이벤트 당일 오전 10시, 트래픽이 평소 30배로 치솟습니다. 인스턴스 한 대는 CPU 100%로 헉헉대다 다운, 사용자는 에러 화면을 봅니다. 반대로 새벽 3시엔 그 큰 인스턴스가 1% 부하로 돈만 먹습니다. 한 대 고정으로는 피크에 죽고 평소엔 낭비합니다. 오토스케일링과 로드밸런서는 "필요한 만큼 자동으로, 죽은 건 알아서 빼고"를 만들어 줍니다.
- 1로드밸런서가 트래픽 분산과 헬스체크로 무엇을 해주는지 안다
- 2오토스케일링 그룹이 지표 기반으로 늘고 주는 원리를 설명할 수 있다
- 3오토스케일링의 전제인 '무상태' 설계의 이유를 안다
- 4헬스체크 경로 설계가 왜 중요한지 예로 들 수 있다
- 5탄력성이 가용성·비용에 동시에 기여하는 구조를 이해한다
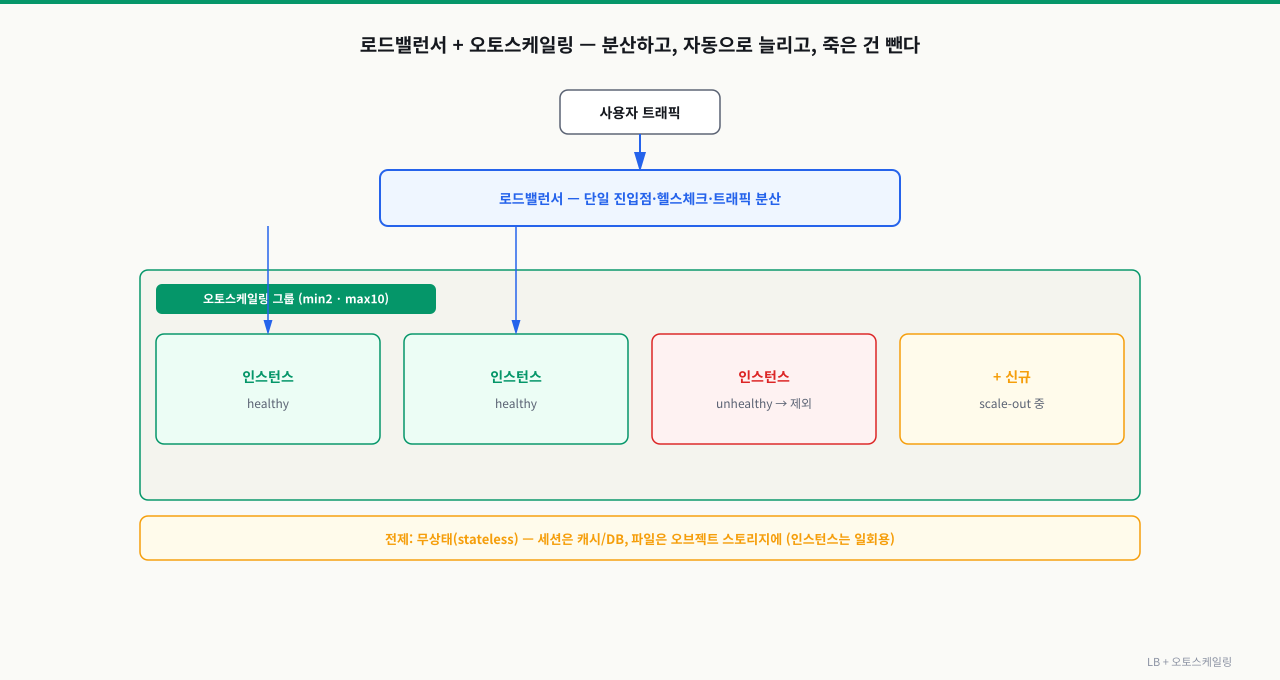
분산과 자동 증감, 두 축
로드밸런서 — 단일 진입점 + 죽은 놈 빼기
로드밸런서는 사용자에게 하나의 주소를 주고, 뒤에 있는 여러 인스턴스로 트래픽을 나눕니다. 동시에 각 인스턴스에 주기적으로 헬스체크를 보내, 응답 없는 인스턴스는 라우팅에서 빼고 복귀하면 다시 넣습니다. 그래서 인스턴스 한 대가 죽거나 배포 중이어도 사용자는 거의 모릅니다.
