헬스체크와 자동 복구 정책
컨테이너는 "Up" 상태인데 사용자 요청은 실패하고, 장애는 아침이 되어서야 발견됩니다. 실무에서 중요한 건 프로세스 생존이 아니라 서비스 응답 가능 상태를 지속적으로 검증하는 것입니다. HEALTHCHECK와 restart 정책을 잘못 조합하면 오히려 조기 실패나 무한 재시작을 만들 수 있습니다. 이 모듈은 상태 판단 기준과 자동 복구 경계를 명확히 잡는 데 집중합니다.
컨테이너가 실행 중(Running)이라는 사실이 곧 서비스가 정상적으로 동작한다는 의미는 아닙니다. 프로세스는 살아 있지만 DB 커넥션 풀이 고갈되거나, 메모리 누수로 응답 불능 상태가 되거나, 초기화 도중 의존성이 준비되지 않아 요청을 처리하지 못하는 경우가 실무에서 빈번히 발생합니다. Docker의 HEALTHCHECK와 restart 정책을 조합하면 이런 상황을 자동으로 감지하고 복구하는 자가 치유(self-healing) 컨테이너를 구현할 수 있습니다.
컨테이너가 단순히 '켜져 있음'을 넘어 '실제로 요청을 처리할 수 있는 상태'인지 지속적으로 검증하고, 문제 발생 시 자동으로 복구되도록 구성하는 방법을 익힙니다.
- 1HEALTHCHECK의 --interval, --timeout, --retries, --start-period 4개 옵션 역할을 설명할 수 있다
- 2starting / healthy / unhealthy 헬스 상태 3가지와 전환 조건을 설명할 수 있다
- 3no / always / on-failure / unless-stopped restart 정책 4가지를 비교해 선택할 수 있다
- 4docker-compose healthcheck와 depends_on condition: service_healthy를 연동할 수 있다
- 5pg_isready, mysqladmin ping, curl, wget으로 실전 DB/웹서버 헬스체크를 구성할 수 있다
HEALTHCHECK 지시어는 Dockerfile에서 직접 지정하거나 docker-compose.yml의 healthcheck 키로 설정할 수 있습니다. 이미 빌드된 공식 이미지에 헬스체크를 추가할 때는 Compose 파일 방식이 편리합니다.
docker --versionmkdir -p ~/healthcheck-lab && cd ~/healthcheck-labdocker pull nginx:alpine && docker pull postgres:16-alpine && docker pull redis:7-alpineHEALTHCHECK 지시어 문법과 옵션
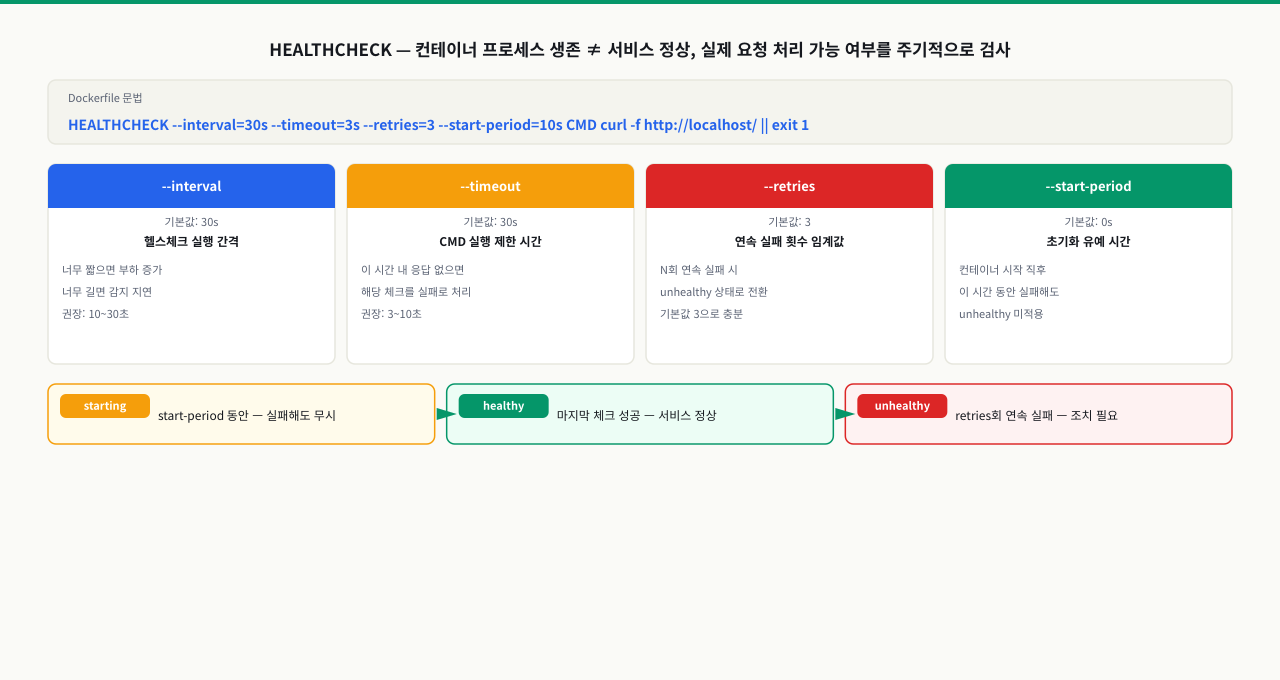
docker ps에서 컨테이너가 "Up 3 hours"로 표시되는데 사용자는 502 Bad Gateway를 받고 있습니다. 프로세스는 살아 있지만 DB 커넥션이 고갈되어 요청을 처리하지 못하는 상태입니다. "컨테이너가 실행 중"이라는 사실이 "서비스가 정상"을 의미하지 않습니다. HEALTHCHECK는 컨테이너 내부에서 실제로 요청을 처리할 수 있는지 주기적으로 검사하고, 그 결과에 따라 starting/healthy/unhealthy 세 가지 상태를 부여합니다. 이 ConceptBlock에서는 HEALTHCHECK 지시어의 문법과 네 가지 옵션의 역할을 다룹니다.
 확대
확대
HEALTHCHECK란
Docker의 HEALTHCHECK 지시어는 컨테이너의 상태를 주기적으로 검사하여 세 가지 상태 중 하나로 분류합니다.
| 상태 | 의미 | 전환 조건 |
|---|---|---|
starting | 초기화 중 | 컨테이너 시작 직후 기본 상태 |
healthy | 정상 | 헬스체크 명령어가 exit code 0 반환 |
unhealthy | 비정상 | 헬스체크가 --retries 횟수만큼 연속 실패 |
Dockerfile HEALTHCHECK 기본 문법
HEALTHCHECK [옵션] CMD <명령어>
네 가지 핵심 옵션: interval, timeout, retries, start_period 네 가지로 헬스체크 동작을 제어합니다.
