배포 후 K8s 대시보드가 빨갛습니다. "Pod가 CrashLoopBackOff예요. 다른 건 ImagePullBackOff, 하나는 OOMKilled로 죽었고, Readiness가 안 떠서 트래픽이 안 가요." PM·인프라인 당신은 이 상태 이름들이 각각 무엇을 뜻하고 어디부터 봐야 할지 알아야 합니다. 이 사전은 컨테이너·K8s 용어와 '상태(state)' 신호를 빠르게 해독합니다. 깊은 실습은 Docker·Kubernetes 트랙으로 연결합니다.
- 1이미지·컨테이너·레지스트리·볼륨 용어로 컨테이너 기본을 읽을 수 있다
- 2Pod·Deployment·Service·Ingress 등 K8s 오브젝트의 역할을 구분할 수 있다
- 3Probe·HPA·리소스 request/limit으로 운영 동작을 이해할 수 있다
- 4CrashLoopBackOff·ImagePullBackOff·OOMKilled 등 상태로 장애 방향을 잡을 수 있다
컨테이너 기본
이미지·컨테이너·레지스트리·볼륨
| 용어 | 한 줄 뜻 | 비고 | 중요도 |
|---|---|---|---|
| Docker / Dockerfile | 컨테이너 플랫폼 / 이미지 빌드 정의 | → 백엔드 애플리케이션의 컨테이너 이미지 빌드와 작성 요령 | ★★ |
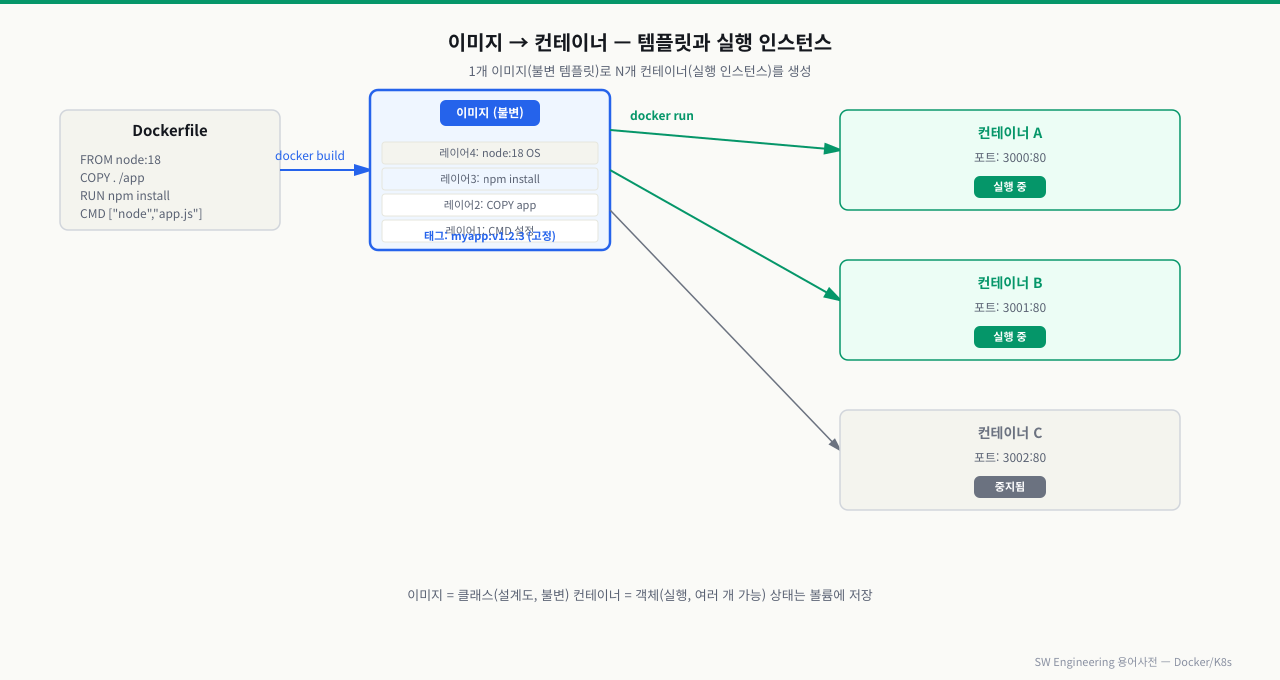
| Docker Image / Container | 불변 템플릿 / 실행 인스턴스 | 1 이미지 → N 컨테이너 | ★★★ |
| Image Tag / Registry / DockerHub / ECR | 버전 태그 / 저장소 | 불변 태그 → 시맨틱 버저닝 | ★★ |
| Volume / Bind Mount | 데이터 영속 / 호스트 연결 | 상태 외부화 → 컨테이너가 삭제되어도 안전하게 데이터를 보관하는 Volume & Bind Mount | ★★ |
| Network Bridge / Docker Compose | 컨테이너 네트워크 / 다중 컨테이너 정의 | → 복잡한 멀티 서비스 환경의 유기적 연동과 배포 | ★★ |
핵심: 이미지는 불변, 태그는 고정(latest 금지)이어야 릴리스 전략의 롤백이 가능합니다. 상태(DB·파일)는 볼륨으로 컨테이너 밖에 둡니다(12-Factor App).