L7(애플리케이션) 로드밸런서는 URL 경로·호스트로 라우팅(/api는 이쪽, /img는 저쪽)까지 합니다.
오토스케일링 그룹 — 지표를 보고 머릿수를 조절
오토스케일링 그룹(ASG)은 "최소 2대, 최대 10대, 평균 CPU 50% 목표" 식으로 정책을 둡니다. 부하가 올라 임계치를 넘으면 scale-out(추가), 내려가면 scale-in(제거)합니다. 새 인스턴스는 검증된 AMI(가상 서버(EC2))로 동일하게 찍어내고, LB가 헬스체크 통과 후 트래픽에 합류시킵니다.
핵심 전제: 인스턴스는 언제 추가·제거돼도 안전해야 합니다 — 즉 무상태여야 합니다.
부하가 오르면 인스턴스가 어떻게 늘고 트래픽이 분산되나 — 요청부터 스케일까지 6단계
LB 주소로 요청 하나가 들어온 순간부터, 그 부하가 쌓여 새 인스턴스가 뜨고 트래픽을 나눠 받기까지는 여러 단계를 거칩니다. 이 흐름을 알면 "왜 스케일이 느리지", "왜 늘었다 줄었다 하지", "배포하면 왜 다 빠지지"를 각각 다른 단계의 문제로 좁힐 수 있습니다. 로드밸런서(분산)와 오토스케일(증감)이 실제로는 하나의 파이프라인으로 맞물려 돈다는 점이 여기서 드러납니다.
[사용자] 요청 → LB의 단일 주소(DNS)
│
① LB 수신 → 헬스체크 통과한 대상에만 분산
│
② 오토스케일이 지표 관측 (평균 CPU · 요청수 · 큐 길이)
│
③ 임계 초과 → 스케일아웃 결정 (desired 용량 +1 …)
│
④ 새 인스턴스 기동 · 워밍업 (AMI로 부팅 → 앱 기동)
│
⑤ 헬스체크 통과 → 대상 그룹 등록 → 트래픽 합류
│
▼
⑥ 부하 감소 → 스케일인(축소) (드레이닝 후 종료)
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① LB 분산 | 헬스체크를 통과한 대상에만 요청을 나눠 보낸다 | 헬스체크 경로·임계가 틀리면 정상 인스턴스를 오판해 빼거나(전부 빠짐) 죽은 인스턴스에 계속 보냄 |
| ② 지표 관측 | 평균 CPU·요청수·큐 길이 같은 지표를 주기적으로 수집 | 수집·집계 주기만큼 반응이 늦어 급증에 한 박자 뒤진다 |
| ③ 스케일 결정 | 지표가 임계를 넘으면 desired 용량을 올린다 | 임계·쿨다운이 민감하면 늘렸다 줄였다 반복(플래핑) |
| ④ 기동·워밍업 | 새 인스턴스를 AMI로 부팅하고 앱이 뜰 때까지 준비 | 기동에 수 분 걸려 순간 스파이크를 못 따라잡음(예측 스케일·여유 용량 필요) |
| ⑤ 등록 | 헬스체크 통과 후 대상 그룹에 넣어 트래픽 합류 | 시작 유예(grace period) 부족 → 준비 전 트래픽 유입·롤링 폭주 |
| ⑥ 스케일인 | 부하가 낮아지면 드레이닝 후 인스턴스 종료 | 드레이닝 없이 즉시 종료하면 진행 중 요청이 끊긴다 |
핵심은 오토스케일이 '즉시'가 아니라 '관측 → 결정 → 기동 → 등록'의 파이프라인이라는 점입니다. 각 단계가 초~분 단위 지연을 더하므로, 갑작스런 스파이크는 예측 스케줄·여유 용량으로 미리 받아야 하고, 헬스체크(①·⑤)나 쿨다운(③)이 잘못되면 스케일 장치 자체가 플래핑·롤링 폭주 같은 사고를 만듭니다. 'unhealthy가 계속된다'(①·⑤), '트래픽은 그대로인데 인스턴스만 는다'(②③의 오판)를 단계로 나눠 보면 원인 구간이 좁혀집니다.
