오전 10시, 결제 API 응답 시간이 평소보다 10배 느리다는 알림이 왔습니다. 사용자들이 결제 버튼을 눌렀다 오류가 난다고 CS 문의가 쏟아집니다. 서버에 접속했는데 어디서부터 봐야 할지 모릅니다. CPU 문제인지, 메모리가 부족한지, 디스크가 꽉 찼는지 — 잘못된 곳을 먼저 보면 10분이 지나도 원인을 못 찾습니다. 올바른 순서로 올바른 도구를 쓰면 3분 안에 병목을 특정할 수 있습니다.
시스템 리소스 모니터링과 성능 분석
서버가 갑자기 느려졌을 때, "CPU 문제인가? 메모리인가? 디스크인가?"를 5분 안에 판단할 수 있어야 합니다. 이 모듈에서는 실무에서 가장 자주 쓰는 성능 진단 도구들을 체계적으로 다룹니다.
성능 문제는 반드시 데이터로 진단합니다. 느리다는 느낌이 아니라, 숫자로 어디가 병목인지 특정해야 해결이 가능합니다.
- 1top/htop로 CPU·메모리·프로세스를 실시간으로 모니터링할 수 있다
- 2load average를 코어 수 기준으로 해석할 수 있다
- 3vmstat로 CPU 스케줄러와 메모리 상태를 종합해 읽을 수 있다
- 4iostat -x의 await로 디스크 I/O 병목을 진단할 수 있다
- 5sar로 지나간 시점의 성능 추이를 되짚어 분석할 수 있다
- 6병목 유형(CPU·I/O·메모리)을 순서대로 특정해 진단할 수 있다
 확대
확대
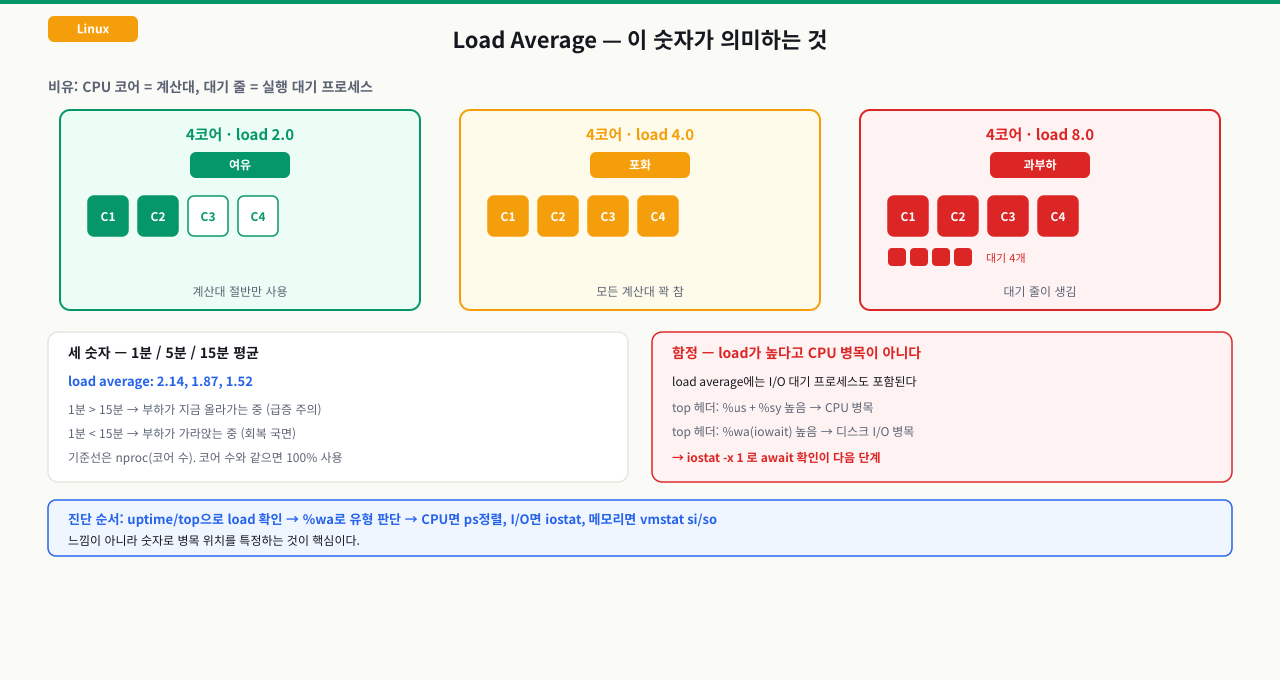
load average — 이 숫자가 높으면 무조건 문제인가?
