장애 알림이 울립니다. "에러율 급증, p99 지연 5초, 502가 쏟아져요." 그런데 로그는 서비스마다 흩어져 있고, 어느 요청이 어디서 막혔는지 추적이 안 됩니다. "평균 응답은 정상인데요?"라는 말에 다들 헷갈립니다. 관측성 용어를 모르면 '무엇이 언제 왜 어디서' 잘못됐는지 추적할 도구도, 언어도 없습니다. 이 사전은 관측성·장애 분석 용어를 빠르게 해독합니다. 운영 철학(SLO·포스트모템)은 SLO·에러버짓·포스트모템에서, 깊은 모니터링 실습은 관련 트랙에서 다룹니다.
- 1관측성 세 기둥(메트릭·로그·트레이스)의 역할을 구분할 수 있다
- 2핵심 지표(에러율·지연 p95/p99·처리량·자원)를 해석할 수 있다
- 3HTTP 4xx/5xx 에러코드로 문제 영역을 가를 수 있다
- 4상관 ID·스택트레이스·RCA로 장애를 추적·분석할 수 있다
관측성 세 기둥 + 도구
 확대
확대
위 그림처럼 메트릭(언제)·로그(왜)·트레이스(어디서)는 각기 다른 질문에 답합니다. 상관 ID(Trace ID)를 모든 서비스 로그에 포함시켜야 MSA에서 흩어진 데이터를 한 요청으로 묶을 수 있습니다.
메트릭·로그·트레이스, 그리고 그것을 보는 스택
| 용어 | 한 줄 뜻 | 비고 | 중요도 |
|---|---|---|---|
| Monitoring / Observability | 모니터링 / 관측성(내부상태 추론) | → SLO·에러버짓·포스트모템 | ★★★ |
| Metric / Log / Trace | 수치추세 / 이벤트기록 / 요청경로 | 세 기둥 | ★★★ |
| APM | 애플리케이션 성능 모니터링 | 코드 레벨 추적 → 애플리케이션 성능 모니터링과 대시보드 구성 | ★★ |
| Prometheus / Grafana | 메트릭 수집 / 시각화 | 대표 스택 → Prometheus Operator와 Grafana 연동 대시보드 구축 | ★★ |
| ELK / Elasticsearch / Logstash / Kibana / Filebeat / Fluentd | 로그 수집·검색·시각화 | 로그 파이프라인 → Filebeat/rsyslog 기반 로그 수집 파이프라인 구성 | ★★ |
| OpenTelemetry / Jaeger / Zipkin | 분산 추적 표준·도구 | 요청 경로 추적 | ★★ |
| Correlation ID / Request ID / Trace ID / Span ID | 요청 식별자 / 구간 식별자 | 흩어진 로그를 묶음 | ★★★ |
| Alert | 임계 초과 알림 | 경보피로 주의 → CI/CD 파이프라인 | ★★ |
핵심: 메트릭으로 '언제 이상한가'를 보고, 트레이스로 '어디서'를, 로그로 '왜'를 봅니다. 상관 ID가 있어야 MSA에서 흩어진 로그를 한 요청으로 묶습니다(모놀리식 vs 마이크로서비스).
핵심 지표
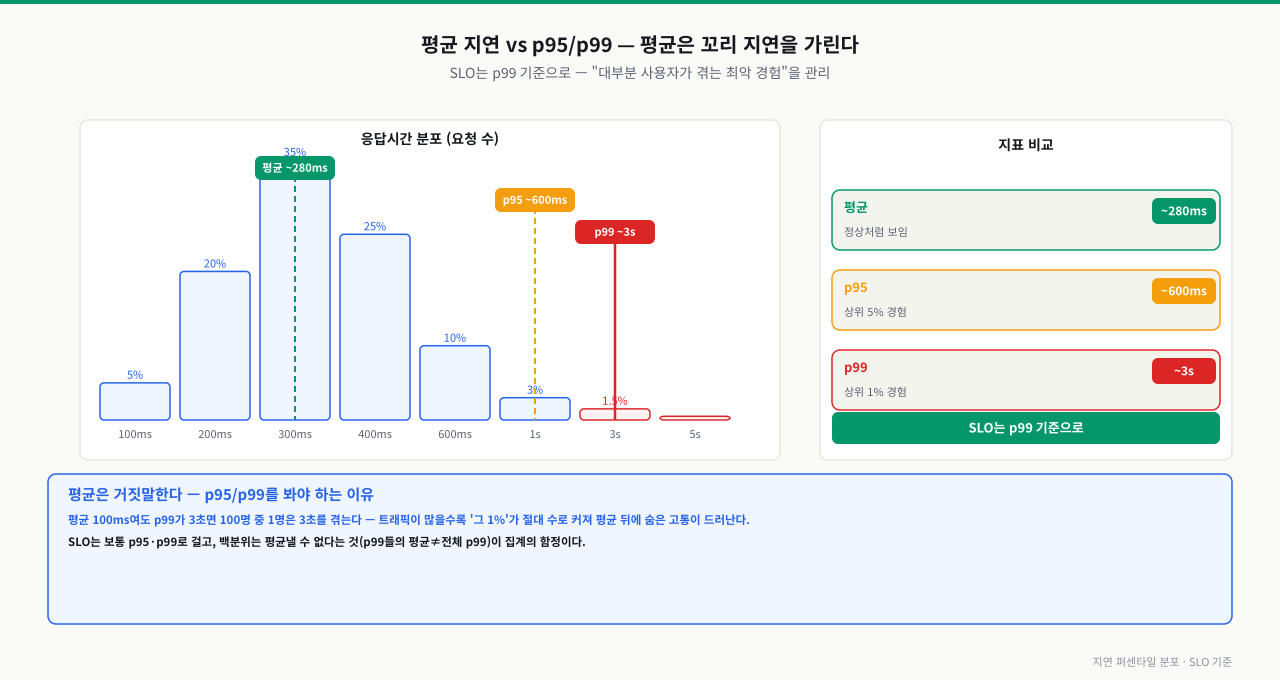 확대
확대
