신규 팀원이 묻습니다. "제 코드 main에 머지됐는데, 언제 실서버에 반영돼요?" 한 팀은 "자동으로 5분 뒤요", 다른 팀은 "담당자가 수동으로 새벽에 올려요"라고 답합니다. 배포 사고가 나자 한쪽은 "파이프라인 로그 보면 어느 단계서 깨졌는지 나와요", 다른 쪽은 "누가 뭘 올렸는지 아무도 몰라요"가 됩니다. CI/CD는 '머지된 코드가 어떤 자동화된 길을 거쳐 사용자에게 닿는가'입니다. 이 길이 있느냐 없느냐가 배포의 속도와 안전을 가릅니다.
- 1CI가 "자주 통합하고 자동 검증"하는 실천임을 설명할 수 있다
- 2Continuous Delivery와 Deployment의 차이를 "마지막 승인 자동화 여부"로 구분할 수 있다
- 3파이프라인 단계(빌드→테스트→산출물→배포)와 fail-fast 게이트를 설명할 수 있다
- 4파이프라인 실패가 무시되는 상황의 위험과 대응을 제시할 수 있다
 확대
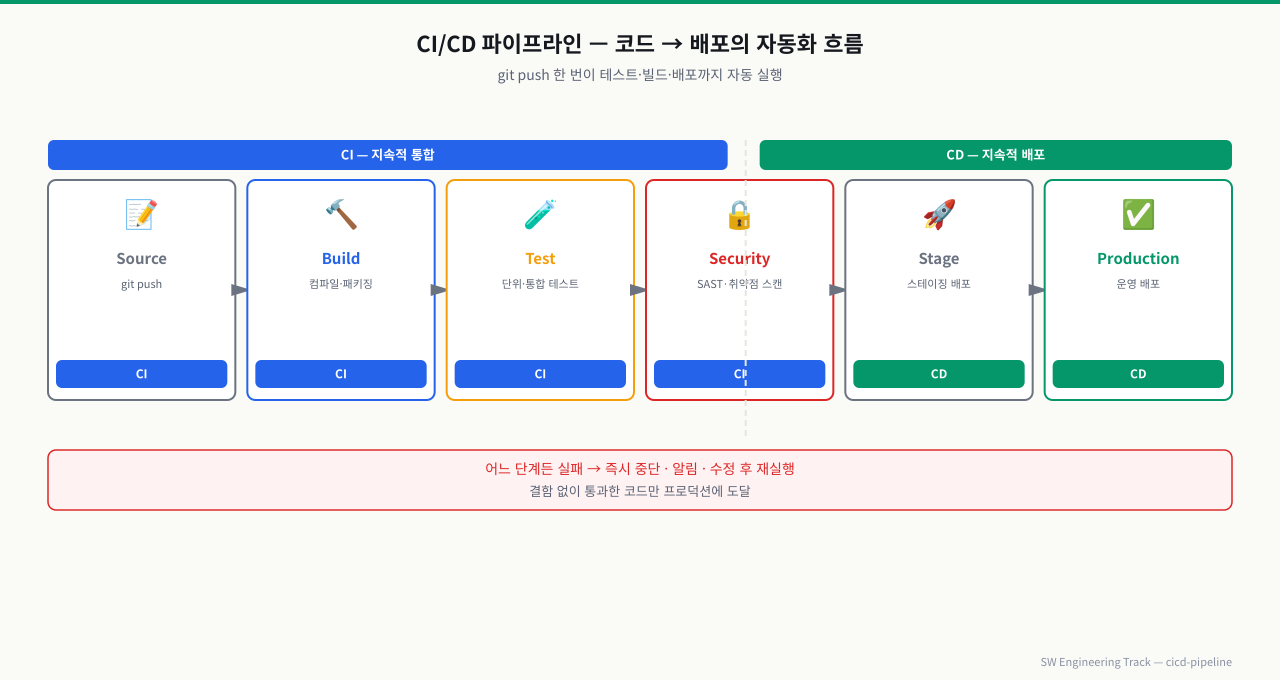
위 그림처럼 CI/CD 파이프라인은 git push 한 번이 빌드·테스트·보안 검사·배포까지 자동으로 이어지며, 어느 단계든 실패 시 즉시 차단합니다.