 확대
확대
load average 올바르게 읽기
uptime 또는 top 상단에 보이는 세 숫자: 1분 / 5분 / 15분 평균 실행 대기 프로세스 수
$ uptime
14:23:01 up 42 days, load average: 2.14, 1.87, 1.52
CPU 코어 수 기준으로 판단합니다:
nproc # 논리 CPU 코어 수 확인
grep -c ^processor /proc/cpuinfo
| 코어 수 | load average 기준 | 상태 |
|---|---|---|
| 4코어 | < 4.0 | 정상 |
| 4코어 | 4.0 ~ 8.0 | 주의 |
| 4코어 | > 8.0 | 위험 |
중요: load average가 높다고 반드시 CPU 병목이 아닙니다. I/O 대기 중인 프로세스도 포함됩니다.
# CPU 병목 vs I/O 병목 구분
top
# 상단 확인: %us(user) + %sy(system) 높음 → CPU 병목
# %wa(iowait) 높음 → I/O 병목
vmstat으로 시스템 전체 상태 1초 단위로 보기
vmstat 1 10 # 1초 간격, 10회 출력
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 512000 82000 1024000 0 0 0 24 312 891 8 2 88 2 0
5 0 0 511000 82000 1024000 0 0 0 512 445 1203 45 8 45 2 0
핵심 컬럼:
- r: 실행 대기 중인 프로세스 수 (코어 수보다 지속적으로 높으면 CPU 포화)
- b: I/O 대기 중인 프로세스 수 (높으면 디스크/네트워크 I/O 병목)
- si/so: swap in/out (0이어야 정상. so > 0이면 메모리 부족 신호)
- wa: CPU I/O 대기 시간 비율 (10% 이상이면 디스크 점검 필요)
iostat으로 디스크 병목 정확히 찾기
iostat -x 1 5 # 확장 통계, 1초 간격, 5회
Device r/s w/s rMB/s wMB/s await svctm %util
sda 12.0 45.0 0.48 2.25 8.50 1.20 12.00
nvme0n1 5.0 120.0 0.20 15.00 0.40 0.30 98.50 ← 포화 상태
진단 기준:
| 지표 | 정상 | 주의 |
|---|---|---|
%util | < 70% | > 90% → 디스크 포화 |
await HDD | < 20ms | > 50ms → 이상 |
await SSD | < 1ms | > 10ms → 이상 |
svctm | await에 근접 | await >> svctm → 큐 대기 과다 |
실습: 병목 유형별 진단 시나리오
시나리오 1: CPU 병목
# 부하 발생 (실습 환경)
stress --cpu 4 --timeout 30 &
# 진단
top # %us 높음, load average 상승
vmstat 1 5 # r 컬럼 높음
시나리오 2: I/O 병목
# 디스크 부하
dd if=/dev/zero of=/tmp/test bs=1M count=2000 &
# 진단
iostat -x 1 5 # %util 높음, await 높음
top # %wa(iowait) 높음
시나리오 3: 메모리 부족
free -h
vmstat 1 5 # si/so 컬럼 확인 (swap in/out)
# 프로세스별 메모리 사용량 (RES 기준)
ps aux --sort=-%mem | head -10
load average와 CPU 코어 수 비교
echo '=== CPU 코어 수 ===' && nproc && echo '=== Load Average ===' && uptime예상 출력
=== CPU 코어 수 === 4 === Load Average === 14:00:00 up 5 days, load average: 0.25, 0.30, 0.28 (load/코어 < 1이면 여유 있는 상태)
top으로 CPU/메모리/iowait 1차 진단
top -bn1 | head -15예상 출력