위 그림처럼 평균 지연은 280ms로 정상처럼 보여도 p99는 3초에 달할 수 있습니다. 빠른 요청 다수가 느린 소수를 희석하는 것이 꼬리 지연(tail latency)이며, SLO는 p99 기준으로 설정해야 실제 사용자 경험을 관리할 수 있습니다.
무엇을 보고 건강을 판단하나
| 용어 | 한 줄 뜻 | 판단 기준 | 중요도 |
|---|---|---|---|
| Error Rate | 에러 비율 | 급증=장애 1순위 신호 | ★★★ |
| Latency / p95 / p99 | 지연 / 95·99퍼센타일 | 평균 말고 p95/p99로 | ★★★ |
| Throughput / TPS / QPS | 처리량 / 초당 트랜잭션·쿼리 | 부하 추세 | ★★ |
| CPU / Memory / Disk Usage / Network I/O | 자원 사용률 | 임계 → 서버 다운 시 신속하게 CPU/메모리/네트워크/로그 확인하는 룰 | ★★ |
| GC Time / Thread Count / Connection Count | GC시간 / 스레드 / 커넥션 수 | 자바 → Heap/GC/Thread Dump 분석과 OOM 대응 실무·DB 연결 지연을 없애는 HikariCP 설정과 대기 성능 튜닝 | ★★ |
| Slow Log / Access Log / Error Log | 느린쿼리 / 접근 / 에러 로그 | 어느 로그를 볼지 | ★★ |
핵심: 평균 지연은 꼬리 지연을 가립니다 — p95/p99로 '대부분 사용자가 겪는 최악'을 봅니다. 이 값이 SLO(SLO·에러버짓·포스트모템)의 기준이 됩니다.
HTTP 에러 · 예외
 확대
확대
위 그림처럼 4xx는 클라이언트·요청 문제, 5xx는 서버 문제입니다. 특히 502(뒷단 죽음)·503(과부하)·504(느림)의 방향 차이를 파악하면 장애 대응 속도가 빨라집니다.
에러코드가 가리키는 방향
| 코드/예외 | 의미 | 방향 | 중요도 |
|---|---|---|---|
| 400 / 401 / 403 | 잘못된요청 / 미인증 / 권한없음 | 클라이언트·인증 → 용어사전 | ★★ |
| 404 / 405 / 409 / 429 | 없음 / 메서드불가 / 충돌 / 한도초과 | 라우팅·멱등·레이트리밋 | ★★ |
| 500 / 502 / 503 / 504 | 서버오류 / 게이트웨이불량 / 불가 / 타임아웃 | 5xx=서버측 | ★★★ |
| Stack Trace / Exception | 예외 호출스택 / 예외 | 원인 코드 위치 | ★★ |
| NullPointer / SQL / Socket / Timeout Exception | 대표 예외들 | NPE=널참조, Socket=연결 | ★★ |
| Connection Refused / Reset / Broken Pipe | 거부 / 재설정 / 끊김 | 뒷단 죽음·네트워크 | ★★ |
핵심: 4xx는 보통 클라이언트/요청 문제, 5xx는 서버 문제입니다. 502=뒷단 죽음/비정상, 503=과부하·점검, **504=뒷단 느림(타임아웃)**으로 방향이 갈립니다(용어사전).