HEALTHCHECK \
--interval=30s \ # 헬스체크 실행 주기 (기본값: 30s)
--timeout=10s \ # 명령어 응답 대기 시간 (기본값: 30s)
--start-period=40s \ # 시작 유예 기간 (기본값: 0s)
--retries=3 \ # 연속 실패 허용 횟수 (기본값: 3)
CMD curl -f http://localhost/health || exit 1
옵션별 동작 상세 설명
 확대
확대
실제 Dockerfile 예시
Nginx 웹서버 헬스체크: curl로 HTTP 응답을 확인하는 가장 일반적인 패턴입니다.
FROM nginx:alpine
# nginx에 curl 설치
RUN apk add --no-cache curl
HEALTHCHECK \
--interval=15s \
--timeout=5s \
--start-period=10s \
--retries=3 \
CMD curl -f http://localhost/ || exit 1
COPY nginx.conf /etc/nginx/nginx.conf
Node.js 애플리케이션 헬스체크: /health 엔드포인트가 있는 경우 이를 활용합니다.
FROM node:18-alpine
WORKDIR /app
COPY package*.json ./
RUN npm ci --only=production
COPY . .
EXPOSE 3000
HEALTHCHECK \
--interval=20s \
--timeout=5s \
--start-period=30s \
--retries=3 \
CMD node -e "require('http').get('http://localhost:3000/health', (r) => process.exit(r.statusCode === 200 ? 0 : 1)).on('error', () => process.exit(1))"
CMD ["node", "server.js"]
헬스체크 비활성화
베이스 이미지에 이미 HEALTHCHECK가 정의되어 있을 때 이를 무효화하려면:
HEALTHCHECK NONE
restart 정책 4가지 비교
새벽 3시에 OOM으로 Node.js 컨테이너가 종료됐습니다. 아침에 출근해서야 서비스가 내려간 것을 알았습니다. restart: unless-stopped를 설정했다면 컨테이너가 자동으로 재시작되어 사용자는 짧은 중단만 경험했을 것입니다. 반대로 유지보수를 위해 docker stop으로 컨테이너를 내렸는데 서버 재부팅 후 다시 올라오면 의도치 않은 동작입니다. 재시작 정책은 "어떤 상황에서 자동으로 다시 켜지게 할 것인가"를 제어합니다. 이 ConceptBlock에서는 no/always/on-failure/unless-stopped 네 가지 정책의 동작 차이와 선택 기준을 다룹니다.
 확대
확대
restart 정책이란
컨테이너가 종료됐을 때 Docker 데몬이 어떻게 처리할지를 지정합니다. docker run --restart 또는 docker-compose.yml의 restart 키로 설정합니다.
4가지 정책 상세 비교
1. no (기본값)
restart: "no"
컨테이너가 종료되면 재시작하지 않습니다. 개발 중 일회성으로 실행하는 컨테이너나 배치 작업에 적합합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/docker/part5/exam_19 && cd /tmp/docker/part5/exam_19
$ docker run --rm alpine echo "작업 완료"
작업 완료
# 종료 후 자동 삭제, 재시작 없음
2. always
restart: always
- 종료 코드와 무관하게 항상 재시작
- Docker 데몬이 재시작될 때도 컨테이너를 자동으로 시작
- 수동으로
docker stop해도 데몬 재시작 시 다시 켜짐
$ docker run -d --restart=always --name demo nginx:alpine
$ docker stop demo
$ sudo systemctl restart docker
$ docker ps # demo 컨테이너가 다시 실행 중!
3. on-failure[:횟수]
restart: on-failure:3
- 비정상 종료(exit code != 0) 시에만 재시작
- 최대 재시작 횟수 제한 가능
- 정상 종료(exit code 0)에는 재시작하지 않음
- 크래시 루프를 방지할 수 있어 디버깅에 유용
# 의도적으로 실패하는 컨테이너 테스트
$ docker run -d --restart=on-failure:3 --name crasher \
alpine sh -c "echo '크래시!' && exit 1"
$ docker ps -a
# CONTAINER ID STATUS
# abc123 Restarting (1) 5 seconds ago
# → 3회 실패 후 더 이상 재시작 안 함
$ docker inspect crasher --format '{{.RestartCount}}'
3
4. unless-stopped
restart: unless-stopped
always와 거의 동일하지만 수동 중지 상태를 기억docker stop으로 명시적으로 중지한 컨테이너는 Docker 데몬 재시작 후에도 다시 시작하지 않음- 운영 환경에서 가장 권장되는 정책
재시작 정책 비교표:
상황 | no | always | on-failure | unless-stopped
-----------------------------|-----|--------|------------|---------------
정상 종료 (exit 0) | - | 재시작 | - | 재시작
비정상 종료 (exit != 0) | - | 재시작 | 재시작 | 재시작
docker stop 후 데몬 재시작 | - | 재시작 | 재시작 | -
크래시 무한 루프 방지 | O | X | O (횟수제한)| X
실무 선택 기준
# 개발/테스트: 재시작 없이 로그 확인
restart: "no"
# 웹서버, API 서버 등 항상 켜져야 하는 서비스
restart: unless-stopped
# 시스템 필수 서비스 (모니터링 에이전트 등)
restart: always
# 빠른 크래시-재시작 루프를 방지해야 하는 서비스
restart: on-failure:5
헬스체크 한 번이 재시작으로 이어지기까지 — 감시부터 복구까지 6단계
헬스체크를 걸고 restart: always만 붙이면 "알아서 복구되겠지"라고 기대하기 쉽습니다. 하지만 감시(HEALTHCHECK)와 복구(restart 정책)는 사실 서로 다른 신호로 움직입니다 — 하나는 상태를 표시할 뿐이고, 다른 하나는 프로세스 종료를 감지합니다. 이 둘이 어디서 이어지고 어디서 끊기는지를 단계로 보면 "healthy인데 트래픽이 실패한다", "컨테이너가 끝없이 재시작된다", "on-failure를 줬는데 조용히 죽어 있다"를 각각 어느 지점 문제인지로 좁힐 수 있습니다.
