월말, 재무팀에서 연락이 옵니다. "클라우드 비용이 지난달보다 40% 늘었는데 왜죠?" 청구서를 열어보지만 '컴퓨트 3200만원'처럼 뭉뚱그려져 어느 팀·서비스가 쓴 건지 알 수가 없습니다. 한참 파보니 누군가 테스트로 띄운 대형 인스턴스 5대가 3주째 돌고 있었고, 삭제된 인스턴스의 볼륨 수십 개가 그대로 과금되고 있었습니다. 클라우드 비용은 방치하면 조용히 샙니다.
- 1클라우드 비용이 '설계·운영의 결과'임을 이해한다
- 2흔한 비용 누수 패턴을 알고 찾아낼 수 있다
- 3예약/Savings Plans와 스팟의 적용 기준을 구분할 수 있다
- 4태깅으로 비용을 분해·추적하는 법을 안다
- 5rightsizing·수명주기·자동 종료로 비용을 줄일 수 있다
비용은 어디서 새는가
가장 흔한 누수 — 쓰지 않는데 켜진 것
비용 최적화의 80%는 화려한 기법이 아니라 '고아 자원' 청소입니다.
- 끄지 않은 개발/테스트 인스턴스(주말·야간 유휴)
- 어디에도 안 붙은 EBS 볼륨, 미사용 탄력적 IP
- 트래픽 없는 NAT 게이트웨이(VPC와 서브넷)
- 잊힌 오래된 스냅샷·로그(수명주기 없는 스토리지 오브젝트·블록·파일 스토리지)
이것만 정기적으로 청소해도 청구서가 눈에 띄게 줍니다. 비용 대비 효과가 가장 큽니다.
과대 프로비저닝 — 큰 옷을 입혀두기
온프레 사양을 그대로 옮기거나 "혹시 몰라" 크게 잡으면, 평균 CPU 5%인 인스턴스에 큰돈을 냅니다. rightsizing은 실제 사용률을 보고 한 단계 작은 타입으로 줄이는 작업입니다(가상 서버(EC2)의 타입 선택). 오토스케일링(오토스케일링 + 로드밸런서)으로 베이스는 작게, 피크만 늘리면 더 효율적입니다.
