스프린트 플래닝. PO가 "이 기능 며칠 걸려요?"라고 묻자 개발자 A는 "3일", B는 "일주일"이라 답합니다. 같은 작업인데 추정이 두 배 넘게 벌어집니다. 한편 백로그엔 하고 싶은 일이 50개. 무엇부터 할지 회의가 한 시간째 평행선입니다. "이게 더 중요해요" "아니 저게 먼저죠"의 반복. 추정과 우선순위는 감이 아니라 방법이 필요합니다 — 그래야 논쟁이 결정으로 바뀝니다.
- 1스토리 포인트가 "절대 시간"이 아니라 "상대 크기"인 이유를 설명할 수 있다
- 2RICE로 백로그 항목의 우선순위를 점수화할 수 있다
- 3MoSCoW로 릴리스 범위의 필수/선택을 가를 수 있다
- 4우선순위 논의에 운영 비용(TCO)을 포함시킬 수 있다
추정 — 왜 '시간'이 아니라 '크기'인가
 확대
확대
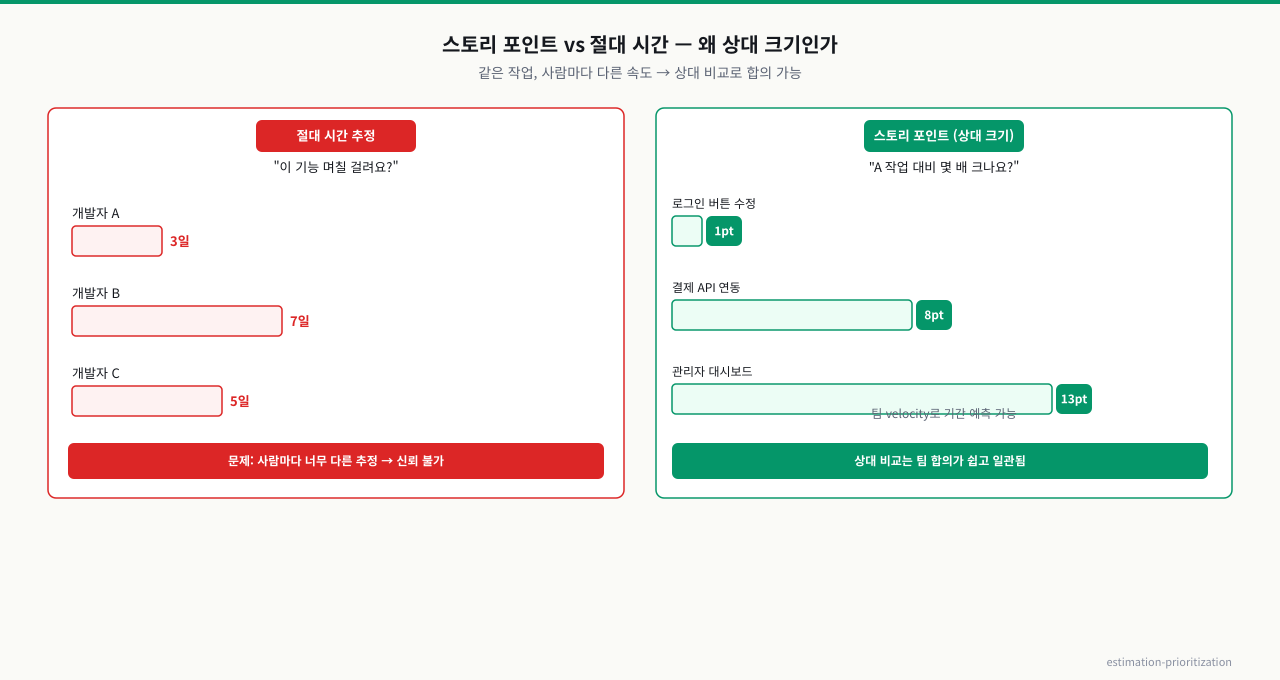
위 그림처럼 같은 작업에 사람마다 추정이 두 배 이상 벌어지는 것이 절대 시간의 문제이고, 스토리 포인트의 상대적 비교는 팀 합의가 훨씬 일관된다.
