오전 9시, NAS 서버에서 S.M.A.R.T 경고 이메일이 왔습니다. "Reallocated Sector Count가 임계값을 초과했습니다." 디스크가 곧 죽을 것 같다는 신호입니다. 서비스를 내리지 않고 해당 디스크를 교체해야 하는데, RAID가 어떻게 구성됐는지, 지금 어레이 상태가 정상인지, 교체 순서를 잘못 밟으면 데이터를 날릴 수도 있습니다. mdadm을 다룰 줄 아는 사람과 모르는 사람의 차이가 여기서 나옵니다.
RAID 구성과 장애 복구
데이터센터에서 디스크 장애는 예방할 수 없는 현실입니다. 기업용 디스크의 연간 장애율은 약 1~5%로, 수십 대의 서버를 운영하면 매년 수 건의 디스크 장애를 경험하게 됩니다. RAID(Redundant Array of Independent Disks)는 여러 디스크를 논리적으로 묶어 성능 향상과 장애 허용성을 동시에 제공하는 기술입니다. 이 챕터에서는 리눅스 소프트웨어 RAID 도구인 mdadm을 사용하여 RAID 1을 구성하고, 실제 장애 시나리오에서 복구하는 전체 절차를 실습합니다.
소프트웨어 RAID 구성과 장애 복구는 리눅스마스터 1급의 핵심 실기 주제입니다. RAID 레벨별 차이를 명확히 이해하고 mdadm 명령 흐름을 실습을 통해 체득합니다.
- 1RAID 레벨(0/1/5/6/10)을 장애 허용·실효 용량·성능 기준으로 비교할 수 있다
- 2XOR 패리티 원리로 RAID 5/6의 복구 메커니즘을 설명할 수 있다
- 3mdadm으로 소프트웨어 RAID를 구성하고 /proc/mdstat를 해석할 수 있다
- 4디스크 장애를 시뮬레이션하고 --fail → --remove → --add로 복구할 수 있다
- 5/etc/mdadm.conf로 영구 설정을 저장하고 hot spare를 구성할 수 있다