 확대
확대
 확대
위 그림처럼 낭비 제거(즉각 20~40%)가 먼저이고, 그 다음 크기 최적화, 마지막으로 약정·스팟 활용 순으로 접근합니다.
확대
위 그림처럼 낭비 제거(즉각 20~40%)가 먼저이고, 그 다음 크기 최적화, 마지막으로 약정·스팟 활용 순으로 접근합니다.
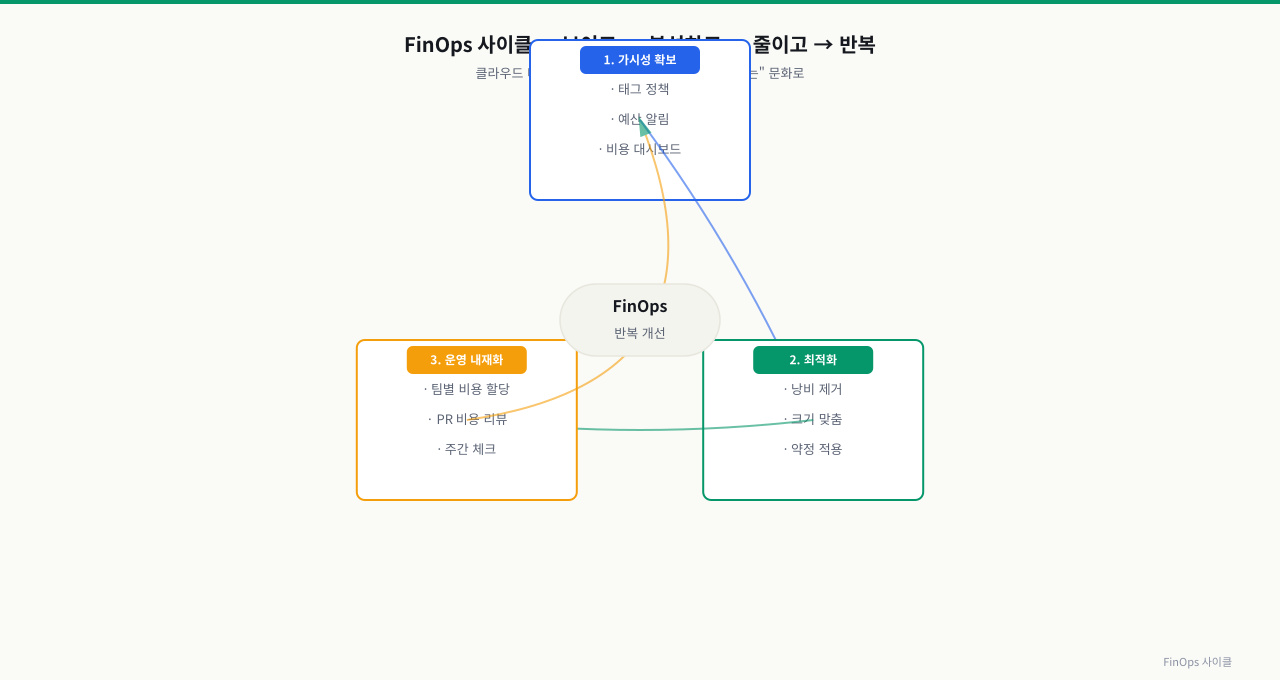 확대
위 그림처럼 FinOps는 가시성 확보 → 최적화 → 팀 운영 내재화를 반복하는 문화입니다. 태그 정책과 예산 알림이 가시성의 시작입니다.
확대
위 그림처럼 FinOps는 가시성 확보 → 최적화 → 팀 운영 내재화를 반복하는 문화입니다. 태그 정책과 예산 알림이 가시성의 시작입니다.
약정과 스팟 — 워크로드 성격에 맞춘 할인
- 예약 인스턴스 / Savings Plans: 1~3년 사용 약정 → 온디맨드 대비 크게 할인. 항상 도는 베이스 워크로드에 적합.
- 스팟 인스턴스: 남는 용량을 최대 수십~90% 싸게 → 단, 용량이 필요해지면 회수(중단). 배치·재시도 가능 워커처럼 중단에 견디는 워크로드에 적합.
패턴: 상시 베이스는 예약, 변동분은 온디맨드/스팟으로 섞어 최적 비용을 만듭니다.
비용 1건이 발생해서 줄어들기까지 — 사용부터 반복까지 5단계
비용 최적화를 '팁 모음'으로 다루면 이번 달만 줄고 다음 달 원위치입니다. 비용은 사용·과금 → 가시화 → 식별 → 조치 → 반복이 도는 사이클이고, 새는 지점은 이 다섯 칸 중 하나가 끊길 때 생깁니다. 어디가 끊겼는지를 알면 '왜 늘었는지 모른다·절감했는데 총액이 늘었다'를 단계로 되짚을 수 있습니다.