 확대
확대
위 그림처럼 이미지는 클래스(설계도), 컨테이너는 객체(실행 인스턴스)와 같습니다. 동일한 이미지로 컨테이너를 여러 개 띄울 수 있고, 상태(파일·DB)는 컨테이너가 아닌 볼륨에 저장해야 합니다.
쿠버네티스 오브젝트
Pod부터 Ingress까지
| 용어 | 한 줄 뜻 | 비고 | 중요도 |
|---|---|---|---|
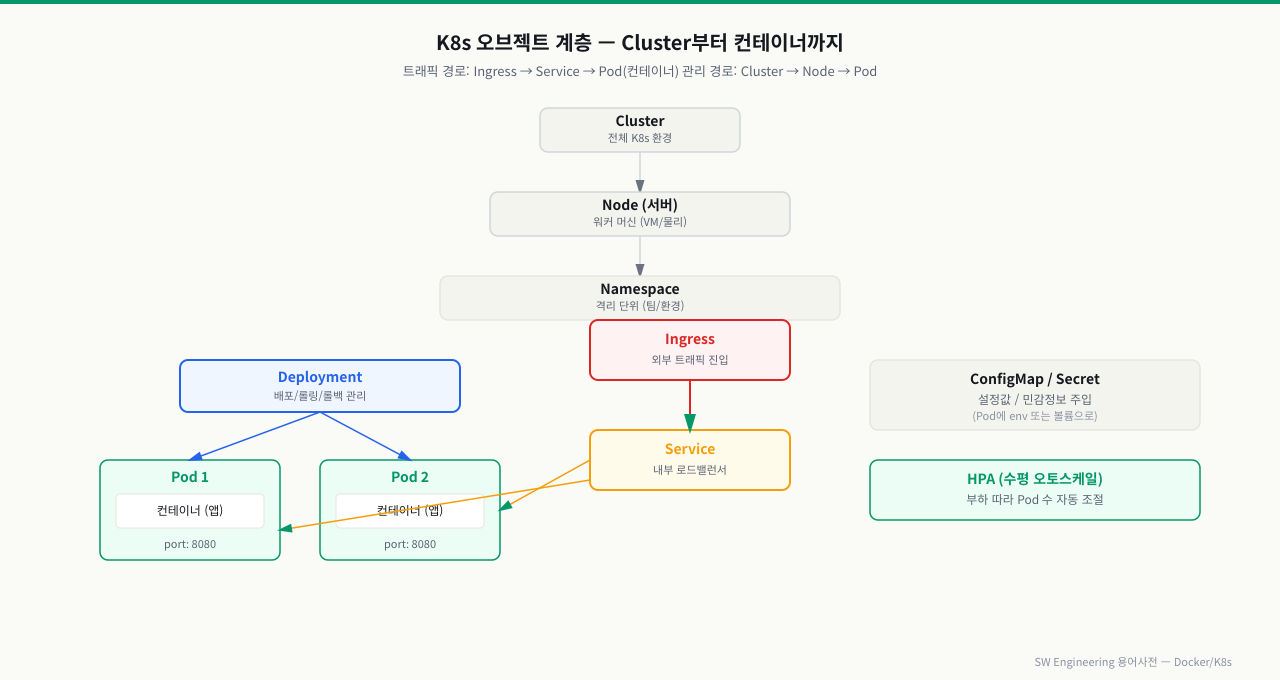
| Cluster / Node / Pod | 클러스터 / 노드(서버) / 최소 배포 단위 | Pod=컨테이너 묶음 → Control Plane과 Worker Node 컴포넌트 간 유기적 구조 분석 | ★★ |
| Deployment / ReplicaSet | 배포·버전 관리 / 복제본 유지 | 롤링·롤백 → Deployment를 이용한 안정적인 서비스 배포와 롤백 전략 | ★★ |
| StatefulSet / DaemonSet | 상태유지 워크로드 / 노드마다 1개 | DB·에이전트 | ★ |
| Job / CronJob | 일회성 / 예약 작업 | 배치 → 용어사전 | ★ |
| Service / Ingress / Ingress Controller | 내부 LB / 외부 진입 / 그 구현 | 트래픽 경로 → ClusterIP, NodePort, LoadBalancer 서비스 완전 분석·Ingress Controller 경로 기반 포워딩과 SSL/TLS 설정 | ★★ |
| ConfigMap / Secret / Namespace | 설정 / 비밀 / 격리 단위 | → ConfigMap과 Secret을 이용한 코드와 환경 설정 분리 | ★★ |
| PVC / PV / StorageClass | 볼륨 요청 / 볼륨 / 스토리지 종류 | 영속 스토리지 → PV와 PVC를 활용한 영구 볼륨 스토리지 바인딩 | ★ |
운영 동작 — Probe·오토스케일·리소스