컨테이너 시작
│
① start-period 유예 (기본 0s, 예: 40s) — 이 동안 실패는 카운트 안 함 → starting
│
② interval마다 헬스체크 CMD 실행 (기본 30s 간격)
│ · exit 0 → 성공, FailingStreak 0으로 리셋 → healthy
│ · exit 1 또는 timeout 초과 → 실패, FailingStreak +1
│
③ 연속 실패가 retries(기본 3)에 도달 → unhealthy
│ ※ 단일 Docker 호스트에서는 여기서 자동 재시작이 '안' 일어남
│
── 별개의 축: PID 1이 종료(exit)할 때만 아래가 발동 ──
│
④ restart 정책 평가 (no · on-failure · always · unless-stopped)
│ · 종료 코드·정책이 맞으면 → ⑤
│ · 안 맞으면 → Exited 유지
│
⑤ 지수 백오프 후 재시작 (100ms→200ms→400ms…) → RestartCount +1 → Running
│
⑥ on-failure:N이면 N회까지만 → 소진되면 재시작 포기 → Exited
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 / 증상 |
|---|---|---|
| ① start-period | 시작 직후 유예 기간. 이 동안 실패해도 retries 카운터를 안 올림 | 너무 짧으면 JVM·DB 워밍업 전에 실패가 쌓여 곧바로 unhealthy |
| ② 주기 실행 | interval마다 CMD 실행, exit 0이면 healthy·리셋, 실패면 FailingStreak +1 | timeout이 너무 짧으면 응답이 느릴 뿐인 정상 서비스도 실패로 계수 |
| ③ unhealthy 판정 | 연속 실패가 retries에 도달하면 상태를 unhealthy로 '표시' | unhealthy인데 재시작이 안 됨 → 정상 동작(표시만 함, 복구는 별개 축) |
| ④ restart 정책 평가 | PID 1이 종료될 때 정책·종료 코드를 보고 재시작 여부 결정 | 정책이 no면 죽어도 안 뜸 / on-failure는 exit 0에는 반응 안 함 |
| ⑤ 백오프 재시작 | 조건이 맞으면 지수 백오프를 두고 다시 실행, RestartCount 증가 | 시작 직후 계속 죽으면 CrashLoop → RestartCount 급증, STATUS가 Restarting |
| ⑥ on-failure 소진 | on-failure:N은 N회까지만 재시작하고 포기 | N회 소진 후 STATUS가 Exited로 굳어 조용히 방치됨 |
즉 **HEALTHCHECK는 '상태를 표시하는 신호'이고 재시작은 '종료(exit)를 감지해 되살리는 손'**이라, 둘은 다른 축에서 움직입니다. 그래서 세 가지 오해가 자주 생깁니다. 첫째, docker ps가 (healthy)인데 트래픽이 실패하면 — 헬스체크가 포트 열림이나 프로세스 생존만 얕게 확인하고 실제 요청 처리를 안 봤을 때입니다. 체크를 /health 같은 실제 엔드포인트로 바꿔야 합니다. 둘째, 컨테이너가 끝없이 재시작되면(CrashLoop) — ⑤의 지수 백오프에도 docker inspect의 RestartCount가 계속 오르고 STATUS가 Restarting을 오갑니다. 이때 State.ExitCode가 137이면 OOM, 1이면 앱 에러가 근본 원인이라 재시작 정책으로는 못 고칩니다. 셋째, on-failure:N을 준 서비스가 조용히 죽어 있으면 — ⑥에서 N회를 소진하고 STATUS가 Exited로 굳은 것이니 재시작 횟수 제한을 다시 점검합니다. 진단은 언제나 docker ps의 STATUS(healthy·unhealthy·starting·Restarting) → docker inspect의 State.Health·RestartCount·State.ExitCode 순서로 좁힙니다.
기본 실습
nginx에 헬스체크를 추가한 커스텀 이미지를 만들고 상태 변화를 관찰합니다.
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/docker/part3/exam_4 && cd /tmp/docker/part3/exam_4
# 헬스체크 실습용 기본 Dockerfile 생성
cat > Dockerfile << 'EOF'
FROM nginx:alpine
RUN apk add --no-cache curl
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \
CMD curl -f http://localhost/ || exit 1
EOF
이제 실습을 진행합니다.
Dockerfile 작성: 헬스체크가 포함된 Dockerfile입니다.
# ~/healthcheck-lab/nginx-health/Dockerfile
FROM nginx:alpine
# curl 설치 (헬스체크에 필요)
RUN apk add --no-cache curl
# 커스텀 헬스체크 엔드포인트 생성
RUN echo '{"status":"ok","service":"nginx"}' > /usr/share/nginx/html/health
HEALTHCHECK \
--interval=10s \
--timeout=3s \
--start-period=5s \
--retries=3 \
CMD curl -f http://localhost/health || exit 1
EXPOSE 80
이미지 빌드 및 실행: 빌드 후 실행해서 헬스체크가 동작하는지 확인합니다.
cd ~/healthcheck-lab/nginx-health
docker build -t nginx-health:v1 .
docker run -d --name nginx-hc -p 8090:80 nginx-health:v1
헬스 상태 확인 (시작 직후 — starting 상태): start_period 동안은 starting 상태로 표시됩니다.
docker ps --format "table {{.Names}}\t{{.Status}}"
# NAMES STATUS
# nginx-hc Up 3 seconds (health: starting)
10초 후 healthy 상태 확인: 헬스체크가 통과하면 healthy로 전환됩니다.
docker ps --format "table {{.Names}}\t{{.Status}}"
# NAMES STATUS
# nginx-hc Up 15 seconds (healthy)
# 헬스체크 이력 상세 확인
docker inspect nginx-hc --format '{{json .State.Health}}' | python3 -m json.tool
{
"Status": "healthy",
"FailingStreak": 0,
"Log": [
{
"Start": "2026-03-28T10:00:10Z",
"End": "2026-03-28T10:00:10.123Z",
"ExitCode": 0,
"Output": " % Total % Received\n100 28 100 28 0:00:00\n{\"status\":\"ok\",\"service\":\"nginx\"}"
}
]
}
unhealthy 상태 강제 유발 — nginx 프로세스 중단: nginx를 중단하면 헬스체크가 실패하고 unhealthy로 바뀝니다.
# 컨테이너 내부에서 nginx 중지 (프로세스 종료 아님)
docker exec nginx-hc nginx -s stop
# 잠시 후 상태 확인 (retries=3이므로 약 30초 후 unhealthy)
watch docker ps --format "table {{.Names}}\t{{.Status}}"
# nginx-hc Up 45 seconds (unhealthy)
정리: 실습 컨테이너를 삭제합니다.
실행 중 컨테이너 강제 삭제 전에 상태를 확정
안전한 실행 조건: 실습 검증이 끝났고, 해당 컨테이너를 더 이상 진단하지 않을 때만 실행합니다.
실행 전 반드시 확인
- docker inspect로 Health 상태를 이미 확인했는가?
- 필요한 로그를 캡처했는가?
- 운영 컨테이너가 아닌 실습용 컨테이너가 맞는가?
docker rm -f nginx-hc위 항목을 모두 확인한 후 복사할 수 있습니다
docker rm -f nginx-hc
mkdir -p ~/healthcheck-lab/nginx-health && cd ~/healthcheck-lab/nginx-healthPostgreSQL이 완전히 초기화될 때까지 애플리케이션 서비스가 시작을 기다리는 구성을 실습합니다.
docker-compose.yml 작성: DB가 healthy 상태가 될 때까지 앱이 대기하는 구성입니다.