상대 추정: 사람마다 다른 속도 문제를 우회한다
"며칠 걸려요?"가 빗나가는 이유는 사람마다 속도가 다르고, 같은 사람도 컨디션·방해 요소에 따라 다르기 때문입니다. 절대 시간은 본질적으로 불안정합니다.
스토리 포인트는 작업의 상대적 크기/복잡도/불확실성을 숫자로 매깁니다(보통 피보나치: 1,2,3,5,8,13). "이 작업은 기준 작업(2점)보다 두 배쯤 복잡 → 5점"처럼 비교합니다.
기준 잡기: "회원 이메일 검증" = 2점 (팀이 합의한 기준 작업)
비교: "소셜 로그인 연동" = 5점 (외부 의존·예외 많음 → 더 큼)
"오타 수정" = 1점
여기에 팀의 **속도(velocity, 스프린트당 완료 포인트)**를 결합하면 "이 백로그(40점)는 우리 속도(20점/스프린트)로 약 2스프린트"라는 예측이 나옵니다. 단, 포인트를 시간으로 1:1 환산하는 순간(5점=5일) 상대 추정의 장점이 사라지니 주의합니다.
우선순위 — 논쟁을 점수로
 확대
확대
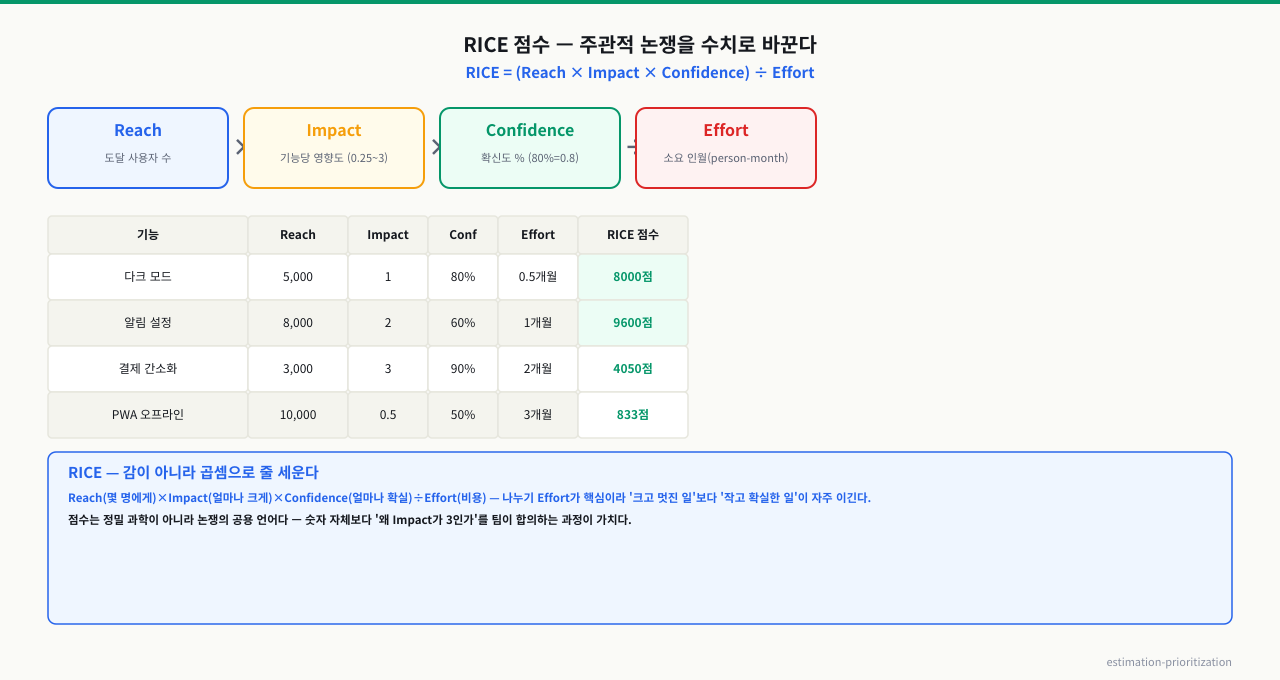
위 그림처럼 RICE = (Reach × Impact × Confidence) ÷ Effort로 계산하면 "이게 더 중요해"라는 논쟁이 비교 가능한 점수로 바뀌어 객관적 우선순위 결정이 가능해진다.
