사용자가 이미지를 올릴 때마다 썸네일을 만들어야 합니다. 이 일로 서버 한 대를 24시간 켜두자니, 정작 일하는 시간은 하루 몇 분뿐 — 나머지는 돈만 먹는 유휴입니다. 반대로 가끔 트래픽이 몰리면 그 한 대로는 부족합니다. "가끔, 갑자기, 짧게" 실행되는 일에 상시 서버는 낭비입니다. 서버리스는 "올라올 때만 실행하고, 동시에 많이 오면 알아서 늘리는" 방식으로 이 틈을 메웁니다.
- 1서버리스가 '서버를 관리하지 않는다'는 의미를 정확히 안다
- 2이벤트 기반 실행과 자동 동시성 확장을 설명할 수 있다
- 3콜드스타트가 무엇이고 언제 문제인지 안다
- 4실행 시간 기반 과금의 손익분기를 판단할 수 있다
- 5서버리스가 맞는 작업과 안 맞는 작업을 구분할 수 있다
이벤트가 올 때만 깨어난다
서버리스 = 서버를 '내가' 관리하지 않는다
서버리스(FaaS)는 서버가 없는 게 아니라, 서버의 프로비저닝·패치·스케일링을 제공자가 가려서 내가 신경 쓸 필요가 없는 모델입니다. PaaS(IaaS·PaaS·SaaS와 리전·AZ)에서 한 발 더 나아가, 이벤트 단위로 실행됩니다.
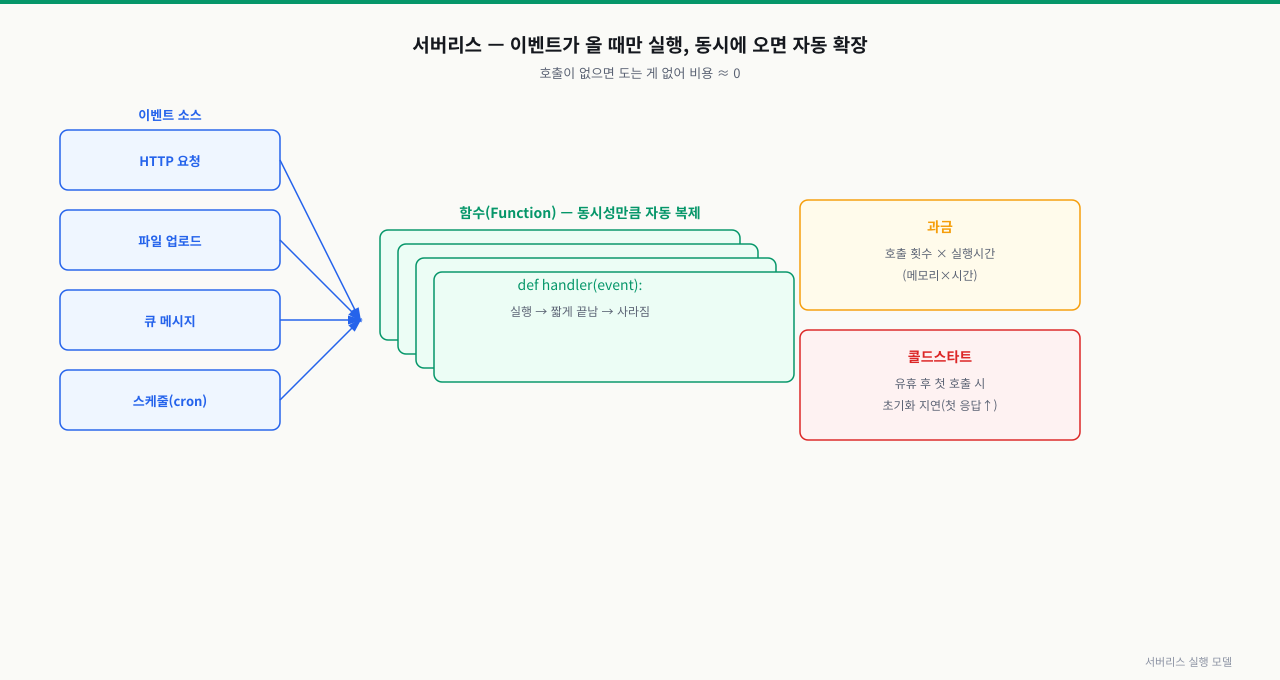
함수는 트리거(HTTP 요청, 파일 업로드, 큐 메시지, 스케줄)가 올 때 실행되고, 동시 요청 수에 맞춰 인스턴스가 자동으로 늘어납니다. 호출이 없으면 도는 게 없어 비용이 거의 0입니다.