# ~/healthcheck-lab/db-wait/docker-compose.yml
version: "3.9"
services:
postgres:
image: postgres:16-alpine
container_name: hc_postgres
environment:
POSTGRES_DB: appdb
POSTGRES_USER: appuser
POSTGRES_PASSWORD: apppass
volumes:
- pg_data:/var/lib/postgresql/data
healthcheck:
# pg_isready: PostgreSQL 전용 연결 준비 확인 도구
test: ["CMD-SHELL", "pg_isready -U appuser -d appdb"]
interval: 5s
timeout: 3s
retries: 5
start_period: 15s
networks:
- app_net
redis:
image: redis:7-alpine
container_name: hc_redis
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 3s
retries: 5
networks:
- app_net
app:
image: alpine:latest
container_name: hc_app
# DB와 Redis가 모두 healthy 상태가 된 이후에만 시작
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
command: >
sh -c "
echo '=== 의존성 서비스 준비 완료 — 앱 시작 ===';
echo 'PostgreSQL 연결 확인...';
echo 'Redis 연결 확인...';
echo '앱이 정상적으로 시작되었습니다.';
sleep 60
"
networks:
- app_net
restart: on-failure:3
networks:
app_net:
driver: bridge
volumes:
pg_data:
실행 및 시작 순서 관찰: 의존 서비스가 healthy가 될 때까지 기다리는 것을 확인합니다.
cd ~/healthcheck-lab/db-wait
docker-compose up
# 출력 예시:
# hc_postgres | PostgreSQL init process complete; ready for start up.
# hc_postgres | LOG: database system is ready to accept connections
# hc_redis | Ready to accept connections
# hc_app | === 의존성 서비스 준비 완료 — 앱 시작 ===
# hc_app | PostgreSQL 연결 확인...
# hc_app | Redis 연결 확인...
# hc_app | 앱이 정상적으로 시작되었습니다.
백그라운드 실행 후 헬스 상태 일괄 확인: 모든 서비스의 헬스 상태를 한 번에 확인합니다.
docker-compose up -d
# 각 서비스의 헬스 상태 확인
docker-compose ps
# NAME SERVICE STATUS PORTS
# hc_app app Up (healthy)
# hc_postgres postgres Up (healthy) 5432/tcp
# hc_redis redis Up (healthy) 6379/tcp
# PostgreSQL 헬스체크 로그 확인
docker inspect hc_postgres --format '{{range .State.Health.Log}}ExitCode: {{.ExitCode}} | {{.Output}}{{println}}{{end}}'
# ExitCode: 0 | /var/run/postgresql:5432 - accepting connections
정리: 실습 환경과 볼륨을 삭제합니다.
docker-compose down -v
mkdir -p ~/healthcheck-lab/db-wait && cd ~/healthcheck-lab/db-wait재시작 정책이 실제로 어떻게 동작하는지 의도적으로 크래시를 발생시켜 확인합니다.
docker-compose.yml 작성: 재시작 정책을 테스트하기 위한 의도적 크래시 환경입니다.
# ~/healthcheck-lab/crash-test/docker-compose.yml
version: "3.9"
services:
# 1) 정상 서비스 — restart: unless-stopped
stable:
image: nginx:alpine
container_name: ct_stable
restart: unless-stopped
ports:
- "8091:80"
# 2) 크래시 반복 서비스 — restart: on-failure:3 (3회 후 포기)
crasher:
image: alpine:latest
container_name: ct_crasher
restart: on-failure:3
command: sh -c "echo '크래시 시뮬레이션!' && exit 1"
# 3) 헬스체크 실패 서비스 — unhealthy 상태 관찰
sick:
image: nginx:alpine
container_name: ct_sick
restart: on-failure:5
healthcheck:
# 존재하지 않는 엔드포인트를 체크 → 항상 실패
test: ["CMD", "curl", "-f", "http://localhost/nonexistent-health"]
interval: 5s
timeout: 3s
retries: 3
start_period: 3s
ports:
- "8092:80"
실행 후 재시작 카운터 관찰: 헬스체크 실패 시 컨테이너가 자동으로 재시작되는 것을 확인합니다.
cd ~/healthcheck-lab/crash-test
docker-compose up -d
# 30초 간격으로 크래셔 상태 관찰
watch -n 3 'docker inspect ct_crasher --format "재시작 횟수: {{.RestartCount}} | 상태: {{.State.Status}}"'
# 예상 출력 (30초 내):
# 재시작 횟수: 1 | 상태: restarting
# 재시작 횟수: 2 | 상태: restarting
# 재시작 횟수: 3 | 상태: exited
# (3회 초과 후 더 이상 재시작하지 않음)
sick 컨테이너 unhealthy 상태 확인: 헬스체크 실패 후 unhealthy로 전환된 것을 확인합니다.
# 약 20초 후 (start-period 3s + interval 5s × 3회)
docker ps --format "table {{.Names}}\t{{.Status}}"
# NAMES STATUS
# ct_stable Up 25 seconds
# ct_crasher Exited (1) 10 seconds ago
# ct_sick Up 25 seconds (unhealthy)
재시작 이력 로그 확인: 컨테이너가 몇 번이나 재시작됐는지 확인합니다.
docker inspect ct_crasher | python3 -c "
import sys, json
data = json.load(sys.stdin)[0]
print('최종 상태:', data['State']['Status'])
print('재시작 횟수:', data['RestartCount'])
print('종료 코드:', data['State']['ExitCode'])
print('오류 메시지:', data['State']['Error'])
"
# 최종 상태: exited
# 재시작 횟수: 3
# 종료 코드: 1
# 오류 메시지:
정리:
docker-compose down
mkdir -p ~/healthcheck-lab/crash-test && cd ~/healthcheck-lab/crash-test- starting/healthy/unhealthy 전환이 interval, retries, start-period 설정과 일치했는가?
- restart 정책이 종료 코드 기반으로 의도대로 동작하는지 확인했는가?
- 의존 서비스 준비 전 앱이 기동되지 않도록 service_healthy 조건을 검증했는가?
트러블슈팅
증상
Spring Boot, JVM 애플리케이션, 또는 초기화 시간이 긴 서비스에서 컨테이너가 시작된 직후 unhealthy 상태가 됩니다.
$ docker ps
CONTAINER ID STATUS
abc123 Up 12 seconds (unhealthy)
$ docker inspect myapp --format '{{range .State.Health.Log}}{{.ExitCode}} {{.Output}}{{println}}{{end}}'
1 curl: (7) Failed to connect to localhost port 8080: Connection refused
1 curl: (7) Failed to connect to localhost port 8080: Connection refused
1 curl: (7) Failed to connect to localhost port 8080: Connection refused
원인 분석
--start-period가 설정되지 않으면 기본값 0s가 적용됩니다. 컨테이너가 시작되는 즉시 헬스체크가 시작되고, JVM 워밍업(통상 10~30초)이 완료되기 전에 --retries 횟수를 모두 소진합니다.
실패 타임라인 (--start-period=0s, --interval=5s, --retries=3):
T+0s: 컨테이너 시작 (JVM 부팅 중...)
T+5s: 1차 헬스체크 → Connection refused (실패 1/3)
T+10s: 2차 헬스체크 → Connection refused (실패 2/3)
T+15s: 3차 헬스체크 → Connection refused (실패 3/3) → unhealthy!
T+20s: JVM 부팅 완료 (이미 늦음)
해결 방법
--start-period를 애플리케이션 최대 시작 시간보다 넉넉하게 설정합니다.
# 수정 전 (문제 있는 설정)
HEALTHCHECK --interval=5s --timeout=3s --retries=3 \
CMD curl -f http://localhost:8080/actuator/health || exit 1
# 수정 후 (Spring Boot 권장 설정)
HEALTHCHECK \
--interval=10s \
--timeout=5s \
--start-period=60s \ # JVM + Spring Boot 초기화를 위한 충분한 유예 기간
--retries=5 \
CMD curl -f http://localhost:8080/actuator/health || exit 1
docker-compose.yml에서 설정 시: Compose 파일에서 헬스체크를 정의하는 방법입니다.
