Docker로 앱을 잘 컨테이너화했습니다(Docker). 로컬에선 docker run 한 줄이면 됐는데, 운영에선 서버 3대에 컨테이너를 나눠 띄우고, 죽으면 살리고, 트래픽 늘면 더 띄우고, 무중단 배포까지 해야 합니다. 이걸 손으로 하면 곧 지옥입니다. 컨테이너 한두 개는 손으로, 수십 개는 오케스트레이터로 — 클라우드는 이 오케스트레이션을 관리형으로 제공합니다.
- 1컨테이너 오케스트레이터가 자동화하는 일을 설명할 수 있다
- 2ECS와 EKS(관리형 쿠버네티스)의 트레이드오프를 안다
- 3Fargate가 서버 관리를 어떻게 덜어주는지 이해한다
- 4서버리스 함수 대신 컨테이너를 고르는 기준을 안다
- 5컨테이너 이미지 저장소(레지스트리)의 역할을 안다
컨테이너를 '여러 대에 걸쳐' 운영하기
오케스트레이터가 대신 하는 일
컨테이너 한두 개는 docker run으로 충분하지만, 운영 규모가 되면 ① 어느 서버에 몇 개 띄울지 배치, ② 죽은 컨테이너 재시작, ③ 부하에 따른 수 조절, ④ 무중단 배포(롤링/블루그린), ⑤ 서비스 디스커버리·로드밸런싱이 필요합니다. 오케스트레이터(ECS/EKS)가 이를 자동화합니다.
이는 Kubernetes 트랙에서 배우는 개념을 클라우드가 관리형 서비스로 제공하는 것입니다 — 컨트롤 플레인을 직접 운영하지 않아도 됩니다.
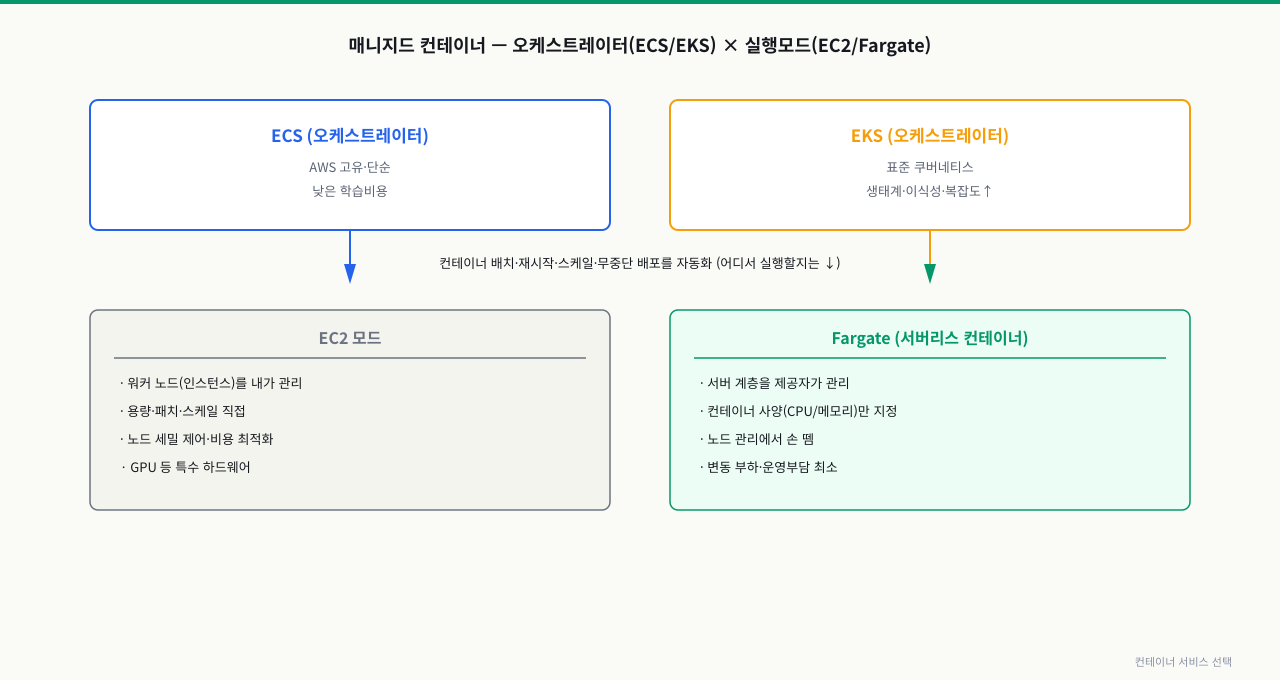
ECS vs EKS — 단순함이냐, 표준·이식성이냐
- ECS: 클라우드 제공자 고유의 비교적 단순한 오케스트레이터. 학습 곡선 완만, AWS와 통합 매끄러움. K8s를 모르는 팀이 빠르게 운영.