확대
위 그림처럼 CI/CD 파이프라인은 git push 한 번이 빌드·테스트·보안 검사·배포까지 자동으로 이어지며, 어느 단계든 실패 시 즉시 차단합니다.
CI — 자주 통합하고 즉시 검증
CI: 깨짐을 빨리 발견하는 안전망
CD — 전달 vs 배포
언제든 배포 가능 vs 통과하면 곧장 배포
CD는 두 가지를 뜻할 수 있어 맥락으로 구분합니다.
-
Continuous Delivery(지속적 전달): 테스트 통과 후 '언제든 배포 가능한 산출물' 까지 자동으로 준비. 프로덕션 배포 '실행'만 사람이 버튼을 누름. → 배포 타이밍을 비즈니스가 통제.
-
Continuous Deployment(지속적 배포): 마지막 승인까지 완전 자동. 파이프라인을 통과하면 사람 개입 없이 프로덕션으로. → 자동화·테스트 신뢰가 높은 팀.
-
Delivery: CI → 테스트 통과 → 산출물 준비 → [사람이 승인] → prod
-
Deployment: CI → 테스트 통과 → 산출물 준비 → 자동 → prod (개입 없음)
PM 관점: Delivery면 "배포 시점"을 마케팅·릴리스 일정에 맞출 수 있고(기능 플래그와 함께 더 유연), Deployment면 "머지 = 곧 출시"이므로 작은 변경을 빠르게 내보냅니다. 어느 쪽이든 릴리스 전략의 점진 배포(카나리 등)와 결합해 위험을 관리합니다.
 확대
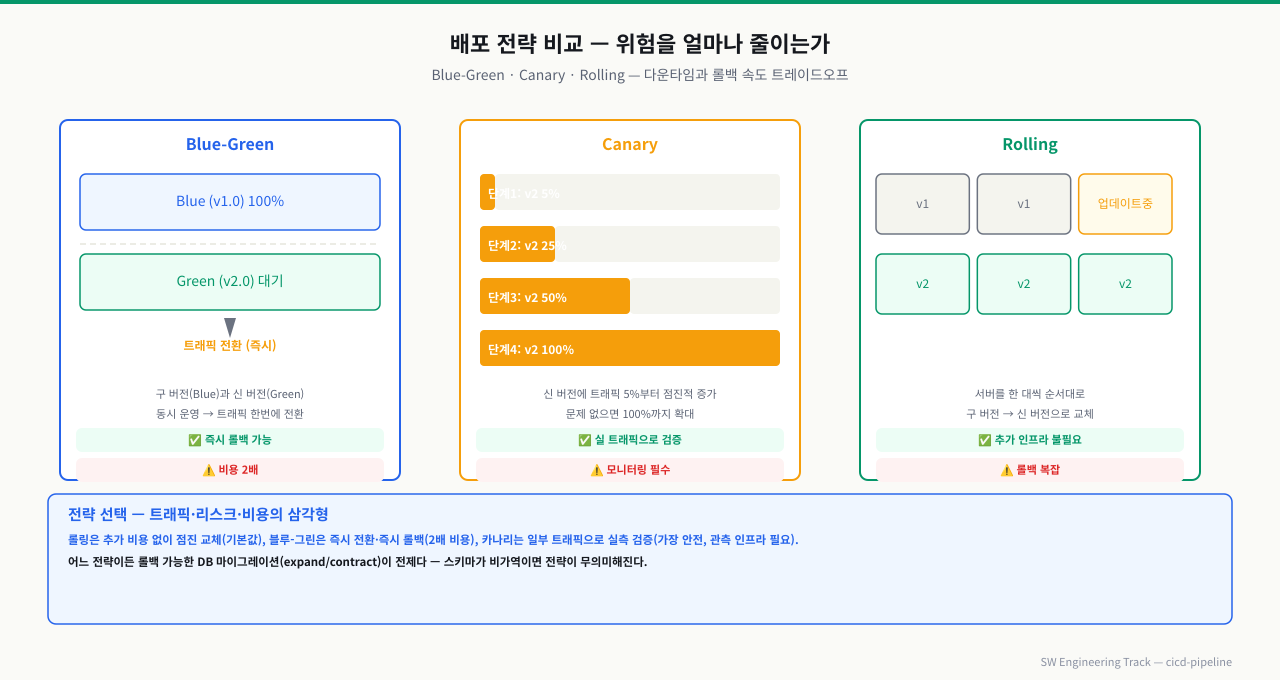
위 그림처럼 Blue-Green은 즉시 롤백이 가능하고, Canary는 실 트래픽으로 검증하며, Rolling은 추가 인프라 없이 순차 교체합니다.