RAID 실습에는 최소 2개의 여분 디스크(또는 루프 디바이스)가 필요합니다. 운영 서버의 데이터 디스크가 아닌 별도 디스크나 VM의 가상 디스크를 사용하세요. mdadm이 없으면 sudo apt install mdadm 또는 sudo yum install mdadm으로 설치합니다.
lsblkmdadm --versioncat /proc/mdstatsudo -vRAID 레벨 비교와 패리티 원리
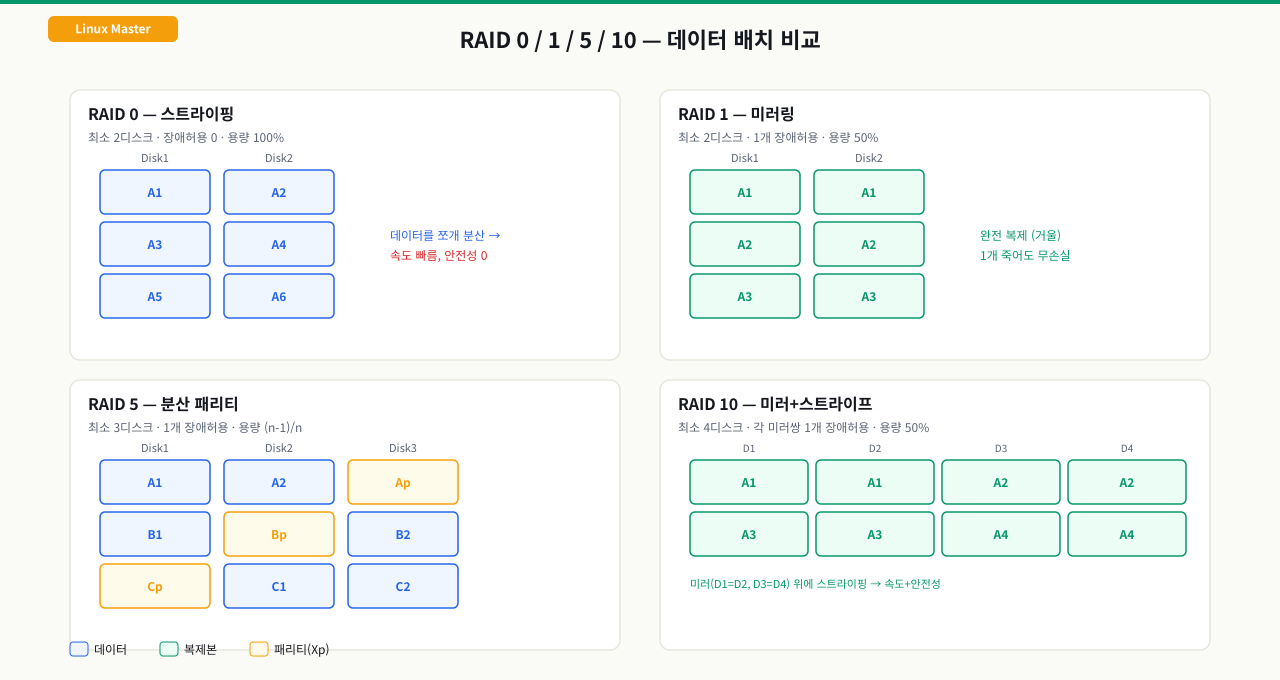
RAID 레벨별 특성
각 RAID 레벨은 서로 다른 성능, 용량 효율, 장애 허용성 트레이드오프를 가집니다.
 확대
확대
RAID 0 — 스트라이핑 (성능 우선)
RAID 0 데이터 분산:
디스크1: [A1][A3][A5][A7]
디스크2: [A2][A4][A6][A8]
쓰기: 데이터를 디스크 수로 분할하여 병렬 기록
- 최소 디스크: 2개
- 장애 허용: 0개 (디스크 1개 장애 → 전체 데이터 손실)
- 실효 용량: N × 디스크 크기 (100% 활용)
- 용도: 임시 데이터, 고성능 캐시 (데이터 안전성 불필요)
RAID 1 — 미러링 (안전성 우선)
RAID 1 미러링:
디스크1: [A][B][C][D] ← 원본
디스크2: [A][B][C][D] ← 동일한 복사본
- 최소 디스크: 2개
- 장애 허용: N-1개 (2개 중 1개 장애 허용)
- 실효 용량: 디스크 크기 × 1 (50% 효율)
- 용도: OS 디스크, 소용량 중요 데이터
RAID 5 — 분산 패리티 (균형형)
RAID 5 패리티 분산 (4개 디스크):
디스크1: [A1][B1][C1][P4]
디스크2: [A2][B2][P3][D1]
디스크3: [A3][P2][C3][D2]
디스크4: [P1][B4][C4][D3]
P = 패리티 블록 (해당 스트라이프의 XOR 값)