RICE와 MoSCoW: 주관을 비교 가능하게
"이게 더 중요해"의 반복을 끝내려면 공통 기준이 필요합니다.
RICE = (Reach × Impact × Confidence) / Effort
- Reach: 일정 기간 얼마나 많은 사용자에게 닿나
- Impact: 닿은 사용자당 영향 크기(3=큼,2=중,1=소,0.5=미미)
- Confidence: 위 추정에 대한 확신(%) — 데이터 있으면 높게
- Effort: 필요한 노력(사람·스프린트)
기능 A: Reach 5000 × Impact 2 × Confidence 0.8 / Effort 3 = 2667
기능 B: Reach 800 × Impact 3 × Confidence 1.0 / Effort 1 = 2400
→ A가 약간 우위. 숫자로 비교 가능 → 논쟁이 검증으로.
MoSCoW — 릴리스 범위 가르기:
- Must: 없으면 출시 무의미(소수여야 정상)
- Should: 중요하나 빠져도 출시 가능
- Could: 있으면 좋음(여유 시)
- Won't(this time): 이번엔 안 함(= Out of Scope)
RICE는 '무엇이 가성비 좋은가', MoSCoW는 '이번 릴리스에 무엇이 필수인가'를 가립니다. 둘은 함께 씁니다.
우선순위에 운영 비용 넣기 — 직접 점검
 확대
확대
위 그림처럼 MoSCoW로 Must/Should/Could/Won't를 구분하고, 구현 공수(40%)에 모니터링·스케일링·온콜·기술부채 비용을 더한 총소유비용(TCO)으로 판단해야 진짜 우선순위가 나온다.
인프라/SRE 관점에서 가장 흔한 누락은 Effort에 '구현'만 넣고 '운영'을 빼는 것입니다. 총소유비용으로 다시 계산합니다.
기능: "실시간 추천 배너"
잘못된 Effort: 구현 3 (개발만)
올바른 Effort: 구현 3 + 운영 4 = 7
운영 항목: 추천 연산 서버 상시 가동, 모니터링·알람 추가,
트래픽 스파이크 스케일링, A/B 실험 인프라
RICE 재계산:
Before) 5000×2×0.8 / 3 = 2667 (운영비 누락 → 과대평가)
After) 5000×2×0.8 / 7 = 1143 (현실적 가성비)
→ 순위가 내려갈 수 있음. 운영비를 빼면 '싸 보이는' 기능에 속는다.
echo '구현공수 + 운영공수 = 총 Effort'- Effort에 운영 항목(모니터링·스케일·온콜·기술부채)이 포함됐는지 확인 — 구현만 들어갔으면 가성비가 부풀려진 것. 인프라가 운영 공수를 더한다
- Must로 분류된 항목이 전체의 절반을 넘으면 → 우선순위를 못 가린 것. 진짜 Must는 소수. 다시 Should로 내릴 것을 찾는다
- Confidence가 낮은(0.5 이하) 항목이 상위에 있으면 → 추정 근거가 약함. 점수를 키우기 전 데이터/프로토타입으로 확신을 먼저 올린다
- velocity(완료 포인트)가 스프린트마다 출렁이면 예측 신뢰도 낮음 → 추정 기준 작업을 재합의하거나 작업을 더 작게 쪼갠다
상황: 매 분기 RICE로 '구현 공수 작고 임팩트 큰' 기능을 우선했는데, 반년 뒤 운영팀이 모니터링 사각·수동 스케일·누적 기술부채로 장애와 야근에 시달립니다.