확대
위 그림처럼 Blue-Green은 즉시 롤백이 가능하고, Canary는 실 트래픽으로 검증하며, Rolling은 추가 인프라 없이 순차 교체합니다.
커밋 하나가 배포까지 가는 법 — 파이프라인 단계
커밋 하나가 배포까지 가는 법 — CI/CD 파이프라인 7단계
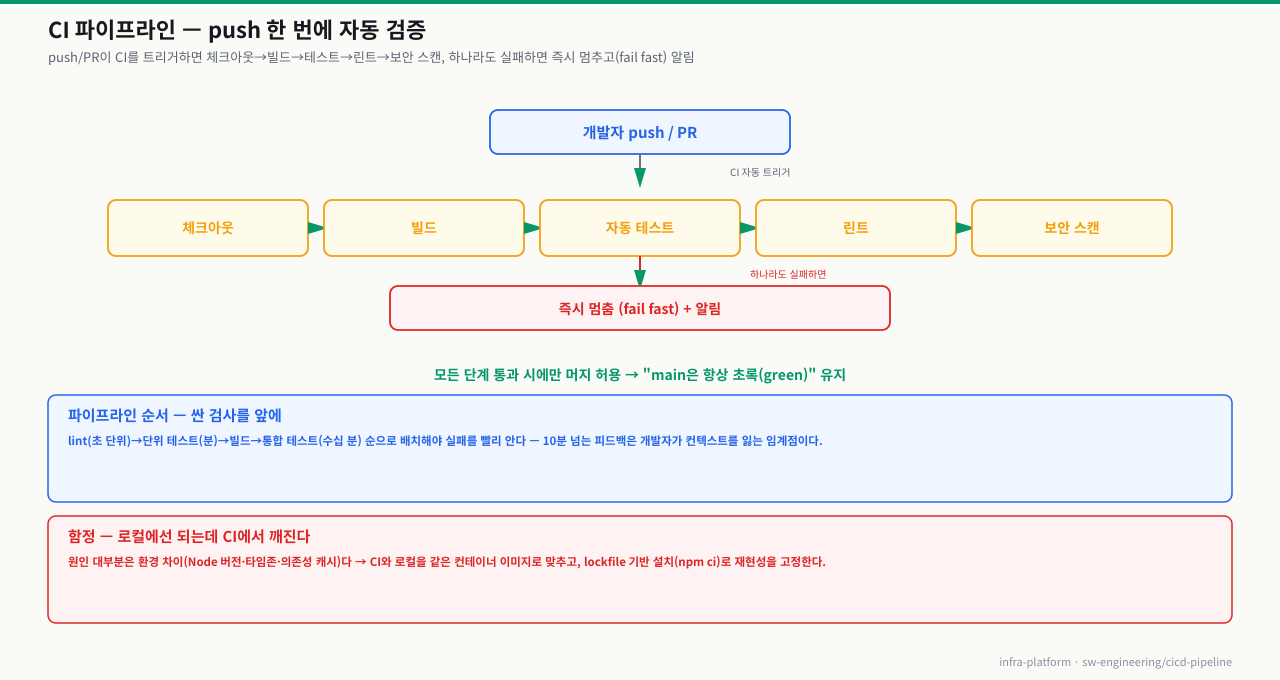
git push 한 번, 또는 PR 머지 한 번. 몇 분 뒤 그 변경이 실서버에 떠 있습니다. 그 사이 트리거·체크아웃·빌드·테스트·이미지 빌드·배포·검증이 순서대로, 앞 단계가 통과해야만 다음으로 자동 실행됩니다. 이 단계 사슬을 알아야 파이프라인이 빨갛게 떴을 때 "어느 칸에서, 왜" 멈췄는지를 좁힐 수 있습니다 — 초반에 깨졌으면 코드·테스트, 후반이면 인프라·배포로 원인 계열이 갈립니다.