- 최소 디스크: 3개
- 장애 허용: 1개
- 실효 용량: (N-1) × 디스크 크기
- 용도: 파일 서버, NAS (가장 널리 사용)
RAID 6 — 이중 패리티 (높은 안전성)
RAID 6 이중 패리티:
각 스트라이프마다 P(XOR 패리티), Q(갈루아 필드 패리티) 2개 저장
→ 동시에 2개 디스크 장애 허용
- 최소 디스크: 4개
- 장애 허용: 2개
- 실효 용량: (N-2) × 디스크 크기
- 용도: 대용량 SATA 디스크 환경, 재구축 시간이 긴 환경
RAID 10 — 미러+스트라이핑 (성능+안전성)
RAID 10 구성 (4개 디스크):
Mirror 쌍1: 디스크1 ↔ 디스크2 (스트라이프 절반)
Mirror 쌍2: 디스크3 ↔ 디스크4 (스트라이프 절반)
- 최소 디스크: 4개
- 장애 허용: 각 미러 쌍에서 1개씩 (최대 2개, 단 같은 쌍이 아닌 경우)
- 실효 용량: 전체의 50%
- 용도: 고성능 DB 서버
RAID 레벨 비교표
| 레벨 | 최소 디스크 | 장애 허용 | 실효 용량 | 읽기 성능 | 쓰기 성능 |
|---|---|---|---|---|---|
| RAID 0 | 2 | 0 | N × 1 | 매우 빠름 | 매우 빠름 |
| RAID 1 | 2 | N-1 | 1개 분량 | 빠름 | 보통 |
| RAID 5 | 3 | 1 | (N-1) × 1 | 빠름 | 느림(패리티 계산) |
| RAID 6 | 4 | 2 | (N-2) × 1 | 빠름 | 더 느림 |
| RAID 10 | 4 | 쌍당 1개 | N/2 × 1 | 매우 빠름 | 빠름 |
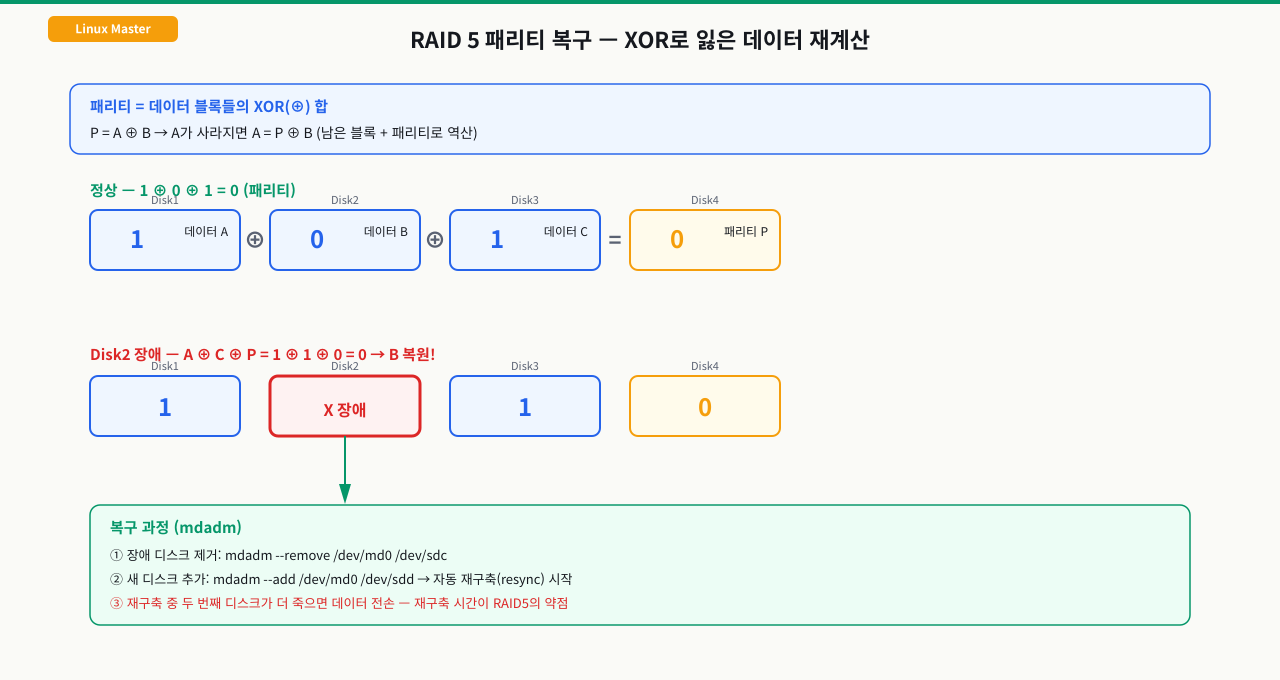
패리티 계산 원리 — XOR 연산
RAID 5/6의 패리티는 XOR(배타적 논리합) 연산으로 계산합니다.