K8s가 앱을 살리고 늘리는 메커니즘
| 용어 | 한 줄 뜻 | 비고 | 중요도 |
|---|---|---|---|
| Liveness / Readiness / Startup Probe | 생존 / 준비 / 기동 점검 | Liveness 실패=재시작, Readiness 실패=트래픽 제외 | ★★★ |
| Resource Request / Limit | 예약량 / 상한 | limit 초과: CPU=throttle, 메모리=OOMKill → requests와 limits 적정 값 계산과 CPU 스로틀링 대처 | ★★★ |
| HPA / VPA | 수평/수직 오토스케일 | 부하 따라 Pod 수 조절 → HPA(Horizontal Pod Autoscaler) 메트릭 기반 파드 확장 | ★★ |
| Rolling Update / Rollback | 점진 교체 / 되돌리기 | → 릴리스 전략 | ★★ |
| Blue-Green / Canary Deployment | 무중단/점진 배포 | → 릴리스 전략 | ★★ |
| Helm / Helm Chart / Values.yaml / Manifest | 패키지 매니저 / 차트 / 값 / 정의 | → 복잡한 매니페스트를 차트(Chart) 단위로 원클릭 배포하기 | ★★ |
핵심: Readiness 실패 = 트래픽 제외(재시작 안 함), Liveness 실패 = 재시작. 메모리 limit 초과는 OOMKilled(137), CPU limit 초과는 throttle(안 죽음)입니다(requests와 limits 적정 값 계산과 CPU 스로틀링 대처).
 확대
확대
위 그림처럼 K8s 오브젝트는 관리 계층(Cluster→Node→Pod)과 트래픽 경로(Ingress→Service→Pod)로 나뉩니다. Deployment가 Pod의 복제본을 유지하고, HPA가 부하에 따라 Pod 수를 자동 조절합니다.