 확대
확대
 확대
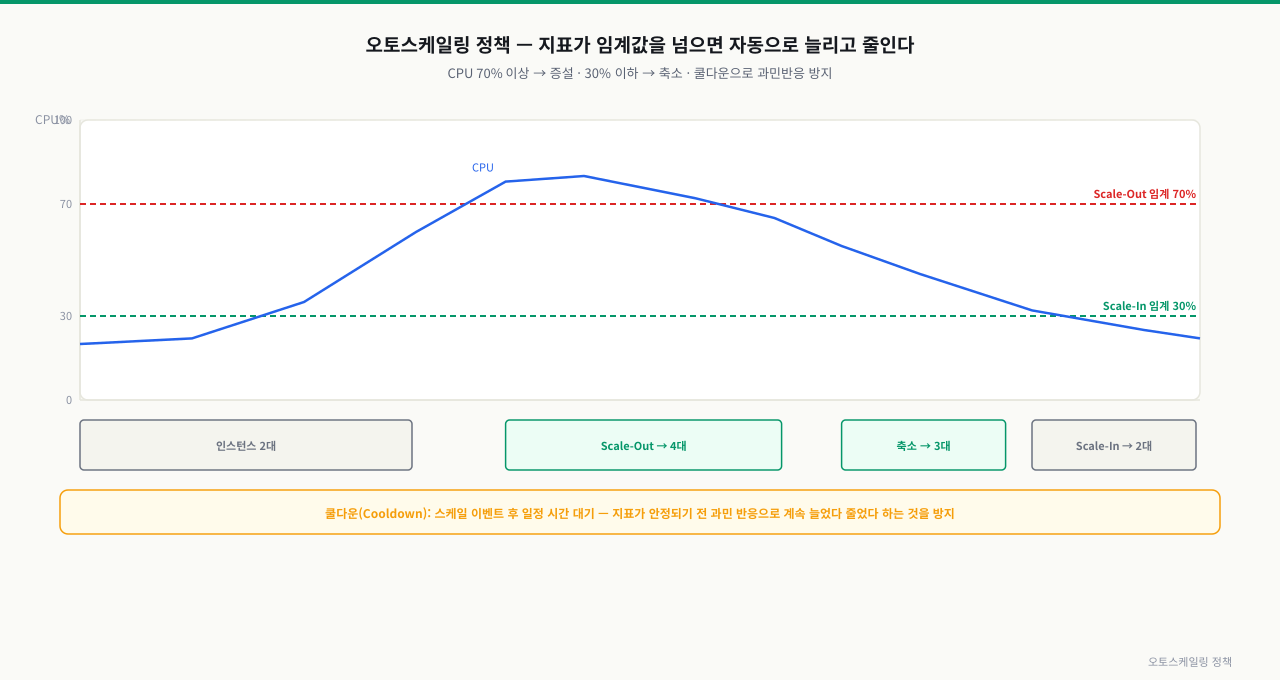
위 그림처럼 CPU가 70%를 넘으면 Scale-Out, 30% 아래로 내려가면 Scale-In이 트리거됩니다. 쿨다운 설정으로 과민 반응을 방지합니다.
확대
위 그림처럼 CPU가 70%를 넘으면 Scale-Out, 30% 아래로 내려가면 Scale-In이 트리거됩니다. 쿨다운 설정으로 과민 반응을 방지합니다.