- EKS: 표준 쿠버네티스 관리형. K8s 도구·생태계(Helm, GitOps 등)와 멀티클라우드 이식성을 얻지만 개념·운영 복잡도↑.
"K8s 생태계가 꼭 필요한가? 멀티클라우드를 갈 건가?"면 EKS, "AWS 안에서 단순하게"면 ECS가 출발점입니다.
 확대
확대
위 그림은 ECS/EKS 오케스트레이터와 EC2/Fargate 실행 모드의 조합을 보여줍니다. 오케스트레이터가 무엇을 할지, 실행 모드가 어디서 할지를 결정합니다.
 확대
확대
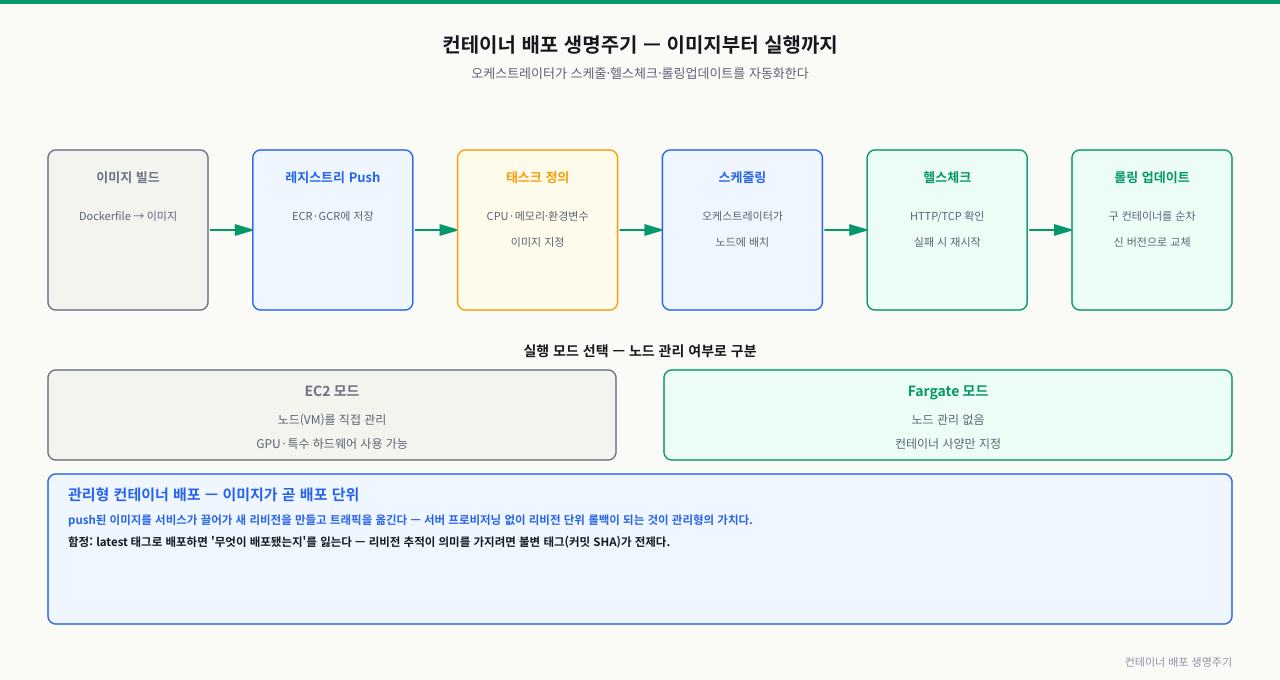
위 그림처럼 빌드→푸시→태스크 정의→스케줄링→헬스체크→롤링 업데이트 순서로 배포가 진행됩니다. 오케스트레이터가 이 흐름 전체를 자동화해 무중단 배포를 가능하게 합니다.
