경영진이 묻습니다. "우리 서비스 안정적이에요?" 누구는 "네, 거의 안 죽어요", 누구는 "지난주 두 번 느렸어요"라고 답합니다. 감으로 말할 뿐 숫자가 없습니다. 한편 장애가 날 때마다 "누가 그랬어?"로 범인을 찾자, 사람들이 장애를 숨기기 시작하고 솔직한 분석이 사라집니다. 같은 장애가 세 번째 반복됩니다. 신뢰성은 '느낌'이 아니라 지표(SLO)로 관리하고, 장애는 '비난'이 아니라 학습(포스트모템)으로 다뤄야 합니다. 이것이 성숙한 운영 문화입니다.
- 1SLI·SLO·SLA의 차이를 "측정값·목표·계약"으로 구분할 수 있다
- 2에러버짓으로 "안정성 vs 배포 속도"를 데이터로 결정하는 법을 설명할 수 있다
- 3비난 없는 포스트모템이 재발 방지에 효과적인 이유를 설명할 수 있다
- 4관측성 세 기둥(메트릭·로그·트레이스)으로 장애를 추적하는 흐름을 설명할 수 있다
SLI · SLO · SLA — 신뢰성을 숫자로
측정값 → 내부 목표 → 외부 계약
"안정적이에요?"에 숫자로 답하려면 이 세 가지를 구분해야 합니다.
SLI (Indicator, 측정값): 실제 가용성 99.95%, p95 지연 320ms
SLO (Objective, 내부목표): 가용성 99.9% 이상, p95 < 500ms ← 우리가 지키려는 선
SLA (Agreement, 외부계약): 99.5% 보장, 미달 시 요금 보상 ← 고객과의 약속
관계: SLA(99.5%) < SLO(99.9%) ← SLO를 더 빡빡하게
→ 계약(SLA) 위반 전에 내부 경보(SLO)가 먼저 울려 대응할 여유
핵심: SLI는 용어사전의 메트릭으로 측정합니다. SLO는 "100%를 목표하지 않는다"는 게 중요 — 100% 가용성은 비현실적이고 비용이 무한대입니다. 적정한 불완전함을 목표로 잡는 것이 SRE의 출발점입니다.
 확대
확대
위 그림처럼 SLI(실측값)를 바탕으로 SLO(내부 목표)를 세우고, SLO보다 느슨하게 SLA(외부 계약)를 설정해 계약 위반 전에 팀이 먼저 감지할 수 있습니다.
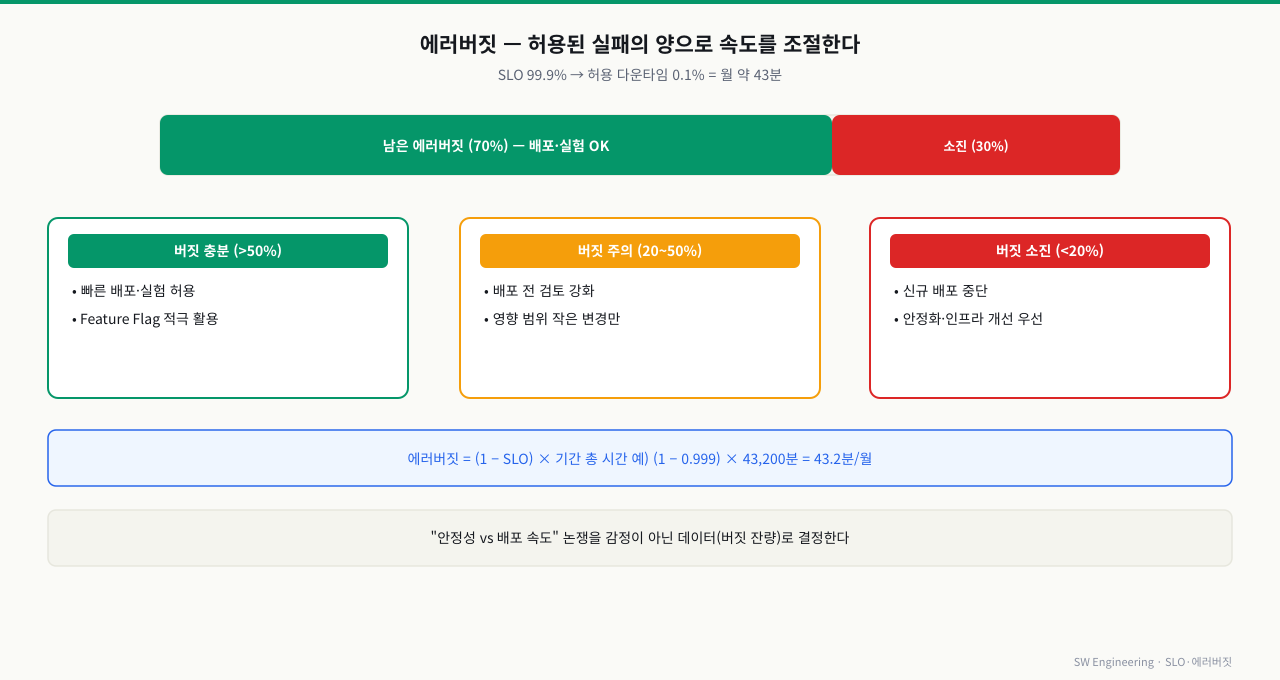
에러버짓 — 안정성 vs 속도를 데이터로
허용된 실패의 양을 예산처럼 쓴다
SLO가 99.9%면 0.1%의 실패가 허용됩니다. 이 허용량이 에러버짓입니다.