원인: Effort에 운영 비용을 넣지 않아 '싸 보이는' 기능이 계속 상위로 올라왔습니다. 각 기능의 운영 꼬리(모니터링·확장·유지보수)가 누적되며 보이지 않는 부채가 됐습니다.
진단 — 우선순위 점검:
□ Effort에 운영 공수(모니터링·스케일·온콜)가 포함됐나?
□ '기술부채 상환' 항목이 백로그에 주기적으로 들어가나?
□ 새 기능의 NFR(가용성·확장성)이 인프라 설계로 이어졌나?
해결: RICE의 Effort를 '총소유비용'으로 정의하고, 운영 항목을 인프라/SRE가 더합니다. 그리고 매 스프린트 일정 비율(예: 20%)을 기술부채·운영개선에 고정 배정합니다(기술 부채와 리팩터링 참고). 단기 가성비만으로 줄 세우면 미래의 운영팀이 비용을 대신 치릅니다.
심화 — 추정은 숫자가 아니라 조직을 통과하는 메시지다
심화: 추정·목표·약속의 구분 — 그리고 숫자가 굳는 경로
스토리 포인트와 RICE를 익힌 다음의 진짜 난제는 계산법이 아니라, 그 숫자가 조직을 통과하면서 겪는 일입니다. 추정이 빗나가는 것보다 추정이 왜곡되는 것이 훨씬 큰 사고를 만듭니다.
- 추정·목표·약속은 다른 것: 추정(estimate)은 확률의 표현("절반 확률로 2주, 안전하게는 4주"), 목표(target)는 비즈니스의 희망("행사 전에 나왔으면"), 약속(commitment)은 버퍼까지 결정한 합의입니다. 사고는 셋이 섞일 때 납니다 — 개발자의 "2주쯤?"이 팀장 보고에서 "2주", 경영 보고에서 "출시일"로 굳는 전달 왜곡이 전형입니다. 처방은 추정을 항상 범위로 말하는 것("잘 풀리면 2주, 보수적으로 4주")과, 약속으로 바꾸는 순간을 명시적 결정으로 만드는 것입니다.
- 앵커링을 차단해야 추정이 산다: "이거 이틀이면 되죠?"라는 요청자의 첫 숫자는 기준점(anchor)이 되어 이후 모든 추정을 끌어당깁니다. 플래닝 포커가 카드를 동시에 공개하는 이유가 바로 이것입니다 — 먼저 나온 숫자에 오염되기 전의 독립 추정을 모으는 장치입니다. 회의에서 추정을 구두로 돌아가며 말하게 하면 이 장치는 무력화됩니다.
- RICE의 점수 역산: 결론을 정해 두고 Reach·Impact를 그에 맞게 채우면 RICE는 객관의 탈을 쓴 주관이 됩니다. RICE의 진짜 용도는 순위 산출이 아니라 어느 입력값에서 의견이 갈리는지 드러내는 것입니다 — "당신은 Reach를 5000으로, 나는 800으로 봤다"는 발견이 점수보다 값집니다. 입력마다 근거(데이터 출처)를 적게 하고, 점수 차가 2배 이내인 항목은 사실상 동순위로 취급하는 것이 겸손한 사용법입니다.
- 추정의 성숙은 기술이 아니라 쪼개기: 팀이 작업을 1~3일 크기로 일관되게 쪼갤 수 있게 되면, 포인트 합산보다 개수 기반(throughput) 예측이 더 정확해지는 시점이 옵니다. 추정 정확도를 올리는 최선의 투자는 추정 회의를 늘리는 것이 아니라 작업을 작고 균일하게 만드는 것입니다.