 확대
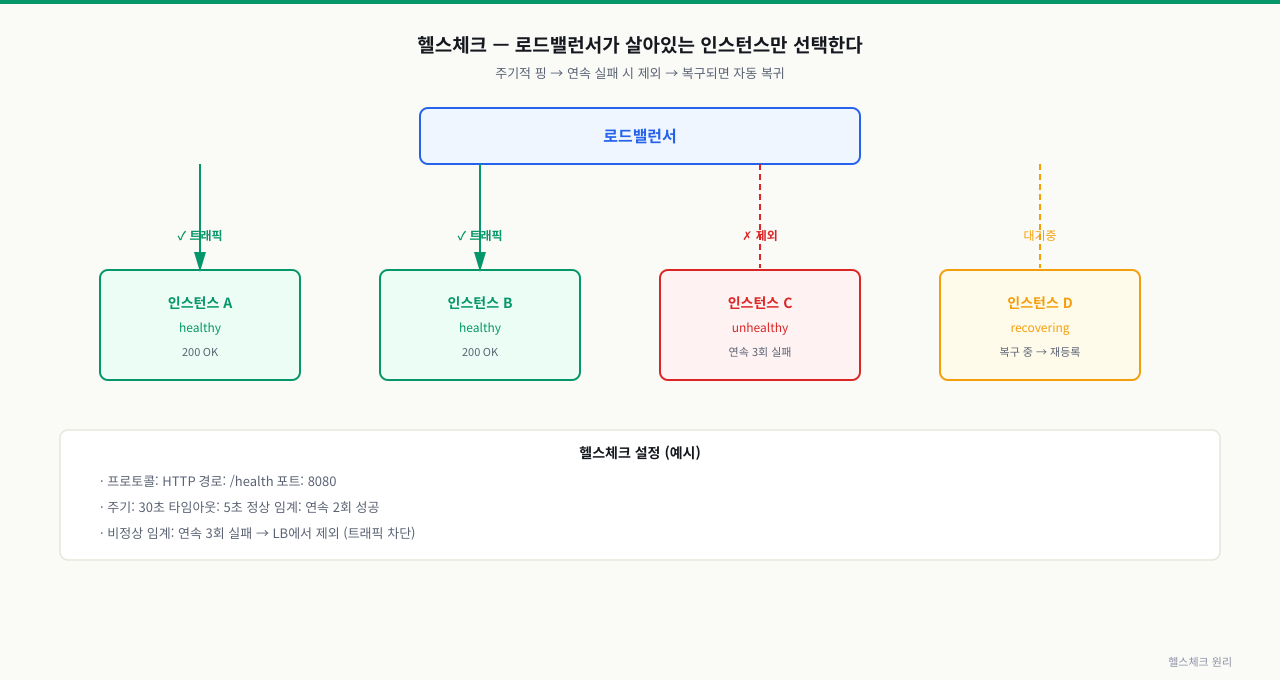
위 그림처럼 연속 실패한 인스턴스는 LB 풀에서 제외되고, 복구 후 연속 성공하면 자동으로 재등록됩니다.
확대
위 그림처럼 연속 실패한 인스턴스는 LB 풀에서 제외되고, 복구 후 연속 성공하면 자동으로 재등록됩니다.
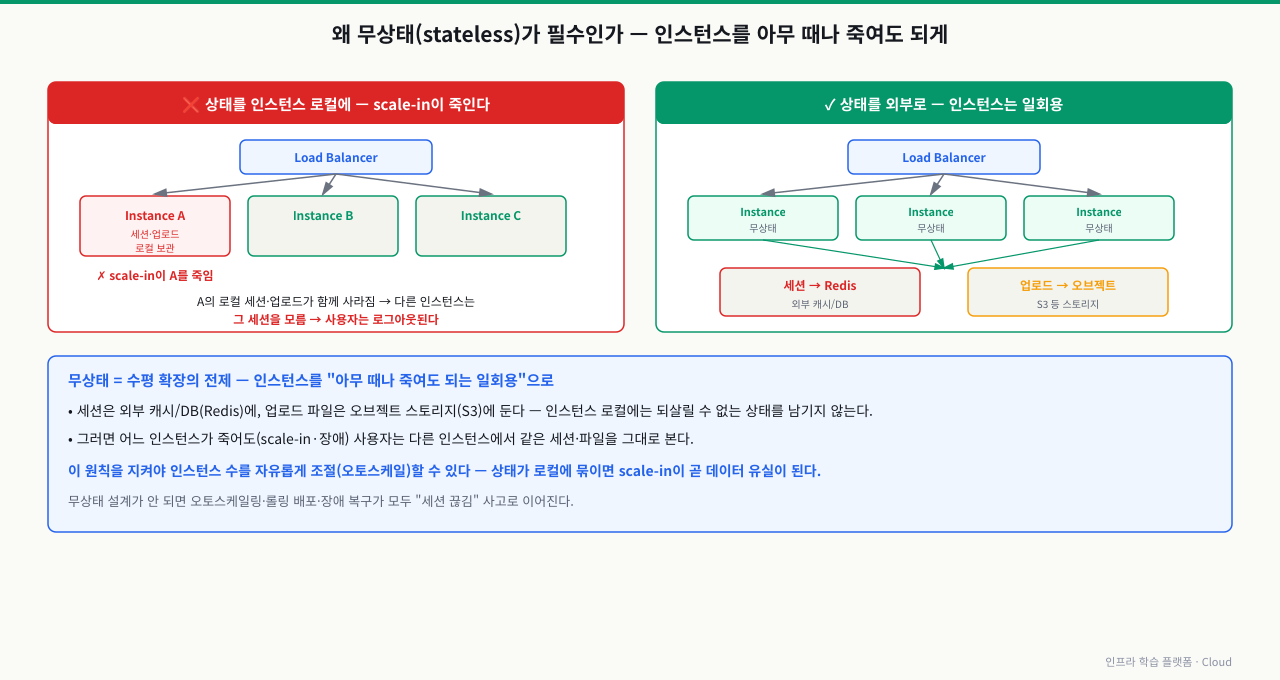
왜 무상태(stateless)가 필수인가
scale-in은 인스턴스를 죽입니다. 그 인스턴스 로컬에 세션이나 업로드 파일이 있었다면 함께 사라집니다. 다른 인스턴스는 그 세션을 모르니 사용자는 로그아웃됩니다. 그래서:
- 세션 → 외부 캐시/DB(예: Redis)에 저장
- 업로드 파일 → 오브젝트 스토리지(오브젝트·블록·파일 스토리지)에 저장
- 인스턴스는 "아무 때나 죽여도 되는 일회용"으로
이 원칙을 지키면 인스턴스 수를 자유롭게 조절할 수 있습니다.
 확대
확대
LB 뒤 인스턴스들이 healthy인지 확인합니다. 배포·스케일 직후 unhealthy가 오래 남으면 헬스체크 설정을 의심합니다.
aws elbv2 describe-target-health --target-group-arn "$TG_ARN" \
--query "TargetHealthDescriptions[].{Id:Target.Id,State:TargetHealth.State}" --output table
+----------------------+-----------+
| i-0aaa... | healthy |
| i-0bbb... | healthy |
| i-0ccc... | unhealthy| ← 조사 대상
+----------------------+-----------+
aws elbv2 describe-target-healthASG가 최소·최대·희망 용량 사이에서 어떻게 동작 중인지 봅니다.
aws autoscaling describe-auto-scaling-groups --auto-scaling-group-names web-asg \