 확대
확대
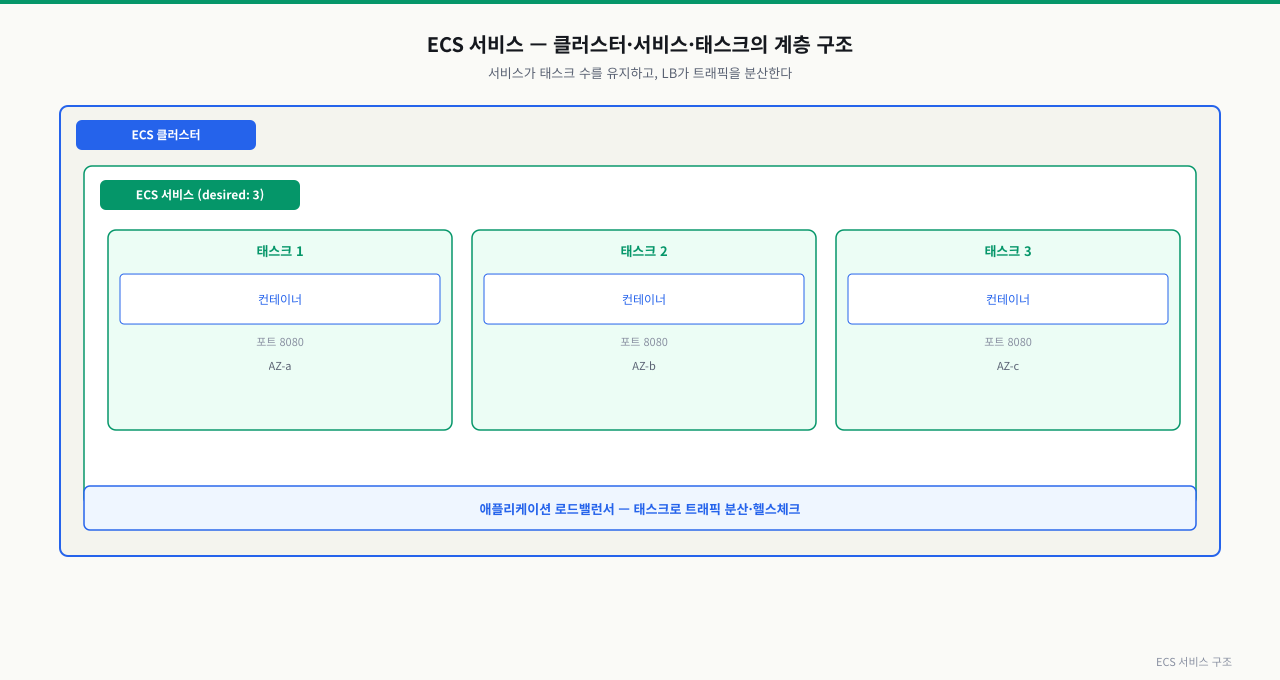
위 그림처럼 클러스터 안에 서비스가 desired 수만큼 태스크를 유지하고, 로드밸런서가 각 태스크로 트래픽을 분산합니다. 태스크가 죽으면 서비스가 자동으로 새 태스크를 띄웁니다.