SLO 99.9% (30일 기준) → 허용 다운타임 ≈ 43분/월 = 에러버짓
버짓이 남음(장애 적음) → 위험 감수 OK: 빠르게 배포·실험·새 기능
버짓 소진(장애 누적) → 안정화 모드: 새 기능 동결, 신뢰성 작업 우선
→ "배포를 더 할까 말까"를 감정·정치가 아니라 '남은 버짓'으로 결정
이것이 릴리스 전략의 배포 속도와 안정성 사이의 긴장을 푸는 도구입니다. 개발팀은 빠르게 내보내고 싶고 운영팀은 안정을 원하는데, 에러버짓은 공통의 객관적 기준을 줍니다 — "이번 달 버짓 다 썼으니 안정화 먼저"는 누구의 의견이 아니라 데이터입니다. PM은 이를 통해 기능 출시와 신뢰성 투자의 균형을 정량적으로 조율합니다.
 확대
확대
위 그림처럼 에러버짓이 충분할 때는 빠른 배포를 허용하고, 소진되면 신규 배포를 중단해 안정화에 집중합니다.
포스트모템 — 비난이 아니라 학습
사람이 아니라 시스템을 고친다
장애 후 '누가 그랬나'를 찾으면, 사람들은 장애를 숨기고 솔직한 분석이 사라집니다. 비난 없는(blameless) 포스트모템은 질문을 바꿉니다.
비난형(나쁨): "왜 김OO이 잘못된 명령을 쳤나?" → 숨김·방어·재발
비난없음(좋음): "왜 시스템이 그 실수를 막지 못했나?"
→ 가드레일 부재? 확인 절차 없음? 위험한 명령에 안전장치 없음?
→ 사람이 아니라 '실수를 허용한 시스템'을 고침 → 재발 방지
포스트모템 구성:
1. 타임라인(언제 무슨 일이) 2. 영향(사용자·매출)
3. 근본원인(RCA) 4. 재발방지 액션(담당·기한, 테스트/자동화/알람 추가)
핵심: 인간은 반드시 실수합니다. 좋은 시스템은 '실수해도 큰일 안 나게' 만듭니다(PR과 코드 리뷰의 게이트, 릴리스 전략의 롤백, 테스트 전략의 회귀 테스트). 포스트모템의 액션이 다음 장애를 막는 가드레일이 됩니다. 개발 조직의 역할의 인시던트 역할(IC·Comms)도 여기서 작동합니다.
 확대
확대
위 그림처럼 메트릭은 "무엇이 이상한가", 로그는 "왜 이상한가", 트레이스는 "어디서 느려졌나"에 각각 답해 세 기둥이 합쳐져야 장애를 완전히 진단할 수 있습니다.
신뢰성 운영 점검 — 직접 확인
조직의 신뢰성 운영이 '느낌'인지 '지표·문화'인지 점검합니다.
□ 핵심 지표(가용성·지연·에러율)를 SLI로 측정 중인가? ([[glossary-observability]])
→ 없으면 "안정적이에요?"에 숫자로 답 불가
□ SLO가 정의돼 있고, 에러버짓 소진 시 행동(안정화 모드)이 합의됐나?