 확대
확대
XOR 진리표:
0 XOR 0 = 0
0 XOR 1 = 1
1 XOR 0 = 1
1 XOR 1 = 0 ← 같으면 0
패리티 계산 예시 (3개 디스크):
디스크1: 1010
디스크2: 1100
디스크3: 0110
패리티P: 1010 XOR 1100 XOR 0110 = 0000
복구 원리 (디스크2 장애 시):
디스크2 = 패리티P XOR 디스크1 XOR 디스크3
디스크2 = 0000 XOR 1010 XOR 0110 = 1100 ← 복구됨
mdadm 명령과 /proc/mdstat 해석
mdadm 핵심 명령
mdadm(multiple device admin)은 리눅스 소프트웨어 RAID를 관리하는 표준 도구입니다.
어레이 생성
# RAID 1 생성 (디스크 2개, 어레이 /dev/md0)
sudo mdadm --create /dev/md0 \
--level=1 \
--raid-devices=2 \
/dev/sdb1 /dev/sdc1
# RAID 5 생성 (디스크 3개)
sudo mdadm --create /dev/md1 \
--level=5 \
--raid-devices=3 \
/dev/sdb /dev/sdc /dev/sdd
# hot spare 포함 RAID 5 (4개 디스크, 1개 스페어)
sudo mdadm --create /dev/md1 \
--level=5 \
--raid-devices=3 \
--spare-devices=1 \
/dev/sdb /dev/sdc /dev/sdd /dev/sde
어레이 상태 확인
# 전체 RAID 상태 실시간 확인
cat /proc/mdstat
Personalities : [raid1] [raid5] [raid6]
md0 : active raid1 sdb1[0] sdc1[1]
10476544 blocks super 1.2 [2/2] [UU]
md1 : active raid5 sdd[2] sdc[1] sdb[0]
20948992 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU]
unused devices: <none>
[UU] 상태 기호 해석:
| 기호 | 의미 |
|---|---|
U | Up — 해당 위치 디스크 정상 |
_ | 장애(faulty) 또는 missing 디스크 |
[2/2] | 필요한 디스크 수 / 현재 활성 디스크 수 |
# 특정 어레이 상세 정보
sudo mdadm --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Wed Mar 28 09:00:00 2026
Raid Level : raid1
Array Size : 10476544 (9.99 GiB 10.73 GB)
Used Dev Size : 10476544 (9.99 GiB 10.73 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Wed Mar 28 09:05:00 2026
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Layout : -
Chunk Size : 512K
Consistency Policy : resync
Name : server1:0 (local to host server1)
UUID : a1b2c3d4:e5f6a7b8:c9d0e1f2:a3b4c5d6
Number Major Minor RaidDevice State
0 8 17 0 active sync /dev/sdb1
1 8 33 1 active sync /dev/sdc1
# 디스크의 RAID 슈퍼블록 정보 확인
sudo mdadm --examine /dev/sdb1
/etc/mdadm.conf 영구 설정
# 현재 어레이 정보를 mdadm.conf에 저장
sudo mdadm --detail --scan | sudo tee -a /etc/mdadm.conf
# initramfs 업데이트 (부팅 시 자동 조립 적용)
sudo update-initramfs -u # Debian/Ubuntu
sudo dracut -f # RHEL/CentOS/Rocky
# /etc/mdadm.conf 예시
ARRAY /dev/md0 metadata=1.2 name=server1:0 UUID=a1b2c3d4:e5f6a7b8:...
ARRAY /dev/md1 metadata=1.2 name=server1:1 UUID=b2c3d4e5:f6a7b8c9:...
목표
/dev/sdb와 /dev/sdc를 사용하여 RAID 1 어레이를 구성하고 파일시스템을 올려 데이터 쓰기까지 확인합니다.