Pod 상태(state) — 장애 신호 사전
빨간 상태가 알려주는 원인
| 상태 | 의미 | 1차 대응 | 중요도 |
|---|---|---|---|
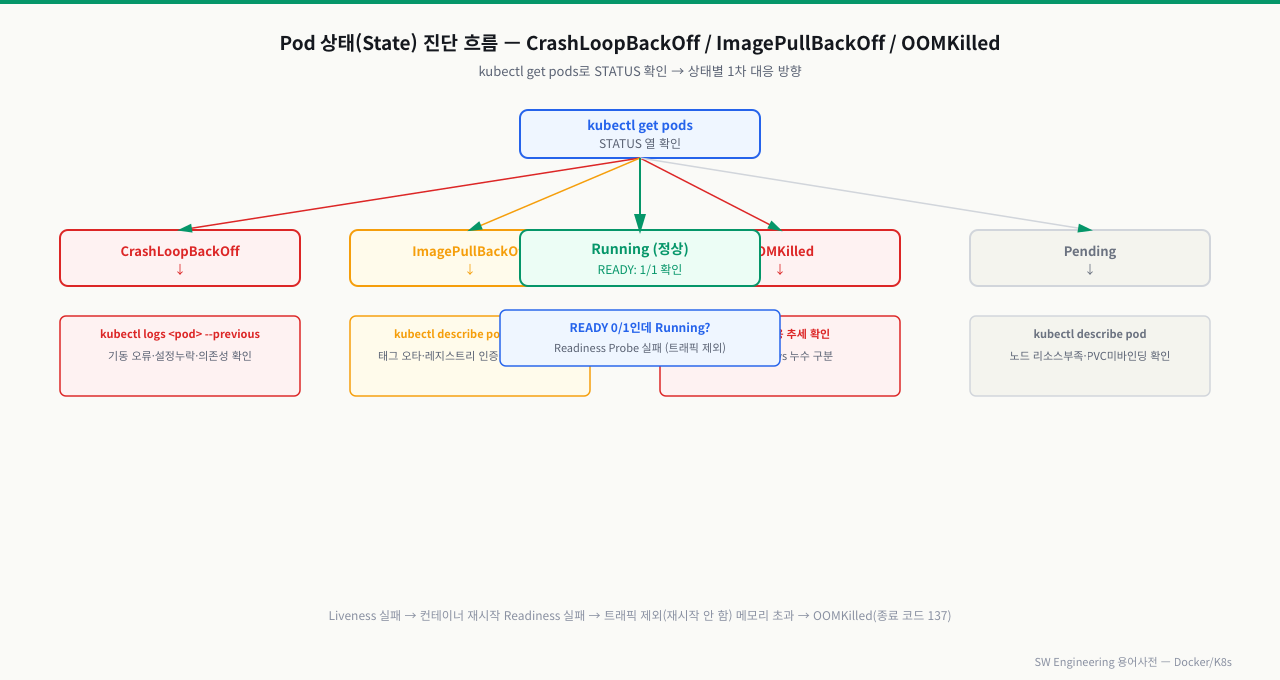
| CrashLoopBackOff | 시작→크래시→재시작 반복 | logs --previous로 기동 오류 확인 | ★★★ |
| ImagePullBackOff | 이미지 못 받음 | 태그 오타·레지스트리 인증(Secret) 확인 | ★★★ |
| OOMKilled | 메모리 limit 초과 종료(137) | limit 상향 vs 누수 구분 → requests와 limits 적정 값 계산과 CPU 스로틀링 대처 | ★★★ |
| Pending | 스케줄될 노드 없음 | 리소스 부족·노드셀렉터·PVC 미바인딩 | ★★ |
| Evicted | 노드 자원 압박으로 퇴거 | 노드 메모리/디스크 압박 | ★★ |
핵심: 상태 이름이 곧 진단의 출발점입니다. kubectl describe pod의 Events와 kubectl logs --previous가 1차 도구입니다(Kubernetes 장애 원인을 빠르게 격리하는 트러블슈팅 가이드).
 확대
확대
위 그림처럼 STATUS 이름이 곧 진단 방향을 알려줍니다. CrashLoopBackOff는 앱 기동 실패(설정/의존성), ImagePullBackOff는 이미지 접근 실패, OOMKilled는 메모리 한도 초과입니다. Running인데 READY 0/1이면 Readiness Probe 실패로 트래픽만 차단된 상태입니다.