[개발자] git push / PR 머지
│
① 트리거: webhook이 CI 서버에 이벤트 통지 (어느 브랜치·태그에 어느 워크플로)
│
② 체크아웃: 해당 커밋을 러너로 가져옴 + 의존성 설치 (캐시 활용)
│
③ 빌드: 소스 컴파일·번들 → 실패하면 즉시 중단 (fail-fast)
│
④ 테스트: 린트 → 단위 → 통합/E2E (빠른 것 먼저) + 보안 스캔
│
⑤ 산출물: 이미지 빌드 → 레지스트리 푸시 (digest로 고정)
│
⑥ 배포: 스테이징 → 헬스체크 → [승인] → 프로덕션 (같은 산출물 승격)
│
⑦ 배포 후 검증: 헬스체크·스모크 테스트 → 실패 시 롤백
▼
[프로덕션] 사용자에게 반영
각 단계에서 무슨 일이 일어나고, 깨지면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 깨지면 |
|---|---|---|
| ① 트리거 | webhook이 어떤 이벤트(브랜치·태그)에 어떤 워크플로를 돌릴지 결정 | webhook 미설정·필터 오류 → 파이프라인이 아예 안 돎 |
| ② 체크아웃·설치 | 커밋 소스 fetch + 의존성 설치, 캐시로 단축 | 의존성·네트워크·오염된 캐시 → "로컬은 되는데 CI만 실패" |
| ③ 빌드 | 컴파일·번들. 실패하면 뒤 단계로 안 넘어감(fail-fast) | 컴파일 에러·버전 불일치 → 초반(1~2분)에 실패 |
| ④ 테스트·스캔 | 린트·단위·통합·보안. 하나라도 실패하면 게이트가 머지·배포 차단 | 테스트 실패는 회귀를 잡은 것(정상) / flaky는 간헐 실패로 신뢰를 무너뜨림 |
| ⑤ 산출물 | 이미지 빌드 후 레지스트리 푸시. digest가 "검증한 바로 그 물건" | 환경마다 재빌드하면 스테이징과 프로덕션 산출물이 다른 물건이 됨 |
| ⑥ 배포 | 스테이징 검증 후 승인(Delivery)·자동(Deployment)으로 prod. 같은 산출물 승격 | 배포 잡에 동시성 제어 없음 → 배포 순서 역전(오래된 커밋이 최신을 덮음) |
| ⑦ 배포 후 검증 | 헬스체크·스모크로 확인, 실패 시 이전 버전으로 롤백 | 검증 단계 없음 → 깨진 배포가 그대로 사용자에게 노출 |
각 단계는 앞 단계의 성공을 전제로만 시작됩니다(fail-fast) — 그래서 멈춘 칸 앞은 전부 통과했다는 뜻이고, 멈춘 칸이 곧 원인의 위치입니다. gh run view <run-id> --log-failed로 "어느 잡에서 멈췄나"를 보면, ②④(초반, 12분)면 코드·테스트·환경 문제, ⑥~⑦(후반)이면 배포 권한·동시성·인프라 문제로 의심 방향이 갈립니다. 파이프라인 진단은 "무엇이 틀렸나"보다 "어느 단계에서 멈췄나"를 먼저 읽는 데서 시작합니다.
파이프라인 읽기 — 직접 확인
배포 사고나 지연 시, 파이프라인 로그가 "어느 단계에서 무엇이 깨졌나"를 알려줍니다. 코드를 못 짜도 단계별 성패는 읽을 수 있습니다.
