"백업 매일 돌고 있어요." 모두가 안심했습니다. 그런데 DB가 깨진 날, 막상 복원하려니 백업 파일이 6개월째 손상된 채 쌓여 있었고, 복구 절차를 아는 사람도 없었습니다. 서비스 복구에 사흘. 다른 회사는 리전 전체 장애 때 30분 만에 다른 리전으로 넘어갔습니다 — 차이는 "백업이 있느냐"가 아니라 "얼마 만에, 어느 시점으로 복구되도록 설계했느냐" 였습니다.
- 1RTO(복구 시간)와 RPO(복구 시점)를 구분하고 목표로 설정할 수 있다
- 2'백업이 있다'와 '복구된다'의 차이와 DR 훈련의 필요성을 안다
- 33-2-1 백업 규칙을 클라우드에서 구현하는 법을 안다
- 4DR 전략 스펙트럼(백업복원~핫스탠바이)의 비용 트레이드오프를 판단한다
- 5비즈니스 중요도별로 복구 목표를 차등 적용할 수 있다
목표부터 정한다 — RTO와 RPO
복구는 '얼마 만에'(RTO)와 '어느 시점으로'(RPO)
DR 설계는 기술이 아니라 목표 설정에서 시작합니다.
- RTO(Recovery Time Objective): 장애 후 서비스를 되살리기까지 허용 시간. "2시간 안에 복구"
- RPO(Recovery Point Objective): 복구 시 감수할 데이터 손실 범위. "최근 5분치는 잃어도 됨"
RPO 5분이면 최소 5분마다 백업/복제해야 하고, RTO 30분이면 수시간 걸리는 풀 복원으로는 못 맞춥니다. 이 두 숫자가 백업 주기·DR 전략·비용을 전부 결정합니다.
백업이 실제로 복구로 이어지는 흐름 — 백업 시점부터 서비스 재개까지 6단계
RTO와 RPO를 정의만 하면 추상적입니다. 백업이 만들어지는 순간부터 장애가 나고 실제로 서비스가 되살아나기까지를 하나의 시간축에 올려 보면, RPO와 RTO가 그 축의 어느 구간인지 손에 잡힙니다. 이 흐름을 따라가면 "왜 백업이 있는데도 RTO를 못 맞추는지", "왜 검증 안 한 백업은 백업이 아닌지"가 단계로 드러납니다.
[운영 중] 데이터가 계속 쌓임
│
① 주기적 백업 → 스냅샷(전체)+증분/트랜잭션 로그로 복구 지점을 계속 생성
│ ← 백업 간격이 곧 RPO 상한(마지막 백업 이후 데이터는 유실)
│
② 오프사이트 보관 → 사본 1벌을 다른 리전·계정·불변 스토리지에(3-2-1의 '1')
│
══════════ ✗ 장애 발생(하드웨어·리전·실수 삭제·랜섬) ══════════
│
③ 복구 지점 선택 → 사고 '직전' 지점을 고름(스냅샷 시각 또는 PITR 임의 시점)
│
④ 복원 → 사본에서 새 인스턴스·볼륨으로 데이터 복원
│
⑤ 검증 → 데이터 무결성·앱 동작 확인(복원됐다고 끝이 아님)
│
⑥ 서비스 재개 → 트래픽 전환 + 인덱스 재생성·캐시 워밍 등 후속 작업
▼ ← ③~⑥ 전체에 걸린 시간이 곧 실측 RTO
[정상 복귀]
각 단계에서 무슨 일이 일어나고, 어긋나면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 어긋나면 |
|---|---|---|
| ① 주기적 백업 | 스냅샷+증분/로그로 복구 지점을 만든다. 간격이 촘촘할수록 RPO가 짧아짐 | 하루 1회뿐이면 최악의 경우 24시간치 유실(RPO=백업 간격) |
| ② 오프사이트 보관 | 사본 1벌을 다른 리전·계정·불변 스토리지에 | 같은 리전·계정에만 두면 리전 장애·계정 침해 시 백업도 함께 소실 |
| ③ 복구 지점 선택 | 사고 직전 지점을 고름 | 오염이 이미 백업에 섞였으면 더 과거로 가야 함 → 추가 데이터 손실 |
| ④ 복원 | 사본에서 새 인스턴스로 복원 | 콜드·아카이브 클래스는 꺼내는 데 시간이 걸려 RTO 초과의 단골 원인 |
| ⑤ 검증 | 데이터·앱 정상 동작 확인 | 검증 없는 백업은 '있다'일 뿐 — 파일 손상·키 분실이 이때 드러남 |
| ⑥ 서비스 재개 | 트래픽 전환+후속 작업 | 인덱스 재생성·캐시 워밍을 RTO 산정에서 빠뜨리면 실제가 더 김 |
즉 RPO는 ①(백업 간격) 위에, RTO는 ③~⑥(복구 소요) 위에 삽니다. '백업이 있다'와 '복구된다'가 갈리는 지점은 ⑤(검증)이고, 리전 재해에서 살아남는지는 ②(오프사이트)로 결정됩니다. 그래서 RTO·RPO는 문서에 적은 '희망 숫자'가 아니라 이 흐름을 실제로 한 번 돌려 본(DR 훈련) 실측값이어야 합니다 — 재본 적 없는 RTO는 장애 당일 반드시 초과됩니다.