→ 없으면 배포 속도 vs 안정성이 매번 정치적 논쟁
□ 모든 의미있는 장애에 비난 없는 포스트모템 + 재발방지 액션이 있나?
→ 없으면 같은 장애 반복
□ 온콜(당번)·인시던트 역할(IC)이 정해져 있나? ([[dev-roles-collaboration]])
→ 없으면 장애 초동에 "누가?"로 시간 허비
성숙도 점검 예:
SLI 측정 ✓ (Prometheus/Grafana)
SLO/에러버짓 ✗ 목표선 없음 → 배포 판단이 감
포스트모템 △ 작성하나 액션 추적 안 됨 → 재발
온콜/IC ✗ → 장애 시 우왕좌왕([[dev-roles-collaboration]])
→ SLO 정의 + 포스트모템 액션 추적 + 온콜표가 다음 개선 1순위
echo 'SLI 측정·SLO 정의·버짓 추적·포스트모템 루틴 확인'- SLI 측정이 없으면 신뢰성을 "느낌"으로 말하는 것 — 먼저 가용성·p95 지연·에러율을 메트릭으로 측정(용어사전). 측정 없이는 목표(SLO)도 없다
- SLO·에러버짓이 없으면 "배포 더 할까"가 매번 정치적 논쟁 → 버짓을 정의해 "남으면 빠르게, 소진되면 안정화"를 데이터로 결정
- 포스트모템을 작성만 하고 재발방지 액션을 추적·완료 안 하면 같은 장애 반복 → 액션을 로드맵과 이슈 트래킹 이슈로 박아 담당·기한 추적
- 온콜·IC(인시던트 지휘)가 없으면 장애 초동에 "누가 대응?"으로 MTTR 악화(개발 조직의 역할) → 온콜표·역할을 평시에 합의
상황: 장애가 날 때마다 "누가 배포했어?", "누가 그 명령 쳤어?"로 책임을 추궁합니다. 그러자 사람들이 작은 장애를 보고하지 않고 조용히 덮기 시작하고, 근본 원인 분석이 사라져 같은 유형의 장애가 반복됩니다. 정작 "우리 서비스 안정적인가"엔 아무도 숫자로 답하지 못합니다.
원인: 비난 문화 + 지표 부재의 결합입니다. 비난은 투명성을 죽여 학습을 막고, SLO·에러버짓이 없어 안정성을 객관적으로 관리하지 못합니다. 신뢰성이 '느낌'과 '정치'의 영역에 머뭅니다.
진단:
□ 최근 장애의 포스트모템이 '사람'을 지목하나, '시스템'을 지목하나?
□ 재발한 장애가 있나? (학습 실패의 증거)
□ "안정적인가?"에 SLI 숫자로 답할 수 있나?
해결: (1) 비난 없는 포스트모템 도입 — '누구'가 아니라 '왜 시스템이 막지 못했나'를 묻고, 재발방지 액션(가드레일·테스트·자동화·알람)을 로드맵과 이슈 트래킹 이슈로 추적. (2) 핵심 SLI를 측정하고 SLO·에러버짓을 정의해 안정성을 데이터로 관리. (3) 온콜·IC 역할을 평시에 합의(개발 조직의 역할). 신뢰성은 영웅의 야근이 아니라, 측정·문화·시스템으로 만들어집니다.
심화 — 숫자는 좋은데 고객이 화나 있다면
심화: SLI는 '어디서·무엇으로 재는가'가 절반이다
SLO를 정의하는 것보다 어려운 것이 SLI를 올바르게 재는 일입니다. 측정 지점과 성공의 정의가 어긋나면, 대시보드는 좋은데 고객은 화나 있는 역설이 생깁니다.
- 측정 지점이 결과를 바꿉니다: 앱 서버 내부에서 재면, 서버가 아예 죽어 요청이 도달하지 못한 시간은 분모에서 사라집니다 — 최악의 장애일수록 가용성이 좋아 보이는 왜곡입니다. SLI는 사용자에 가까운 지점(로드밸런서·엣지, 가능하면 클라이언트)에서 잴수록 진실에 가깝습니다.