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/actuator/health"]
interval: 10s
timeout: 5s
start_period: 60s # ← 이 설정이 핵심
retries: 5
검증: 헬스체크 설정이 실제로 동작하는지 확인합니다.
docker ps --format "{{.Names}}: {{.Status}}"
# myapp: Up 65 seconds (healthy) ← start-period 후 정상 판정
증상과 배경
PostgreSQL 컨테이너의 헬스체크를 curl로 설정했는데 작동하지 않거나, pg_isready를 사용했을 때 실제 DB 준비 여부와 다른 결과가 나옵니다.
# 잘못된 방법: curl은 PostgreSQL과 통신할 수 없음
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:5432/"]
# 결과: curl: (1) Received HTTP/0.9 when not allowed
서비스별 올바른 헬스체크 명령어
PostgreSQL: pg_isready 명령어로 DB 준비 상태를 확인합니다.
# 방법 1: pg_isready (권장) — TCP 연결 준비 여부만 확인
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ${POSTGRES_USER} -d ${POSTGRES_DB}"]
interval: 5s
timeout: 3s
retries: 5
start_period: 10s
# 방법 2: psql (실제 쿼리 실행 — 더 엄격한 검증)
healthcheck:
test: ["CMD-SHELL", "psql -U ${POSTGRES_USER} -d ${POSTGRES_DB} -c 'SELECT 1' || exit 1"]
pg_isready 출력 예시: 정상일 때와 아닐 때의 출력 차이입니다.
$ docker exec hc_postgres pg_isready -U appuser -d appdb
/var/run/postgresql:5432 - accepting connections # exit code 0 → healthy
$ docker exec hc_postgres pg_isready -U appuser -d appdb
/var/run/postgresql:5432 - rejecting connections # exit code 1 → 실패
MySQL/MariaDB: mysqladmin ping으로 DB 응답을 확인합니다.
# mysqladmin ping 사용
healthcheck:
test: ["CMD", "mysqladmin", "ping", "-h", "localhost", "-u", "root", "-p${MYSQL_ROOT_PASSWORD}"]
# 또는 mysql 클라이언트로 쿼리 실행
healthcheck:
test: ["CMD-SHELL", "mysql -u root -p${MYSQL_ROOT_PASSWORD} -e 'SELECT 1' || exit 1"]
Redis: redis-cli ping 명령어로 응답 여부를 확인합니다.
healthcheck:
test: ["CMD", "redis-cli", "ping"]
# 성공 시 출력: PONG (exit code 0)
HTTP/HTTPS 웹서버: curl로 HTTP 상태코드를 확인하는 범용 패턴입니다.
# curl 사용 (curl이 이미지에 포함된 경우)
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost/health"]
# wget 사용 (Alpine 이미지 기본 포함)
healthcheck:
test: ["CMD", "wget", "--no-verbose", "--tries=1", "--spider", "http://localhost/health"]
# nc (netcat) — 포트 열림 여부만 확인
healthcheck:
test: ["CMD-SHELL", "nc -z localhost 80 || exit 1"]
CMD vs CMD-SHELL 차이
# CMD: 환경변수 치환 불가, exec 형식으로 직접 실행
test: ["CMD", "pg_isready", "-U", "appuser"]
# CMD-SHELL: sh -c로 실행, 환경변수 치환 가능, 파이프/조건 연산자 사용 가능
test: ["CMD-SHELL", "pg_isready -U ${POSTGRES_USER} || exit 1"]
# ↑ 환경변수 사용 가능
심화 — 재시작은 종료를 트리거로, 지수 백오프로 일어난다
심화: restart 정책과 HEALTHCHECK는 서로 다른 신호로 움직인다
"헬스체크를 걸고 restart: always만 붙이면 알아서 복구되겠지"라는 기대는 두 메커니즘이 사실 서로 다른 신호로 움직인다는 것을 놓친 것입니다. 자동 복구를 신뢰하려면 각각이 무엇에 반응하는지 정확히 알아야 합니다.
- restart 정책은 '프로세스 종료(exit)'를 트리거로 한다: 컨테이너의 PID 1이 종료되면 정책에 따라 다시 띄웁니다.
on-failure는 종료 코드가 0이 아닐 때만,always·unless-stopped는 종료 코드와 무관하게 재시작합니다. HEALTHCHECK가 unhealthy로 바뀌는 것만으로는 (단일 Docker 호스트에서) 재시작이 일어나지 않습니다 — 헬스 상태와 재시작은 다른 축입니다. - crash loop에는 지수 백오프가 걸린다: 컨테이너가 시작하자마자 계속 죽으면, Docker는 재시작 간격을 대략 100ms에서 시작해 2배씩 늘립니다(상한까지). 그래서 무한 재시작이 CPU를 태우지 않습니다. 대신
docker ps의 STATUS가Restarting을 오가고,docker inspect의 RestartCount가 계속 증가합니다. - 종료 코드가 원인을 말해 준다:
137은 128+9(SIGKILL)로 대개 cgroup 메모리 한도 초과 시 OOM Killer가 죽인 경우,143은 128+15(SIGTERM)로 정상 종료 요청을 받은 경우입니다.docker inspect의State.ExitCode·State.OOMKilled를 먼저 읽으면 재시작 루프의 진짜 원인이 보입니다.
정리하면 HEALTHCHECK는 '상태를 보고하는 신호'이고 restart 정책은 '종료를 감지해 되살리는 손'입니다. 둘을 엮어 진짜 self-healing을 만들려면, 앱이 문제 상황에서 스스로 종료(exit) 하도록 설계하거나, 헬스 상태를 보고 조치하는 오케스트레이터를 얹어야 합니다.
상황: 운영 컨테이너를 restart: always로 띄웠는데, 잘 돌다가도 몇 분 간격으로 죽고 다시 뜨기를 반복합니다. docker ps의 STATUS에 Restarting이 자주 보이고, 로그에는 명확한 예외 스택도 없이 갑자기 끊깁니다.
원인: docker inspect로 보니 마지막 종료 코드가 137(128+9, SIGKILL)이고 State.OOMKilled가 true였습니다. 컨테이너가 --memory(또는 Compose의 mem_limit)로 걸린 cgroup 메모리 한도를 넘자, 커널의 OOM Killer가 프로세스를 강제 종료한 것입니다. restart: always는 죽은 컨테이너를 성실히 되살리지만, 되살아난 컨테이너가 다시 같은 한도에 부딪혀 또 죽습니다 — 재시작 정책이 근본 원인을 감추고 있었습니다.
진단: docker inspect --format '{{.State.OOMKilled}} {{.State.ExitCode}} {{.RestartCount}}' <container>로 OOM 여부·종료 코드·재시작 횟수를 한 번에 확인합니다. 호스트의 dmesg에 oom-killer 또는 Killed process 로그가 시각과 함께 남았는지도 봅니다. docker stats로 재시작 직전 메모리가 한도에 붙는지 관찰하면 확정입니다.