 확대
확대
 확대
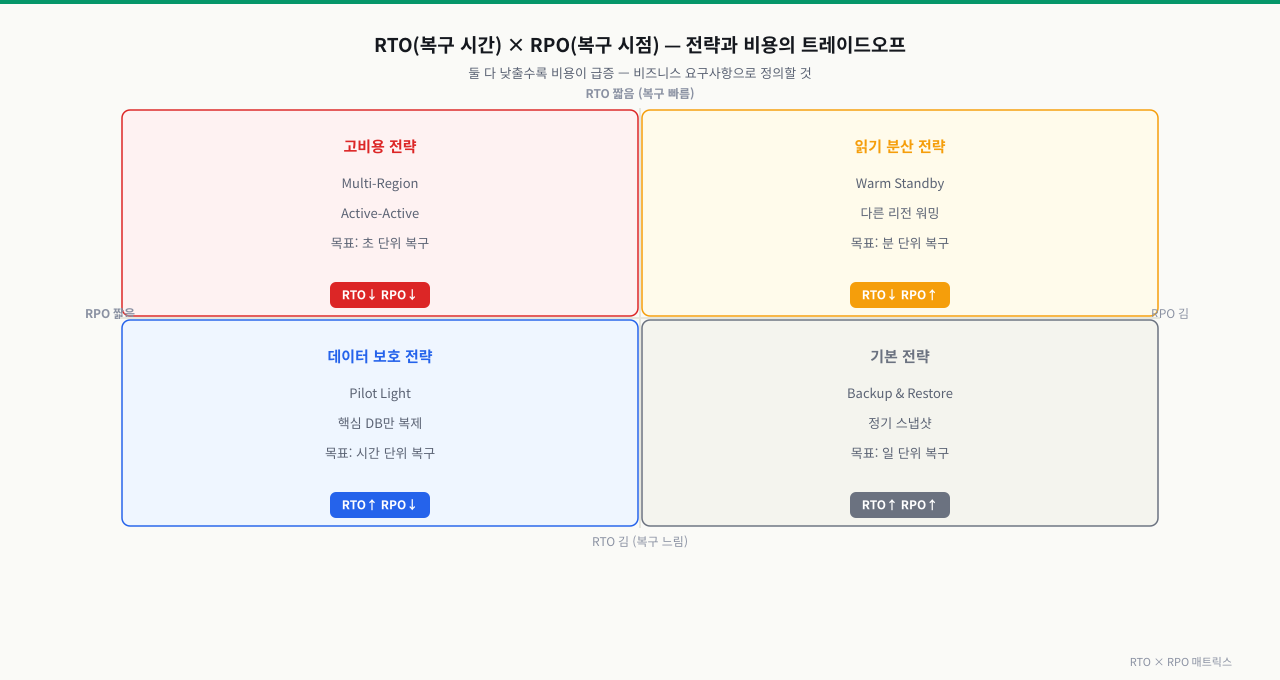
위 그림처럼 RTO·RPO 둘 다 짧을수록 비용이 급증합니다. 비즈니스 요구사항으로 목표치를 정한 뒤 적합한 전략을 선택합니다.
확대
위 그림처럼 RTO·RPO 둘 다 짧을수록 비용이 급증합니다. 비즈니스 요구사항으로 목표치를 정한 뒤 적합한 전략을 선택합니다.
 확대
위 그림처럼 3개 사본, 2가지 매체, 1개 오프사이트를 지키면 단일 위치 재해에서도 데이터를 복구할 수 있습니다.
