로그 관리와 rsyslog/journald
새벽 4시, "디스크 사용량 100%" 알림이 울립니다. 서비스는 이미 로그를 쓰지 못해 500을 뱉기 시작했습니다. df -h 는 / 가 꽉 찼다고 하는데, 정작 큰 파일을 찾기가 어렵습니다.
du -sh /var/log/* 를 돌려보니 /var/log/messages 가 40GB. 며칠 전 누군가 디버그 로그 레벨을 켜둔 채 잊었고, logrotate가 그 속도를 못 따라간 겁니다. 더 황당한 건, 파일을 지워도 디스크가 회복되지 않는다는 점이었습니다 — rsyslog가 그 파일을 아직 열고 있었거든요.
로그는 평소엔 고맙다가 관리가 안 되면 서버를 죽입니다. journald와 rsyslog의 역할, journalctl로 빠르게 추적하는 법, logrotate로 디스크가 차기 전에 막는 법을 이 모듈에서 다룹니다.
로그는 서버 운영자의 블랙박스입니다. 장애가 나면 로그를 보고, 보안 침해를 당하면 로그로 역추적합니다. 그런데 로그가 너무 오래되면 디스크가 꽉 차고, 너무 빨리 지우면 추적이 안 됩니다.
로그를 잘 다루는 것이 장애를 빠르게 해결하는 핵심입니다.
- 1rsyslog와 journald의 역할 분리를 구분해 설명할 수 있다
- 2journalctl로 systemd 유닛 로그를 시간·심각도별로 필터링할 수 있다
- 3rsyslog 규칙(facility.severity → 목적지)을 작성할 수 있다
- 4logrotate로 로그 세대를 관리해 디스크 고갈을 막을 수 있다
- 5로그를 추적해 장애와 보안 침해의 원인을 찾을 수 있다
 확대
확대
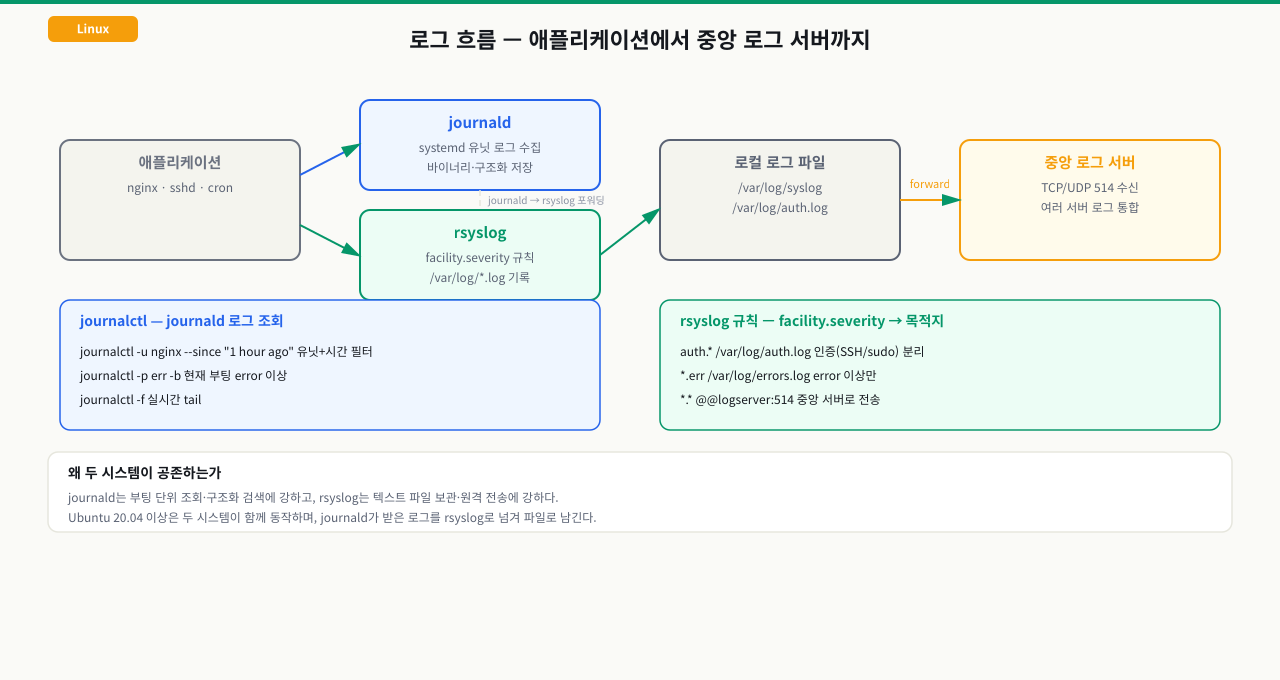
rsyslog vs journald — 뭐가 다른가?