--query "AutoScalingGroups[0].{Min:MinSize,Max:MaxSize,Desired:DesiredCapacity,InService:length(Instances)}"
{ "Min": 2, "Max": 10, "Desired": 4, "InService": 4 }
aws autoscaling describe-auto-scaling-groups- describe-target-health에 unhealthy가 지속되는 인스턴스 — 앱 미기동인지(진짜 문제) 헬스체크 경로/타임아웃이 빡센지(오판) 구분
- DesiredCapacity vs InService 수 일치 여부 — 불일치면 인스턴스 기동 실패·헬스체크 탈락 반복(롤링 폭주) 의심
- scale 이벤트 로그의 빈도 — 짧은 시간에 늘었다 줄었다 반복(flapping)하면 임계치·쿨다운이 너무 민감. 쿨다운 늘리기
- scale-in 시 사용자 로그아웃/업로드 유실 신고 — 상태가 인스턴스 로컬에 남아 있다는 신호. 외부 저장소로 분리
상황: 새 인스턴스가 헬스체크를 통과 못 해 LB가 빼고, ASG가 죽이고 또 띄우는 루프.
원인: ① 헬스체크 경로(/health)가 앱 준비 전에 호출됨(기동 시간 < 체크 시작), ② 경로가 200을 안 줌(앱 버그/포트 불일치), ③ 보안그룹이 LB→인스턴스 헬스체크 포트를 안 허용.
진단: 인스턴스에 직접 들어가 curl localhost:<port>/health 응답 확인 → LB 대상그룹 헬스체크 경로·포트·정상 임계 확인 → 보안그룹에서 LB SG로부터의 인바운드 허용 확인.
해결: 헬스체크에 시작 유예(health check grace period) 를 둬 기동 시간을 확보. 경로를 가볍고 정확한 /health로. 보안그룹에 LB로부터의 헬스체크 포트 인바운드 추가. 헬스체크 설계는 SLO·에러버짓·포스트모템의 가용성 측정과도 연결됩니다.
심화 — 늘리는 것보다 줄이는 것, 그리고 의심하는 것
심화: 스케일 인의 규칙 — 누구를, 언제, 어떻게 내리는가
scale-out은 더하기지만 scale-in은 골라서 빼기입니다. 아무 인스턴스나 즉시 죽이면 진행 중인 작업이 함께 사라지므로, ASG에는 '내리는 쪽'을 위한 장치가 따로 있습니다.