Pod 상태 진단 — 직접 확인
K8s 장애는 상태 → 이벤트 → 로그 순으로 원인을 좁힙니다.
kubectl get pods # STATUS 열에서 상태 확인
kubectl describe pod <pod> # Events 섹션에 구체 사유
kubectl logs <pod> --previous # 죽기 직전(이전 컨테이너) 로그
NAME READY STATUS RESTARTS
app-xxx 0/1 CrashLoopBackOff 7 ← 7번 재시작. logs --previous 필수
api-yyy 0/1 ImagePullBackOff 0 ← describe Events에서 pull 실패 사유
db-zzz 0/1 OOMKilled 3 ← 메모리 limit 초과([[resource-limits]])
describe Events: Failed to pull image "myapp:v1.3": not found
→ 태그 오타 또는 레지스트리에 이미지 없음
kubectl get pods; kubectl describe pod <pod>; kubectl logs <pod> --previous- STATUS가 CrashLoopBackOff면 → kubectl logs <pod> --previous로 죽기 직전 로그 확인(설정 누락·의존성·기동 오류가 대부분)(Kubernetes 장애 원인을 빠르게 격리하는 트러블슈팅 가이드)
- ImagePullBackOff면 → kubectl describe의 Events에서 "not found"(태그 오타) vs "unauthorized"(레지스트리 Secret 누락) 구분
- OOMKilled(RESTARTS 증가)면 → 메모리 사용 추세 확인. 일시 폭증이면 limit 상향, 우상향이면 누수(requests와 limits 적정 값 계산과 CPU 스로틀링 대처·Heap/GC/Thread Dump 분석과 OOM 대응 실무)
- READY 0/1인데 STATUS Running이면 → Readiness Probe 실패(앱은 떴으나 준비 안 됨). describe의 Readiness probe 실패 사유 확인
상황: 새 버전 배포 후 모든 Pod가 CrashLoopBackOff로 뜨고 서비스가 전면 중단됩니다.
원인: 컨테이너가 기동 중 필수 설정(DB 접속 주소)을 못 읽어 즉시 크래시합니다. ConfigMap의 오타나 Secret 누락이 흔한 원인입니다(ConfigMap과 Secret을 이용한 코드와 환경 설정 분리). 이미지/코드 문제가 아니라 설정 주입 문제입니다.
진단:
kubectl logs <pod> --previous | tail -30
# "Could not resolve host: db-prd" 또는 "Connection refused" → DB 주소/설정 문제
kubectl get configmap app-config -o yaml # 주소 오타 확인
해결: ConfigMap/Secret의 값을 정정하고 재배포(또는 롤아웃 재시작). 근본 대응: (1) 설정 변경도 PR과 코드 리뷰·CI 검증을 거치게, (2) 즉시 릴리스 전략로 직전 정상 버전으로 롤백해 서비스 복구 후 원인 수정. CrashLoopBackOff는 "코드보다 설정/의존성 기동 실패"를 먼저 의심하는 것이 빠른 길입니다. 깊은 K8s 트러블슈팅은 Kubernetes 장애 원인을 빠르게 격리하는 트러블슈팅 가이드.
심화 — 용어 하나가 아니라 '결합'이 사고를 만든다
심화: Probe·HPA·태그 — 용어 둘이 만나는 지점이 진짜 시험대
표의 용어를 하나씩 아는 것과, 둘이 결합했을 때의 동작을 아는 것은 다릅니다. 실제 사고는 대부분 그 결합 지점에서 납니다.
- Liveness에 의존성 검사를 넣으면 장애가 증폭됩니다: Liveness와 Readiness에 같은 /health(DB 핑 포함)를 물리면, DB가 잠깐 느려질 때 트래픽만 빠졌어야 할 파드들이 Liveness 실패로 전부 재시작됩니다. Liveness는 "프로세스가 살아있나"만 보고, 외부 의존성 검사는 Readiness에만 — 면접에서 "둘의 차이"보다 한 단계 깊은 지점이 바로 이 분리 원칙입니다.
- HPA는 request 대비 %로 계산합니다: HPA의 "CPU 70%"는 절대값이 아니라 request 대비 비율입니다. request를 실제 사용량의 몇 배로 후하게 잡으면 사용률이 늘 낮게 계산돼 HPA가 영영 안 늘고, 너무 짜게 잡으면 상시 최대 replica에 붙습니다. "HPA가 동작 안 해요"의 절반은 HPA가 아니라 request 설정 문제입니다(requests와 limits 적정 값 계산과 CPU 스로틀링 대처·HPA(Horizontal Pod Autoscaler) 메트릭 기반 파드 확장).