# 최근 파이프라인 실행 목록(성공/실패/소요시간)
gh run list --limit 10
# 실패한 실행의 어느 잡/단계에서 깨졌는지
gh run view <run-id> --log-failed | head -40
$ gh run list --limit 5
STATUS WORKFLOW BRANCH EVENT ELAPSED
✓ ci main push 4m12s
✗ ci main push 1m03s ← 실패! 1분에 멈춤 = 초반(빌드/테스트)
✓ deploy main tag 6m40s
$ gh run view --log-failed
✗ test: payment.spec.ts > 중복결제 방지 FAILED
Expected 1 charge, got 2 ← 테스트가 회귀 버그를 잡음(게이트 작동)
gh run list --limit 10- 실패가 초반(빌드/테스트, 1~2분)에 났으면 코드/테스트 문제 — fail fast가 잘 작동한 것. 후반(배포 단계) 실패면 인프라/환경 문제로 의심 방향이 다르다
- --log-failed에서 실패한 테스트 이름이 곧 회귀가 난 기능 — 그 테스트가 "막아준" 것이므로 게이트가 정상. 통과시켜 배포했다면 그 버그가 prod로 갔을 것
- 파이프라인 소요시간이 점점 길어지면(예: 4분→15분) 개발 피드백 루프 악화 → 테스트 병렬화·캐시로 단축 검토(인프라 과제)
- 같은 테스트가 돌릴 때마다 성패가 바뀌면(flaky) → 격리/수정. 방치하면 팀이 빨간불을 무시하기 시작해 게이트 전체가 무력화된다
상황: CI가 간헐적으로(테스트 flaky·환경 불안정) 실패하자 팀이 "또 그거겠지" 하며 빨간불을 무시하기 시작합니다. 그러다 진짜로 깨진 빌드가 main에 섞여, 정작 배포해야 할 때 파이프라인이 막혀 모두가 멈춥니다.
원인: 경보 피로(alert fatigue) 입니다. 신뢰할 수 없는 신호(자주 거짓 실패)는 사람을 무감각하게 만들어, 신호 자체의 가치를 파괴합니다. "초록이 의미 없는" 상태가 되면 게이트는 형식만 남습니다.
진단:
# 최근 실패들의 원인이 같은 flaky 테스트인지 패턴 확인
gh run list --status failure --limit 20 --json conclusion,displayTitle
# 동일 테스트가 반복 실패↔성공이면 flaky 확정
해결: (1) flaky 테스트를 즉시 격리(quarantine)해 메인 신호에서 분리하고 별도 수정. (2) "main은 항상 초록"을 깨는 커밋은 머지 금지(보호 규칙). (3) 빨간불이 뜨면 새 작업보다 복구를 우선(stop-the-line)하는 규범. 신뢰할 수 있는 파이프라인은 자동화의 양이 아니라 '신호의 정직함'에서 옵니다. 인프라/SRE가 이 신뢰를 지키는 책임자입니다.
심화 — 초록 파이프라인이 보장하지 않는 것
심화: 검증한 것과 배포한 것이 같은 물건인가 — 빌드 한 번 원칙
단계와 게이트를 갖춰도 사고가 나는 영역이 남습니다. 대부분 "스테이징에서 검증한 것과 프로덕션에 배포한 것이 같은 물건인가"라는, 파이프라인 설계자만 답할 수 있는 질문에서 시작됩니다.
- 한 번 빌드, 여러 번 승격(build once, promote): 환경마다 다시 빌드하는 파이프라인은 stg에서 검증한 바이너리와 prod 바이너리가 다를 수 있습니다 — 빌드 시각에 따라 딸려 들어가는 의존성 버전이 달라지기 때문입니다. 검증은 산출물(이미지 digest)에 하고, 승격은 같은 산출물을 다음 환경으로 옮기는 것이어야 합니다. 재빌드가 끼어드는 순간 stg 검증은 참고자료로 격하됩니다.
