운영 서버에서만 Node.js 앱이 SyntaxError로 죽었습니다. 로컬은 Node 20인데 서버는 Node 12였고, nullish coalescing 문법을 서버 런타임이 이해하지 못했습니다.
컨테이너를 쓰면 이 차이를 이미지 안에 묶을 수 있지만, Docker 엔진이 실제로 무엇을 격리하는지 모르면 장애 때 어디를 봐야 할지 모릅니다. 이 모듈에서는 컨테이너가 리눅스 커널 위에서 어떤 장치로 격리되는지 직접 확인합니다.
컨테이너 패러다임과 Docker 엔진
소프트웨어 배포의 역사에서 컨테이너 기술은 근본적인 패러다임 전환을 가져왔습니다. "내 로컬에서는 잘 되는데 왜 운영 서버에서는 안 되죠?"라는 질문은 수많은 개발자와 운영자를 괴롭혔던 고전적인 문제입니다. 이 챕터에서는 그 문제의 근원을 이해하고, 컨테이너가 어떻게 이를 해결하는지 살펴봅니다.
앞 모듈에서 "왜 컨테이너인가"를 배웠다면, 이번엔 Docker 엔진이 어떻게 컨테이너를 만들고 격리하는지 내부 구조를 이해하고 직접 설치까지 완료합니다.
- 1네임스페이스와 cgroups로 컨테이너 격리가 동작하는 방식을 설명할 수 있다
- 2Docker 엔진 내부 아키텍처에서 dockerd, containerd, runc의 역할 분리를 설명할 수 있다
- 3Ubuntu/Debian 환경에 Docker Engine을 공식 방법으로 설치할 수 있다
- 4docker run hello-world로 설치를 검증하고 기본 흐름을 이해할 수 있다
이 챕터는 Docker 설치부터 시작합니다. 아래 항목을 확인한 뒤 진행하세요.
macOS라면 Docker Desktop으로 대체 가능
sudo -vcurl -s https://download.docker.com > /dev/null && echo OK컨테이너가 격리를 구현하는 방법 — 네임스페이스와 cgroups
앞 모듈에서 "컨테이너는 커널을 공유하면서도 격리된다"고 배웠습니다. Docker가 이것을 어떻게 구현하는지 봅니다.
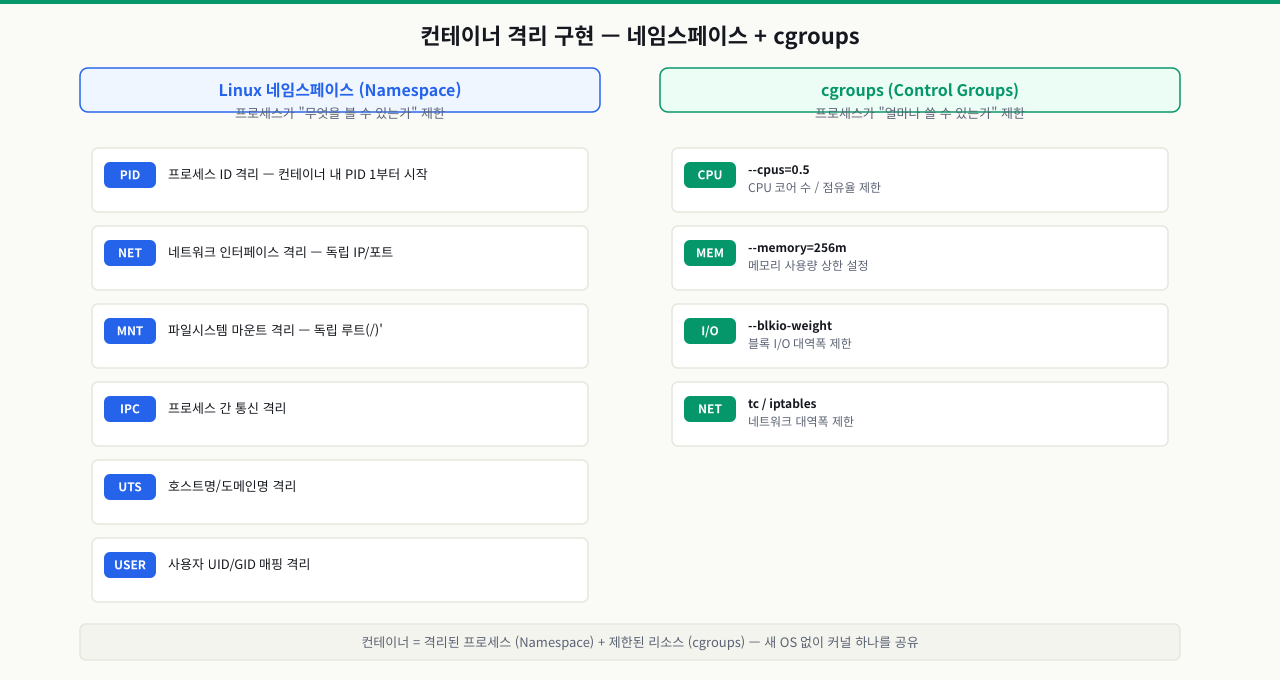
컨테이너가 격리된다는 것은 마법이 아닙니다. 리눅스 커널이 오래전부터 제공해온 두 가지 기능을 Docker가 사용하기 쉽게 포장한 것입니다. **네임스페이스(Namespace)**와 **cgroups(Control Groups)**가 그것입니다.
네임스페이스는 "각 컨테이너가 자기만의 세계를 가지게 한다"는 개념입니다. 컨테이너 안에서 보면 자신이 혼자 서버 전체를 쓰는 것처럼 보이지만, 실제로는 같은 커널 위에서 수십 개의 컨테이너가 동시에 동작하고 있습니다. 네임스페이스가 프로세스, 네트워크, 파일시스템 등 커널 자원을 컨테이너마다 독립된 공간으로 분리해주기 때문입니다.
cgroups는 "각 컨테이너가 쓸 수 있는 자원의 양을 제한한다"는 개념입니다. 아무리 격리되어 있어도 CPU나 메모리를 무한정 쓸 수 있으면 한 컨테이너가 서버 전체를 점유할 수 있습니다. cgroups가 각 컨테이너에 자원 상한선을 걸어줍니다.