함수를 한 번 호출하면 실제로 무슨 일이 일어나나 — 트리거부터 회수까지
함수는 평소엔 어딘가에 '떠 있지' 않습니다. 트리거가 와야 플랫폼이 실행 환경을 붙여 주고, 끝나면 잠시 살려 뒀다가 회수합니다. 이 깨어남 → 실행 → 잠깐 대기 → 회수의 생애주기를 알면, 콜드스타트·스로틀·타임아웃·무상태 같은 서버리스의 대표 함정이 왜 생기는지가 한눈에 이어집니다 — 전부 이 흐름의 특정 단계에서 나오는 증상이기 때문입니다.
[트리거] HTTP 요청 · S3 업로드 · 큐 메시지 · 스케줄
│
① 이벤트 도착 → 플랫폼이 실행 인스턴스 확보
│ ├─ 웜(warm): 최근 쓰던 인스턴스 재사용 → 즉시 실행
│ └─ 콜드(cold): 새 인스턴스 초기화(런타임·코드 로드·연결 준비)
│
② 핸들러 실행 (내 코드가 이벤트를 처리)
│
③ 응답 반환 (동기=호출자에게 / 비동기=다음 단계로)
│
④ 인스턴스 웜 유지 (다음 호출 대비 잠시 살려둠)
│
▼
⑤ 유휴 지속 → 인스턴스 회수 (한동안 호출 없으면 종료 → 다음은 콜드)
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① 인스턴스 확보 | 웜이면 기존 인스턴스 재사용, 콜드면 새로 초기화(런타임·코드 로드) | 콜드 초기화가 길면 첫 응답 지연(콜드스타트) / 동시 실행이 한도 초과 → 스로틀(429) |
| ② 핸들러 실행 | 이벤트를 넘겨받아 내 코드를 실행 | 실행이 설정한 타임아웃을 넘으면 강제 종료(Task timed out) |
| ③ 응답 반환 | 동기 호출은 결과를 즉시 반환, 비동기는 다음 단계로 전달 | 동기 경로가 타임아웃보다 오래 걸리면 앞단 게이트웨이가 504 |
| ④ 웜 유지 | 다음 호출을 대비해 인스턴스를 잠시 살려둔다 | 전역변수·/tmp 잔재가 다음 호출에 새어 상태 오염(재사용 부작용) |
| ⑤ 유휴 회수 | 한동안 호출이 없으면 인스턴스를 종료 | 회수 뒤 첫 호출은 다시 콜드 → 트래픽 뜸하면 콜드스타트가 잦아짐 |
서버리스의 4대 함정 — 콜드스타트·스로틀·타임아웃·무상태 — 은 별개의 버그가 아니라 전부 이 생애주기의 특정 단계에서 나오는 증상입니다. 콜드스타트는 ①, 스로틀(429)은 ①의 동시성 한도, 타임아웃은 ②, '가끔 이상한 값이 섞인다'는 ④의 웜 재사용에서 옵니다. 그래서 로그의 Init Duration(① 콜드), Duration 대 Timeout(②), 429 발생(①)만 짚으면 어느 단계의 문제인지 바로 좁혀집니다.
 확대
확대
위 그림처럼 이벤트가 오면 함수가 실행되고, 동시에 여러 이벤트가 오면 자동으로 복제됩니다. 호출이 없으면 실행되는 것이 없어 비용이 거의 0에 가깝습니다.
 확대
확대
위 그림처럼 서버리스는 이벤트 기반·간헐적 작업에 적합하고, 컨테이너는 상시 실행·긴 처리 시간이 필요한 워크로드에 적합합니다. 최대 실행 시간 제한과 콜드스타트가 핵심 트레이드오프입니다.