해결: 원인이 정상적 사용량인지 누수인지 나눠서 대응합니다. 워크로드에 비해 한도가 낮았다면 --memory를 실제 피크에 여유를 둬 올리고, 시간이 갈수록 메모리가 계속 우상향한다면 앱의 누수를 잡습니다. restart: always는 일시적 장애의 안전망으로 유지하되, 재시작 루프 자체를 알림으로 감지(RestartCount 급증)해 '되살아나니까 괜찮다'는 착각에 빠지지 않도록 합니다. 재시작은 자원 부족의 해결책이 아닙니다.
실무 맥락
상황
스타트업 A사는 트래픽이 적은 내부 관리 도구를 EC2 단일 서버에 Docker Compose로 운영합니다. Kubernetes를 도입할 규모는 아니지만, 서버를 24시간 모니터링할 인력도 없어 자동 복구가 필요합니다.
실무 수준의 self-healing Compose 구성
# production/docker-compose.yml
version: "3.9"
x-healthcheck-defaults: &hc-defaults
interval: 15s
timeout: 5s
retries: 3
start_period: 30s
x-restart-policy: &restart-policy
restart: unless-stopped
services:
nginx:
<<: *restart-policy
image: nginx:1.25-alpine
ports:
- "80:80"
- "443:443"
volumes:
- ./nginx/conf.d:/etc/nginx/conf.d:ro
- ./certbot/www:/var/www/certbot:ro
- ./certbot/conf:/etc/letsencrypt:ro
healthcheck:
<<: *hc-defaults
test: ["CMD", "wget", "--no-verbose", "--tries=1", "--spider", "http://localhost/health"]
start_period: 10s
depends_on:
api:
condition: service_healthy
networks:
- frontend
api:
<<: *restart-policy
image: company/internal-api:${VERSION}
env_file: .env.production
healthcheck:
<<: *hc-defaults
test: ["CMD", "wget", "--no-verbose", "--tries=1", "--spider", "http://localhost:3000/api/health"]
start_period: 45s # Node.js 초기화 시간 고려
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
networks:
- frontend
- backend
postgres:
<<: *restart-policy
image: postgres:16-alpine
volumes:
- pg_data:/var/lib/postgresql/data
- ./backups:/backups
env_file: .env.db
healthcheck:
<<: *hc-defaults
test: ["CMD-SHELL", "pg_isready -U ${POSTGRES_USER} -d ${POSTGRES_DB}"]
start_period: 15s
networks:
- backend
redis:
<<: *restart-policy
image: redis:7-alpine
command: redis-server --appendonly yes --requirepass ${REDIS_PASSWORD}
volumes:
- redis_data:/data
healthcheck:
<<: *hc-defaults
test: ["CMD-SHELL", "redis-cli -a ${REDIS_PASSWORD} ping | grep PONG || exit 1"]
start_period: 5s
networks:
- backend
networks:
frontend:
backend:
volumes:
pg_data:
redis_data:
운영팀이 추가하는 모니터링 스크립트
#!/bin/bash
# /opt/scripts/health-monitor.sh — cron으로 5분마다 실행
PROJECT_DIR="/opt/app/production"
ALERT_EMAIL="ops@company.com"
cd "$PROJECT_DIR"
# unhealthy 컨테이너 감지
UNHEALTHY=$(docker-compose ps --format json | \
python3 -c "
import sys, json
services = [json.loads(l) for l in sys.stdin]
unhealthy = [s['Name'] for s in services if 'unhealthy' in s.get('Health', '')]
print('\n'.join(unhealthy))
")
if [ -n "$UNHEALTHY" ]; then
echo "ALERT: unhealthy 컨테이너 감지: $UNHEALTHY"
# 헬스체크 로그 수집
for container in $UNHEALTHY; do
docker inspect "$container" \
--format '{{range .State.Health.Log}}{{.ExitCode}}: {{.Output}}{{end}}'
done | mail -s "Docker Health Alert" "$ALERT_EMAIL"
# 자동 재시작 시도
docker-compose restart $UNHEALTHY
fi
Kubernetes 이전 시 주요 변경점
| 기능 | Docker Compose | Kubernetes |
|---|---|---|
| 헬스체크 | HEALTHCHECK / healthcheck | livenessProbe / readinessProbe |
| 자동 재시작 | restart 정책 | restartPolicy |
| 의존성 순서 | depends_on + condition | initContainers |
| 자가 치유 | 단일 서버 내에서만 | 노드 장애 시에도 복구 |
HEALTHCHECK와 restart 정책으로 익힌 개념은 Kubernetes의 Probe 설정으로 자연스럽게 이어집니다. 원리는 동일하고 키워드만 바뀝니다.
HEALTHCHECK 상태 전파와 depends_on 연동
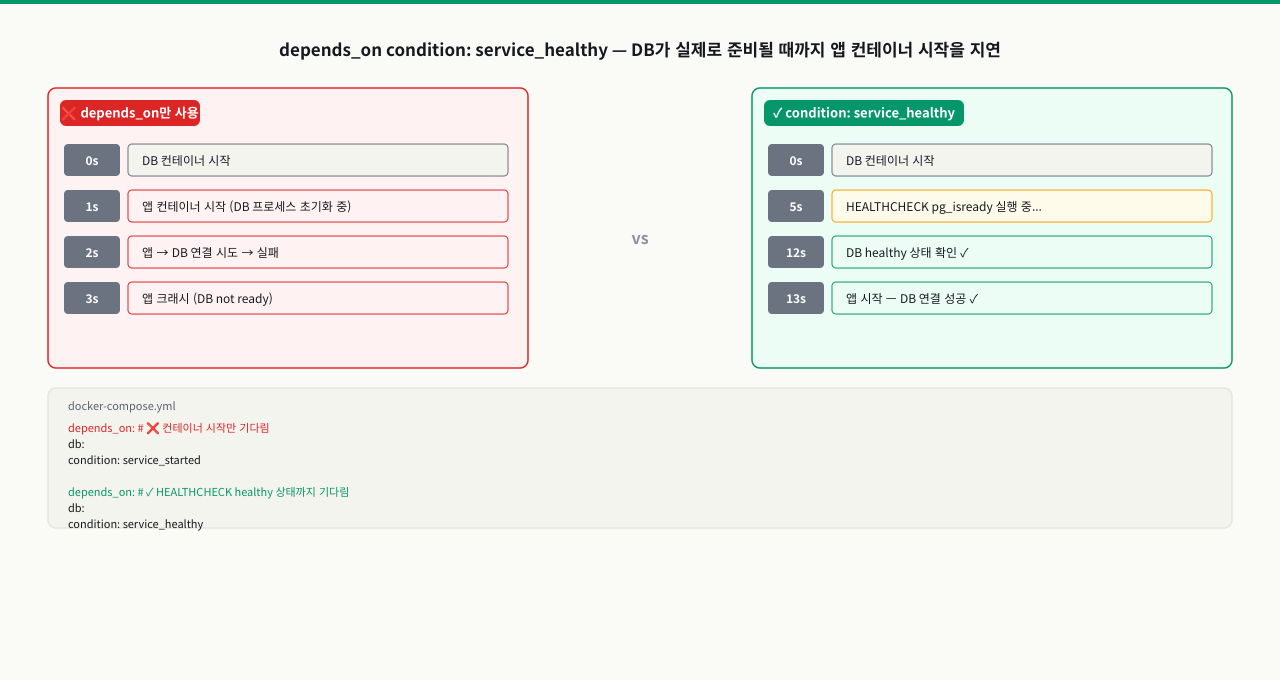
docker compose up으로 앱과 DB를 함께 올렸는데 앱이 "DB 연결 실패"로 크래시합니다. DB 컨테이너는 시작됐지만 PostgreSQL 프로세스가 아직 초기화 중이었기 때문입니다. depends_on: db만으로는 컨테이너 시작 순서만 보장하고 DB가 실제로 연결을 받을 준비가 됐는지는 보장하지 않습니다. condition: service_healthy를 쓰면 DB가 pg_isready를 통과할 때까지 앱 시작을 지연시킬 수 있습니다. 이 ConceptBlock에서는 HEALTHCHECK 상태 머신의 동작 원리와 depends_on과의 연동 방법을 다룹니다.