 확대
확대
아래 표는 네임스페이스가 어떤 항목을 격리하는지 정리한 것입니다:
리눅스 네임스페이스 — 컨테이너마다 독립된 세계:
| 네임스페이스 | 격리 대상 | 효과 |
|---|---|---|
pid | 프로세스 ID | 컨테이너 안에서 PID 1부터 시작 |
net | 네트워크 인터페이스, 라우팅 | 독립된 IP 주소와 포트 공간 |
mnt | 파일시스템 마운트 | / 아래가 컨테이너 전용 파일시스템 |
uts | 호스트명 | 컨테이너마다 다른 hostname |
ipc | 공유 메모리, 세마포어 | 컨테이너 간 IPC 격리 |
user | 사용자/그룹 ID | root지만 호스트엔 일반 사용자 |
cgroups — 자원 사용량 제한:
cgroups는 docker run 실행 시 --memory, --cpus 플래그로 설정한 제한값을 커널 수준에서 강제합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/docker/part1/exam_4 && cd /tmp/docker/part1/exam_4
# 컨테이너에 메모리와 CPU 제한 적용
docker run --memory=512m --cpus=0.5 nginx
# → 커널이 이 컨테이너 프로세스의 메모리를 512MB로 제한
# → 초과 시 OOM Killer가 컨테이너 프로세스를 종료
이 두 기술(네임스페이스 + cgroups)이 Docker가 컨테이너를 격리하는 핵심 메커니즘입니다. Docker 엔진은 이 기술들을 사용하기 쉽게 포장한 것입니다.
docker run 한 줄이 컨테이너를 조립하는 법 — namespace·cgroup·overlayfs 5단계
방금 namespace(격리)와 cgroup(제한)을 따로 배웠습니다. 그런데 실제 docker run 한 줄은 이 둘에 **overlayfs 레이어(파일시스템)**까지 더해 세 장치를 순서대로 조립해, '독립된 것처럼 보이는 프로세스' 하나를 만들어 냅니다. 이 조립 순서를 알면 컨테이너가 왜 VM보다 가벼운지(커널을 공유하니까), 그리고 실행이 실패했을 때 어느 조립 단계를 봐야 하는지가 한눈에 보입니다.
docker run --memory=512m --cpus=0.5 nginx
│
① 파일시스템 조립 → overlayfs로 읽기전용 이미지 레이어들 위에
│ 쓰기 가능 레이어 1장을 얹어 컨테이너의 루트(/)를 만듦
│
② namespace 생성 → clone()으로 pid·net·mnt·uts·ipc(·user) 분리
│ → 컨테이너는 자기만의 PID 1·eth0·/ 를 보게 됨
│
③ cgroup 배치 → 이 프로세스를 cgroup에 넣고 CPU 0.5·메모리 512m 상한 기록
│ → 커널이 초과 시 스로틀·OOM으로 강제
│
④ 루트 전환 → mnt 네임스페이스 안에서 ①의 overlayfs를 / 로 pivot_root
│
⑤ 프로세스 실행 → 격리·제한된 환경에서 nginx 를 PID 1로 시작
▼
[컨테이너] 호스트 커널을 공유하는, 격리된 하나의 프로세스
세 장치가 각각 무엇을 맡고, 없거나 새면 어떻게 되나:
| 장치 | 무엇을 하나 | 없거나 새면 |
|---|---|---|
| namespace | 프로세스가 보는 시야를 분리 — pid·net·mnt·uts·ipc·user별로 '나 혼자 쓰는 것처럼' 보이게 | 격리 안 됨 → 호스트 프로세스·네트워크가 그대로 보임. 단 /proc/cpuinfo·/proc/meminfo는 안 가려져 컨테이너 안에서도 호스트 코어·메모리가 보임 |
| cgroup | 프로세스가 쓸 수 있는 자원의 양을 제한 — CPU·메모리·I/O 상한 | 상한 없음 → 한 컨테이너가 호스트 자원을 독식(noisy neighbor), OOM으로 옆 컨테이너까지 위협 |
| overlayfs 레이어 | 파일시스템을 조립 — 읽기전용 이미지 레이어 + 쓰기 가능 컨테이너 레이어(CoW) | 레이어 공유 안 됨 → 디스크 중복, docker rm 시 쓰기 레이어만 날아가야 하는 경계가 무너짐 |
VM과의 근본 차이가 여기서 드러납니다. VM은 하이퍼바이저 위에 게스트 커널을 통째로 올려 부팅하지만, 컨테이너는 위 세 장치로 '격리된 척'하는 하나의 프로세스일 뿐 호스트 커널을 그대로 공유합니다. 그래서 부팅이 없고 수십 ms 만에 뜨며 이미지도 가볍습니다. 대신 커널이 따로 없으니 호스트 커널 버전·cgroup 버전·아키텍처 차이가 컨테이너로 그대로 샙니다. 핵심은 시야(namespace)와 몫(cgroup)이 서로 다른 장치라는 점입니다 — 격리했다고 자원 한도까지 아는 게 아니고, 자원을 제한했다고 시야가 좁아지는 것도 아닙니다.
정리하면 docker run 실패는 이 조립 단계로 좁혀 진단합니다 — 이미지·overlayfs 준비 실패(①), clone()/namespace 생성 실패(②), cgroup 한도 관련(③, OOMKilled·스로틀), 루트 마운트 실패(④, exec 경로 문제로 exit 127/126)입니다.