mkdir -p /tmp/linux-master/part1/raid
# RAID 실습용 가상 디스크 4개 생성
for i in 1 2 3 4; do
dd if=/dev/zero of=/tmp/linux-master/part1/raid/disk${i}.img bs=1M count=512 2>/dev/null
sudo losetup -f --show /tmp/linux-master/part1/raid/disk${i}.img
done
echo "RAID 실습용 루프백 장치 4개 준비 완료"
1단계: 실습 디스크 준비 확인
lsblk /dev/sdb /dev/sdc
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sdb 8:16 0 10G 0 disk
sdc 8:32 0 10G 0 disk
2단계: RAID 1 어레이 생성
sudo mdadm --create /dev/md0 \
--level=1 \
--raid-devices=2 \
/dev/sdb /dev/sdc
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store '/boot' on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
--metadata=0.90
Continue creating array? y
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
3단계: 초기 동기화 확인
cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdc[1] sdb[0]
10476544 blocks super 1.2 [2/2] [UU]
[=======>.............] resync = 38.2% (4003840/10476544) finish=0.5min speed=200192K/sec
unused devices: <none>
# 동기화 완료 대기
watch -n1 cat /proc/mdstat
md0 : active raid1 sdc[1] sdb[0]
10476544 blocks super 1.2 [2/2] [UU]
# [UU] = 두 디스크 모두 정상, 동기화 완료
4단계: 파일시스템 생성 및 마운트
# ext4 파일시스템 생성
sudo mkfs.ext4 /dev/md0
# 마운트
sudo mkdir /raid1
sudo mount /dev/md0 /raid1
# 테스트 데이터 쓰기
echo "RAID1 test data" | sudo tee /raid1/test.txt
df -hT /raid1
Filesystem Type Size Used Avail Use% Mounted on
/dev/md0 ext4 9.8G 28K 9.3G 1% /raid1
5단계: mdadm.conf 저장 및 fstab 등록
# RAID 설정 영구 저장
sudo mdadm --detail --scan | sudo tee -a /etc/mdadm.conf
# initramfs 업데이트
sudo update-initramfs -u 2>/dev/null || sudo dracut -f
# fstab 등록
echo '/dev/md0 /raid1 ext4 defaults 0 2' | sudo tee -a /etc/fstab
sudo mount -a && echo "fstab 검증 OK"
목표
RAID 1 어레이에서 디스크 장애를 시뮬레이션하고, 새 디스크로 교체하여 재구축 완료까지 모니터링합니다.
mkdir -p /tmp/linux-master/part1/raid
# RAID 실습용 가상 디스크 4개 생성
for i in 1 2 3 4; do
dd if=/dev/zero of=/tmp/linux-master/part1/raid/disk${i}.img bs=1M count=512 2>/dev/null
sudo losetup -f --show /tmp/linux-master/part1/raid/disk${i}.img
done
echo "RAID 실습용 루프백 장치 4개 준비 완료"
1단계: 장애 디스크 마킹 (--fail)
# sdb를 faulty 상태로 마킹 (S.M.A.R.T 경고 수신 후 예방적 교체 시나리오)
sudo mdadm --fail /dev/md0 /dev/sdb
mdadm: set /dev/sdb faulty in /dev/md0
cat /proc/mdstat
md0 : active raid1 sdc[1] sdb[0](F)
10476544 blocks super 1.2 [2/1] [_U]
# (F) = Faulty 상태, [_U] = sdb 장애, sdc 정상
sudo mdadm --detail /dev/md0 | grep -A5 "Number"
Number Major Minor RaidDevice State
- 0 0 0 removed
1 8 32 1 active sync /dev/sdc
0 8 16 - faulty /dev/sdb
2단계: 장애 디스크 제거 (--remove)
sudo mdadm --remove /dev/md0 /dev/sdb
mdadm: hot removed /dev/sdb from /dev/md0
# 이제 물리적으로 디스크를 교체 (Hot-swap 가능한 경우)
# 실습에서는 동일 디스크를 재사용하거나 /dev/sdd로 교체 가정
3단계: 새 디스크 추가 및 재구축 (--add)
# 새 디스크 /dev/sdd 추가 (또는 교체된 /dev/sdb 재사용)
sudo mdadm --add /dev/md0 /dev/sdd
mdadm: added /dev/sdd
# 재구축(resync) 진행 상황 모니터링
watch -n2 cat /proc/mdstat
md0 : active raid1 sdd[2] sdc[1]
10476544 blocks super 1.2 [2/1] [_U]
[=============>.......] recovery = 68.3% (7161856/10476544) finish=0.2min speed=198920K/sec
# 재구축 완료 확인
cat /proc/mdstat
md0 : active raid1 sdd[2] sdc[1]
10476544 blocks super 1.2 [2/2] [UU]
# [UU] = 재구축 완료, 두 디스크 모두 정상
4단계: 데이터 무결성 확인
# 원본 데이터 확인
cat /raid1/test.txt
# RAID1 test data ← 데이터 보존 확인
Hot Spare 설정
# 어레이에 hot spare 디스크 추가
# 장애 발생 시 자동으로 재구축 시작
sudo mdadm --add /dev/md0 /dev/sde
sudo mdadm --detail /dev/md0 | grep spare
# 2 8 64 - spare /dev/sde
목표
/proc/mdstat와 mdadm --detail로 어레이 상태를 모니터링하고, 이메일 알림을 설정합니다.