Ubuntu 20.04 이상에서는 두 로깅 시스템이 공존합니다.
애플리케이션
↓ syslog() 호출
rsyslog ←──── journald (systemd 유닛 로그 수집)
↓
/var/log/*.log (텍스트 파일)
| 구분 | journald | rsyslog |
|---|---|---|
| 저장 형식 | 바이너리 (구조화) | 텍스트 파일 |
| 검색 | journalctl 명령 | grep/awk |
| 부팅 단위 조회 | 가능 | 불가 |
| 영구 보관 | /var/log/journal/ 설정 필요 | 기본 영구 |
| 원격 전송 | 제한적 | 강력 (TCP/UDP) |
journalctl 핵심 사용법
# 전체 로그 (최신부터)
journalctl -r
# 특정 유닛 로그
journalctl -u nginx
journalctl -u nginx -f # 실시간 tail
# 시간 필터
journalctl --since "2026-04-14 10:00:00"
journalctl --since "1 hour ago" --until "30 min ago"
# 부팅 단위
journalctl -b # 현재 부팅 로그
journalctl -b -1 # 이전 부팅 로그
journalctl --list-boots
# 심각도 필터 (0=emerg ~ 7=debug)
journalctl -p err # error 이상만
journalctl -p warning -u sshd
# 특정 프로세스/PID
journalctl _PID=1234
journalctl _COMM=nginx
# 디스크 사용량 및 정리
journalctl --disk-usage
journalctl --vacuum-size=500M # 500MB 이하로 정리
journalctl --vacuum-time=30d # 30일 이전 삭제
- journalctl --disk-usage 출력에서 먼저 총 사용량을 보고, 그 다음 journalctl -b 로 이번 부팅 이후 로그와 journalctl -b -1 로 이전 부팅 로그를 비교 — 갑자기 증가한 부팅 구간이 장애 발생 시점
- 저널 용량 기준: 500MB 미만=정상, 1GB 이상=vacuum 권장, 5GB 이상=즉시 --vacuum-size=500M 실행 — 기본 보관 한도는 /etc/systemd/journald.conf의 SystemMaxUse
- /var/log/journal 디렉토리가 없고 journalctl --disk-usage가 0이면 → 휘발성 저널(재부팅 시 소멸), /var/log/journal 존재하고 용량이 쌓이면 → 영구 저장 설정 확인됨을 의미
journald 디스크 사용량 및 저널 유형 확인
journalctl --disk-usage && ls -la /var/log/journal 2>/dev/null || echo '휘발성 저널 (재부팅 시 삭제됨)'예상 출력
Archived and active journals take up 48.0M in the file system. (또는 '휘발성 저널' 메시지)
최근 1시간 에러 로그 필터링
journalctl -p err --since '1 hour ago' --no-pager | head -20예상 출력
(에러가 없으면 출력 없음, 있으면 에러 메시지 목록 출력)
rsyslog 활성 규칙 확인
grep -v '^#' /etc/rsyslog.conf | grep -v '^$' | head -20예상 출력
auth,authpriv.* /var/log/auth.log *.*;auth,authpriv.none -/var/log/syslog
logrotate 설정 확인 및 드라이런
ls /etc/logrotate.d/ && logrotate -d /etc/logrotate.conf 2>&1 | head -20예상 출력
apache2 apt dpkg rsyslog syslog ufw reading config file /etc/logrotate.conf Allocating hash table for state file
SSH 브루트포스 시도 IP 탐지
grep 'Failed password' /var/log/auth.log 2>/dev/null | awk '{print $(NF-3)}' | sort | uniq -c | sort -rn | head -10예상 출력