 확대
확대
HEALTHCHECK 상태 머신
컨테이너 시작 후 헬스체크 상태는 세 단계를 거칩니다.
컨테이너 시작
↓
starting ← --start-period 동안 (헬스체크 실패해도 unhealthy로 안 감)
↓
healthy ← 헬스체크 성공
또는
unhealthy ← --retries 횟수 연속 실패 시
# 컨테이너 상태 확인 (STATUS 컬럼)
docker ps
# NAME STATUS
# api Up 2 min (healthy) ← 정상
# db Up 30s (starting) ← 초기화 중
# worker Up 5 min (unhealthy) ← 문제 발생!
Dockerfile HEALTHCHECK 완전 문법
HEALTHCHECK [OPTIONS] CMD <command>
# 옵션:
# --interval=DURATION 헬스체크 실행 간격 (기본: 30s)
# --timeout=DURATION 타임아웃 (기본: 30s)
# --start-period=DURATION 초기화 유예 기간 (기본: 0s)
# --retries=N 연속 실패 횟수 → unhealthy (기본: 3)
# HTTP 서버 헬스체크
HEALTHCHECK --interval=30s --timeout=10s --start-period=40s --retries=3 \
CMD curl -f http://localhost:8080/health || exit 1
# TCP 포트 확인 (nc 사용)
HEALTHCHECK --interval=10s --timeout=5s --retries=3 \
CMD nc -z localhost 5432 || exit 1
# 커스텀 스크립트
HEALTHCHECK --interval=30s CMD /app/healthcheck.sh
# 헬스체크 비활성화 (상위 이미지의 HEALTHCHECK 제거)
HEALTHCHECK NONE
depends_on + service_healthy 패턴
services:
db:
image: postgres:16-alpine
healthcheck:
test: ["CMD", "pg_isready", "-U", "postgres"]
interval: 5s
timeout: 5s
retries: 5
start_period: 10s
redis:
image: redis:7-alpine
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 3s
retries: 3
app:
image: myapp
depends_on:
db:
condition: service_healthy # DB가 healthy 될 때까지 대기
redis:
condition: service_healthy # Redis도 healthy 될 때까지 대기
# depends_on 없이 그냥 실행하면:
# DB 컨테이너가 시작됐어도 PostgreSQL이 아직 초기화 중
# → 앱이 DB 연결 실패로 크래시 → restart → 연결 성공
# (retry 루프로 해결 가능하지만, service_healthy가 더 깔끔)
헬스체크 이력 확인
# 최근 헬스체크 결과 확인
docker inspect my-container --format \
'{{range .State.Health.Log}}{{.Start}} Exit:{{.ExitCode}} {{.Output}}{{end}}'
# Python으로 보기 좋게 출력
docker inspect my-container | python3 -c "
import sys, json
data = json.load(sys.stdin)
health = data[0]['State']['Health']
print('Status:', health['Status'])
print('--- Last 3 checks ---')
for h in health['Log'][-3:]:
print(h['Start'][:19], 'ExitCode:', h['ExitCode'])
if h['Output']:
print(' ', h['Output'][:100])
"
재시작 정책 4종 — 운영 상황별 올바른 선택
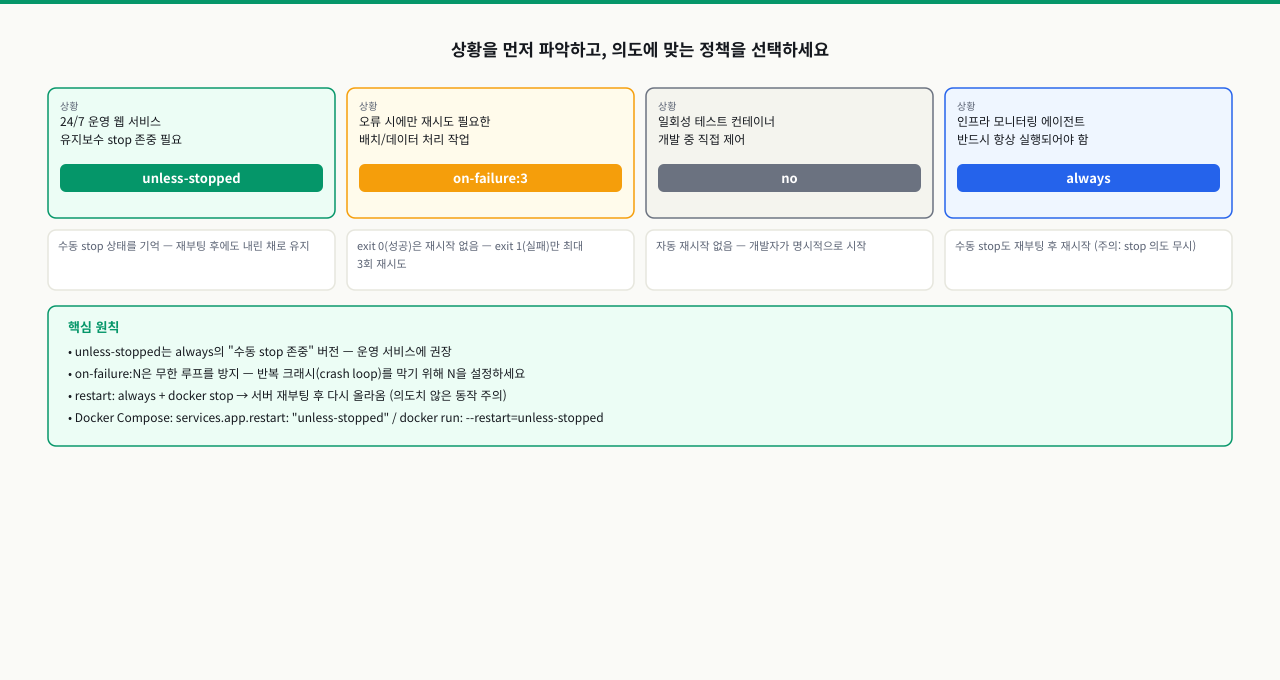
restart: always를 설정했는데 배포 중 점검을 위해 docker stop으로 컨테이너를 내렸습니다. 서버를 재부팅했더니 컨테이너가 다시 올라와 있습니다. 유지보수 의도가 무시된 것입니다. unless-stopped는 수동 stop 상태를 기억해서 재부팅 후에도 내린 채로 둡니다. 반대로 배치 작업은 정상 완료(exit 0) 후 재시작이 불필요하고, 오류(exit 1) 시에만 재시도해야 합니다. 이 ConceptBlock에서는 4가지 재시작 정책의 실제 동작 차이와 상황별 선택 가이드를 다룹니다.