- 파이프라인 정의도 코드이고, 공격 표면입니다: 서드파티 액션·플러그인을 버전 태그로 참조하면 그 태그는 소유자가 언제든 다른 커밋으로 옮길 수 있습니다 — 커밋 해시로 고정하는 것이 안전합니다. 파이프라인 파일의 변경은 곧 '배포 권한을 가진 코드'의 변경이므로 애플리케이션 코드와 같은 리뷰(PR과 코드 리뷰)를 거쳐야 합니다.
- 캐시는 양날입니다: 의존성 캐시는 파이프라인을 몇 배 빠르게 하지만, 오염된 캐시는 "로컬에선 되는데 CI만 실패"(또는 그 반대)라는 미궁을 만듭니다. 원인 불명 실패의 표준 절차에 '캐시 무효화 후 재실행'을 넣어두면 조사 시간이 크게 줄어듭니다.
- 속도는 문화가 됩니다: CI가 15분을 넘기 시작하면 개발자들은 커밋을 모아서 올리고(작은 통합 붕괴), 결과를 안 기다리고 다음 일로 넘어가며, '급하니 스킵하자'는 요청이 늘어납니다. 파이프라인 소요시간은 기술 지표가 아니라 팀의 행동을 바꾸는 조직 지표로 관리해야 합니다.
상황: PR 두 개가 10분 간격으로 머지돼 각각 배포 파이프라인이 돌았습니다. 먼저 머지된 커밋의 파이프라인은 테스트 재시도 때문에 25분 걸렸고, 나중 커밋의 파이프라인은 12분 만에 끝났습니다. 결과: 나중 커밋이 먼저 배포되고, 그 뒤 먼저 커밋의 배포가 완료되며 더 오래된 코드로 프로덕션을 덮어썼습니다. 두 실행 모두 초록이라 아무 경보도 없었고, 개발자는 자기 변경이 사라진 것을 다음 날에야 발견했습니다.
원인: 배포 잡에 동시 실행·순서 제어가 없습니다. 각 파이프라인은 자기 커밋 기준으로 각자 성공했을 뿐, "지금 prod에 떠 있는 것보다 내가 최신인가"는 아무도 검사하지 않습니다. 재시도로 소요시간이 역전되면 배포 순서도 함께 뒤집힙니다.
진단:
gh run list --workflow deploy --limit 5 --json headSha,startedAt,updatedAt
# run A(a1b2c3) 14:00 시작 → 14:25 완료
# run B(d4e5f6) 14:10 시작 → 14:22 완료 ← B가 먼저 끝나고 A가 나중에 덮음
kubectl get deploy app -o jsonpath='{.spec.template.spec.containers[0].image}'
# prod 이미지 태그가 a1b2c3(이전 커밋) → 역전 확정
해결: (1) 배포 잡에 동시성 제어를 겁니다 — 같은 환경으로의 배포는 한 번에 하나만 실행하고, 더 새 커밋이 대기 중이면 오래된 실행은 취소합니다(GitHub Actions의 concurrency group 등). (2) 배포 후 검증 단계에서 '배포된 버전 == 이 실행의 커밋'을 확인해 역전을 즉시 탐지합니다. (3) 구조적으로는 '커밋마다 배포 명령을 쏘는' 방식보다, 원하는 버전을 선언해 두면 시스템이 수렴하는 모델(GitOps)이 이 유형의 사고를 원천 차단합니다. 실행 하나하나는 옳았는데 겹치는 순간 사고가 되는 것 — 파이프라인을 잡 단위가 아니라 시스템으로 봐야 하는 이유입니다.