47 203.0.113.1 23 198.51.100.2 (실패 횟수가 높은 IP가 브루트포스 의심)
rsyslog 규칙과 원격 로그 전송
# /etc/rsyslog.conf 또는 /etc/rsyslog.d/50-default.conf
# 문법: facility.severity destination
auth,authpriv.* /var/log/auth.log
kern.* /var/log/kern.log
*.*;auth,authpriv.none /var/log/syslog
# 심각도 수준: emerg(0) > alert(1) > crit(2) > err(3) > warning(4) > notice(5) > info(6) > debug(7)
# *.err → err 이상 (err, crit, alert, emerg)
# *.=info → info만 정확히
# *.info;mail.none → info 이상이지만 mail facility 제외
원격 서버로 로그 전송 (중앙 로그 서버 구성):
# 클라이언트: /etc/rsyslog.d/10-remote.conf
*.* @@log-server.example.com:514 # TCP (@@)
*.* @log-server.example.com:514 # UDP (@)
# 서버: 수신 설정 활성화
# /etc/rsyslog.conf
module(load="imtcp")
input(type="imtcp" port="514")
logrotate — 디스크가 꽉 차기 전에
 확대
확대
# /etc/logrotate.d/nginx 예시
/var/log/nginx/*.log {
daily # 매일 로테이션
rotate 14 # 14개 세대 보관
compress # gzip 압축
delaycompress # 직전 파일은 압축 안 함 (읽기 가능 유지)
missingok # 파일 없어도 에러 없음
notifempty # 빈 파일은 로테이션 안 함
create 0640 www-data adm # 새 파일 권한/소유자
sharedscripts
postrotate
nginx -s reopen # 로테이션 후 nginx에 새 파일 열도록 시그널
endscript
}
# 즉시 실행 (테스트)
logrotate -d /etc/logrotate.d/nginx # dry-run
logrotate -f /etc/logrotate.d/nginx # 강제 실행
$ df -h
/dev/sda1 50G 50G 0G 100% / ← 꽉 참
$ du -sh /var/log/* | sort -rh | head -5
12G /var/log/syslog
8G /var/log/auth.log
원인: logrotate 미설정 또는 로그 레벨이 debug로 설정된 채 방치
즉시 조치:
# 현재 로그 빠르게 비우기 (파일 삭제 X — 프로세스가 파일 핸들 유지 중)
> /var/log/syslog # 파일 내용만 비움
# journald 즉시 정리
journalctl --vacuum-size=100M
근본 해결:
# rsyslog 레벨 조정 (debug → info)
# /etc/rsyslog.conf
*.info /var/log/syslog # debug 제외
# logrotate 즉시 적용
logrotate -f /etc/logrotate.conf
실무에서 로그를 보는 상황
장애 분석 패턴:
# 1. 언제 문제가 시작됐나?
journalctl -u myapp --since "2026-04-14 02:00" | head -50
# 2. 에러 메시지 추출
journalctl -u myapp -p err --since today
# 3. 특정 키워드 찾기
journalctl -u myapp | grep -i "OOM\|killed\|failed"
# 4. 보안 침해 의심
grep "Failed password" /var/log/auth.log | awk '{print $11}' | sort | uniq -c | sort -rn
# → IP별 실패 횟수 → 브루트포스 탐지
로그 중앙화는 5대 이상 서버 운영 시 필수입니다. 개별 서버 SSH 접속 없이 한 곳에서 전체 로그를 검색할 수 있어야 장애 대응 속도가 됩니다.
다음 모듈에서는 백업과 복구 전략 — rsync, tar, 3-2-1 원칙으로 데이터를 안전하게 보호하고 장애 시 복구하는 방법을 다룹니다.