요약하면 — 숫자를 잘 뽑는 팀보다, 숫자에 신뢰수준을 붙여 전달하고 약속과 구분해 지키는 조직이 추정을 잘하는 조직입니다.
상황: 대형 고객 계약에 '6주 후 오픈' 조항이 들어간 채 개발팀에 전달됩니다. 팀 추정은 12주. 경영 회의에서 "어떻게든 맞춰보자"가 반복되다 추정이 6주로 '조정'됩니다. 범위는 그대로입니다. 팀은 테스트 작성 생략, 코드 리뷰 약식, 스테이징 검증 생략으로 기한을 맞춥니다. 오픈은 성공 — 그리고 이후 3개월간 결함 수습과 핫픽스에 도합 20주가 들어가고, 그 사이 다음 분기 로드맵이 통째로 밀립니다.
원인: 추정이 협상으로 줄었습니다. 범위·인력·접근 방식이 그대로인데 추정치만 12주에서 6주로 바뀌었다면 그것은 재추정이 아니라 희망 사항입니다. 일정 압박은 일의 총량을 줄이지 못하므로, 압축분은 보이지 않는 곳 — 테스트·리뷰·검증이라는 품질 게이트 — 에서 빠져나갔고, 그 부채가 이자까지 붙어 돌아온 것입니다.
진단: 추정 변경 이력을 봅니다 — 추정이 줄어든 시점에 범위 축소나 접근 변경이 동반됐는지를 확인합니다. 동반되지 않은 하향은 전부 의심 대상입니다. 사후에는 오픈 후 90일간의 결함 수·핫픽스 투입 시간을 집계해 '아낀 6주 vs 치른 20주'를 숫자로 만들어 둡니다. 이 숫자가 다음 협상의 근거가 됩니다.
해결: 원칙을 하나 세웁니다 — 일정이 고정이면 협상 대상은 추정이 아니라 범위입니다. 6주가 움직일 수 없다면 MoSCoW로 Must만 남긴 6주짜리 범위를 다시 정의하고, Should 이하는 오픈 후 단계로 미룹니다. 그리고 영업·경영과의 규칙을 만듭니다: 고객 일정 약속 전에 추정 범위(낙관/보수)를 먼저 받고, 약속에는 보수 추정 기준의 버퍼를 얹습니다. 추정을 깎으면 일이 줄어드는 것이 아니라 품질이 줄어듭니다 — 이 문장을 조직이 공유하는 것이 재발 방지의 전부입니다.
PM은 RICE·MoSCoW로 이해관계자 간 우선순위 논쟁을 '비교 가능한 결정'으로 바꿉니다. 인프라/SRE는 이 논의에서 결정적 역할을 합니다 — 각 기능의 운영 비용을 가시화해, "구현 3일이지만 운영은 영원히"라는 진실을 숫자로 드러냅니다. 또한 추정 회의(플래닝 포커 등)에서 외부 의존·데이터 마이그레이션·롤백 난이도 같은 '인프라 복잡도'를 포인트에 반영하도록 목소리를 냅니다. 추정과 우선순위는 단순한 PM 업무가 아니라, 조직이 무엇에 시간을 쓸지 정하는 가장 중요한 협업입니다.
다음 모듈에서는 이렇게 정한 우선순위를 시간 축에 배치하는 로드맵과, 일을 추적하는 이슈 트래킹을 다룹니다.
실전 랩으로 손에 익히기: 추정·우선순위 실습 — 스토리포인트로 상대 추정하고 RICE·MoSCoW로 백로그를 줄 세웁니다.
관련 모듈로 더 깊이:
- 로드맵과 이슈 트래킹 — 우선순위를 시간 축에 배치하는 로드맵·이슈 트래킹
- 애자일과 스크럼 — 추정·우선순위를 스프린트 리듬에 녹이는 법
- 요구사항 정의 — 무엇을 만들지 정의해 추정의 대상을 명확히 하는 PRD