 확대
확대
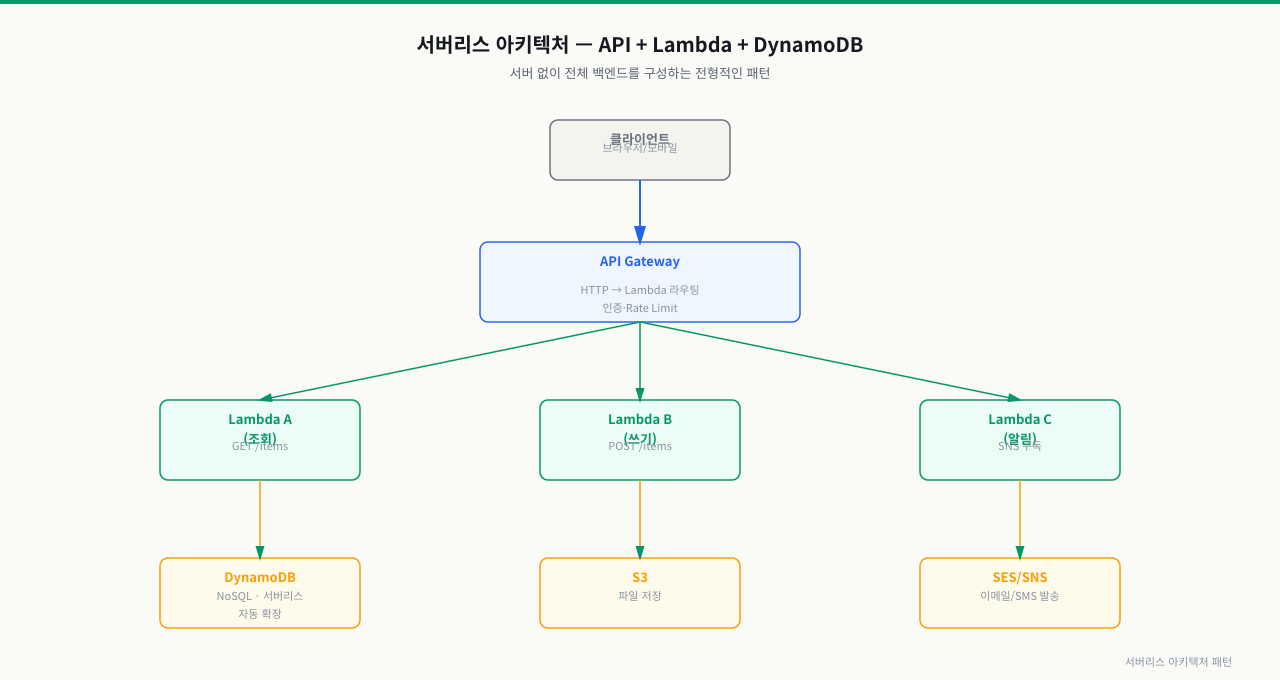
위 그림처럼 API Gateway→Lambda→DynamoDB/S3 조합으로 서버 없이 전체 백엔드를 구성할 수 있습니다. 각 컴포넌트가 독립적으로 확장돼 인프라 관리 없이 변동 부하를 수용합니다.
콜드스타트 — 깨어나는 데 드는 시간
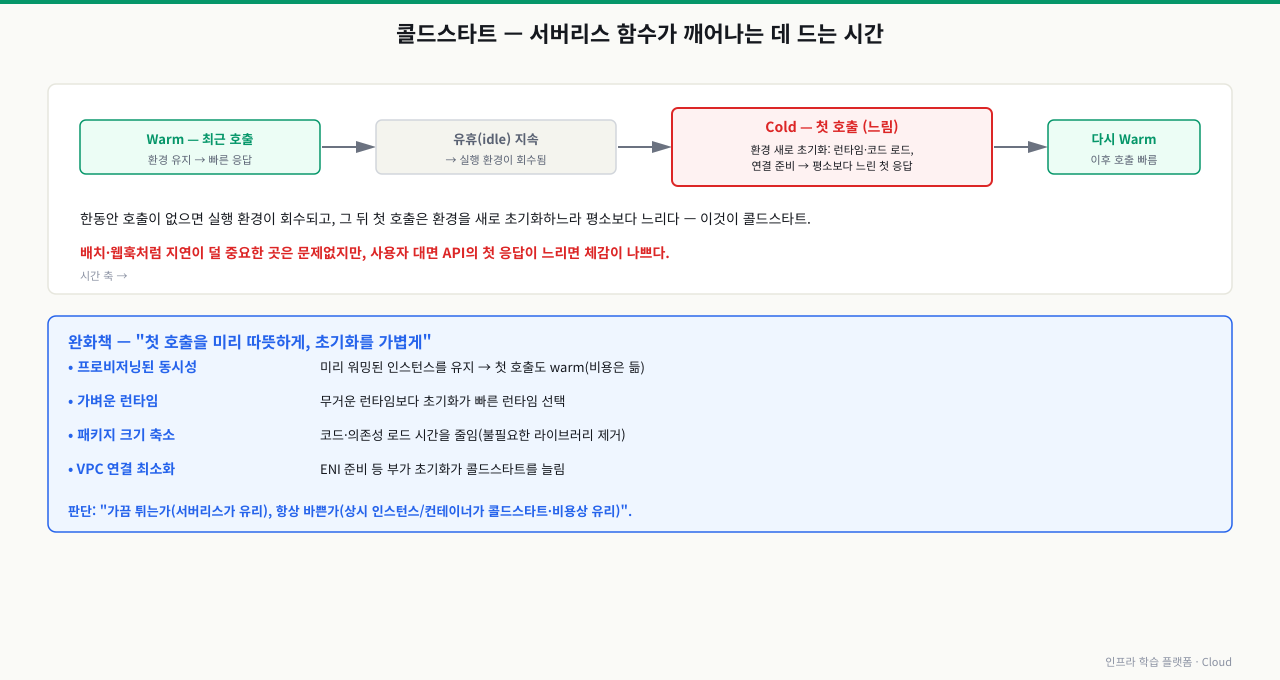
한동안 호출이 없으면 실행 환경이 회수됩니다. 그 뒤 첫 호출은 환경을 새로 초기화(런타임·코드 로드, 연결 준비)하느라 평소보다 느립니다 — 이것이 콜드스타트입니다.