top - 14:00:00 up 5 days Tasks: 120 total, 1 running %Cpu(s): 2.3 us, 0.5 sy, 0.0 ni, 97.0 id, 0.2 wa MiB Mem : 7981.0 total, 5000.0 free, 1500.0 used
vmstat으로 swap과 I/O 대기 프로세스 확인
vmstat 1 5예상 출력
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa 0 0 0 5000000 80000 1500000 0 0 0 20 300 800 2 1 97 0 (si/so=0이면 swap 미사용, b=0이면 I/O 대기 없음)
iostat으로 디스크 병목 지표 확인
iostat -x 1 3 2>/dev/null || echo 'sysstat 미설치 — sudo apt install sysstat'예상 출력
Device r/s w/s rMB/s wMB/s await %util sda 1.0 12.0 0.04 0.48 4.50 3.20 (%util < 70%, await < 20ms면 정상)
메모리 사용량 상위 프로세스 확인
ps aux --sort=-%mem | awk 'NR<=6 {printf "%-10s %5s %5s %s\n", $1, $3, $4, $11}'예상 출력
USER %CPU %MEM COMMAND root 0.0 5.2 /usr/bin/python3 www-data 0.1 3.1 nginx postgres 0.0 2.8 postgres
- uptime 출력에서 먼저 load average 1분 값을 보고, 그 다음 nproc 코어 수와 비교 — load/코어 > 2이면 포화, 그 다음 top의 %wa(iowait)가 10% 이상인지 확인해 CPU 병목인지 I/O 병목인지 구분
- 병목 판단 기준: top %wa < 5%이고 %us+%sy > 80%이면 CPU 병목, %wa > 20%이면 I/O 병목 — iostat -x의 await가 HDD 20ms 초과, SSD 1ms 초과이면 디스크 이상, vmstat si/so > 0이면 메모리 부족(swap 사용)
- load average가 코어 수의 2배 이상인데 top %us+%wa 모두 낮으면 → 다수 프로세스가 D 상태(I/O 대기, ps aux로 D 확인), free -h에서 available이 총 메모리의 10% 미만이면 → OOM killer 발동 위험을 의미
I/O 병목을 CPU 문제로 오진하는 케이스
$ uptime
load average: 25.00, 22.00, 18.00
$ top
%Cpu(s): 8.3 us, 1.2 sy, 0.0 ni, 12.5 id, 77.8 wa ← wa가 77.8%!
원인: load average는 CPU 대기뿐 아니라 I/O 대기 프로세스도 포함합니다. %wa(iowait)가 높으면 디스크/NFS/SAN 문제입니다.
# 확인
iostat -x 1 5 # 디스크 %util, await 확인
df -h # 디스크 풀 확인
dmesg | tail -20 # 디스크 에러 로그
흔한 원인: NFS 마운트 포인트 응답 없음, 디스크 불량 섹터, RAID 리빌드 중
실무에서 이 도구들이 쓰이는 순간
온콜 장애 대응 시나리오:
오전 3시: "API 응답 시간 급증" 알림
1. uptime → load average 확인
2. top → CPU/메모리/iowait 1차 확인
3. 이상 지표 발견:
- %wa 높음 → iostat -x 1 → 디스크 확인
- si/so 있음 → free -h → OOM 근접 확인
- r 높음 → 프로세스 급증 여부 확인
4. 원인 특정 → 해결 or 에스컬레이션
보통 신입이 가장 많이 틀리는 부분: load average만 보고 CPU 병목이라고 판단하는 것. iowait 확인까지 해야 합니다.
다음 모듈에서는 로그 관리와 분석 — rsyslog와 journald로 시스템 로그를 수집·보관하고 장애 원인을 추적하는 방법을 다룹니다.