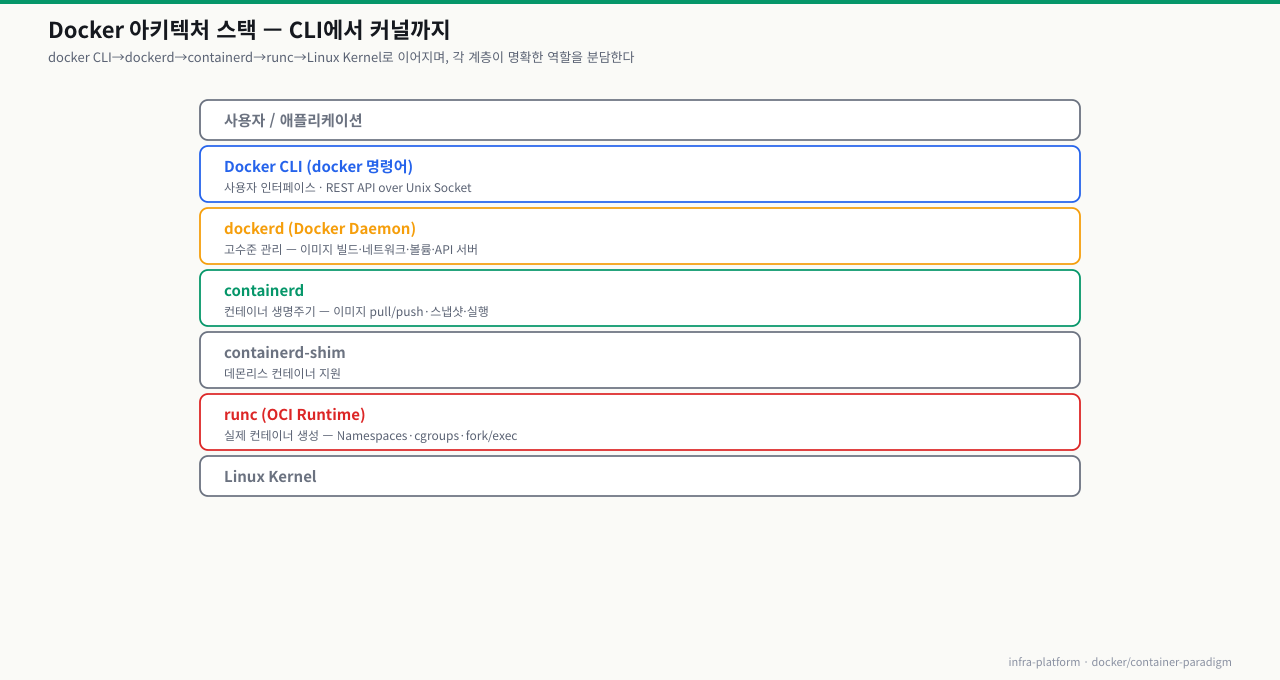
Docker 엔진 아키텍처 — dockerd, containerd, runc
docker run nginx를 실행하면 CLI부터 실제 프로세스 생성까지 여러 컴포넌트를 거칩니다. 장애가 났을 때 dockerd가 죽었는지, containerd가 문제인지, runc가 실패했는지 구분해야 올바른 지점에서 복구할 수 있습니다. 또한 Kubernetes가 Docker 대신 containerd를 직접 쓰는 이유, 컨테이너 안에서 Docker 소켓을 마운트하면 왜 보안 위험이 되는지도 이 구조에서 이해됩니다. 이 ConceptBlock에서는 Docker 엔진의 계층 구조와 각 컴포넌트의 역할 분리를 다룹니다.
 확대
확대
Docker 엔진의 내부 구조
초기 Docker는 단일 모놀리식 바이너리였지만, 현재는 OCI(Open Container Initiative) 표준에 따라 여러 컴포넌트로 분리되어 있습니다. 이 분리는 컨테이너 생태계의 상호 운용성을 높이고 각 레이어가 독립적으로 교체 가능하도록 합니다.
 확대
확대
각 컴포넌트의 역할
Docker CLI
사용자가 입력하는 docker run, docker build 등의 명령어를 처리합니다. CLI는 /var/run/docker.sock 유닉스 소켓을 통해 dockerd와 REST API로 통신합니다.
dockerd (Docker Daemon) Docker의 핵심 데몬 프로세스입니다. 다음 역할을 담당합니다:
- Docker API 서버 운영
- Dockerfile 빌드 처리 (
docker build) - Docker 네트워크 관리 (bridge, overlay 등)
- Docker 볼륨 관리
- containerd와의 통신 조율
containerd CNCF(Cloud Native Computing Foundation)에 기증된 독립적인 컨테이너 런타임입니다. Kubernetes도 직접 containerd를 사용합니다. 주요 역할:
- 컨테이너 이미지 pull/push 및 저장소 관리
- 컨테이너 스냅샷 관리 (overlay filesystem)
- 컨테이너 실행/중지/삭제 생명주기 관리
containerd-shim containerd와 실제 컨테이너 프로세스 사이의 중간 프로세스입니다. containerd가 재시작되더라도 실행 중인 컨테이너가 종료되지 않도록 보호하는 역할을 합니다.
runc OCI 런타임 스펙(OCI Runtime Specification)의 참조 구현체입니다. 실제로 다음 작업을 수행합니다:
- Linux 네임스페이스 생성 및 설정
- cgroup 계층 구조 생성 및 리소스 제한 설정
- 컨테이너 루트 파일시스템 마운트 (overlay)
clone()시스템 콜로 격리된 프로세스 생성
Docker 소켓과 보안
/var/run/docker.sock은 Docker CLI와 dockerd가 통신하는 Unix 소켓입니다. 이 소켓에 접근하는 것은 사실상 root 권한과 동일하므로, 누가 접근할 수 있는지 확인하는 것이 중요합니다.
# Docker 소켓 파일 확인
ls -la /var/run/docker.sock
# srw-rw---- 1 root docker ... /var/run/docker.sock
/var/run/docker.sock은 docker 그룹에 속한 사용자만 접근할 수 있습니다. 이 소켓에 접근할 수 있다는 것은 사실상 root 권한과 동일한 수준의 권한을 의미하므로, 신뢰할 수 있는 사용자에게만 docker 그룹 멤버십을 부여해야 합니다.
목표
Docker 공식 문서에서 권장하는 apt 저장소를 통해 Docker Engine을 설치합니다. 배포판 기본 저장소의 구버전 Docker 대신 항상 공식 방법을 사용하세요.
사전 조건
- Ubuntu 20.04 LTS, 22.04 LTS, 또는 24.04 LTS
- sudo 권한이 있는 사용자 계정
- 인터넷 연결
단계별 설치
1단계: 기존 충돌 패키지 제거
배포판 기본 저장소에 포함된 구버전 Docker 관련 패키지를 제거합니다.