장애 분석 — RCA·포스트모템
원인을 찾고 재발을 막는 용어
| 용어 | 한 줄 뜻 | 비고 | 중요도 |
|---|---|---|---|
| RCA (Root Cause Analysis) | 근본 원인 분석 | 증상 아닌 원인 | ★★ |
| Incident / Postmortem | 장애 / 사후분석 | 비난없이 → SLO·에러버짓·포스트모템 | ★★★ |
| Hotfix / Temporary Workaround | 긴급수정 / 임시조치 | 임시는 부채로 → 기술 부채와 리팩터링 | ★★ |
핵심: 임시조치(workaround)로 급한 불을 끈 뒤 RCA로 근본 원인을 찾아 포스트모템 액션(테스트·자동화·알람 추가)으로 재발을 막습니다(SLO·에러버짓·포스트모템). 임시조치를 방치하면 기술 부채가 됩니다(기술 부채와 리팩터링).
지표·로그로 장애 추적 — 직접 확인
장애 시 메트릭(언제) → 트레이스(어디서) → 로그(왜) 순으로 좁힙니다.
1) 메트릭: 에러율·p99가 언제 치솟았나? (배포 시각과 겹치나?)
2) 에러코드: 5xx 중 무엇? 502(뒷단 죽음)/503(과부하)/504(느림)
3) 트레이스: 느린 요청의 Trace ID로 어느 서비스/구간이 병목인지
4) 로그: 그 Trace ID로 모든 서비스 로그를 묶어 예외·원인 확인
에러율 0.1%→8% (14:02, v1.3 배포 직후) → 배포가 원인 1순위
5xx 분포: 504 Gateway Timeout 다수 → 뒷단 '느림'(죽음 아님)
Trace abc123: payment-service 4.8s 점유 → 그 서비스 슬로우([[glossary-db-sql]])
로그(abc123): "Slow query ... orders Full Scan" → 인덱스 부재
→ 14:02 배포의 쿼리 변경 의심 → 롤백 + 인덱스 추가
echo '대시보드 에러율·p99 → 상관ID로 로그 추적'- 에러율/지연 급증 시각이 배포 시각과 겹치면 그 배포가 1순위 의심 → 릴리스 전략로 롤백 우선, 원인은 그다음
- 5xx 종류로 방향을 가른다: 502=뒷단 죽음(재시작?), 503=과부하(스케일?), 504=뒷단 느림(슬로우쿼리·외부지연)(용어사전)
- p99가 나쁜데 평균은 정상이면 꼬리 지연 — 일부 요청만 느린 것. 트레이스로 그 느린 요청의 병목 구간을 특정
- 상관ID(Trace ID)가 로그에 없으면 분산 추적 불가 → 진입점에서 ID 부여·전파를 인프라가 표준화해야 함(모놀리식 vs 마이크로서비스)
상황: 대시보드의 평균 응답시간은 200ms로 양호한데, 일부 사용자가 "몇 초씩 걸린다"고 항의합니다. 평균만 보던 팀은 문제를 재현·인지하지 못합니다.
원인: 평균이 꼬리 지연(tail latency)을 가린 것입니다. 빠른 요청 다수가 느린 소수를 희석해 평균은 좋아 보이지만, p95/p99로 보면 '상위 1~5% 사용자'는 수 초를 겪고 있습니다.
진단:
□ p95/p99 지연을 보고 있나? (평균만 보면 함정)
□ 느린 요청의 Trace ID로 병목 구간(특정 쿼리·외부호출)을 특정했나?
□ 특정 조건(데이터 많은 사용자·특정 엔드포인트)에 몰리나?
해결: 대시보드에 p95/p99를 핵심 지표로 추가하고(SLO·에러버짓·포스트모템), 느린 요청을 트레이스로 추적해 병목(N+1·슬로우쿼리·외부 동기호출)을 특정합니다(용어사전·동기 vs 비동기). SLO를 p99 기준으로 잡으면 '대부분 사용자의 최악 경험'을 관리하게 됩니다. 평균은 안심을 주지만 진실을 가립니다.
심화 — 다 수집하면 다 보일 것이라는 착각
심화: 샘플링·카디널리티·경보 피로 — 관측에도 예산이 있다
세 기둥을 갖췄다면 다음 질문은 '얼마나 수집하고 얼마나 버릴 것인가'입니다. 관측 데이터는 공짜가 아니고, 무한정 모으면 비용보다 먼저 관측 시스템 자체가 무너집니다.
- 트레이스는 대부분 샘플링됩니다: 전 요청을 저장하면 비용이 폭발하므로 보통 일부(예: 1%)만 남깁니다. 문제는 '고객이 항의한 바로 그 요청'이 샘플에 없을 수 있다는 것 — 그래서 에러·느린 요청을 우선 보존하는 tail 기반 샘플링이 필요합니다. '트레이스가 있다'와 '그 요청의 트레이스가 있다'는 다른 말입니다.