[① 사용·과금] 리소스가 켜진 시간·사용량·전송량만큼 요금 누적
│
▼
[② 가시화] 태그(team·service·env) + 비용 리포트로 청구서를 분해
│ '어느 팀·서비스가 얼마를' 볼 수 있게
▼
[③ 식별] 낭비 찾기: 유휴(안 붙은 볼륨·미사용 IP)·과대(CPU 한 자릿수)·미사용 약정
│
▼
[④ 조치] 정리(삭제)·rightsizing·예약/스팟·오토스케일·수명주기
│
▼
[⑤ 반복·예방] 예산 알림·태그 가드레일로 재발 차단 → 다시 ①을 관측
각 단계가 하는 일과, 끊기면 나오는 증상:
| 단계 | 하는 일 | 여기서 끊기면 |
|---|---|---|
| ① 사용·과금 | 리소스는 쓴 만큼(가동 시간·사용량·전송량) 요금이 쌓인다 | 예산 알림이 없음 → 월말 청구서로 처음 알게 됨(사후 대응) |
| ② 가시화 | 태그와 비용 리포트로 청구서를 팀·서비스·환경 차원으로 분해 | 태그 부재 → '컴퓨트 3200만원'으로 뭉뚱그려져 원인·책임 주체 불명 |
| ③ 식별 | 유휴·과대 프로비저닝·미사용 약정 같은 낭비를 지목 | 고아 자원·과대 사양 방치 → 쓰지 않는데 계속 과금 |
| ④ 조치 | 정리·rightsizing·약정/스팟·수명주기로 실제 비용을 낮춤 | 약정 현황을 모른 채 rightsizing → 미사용 약정 + 온디맨드 이중 과금 |
| ⑤ 반복·예방 | 예산 알림·가드레일로 재발을 막고 추세를 관측 | 일회성 청소 후 방치 → 낭비 재누적, 다음 달 원위치 |
즉 비용 관리는 한 번의 청소가 아니라 다섯 칸이 계속 도는 사이클입니다. 왜 늘었는지 모른다면 ②(태그 부재), 안 쓰는데 과금된다면 ③(고아 자원·과대 사양), 절감했는데 총액이 늘었다면 ④(약정과 rightsizing이 따로 논 것)를 의심합니다. 그리고 성장하는 서비스라면 총액이 아니라 단위 비용(요청당·사용자당)으로 봐야 — 트래픽 2배에 비용 1.5배는 개선, 트래픽 그대로에 비용만 늘면 그것이 진짜 누수입니다.
어디에도 연결되지 않은(available) EBS 볼륨을 찾습니다. 이들은 쓰지 않아도 과금됩니다.
aws ec2 describe-volumes --filters Name=status,Values=available \
--query "Volumes[].{Id:VolumeId,Size:Size,Created:CreateTime}" --output table
+------------------+------+----------------------+
| vol-0aaa... | 100 | 2026-03-01T... | ← 3개월째 미사용
| vol-0bbb... | 50 | 2026-05-12T... |
+------------------+------+----------------------+
aws ec2 describe-volumes필수 태그(예: team)가 없는 자원을 찾습니다. 태그 없는 자원은 비용 책임 주체가 불명확합니다.
aws resourcegroupstaggingapi get-resources \
--query "ResourceTagMappingList[?length(Tags[?Key=='team'])==\`0\`].ResourceARN" --output text | head
arn:aws:ec2:...:instance/i-0xxx # team 태그 없음 → 누구 것인지 불명
aws resourcegroupstaggingapi get-resources- status=available인 EBS 볼륨·미연결 탄력적 IP — 사용 안 하면 즉시 삭제·반납(스냅샷 후)
- 필수 태그(team/service/env) 누락 자원 — 비용 분해 불가. 태그 정책으로 강제하고 누락분 소급 태깅
- CPU 사용률이 며칠째 한 자릿수인 인스턴스 — 과대 프로비저닝. rightsizing 또는 오토스케일 전환
- 월별 비용 추세에서 갑자기 튄 항목 — 예산 알림(budget alert)으로 조기 감지. 사후가 아니라 사전에
상황: 비용 급증의 원인을 특정하지 못해 대응이 늦어짐.
원인: 자원에 일관된 태그가 없어 비용을 팀·서비스·환경 차원으로 분해할 수 없음. 태깅이 사후약방문이 됨.
진단: 비용 탐색 도구(Cost Explorer 등)에서 태그·서비스별 분해 시도 → 태그 없는 비중 확인.
해결: ① 필수 태그(team/service/env) 정책을 가드레일로 강제(태그 없으면 생성 차단)(관측과 거버넌스), ② IaC(IaC와 Terraform)에 태그를 코드로 박아 일관성 확보, ③ 예산 알림으로 임계 초과 시 사전 통보. 태깅은 '나중에'가 아니라 처음부터.
심화 — 약정과 단위 비용, 청구서 너머를 읽는 법
심화: 약정은 할인이자 부채 — 활용률·커버리지·단위 비용
고아 자원 청소와 rightsizing이 끝나면 다음 단계는 약정 설계인데, 여기부터는 잘못 사면 손해가 나는 영역입니다.
- 약정은 쓰든 안 쓰든 청구됩니다. 3년 약정 후 아키텍처가 바뀌면(컨테이너 전환, 인스턴스 세대 교체) 새 자원의 온디맨드 요금과 미사용 약정을 이중으로 내게 됩니다.