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/docker/part1/exam_1 && cd /tmp/docker/part1/exam_1
# Docker 설치 확인용 스크립트 생성
cat > check-docker.sh << 'EOF'
#!/bin/bash
echo "=== Docker 설치 확인 ==="
docker --version
docker info | grep -E "Server Version|Operating System|Architecture"
EOF
chmod +x check-docker.sh
이제 실습을 진행합니다.
for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do
sudo apt-get remove -y $pkg 2>/dev/null
done
2단계: Docker 공식 GPG 키 추가
패키지 무결성 검증을 위한 GPG 키를 등록합니다.
# 필수 패키지 설치
sudo apt-get update
sudo apt-get install -y ca-certificates curl
# GPG 키 저장 디렉토리 생성
sudo install -m 0755 -d /etc/apt/keyrings
# Docker 공식 GPG 키 다운로드
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg \
-o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
3단계: Docker apt 저장소 추가
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] \
https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
4단계: Docker Engine 설치
sudo apt-get install -y \
docker-ce \
docker-ce-cli \
containerd.io \
docker-buildx-plugin \
docker-compose-plugin
각 패키지의 역할:
docker-ce: Docker Community Edition 데몬 (dockerd)docker-ce-cli: Docker CLI 클라이언트containerd.io: containerd 컨테이너 런타임docker-buildx-plugin: BuildKit 기반 멀티플랫폼 빌드 플러그인docker-compose-plugin:docker compose서브커맨드 플러그인
5단계: Docker 서비스 시작 및 자동 시작 설정
# Docker 데몬 시작
sudo systemctl start docker
# 부팅 시 자동 시작 설정
sudo systemctl enable docker
# 서비스 상태 확인
sudo systemctl status docker
정상 상태 출력 예시:
● docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled)
Active: active (running) since ...
6단계: docker 그룹에 현재 사용자 추가
# 현재 사용자를 docker 그룹에 추가
sudo usermod -aG docker $USER
# 변경 사항 즉시 적용 (새 셸 세션)
newgrp docker
# 또는 로그아웃 후 재로그인
7단계: 설치 확인
# hello-world 컨테이너 실행
docker run hello-world
성공 시 다음과 같은 메시지가 출력됩니다:
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
- systemctl status docker 출력에서 먼저 "Active: active (running)" 확인 — 여기가 정상이어야 나머지 단계가 의미 있다
- docker version 출력의 Client 버전과 Server 버전이 모두 표시되는지 확인 — Server 항목이 없으면 dockerd가 실행 중이 아닌 것
- docker run hello-world 실행 시 "Unable to find image" 메시지가 나온 뒤 pull이 진행되고 "Hello from Docker!"로 끝나야 정상 — pull 없이 바로 실행되면 이미 이미지가 로컬에 있는 것
- sudo 없이 docker ps 실행해서 permission denied가 뜨면 newgrp docker 또는 로그아웃/재로그인이 안 된 것 — id 명령으로 현재 세션의 그룹 목록에 docker가 있는지 먼저 확인
목표
Red Hat 계열 리눅스 배포판에 Docker Engine을 공식 yum 저장소를 통해 설치합니다.
단계별 설치
1단계: 기존 충돌 패키지 제거
sudo yum remove -y docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine \
podman \
runc
2단계: yum-utils 설치 및 저장소 추가
sudo yum install -y yum-utils
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
3단계: Docker Engine 설치
sudo yum install -y \
docker-ce \
docker-ce-cli \
containerd.io \
docker-buildx-plugin \
docker-compose-plugin
4단계: 서비스 시작 및 사용자 설정
sudo systemctl start docker
sudo systemctl enable docker
sudo usermod -aG docker $USER
newgrp docker
# 설치 확인
docker run hello-world
Docker 버전 확인
# Docker 클라이언트와 서버 버전 확인
docker version
# 시스템 전반적인 정보 확인
docker info
docker info 출력에서 주요 항목:
Server Version: dockerd 버전Storage Driver: 파일시스템 드라이버 (보통 overlay2)Cgroup Driver: cgroup 관리 방식 (cgroupv2 권장)Total Memory: 사용 가능한 총 메모리
목표
docker run hello-world 실행 과정을 단계별로 분석하고, 실제로 컨테이너가 어떻게 동작하는지 확인합니다.
Docker가 docker run hello-world 처리하는 과정
1. docker CLI → dockerd에 REST API 요청
2. dockerd → 로컬 이미지 캐시 확인
3. 이미지 없음 → Docker Hub에서 pull
4. containerd → 이미지 스냅샷 준비
5. runc → Linux 네임스페이스/cgroups 설정 후 컨테이너 프로세스 실행
6. hello-world 프로그램 실행 후 출력
7. 프로세스 종료 → 컨테이너 Exited 상태
실습
이 실습은 Docker 데몬이 설치된 환경에서 바로 실행할 수 있는 순수 명령어 실습입니다. hello-world 이미지는 Docker Hub에서 자동으로 pull됩니다.
기본 실행 및 상태 확인
# hello-world 실행
docker run hello-world
# 모든 컨테이너 확인 (종료된 것 포함)
docker ps -a
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# a1b2c3d4e5f6 hello-world "/hello" 10 seconds ago Exited (0) 9 seconds ago magical_tesla
이미지 캐시 확인
# 로컬에 저장된 이미지 목록
docker images
# REPOSITORY TAG IMAGE ID CREATED SIZE
# hello-world latest d2c94e258dcb ... 13.3kB
이미지 레이어 구조 확인
# 이미지 상세 정보 확인
docker image inspect hello-world
# 레이어 정보만 추출
docker image inspect hello-world --format '{{json .RootFS.Layers}}'
컨테이너와 이미지 정리
# 종료된 컨테이너 삭제
docker rm $(docker ps -aq -f status=exited)
# 또는 컨테이너 실행 후 자동 삭제
docker run --rm hello-world
Docker 시스템 리소스 사용량 확인
# 디스크 사용량 확인
docker system df
# 전체 시스템 정보
docker info
문제 상황
개발자가 로컬 환경(macOS, Ubuntu 22.04)에서 잘 작동하던 Node.js 애플리케이션을 운영 서버(CentOS 7, Node.js 12)에 배포했는데 다음과 같은 에러가 발생했습니다.