EC2 모드 vs Fargate — 서버를 내가 관리하나
오케스트레이터(ECS/EKS) 위에서 컨테이너가 실제로 도는 곳은 두 가지입니다.
- EC2 모드: 컨테이너를 올릴 워커 노드(인스턴스)를 내가 관리(용량·패치·스케일). 노드를 세밀하게 통제하고 비용을 최적화할 여지가 큼.
- Fargate: 그 서버 계층을 제공자가 가림. 나는 컨테이너 사양(CPU/메모리)만 정함. 서버 관리에서 손을 떼는 대신 단가·제어는 다름.
서버리스(Lambda)가 '함수 단위 서버리스'라면 Fargate는 '컨테이너 단위 서버리스'에 가깝습니다.
 확대
확대
컨테이너 레지스트리 — 이미지의 집
오케스트레이터가 컨테이너를 띄우려면 이미지를 어딘가에서 가져와야 합니다. 컨테이너 레지스트리(예: ECR)가 빌드한 이미지를 저장·버전 관리하는 곳입니다. CI(CI/CD 파이프라인)가 이미지를 빌드해 레지스트리에 푸시하면, 오케스트레이터가 그 이미지를 풀해 배포합니다. 이미지 태그 전략은 시맨틱 버저닝·릴리스 전략와 이어집니다.
컨테이너 하나가 관리형 서비스에 배포되는 법 — 태스크 정의부터 트래픽까지 6단계
docker run은 내 노트북 한 대의 이야기지만, ECS·Cloud Run에 올린 컨테이너는 스케줄러의 손을 거쳐 뜹니다. 이미지와 태스크 정의를 넘기면 플랫폼이 자리를 고르고, 이미지를 내려받고, 띄우고, 상태를 확인한 뒤 트래픽에 합류시킵니다. 이 흐름을 알면 "컨테이너가 왜 안 뜨지"라는 막연한 신고를 배치·pull·시작·헬스체크 중 어느 단계인지로 좁힐 수 있습니다.
[배포] 이미지(레지스트리) + 태스크 정의(CPU · 메모리 · 포트 · 환경변수)
│
① 스케줄러가 배치 결정 (자원 여유 있는 노드/슬롯 선택)
│
② 이미지 pull (레지스트리 → 노드로 내려받기)
│
③ 컨테이너 시작 (프로세스 기동 → 헬스체크 대기)
│
④ 헬스체크 통과 (준비되면 healthy 판정)
│
⑤ LB 대상(target) 등록 → 트래픽 수신
│
▼
⑥ desired 유지 · 롤링 배포 (죽으면 재기동 / 새 버전 무중단 교체)
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① 배치 결정 | 스케줄러가 예약 가능한 CPU·메모리가 남은 노드/슬롯을 고른다(빈패킹) | 노드에 자리 없음 → unable to place a task로 태스크가 PENDING에 멈춤 |
| ② 이미지 pull | 레지스트리에서 노드로 이미지를 내려받는다 | 권한·태그·네트워크 문제 → CannotPullContainerError |
| ③ 컨테이너 시작 | 프로세스를 기동하고 헬스체크를 기다린다 | 시작 즉시 종료(OOM 137·설정 오류) → 재기동 반복 |
| ④ 헬스체크 | 준비되면 healthy로 판정 | 경로·시작 유예 오설정 → healthy가 못 돼 롤백·교체 폭주 |
| ⑤ LB 등록 | healthy 대상을 대상 그룹에 넣어 트래픽 수신 | 보안그룹이 LB→컨테이너 포트를 막으면 등록돼도 무응답 |
| ⑥ 유지·롤링 | desired 수를 지키고 새 버전을 무중단 교체 | 앱이 SIGTERM을 무시하면 배포마다 502/504 스파이크 |
'컨테이너가 안 뜬다'는 신고는 대부분 ①(자리)·②(pull)·③(시작)·④(헬스) 중 하나에서 멈춘 것입니다. 서버리스와 달리 노드라는 물리 자리가 있어 ①이 먼저 실패할 수 있고(태스크만 늘리고 노드를 안 늘리면 영원히 PENDING), pull·시작·헬스는 그다음 문제입니다. describe-services의 events(배치 실패 사유)와 멈춘 태스크의 stoppedReason·exitCode를 보면 어느 단계에서 멈췄는지 한 단계로 좁힐 수 있습니다.