- '성공'의 정의가 부풀 수 있습니다: 헬스체크·내부 호출 트래픽이 분모에 섞이면 성공률이 부풀고, HTTP 200이지만 본문이 에러인 응답은 실패로 안 잡힙니다. SLI 정의서에 '무엇을 요청으로 세고, 무엇을 성공으로 보는가'를 명시해야 팀마다 다른 숫자를 들고 오는 일이 없어집니다.
- 트래픽이 적으면 백분율이 요동칩니다: 새벽에 요청 20건 중 1건 실패는 에러율 5% — 단순 임계 경보가 오발됩니다. 그래서 burn rate 경보는 짧은 창(빠른 소진 감지)과 긴 창(오발 필터)을 함께 보는 다중 윈도우로 겁니다. 트래픽 규모가 작은 서비스일수록 이 노이즈 설계가 SLO 운영의 성패를 가릅니다.
- SLO를 인사평가에 쓰면 왜곡이 시작됩니다: SLO 달성률이 팀 성과 지표가 되는 순간, 장애를 '집계 제외'로 협상하고 SLI 정의를 느슨하게 고치려는 유인이 생깁니다. SLO는 배포 속도를 조절하는 의사결정 도구이지 잘잘못을 가리는 평가 지표가 아닙니다 — 이 원칙이 무너지면 비난 없는 문화도 함께 무너집니다.
그래서 성숙한 팀은 SLO 리뷰에서 목표 달성 여부만 보지 않고, SLI 정의와 측정 지점 자체를 주기적으로 감사합니다.
상황: 월간 신뢰성 리뷰에서 가용성 SLI 99.97%로 SLO(99.9%)를 여유 있게 달성했다고 보고했는데, 같은 달 고객센터에 접속 불가 문의가 수백 건 접수됐습니다. 실제로 그 달엔 15분짜리 전면 장애가 두 번 있었습니다.
원인: SLI를 앱 서버 내부 메트릭으로 계산하고 있었습니다. 전면 장애 때는 서버가 죽어 요청 자체가 기록되지 않으니 실패도 집계되지 않았고, 살아 있던 시간의 성공률만 남았습니다. 게다가 분모의 상당 부분이 로드밸런서의 헬스체크 트래픽이라 성공률이 더 부풀어 있었습니다.
진단: 로드밸런서 액세스 로그의 총 요청 수·5xx 수와 앱 메트릭을 같은 시간 창으로 비교합니다. 장애 시간대에 LB에는 502가 쏟아졌는데 앱 메트릭에는 그 요청이 아예 없다면, 측정 지점이 잘못된 것입니다.
해결: (1) 가용성 SLI의 기준을 앱 내부가 아니라 로드밸런서(사용자에 가장 가까운 지점) 로 옮기고, 헬스체크·내부 트래픽을 분모에서 제외합니다. (2) '성공'의 정의를 문서화합니다 — 200이어도 에러 본문이면 실패로 집계. (3) 재계산한 SLI로 에러버짓을 다시 산정하면 이미 소진 상태일 수 있으므로, 안정화 우선순위를 다시 잡습니다(용어사전). 잘못 잰 SLO는 없느니만 못합니다 — 팀에게 '우리는 안정적'이라는 근거 있는 착각을 주기 때문입니다.
인프라/SRE로서 이 모듈은 당신 직무의 핵심 철학입니다 — 신뢰성을 SLI로 측정하고 SLO·에러버짓으로 '안정성 vs 속도'를 데이터로 조율하며(용어사전·릴리스 전략), 장애는 비난 없는 포스트모템으로 학습해 시스템을 고칩니다. 에러버짓은 개발팀과의 오랜 긴장(빠른 배포 vs 안정)을 푸는 공통 언어가 됩니다. PM은 SLO를 비기능 요구(요구사항 정의)로 명시하고, 에러버짓 소진 시 '안정화 모드'를 로드맵에 반영하며, 포스트모템 액션이 기술 부채(기술 부채와 리팩터링)처럼 꾸준히 상환되도록 우선순위를 지킵니다.
이것으로 본론 6개 Phase(개발자의 언어·큰그림·요구사항·협업·배포·아키텍처·품질문화)를 마칩니다. 이어지는 '용어사전(Phase G)'에서 도메인별 실무 용어를 빠르게 해독하는 레퍼런스를 제공합니다.
실전 랩으로 손에 익히기: SLO·에러버짓 실습 — SLI·SLO·에러버짓과 blameless 포스트모템을 설계합니다.