확대
위 그림처럼 3개 사본, 2가지 매체, 1개 오프사이트를 지키면 단일 위치 재해에서도 데이터를 복구할 수 있습니다.
백업이 '있다' ≠ '복구된다'
가장 흔한 착각이 "백업이 돌고 있으니 안전하다"입니다. 백업이 있어도:
- 파일이 손상됐거나 암호화 키를 잃어 못 읽을 수 있고
- 복구 절차를 아무도 해본 적 없어 사고 때 헤매고
- 대용량 복구가 RTO를 초과할 수 있습니다
'백업 성공 로그'는 복구를 보장하지 않습니다. 정기적으로 백업에서 실제 복원해보는 DR 훈련(game day) 이 유일한 진짜 검증입니다(관리형 데이터베이스(RDS)의 PITR 복원 연습).
 확대
확대
3-2-1 규칙 — 분리된 사본으로 살아남기
사본 3개 / 서로 다른 2개 위치 / 그중 1개는 오프사이트(다른 리전·계정). 한 위치가 통째로 날아가도(리전 장애), 실수로 지워도, 랜섬웨어로 암호화돼도 분리된 사본이 살아남습니다.
클라우드 구현: 교차 리전 복제 + 별도 계정 보관 + 불변(immutable) 스토리지(쓰기 후 변경·삭제 방지). 백업 계정을 분리하면 운영 계정이 침해돼도 백업은 지켜집니다(관측과 거버넌스의 멀티계정·가드레일).
'백업 잡이 켜져 있다'가 아니라 '최근 복구 지점이 실제로 생성됐는지'를 봅니다.
aws backup list-recovery-points-by-backup-vault --backup-vault-name prod-vault \
--query "RecoveryPoints[0:3].{Created:CreationDate,Status:Status,Size:BackupSizeInBytes}" --output table
+----------------------+-----------+-------------+
| 2026-06-16T02:00Z | COMPLETED| 53687091200|
| 2026-06-15T02:00Z | COMPLETED| 53201000000|
+----------------------+-----------+-------------+
aws backup list-recovery-points-by-backup-vault오프사이트 사본이 실제로 있는지 — 오프사이트가 없으면 리전 장애에 속수무책입니다.
aws backup list-copy-jobs --by-state COMPLETED \
--query "CopyJobs[0:3].{Dest:DestinationBackupVaultArn,State:State}" --output table
+--------------------------------------------------+-----------+
| arn:aws:backup:ap-northeast-1:...:vault/dr-vault | COMPLETED| ← 도쿄로 복사됨
+--------------------------------------------------+-----------+
aws backup ...- 최근 RecoveryPoint의 CreationDate가 RPO 목표보다 오래됐는지 — 예: RPO 24h인데 마지막 백업이 3일 전이면 백업 잡 실패. 즉시 원인 점검
- Status가 COMPLETED가 아닌(FAILED/PARTIAL) 복구 지점 — 백업이 실패 중. '성공 로그'만 믿지 말고 상태 직접 확인
- 교차 리전/계정 복사(copy-job)가 없는 핵심 데이터 — 오프사이트 사본 부재. 리전 장애·랜섬·실수삭제에 취약(3-2-1의 1 누락)
- 마지막 DR 복구 훈련 일자 — 한 번도 복원해본 적 없으면 RTO는 '추정'일 뿐. 정기 game day 일정 수립
상황: 백업은 있는데 복구가 RTO를 크게 초과.
원인: ① 대용량 데이터를 콜드/아카이브 스토리지에서 꺼내는 데 시간(검색 지연), ② 복원 후 인덱스 재생성·캐시 워밍 등 후속 작업 미고려, ③ 복구 절차가 수동·미문서화라 단계마다 지체, ④ RTO를 측정 없이 '희망'으로 잡음.
진단: 백업 스토리지 클래스(꺼내는 속도) 확인 → 실제 복원 시간을 game day로 측정 → 복원 후 정상화까지 전체 시간 측정.
해결: RTO가 빡빡하면 백업·복원 대신 웜/핫 스탠바이로 전략 격상(클라우드 비용 최적화 비용 트레이드오프 감수). 자주 복구하는 데이터는 즉시 접근 가능한 스토리지 클래스에. 복구 절차를 자동화(IaC와 Terraform)·문서화(runbook)하고 정기 훈련으로 실측 RTO를 확보. RTO는 '재본 적 있는' 숫자여야 합니다.