- 그래서 읽어야 할 지표가 두 개입니다. 활용률(utilization) — 사둔 약정을 실제로 얼마나 쓰고 있나(100%에 가까워야 정상), 커버리지(coverage) — 전체 사용량 중 약정으로 덮인 비율(baseline만큼만). 순서는 활용률이 먼저입니다 — 커버리지 욕심에 크게 사면 활용률이 무너집니다.
- 실무 요령: 작게 나눠 점진 약정(한 번에 3년치 몰빵 금지), 아키텍처 로드맵과 대조(전환 계획이 있으면 인스턴스 패밀리에 고정되는 RI 대신 유연한 Savings Plans), 만료 시점을 분산해 갱신 판단을 나눕니다.
마지막으로, 성장하는 서비스에서 "비용이 늘었다"는 그 자체로는 판단이 안 됩니다. 단위 비용(unit economics) — 요청당·사용자당 비용 — 으로 봐야 합니다. 트래픽이 2배인데 비용이 1.5배면 효율이 좋아진 것이고, 트래픽은 그대로인데 비용만 늘면 그것이 진짜 누수입니다.
상황: 비용 절감 프로젝트로 m5 계열 인스턴스를 최신 세대로 교체해 단가를 20% 낮췄는데, 다음 달 청구서 총액은 오히려 늘었습니다. 절감 보고를 올린 팀은 원인을 설명하지 못합니다.
원인: 기존에 사둔 표준(Standard) RI가 m5 패밀리에 고정돼 있었습니다. 새 인스턴스는 약정 대상이 아니라 온디맨드로 과금되고, m5 약정은 아무도 안 쓰는데 만료까지 계속 청구됩니다 — rightsizing과 약정 관리가 따로 놀면 절감이 손해로 뒤집힙니다.
진단: 비용 도구의 RI/Savings Plans 활용률 리포트를 확인합니다 — 31%면 약정 금액의 69%가 허공에 나가는 중입니다. 어떤 패밀리·리전에 약정이 묶여 있고 실제 사용이 어디로 이동했는지 대조하면 어긋난 시점이 인스턴스 교체일과 일치합니다.
해결: ① 전환형(Convertible) RI라면 새 패밀리로 교환, ② 표준 RI는 마켓플레이스 판매를 검토, ③ 재발 방지로 인스턴스 교체 계획이 있는 조직은 패밀리·리전에 묶이지 않는 Compute Savings Plans를 우선합니다. 그리고 약정 변경과 아키텍처 변경은 같은 자리에서 결정합니다 — 약정 현황을 모르는 rightsizing은 반쪽짜리입니다.
비용 최적화(FinOps)는 인프라 엔지니어·PM 모두의 관심사가 됐습니다. "비용을 어떻게 관리하나요?"에 좋은 답은 ① 태깅으로 가시화, ② 고아 자원 정기 청소, ③ rightsizing, ④ 베이스는 예약·변동은 스팟, ⑤ 예산 알림으로 사전 감지 — 입니다.
PM 관점에서 중요한 메시지: "클라우드로 옮기면 싸진다"는 보장이 아닙니다(왜 클라우드인가). 최적화 없는 lift-and-shift는 오히려 비싸집니다. 비용은 기능·아키텍처 결정의 결과이므로, 설계 단계에서부터 비용을 고려하는 문화가 핵심입니다. 절감의 80%는 화려한 기법이 아니라 '안 쓰는 것 끄기'에서 나옵니다.
관련 모듈로 더 깊이:
- 관측과 거버넌스 — 비용을 본 뒤 자원·다계정을 지표로 관측·통제하는 거버넌스
- IaC와 Terraform — 자원을 코드로 선언해 낭비·드리프트 없이 비용을 관리하는 IaC
- Well-Architected — 비용 최적화를 5대 기둥 중 하나로 다루는 설계 원칙
다음 모듈에서는 비용을 본 다음 자원 자체를 보는 눈 — 지표·로그로 관측하고 다계정을 통제하는 모니터링과 거버넌스(가드레일) 를 다룹니다.