DEPLOYMENT
00:00 경과
LABLAB-DB-03-INDEX-DESIGN중급
쿼리가 100만 건을 다 뒤진다 — PostgreSQL 인덱스 설계
ELAPSED
00:00
PHASE
0 / 6
SLA
60분
🗄️ Database← 목록
TRACK
DATABASE
SLA
60분
LEVEL
중급
PHASES
5단계
ENV
local
INCOMING TICKET
“모니터링 경보: "주문 조회 API 평균 응답 3.2초 — SLO 위반. orders 테이블 100만 건 돌파 이후 갑자기 느려짐"”
YOUR ROLE
주니어 인프라 엔지니어
안 하면 나중에
주문 조회 API SLO 위반 — 사용자 경험 저하. 인덱스 없이 데이터가 계속 쌓이면 응답 시간이 선형으로 증가
📋상황 브리핑
신규 배포 직후 모니터링 대시보드에 빨간 불이 켜졌습니다.
주문 조회 API 평균 응답 3.2초 — SLO 위반
개발팀은 "코드는 안 바꿨는데요"라고 합니다. 맞는 말입니다. 코드는 바뀌지 않았습니다.
바뀐 건 데이터입니다. orders 테이블이 지난달 10만 건에서 이번 달 100만 건으로 늘었습니다.
데이터가 10배 늘었는데 쿼리 시간이 10배 느려졌다면, 인덱스가 없는 것입니다.
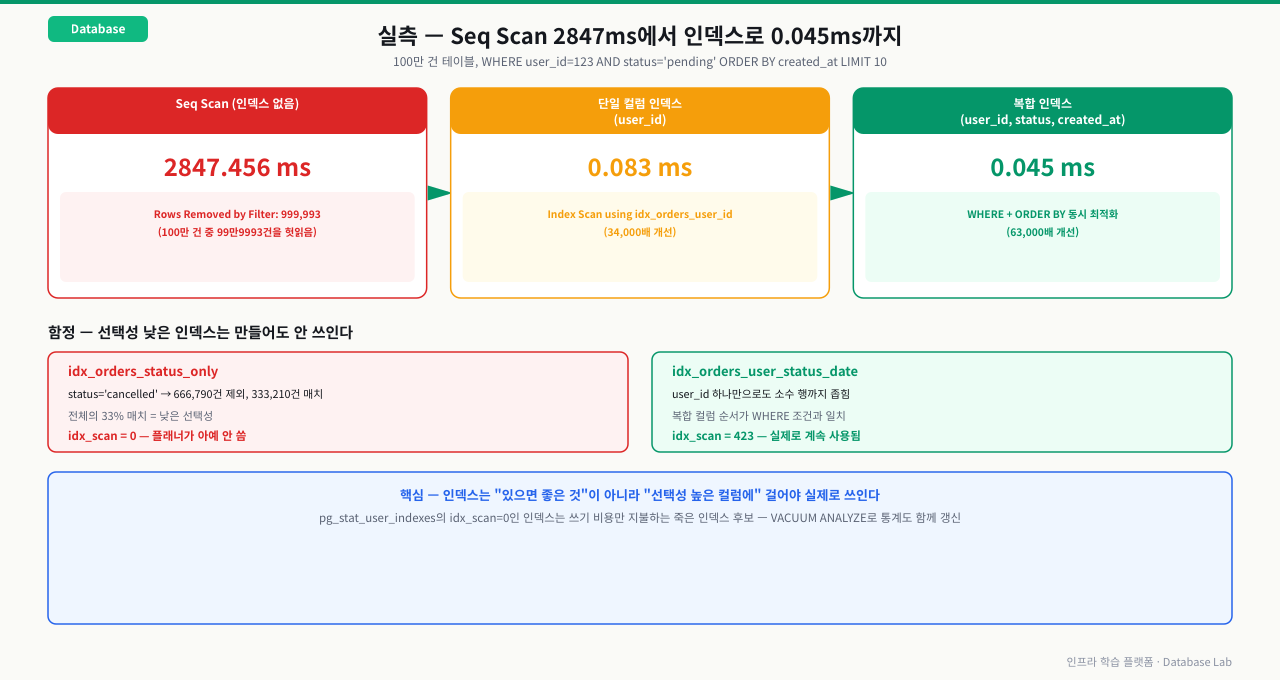
인덱스는 "100만 건을 전부 뒤지는 것"을 "딱 필요한 것만 찾는 것"으로 바꿔줍니다.
 확대
확대이 Lab에서는 EXPLAIN ANALYZE로 쿼리가 왜 느린지 읽고, 단일 인덱스와 복합 인덱스를 설계해
응답 시간을 3초에서 수 밀리초로 줄이는 전 과정을 실습합니다.
⏱ 60분📊 중급🔧 5단계#postgresql#index#query-optimization#explain-analyze
MISSION
1
EXPLAIN ANALYZE — 쿼리가 왜 느린지 읽기
EXPLAIN ANALYZE로 느린 쿼리의 실행 계획을 확인하고 Seq Scan과 높은 cost를 발견한다
2
단일 컬럼 인덱스 생성
user_id 컬럼에 인덱스를 생성하고, EXPLAIN ANALYZE로 Seq Scan에서 Index Scan으로 바뀐 것을 확인한다
3
복합 인덱스 설계 — WHERE + ORDER BY 최적화
user_id, status, created_at 세 컬럼을 조합한 복합 인덱스를 만들고, 정렬까지 인덱스로 처리되는지 확인한다
4
인덱스 선택성 & 오버헤드 이해
선택성이 낮은 컬럼(status)에만 인덱스를 만들면 오히려 성능이 나빠질 수 있음을 실험으로 확인하고, 인덱스 사용 현황 모니터링 쿼리를 작성한다
5
VACUUM ANALYZE — 통계 갱신과 죽은 행 정리
VACUUM ANALYZE를 실행해 테이블 통계를 갱신하고, 플래너가 더 정확한 실행 계획을 세울 수 있도록 한다
📌 선수 지식
• [실습] postgresql-setup
• [실습] postgresql-slow-query
ℹ️ 실습 환경
환경: local
필요 도구: bash, postgresql, psql
검증 스크립트:
/labs/lab-db-03-index-design/scripts/verify.sh🔒
실습 실행은 Pro 플랜 전용입니다
인시던트 브리프와 학습 자료는 지금 바로 확인할 수 있습니다. 실제 실습 진행 및 터미널 사용은 Pro 플랜에서 가능합니다.
Pro로 업그레이드 →>_ LAB WORKSPACE
NOTES