실시간 상태 모니터링
# 모든 RAID 어레이 상태 한눈에 보기
cat /proc/mdstat
Personalities : [raid1] [raid5] [raid6]
md0 : active raid1 sdd[2] sdc[1]
10476544 blocks super 1.2 [2/2] [UU]
md1 : active raid5 sdf[3] sde[2] sdd[1] sdc[0]
31457280 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
unused devices: <none>
# 어레이 세부 상태 확인
sudo mdadm --detail /dev/md0
# 디스크 슈퍼블록 확인
sudo mdadm --examine /dev/sdc
/dev/sdc:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : a1b2c3d4:e5f6a7b8:c9d0e1f2:a3b4c5d6
Name : server1:0
Creation Time : Wed Mar 28 09:00:00 2026
Raid Level : raid1
Raid Devices : 2
Avail Dev Size : 20953088 (9.99 GiB 10.73 GB)
Array Size : 10476544 (9.99 GiB 10.73 GB)
mdadm 모니터 데몬 설정
# /etc/mdadm.conf에 이메일 알림 설정
echo 'MAILADDR admin@company.com' | sudo tee -a /etc/mdadm.conf
# mdadm 모니터 데몬 시작 (장애 시 자동 이메일 발송)
sudo mdadm --monitor --daemonise --mail=admin@company.com \
--delay=30 /dev/md0 /dev/md1
# systemd로 mdmonitor 서비스 활성화
sudo systemctl enable mdmonitor
sudo systemctl start mdmonitor
sudo systemctl status mdmonitor
● mdmonitor.service - MD array monitor
Loaded: loaded (/usr/lib/systemd/system/mdmonitor.service; enabled)
Active: active (running) since Wed 2026-03-28 09:30:00 KST
- /proc/mdstat 출력에서 먼저 [N/N] 숫자가 같은지 확인하고(같으면 정상), 그 다음 [] 안의 U와 _ 기호를 확인 — [UU]=정상, [U_]=1개 장애, recovery 줄이 있으면 재구축 진행 중
- RAID 상태 기준: [2/2] [UU]=완전 정상, [2/1] [_U]=장애 후 degraded(RAID 1은 운영 가능), recovery 속도 200MB/s 이상=정상 재구축, 50MB/s 이하=디스크 성능 저하 또는 서비스 I/O 경합
- cat /proc/mdstat에서 어레이가 없고 "unused devices"만 보이면 → /etc/mdadm.conf 미설정(mdadm --assemble --scan으로 수동 조립), (F) 표시 디스크가 있으면 → 즉시 --remove 후 교체를 의미
문제 상황
RAID 어레이를 구성하고 마운트했으나 재부팅 후 /dev/md0이 존재하지 않아 마운트에 실패합니다.