 확대
확대
4가지 재시작 정책 비교
# no (기본값): 재시작 안 함
docker run --restart no myapp
# always: 항상 재시작 (수동 docker stop 후 Docker 재시작해도 시작됨)
docker run --restart always myapp
# unless-stopped: 수동으로 stop한 경우만 제외하고 재시작 (권장)
docker run --restart unless-stopped myapp
# on-failure: 오류 종료(exit code ≠ 0)일 때만 재시작
docker run --restart on-failure myapp
# on-failure:N: 최대 N번 시도 후 포기
docker run --restart on-failure:3 myapp
always vs unless-stopped — 실무에서 중요한 차이
가장 많이 혼동하는 부분입니다.
시나리오: 유지보수를 위해 docker stop myapp 실행 후
서버를 재부팅했을 때 어떻게 되는가?
always: 재부팅 후 컨테이너 자동 시작됨 ← 의도치 않은 재시작!
unless-stopped: 재부팅 후도 중지 상태 유지됨 ✓ (stop한 의도를 기억)
# 예시
docker run -d --name myapp --restart always myapp
docker stop myapp # 유지보수를 위해 중지
sudo reboot # 서버 재부팅
# 재부팅 후: myapp 컨테이너가 자동 시작됨 (always)
docker run -d --name myapp --restart unless-stopped myapp
docker stop myapp # 유지보수를 위해 중지
sudo reboot # 서버 재부팅
# 재부팅 후: myapp 컨테이너 중지 상태 유지 (unless-stopped) ✓
권장 사항: 대부분의 운영 서비스는 unless-stopped 사용
정책 선택 가이드
| 상황 | 권장 정책 |
|---|---|
| 개발 중, 테스트 실행 | no (기본값) |
| 일반 운영 서비스 (웹 서버, API 등) | unless-stopped |
| 절대 중단되면 안 되는 인프라 (Docker 재시작 포함) | always |
| 배치 작업, 오류 시만 재시도 필요 | on-failure:3 |
| 실행 완료 후 종료가 정상인 작업 | no |
재시작 횟수와 딜레이
Docker는 재시작이 반복될수록 딜레이를 늘립니다 (exponential backoff).
# 재시작 횟수 확인
docker inspect myapp --format '{{.RestartCount}}'
# 5 → 5번 재시작됨
# 현재 재시작 정책 확인
docker inspect myapp --format '{{.HostConfig.RestartPolicy}}'
# {unless-stopped 0}
# 실행 중인 컨테이너 재시작 정책 변경 (재시작 필요 없음)
docker update --restart unless-stopped myapp
재시작 딜레이: 100ms → 200ms → 400ms → 800ms → ... (최대 1분)
on-failure:3 설정 시 3번 모두 실패하면 더 이상 재시작하지 않습니다.
핵심 요약
| 개념 | 명령/설정 | 설명 |
|---|---|---|
| 헬스체크 주기 | --interval=30s | 헬스체크 실행 간격 (기본 30초) |
| 응답 대기 시간 | --timeout=10s | 명령어 응답 대기 시간 초과 시 실패 처리 |
| 연속 실패 허용 | --retries=3 | unhealthy 판정 전 허용 실패 횟수 |
| 시작 유예 기간 | --start-period=60s | 이 기간 동안 실패는 retries에 미포함 |
| 컨테이너 상태 | starting / healthy / unhealthy | HEALTHCHECK 결과에 따른 3가지 상태 |
| 항상 재시작 | restart: always | 종료 코드 무관, 데몬 재시작 시에도 적용 |
| 수동 중지 존중 | restart: unless-stopped | docker stop 후 데몬 재시작 시 비적용 |
| 실패 시만 재시작 | restart: on-failure:3 | 비정상 종료 시 최대 3회 재시작 |
| 서비스 준비 대기 | condition: service_healthy | depends_on과 조합, healthy 상태 확인 후 시작 |
| PostgreSQL 헬스체크 | pg_isready -U user -d db | PostgreSQL 전용 연결 준비 확인 도구 |
| Redis 헬스체크 | redis-cli ping | PONG 응답 확인 |
| HTTP 헬스체크 | curl -f URL 또는 wget --spider URL | HTTP 200 응답 확인 |
명령어·단축키 빠른 참조
이 모듈에서 헬스 상태 확인과 재시작 정책 조작에 실제로 쓴 docker 명령을 실전 예와 함께 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
docker ps | STATUS 컬럼에서 헬스 상태 확인 | docker ps --format "table {{.Names}}\t{{.Status}}" → (healthy) / (unhealthy) / (health: starting) |
docker inspect(Health) | 헬스체크 로그·실패 이력 조회 | docker inspect nginx-hc --format '{{json .State.Health}}' | python3 -m json.tool |
docker inspect(재시작) | 재시작 횟수·종료 원인 확인 | docker inspect crasher --format '{{.RestartCount}} {{.State.ExitCode}} {{.State.OOMKilled}}' |
docker run --restart | 실행 시 재시작 정책 지정 | docker run -d --restart=unless-stopped nginx:alpine |
docker update --restart | 실행 중 컨테이너 정책 변경 | docker update --restart on-failure:5 myapp |
docker compose ps | 서비스별 헬스 상태 일괄 확인 | docker compose ps → Up (healthy) |
docker compose up | 의존성 healthy 대기 후 기동 | docker compose up(포그라운드) / docker compose up -d |
docker compose restart | unhealthy 서비스만 재시작 | docker compose restart <서비스명> |
docker exec | 헬스체크 실패를 의도적으로 유발 | docker exec nginx-hc nginx -s stop (→ unhealthy 관찰) |
watch | 상태 전환 실시간 관찰 | watch docker ps --format "table {{.Names}}\t{{.Status}}" |
docker rm -f | 실습 컨테이너 강제 정리 | docker rm -f nginx-hc |
관련 모듈로 더 깊이:
- 프로덕션 수준의 멀티 서버 아키텍처 배포 워크플로우 — depends_on + service_healthy로 Nginx·WAS·DB 시작 순서를 보장하는 실전 구성
- 컨테이너 환경에서 처음 마주하는 흔한 오류 5가지 극복기 — 헬스체크가 unhealthy로 잡은 컨테이너를 셸 접속으로 파고드는 법
- cAdvisor + Prometheus + Grafana 모니터링 실무 — 헬스 상태와 재시작 이벤트를 지표로 수집해 자가 치유를 관측하는 법
다음 모듈에서는 운영 서버에서 컨테이너 내부 셸 접속, 파일 추출, 네트워크 트래픽 캡처 등 심화 디버깅 기법을 다룹니다.