- 종료 정책(termination policy): 기본값은 ① AZ 간 인스턴스 수 균형을 맞추는 방향에서 ② 가장 오래된 시작 템플릿(구성)의 인스턴스를 먼저 고릅니다. 배포 후 신·구 구성이 섞여 있으면 구버전부터 자연스럽게 정리되는 효과가 있습니다.
- scale-in 보호(instance protection): "이 인스턴스는 빼지 마라"는 표시입니다. 긴 배치 작업을 처리 중인 워커가 중간에 잘리면 안 될 때, 작업 시작 시 보호를 켜고 끝나면 푸는 패턴으로 씁니다.
- 라이프사이클 훅(lifecycle hook): 종료 직전 인스턴스를
Terminating:Wait상태로 붙잡아 마무리 시간을 줍니다 — 버퍼에 남은 로그 전송, 처리 중이던 큐 메시지 완료, 커넥션 정리. 연결 드레이닝이 LB 관점의 배웅이라면, 훅은 인스턴스 자신의 뒷정리 시간입니다. 기동 쪽 훅도 있어 웜업·캐시 예열에 씁니다.
이 장치들 없이 scale-in을 켜면 "줄어들 때마다 어디선가 로그와 작업이 사라지는" 시스템이 됩니다. 무상태 설계가 전제라면, 이 규칙들은 마무리입니다.
상황: 전날 저녁 배포 후 밤사이 scale-out이 연쇄로 발생. LB의 요청 수(RequestCount)는 평소와 같은데 모든 인스턴스의 CPU가 90%대라 ASG는 계속 증설했고, 최대치에 도달한 채 아침을 맞았습니다. 서비스는 멀쩡해 보여 알림도 없었습니다.
원인: 배포 코드에 들어간 재시도 폭주 버그. 외부 API 호출이 실패하면 대기 없이 무한 재시도하는 루프가 CPU를 태웠습니다. 오토스케일링은 이것을 장애가 아니라 '부하'로 해석해 돈으로 증상을 덮었습니다 — 자동 복구 장치가 버그의 은폐 장치가 된 셈입니다.
진단: 요청 수는 평평한데 인스턴스 수만 상승하는 구간을 확인(요청당 CPU 비용이 갑자기 뛴 것) → 인스턴스 수 증가가 시작된 시각과 배포 시각 대조 → 앱 로그에서 동일 요청의 재시도 반복 확인.
해결: ① 롤백으로 원인 제거 ② 재시도에 지수 백오프와 최대 횟수 도입 ③ '최대 용량 도달'과 '요청 수 대비 인스턴스 수 비율 급변'에 알림을 겁니다(관측과 거버넌스). 오토스케일링은 버그를 조용히 흡수할 수 있으므로, 스케일 이벤트 자체를 관측 대상으로 둬야 비용으로 배우는 일을 막습니다.
면접 단골: "트래픽이 급증하면 어떻게 대응하나요?" → "오토스케일링 그룹으로 지표 기반 증설하고 앞에 로드밸런서를 둔다. 단, 앱을 무상태로 만들어 세션은 외부 캐시, 파일은 오브젝트 스토리지에 둔다"가 좋은 답입니다.
실무 함정: 오토스케일링은 만능이 아닙니다. 인스턴스 기동에 수 분이 걸리면 갑작스런 스파이크는 못 따라잡습니다(예측 스케일링·여유 용량 필요). 또 DB가 병목이면 웹 인스턴스만 늘려도 소용없습니다 — 병목 지점을 먼저 찾아야 합니다(관리형 데이터베이스(RDS)).
관련 모듈로 더 깊이:
- 가상 서버(EC2) — 오토스케일링이 늘렸다 줄이는 대상인 가상 서버 자체
- VPC와 서브넷 — 로드밸런서·인스턴스가 사는 네트워크와 퍼블릭/프라이빗 서브넷
- 관측과 거버넌스 — 스케일링 판단의 근거가 되는 지표·관측 체계
다음 모듈에서는 이 인스턴스·LB가 사는 네트워크 자체 — VPC·서브넷·라우팅·게이트웨이 로 들어가, 퍼블릭과 프라이빗을 어떻게 나누는지 다룹니다.