# 재부팅 후 확인
cat /proc/mdstat
# Personalities :
# unused devices: <none> ← 어레이 없음
ls /dev/md*
# ls: cannot access '/dev/md*': No such file or directory
원인 분석
소프트웨어 RAID는 부팅 시 /etc/mdadm.conf를 참조하여 어레이를 자동으로 조립(assemble)합니다. 이 파일에 어레이 정보가 없으면 자동 조립이 실패합니다.
cat /etc/mdadm.conf
# DEVICE partitions ← 어레이 ARRAY 항목 없음
해결 방법
# 1. 디스크에서 RAID 슈퍼블록 스캔하여 어레이 감지
sudo mdadm --assemble --scan
# 2. 조립 성공 여부 확인
cat /proc/mdstat
md0 : active raid1 sdd[2] sdc[1]
10476544 blocks super 1.2 [2/2] [UU]
# 3. 현재 어레이를 mdadm.conf에 영구 등록
sudo mdadm --detail --scan | sudo tee -a /etc/mdadm.conf
cat /etc/mdadm.conf
DEVICE partitions
ARRAY /dev/md0 metadata=1.2 name=server1:0 UUID=a1b2c3d4:e5f6a7b8:...
# 4. initramfs 업데이트 (부팅 시 조립 적용)
sudo update-initramfs -u # Debian/Ubuntu
# 또는
sudo dracut -f # RHEL/CentOS/Rocky Linux
# 5. 재부팅 후 검증
sudo reboot
# 재부팅 후 cat /proc/mdstat로 자동 조립 확인
예방 포인트
- RAID 생성 직후
mdadm --detail --scan >> /etc/mdadm.conf실행을 워크플로에 포함합니다 update-initramfs또는dracut -f로 initramfs를 갱신해야 부팅 초기 단계에서 어레이가 조립됩니다
문제 상황
RAID 5 어레이에 디스크를 추가하여 재구축이 시작됐는데, 같은 서버에서 운영 중인 DB 서비스의 응답 시간이 크게 증가했습니다.
cat /proc/mdstat
md1 : active raid5 sde[3] sdd[2] sdc[1] sdb[0]
31457280 blocks super 1.2 level 5, 512k chunk [4/3] [UUU_]
[====>................] recovery = 22.1% (2318848/10485760) finish=5.3min speed=200000K/sec
원인 분석
RAID 재구축 시 커널은 기본적으로 가능한 최대 속도로 재구축을 수행합니다. 이로 인해 서비스 I/O와 재구축 I/O가 경합하여 서비스 성능이 저하됩니다.
해결 방법
# 현재 sync_speed 한계 확인
cat /proc/sys/dev/raid/speed_limit_min
cat /proc/sys/dev/raid/speed_limit_max
# speed_limit_min: 1000 (KB/s)
# speed_limit_max: 200000 (KB/s) ← 200MB/s
# 재구축 속도를 50MB/s로 제한 (서비스 I/O 영향 최소화)
echo 50000 | sudo tee /proc/sys/dev/raid/speed_limit_max
# 적용 확인
cat /proc/mdstat
# speed=50123K/sec ← 속도 제한 적용됨
# 영구 적용 (재부팅 후에도 유지)
cat << 'EOF' | sudo tee /etc/sysctl.d/99-raid.conf
dev.raid.speed_limit_min = 1000
dev.raid.speed_limit_max = 50000
EOF
sudo sysctl -p /etc/sysctl.d/99-raid.conf
# 재구축 완료 후 원래 속도 제한으로 복원
echo 200000 | sudo tee /proc/sys/dev/raid/speed_limit_max
운영 시 권장 사항
- 재구축 중에는 I/O 집중 작업(백업, 대용량 쿼리)을 피합니다
- 비업무 시간(야간)에 재구축이 완료되도록 속도를 조절합니다
- 모니터링 대시보드에서 I/O wait 지표를 주시합니다 (
iostat -x 1)
상황
파일 서버(NAS)의 RAID 5 어레이를 구성하는 디스크 /dev/sdc에서 S.M.A.R.T 경고(Reallocated Sector Count 급증)가 발생했습니다. 서비스 중단 없이 해당 디스크를 교체해야 합니다.