배치·웹훅처럼 지연이 덜 중요한 곳은 문제없지만, 사용자 대면 API의 첫 응답이 느리면 체감이 나쁩니다. 완화책: 프로비저닝된 동시성(미리 워밍 유지), 가벼운 런타임, 패키지 크기 축소, VPC 연결 최소화.
 확대
확대
과금 — 안 쓰면 0, 항상 바쁘면 비쌀 수도
서버리스는 실행 횟수 + 실행 시간(메모리×시간) 에 비례해 과금합니다. 간헐적 작업은 거의 공짜입니다. 하지만 초당 수천 건이 끊임없이 도는 무거운 워크로드라면 상시 인스턴스보다 비쌀 수 있습니다. 판단 기준은 단순합니다: "가끔 튀는가(서버리스), 항상 바쁜가(인스턴스/컨테이너)".
과금과 성능을 좌우하는 메모리·타임아웃을 확인합니다. 메모리를 올리면 CPU도 함께 올라 더 빨리 끝나 비용이 오히려 줄기도 합니다.
aws lambda get-function-configuration --function-name make-thumbnail \
--query "{Mem:MemorySize,Timeout:Timeout,Runtime:Runtime}"
{ "Mem": 512, "Timeout": 30, "Runtime": "python3.12" }
aws lambda get-function-configuration실행 로그에서 에러와 초기화 지연(Init Duration=콜드스타트)을 봅니다.
aws logs filter-log-events --log-group-name /aws/lambda/make-thumbnail \
--filter-pattern "REPORT" --limit 3 --query "events[].message" --output text
REPORT Duration: 842 ms Init Duration: 410 ms Memory Used: 180 MB ← 콜드스타트
REPORT Duration: 120 ms Memory Used: 178 MB ← 웜
aws logs filter-log-events- REPORT의 Init Duration이 자주 보이면 — 콜드스타트 빈발. 사용자 대면이면 프로비저닝된 동시성·런타임 경량화 검토
- Memory Used가 할당 MemorySize에 한참 못 미치면 — 과할당. 줄여 비용↓ (단 CPU도 함께 줄어 느려질 수 있어 측정 후 조정)
- Timeout에 임박하거나 타임아웃 에러 — 작업이 길어 함수에 부적합할 수 있음. 컨테이너/배치로 분리 검토
- 호출량×평균 Duration 추세 — 상시 고부하로 수렴하면 서버리스 비용이 인스턴스를 넘는 지점인지 재평가
상황: 함수 동시 실행이 폭증하면 각 인스턴스가 DB 커넥션을 열어 DB 커넥션이 고갈됨.
원인: 서버리스는 동시성에 맞춰 함수 인스턴스가 수백~수천 개로 늘 수 있습니다. 각자 DB 커넥션을 직접 열면 관리형 데이터베이스(RDS)의 최대 커넥션을 순식간에 초과합니다. 전통적 커넥션 풀 가정이 깨집니다.
진단: DB의 활성 커넥션 수와 함수 동시 실행 수를 비교 → 함수당 커넥션 사용 패턴 확인.
해결: 함수와 DB 사이에 커넥션 풀 프록시(예: RDS Proxy)를 둬 커넥션을 공유·재사용. 함수 동시성에 상한(reserved concurrency)을 둬 폭주를 막음. 가능하면 함수는 짧게 붙고 빨리 떼게 설계. 커넥션 풀의 원리는 Database 트랙과 이어집니다.
심화 — 동시성의 산수를 알아야 폭주를 다스린다
심화: 동시성 한도는 계정 단위로 공유된다
"알아서 늘어난다"의 다음 단계 질문은 "어디까지, 그리고 누구의 몫을 먹으며 늘어나는가"입니다.