Error: Cannot find module 'some-package'
SyntaxError: Unexpected token '??' (nullish coalescing — Node.js 14+ 기능)
근본 원인 분석
이 문제는 **환경 불일치(Environment Mismatch)**에서 발생합니다:
| 항목 | 로컬 환경 | 운영 환경 |
|---|---|---|
| OS | macOS Ventura | CentOS 7 |
| Node.js | v20.x | v12.x |
| npm | 10.x | 6.x |
| 시스템 라이브러리 | 최신 | 구버전 |
| 환경 변수 | .env 파일 존재 | .env 없음 |
컨테이너가 해결하는 방법
컨테이너 이미지는 애플리케이션 실행에 필요한 모든 의존성을 패키징합니다:
- 정확한 버전의 런타임 (Node.js 20.x)
- 시스템 라이브러리
- 설정 파일
- 애플리케이션 코드
# Dockerfile - 환경을 코드로 정의
FROM node:20-alpine
WORKDIR /app
COPY package*.json ./
RUN npm ci --only=production
COPY . .
EXPOSE 3000
CMD ["node", "server.js"]
이 이미지는 어느 환경에서 실행해도 동일한 Node.js 20 환경을 보장합니다.
즉각적인 디버깅 방법
# 운영 환경과 동일한 베이스 이미지로 컨테이너를 띄워 직접 확인
docker run --rm -it node:20-alpine sh
# 컨테이너 내에서 실제 실행 환경 확인
node --version
npm --version
예방 방법
- Dockerfile에 정확한 버전 태그 명시:
node:20.11.0-alpine(:latest금지) - package-lock.json 또는 yarn.lock 커밋: 의존성 버전 고정
- 환경 변수는 런타임에 주입:
.env파일 대신-e플래그나 시크릿 매니저 활용 - CI/CD에서 동일한 Docker 이미지 사용: 빌드/테스트/배포 환경 통일
문제 상황
sudo 없이 docker 명령어를 실행하면 다음 에러가 발생합니다:
$ docker run hello-world
permission denied while trying to connect to the Docker daemon socket
at unix:///var/run/docker.sock: Get "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/containers/json":
dial unix /var/run/docker.sock: connect: permission denied
원인
/var/run/docker.sock 파일은 docker 그룹만 읽기/쓰기 권한을 가집니다:
ls -la /var/run/docker.sock
# srw-rw---- 1 root docker ... /var/run/docker.sock
현재 사용자가 docker 그룹에 속하지 않으면 소켓에 접근할 수 없습니다.
해결 방법
# 1. 현재 사용자의 그룹 확인
id
# uid=1000(ubuntu) gid=1000(ubuntu) groups=1000(ubuntu)
# docker 그룹이 없음
# 2. docker 그룹에 사용자 추가
sudo usermod -aG docker $USER
# 3. 현재 세션에 즉시 적용
newgrp docker
# 4. 확인
id
# uid=1000(ubuntu) gid=1000(ubuntu) groups=1000(ubuntu),998(docker)
# 5. 테스트
docker run hello-world
주의사항
usermod -aG docker $USER 실행 후 newgrp docker를 사용하지 않고 그냥 명령어를 실행하면 여전히 같은 에러가 발생합니다. 이는 현재 셸 세션이 이전 그룹 정보를 캐싱하고 있기 때문입니다. 반드시 newgrp docker 또는 로그아웃/재로그인이 필요합니다.
Docker 소켓을 사용하는 컨테이너의 보안 고려사항
컨테이너 내부에서 Docker 소켓을 마운트하는 패턴(Docker-in-Docker)은 보안상 매우 위험합니다:
# 이렇게 하면 컨테이너가 호스트 Docker에 완전한 접근 권한을 가짐 (위험!)
docker run -v /var/run/docker.sock:/var/run/docker.sock some-image
CI/CD 시스템이나 모니터링 도구에서 이 패턴을 사용할 때는 최소 권한 원칙에 따라 신중하게 결정해야 합니다.
심화 — 격리했다고 한도를 아는 건 아니다
심화: 격리의 구멍 — 컨테이너 안의 nproc·free는 호스트를 본다
앞에서 네임스페이스가 격리를, cgroups가 자원 제한을 담당한다고 배웠습니다. 이 둘을 하나로 뭉뚱그리면 "격리했으니 알아서 한도 안에서 돌겠지"라는 오해가 생기는데, 여기서 실제 성능·OOM 사고가 나옵니다.
- 네임스페이스가 격리하는 것과 아닌 것: pid·net·mnt 네임스페이스는 프로세스·네트워크·마운트의 '보이는 범위'를 나눕니다. 하지만
/proc/cpuinfo·/proc/meminfo는 커널 전역 정보라 네임스페이스로 가려지지 않습니다. 64코어·256GB 호스트에서--cpus 1 --memory 512m로 띄운 컨테이너 안에서도nproc는 64,free는 256GB로 보입니다. cgroup은 '쓸 수 있는 양'을 제한할 뿐 '보이는 숫자'를 바꾸지 않습니다. - 런타임이 이 거짓말에 속습니다: 코어 수로 스레드풀·워커 수를 자동 결정하는 런타임이 많습니다 — Go의 GOMAXPROCS, nginx의
worker_processes auto, JVM의 가용 프로세서, Node의 워커 풀. 호스트 64코어를 보고 워커 64개를 띄우면, 정작--cpus 1의 CPU 몫 안에서 64개가 경합해 컨텍스트 스위칭만 늘고 느려집니다. 메모리도 마찬가지로, 호스트 RAM 기준으로 힙·캐시를 크게 잡으면 cgroup 한도를 넘겨 OOMKill이 납니다. - 한도를 명시하거나 cgroup 인식 런타임으로 메웁니다: 최신 JVM(UseContainerSupport)·최신 Go·Node는 cgroup 한도를 읽어 스스로 맞추기도 하지만, 오래된 버전이나
worker_processes auto는 여전히 호스트를 봅니다. GOMAXPROCS·worker 수·-Xmx·스레드풀 크기를 컨테이너 한도에 맞춰 명시하거나, automaxprocs 같은 보정 라이브러리를 씁니다. - 왜 이게 패러다임 이야기인가: "컨테이너는 격리된 프로세스"의 정확한 뜻은 '보이는 범위(네임스페이스)'와 '쓸 수 있는 양(cgroup)'이 서로 다른 장치라는 것입니다. 격리와 제한을 별개로 이해해야, 자원 한도를 건 컨테이너가 왜 여전히 호스트 전체를 본다고 착각하고 과다 할당하는지가 설명됩니다.