- CrashLoopBackOff의 '원인'은 exit code가 가릅니다: 같은 CrashLoopBackOff라도
kubectl describe의 Last State exit code가 137이면 OOMKilled(메모리), 1이면 앱 오류(로그 확인), 0이면 프로세스가 정상 종료를 반복하는 것(포그라운드 프로세스 부재)입니다. 상태 이름 다음엔 exit code를 읽는 것이 진단의 두 번째 좌표입니다(Kubernetes 장애 원인을 빠르게 격리하는 트러블슈팅 가이드). - latest 태그와 롤백은 양립하지 않습니다: 롤백은 이전 매니페스트의 이미지 이름으로 되돌리는 것입니다. 태그가 latest면 이전 버전과 이름이 같아, 롤백해도 레지스트리에서 같은(문제 있는) 이미지를 다시 받아올 수 있습니다. "롤백했는데 증상이 그대로"의 단골 원인입니다(릴리스 전략).
상황: DB 페일오버로 30초간 연결이 끊겼다 복구됐는데, 그 순간부터 멀쩡하던 앱 파드 수십 개가 일제히 재시작을 반복하며 전면 장애가 10분 넘게 이어집니다.
원인: Liveness Probe가 DB 핑을 포함한 /health를 가리키고 있었습니다. DB 순단 동안 /health가 실패하자 K8s가 파드들을 재시작했고, 재시작된 파드는 기동·커넥션 풀 재수립에 시간이 걸려 다시 Liveness에 실패 — 그사이 남은 파드로 트래픽이 몰려 그마저 느려지는 연쇄가 됐습니다. DB는 30초 만에 살아났지만, 재시작 폭풍은 스스로 번식했습니다.
진단: kubectl describe pod의 Events에서 "Liveness probe failed" 시각이 DB 순단 시각과 일치하는지, RESTARTS가 특정 파드 하나가 아니라 전 파드에서 동시에 증가했는지 확인합니다. 개별 파드 문제라면 한둘만 재시작되지, 전부가 같이 돈다면 Probe 설계 문제입니다.
해결: Liveness는 프로세스 생존만 보는 가벼운 엔드포인트로 분리하고, DB 등 의존성 검사는 Readiness로 옮깁니다 — 그러면 DB 순단 시 트래픽만 빠졌다가 복구 즉시 돌아옵니다. failureThreshold·timeout에 여유를 두고, 기동이 느린 앱은 Startup Probe로 초기 유예를 줍니다. "Liveness 실패=재시작"이라는 정의를 아는 것과, 무엇을 Liveness에 물리면 안 되는지를 아는 것의 차이가 이 사고를 가릅니다(Kubernetes 장애 원인을 빠르게 격리하는 트러블슈팅 가이드).
인프라/플랫폼 엔지니어에게 이 상태 사전은 K8s 운영의 일상 언어입니다 — get/describe/logs로 상태를 읽고, Probe·리소스 limit·HPA를 설계하며(requests와 limits 적정 값 계산과 CPU 스로틀링 대처·HPA(Horizontal Pod Autoscaler) 메트릭 기반 파드 확장), 롤링/카나리 배포를 운영합니다(릴리스 전략). 깊은 실습은 Kubernetes 트랙에 있습니다. PM은 이 용어를 알면 "배포가 안 떠요"를 "CrashLoopBackOff(기동 실패) / ImagePullBackOff(이미지) / OOMKilled(메모리)"로 즉시 분류해, 영향 범위와 복구 시간을 가늠하고 롤백 결정을 빠르게 내릴 수 있습니다.
다음 용어사전에서는 이 컨테이너들을 빌드·배포하는 CI/CD·Git 용어를 정리합니다.
용어 식별 실습으로 굳히기: 용어 식별 — Docker / Kubernetes — 증상·로그를 보고 컨테이너·K8s 오브젝트·운영 용어를 가려냅니다.