오케스트레이터가 원하는 수(desired)만큼 실제로 돌고 있는지(running) 봅니다. 불일치는 배포·헬스 문제 신호입니다.
aws ecs describe-services --cluster prod --services web \
--query "services[0].{Desired:desiredCount,Running:runningCount,Pending:pendingCount}"
{ "Desired": 4, "Running": 4, "Pending": 0 }
aws ecs describe-services컨테이너가 자꾸 죽으면 stoppedReason에서 원인(이미지 풀 실패, OOM, 헬스체크 실패)을 봅니다.
aws ecs list-tasks --cluster prod --desired-status STOPPED --query "taskArns[0]" --output text \
| xargs -I{} aws ecs describe-tasks --cluster prod --tasks {} \
--query "tasks[0].{Reason:stoppedReason,Exit:containers[0].exitCode}"
{ "Reason": "Essential container in task exited", "Exit": 137 }
aws ecs describe-tasks- Desired vs Running 불일치가 지속되면 — 태스크 기동 실패 반복. stoppedReason·exitCode로 원인 추적
- exitCode 137(=128+9, SIGKILL) — 대개 메모리 초과(OOM). 태스크 정의의 메모리 상향 또는 누수 점검(Kubernetes OOMKilled와 동일 원리)
- stoppedReason에 'CannotPullContainerError' — 레지스트리 권한/태그/네트워크 문제. ECR 접근 IAM·이미지 태그 확인
- 롤링 배포 중 헬스체크 실패로 롤백 — 헬스 경로·기동 유예 점검(오토스케일링 + 로드밸런서의 헬스체크와 동일)
상황: 컨테이너가 기동조차 못 하고 이미지 풀 단계에서 실패.
원인: ① 태스크 실행 역할(execution role)에 레지스트리(ECR) 풀 권한이 없음, ② 이미지 태그·경로 오타, ③ 프라이빗 서브넷에서 레지스트리로 나가는 네트워크 경로(NAT/VPC 엔드포인트) 부재.
진단: 태스크 정의의 이미지 URI 확인 → 실행 역할의 ECR 권한 확인 → 서브넷의 아웃바운드 경로 확인(VPC와 서브넷).
해결: 실행 역할에 ECR 풀 정책 부여, 이미지 태그를 정확히, 프라이빗 서브넷이면 NAT 또는 ECR용 VPC 엔드포인트로 이미지 풀 경로 확보. 권한 문제는 계정과 IAM의 최소권한 설정과 직결됩니다.
심화 — '무중단 배포'는 설정과 앱이 함께 만든다
심화: 롤링 배포의 내부 — 서지 용량과 우아한 종료
"오케스트레이터가 무중단 배포를 해 준다"는 절반만 맞는 말입니다. 내부 동작을 모르면 배포할 때마다 에러가 튀는 서비스가 됩니다.
- 서지(surge)의 산수: 롤링 배포는 새 태스크를 먼저 띄우고(maximumPercent, 예: 200%면 desired의 2배까지) 헬스체크를 통과해야 옛 태스크를 내립니다(minimumHealthyPercent 아래로는 안 내려감). 즉 배포 순간에는 평소보다 많은 용량이 필요합니다 — EC2 모드에서 노드에 여유가 없으면 새 태스크가 뜰 자리가 없어 배포가 그 자리에서 멈춥니다.