S.M.A.R.T 경고 확인
# S.M.A.R.T 상태 확인 (smartmontools 필요)
sudo smartctl -a /dev/sdc | grep -E "Reallocated|Pending|Uncorrectable"
5 Reallocated_Sector_Ct 0x0033 001 001 036 Pre-fail ... 2847
197 Current_Pending_Sector 0x0032 098 098 000 Old_age ... 213
198 Offline_Uncorrectable 0x0030 098 098 000 Old_age ... 201
무중단 교체 절차
# 1. 현재 어레이 상태 확인
sudo mdadm --detail /dev/md1
cat /proc/mdstat
# 2. 경고 디스크를 faulty로 마킹
sudo mdadm --fail /dev/md1 /dev/sdc
mdadm: set /dev/sdc faulty in /dev/md1
# 3. 어레이에서 논리적 제거
sudo mdadm --remove /dev/md1 /dev/sdc
# 4. 물리적 디스크 교체 (hot-swap 가능한 경우 서버 가동 중 교체)
# 교체 후 신규 디스크 /dev/sdc가 인식됨 확인
lsblk | grep sdc
# 5. 신규 디스크를 어레이에 추가
sudo mdadm --add /dev/md1 /dev/sdc
mdadm: added /dev/sdc
# 6. 재구축 진행 모니터링
watch -n5 'cat /proc/mdstat && echo && sudo mdadm --detail /dev/md1 | tail -10'
md1 : active raid5 sdc[4] sde[3] sdd[2] sdb[0]
31457280 blocks super 1.2 level 5 [4/3] [U_UU]
[=========>...........] recovery = 47.2% (4952064/10485760) finish=0.7min
# 7. 재구축 완료 후 최종 확인
sudo mdadm --detail /dev/md1 | grep -E "State|Active|Working|Failed|Spare"
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
현업 포인트
- S.M.A.R.T 모니터링은
smartd데몬으로 자동화하여 경고를 이메일로 수신합니다 - RAID 5는 재구축 중 추가 디스크 장애 시 데이터 손실 위험이 있으므로, 재구축 완료 전까지 I/O 부하를 줄입니다
- 대용량 디스크(4TB+) 환경에서는 재구축 시간이 수 시간에 달하므로 RAID 6 또는 hot spare 운영을 권장합니다
정리
핵심 개념 요약
| 항목 | 핵심 내용 |
|---|---|
| RAID 0 | 스트라이핑, 장애 허용 없음, 성능 최대, 실효 용량 100% |
| RAID 1 | 미러링, N-1개 장애 허용, 실효 용량 50% |
| RAID 5 | 분산 패리티(XOR), 1개 장애 허용, (N-1)/N 용량 |
| RAID 6 | 이중 패리티(P+Q), 2개 장애 허용, (N-2)/N 용량 |
| RAID 10 | 미러+스트라이핑, 쌍당 1개 허용, 50% 용량 |
| /proc/mdstat | U=정상, _=장애/missing, (F)=faulty |
| 장애 복구 순서 | --fail → --remove → 물리 교체 → --add |
| 영구 설정 | mdadm --detail --scan >> /etc/mdadm.conf + update-initramfs -u |
자주 사용하는 명령어 치트시트
# RAID 상태 확인
cat /proc/mdstat
sudo mdadm --detail /dev/md0
sudo mdadm --examine /dev/sdb
# RAID 생성
sudo mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/sdb /dev/sdc
# 장애 복구 시퀀스
sudo mdadm --fail /dev/md0 /dev/sdb # 1. faulty 마킹
sudo mdadm --remove /dev/md0 /dev/sdb # 2. 어레이에서 제거
sudo mdadm --add /dev/md0 /dev/sdd # 3. 새 디스크 추가 (재구축 자동 시작)
# 영구 설정 저장
sudo mdadm --detail --scan | sudo tee -a /etc/mdadm.conf
sudo update-initramfs -u # Debian/Ubuntu
sudo dracut -f # RHEL/CentOS/Rocky
다음 모듈에서는 부팅 프로세스와 systemd — 서버가 켜지는 순간부터 서비스 시작까지의 흐름과 장애 복구를 다룹니다.