정리하면 네임스페이스는 '시야'를, cgroup은 '몫'을 다룹니다. 이 둘이 다르다는 걸 알아야 자원 한도가 앱의 자동 튜닝까지 자동으로 바꿔 주지는 않는다는 점을 놓치지 않습니다.
상황: 넉넉한 호스트에 자원 한도를 걸어 여러 앱을 촘촘히 올렸습니다. 그런데 한 앱이 뜨자마자 워커·스레드를 대량 생성하고, docker stats에는 CPU가 한도에 붙어 스로틀링되며 이따금 OOMKilled가 찍힙니다. 코드도 트래픽도 그대로입니다.
원인: 앱이 워커 수·힙 크기를 nproc·전체 메모리를 기준으로 자동 결정합니다. 네임스페이스는 프로세스 뷰만 격리할 뿐 /proc/cpuinfo·/proc/meminfo는 호스트 전역이라, 컨테이너 안에서도 64코어·256GB로 보입니다. 앱은 그 숫자대로 워커 64개·큰 힙을 잡지만 실제로는 cgroup의 1코어·512MB 안에 갇혀 경합과 OOM이 납니다. 앞의 '환경 불일치' 사례와 달리, 환경은 같은데 자원 인식이 틀어진 경우입니다.
진단: 컨테이너 안에서 실제로 어떤 숫자를 보는지 확인합니다.
docker exec <컨테이너> sh -c 'nproc; free -m | head'
# 64 ← --cpus 1인데도 호스트 코어 수가 보인다
# Mem: 257842 ... ← -m 512m인데도 호스트 전체 RAM이 보인다
여기서 나온 코어 수와 앱이 실제로 띄운 워커 수가 같으면(=호스트 코어 수만큼) 확정입니다. docker inspect의 OOMKilled와 CPU throttling 지표도 함께 봅니다.
해결: 런타임이 '보이는 값(nproc)'이 아니라 '쓸 수 있는 값(cgroup 한도)'을 기준으로 자원을 잡게 만듭니다. Go는 GOMAXPROCS를 한도에 맞추거나 automaxprocs를, Node·스레드풀은 워커 수를 명시, nginx는 worker_processes를 auto 대신 숫자로, JVM은 컨테이너 인식이 되는 최신 버전을 쓰고 -Xmx를 한도 안쪽으로 둡니다. 근본 원칙은 자동 튜닝을 호스트가 아니라 컨테이너 한도에 묶는 것입니다.
DevOps/SRE 엔지니어의 일상
컨테이너는 현대 소프트웨어 개발과 운영의 중심에 있습니다. 현업에서 어떻게 활용되는지 살펴봅니다.
개발 환경 표준화
팀 전체가 동일한 개발 환경을 사용하도록 Dockerfile과 docker-compose.yml을 관리합니다.
# 신규 입사자 온보딩: 이 한 줄로 전체 개발 환경 구성
docker compose up -d
# 더 이상 "내 맥에서는 되는데요" 문제 없음
CI/CD 파이프라인에서의 역할
Jenkins, GitHub Actions, GitLab CI 등 대부분의 CI/CD 도구는 컨테이너 기반으로 빌드 환경을 제공합니다:
# GitHub Actions 예시
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Build Docker image
run: docker build -t myapp:${{ github.sha }} .
- name: Run tests in container
run: docker run --rm myapp:${{ github.sha }} npm test
마이크로서비스 아키텍처와 컨테이너
Netflix, Uber, Kakao 같은 대형 서비스는 수백~수천 개의 마이크로서비스를 컨테이너로 운영합니다. 각 서비스가 독립적으로 배포 가능하며, 장애 영향 범위가 최소화됩니다.
실제 현업 Docker 사용 빈도
개발자 설문 기준으로 2024년 현재:
- 약 85%의 기업이 컨테이너를 프로덕션 환경에 사용
- Kubernetes를 사용하는 기업의 100%가 컨테이너 기반
- Docker는 컨테이너 도구 중 가장 높은 인지도와 사용률 유지
이 챕터에서 배운 내용이 실제로 쓰이는 순간
- 인프라 구축 회의: "VM으로 할까요, 컨테이너로 할까요?" 결정 시 각 트레이드오프 설명
- 보안 리뷰: "이 컨테이너가 docker.sock을 마운트하면 어떤 위험이 있나요?" 답변
- 온콜 대응:
systemctl status docker로 데몬 상태 확인, 재시작 - 신규 서버 프로비저닝: 자동화 스크립트에 Docker 설치 과정 포함
Docker를 단순히 "명령어"로 외우는 것이 아니라 내부 동작 원리를 이해하면, 장애 상황에서 훨씬 빠르게 근본 원인을 파악하고 해결할 수 있습니다.
