후 티켓 확정
2. n8n에서 디바운스·중복 제거 — 동일 키(서비스+에러코드) N분 내 1건으로 묶기
3. 쓰기 권한 최소화 — 토큰은 읽기 위주, 티켓 생성은 별도 제한·감사로그
4. 저심각도만 완전 자동, 고심각도는 사람 게이트 — 위험도에 따라 자동화 수준을 나눈다
자동화는 "전부 자동" 아니면 "전부 수동"이 아닙니다. 위험도에 따라 자동화 수준을 나누는 것이 설계의 핵심입니다.
패턴2의 대표 리스크입니다. 대화형은 편리한 만큼, LLM의 도구 선택이 빗나가면 파급이 큽니다.
1. 읽기 위주 권한 — Jira/Monitoring MCP는 기본 조회만, 쓰기는 별도 토큰·제한
2. 위험 작업 확인 단계 — 삭제·대량 수정은 "정말 실행할까요?" 사람 확인 후 실행
3. 감사로그 필수 — 누가/언제/어떤 도구를 호출했는지 기록(governance as code)
4. 범위 제한 — MCP 서버가 노출하는 도구를 꼭 필요한 것만으로 최소화
권한 최소화는 선택이 아니라 멀티툴 자동화의 전제입니다. "쓰기는 제한·감사"가 기본값이어야 합니다.
관리 직무(PM·PMO·운영·SM)에서 이 아키텍처를 설계하는 일은 점점 당신의 몫이 됩니다. 당신이 직접 n8n 노드를 잇거나 MCP 서버를 코딩하지 않더라도, **"어떤 업무를 어떤 패턴으로 자동화하고, 각 도구에 무슨 역할을 주며, 어디에 사람 승인을 끼울지"**를 결정하는 건 도구가 아니라 사람이 하는 설계 판단입니다.
특히 한국 SI/SM 현장에서는 두 가지가 함께 옵니다. 하나는 치환 — 고객사가 Jira 대신 Redmine을, Slack 대신 잔디·카카오워크를 쓰는 경우가 많고, 폐쇄망이면 n8n·LLM을 온프레미스/사내 게이트웨이로 올려 데이터가 밖으로 나가지 않게 해야 합니다. 다른 하나는 책임 — 협력사가 "AI로 자동화했다"며 가져온 파이프라인을 그대로 신뢰하면 안 됩니다. 승인 게이트가 빠져 있거나 토큰 권한이 과한 자동화는 언젠가 사고를 냅니다. 결과에 대한 책임은 결국 관리하는 쪽에 남습니다.
잘 설계된 멀티툴 자동화는 야간 누락을 줄이고 MTTR을 단축하며 반복 보고의 시간을 크게 줄여, 당신이 판단과 소통이라는 관리자 본연의 일에 집중하게 합니다. 단, 그 전제는 언제나 "위험한 지점에는 사람이 있다"는 것입니다.
관련 모듈로 더 깊이:
- AI를 PM·운영 보조로 — 이 아키텍처의 토대가 되는 AI 활용 기본기와 안전수칙(초안은 AI, 책임은 사람)
- 고급 프롬프트 패턴과 AI 도구 연계 — 도구별 적합 작업과 보안 경계 — 무엇을 어디에 넣어도 되는가
- 정보보안 관리 — 폐쇄망·기밀 데이터에서 도구 연계 시 지켜야 할 보안 경계의 관리 원리
다음 모듈에서는 지금까지 설계한 자동화 아키텍처에 휴먼 체크포인트와 권한 최소화를 실제로 적용하는 안전·거버넌스 관점을 캡스톤으로 묶어, AI 활용을 책임 있는 운영으로 마무리합니다.