 확대
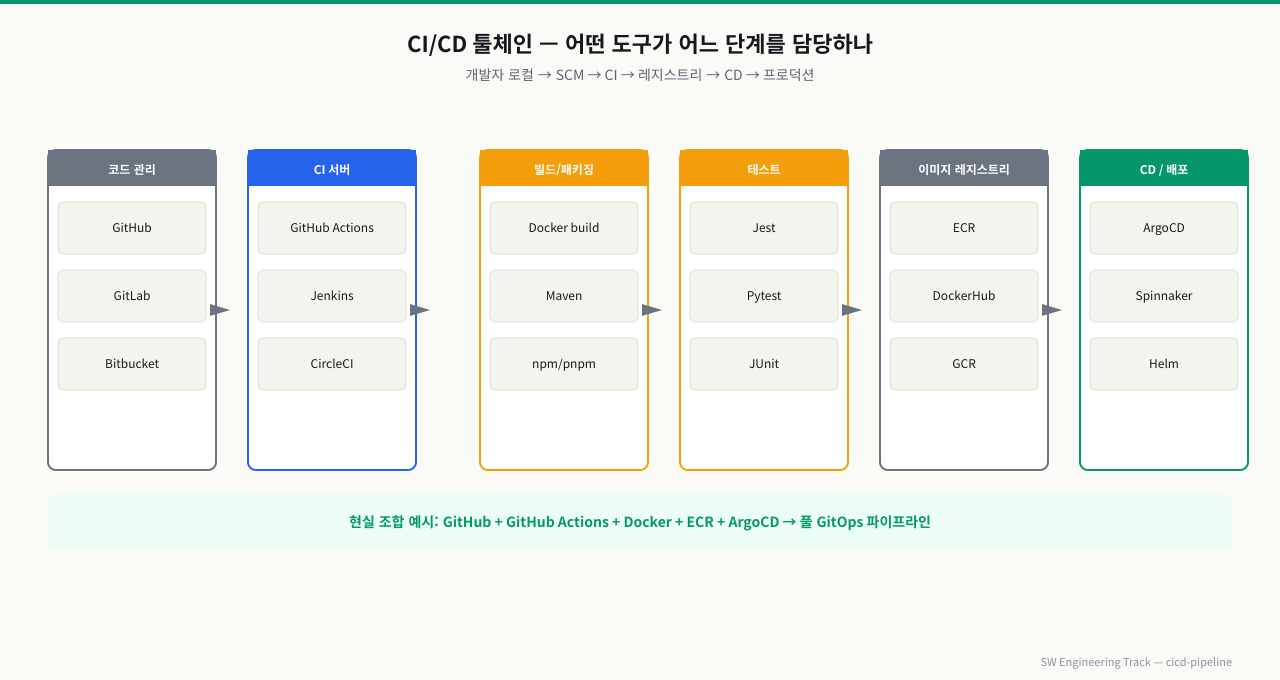
위 그림처럼 실제 CI/CD는 코드 관리·CI 서버·빌드·테스트·레지스트리·CD 배포 단계마다 전용 도구가 체인으로 연결됩니다.
확대
위 그림처럼 실제 CI/CD는 코드 관리·CI 서버·빌드·테스트·레지스트리·CD 배포 단계마다 전용 도구가 체인으로 연결됩니다.
인프라/플랫폼 엔지니어로서 CI/CD 파이프라인은 당신이 만들고 지키는 핵심 자산입니다 — GitHub Actions·GitLab CI·Jenkins 등으로 빌드·테스트·스캔·배포를 코드로 정의하고, 브랜치 전략의 규칙(어느 브랜치/태그→어느 환경)을 파이프라인에 박습니다. 파이프라인 속도(피드백 루프)와 신뢰도(flaky 제거)를 함께 관리하는 것이 SRE의 일상입니다. PM은 CI/CD 덕분에 "머지=배포 후보"라는 빠른 흐름을 일정에 반영하고, Delivery 모델이면 배포 타이밍을 비즈니스 이벤트에 맞춰 통제합니다. 파이프라인은 단순 편의가 아니라, 변경을 안전하고 반복 가능하게 사용자에게 전달하는 조직의 동맥입니다.
다음 모듈에서는 이 파이프라인의 마지막 구간 — 프로덕션에 '어떻게' 내보낼지(블루그린·카나리·롤링·기능 플래그)를 다룹니다.
실전 랩으로 손에 익히기: CI/CD 파이프라인 설계 실습 — 파이프라인 단계·품질 게이트·배포 자동화를 직접 설계합니다.