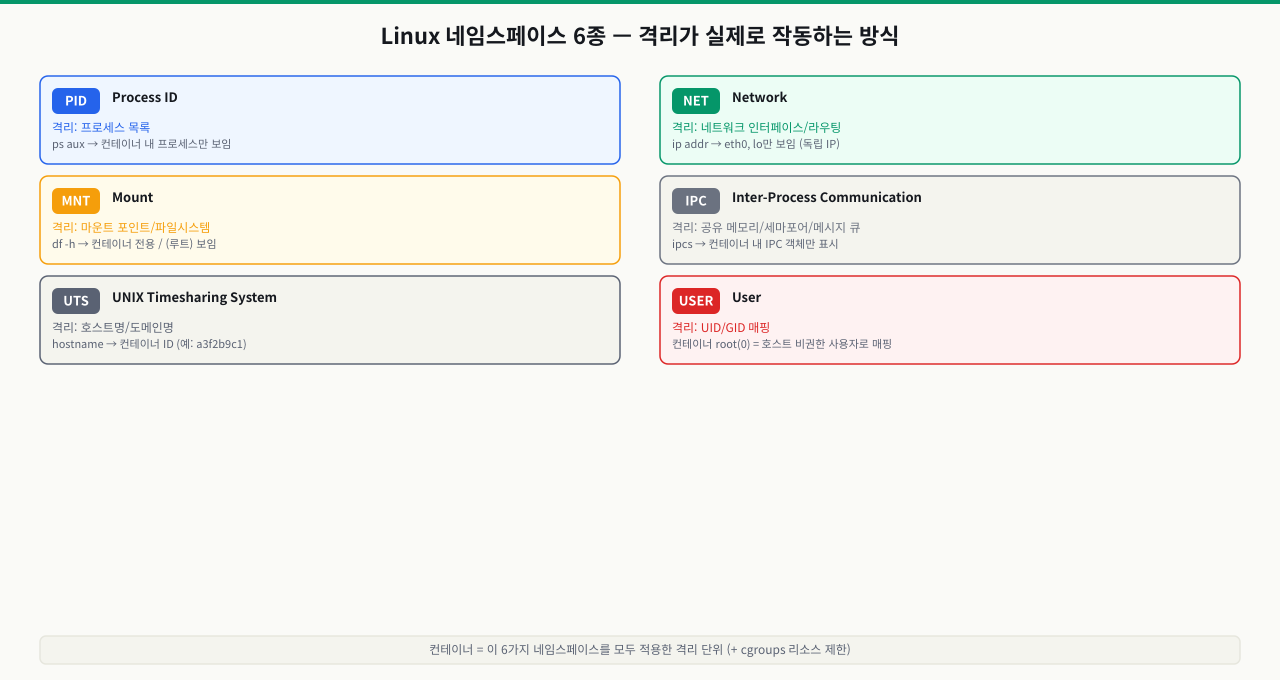
Linux 네임스페이스 6종 — 격리가 실제로 작동하는 방식
docker exec demo ps aux를 실행했을 때 PID가 1번부터 시작하는 걸 보고 이상하다고 느낀 적 있을 겁니다. 호스트에서 같은 프로세스를 보면 PID가 수만 번대입니다. 같은 프로세스를 두 개의 다른 PID로 보는 이유가 pid 네임스페이스입니다. 네임스페이스의 6가지 유형을 구체적으로 알면 컨테이너 내부에서 보이는 세계가 왜 다른지, 컨테이너가 어느 수준까지 격리되고 어느 수준에서 공유하는지 이해할 수 있습니다. 이 ConceptBlock에서는 각 네임스페이스가 무엇을 격리하는지 실제 명령어로 확인합니다.
 확대
확대
컨테이너는 사실 "격리된 프로세스"다
컨테이너의 본질은 VM처럼 별도 OS를 띄우는 것이 아니라, 리눅스 커널의 네임스페이스 기능으로 격리된 프로세스입니다. 네임스페이스가 뭘 격리하는지 구체적으로 알아야 "컨테이너 안에서 보이는 세계"가 왜 다른지 이해됩니다.
pid 네임스페이스 — 프로세스 번호 격리
컨테이너 안에서 보이는 PID와 호스트에서 보이는 PID가 다릅니다.
# 컨테이너 실행
docker run -d --name demo nginx
# 호스트에서 nginx 프로세스 PID 확인 (큰 번호)
docker inspect demo --format '{{.State.Pid}}'
# 예: 12345
# 컨테이너 안에서는 PID 1로 보임
docker exec demo ps aux
# PID USER COMMAND
# 1 root nginx: master process
# 31 nginx nginx: worker process
컨테이너 밖에서는 PID 12345인데, 컨테이너 안에서는 PID 1입니다. 같은 프로세스를 두 개의 다른 PID 공간에서 보고 있는 것입니다.
net 네임스페이스 — 네트워크 인터페이스 격리
컨테이너는 자신만의 eth0, 라우팅 테이블, iptables를 가집니다.
# 컨테이너 안의 네트워크 인터페이스
docker exec demo ip addr show
# eth0: 172.17.0.2/16 ← 컨테이너 전용 IP
# 호스트의 네트워크 인터페이스 (컨테이너 eth0과 별개)
ip addr show
# eth0: 192.168.1.100/24 ← 호스트 IP
# docker0: 172.17.0.1/16 ← Docker 브릿지
mnt 네임스페이스 — 파일시스템 격리
컨테이너는 호스트와 다른 /(루트) 파일시스템을 봅니다.
# 컨테이너 안의 /
docker exec demo ls /
# bin boot dev etc lib media mnt opt proc root run sbin srv sys tmp usr var
# 호스트 / 와 내용이 다름 (이미지의 파일시스템)
# 컨테이너가 삭제될 때 이 파일시스템도 사라짐
uts 네임스페이스 — 호스트명 격리
컨테이너는 호스트와 다른 hostname을 가집니다. --hostname 옵션으로 직접 지정하지 않으면 컨테이너 ID 앞 12자리가 자동으로 사용됩니다.
# 컨테이너 안의 hostname
docker exec demo hostname
# a1b2c3d4e5f6 ← 컨테이너 ID 기반 자동 생성
# --hostname 옵션으로 지정 가능
docker run --hostname myapp nginx
docker exec myapp hostname
# myapp
ipc 네임스페이스 — 프로세스 간 통신 격리
공유 메모리(shared memory), 세마포어 등 IPC 리소스가 컨테이너 간 격리됩니다. 컨테이너 A가 만든 공유 메모리를 컨테이너 B는 볼 수 없습니다.
user 네임스페이스 — 사용자 ID 격리 (Rootless Container의 기초)
컨테이너 안의 root(UID 0)는 호스트에서 일반 사용자로 매핑될 수 있습니다. 이 구조를 쓰면 컨테이너가 탈출하더라도 호스트의 root 권한을 바로 얻지 못합니다. 자세한 보안 설정은 docker-security 챕터에서 심화 학습합니다.
네임스페이스 실제 확인
네임스페이스는 /proc/<PID>/ns/ 디렉토리 아래 심볼릭 링크로 존재합니다. 링크가 가리키는 숫자 ID가 같으면 같은 네임스페이스를 공유하고, 다르면 격리된 것입니다.