- 내리는 쪽이 더 어렵습니다: 옛 태스크를 내릴 때는 ① 로드밸런서에서 대상 등록 해제 ② 진행 중 요청이 끝나길 대기(드레이닝, 기본 수 분) ③ 컨테이너에 SIGTERM 전송 ④ 유예시간(기본 30초) 뒤 SIGKILL 순서로 진행됩니다.
- 앱이 SIGTERM을 무시하면: 처리 중이던 요청이 강제로 끊겨, 배포 때마다 502/504 에러가 스파이크로 튑니다. 앱은 SIGTERM을 받으면 새 요청은 거부하고 진행 중 요청을 마친 뒤 종료하는 우아한 종료(graceful shutdown) 를 구현해야 합니다. 이것만은 오케스트레이터가 대신 못 해 주는, 애플리케이션의 몫입니다.
배포가 잦은 팀일수록 이 몇십 초의 디테일이 '배포=무섭다'와 '배포=일상'을 가릅니다. 기동이 느린 앱의 헬스체크 유예 설정과 함께, 배포 파이프라인(CI/CD 파이프라인)의 기본 점검 항목입니다.
상황: 트래픽 급증에 대응해 태스크 수를 올렸지만 새 태스크가 전부 PENDING. 태스크 오토스케일링을 걸어 뒀는데도 스케일아웃이 되지 않습니다.
원인: 태스크 수요와 노드 용량이 따로 놉니다. EC2 모드에서 태스크는 노드에 남은 예약 가능 CPU·메모리 안에서만 배치됩니다(빈패킹). 예를 들어 8GB 노드에 3GB 예약 태스크는 2개만 들어가고 2GB는 자투리로 버려집니다. 태스크 오토스케일링은 desired 값만 올릴 뿐 노드(EC2)를 늘려 주지는 않으므로, 노드 스케일링이 연동돼 있지 않으면 자리가 없어 영원히 PENDING입니다.
진단: aws ecs describe-services --query 'services[0].events'에서 배치 실패 사유(insufficient memory/CPU)를 확인 → 클러스터 노드별 잔여 예약 용량과 태스크 정의의 예약값을 대조합니다.
해결: ① capacity provider의 managed scaling을 켜 태스크 수요에 맞춰 노드 그룹이 자동으로 늘어나게 연동 ② 태스크의 CPU·메모리 예약값을 실사용에 맞게 조정해 자투리 낭비를 줄임 ③ 이 용량 관리 자체를 없애고 싶다면 Fargate로 전환(노드 자리 걱정 없이 태스크 단위로 뜸). '컨테이너 오토스케일링'은 태스크와 노드 두 층이 함께 스케일돼야 완성됩니다(오토스케일링 + 로드밸런서).
"왜 ECS/EKS/Fargate 중 그걸 골랐나요?"는 클라우드 인프라 면접 단골입니다. 좋은 답은 기술 유행이 아니라 팀 역량·이식성 요구·운영 부담으로 설명하는 것입니다 — "K8s 경험이 없고 AWS 단일 클라우드라 ECS+Fargate로 운영 부담을 줄였다" 같은 식.
실무 흐름: Docker로 이미지를 만들고 → CI(CI/CD 파이프라인)가 레지스트리에 푸시 → 오케스트레이터가 롤링 배포 → 오토스케일링 + 로드밸런서로 스케일 → 관측과 거버넌스로 관측. 이 트랙의 조각들이 하나의 파이프라인으로 연결됩니다. 깊은 K8s 운영은 Kubernetes 트랙에서 다룹니다.
관련 모듈로 더 깊이:
- 컨테이너 이미지 보안 — 컨테이너로 배포하기 전에 이미지 취약점을 점검·차단하는 법
- 가상 서버(EC2) — 컨테이너의 토대가 되는 가상 서버(노드)
- 서버리스(Lambda) — 상시 컨테이너 대신 이벤트로만 실행하는 서버리스 대안
다음 모듈에서는 지금까지 손/콘솔로 만든 모든 자원을 코드로 선언해 재현하는 IaC와 Terraform 으로 들어갑니다.