- 동시성의 산수: 필요한 동시 실행 수 ≈ 초당 요청 수 × 평균 실행 시간(초). 초당 100건 × 0.5초면 동시성 50이지만, 같은 트래픽이라도 함수가 5초씩 걸리면 500입니다. 실행 시간이 늘어지면 트래픽이 그대로여도 동시성이 폭증합니다.
- 한도는 리전의 모든 함수가 공유합니다: 동시 실행 한도(기본 1,000 안팎)는 함수별이 아니라 계정·리전 단위입니다. 이벤트 폭주로 한 함수가 한도를 다 차지하면, 멀쩡하던 다른 함수들까지 스로틀(429)됩니다 — 썸네일 배치가 결제 웹훅을 죽이는 구조가 됩니다.
- reserved vs provisioned — 이름이 비슷해 헷갈립니다: reserved concurrency는 함수의 동시성 몫을 떼어 보장하는 동시에 그 함수의 상한이 됩니다(폭주 차단·타 함수 보호용). provisioned concurrency는 콜드스타트 제거를 위해 인스턴스를 미리 워밍해 두는 것으로, 유휴 시간에도 과금됩니다. 폭주 방지는 reserved, 지연 개선은 provisioned입니다.
핵심 함수(결제·인증 웹훅)에 reserved로 최소 몫을 보장하고, 폭주 위험 함수(배치·이벤트 소비)에 reserved로 상한을 거는 것 — 이것이 함수가 수십 개로 늘었을 때의 동시성 설계 기본기입니다.
상황: 이미지 업로드 버킷에 썸네일 생성 함수를 트리거로 걸어 두었는데, 밤사이 호출 그래프가 수직 상승. 사용자 업로드는 몇 건뿐인데 호출은 수백만 건이고, S3 PUT 요청 비용과 Lambda 실행 비용이 함께 폭증했습니다.
원인: 재귀 루프입니다. 함수가 생성한 썸네일을 원본과 같은 버킷에 저장했고, 그 저장(PUT)이 다시 같은 트리거를 발화 — 썸네일이 썸네일을 만드는 무한 연쇄입니다. 서버리스는 '알아서 늘어나는' 특성 탓에 이 루프가 사람 개입 없이 초당 수백 건으로 자가 증폭합니다.
진단: CloudWatch 호출 수 그래프에서 특정 시점부터의 기하급수적 증가 확인 → S3 이벤트 알림 설정에서 트리거 대상 버킷·프리픽스와 함수의 출력 경로가 겹치는지 대조합니다.
해결: ① 출력은 다른 버킷으로 분리하거나, 트리거에 프리픽스·서픽스 필터를 걸어 입력(uploads/)과 출력(thumbs/)을 나눔 ② 함수에 reserved concurrency 상한을 걸어 폭주해도 피해 폭을 제한 ③ 예산·이상 지출 알람을 미리 설정해, 새는 것을 다음 날 아침이 아니라 몇 분 안에 알게 합니다. 이벤트 기반 설계에서 "내 출력이 내 트리거가 되는가"는 배포 전 체크리스트에 넣을 가치가 있는 질문입니다.
서버리스는 "운영 부담 최소화 + 트래픽 변동 대응"이 필요한 곳에서 강력하지만, 만능이 아닙니다. 면접에서 "왜 서버리스를 썼나/안 썼나"를 트레이드오프로 설명할 수 있어야 합니다 — 콜드스타트, 실행시간 제한, 상시 고부하 시 비용, DB 커넥션 폭주 같은 현실적 제약을 아는지가 핵심입니다.
실무 패턴: 전체를 서버리스로 짓기보다, 간헐적·이벤트성 부분만 서버리스로 떼어내고(이미지 처리, 알림, 정기 배치) 핵심 상시 API는 컨테이너로 두는 혼합이 흔합니다. 이벤트 기반 아키텍처(동기 vs 비동기)와 잘 맞습니다.
관련 모듈로 더 깊이:
- 매니지드 컨테이너 — 서버리스로 무거운 상시 워크로드를 담는 매니지드 컨테이너 대안
- 메시지 큐와 이벤트 — 서버리스 함수를 트리거하는 이벤트·큐 기반 비동기 처리
- API 게이트웨이 — 서버리스 앞단에서 인증·라우팅·레이트리밋을 담당하는 API 게이트웨이
다음 모듈에서는 서버리스로는 무거운 상시 워크로드를 담는 또 다른 방식 — 매니지드 컨테이너 서비스(ECS·EKS·Fargate) 를 다룹니다.