- 메트릭 라벨은 유한한 값만: 메트릭은 라벨 값 조합마다 별도 시계열을 만듭니다. user_id·세션·원본 URL처럼 고유값이 무한한 식별자를 라벨에 넣으면 시계열이 수백만 개로 폭발(카디널리티 폭발)해 모니터링 서버가 먼저 죽습니다. 개별 사건의 추적은 메트릭이 아니라 로그·트레이스의 역할 — 세 기둥의 역할 구분은 비용 설계이기도 합니다.
- 로그는 레벨·보존 정책이 비용을 결정합니다: '일단 전부 DEBUG로'는 스토리지·검색 비용을 폭발시키고 정작 장애 때 검색을 느리게 만듭니다. 구조화 로그 + 환경별 레벨 + 보존 기간 차등(예: 상세 7일, 요약 90일)이 기본기입니다(Filebeat/rsyslog 기반 로그 수집 파이프라인 구성).
- 경보 개수는 관측 수준이 아닙니다: 알람을 많이 걸수록 잘 보는 게 아니라, 대응할 수 없는 알람이 진짜 신호를 묻습니다(경보 피로). 알람은 '사람이 지금 행동해야 하는 것'에만 걸고 나머지는 대시보드·티켓으로 내립니다 — '새벽에 깨울 가치가 있는가'가 기준입니다.
그래서 성숙한 팀은 관측 파이프라인 자체를 하나의 시스템으로 운영합니다 — 시계열 수·로그 용량·알람 대응률을 주기적으로 점검하고, '수집했지만 아무도 안 보는 데이터'를 정리합니다.
상황: VIP 고객의 '느리다'는 문의를 조사하려고 요청 지연 메트릭에 user_id 라벨을 추가했습니다. 이틀 뒤 모니터링 서버의 메모리가 치솟아 죽었고, 대시보드·알람이 전부 멈춘 사이 실제 서비스 장애가 겹쳐 '눈 감고 대응'하는 최악의 상황이 됐습니다.
원인: 카디널리티 폭발입니다. 메트릭은 라벨 값 조합마다 별도의 시계열을 유지하는데, 수십만 명의 user_id가 라벨로 들어가자 시계열이 수만 개에서 수백만 개로 폭증했습니다. 메트릭 시스템은 '적은 수의 시계열을 오래 보는' 집계 도구이지, 개별 사용자를 추적하는 도구가 아닙니다.
진단: 메트릭 시스템의 총 시계열 수 추이를 보면 라벨 추가 배포 시점부터 수직 상승합니다. 라벨별 고유값 개수(카디널리티) 상위를 뽑아 user_id가 압도적인지 확인합니다 — 시계열 폭증 시점과 배포 시점이 일치하면 확정입니다.
해결: (1) user_id 라벨을 제거해 시계열 수를 원상 복구합니다. (2) 개별 사용자 추적은 역할에 맞는 기둥으로 옮깁니다 — 요청에 Trace ID를 남겨 그 사용자의 로그·트레이스를 검색하는 방식으로, 메트릭에는 집계(전체 p99·에러율, SLO·에러버짓·포스트모템의 SLI)만 남깁니다. (3) 재발 방지로 '메트릭 라벨은 유한한 값(상태 코드·엔드포인트·리전)만'이라는 가이드를 정하고, 시계열 수 자체에도 알람을 겁니다. 관측 시스템이 죽으면 모든 장애가 깜깜이가 되므로, 관측 인프라의 용량도 관측 대상입니다.
인프라/SRE에게 관측성은 직무의 눈입니다 — 메트릭·로그·트레이스를 엮어 장애를 '언제·어디서·왜'로 추적하고(SLO·에러버짓·포스트모템), 상관 ID로 MSA의 흩어진 로그를 묶습니다. 깊은 모니터링 실습(Prometheus·Loki·APM)은 관련 트랙에 있습니다. PM은 이 용어로 장애 보고를 정확히 읽고("502 다수=뒷단 죽음", "p99 악화=꼬리 지연"), 포스트모템 액션을 백로그로 추적합니다(로드맵과 이슈 트래킹). 관측성 없는 운영은 깜깜이 운전이며, 좋은 지표는 사고를 조기에 드러냅니다.
다음 용어사전에서는 대량 데이터를 다루는 배치·비동기 처리 용어를 정리합니다.
용어 식별 실습으로 굳히기: 용어 식별 — Observability / 장애 분석 — 알람·증상을 보고 메트릭·로그·트레이스·SLO 용어를 가려냅니다.