# 컨테이너 프로세스의 네임스페이스 파일 목록
PID=$(docker inspect demo --format '{{.State.Pid}}')
sudo ls -la /proc/$PID/ns/
# lrwxrwxrwx ... ipc -> ipc:[4026532345]
# lrwxrwxrwx ... mnt -> mnt:[4026532344]
# lrwxrwxrwx ... net -> net:[4026532348]
# lrwxrwxrwx ... pid -> pid:[4026532346]
# lrwxrwxrwx ... uts -> uts:[4026532343]
각 네임스페이스는 고유한 ID를 가지며, 같은 ID면 같은 네임스페이스를 공유하고 있음을 의미합니다.
이미지 레이어와 레이어 공유 — docker pull이 빠른 이유
ubuntu:22.04와 python:3.11 이미지를 따로 pull했는데 두 번째 pull이 유독 빠르게 끝납니다. 'Already exists' 메시지가 표시되며 일부 레이어만 내려받습니다. 두 이미지가 공통 레이어를 공유하기 때문입니다. 이 공유 구조를 이해하면 Dockerfile에서 왜 COPY requirements.txt를 소스코드보다 앞에 두어야 하는지, 컨테이너를 삭제해도 이미지가 남아있는 이유가 자연스럽게 설명됩니다. 이 ConceptBlock에서는 이미지 레이어 구조와 컨테이너 쓰기 레이어의 관계를 다룹니다.
 확대
확대
Docker 이미지 = 레이어(Layer)의 스택
Dockerfile 명령어 하나(FROM, RUN, COPY 등)가 실행될 때마다 새로운 읽기 전용 레이어가 생성됩니다. 이미지는 이 레이어들이 쌓인 구조입니다.
docker pull python:3.11-slim 실행 시 터미널 출력:
3.11-slim: Pulling from library/python
a480a496ba95: Pull complete ← 레이어 1 (Debian 기반)
f3ace1b8ce45: Pull complete ← 레이어 2 (apt 업데이트)
11d6fdd0e8a7: Pull complete ← 레이어 3 (Python 설치)
Digest: sha256:abc123...
각 줄이 하나의 레이어입니다.
레이어 공유 — 디스크를 절약하는 방법
같은 베이스 이미지를 쓰는 이미지들은 하위 레이어를 공유합니다.
# ubuntu:22.04 pull
docker pull ubuntu:22.04
# Layers: abc111, abc222, abc333
# python:3.11 pull (ubuntu 기반)
docker pull python:3.11
# abc111: Already exists ← 이미 있는 레이어는 다운로드 안 함!
# abc222: Already exists ← 재사용!
# abc333: Already exists ← 재사용!
# xyz444: Pull complete ← Python만 새로 받음
이것이 docker pull이 빠른 이유입니다. 디스크에도 중복 없이 한 번만 저장됩니다.
이미지 레이어 확인 명령어
docker history로 이미지를 구성하는 레이어와 각각의 크기를 확인하고, docker system df로 공유 레이어를 반영한 실제 디스크 사용량을 파악할 수 있습니다.
# 이미지의 레이어 히스토리와 각 크기 확인
docker history nginx:alpine
# IMAGE CREATED CREATED BY SIZE
# abc123def456 2 days ago CMD ["nginx" "-g" "daemon ... 0B
# <missing> 2 days ago EXPOSE map[80/tcp:{}] 0B
# <missing> 2 days ago COPY /etc/nginx /etc/nginx ... 5.47kB
# <missing> 2 days ago RUN /bin/sh -c apk add --... 15.1MB
# <missing> 2 days ago FROM alpine:3.19 7.73MB ← 베이스
# 로컬 이미지 목록과 크기
docker image ls
# REPOSITORY TAG IMAGE ID SIZE
# nginx alpine abc123 43.2MB
# python 3.11 def456 230MB
# 전체 디스크 사용량 (공유 레이어 반영한 실제 사용량)
docker system df
# TYPE TOTAL SIZE RECLAIMABLE
# Images 5 520MB 320MB (61%)
컨테이너 = 이미지 + 쓰기 레이어 1개
이미지 레이어는 읽기 전용입니다. docker run으로 컨테이너를 만들면 그 위에 쓰기 가능한 레이어가 하나 추가됩니다. 컨테이너를 삭제하면 이 쓰기 레이어만 사라지고, 이미지 레이어는 그대로 남습니다.
 확대
확대
같은 이미지로 컨테이너 10개를 실행해도 이미지 레이어는 공유하고, 쓰기 레이어만 10개 생성됩니다.
정리
이 챕터에서 배운 핵심 내용을 정리합니다:
핵심 개념 요약
- VM vs 컨테이너: VM은 하드웨어 수준 격리(독립 커널), 컨테이너는 OS 수준 격리(공유 커널 + 네임스페이스/cgroups)
- Docker 엔진 계층: CLI → dockerd → containerd → runc 순으로 책임이 분리됨
- 설치 방법: 공식 저장소(apt/yum)를 통해 설치하고
usermod -aG docker $USER로 권한 설정 - 컨테이너 패러다임: 환경을 코드로 정의하여 어느 환경에서든 동일하게 실행
자주 사용하는 명령어 치트시트
# Docker 버전 확인
docker version
# 시스템 정보 확인
docker info
# hello-world 실행
docker run hello-world
# 로컬 이미지 목록
docker images
# 실행 중인 컨테이너 목록
docker ps
# 모든 컨테이너 목록 (종료된 것 포함)
docker ps -a
# Docker 서비스 상태
sudo systemctl status docker
관련 모듈로 더 깊이:
- 포트 바인딩 오류 방지와 컨테이너의 핵심 상태 변화 — 엔진 구조 이해를 바탕으로 컨테이너의 run/stop/rm 상태 변화를 실제로 제어
- pull, build, tag, push 이미지 관리 라이프사이클 — 컨테이너가 실행하는 이미지의 레이어 구조와 pull/build/push 라이프사이클
다음 모듈에서는 컨테이너의 생명주기를 심층적으로 다룹니다. docker run, docker stop, docker rm의 정확한 동작과 포트 바인딩으로 외부 트래픽을 컨테이너로 전달하는 방법을 학습합니다.