심화 — 복제는 백업이 아니다
심화: 가용성 복제와 시점 복구 — 그리고 시스템 간 정합성
"Multi-AZ에 읽기 복제본까지 있으니 백업은 됐다"는 실무 최다 착각입니다. 복제는 장애를 견디는 수단이지, 실수를 되돌리는 수단이 아닙니다 — 잘못된 DELETE, 랜섬웨어의 암호화, 버그가 쓴 오염 데이터는 복제본에 즉시 똑같이 전파됩니다. 복제가 지켜주는 건 '하드웨어가 죽어도 서비스가 산다'까지입니다.
실수를 되돌리는 건 시점 복구(PITR) 입니다 — 스냅샷에 트랜잭션 로그(WAL/binlog)를 이어 붙여 '사고 1분 전'으로 되감습니다(관리형 데이터베이스(RDS)). 하루 1회 스냅샷만 있으면 실질 RPO가 최대 24시간이지만, PITR이 켜져 있으면 분 단위로 좁혀집니다. RPO 질문에는 복제 유무가 아니라 시점 복구 능력으로 답해야 합니다.
규모가 커지면 하나 더 — 시스템 간 백업 시점 정합성입니다. DB는 02:00, 파일 스토리지는 03:30에 따로 백업하면, 복원 후 '주문 레코드는 있는데 첨부파일은 없는' 반쪽 상태가 됩니다. 서로 참조하는 시스템은 같은 백업 그룹으로 묶어 시점을 맞추고, DR 훈련도 시스템 단위가 아니라 서비스 단위로 복원해 정합성까지 검증합니다.
상황: 운영 DB에서 수동 데이터 보정 중 WHERE 절이 빠진 UPDATE가 실행됐습니다. 'Multi-AZ니까 스탠바이에서 복구하면 된다'고 판단했지만, 동기 복제는 잘못된 쓰기도 이미 즉시 복제한 뒤였습니다.
원인: 복제를 백업으로 오해한 설계. 스냅샷은 매일 새벽 1회뿐이고 PITR은 비활성 — 사고가 오후에 났으니 스냅샷으로 복원하면 그날 영업 데이터를 통째로 잃습니다(실질 RPO 최대 24시간). 가용성은 갖췄지만 되돌릴 시점이 없습니다.
진단: 먼저 스탠바이·읽기 복제본의 데이터가 원본과 동일하게 오염됐는지 확인합니다(복제 지연이 크면 드물게 살아 있기도 합니다) → 가장 최근 복구 지점(스냅샷 시각·PITR 가능 범위)을 조회해 실제로 되돌아갈 수 있는 시점을 확정합니다.
해결: PITR이 가능하다면 사고 직전 시점의 인스턴스를 별도로 복원해, 오염된 행만 원본과 대조해 역보정하는 것이 손실을 최소화합니다(전체 롤백은 사고 이후의 정상 트랜잭션까지 날립니다). 재발 방지: ① 운영 DB에 PITR 상시 활성화, ② 수동 보정은 트랜잭션으로 감싸 영향 건수를 확인한 뒤 커밋하는 절차 강제, ③ 'RPO 몇 분까지 감수 가능한가'를 복제 유무가 아니라 시점 복구 능력으로 답하도록 팀 기준을 바꿉니다.
면접·감사 단골: "RTO/RPO가 어떻게 되나요?"에 숫자로 답하고 그 근거(백업 주기·DR 전략)를 말할 수 있어야 합니다. "백업해요"만으로는 부족 — "RPO 15분(15분마다 복제), RTO 1시간(웜 스탠바이), 분기마다 복구 훈련"처럼 목표·수단·검증이 세트입니다.
실무 핵심: ① 모든 시스템에 같은 DR을 적용하지 말고 비즈니스 중요도별 차등(결제=핫스탠바이, 내부도구=백업복원), ② 백업 계정·리전 분리로 침해·삭제·랜섬 격리, ③ '백업 있음'이 아니라 '복구 검증됨'을 KPI로. 백업 비용은 보험이지만, 복구 안 되는 백업은 비싼 착각입니다. 이 주제는 관리형 데이터베이스(RDS)·관측과 거버넌스·클라우드 비용 최적화와 한 묶음으로 운영됩니다.
다음 단계로는 이 복원력을 코드로 선언·자동화하는 IaC와 Terraform, 백업·복구 상태를 관측·알람하는 관측과 거버넌스로 이어집니다.